Modele przetwarzania dokumentów
Ważne
- Publiczne wersje zapoznawcze analizy dokumentów zapewniają wczesny dostęp do funkcji, które są aktywnie opracowywane.
- Funkcje, podejścia i procesy mogą ulec zmianie przed ogólną dostępnością na podstawie opinii użytkowników.
- Publiczna wersja zapoznawcza bibliotek klienckich usługi Document Intelligence jest domyślna dla interfejsu API REST w wersji 2024-02-29-preview.
- Publiczna wersja zapoznawcza 2024-02-29-preview jest obecnie dostępna tylko w następujących regionach świadczenia usługi Azure:
- Wschodnie stany USA
- Zachodnie stany USA 2
- Europa Zachodnia
Ta zawartość dotyczy:v4.0 (wersja zapoznawcza) | Poprzednie wersje:![]()
![]() v3.1 (GA)v3.0 (GA)
v3.1 (GA)v3.0 (GA)![]()
![]() v2.1 (GA)
v2.1 (GA)
Ta zawartość dotyczy:v3.1 (GA)Najnowsza wersja:![]()
![]() v4.0 (wersja zapoznawcza) | | Poprzednie wersje:
v4.0 (wersja zapoznawcza) | | Poprzednie wersje:![]() v3.0
v3.0![]() v2.1
v2.1
Ta zawartość dotyczy:v3.0 (GA) | Najnowsze wersje:![]()
![]() v4.0 (wersja zapoznawcza)
v4.0 (wersja zapoznawcza)![]() v3.1 | Poprzednia wersja:
v3.1 | Poprzednia wersja:![]() v2.1
v2.1
Ta zawartość dotyczy:v2.1 Najnowsza wersja:![]()
![]() v4.0 (wersja zapoznawcza) |
v4.0 (wersja zapoznawcza) |
Usługa Azure AI Document Intelligence obsługuje szeroką gamę modeli, które umożliwiają dodawanie inteligentnego przetwarzania dokumentów do aplikacji i przepływów. Możesz użyć wstępnie utworzonego modelu specyficznego dla domeny lub wytrenować model niestandardowy dostosowany do konkretnych potrzeb biznesowych i przypadków użycia. Analiza dokumentów może być używana z interfejsem API REST lub bibliotekami klienta języka Python, C#, Java i JavaScript.
Omówienie modelu
W poniższej tabeli przedstawiono dostępne modele dla każdej bieżącej wersji zapoznawczej i stabilnego interfejsu API:
| Typ modelu | Model | • 2024-02-29-preview Punktor 2023-10-31-preview |
2023-07-31 (ogólna dostępność) | 2022-08-31 (ogólna dostępność) | Wersja 2.1 (ogólna dostępność) |
|---|---|---|---|---|---|
| Modele analizy dokumentów | Przeczytaj | ✔️ | ✔️ | ✔️ | nie dotyczy |
| Modele analizy dokumentów | Układ | ✔️ | ✔️ | ✔️ | ✔️ |
| Modele analizy dokumentów | Dokument ogólny | przeniesiony do układu** | ✔️ | ✔️ | nie dotyczy |
| Wstępnie utworzone modele | Kontrakt | ✔️ | ✔️ | nie dotyczy | nie dotyczy |
| Wstępnie utworzone modele | Karta ubezpieczenia zdrowotnego | ✔️ | ✔️ | ✔️ | nie dotyczy |
| Wstępnie utworzone modele | Dokument tożsamości | ✔️ | ✔️ | ✔️ | ✔️ |
| Wstępnie utworzone modele | Faktura | ✔️ | ✔️ | ✔️ | ✔️ |
| Wstępnie utworzone modele | Otrzymania | ✔️ | ✔️ | ✔️ | ✔️ |
| Wstępnie utworzone modele | Podatek 1040 USA* | ✔️ | ✔️ | nie dotyczy | nie dotyczy |
| Wstępnie utworzone modele | Podatek od USA 1098* | ✔️ | nie dotyczy | nie dotyczy | nie dotyczy |
| Wstępnie utworzone modele | Podatek od USA 1099* | ✔️ | nie dotyczy | nie dotyczy | nie dotyczy |
| Wstępnie utworzone modele | Podatek w USA W2 | ✔️ | ✔️ | ✔️ | nie dotyczy |
| Wstępnie utworzone modele | US Mortgage 1003 URLA | ✔️ | nie dotyczy | nie dotyczy | nie dotyczy |
| Wstępnie utworzone modele | Podsumowanie kredytu hipotecznego USA 1008 | ✔️ | nie dotyczy | nie dotyczy | nie dotyczy |
| Wstępnie utworzone modele | Ujawnienie zamknięcia kredytów hipotecznych w USA | ✔️ | nie dotyczy | nie dotyczy | nie dotyczy |
| Wstępnie utworzone modele | Akt małżeństwa | ✔️ | nie dotyczy | nie dotyczy | nie dotyczy |
| Wstępnie utworzone modele | Karta kredytowa | ✔️ | nie dotyczy | nie dotyczy | nie dotyczy |
| Wstępnie utworzone modele | Wizytówka | deprecated | ✔️ | ✔️ | ✔️ |
| Niestandardowy model klasyfikacji | Klasyfikator niestandardowy | ✔️ | ✔️ | nie dotyczy | nie dotyczy |
| Niestandardowy model wyodrębniania | Niestandardowe neuronowe | ✔️ | ✔️ | ✔️ | nie dotyczy |
| Model customextraction | Szablon niestandardowy | ✔️ | ✔️ | ✔️ | ✔️ |
| Niestandardowy model wyodrębniania | Komponowane niestandardowe | ✔️ | ✔️ | ✔️ | ✔️ |
| Wszystkie modele | Możliwości dodatków | ✔️ | ✔️ | nie dotyczy | nie dotyczy |
* — zawiera podrzędne modele. Zobacz informacje specyficzne dla modelu dotyczące obsługiwanych odmian i podtypów.
| Możliwość dodawania | Dodatek/wersja bezpłatna | • 2024-02-29-preview Punktor [2023-10-31-preview](/rest/api/aiservices/operation-groups?view=rest-aiservices-2024-02-29-preview&preserve-view=true |
2023-07-31 (ogólna dostępność) |
2022-08-31 (ogólna dostępność) |
Wersja 2.1 (ogólna dostępność) |
|---|---|---|---|---|---|
| Wyodrębnianie właściwości czcionki | Dodatek | ✔️ | ✔️ | nie dotyczy | nie dotyczy |
| Wyodrębnianie formuł | Dodatek | ✔️ | ✔️ | nie dotyczy | nie dotyczy |
| Wyodrębnianie o wysokiej rozdzielczości | Dodatek | ✔️ | ✔️ | nie dotyczy | nie dotyczy |
| Wyodrębnianie kodów kreskowych | Bezpłatna | ✔️ | ✔️ | nie dotyczy | nie dotyczy |
| Wykrywanie języka | Bezpłatna | ✔️ | ✔️ | nie dotyczy | nie dotyczy |
| Pary klucz-wartość | Bezpłatna | ✔️ | nie dotyczy | nie dotyczy | nie dotyczy |
| Pola zapytania | Dodatek* | ✔️ | nie dotyczy | nie dotyczy | nie dotyczy |
Funkcje analizy modelu
