Model dokumentu identyfikatora analizy dokumentów
Ważne
- Publiczne wersje zapoznawcze analizy dokumentów zapewniają wczesny dostęp do funkcji, które są aktywnie opracowywane.
- Funkcje, podejścia i procesy mogą ulec zmianie przed ogólną dostępnością na podstawie opinii użytkowników.
- Publiczna wersja zapoznawcza bibliotek klienckich usługi Document Intelligence jest domyślna dla interfejsu API REST w wersji 2024-02-29-preview.
- Publiczna wersja zapoznawcza 2024-02-29-preview jest obecnie dostępna tylko w następujących regionach świadczenia usługi Azure:
- Wschodnie stany USA
- Zachodnie stany USA 2
- Europa Zachodnia
Ta zawartość dotyczy:v4.0 (wersja zapoznawcza) | Poprzednie wersje:![]()
![]() v3.1 (GA)v3.0 (GA)
v3.1 (GA)v3.0 (GA)![]()
![]() v2.1 (GA)
v2.1 (GA)
Ta zawartość dotyczy:v3.1 (GA)Najnowsza wersja:![]()
![]() v4.0 (wersja zapoznawcza) | | Poprzednie wersje:
v4.0 (wersja zapoznawcza) | | Poprzednie wersje:![]() v3.0
v3.0![]() v2.1
v2.1
Ta zawartość dotyczy:v3.0 (GA) | Najnowsze wersje:![]()
![]() v4.0 (wersja zapoznawcza)
v4.0 (wersja zapoznawcza)![]() v3.1 | Poprzednia wersja:
v3.1 | Poprzednia wersja:![]() v2.1
v2.1
Ta zawartość dotyczy:v2.1 Najnowsza wersja:![]()
![]() v4.0 (wersja zapoznawcza) |
v4.0 (wersja zapoznawcza) |
Model dokumentów tożsamości analizy dokumentów (ID) łączy optyczne rozpoznawanie znaków (OCR) z modelami uczenia głębokiego w celu analizowania i wyodrębniania kluczowych informacji z dokumentów tożsamości. Interfejs API analizuje dokumenty tożsamości (w tym następujące) i zwraca ustrukturyzowaną reprezentację danych JSON:
- Książka paszportowa, karta paszportowa na całym świecie
- Licencja kierowcy z Stany Zjednoczone, Europy, Indii, Kanady i Australii
- Stany Zjednoczone karty identyfikacyjne, zezwolenie na pobyt (zielona karta), kartę ubezpieczenia społecznego, identyfikator wojskowy
- Europejskie karty identyfikacyjne, zezwolenia na pobyt
- Karta Pan w Indiach, karta Aadhaar
- Karty identyfikacyjne Kanady, pozwolenie na pobyt (karta klonowa)
- Australia photo card, key-pass ID (w tym wersja cyfrowa)
Analiza dokumentów może analizować i wyodrębniać informacje z dokumentów identyfikacyjnych wystawionych przez instytucje rządowe przy użyciu wstępnie utworzonego modelu identyfikatorów. Łączy nasze zaawansowane funkcje optycznego rozpoznawania znaków (OCR) z funkcjami rozpoznawania identyfikatorów, aby wyodrębnić kluczowe informacje z światowych paszportów i licencji kierowców USA (wszystkie 50 stanów i DC). Interfejs API identyfikatorów wyodrębnia kluczowe informacje z tych dokumentów tożsamości, takich jak imię, nazwisko, data urodzenia, numer dokumentu i inne. Ten interfejs API jest dostępny w usłudze Document Intelligence w wersji 2.1 jako usługi w chmurze.
Przetwarzanie dokumentów tożsamości
Przetwarzanie dokumentów tożsamości obejmuje wyodrębnianie danych z dokumentów tożsamości ręcznie lub przy użyciu technologii OCR. Przetwarzanie dokumentów identyfikatorów to ważny krok w każdej operacji biznesowej, która wymaga potwierdzenia tożsamości. Przykłady obejmują weryfikację klienta w bankach i innych instytucjach finansowych, wniosków hipotecznych, wizyt medycznych, przetwarzania roszczeń, branży hotelarskiej i nie tylko. Osoby fizyczne dostarczają pewne dowody tożsamości za pośrednictwem licencji, paszportów i innych podobnych dokumentów, aby firma mogła skutecznie je zweryfikować przed świadczeniem usług i świadczeń.
