W tym artykule pokazano, jak utworzyć usługę wyszukiwania, która umożliwia użytkownikom wyszukiwanie dokumentów na podstawie zawartości dokumentu oprócz wszystkich metadanych skojarzonych z plikami.
Tę usługę można zaimplementować przy użyciu wielu indeksatorów w usłudzeAzure AI Search.
W tym artykule użyto przykładowego obciążenia, aby zademonstrować sposób tworzenia pojedynczego indeksu wyszukiwania opartego na plikach w usłudze Azure Blob Storage. Metadane pliku są przechowywane w usłudze Azure Table Storage.
Architektura
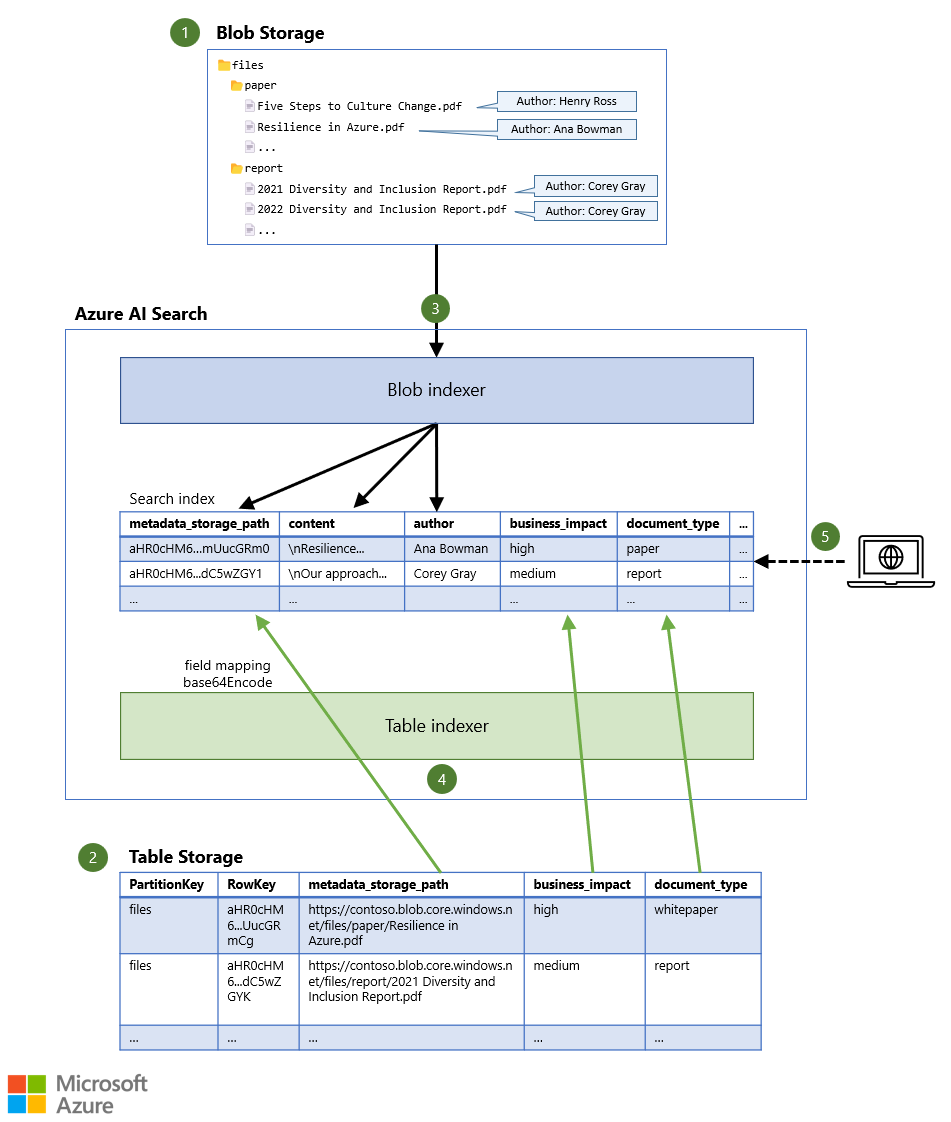
Pobierz plik programu PowerPoint tej architektury.
Przepływ danych
- Pliki są przechowywane w usłudze Blob Storage, prawdopodobnie wraz z ograniczoną ilością metadanych (na przykład autorem dokumentu).
- Dodatkowe metadane są przechowywane w usłudze Table Storage, która może przechowywać znacznie więcej informacji dla każdego dokumentu.
- Indeksator odczytuje zawartość każdego pliku wraz z dowolnymi metadanymi obiektu blob i przechowuje dane w indeksie wyszukiwania.