| Model ID | Wyodrębnianie zawartości | Pola zapytania | Ustępów | Role akapitu | Znaczniki zaznaczenia | Tabele | Pary klucz-wartość | Języki | Kodów kreskowych | Analiza dokumentów | Formuły* | Czcionka stylu* | Wysoka rozdzielczość* |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| odczyt wstępnie utworzony | ✓ | O | O | O | O | O | |||||||
| wstępnie utworzony układ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | ||
| wstępnie utworzony dokument | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | |
| wstępnie utworzona karta biznesowa | ✓ | ✓ | ✓ | ||||||||||
| wstępnie utworzony kontrakt | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||
| prebuilt-healthInsuranceCard.us | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-idDocument | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| wstępnie utworzona faktura | ✓ | ✓ | ✓ | ✓ | O | O | O | ✓ | O | O | O | ||
| wstępnie utworzone potwierdzenie | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-marriageCertificate.us | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| wstępnie utworzona karta kredytowa | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.1003 | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.1008 | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.closingDisclosure | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.w2 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1098 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1098E | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1098T | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1099(odmiany) | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1040(odmiany) | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| { customModelName } | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O |
√ - Włączone
O - Opcjonalne
* - Funkcje w warstwie Premium generują dodatkowe koszty
Dodatek* — pola zapytania są wyceniane inaczej niż inne funkcje dodatku. Aby uzyskać szczegółowe informacje, zobacz cennik .
| Model | Opis |
|---|---|
| Modele analizy dokumentów | |
| Odczytywanie OCR | Wyodrębnij tekst drukowany i odręczny, w tym wyrazy, lokalizacje i wykryte języki. |
| Analiza układu | Wyodrębnij elementy tekstu i układu dokumentu, takie jak tabele, znaczniki zaznaczenia, tytuły, nagłówki sekcji i nie tylko. |
| Wstępnie utworzone modele | |
| Karta ubezpieczenia zdrowotnego | Automatyzowanie procesów opieki zdrowotnej poprzez wyodrębnienie ubezpieczyciela, członka, recepty, numeru grupy i innych kluczowych informacji z amerykańskich kart ubezpieczenia zdrowotnego. |
| Modele dokumentów podatkowych USA | Przetwarzanie amerykańskich formularzy podatkowych w celu wyodrębnienia pracownika, pracodawcy, płacy i innych informacji. |
| Amerykańskie modele dokumentów hipotecznych | Przetwarzanie amerykańskich formularzy kredytów hipotecznych w celu wyodrębnienia pożyczki kredytobiorcy i informacji o nieruchomości. |
| Kontrakt | Wyodrębnij umowę i szczegóły strony. |
| Faktura | Automatyzowanie faktur. |
| Otrzymania | Wyodrębnij dane paragonu z paragonów. |
| Dokument tożsamości (ID) | Wyodrębnij pola tożsamości (ID) z amerykańskich licencji kierowców i międzynarodowych paszportów. |
| Wizytówka | Skanuj wizytówki, aby wyodrębnić kluczowe pola i dane do aplikacji. |
| Modele niestandardowe | |
| Model niestandardowy (omówienie) | Wyodrębnianie danych z formularzy i dokumentów specyficznych dla Twojej firmy. Modele niestandardowe są trenowane dla unikatowych danych i przypadków użycia. |
| Niestandardowe modele wyodrębniania | ● Niestandardowe modele szablonów używają wskazówek układu do wyodrębniania wartości z dokumentów i nadają się do wyodrębniania pól z dokumentów o wysokiej strukturze za pomocą zdefiniowanych szablonów wizualnych. ● Niestandardowe modele neuronowe są szkolone na różnych typach dokumentów w celu wyodrębniania pól ze strukturą, częściowo ustrukturyzowaną i nieustrukturyzowaną. |
| Niestandardowy model klasyfikacji | Model klasyfikacji niestandardowej może sklasyfikować każdą stronę w pliku wejściowym, aby zidentyfikować dokumenty w ramach programu , a także zidentyfikować wiele dokumentów lub wiele wystąpień pojedynczego dokumentu w pliku wejściowym. |
| Modele złożone | Połącz kilka modeli niestandardowych w jeden model, aby zautomatyzować przetwarzanie różnych typów dokumentów przy użyciu jednego złożonego modelu. |
W przypadku wszystkich modeli, z wyjątkiem modelu wizytówek, analiza dokumentów obsługuje teraz funkcje dodatków, aby umożliwić bardziej zaawansowaną analizę. Te opcjonalne możliwości można włączyć i wyłączyć w zależności od scenariusza wyodrębniania dokumentów. Dostępnych jest siedem funkcji dodatku dla wersji interfejsu API (GA) i nowszej wersji interfejsu 2023-07-31 API:
ocrHighResolutionformulasstyleFontbarcodeslanguageskeyValuePairs(2024-02-29-preview, 2023-10-31-preview)queryFields(2024-02-29-preview, 2023-10-31-preview)Not available with the US.Tax models
Szczegóły modelu
W tej sekcji opisano dane wyjściowe, których można oczekiwać od każdego modelu. Należy pamiętać, że można rozszerzyć dane wyjściowe większości modeli przy użyciu funkcji dodatków.
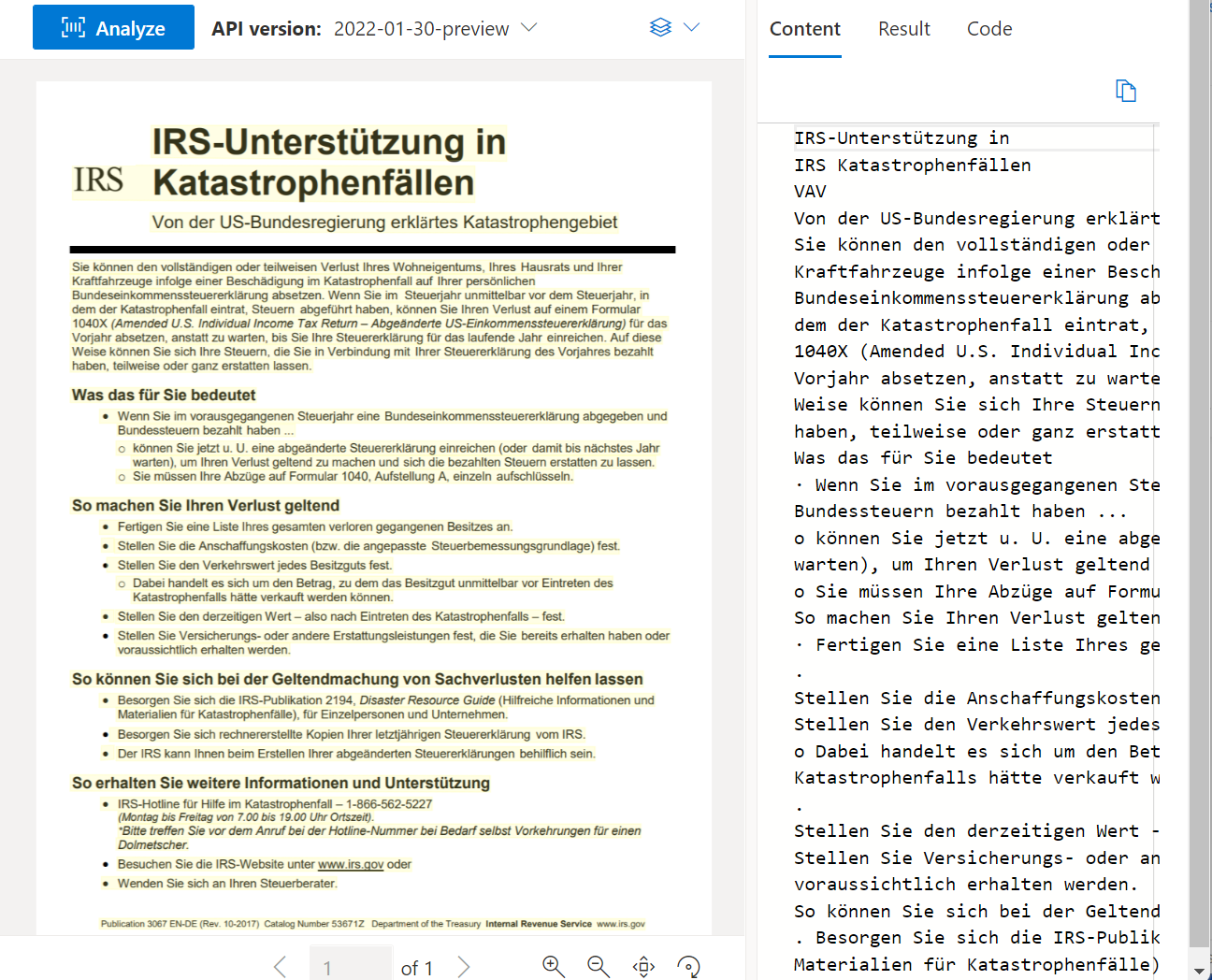
Odczytywanie metodą OCR