Przykładowa licencja kierowcy USA przetworzona w usłudze Document Intelligence Studio
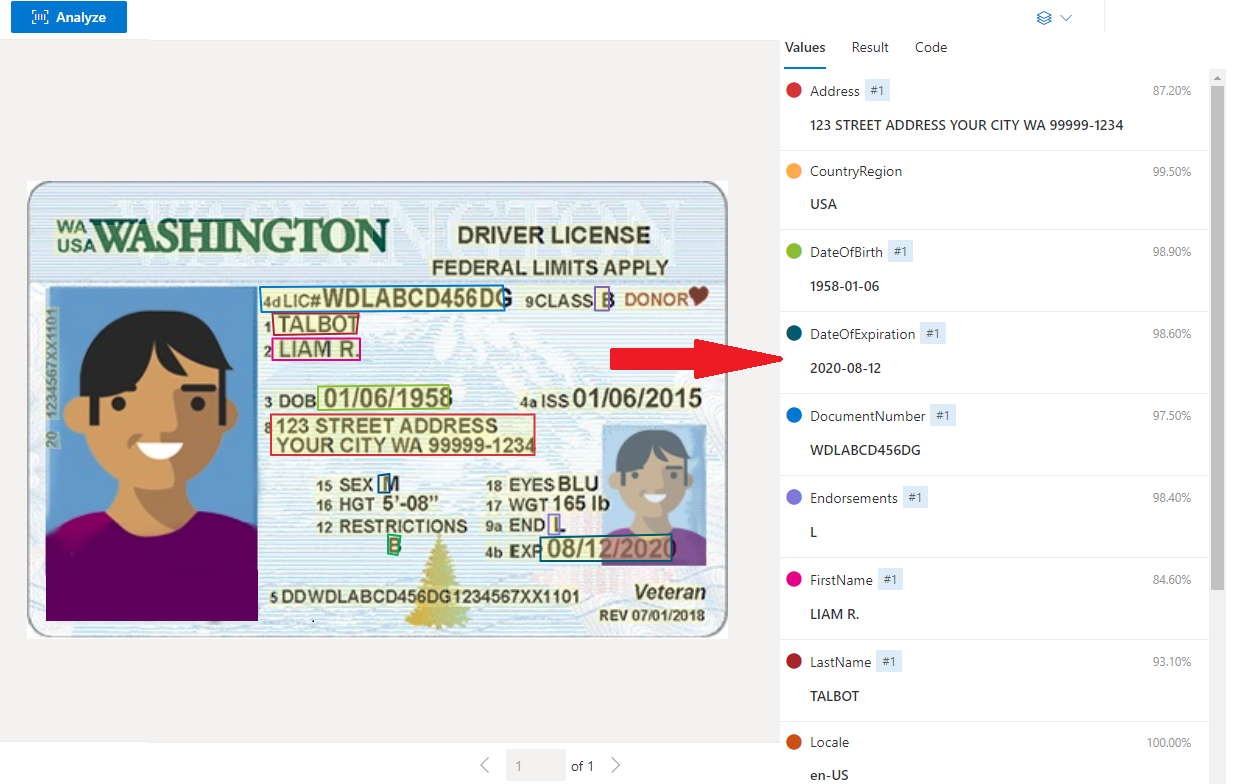
Wyodrębnianie danych
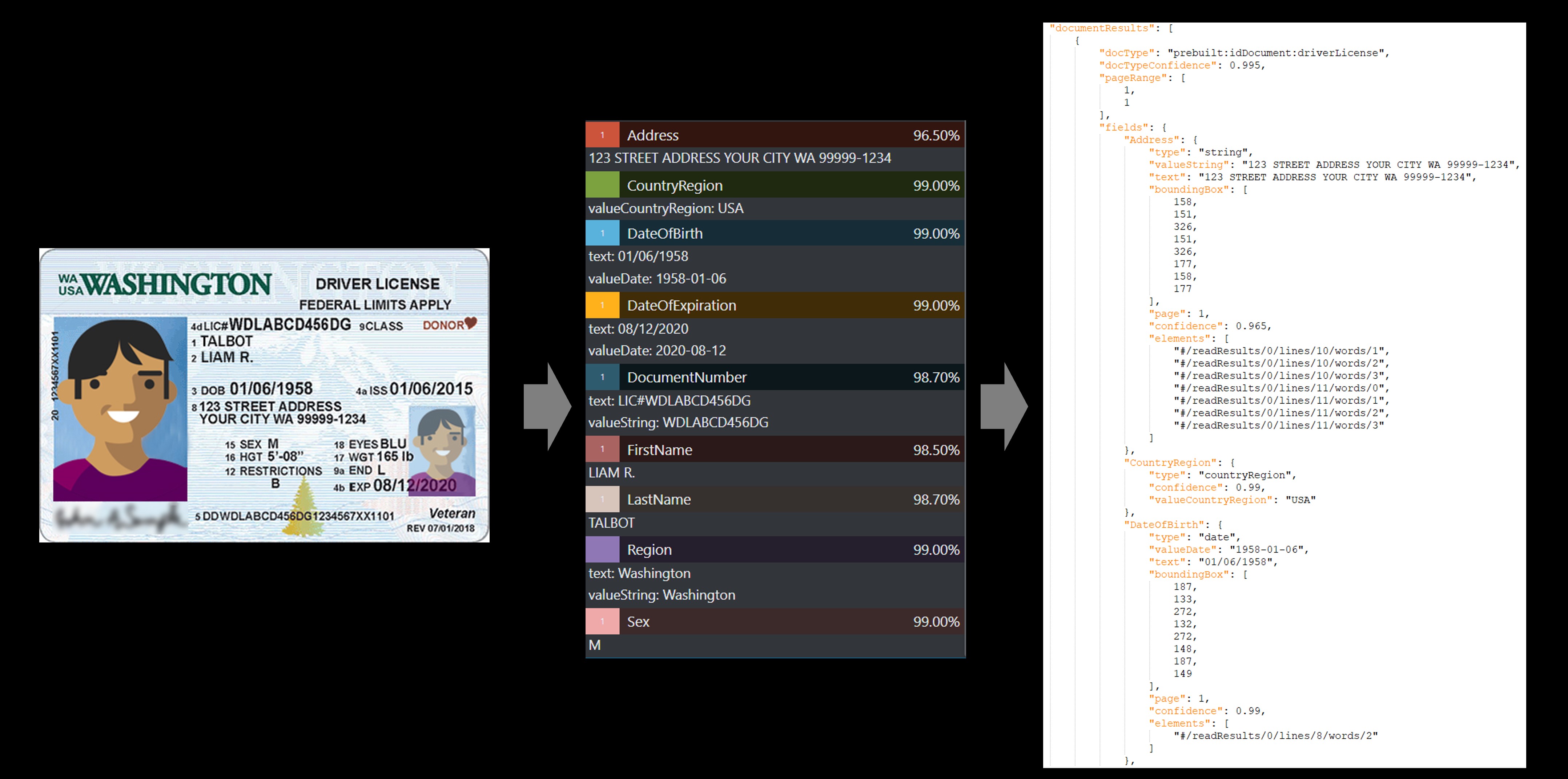
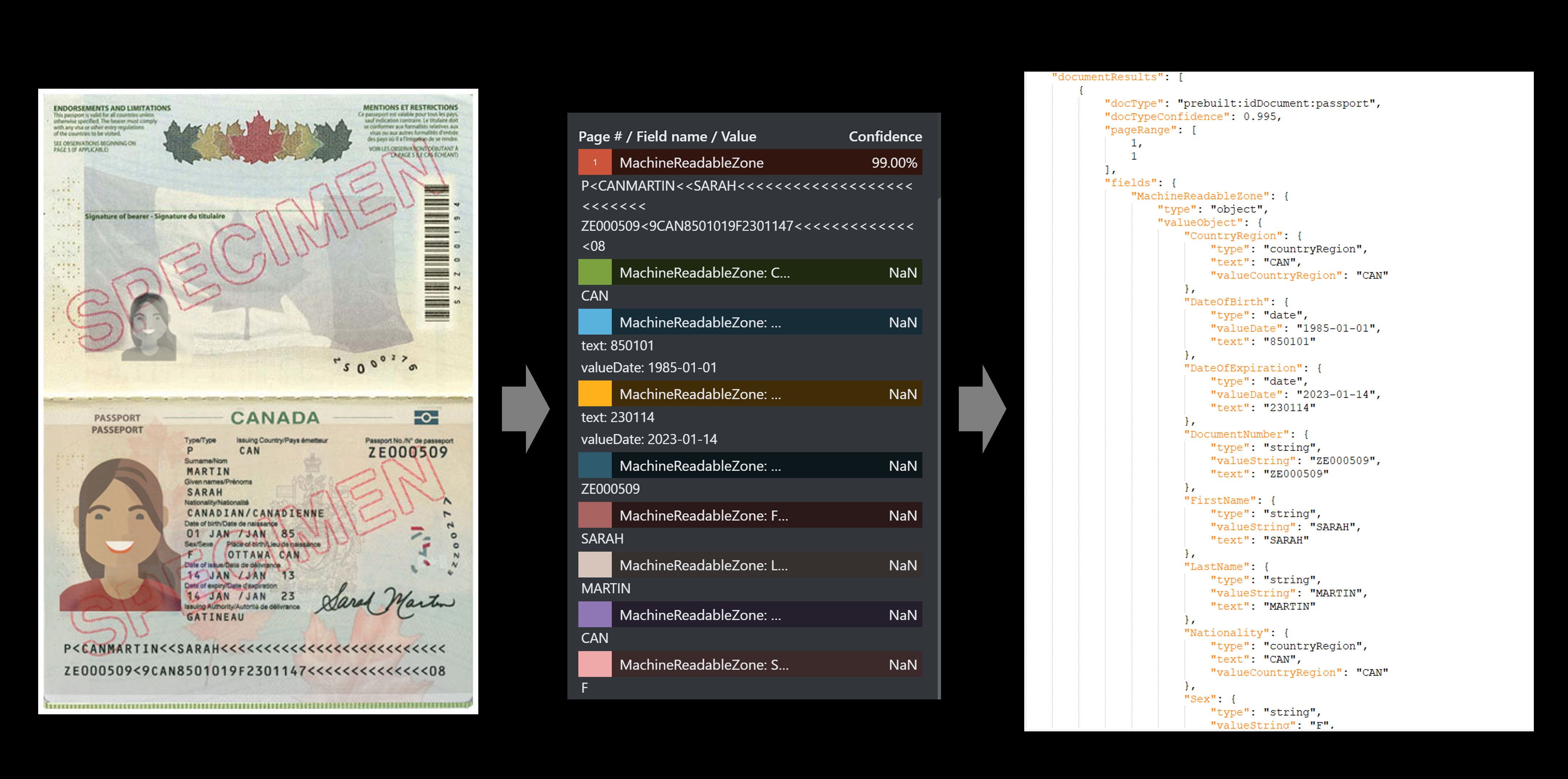
Wstępnie utworzona usługa identyfikatorów wyodrębnia wartości kluczy z światowych paszportów i licencji kierowców USA i zwraca je w zorganizowanej ustrukturyzowanej odpowiedzi JSON.
Przykład licencji kierowcy
Przykład usługi Passport
Opcje programowania
Analiza dokumentów w wersji 4.0 (2024-02-29-preview, 2023-10-31-preview) obsługuje następujące narzędzia, aplikacje i biblioteki:
| Funkcja | Zasoby | Model ID |
|---|---|---|
| Model dokumentu identyfikatora | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK |
prebuilt-idDocument |