- Inny indeksator odczytuje dodatkowe metadane z tabeli i przechowuje je w tym samym indeksie wyszukiwania.
- Zapytanie wyszukiwania jest wysyłane do usługi wyszukiwania. Zapytanie zwraca pasujące dokumenty na podstawie zawartości dokumentu i metadanych dokumentu.
Składniki
- Usługa Blob Storage zapewnia ekonomiczny magazyn w chmurze dla danych plików, w tym dane w formatach, takich jak PDF, HTML i CSV, oraz w plikach platformy Microsoft 365.
- Usługa Table Storage zapewnia magazyn danych nierelacyjnych ze strukturą. W tym scenariuszu jest używany do przechowywania metadanych dla każdego dokumentu.
- Azure AI Search to w pełni zarządzana usługa wyszukiwania, która udostępnia infrastrukturę, interfejsy API i narzędzia do tworzenia rozbudowanego środowiska wyszukiwania.
Alternatywy
W tym scenariuszu indeksatory w usłudze Azure AI Search umożliwiają automatyczne odnajdywanie nowej zawartości w obsługiwanych źródłach danych, takich jak obiekty blob i magazyn tabel, a następnie dodawanie ich do indeksu wyszukiwania. Alternatywnie możesz użyć interfejsów API udostępnianych przez usługę Azure AI Search, aby wypchnąć dane do indeksu wyszukiwania. Jeśli jednak musisz napisać kod, aby wypchnąć dane do indeksu wyszukiwania, a także przeanalizować i wyodrębnić tekst z dokumentów binarnych, które chcesz wyszukać. Indeksator usługi Blob Storage obsługuje wiele formatów dokumentów, co znacznie upraszcza proces wyodrębniania i indeksowania tekstu.
Ponadto w przypadku używania indeksatorów możesz opcjonalnie wzbogacić dane w ramach potoku indeksowania. Na przykład usługi Azure AI umożliwiają wykonywanie optycznego rozpoznawania znaków (OCR) lub wizualnej analizy obrazów w dokumentach, wykrywanie języka dokumentów lub tłumaczenie dokumentów. Możesz również zdefiniować własne umiejętności niestandardowe, aby wzbogacić dane w sposób odpowiedni dla danego scenariusza biznesowego.
Ta architektura używa obiektów blob i magazynu tabel, ponieważ są one ekonomiczne i wydajne. Ten projekt umożliwia również łączny magazyn dokumentów i metadanych na jednym koncie magazynu. Alternatywne obsługiwane źródła danych dla samych dokumentów obejmują usługi Azure Data Lake Storage i Azure Files. Metadane dokumentu mogą być przechowywane w dowolnym innym obsługiwanym źródle danych, które przechowuje dane ustrukturyzowane, takie jak Azure SQL Database i Azure Cosmos DB.
Szczegóły scenariusza
Wyszukiwanie zawartości pliku
To rozwiązanie umożliwia użytkownikom wyszukiwanie dokumentów na podstawie zawartości pliku i dodatkowych metadanych przechowywanych oddzielnie dla każdego dokumentu. Oprócz przeszukiwania zawartości tekstowej dokumentu użytkownik może chcieć wyszukać autora dokumentu, typ dokumentu (na przykład papier lub raport) lub jego wpływ biznesowy (wysoki, średni lub niski).
Azure AI Search to w pełni zarządzana usługa wyszukiwania, która umożliwia tworzenie indeksów wyszukiwania zawierających informacje, które mają umożliwić użytkownikom wyszukiwanie.
Ponieważ pliki, które są przeszukiwane w tym scenariuszu, to dokumenty binarne, można je przechowywać w usłudze Blob Storage. Jeśli tak, możesz użyć wbudowanego indeksatora usługi Blob Storage w usłudze Azure AI Search, aby automatycznie wyodrębnić tekst z plików i dodać ich zawartość do indeksu wyszukiwania.
Wyszukiwanie metadanych pliku
Jeśli chcesz dołączyć dodatkowe informacje o plikach, możesz bezpośrednio skojarzyć metadane z obiektami blob bez użycia oddzielnego magazynu. Wbudowany indeksator wyszukiwania usługi Blob Storage może nawet odczytać te metadane i umieścić je w indeksie wyszukiwania. Dzięki temu użytkownicy mogą wyszukiwać metadane wraz z zawartością pliku. Jednak ilość metadanych jest ograniczona do 8 KB na obiekt blob, więc ilość informacji, które można umieścić w każdym obiekcie blob, jest dość mała. Możesz zdecydować się na przechowywanie tylko najbardziej krytycznych informacji bezpośrednio na obiektach blob. W tym scenariuszu tylko autor dokumentu jest przechowywany w obiekcie blob.