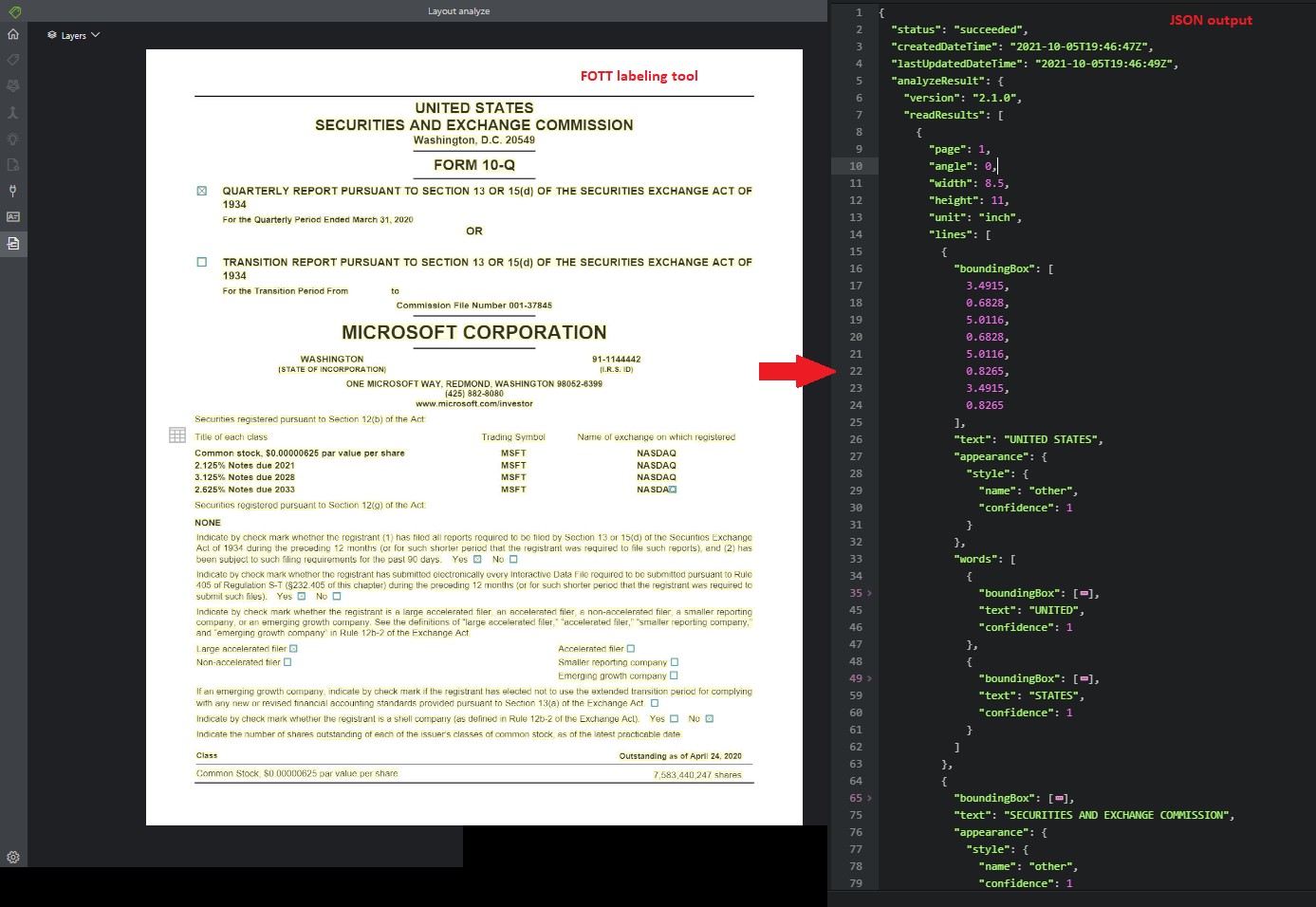
Interfejs API odczytu analizuje i wyodrębnia wiersze, wyrazy, ich lokalizacje, wykryte języki i styl odręczny, jeśli zostanie wykryty.
Przykładowy dokument przetworzony przy użyciu programu Document Intelligence Studio:
Analiza układu