Narzędzie Document Intelligence w wersji 3.1 obsługuje następujące narzędzia, aplikacje i biblioteki:
| Funkcja | Zasoby | Model ID |
|---|---|---|
| Model dokumentu identyfikatora | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK |
prebuilt-idDocument |
Narzędzie Document Intelligence w wersji 3.0 obsługuje następujące narzędzia, aplikacje i biblioteki:
| Funkcja | Zasoby | Model ID |
|---|---|---|
| Model dokumentu identyfikatora | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK |
prebuilt-idDocument |
Narzędzie Document Intelligence w wersji 2.1 obsługuje następujące narzędzia, aplikacje i biblioteki:
| Funkcja | Zasoby |
|---|---|
| Model dokumentu identyfikatora | • Narzędzie do etykietowania analizy dokumentów• Interfejs API REST• Zestaw SDK biblioteki klienckiej• Kontener docker analizy dokumentów |
Wymagania dotyczące danych wejściowych
Aby uzyskać najlepsze wyniki, podaj jedno jasne zdjęcie lub wysokiej jakości skanowanie na dokument.
Obsługiwane formaty plików:
Model PDF Obraz:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) i HTMLPrzeczytaj ✔ ✔ ✔ Układ ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Dokument ogólny ✔ ✔ Wstępnie utworzona ✔ ✔ Niestandardowe wyodrębnianie ✔ ✔ Klasyfikacja niestandardowa ✔ ✔ ✔ (2024-02-29-preview) W przypadku plików PDF i TIFF można przetworzyć maksymalnie 2000 stron (w przypadku subskrypcji w warstwie Bezpłatna przetwarzane są tylko pierwsze dwie strony).
Rozmiar pliku do analizowania dokumentów wynosi 500 MB dla warstwy płatnej (S0) i 4 MB za bezpłatną (F0).