Aby przezwyciężyć to ograniczenie magazynu, możesz umieścić dodatkowe metadane w innym źródle danych, które ma obsługiwany indeksator, na przykład Table Storage. Możesz dodać typ dokumentu, wpływ biznesowy i inne wartości metadanych jako oddzielne kolumny w tabeli. Jeśli skonfigurujesz wbudowany indeksator usługi Table Storage tak, aby był przeznaczony dla tego samego indeksu wyszukiwania co indeksator obiektów blob, metadane magazynu obiektów blob i tabel są łączone dla każdego dokumentu w indeksie wyszukiwania.
Używanie wielu źródeł danych dla pojedynczego indeksu wyszukiwania
Aby upewnić się, że oba indeksatory wskazują ten sam dokument w indeksie wyszukiwania, klucz dokumentu w indeksie wyszukiwania jest ustawiony na unikatowy identyfikator pliku. Ten unikatowy identyfikator jest następnie używany do odwoływania się do pliku w obu źródłach danych. Indeksator obiektów blob domyślnie używa metadata_storage_path elementu jako klucza dokumentu. Właściwość metadata_storage_path przechowuje pełny adres URL pliku w usłudze Blob Storage, na przykład https://contoso.blob.core.windows.net/files/paper/Resilience in Azure.pdf. Indeksator wykonuje kodowanie Base64 na wartości, aby upewnić się, że w kluczu dokumentu nie ma nieprawidłowych znaków. Wynik jest unikatowym kluczem dokumentu, na przykład aHR0cHM6...mUucGRm0.
Jeśli dodasz metadata_storage_path kolumnę jako kolumnę w usłudze Table Storage, wiesz dokładnie, do którego obiektu blob należą metadane w innych kolumnach, aby można było użyć dowolnej PartitionKey wartości i RowKey w tabeli. Można na przykład użyć nazwy kontenera obiektów blob jako PartitionKey i pełnego adresu URL obiektu blob zakodowanego w formacie Base64 jako RowKey, zapewniając, że w tych kluczach nie ma nieprawidłowych znaków.
Następnie możesz użyć mapowania pól w indeksatorze tabeli, aby zamapować metadata_storage_path kolumnę (lub inną kolumnę) w usłudze Table Storage na metadata_storage_path pole klucza dokumentu w indeksie wyszukiwania. Jeśli zastosujesz funkcję base64Encode na mapowaniu pól, zostanie wyświetlony ten sam klucz dokumentu (aHR0cHM6...mUucGRm0 we wcześniejszym przykładzie), a metadane z usługi Table Storage są dodawane do tego samego dokumentu, który został wyodrębniony z usługi Blob Storage.
Uwaga
W dokumentacji indeksatora tabel stwierdza się, że nie należy definiować mapowania pól na alternatywne unikatowe pole ciągu w tabeli. Dzieje się tak, ponieważ indeksator domyślnie łączy PartitionKey element i RowKey jako klucz dokumentu. Ponieważ już korzystasz z klucza dokumentu skonfigurowanego przez indeksator obiektów blob (który jest pełnym adresem URL obiektu blob zakodowanym w formacie Base64), utwórz mapowanie pól, aby upewnić się, że oba indeksatory odwołują się do tego samego dokumentu w indeksie wyszukiwania i są obsługiwane w tym scenariuszu.
Alternatywnie można mapować RowKey element (ustawiony na pełny adres URL obiektu blob zakodowany w formacie Base64) metadata_storage_path bezpośrednio do klucza dokumentu bez konieczności przechowywania go oddzielnie i kodowania Base64 w ramach mapowania pól. Jednak zachowanie niezakodowanego adresu URL w oddzielnej kolumnie wyjaśnia, do którego obiektu blob odwołuje się i umożliwia wybranie dowolnego klucza partycji i kluczy wierszy bez wpływu na indeksator wyszukiwania.
Potencjalne przypadki użycia
Ten scenariusz dotyczy aplikacji, które wymagają możliwości wyszukiwania dokumentów na podstawie ich zawartości i dodatkowych metadanych.
Kwestie wymagające rozważenia
Te zagadnienia implementują filary platformy Azure Well-Architected Framework, która jest zestawem wytycznych, których można użyć do poprawy jakości obciążenia. Aby uzyskać więcej informacji, zobacz Microsoft Azure Well-Architected Framework.
Niezawodność
Niezawodność gwarantuje, że aplikacja może spełnić zobowiązania wobec klientów. Aby uzyskać więcej informacji, zobacz Omówienie filaru niezawodności.