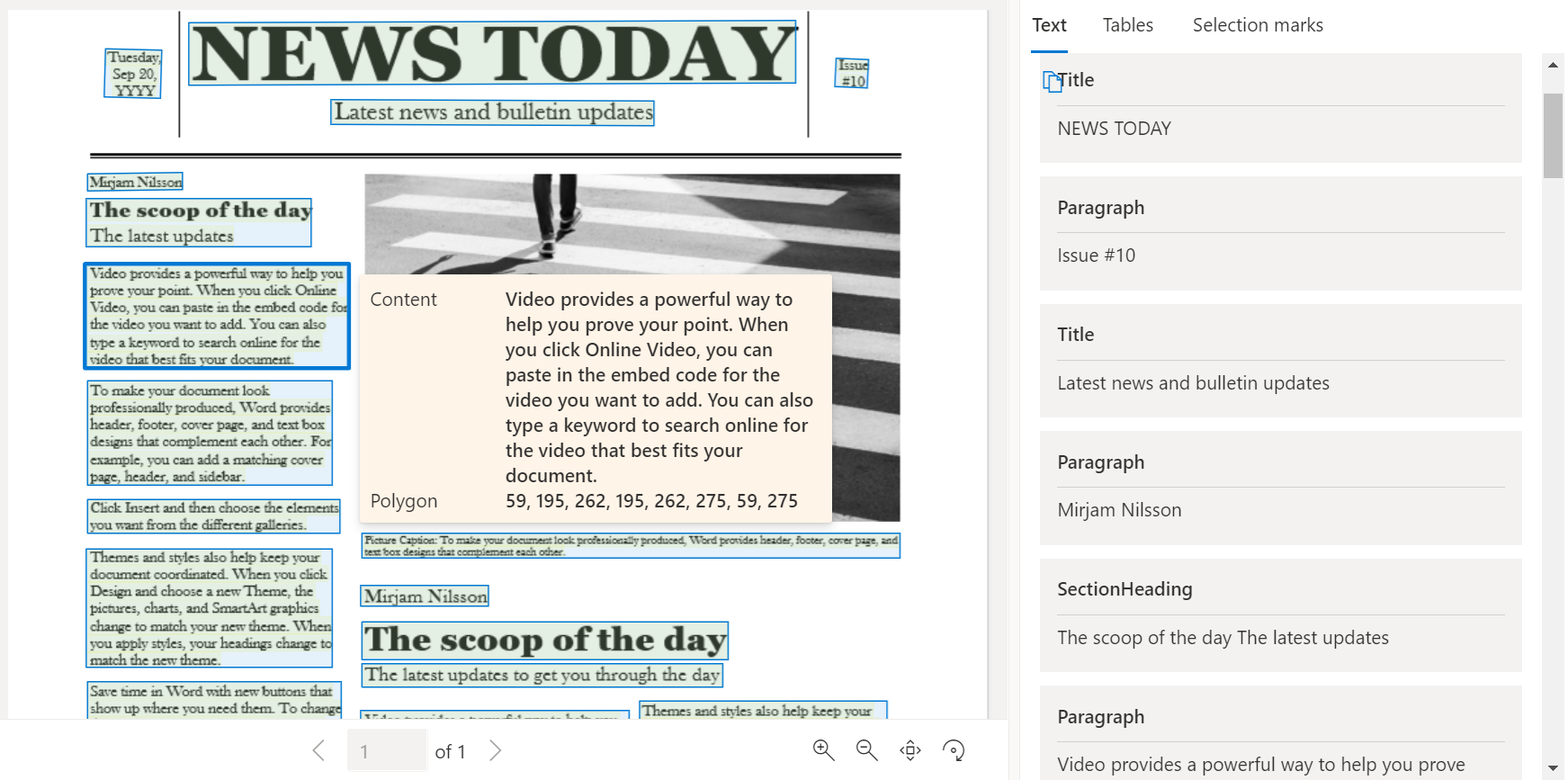
Model analizy układu analizuje i wyodrębnia tekst, tabele, znaczniki zaznaczenia i inne elementy struktury, takie jak tytuły, nagłówki sekcji, nagłówki stron, stopki stron i inne.
Przykładowy dokument przetworzony przy użyciu programu Document Intelligence Studio:
Karta ubezpieczenia zdrowotnego
![]()
Model karty ubezpieczenia zdrowotnego łączy zaawansowane funkcje optycznego rozpoznawania znaków (OCR) z modelami uczenia głębokiego w celu analizowania i wyodrębniania kluczowych informacji z amerykańskich kart ubezpieczenia zdrowotnego.
Przykładowa karta ubezpieczenia zdrowotnego USA przetworzona przy użyciu usługi Document Intelligence Studio:

Amerykańskie dokumenty podatkowe

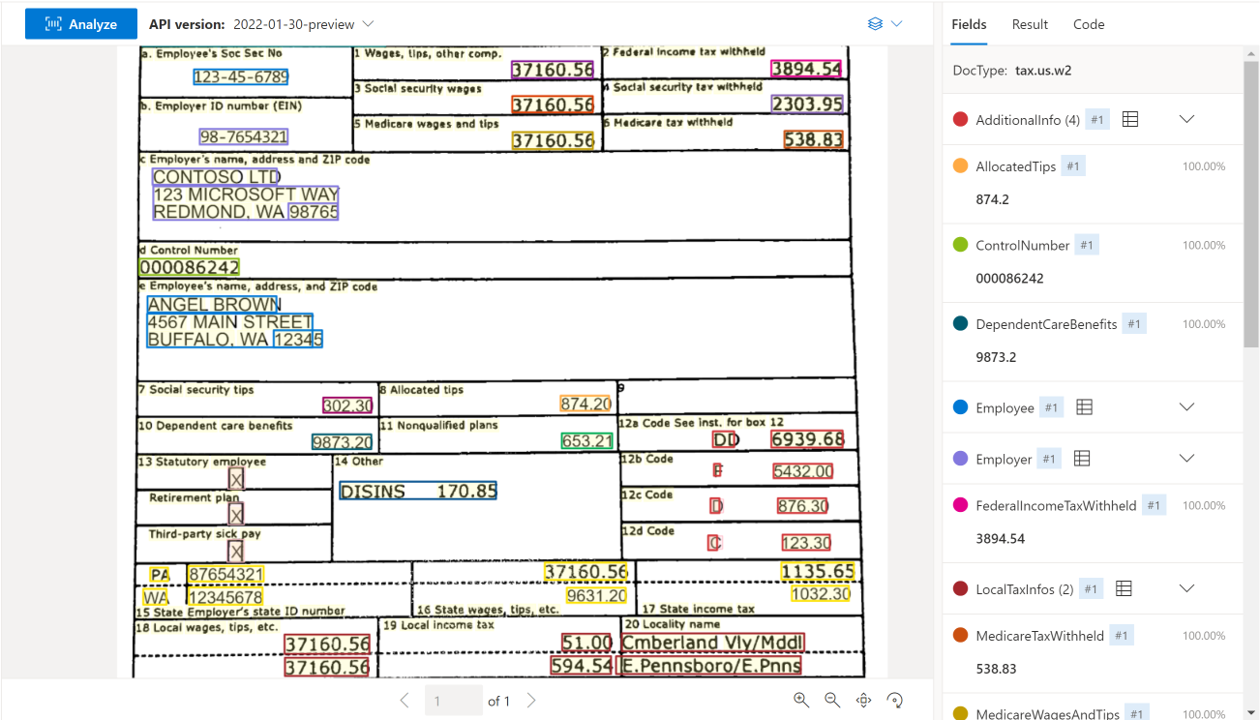
Modele dokumentów podatkowych w USA analizują i wyodrębniają kluczowe pola i elementy wierszy z wybranej grupy dokumentów podatkowych. Interfejs API obsługuje analizę dokumentów podatkowych w języku angielskim USA różnych formatów i jakości, w tym obrazów przechwyconych przez telefon, zeskanowanych dokumentów i cyfrowych plików PDF. Obecnie obsługiwane są następujące modele:
| Model | opis | Identyfikator modelu |
|---|---|---|
| Amerykański podatek W-2 | Wyodrębnij szczegóły odszkodowania podlegającego opodatkowaniu. | prebuilt-tax.us.W-2 |
| Podatek amerykański 1040 | Wyodrębnij szczegóły odsetek hipotecznych. | prebuilt-tax.us.1040(odmiany) |
| Podatek amerykański 1098 | Wyodrębnij szczegóły odsetek hipotecznych. | prebuilt-tax.us.1098(odmiany) |
| Podatek amerykański 1099 | Wyodrębnij dochód uzyskany ze źródeł innych niż pracodawca. | prebuilt-tax.us.1099(odmiany) |
Przykładowy dokument W-2 przetworzony przy użyciu programu Document Intelligence Studio:
Amerykańskie dokumenty hipoteczne

Amerykańskie modele dokumentów hipotecznych analizują i wyodrębniają kluczowe pola, w tym kredytobiorcę, pożyczkę i informacje o nieruchomościach z wybranej grupy dokumentów hipotecznych. Interfejs API obsługuje analizę dokumentów hipotecznych w języku angielskim USA różnych formatów i jakości, w tym obrazów przechwyconych przez telefon, zeskanowanych dokumentów i cyfrowych plików PDF. Obecnie obsługiwane są następujące modele:
| Model | opis | Identyfikator modelu |
|---|---|---|
| 1003 Umowa licencyjna użytkownika końcowego (EULA) | Wyodrębnij pożyczkę, kredytobiorcę, szczegóły nieruchomości. | prebuilt-mortgage.us.1003 |
| Dokument podsumowujący 1008 | Wyodrębnij kredytobiorcę, sprzedawcę, nieruchomość, kredyt hipoteczny i szczegóły ubezpieczania. | prebuilt-mortgage.us.1008 |
| Zamykanie ujawnienia | Wyodrębnianie szczegółów zamknięcia, kosztów transakcji i pożyczki. | prebuilt-mortgage.us.closingDisclosure |
| Akt małżeństwa | Wyodrębnij szczegóły informacji o małżeństwie dla osób ubiegających się o wspólne pożyczki. | wstępnie utworzone małżeństwoCertificate |
| Amerykański podatek W-2 | Wyodrębnij szczegóły odszkodowania podlegającego opodatkowaniu na potrzeby weryfikacji dochodów. | prebuilt-tax.us.W-2 |
Przykładowy dokument ujawnienia zamknięcia przetwarzany przy użyciu programu Document Intelligence Studio:

Kontrakt
![]()
Model kontraktu analizuje i wyodrębnia kluczowe pola i elementy wierszy z umów, w tym stron, jurysdykcji, identyfikatora umowy i tytułu. Model obsługuje obecnie dokumenty kontraktowe w języku angielskim.
Przykładowy kontrakt przetwarzany przy użyciu programu Document Intelligence Studio:

Faktura
Model faktur automatyzuje przetwarzanie faktur w celu wyodrębnienia nazwy klienta, adresu rozliczeniowego, daty ukończenia i kwoty należnej, elementów wiersza i innych kluczowych danych. Obecnie model obsługuje faktury angielskie, hiszpańskie, niemieckie, francuskie, włoskie, portugalskie i holenderskie.
Przykładowa faktura przetworzona przy użyciu programu Document Intelligence Studio:

Przyjęcie

Użyj modelu paragonu, aby zeskanować paragony sprzedaży pod kątem nazwy sprzedawcy, dat, pozycji wiersza, ilości i sum z paragonów drukowanych i odręcznych. Wersja 3.0 obsługuje również przetwarzanie paragonów hotelowych jednostronicowych.
Przykładowe potwierdzenie przetworzone przy użyciu programu Document Intelligence Studio:

Dokument tożsamości (ID)

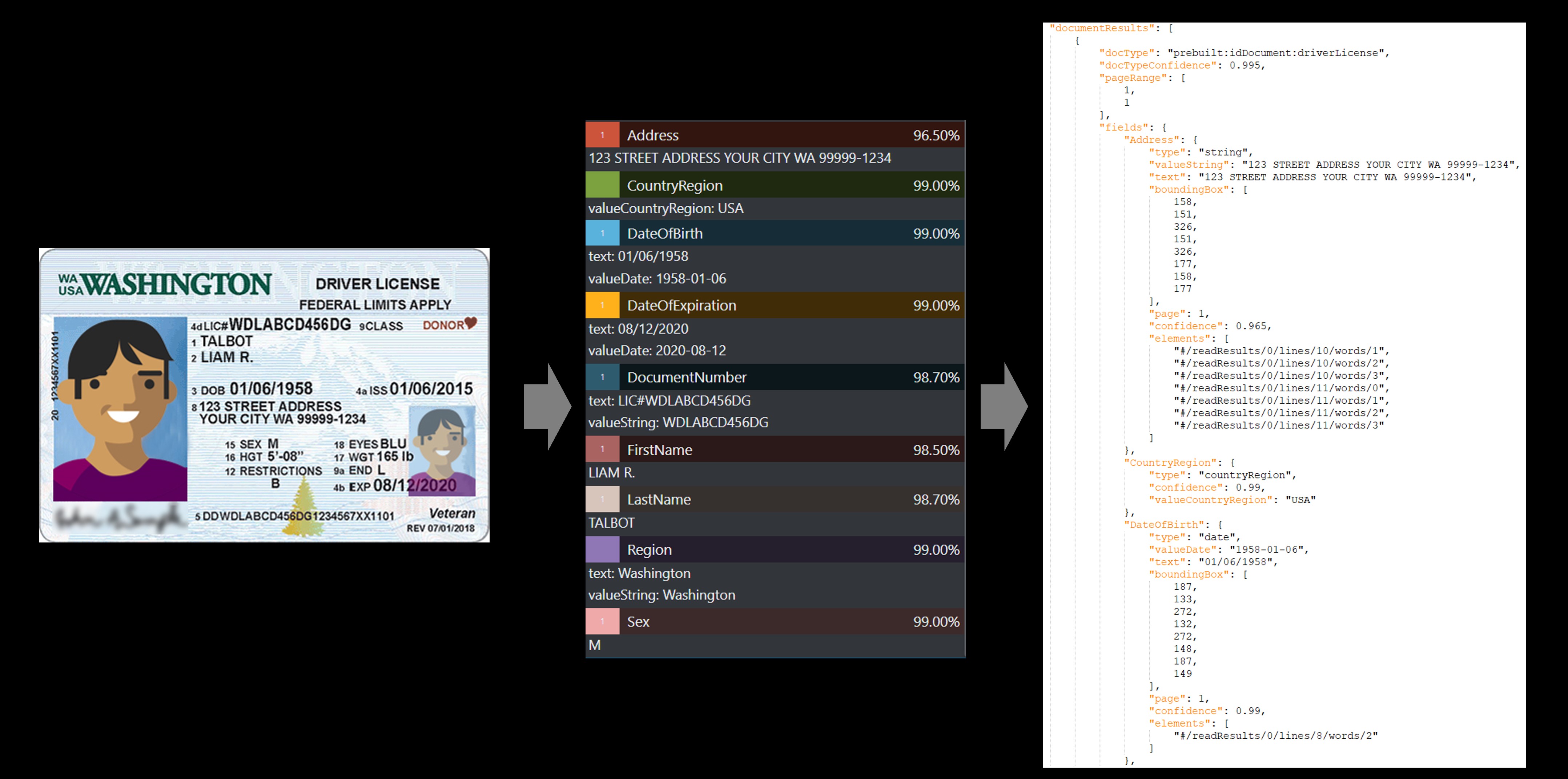
Użyj modelu Dokumentu tożsamości (ID), aby przetworzyć licencje kierowców USA (wszystkie 50 stanów i dystryktu Kolumbii) oraz strony biograficzne z międzynarodowych paszportów (z wyjątkiem wiz i innych dokumentów podróży), aby wyodrębnić kluczowe pola.
Przykładowa licencja kierowcy USA przetworzona przy użyciu programu Document Intelligence Studio:

Akt małżeństwa
![]()
Użyj modelu certyfikatu małżeństwa, aby przetworzyć amerykańskie certyfikaty małżeńskie, aby wyodrębnić kluczowe pola, w tym osoby, datę i lokalizację.
Przykładowy certyfikat małżeństwa USA przetworzony przy użyciu usługi Document Intelligence Studio:

Karta kredytowa
![]()
Użyj modelu karty kredytowej, aby przetworzyć karty kredytowe i debetowe w celu wyodrębnienia pól kluczy.
Przykładowa karta kredytowa przetworzona przy użyciu programu Document Intelligence Studio:

Modele niestandardowe

Modele niestandardowe można ogólnie klasyfikować na dwa typy. Niestandardowe modele klasyfikacji, które obsługują klasyfikację "typu dokumentu" i niestandardowe modele wyodrębniania, które mogą wyodrębniać zdefiniowany schemat z określonego typu dokumentu.

Niestandardowe modele dokumentów analizują i wyodrębniają dane z formularzy i dokumentów specyficznych dla Twojej firmy. Są one szkolone w celu rozpoznawania pól formularzy w ramach odrębnej zawartości i wyodrębniania par klucz-wartość i danych tabeli. Aby rozpocząć pracę, potrzebujesz tylko jednego przykładu typu formularza.
Model niestandardowy w wersji 3.0 obsługuje wykrywanie podpisów w niestandardowym szablonie (formularzu) i tabelach międzystronicowych w modelach szablonów i neuronowych.
Przykładowy szablon niestandardowy przetworzony przy użyciu programu Document Intelligence Studio:
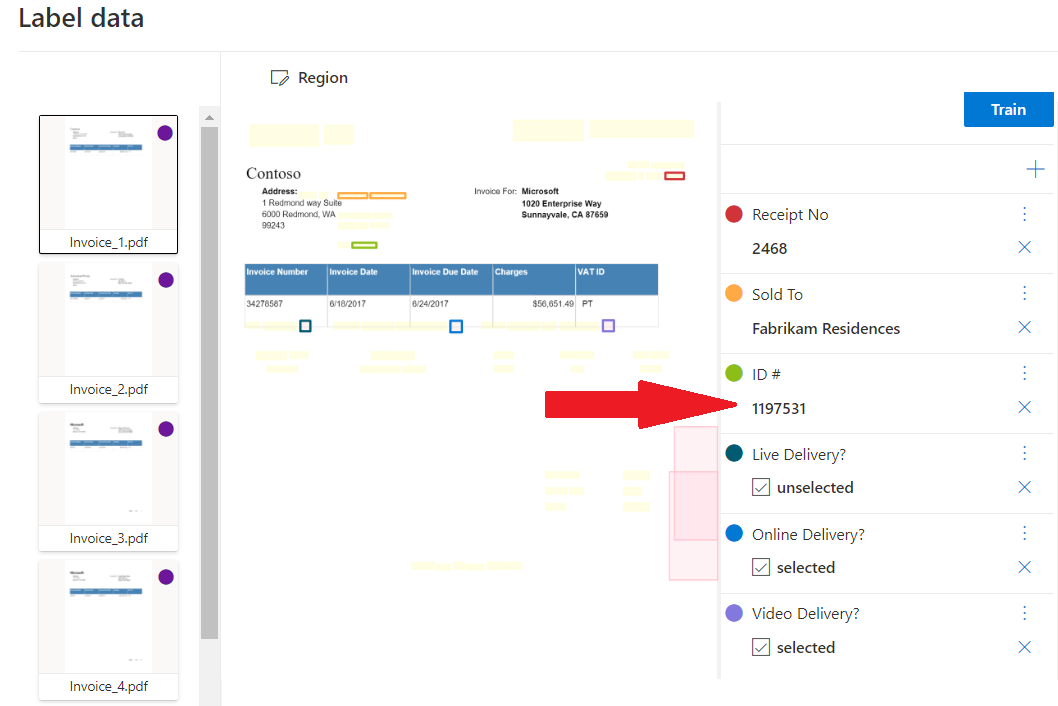
Niestandardowe wyodrębnianie