Wymiary obrazu muszą mieć od 50 x 50 pikseli do 10 000 pikseli x 10 000 pikseli.
Jeśli pliki PDF są zablokowane hasłem, przed ich przesłaniem usuń blokadę.
Minimalna wysokość tekstu do wyodrębnienia to 12 pikseli dla obrazu o rozmiarze 1024 x 768 pikseli. Ten wymiar odpowiada około
8-point text na 150 kropek na cal (DPI).W przypadku trenowania modelu niestandardowego maksymalna liczba stron dla danych szkoleniowych wynosi 500 dla niestandardowego modelu szablonu i 50 000 dla niestandardowego modelu neuronowego.
W przypadku trenowania niestandardowego modelu wyodrębniania łączny rozmiar danych treningowych wynosi 50 MB dla modelu szablonu i 1G-MB dla modelu neuronowego.
W przypadku trenowania niestandardowego modelu klasyfikacji całkowity rozmiar danych treningowych wynosi
1GBmaksymalnie 10 000 stron.
Obsługiwane formaty plików: JPEG, PNG, PDF i TIFF.
Obsługiwana liczba stron dla plików PDF i TIFF: maksymalnie 2000 stron lub tylko dwie pierwsze strony dla subskrybentów warstwy bezpłatna.
Obsługiwany rozmiar pliku: mniej niż 50 MB ŁĄCZNIE; minimalna liczba pikseli: 50 x 50 pikseli; maksymalna liczba pikseli: 10 000 x 10 000 pikseli.
Wyodrębnianie danych modelu dokumentów identyfikatorów
Wyodrębnij dane, w tym nazwę, datę urodzenia i datę wygaśnięcia z dokumentów identyfikatorów. Potrzebne są następujące zasoby:
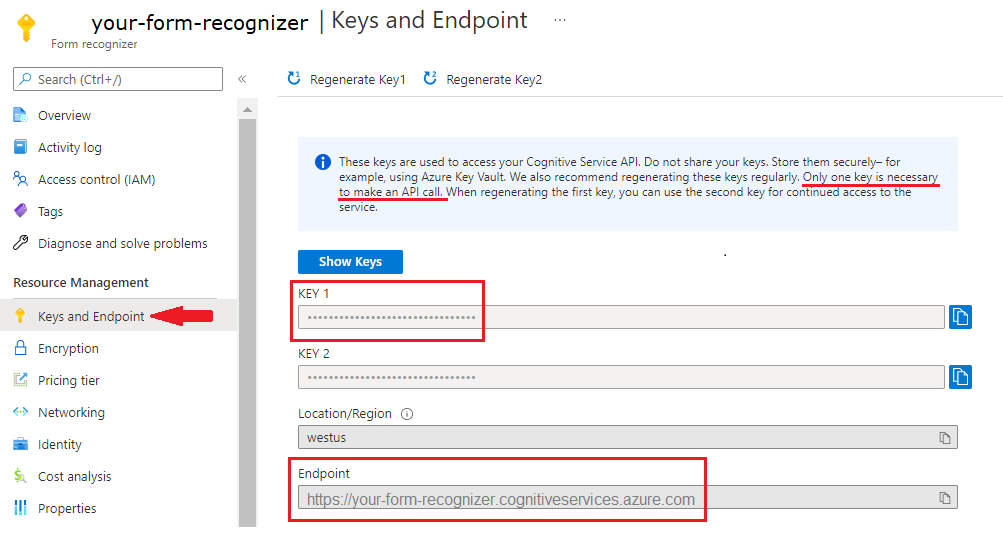
Subskrypcja platformy Azure — możesz utworzyć jedną bezpłatnie.
Wystąpienie analizy dokumentów w witrynie Azure Portal. Aby wypróbować usługę, możesz użyć bezpłatnej warstwy cenowej (
F0). Po wdrożeniu zasobu wybierz pozycję Przejdź do zasobu , aby uzyskać klucz i punkt końcowy.
Uwaga
Program Document Intelligence Studio jest dostępny z interfejsami API w wersji 3.1 i 3.0 oraz nowszymi wersjami.
Na stronie głównej programu Document Intelligence Studio wybierz pozycję Dokumenty tożsamości.
Możesz przeanalizować przykładową fakturę lub przekazać własne pliki.
Wybierz przycisk Run analysis (Uruchom analizę), a w razie potrzeby skonfiguruj opcje Analizuj:

Narzędzie do etykietowania przykładowego analizy dokumentów
Przejdź do narzędzia przykładowego analizy dokumentów.