Usługa Azure AI Search zapewnia umowę dotyczącą wysokiego poziomu usług (SLA) dla operacji odczytu (wykonywania zapytań), jeśli masz co najmniej dwie repliki. Zapewnia ona wysoką umowę SLA dla aktualizacji (aktualizowanie indeksów wyszukiwania), jeśli masz co najmniej trzy repliki. Dlatego należy aprowizować co najmniej dwie repliki, jeśli chcesz, aby użytkownicy mogli niezawodnie wyszukiwać, i trzy, jeśli rzeczywiste zmiany indeksu również muszą być operacjami o wysokiej dostępności.
Usługa Azure Storage zawsze przechowuje wiele kopii danych , aby chronić je przed zaplanowanymi i nieplanowanymi zdarzeniami. Usługa Azure Storage udostępnia dodatkowe opcje nadmiarowości replikowania danych między regionami. Te zabezpieczenia dotyczą danych w magazynie obiektów blob i tabel.
Zabezpieczenia
Zabezpieczenia zapewniają ochronę przed celowymi atakami i nadużyciami cennych danych i systemów. Aby uzyskać więcej informacji, zobacz Omówienie filaru zabezpieczeń.
Usługa Azure AI Search zapewnia niezawodne mechanizmy kontroli zabezpieczeń, które ułatwiają implementowanie zabezpieczeń sieci, uwierzytelniania i autoryzacji, rezydencji i ochrony danych oraz mechanizmów kontroli administracyjnych, które pomagają zachować bezpieczeństwo, prywatność i zgodność.
Jeśli to możliwe, użyj uwierzytelniania Firmy Microsoft Entra, aby zapewnić dostęp do samej usługi wyszukiwania i połączyć usługę wyszukiwania z innymi zasobami platformy Azure (takimi jak obiekty blob i magazyn tabel w tym scenariuszu) przy użyciu tożsamości zarządzanej.
Możesz nawiązać połączenie z usługi wyszukiwania z kontem magazynu przy użyciu prywatnego punktu końcowego. W przypadku korzystania z prywatnego punktu końcowego indeksatory mogą używać połączenia prywatnego bez konieczności publicznego udostępniania obiektu blob i magazynu tabel.
Optymalizacja kosztów
Optymalizacja kosztów polega na zmniejszeniu niepotrzebnych wydatków i poprawie wydajności operacyjnej. Aby uzyskać więcej informacji, zobacz Omówienie filaru optymalizacji kosztów.
Aby uzyskać informacje na temat kosztów uruchamiania tego scenariusza, zobacz to wstępnie skonfigurowane oszacowanie w kalkulatorze cen platformy Azure. Wszystkie usługi opisane tutaj są skonfigurowane w tym oszacowaniu. Oszacowanie dotyczy obciążenia, które ma całkowity rozmiar dokumentu wynoszący 20 GB w usłudze Blob Storage i 1 GB metadanych w usłudze Table Storage. Dwie jednostki wyszukiwania są używane do spełnienia umowy SLA na potrzeby odczytu, zgodnie z opisem w sekcji Niezawodność tego artykułu. Aby zobaczyć, jak ceny zmienią się dla konkretnego przypadku użycia, zmień odpowiednie zmienne, aby odpowiadały oczekiwanemu użyciu.
Jeśli przejrzysz oszacowanie, zobaczysz, że koszt magazynu obiektów blob i tabel jest stosunkowo niski. Większość kosztów jest naliczana przez usługę Azure AI Search, ponieważ wykonuje rzeczywiste indeksowanie i obliczenia na potrzeby uruchamiania zapytań wyszukiwania.
Wdrażanie tego scenariusza
Aby wdrożyć to przykładowe obciążenie, zobacz Indeksowanie zawartości pliku i metadanych w usłudze Azure AI Search. Możesz użyć tego przykładu do:
- Utwórz wymagane usługi platformy Azure.
- Przekaż kilka przykładowych dokumentów do usługi Blob Storage.
- Wypełnij wartość metadanych autora obiektu blob.
- Przechowuj wartości metadanych o typie dokumentu i wpływie na działalność biznesową w usłudze Table Storage.
- Utwórz indeksatory, które utrzymują indeks wyszukiwania.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Główny autor:
- Jelle Druyts | Główny inżynier środowiska klienta
Inny współautor:
- Mick Alberts | Składnik zapisywania technicznego
Aby wyświetlić niepubalne profile serwisu LinkedIn, zaloguj się do serwisu LinkedIn.
Następne kroki
- Wprowadzenie do usługi Azure AI Search
- Zwiększanie trafności przy użyciu wyszukiwania semantycznego w usłudze Azure AI Search
- Filtry zabezpieczeń na potrzeby przycinania wyników w usłudze Azure AI Search
- Samouczek: indeksowanie z wielu źródeł danych przy użyciu zestawu .NET SDK