Niestandardowy model wyodrębniania może być jednym z dwóch typów, szablonem niestandardowym lub niestandardowym neuronowym. Aby utworzyć niestandardowy model wyodrębniania, oznacz zestaw danych dokumentów wartościami, które chcesz wyodrębnić i wytrenować model w oznaczonym zestawie danych. Do rozpoczęcia pracy potrzebujesz tylko pięciu przykładów tego samego formularza lub typu dokumentu.
Przykładowe wyodrębnianie niestandardowe przetworzone przy użyciu programu Document Intelligence Studio:

Klasyfikator niestandardowy

Niestandardowy model klasyfikacji umożliwia zidentyfikowanie typu dokumentu przed wywołaniem modelu wyodrębniania. Model klasyfikacji jest dostępny od interfejsu 2023-07-31 (GA) API. Trenowanie niestandardowego modelu klasyfikacji wymaga co najmniej dwóch odrębnych klas i co najmniej pięciu próbek na klasę.
Modele złożone
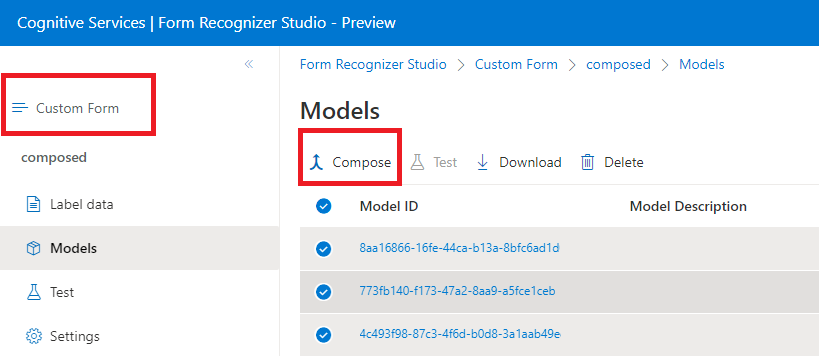
Utworzony model jest tworzony przez pobranie kolekcji modeli niestandardowych i przypisanie ich do pojedynczego modelu utworzonego na podstawie typów formularzy. Można przypisać wiele modeli niestandardowych do złożonego modelu o nazwie z jednym identyfikatorem modelu. Do pojedynczego modelu złożonego można przypisać maksymalnie 200 wytrenowanych modeli niestandardowych.
Okno dialogowe złożonego modelu w programie Document Intelligence Studio:
Wymagania dotyczące danych wejściowych
Aby uzyskać najlepsze wyniki, podaj jedno jasne zdjęcie lub wysokiej jakości skanowanie na dokument.
Obsługiwane formaty plików:
Model PDF Obraz:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) i HTMLPrzeczytaj ✔ ✔ ✔ Układ ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Dokument ogólny ✔ ✔ Wstępnie utworzona ✔ ✔ Niestandardowe wyodrębnianie ✔ ✔ Klasyfikacja niestandardowa ✔ ✔ ✔ (2024-02-29-preview) W przypadku plików PDF i TIFF można przetworzyć maksymalnie 2000 stron (w przypadku subskrypcji w warstwie Bezpłatna przetwarzane są tylko pierwsze dwie strony).
Rozmiar pliku do analizowania dokumentów wynosi 500 MB dla warstwy płatnej (S0) i 4 MB za bezpłatną (F0).
Wymiary obrazu muszą mieć od 50 x 50 pikseli do 10 000 pikseli x 10 000 pikseli.
Jeśli pliki PDF są zablokowane hasłem, przed ich przesłaniem usuń blokadę.
Minimalna wysokość tekstu do wyodrębnienia to 12 pikseli dla obrazu o rozmiarze 1024 x 768 pikseli. Ten wymiar odpowiada około
8-point text na 150 kropek na cal (DPI).W przypadku trenowania modelu niestandardowego maksymalna liczba stron dla danych szkoleniowych wynosi 500 dla niestandardowego modelu szablonu i 50 000 dla niestandardowego modelu neuronowego.
W przypadku trenowania niestandardowego modelu wyodrębniania łączny rozmiar danych treningowych wynosi 50 MB dla modelu szablonu i 1G-MB dla modelu neuronowego.
W przypadku trenowania niestandardowego modelu klasyfikacji całkowity rozmiar danych treningowych wynosi
1GBmaksymalnie 10 000 stron.
Uwaga
Przykładowe narzędzie etykietowania nie obsługuje formatu pliku BMP. Jest to ograniczenie narzędzia, a nie usługi analizy dokumentów.
Migracja wersji
Dowiedz się, jak używać analizy dokumentów w wersji 3.0 w aplikacjach, postępując zgodnie z naszym przewodnikiem migracji analizy dokumentów w wersji 3.1
| Model | Opis |
|---|---|
| Analiza dokumentów | |
| Układ | Wyodrębnij informacje o tekście i układzie z dokumentów. |
| Prekompilowanych | |
| Faktura | Wyodrębnij kluczowe informacje z faktur w języku angielskim i hiszpańskim. |
| Otrzymania | Wyodrębnij kluczowe informacje z rachunków w języku angielskim. |
| Dokument tożsamości | Wyodrębnij kluczowe informacje z amerykańskich licencji kierowców i międzynarodowych paszportów. |
| Wizytówka | Wyodrębnij kluczowe informacje z angielskich wizytówek. |
| Okres niestandardowy | |
| Okres niestandardowy | Wyodrębnianie danych z formularzy i dokumentów specyficznych dla Twojej firmy. Modele niestandardowe są trenowane dla unikatowych danych i przypadków użycia. |
| Składający się | Utwórz kolekcję modeli niestandardowych i przypisz je do pojedynczego modelu utworzonego na podstawie typów formularzy. |
Układ
Interfejs API układu analizuje i wyodrębnia tekst, tabele i nagłówki, znaczniki wyboru i informacje o strukturze z dokumentów.
Przykładowy dokument przetworzony przy użyciu narzędzia do etykietowania przykładowego:
Faktura
Model faktur analizuje i wyodrębnia kluczowe informacje z faktur sprzedaży. Interfejs API analizuje faktury w różnych formatach i wyodrębnia kluczowe informacje, takie jak nazwa klienta, adres rozliczeniowy, data ukończenia i kwota należności.
Przykładowa faktura przetworzona przy użyciu narzędzia do etykietowania przykładowego:

Przyjęcie
- Model paragonu analizuje i wyodrębnia kluczowe informacje z drukowanych i odręcznych paragonów sprzedaży.
Przykładowe potwierdzenie przetworzone przy użyciu narzędzia do etykietowania przykładowego:
Dokument tożsamości
Model dokumentu identyfikatora analizuje i wyodrębnia kluczowe informacje z następujących dokumentów:
Licencje kierowców USA (wszystkie 50 stanów i Dystrykt Kolumbii)
Strony biograficzne z międzynarodowych paszportów (z wyłączeniem wiz i innych dokumentów podróży). Interfejs API analizuje dokumenty tożsamości i wyodrębnia
Przykładowa licencja kierowcy USA przetworzona przy użyciu narzędzia do etykietowania przykładowego:
Karta biznesowa
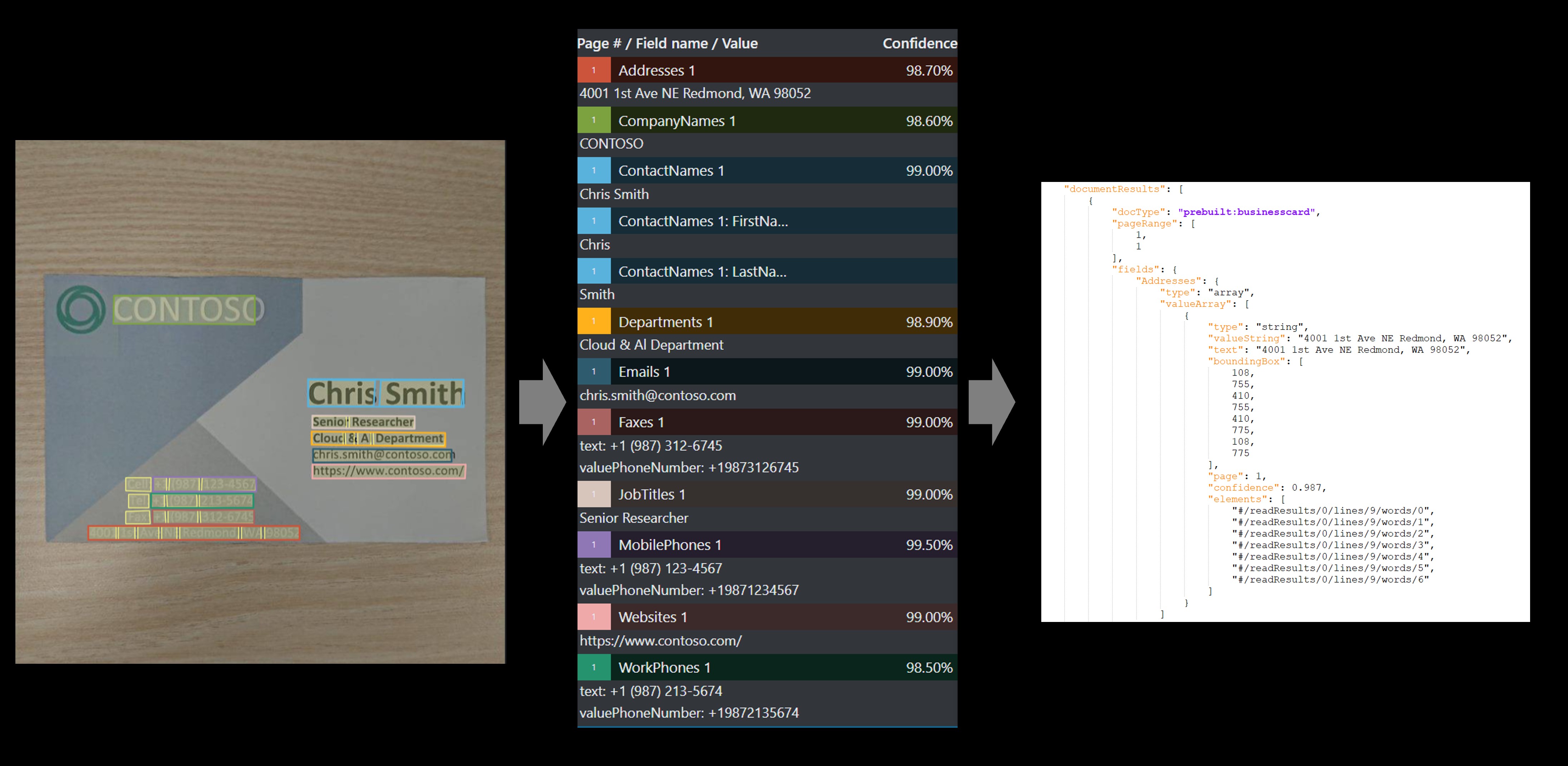
Model wizytówek analizuje i wyodrębnia kluczowe informacje z obrazów wizytówek.
Przykładowa wizytówka przetworzona przy użyciu narzędzia do etykietowania przykładowego:
Niestandardowy
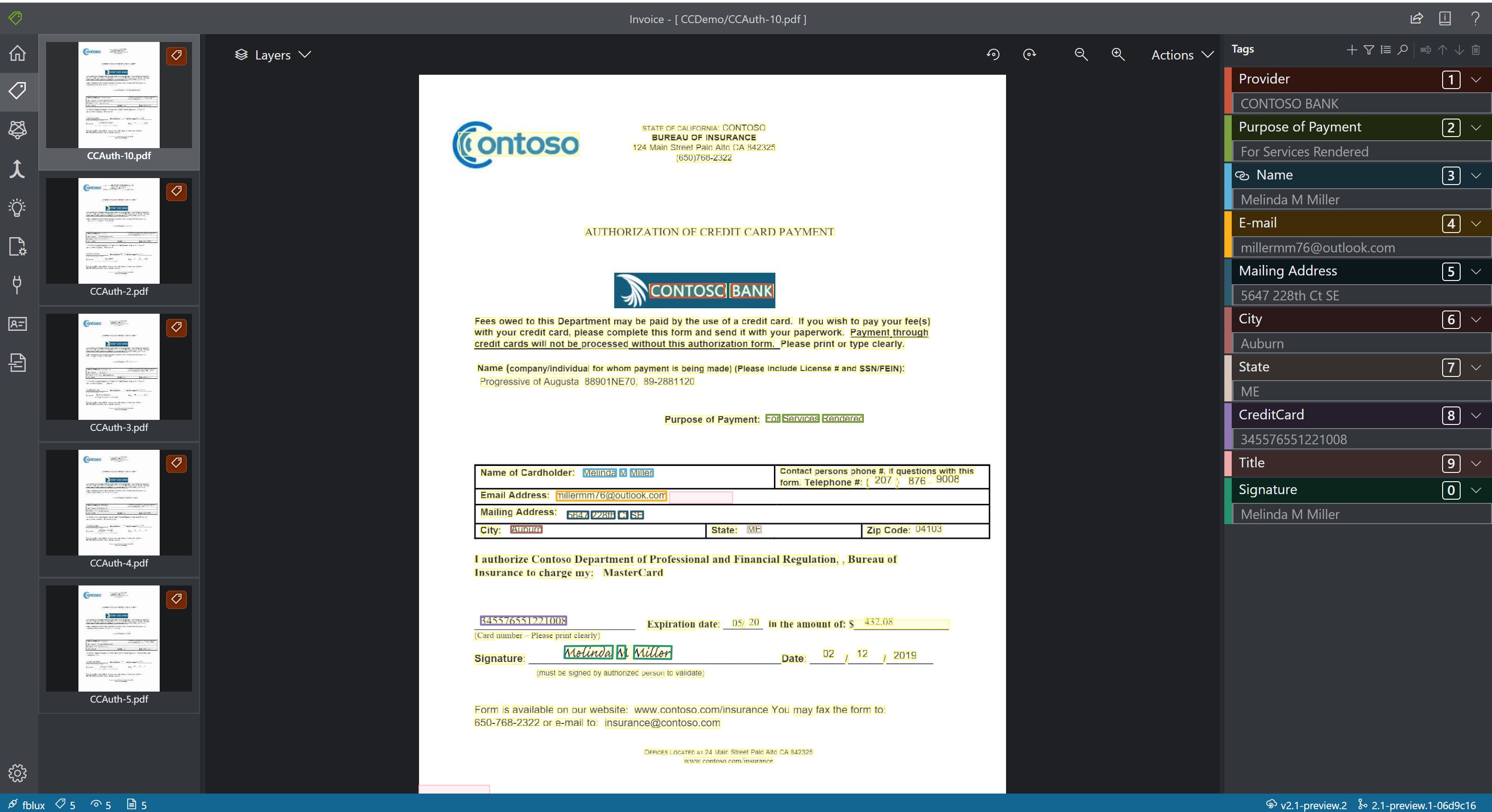
- Modele niestandardowe analizują i wyodrębniają dane z formularzy i dokumentów specyficznych dla Twojej firmy. Interfejs API to program uczenia maszynowego wyszkolony do rozpoznawania pól formularzy w ramach odrębnej zawartości i wyodrębniania par klucz-wartość i danych tabeli. Aby rozpocząć pracę, potrzebujesz tylko pięciu przykładów tego samego typu formularza, a model niestandardowy można wytrenować przy użyciu zestawów danych oznaczonych etykietami lub bez ich użycia.
Przykładowe przetwarzanie modelu niestandardowego przy użyciu narzędzia do etykietowania przykładowego:
Skomponowany model niestandardowy
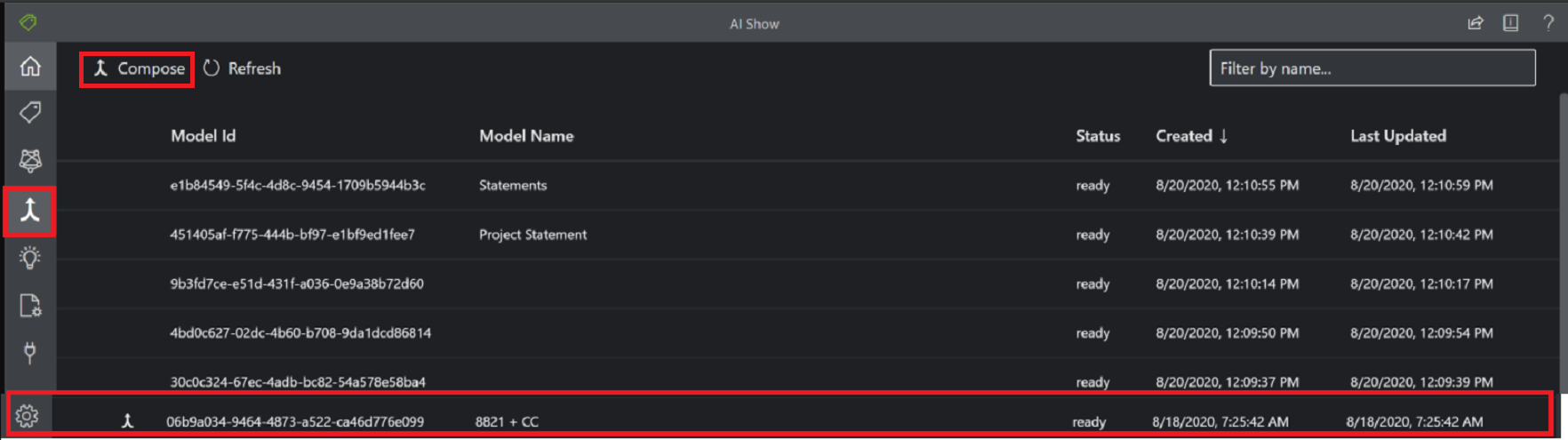
Utworzony model jest tworzony przez pobranie kolekcji modeli niestandardowych i przypisanie ich do pojedynczego modelu utworzonego na podstawie typów formularzy. Można przypisać wiele modeli niestandardowych do złożonego modelu o nazwie z jednym identyfikatorem modelu. Do jednego modelu składanego można przypisać maksymalnie 100 wytrenowanych modeli niestandardowych.
Okno dialogowe złożonego modelu przy użyciu narzędzia Przykładowe etykietowanie:
Wyodrębnianie danych modelu
| Model | Wyodrębnianie tekstu | Wykrywanie języka | Znaczniki zaznaczenia | Tabele | Ustępów | Role akapitu | Pary klucz-wartość | Pola |
|---|---|---|---|---|---|---|---|---|
| Układ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Faktura | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Otrzymania | ✓ | ✓ | ✓ | |||||
| Identyfikator dokumentu | ✓ | ✓ | ✓ | |||||
| Wizytówka | ✓ | ✓ | ✓ | |||||
| Formularz niestandardowy | ✓ | ✓ | ✓ | ✓ | ✓ |
Wymagania dotyczące danych wejściowych
Aby uzyskać najlepsze wyniki, podaj jedno jasne zdjęcie lub wysokiej jakości skanowanie na dokument.
Obsługiwane formaty plików:
Model PDF Obraz:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) i HTMLPrzeczytaj ✔ ✔ ✔ Układ ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Dokument ogólny ✔ ✔ Wstępnie utworzona ✔ ✔ Niestandardowe wyodrębnianie ✔ ✔ Klasyfikacja niestandardowa ✔ ✔ ✔ (2024-02-29-preview) W przypadku plików PDF i TIFF można przetworzyć maksymalnie 2000 stron (w przypadku subskrypcji w warstwie Bezpłatna przetwarzane są tylko pierwsze dwie strony).
Rozmiar pliku do analizowania dokumentów wynosi 500 MB dla warstwy płatnej (S0) i 4 MB za bezpłatną (F0).
Wymiary obrazu muszą mieć od 50 x 50 pikseli do 10 000 pikseli x 10 000 pikseli.
Jeśli pliki PDF są zablokowane hasłem, przed ich przesłaniem usuń blokadę.
Minimalna wysokość tekstu do wyodrębnienia to 12 pikseli dla obrazu o rozmiarze 1024 x 768 pikseli. Ten wymiar odpowiada około
8-point text na 150 kropek na cal (DPI).W przypadku trenowania modelu niestandardowego maksymalna liczba stron dla danych szkoleniowych wynosi 500 dla niestandardowego modelu szablonu i 50 000 dla niestandardowego modelu neuronowego.
W przypadku trenowania niestandardowego modelu wyodrębniania łączny rozmiar danych treningowych wynosi 50 MB dla modelu szablonu i 1G-MB dla modelu neuronowego.
W przypadku trenowania niestandardowego modelu klasyfikacji całkowity rozmiar danych treningowych wynosi
1GBmaksymalnie 10 000 stron.
Uwaga
Przykładowe narzędzie etykietowania nie obsługuje formatu pliku BMP. Jest to ograniczenie narzędzia, a nie usługi analizy dokumentów.
Migracja wersji
Aby dowiedzieć się, jak używać analizy dokumentów w wersji 3.0 w aplikacjach, zapoznaj się z naszym przewodnikiem migracji analizy dokumentów w wersji 3.1
Następne kroki
Spróbuj przetwarzać własne formularze i dokumenty za pomocą programu Document Intelligence Studio.
Ukończ przewodnik Szybki start dotyczący analizy dokumentów i rozpocznij tworzenie aplikacji do przetwarzania dokumentów w wybranym języku programowania.
Spróbuj przetwarzać własne formularze i dokumenty za pomocą narzędzia do etykietowania przykładowego analizy dokumentów.
Ukończ przewodnik Szybki start dotyczący analizy dokumentów i rozpocznij tworzenie aplikacji do przetwarzania dokumentów w wybranym języku programowania.