Na stronie głównej przykładowego narzędzia wybierz kafelek Użyj wstępnie utworzonego modelu, aby pobrać dane .
Wybierz typ formularza do przeanalizowania z menu rozwijanego.
Wybierz adres URL pliku, który chcesz przeanalizować z poniższych opcji:
- Przykładowy dokument faktury.
- Przykładowy dokument o identyfikatorze.
- Przykładowy obraz potwierdzenia.
- Przykładowy obraz wizytówki.
W polu Źródło wybierz pozycję Adres URL z menu rozwijanego, wklej wybrany adres URL i wybierz przycisk Pobierz.
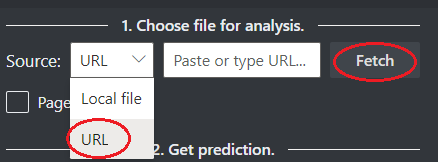
W polu Punkt końcowy usługi Analizy dokumentów wklej punkt końcowy uzyskany w ramach subskrypcji analizy dokumentów.
W polu klucza wklej klucz uzyskany z zasobu analizy dokumentów.
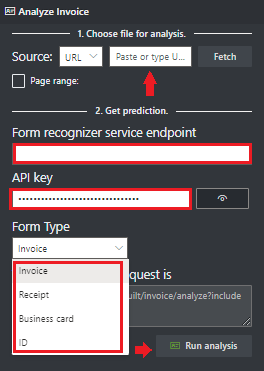
Wybierz pozycję Uruchom analizę. Narzędzie do etykietowania przykładowego analizy dokumentów wywołuje interfejs API analizy wstępnie utworzonej i analizuje dokument.
Wyświetl wyniki — zobacz wyodrębnione pary klucz-wartość, elementy wiersza, wyróżniony tekst wyodrębniony i wykryte tabele.
Pobierz plik wyjściowy JSON, aby wyświetlić szczegółowe wyniki.
- Węzeł "readResults" zawiera każdy wiersz tekstu z odpowiednim umieszczeniem pola ograniczenia na stronie.
- Węzeł "selectionMarks" pokazuje każdy znacznik zaznaczenia (pole wyboru, znacznik radiowy) i określa, czy jego stan jest zaznaczony , czy niezaznaczony.
- Sekcja "pageResults" zawiera wyodrębnione tabele. Dla każdej tabeli analiza dokumentów wyodrębnia tekst, wiersz i indeks kolumn, zakres wierszy i kolumn, pole ograniczenia i nie tylko.
- Pole "documentResults" zawiera informacje o parach klucz/wartość i informacje o elementach wiersza dla najbardziej odpowiednich części dokumentu.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Uwaga
Przykładowe narzędzie etykietowania nie obsługuje formatu pliku BMP. Jest to ograniczenie narzędzia, a nie usługi analizy dokumentów.
Obsługiwane typy dokumentu
| Region (Region) | Typy dokumentów |
|---|---|
| Cały świat | Książka paszportowa, karta paszportowa |
| Stany Zjednoczone | Prawo jazdy, karty identyfikacyjnej, zezwolenia na pobyt (zielona karta), karty ubezpieczenia społecznego, identyfikatora wojskowego |
| Europa | Prawo jazdy, karta identyfikacji, zezwolenie na pobyt |
| Indie | Prawo jazdy, KARTA PAN, Aadhaar Card |
| Kanada | Prawo jazdy, karta identyfikacji, zezwolenie na pobyt (karta maple) |
| Australia | Licencja kierowcy, karta fotograficzna, identyfikator klucza (w tym wersja cyfrowa) |
Wyodrębnianie pól
Poniżej przedstawiono pola wyodrębnione na typ dokumentu. Model prebuilt-idDocument identyfikatora analizy dokumentów wyodrębnia następujące pola w pliku documents.*.fields. Dane wyjściowe json zawierają cały wyodrębniony tekst w dokumentach, wyrazach, wierszach i stylach.
idDocument.driverLicense
| Pole | Typ | Opis | Przykład |
|---|---|---|---|
CountryRegion |
countryRegion |
Kod kraju lub regionu | USA |
Region |
string |
Województwo | Waszyngton |
DocumentNumber |
string |
Numer licencji kierowcy | WDLABCD456DG |
DocumentDiscriminator |
string |
Dyskryminujący dokument dotyczący prawa jazdy | 12645646464554646456464544 |
FirstName |
string |
Imię i środkowe inicjały, jeśli ma to zastosowanie | LIAM R. |
LastName |
string |
Surname | TALBOT |
Address |
address |
Adres | 123 ULICA ADRES MIASTA WA 99999-1234 |
DateOfBirth |
date |
Data urodzenia | 01/06/1958 |
DateOfExpiration |
date |
Data wygaśnięcia | 08/12/2020 |
DateOfIssue |
date |
Data wydania | 08/12/2012 |
EyeColor |
string |
Kolor oczu | Niebieskie |
HairColor |
string |
Kolor włosów | Brązowy |
Height |
string |
Wysokość | 5'11" |
Weight |
string |
Weight | 185LB |
Sex |
string |
Płeć | M |
Endorsements |
string |
Poręczenia | L |
Restrictions |
string |
Ograniczenia | B |
VehicleClassifications |
string |
Klasyfikacja pojazdów | D |
idDocument.passport
| Pole | Typ | Opis | Przykład |
|---|---|---|---|
DocumentNumber |
string |
Numer paszportu | 340020013 |
FirstName |
string |
Imię i środkowe inicjały, jeśli ma to zastosowanie | JENNIFER |
MiddleName |
string |
Imię i nazwisko | REYES |
LastName |
string |
Surname | BROOKS |
Aliases |
array |
||
Aliases.* |
string |
Znany również jako | MAT LIN |
DateOfBirth |
date |
Data urodzenia | 1980-01-01 |
DateOfExpiration |
date |
Data wygaśnięcia | 2019-05-05 |
DateOfIssue |
date |
Data wydania | 2014-05-06 |
Sex |
string |
Płeć | F |
CountryRegion |
countryRegion |
Wydawanie kraju lub organizacji | USA |
DocumentType |
string |
Document type | P |
Nationality |
countryRegion |
Narodowość | USA |
PlaceOfBirth |
string |
Miejsce urodzenia | MASSACHUSETTS, USA |
PlaceOfIssue |
string |
Miejsce problemu | MIEŚCIE LIZBONA |
IssuingAuthority |
string |
Urząd wystawiający | departament stanu Stany Zjednoczone |
PersonalNumber |
string |
Osobisty identyfikator. L.p. | A234567893 |
MachineReadableZone |
object |
Strefa z możliwością odczytu maszyny (MRZ) | P<USABROOKS<<JENNIFER<<<<<<<<<<<<<<<<<<<<<<< 3400200135USA8001014F190505471000307<715816 |
MachineReadableZone.FirstName |
string |
Imię i środkowe inicjały, jeśli ma to zastosowanie | JENNIFER |
MachineReadableZone.LastName |
string |
Surname | BROOKS |
MachineReadableZone.DocumentNumber |
string |
Numer paszportu | 340020013 |
MachineReadableZone.CountryRegion |
countryRegion |
Wydawanie kraju lub organizacji | USA |
MachineReadableZone.Nationality |
countryRegion |
Narodowość | USA |
MachineReadableZone.DateOfBirth |
date |
Data urodzenia | 1980-01-01 |
MachineReadableZone.DateOfExpiration |
date |
Data wygaśnięcia | 2019-05-05 |
MachineReadableZone.Sex |
string |
Płeć | F |
idDocument.nationalIdentityCard
| Pole | Typ | Opis | Przykład |
|---|---|---|---|
CountryRegion |
countryRegion |
Kod kraju lub regionu | USA |
Region |
string |
Województwo | Waszyngton |
DocumentNumber |
string |
Krajowy numer karty tożsamości | WDLABCD456DG |
DocumentDiscriminator |
string |
Dokument z krajowym dokumentem karty tożsamości dyskryminującym | 12645646464554646456464544 |
FirstName |
string |
Imię i środkowe inicjały, jeśli ma to zastosowanie | LIAM R. |
LastName |
string |
Surname | TALBOT |
Address |
address |
Adres | 123 ULICA ADRES MIASTA WA 99999-1234 |
DateOfBirth |
date |
Data urodzenia | 01/06/1958 |
DateOfExpiration |
date |
Data wygaśnięcia | 08/12/2020 |
DateOfIssue |
date |
Data wydania | 08/12/2012 |
EyeColor |
string |
Kolor oczu | NIEBIESKI |
HairColor |
string |
Kolor włosów | BRĄZOWY |
Height |
string |
Wysokość | 5'11" |
Weight |
string |
Weight | 185LB |
Sex |
string |
Płeć | M |
idDocument.residencePermit
| Pole | Typ | Opis | Przykład |
|---|---|---|---|
CountryRegion |
countryRegion |
Kod kraju lub regionu | USA |
DocumentNumber |
string |
Numer zezwolenia na pobyt | WDLABCD456DG |
FirstName |
string |
Imię i środkowe inicjały, jeśli ma to zastosowanie | LIAM R. |
LastName |
string |
Surname | TALBOT |
DateOfBirth |
date |
Data urodzenia | 01/06/1958 |
DateOfExpiration |
date |
Data wygaśnięcia | 08/12/2020 |
DateOfIssue |
date |
Data wydania | 08/12/2012 |
Sex |
string |
Płeć | M |
PlaceOfBirth |
string |
Miejsce urodzenia | Niemcy |
Category |
string |
Kategoria zezwoleń | DV2 |
Address |
string |
Adres | 123 ULICA ADRES MIASTA WA 99999-1234 |
idDocument.usSocialSecurityCard
| Pole | Typ | Opis | Przykład |
|---|---|---|---|
DocumentNumber |
string |
Numer karty ubezpieczenia społecznego | WDLABCD456DG |
FirstName |
string |
Imię i środkowe inicjały, jeśli ma to zastosowanie | LIAM R. |
LastName |
string |
Surname | TALBOT |
DateOfIssue |
date |
Data wydania | 08/12/2012 |
idDocument
| Pole | Typ | Opis | Przykład |
|---|---|---|---|
Address |
address |
Adres | 123 ULICA ADRES MIASTA WA 99999-1234 |
DocumentNumber |
string |
Numer licencji kierowcy | WDLABCD456DG |
FirstName |
string |
Imię i środkowe inicjały, jeśli ma to zastosowanie | LIAM R. |
LastName |
string |
Surname | TALBOT |
DateOfBirth |
date |
Data urodzenia | 01/06/1958 |
DateOfExpiration |
date |
Data wygaśnięcia | 08/12/2020 |
Obsługiwane typy dokumentu
Model dokumentu ID obsługuje obecnie amerykańskie licencje kierowców i stronę biograficzną z międzynarodowych paszportów (z wyłączeniem wiz i innych dokumentów podróży) wyodrębniania.
Wyodrębnione pola
| Nazwisko | Pisz | Opis | Wartość |
|---|---|---|---|
| Country | kraj | Kod kraju zgodny ze standardem ISO 3166 | "USA" |
| DateOfBirth | data | DOB w formacie RRRR-MM-DD | "1980-01-01" |
| DateOfExpiration | data | Data wygaśnięcia w formacie RRRR-MM-DD | "2019-05-05" |
| Numer dokumentu | string | Odpowiedni numer paszportu, numer licencji kierowcy itp. | "340020013" |
| FirstName | string | Wyodrębnione imię i środkowe inicjały, jeśli ma to zastosowanie | "JENNIFER" |
| LastName | string | Wyodrębnione nazwisko | "BROOKS" |
| Narodowość | kraj | Kod kraju zgodny ze standardem ISO 3166 | "USA" |
| Płeć | płeć | Możliwe wyodrębnione wartości obejmują "M" "F" "X" | „F” |
| MachineReadableZone | obiekt | Wyodrębniony magazyn MRZ paszportu zawierający dwa wiersze z 44 znakami | "P<USABROOKS<<JENNIFER<<<<<<<<<<<<<<<<<<<<<<< 3400200135USA8001014F190505471000307<715816" |
| DocumentType | string | Typ dokumentu, na przykład Paszport, Licencja kierowcy | "paszport" |
| Adres | string | Wyodrębniony adres (tylko prawo jazdy) | "123 STREET ADDRESS YOUR CITY WA 99999-1234" |
| Region (Region) | string | Wyodrębniony region, stan, prowincja itp. (tylko prawo jazdy) | "Waszyngton" |
Przewodnik migracji
- Postępuj zgodnie z naszym przewodnikiem migracji do analizy dokumentów w wersji 3.1, aby dowiedzieć się, jak używać wersji 3.0 w aplikacjach i przepływach pracy.
Następne kroki
Spróbuj przetwarzać własne formularze i dokumenty za pomocą programu Document Intelligence Studio.
Ukończ przewodnik Szybki start dotyczący analizy dokumentów i rozpocznij tworzenie aplikacji do przetwarzania dokumentów w wybranym języku programowania.
Spróbuj przetwarzać własne formularze i dokumenty za pomocą narzędzia do etykietowania przykładowego analizy dokumentów.
Ukończ przewodnik Szybki start dotyczący analizy dokumentów i rozpocznij tworzenie aplikacji do przetwarzania dokumentów w wybranym języku programowania.