Niewłaściwy antywzorzec tworzenia wystąpień
Czasami nowe wystąpienia klasy są stale tworzone, gdy ma zostać utworzone raz, a następnie udostępnione. To zachowanie może zaszkodzić wydajności i jest nazywane niewłaściwym antywzorzecem wystąpienia. Antywzorzec to powszechna odpowiedź na cykliczny problem, który jest zwykle nieskuteczny, a nawet może być przeciwny do produktywności.
Opis problemu
Wiele bibliotek zapewnia abstrakcje zasobów zewnętrznych. Wewnętrznie te klasy zwykle zarządzają własnymi połączeniami z zasobami, działając jako brokerzy, za pomocą których klienci mogą uzyskiwać dostęp do zasobu. Oto kilka przykładów klas brokera, które mają zastosowanie do aplikacji platformy Azure:
System.Net.Http.HttpClient. Komunikuje się z usługą internetową przy użyciu protokołu HTTP.Microsoft.ServiceBus.Messaging.QueueClient. Wysyła komunikaty do kolejki usługi Service Bus i odbiera komunikaty z tej kolejki.Microsoft.Azure.Documents.Client.DocumentClient. Połączenie do wystąpienia usługi Azure Cosmos DB.StackExchange.Redis.ConnectionMultiplexer. Nawiązuje połączenie z pamięcią podręczną Redis, w tym z usługą Azure Cache for Redis.
Te klasy są przeznaczone do jednorazowego utworzenia ich wystąpienia i ponownego używania w okresie istnienia aplikacji. Jest jednak typowym nieporozumieniem, że te klasy powinny być pobierane tylko w razie konieczności i szybko zwalniane. (Wymienione w tym miejscu są biblioteki .NET, ale wzorzec nie jest unikatowy dla platformy .NET). Poniższy przykład ASP.NET tworzy wystąpienie HttpClient programu do komunikowania się z usługą zdalną. Pełny przykład można znaleźć tutaj.
public class NewHttpClientInstancePerRequestController : ApiController
{
// This method creates a new instance of HttpClient and disposes it for every call to GetProductAsync.
public async Task<Product> GetProductAsync(string id)
{
using (var httpClient = new HttpClient())
{
var hostName = HttpContext.Current.Request.Url.Host;
var result = await httpClient.GetStringAsync(string.Format("http://{0}:8080/api/...", hostName));
return new Product { Name = result };
}
}
}
W aplikacji internetowej ta technika nie jest skalowalna. Nowy obiekt HttpClient jest tworzony dla każdego żądania użytkownika. Przy dużym obciążeniu serwer sieci Web może wyczerpać liczbę dostępnych gniazd, co skutkuje błędami SocketException.
Ten problem nie jest ograniczony do klasy HttpClient. Inne klasy, które opakowują zasoby lub których tworzenie jest kosztowne, mogą powodować podobne problemy. Poniższy przykład tworzy wystąpienie klasy ExpensiveToCreateService. Tutaj problemem niekoniecznie jest wyczerpanie liczby gniazd, ale po prostu czas, jaki zajmuje utworzenie każdego wystąpienia. Stale tworzenie i niszczenie wystąpień tej klasy może niekorzystnie wpłynąć na skalowalność systemu.
public class NewServiceInstancePerRequestController : ApiController
{
public async Task<Product> GetProductAsync(string id)
{
var expensiveToCreateService = new ExpensiveToCreateService();
return await expensiveToCreateService.GetProductByIdAsync(id);
}
}
public class ExpensiveToCreateService
{
public ExpensiveToCreateService()
{
// Simulate delay due to setup and configuration of ExpensiveToCreateService
Thread.SpinWait(Int32.MaxValue / 100);
}
...
}
Jak naprawić niewłaściwy antywzorzec tworzenia wystąpień
Jeśli klasa, która opakowuje zasób zewnętrzny jest możliwa do udostępniania i bezpieczna wątkowo, należy utworzyć udostępnione pojedyncze wystąpienie lub pulę wystąpień wielokrotnego użytku tej klasy.
W poniższym przykładzie użyto statycznego wystąpienia HttpClient, w związku z tym połączenie jest udostępniane wszystkim żądaniom.
public class SingleHttpClientInstanceController : ApiController
{
private static readonly HttpClient httpClient;
static SingleHttpClientInstanceController()
{
httpClient = new HttpClient();
}
// This method uses the shared instance of HttpClient for every call to GetProductAsync.
public async Task<Product> GetProductAsync(string id)
{
var hostName = HttpContext.Current.Request.Url.Host;
var result = await httpClient.GetStringAsync(string.Format("http://{0}:8080/api/...", hostName));
return new Product { Name = result };
}
}
Kwestie wymagające rozważenia
Kluczowym elementem tego antywzorca jest wielokrotne tworzenie i niszczenie wystąpień obiektu możliwego do udostępniania. Jeśli klasa nie jest możliwa do udostępniania (nie jest bezpieczna wątkowo), ten wzorzec nie ma zastosowania.
Typ udostępnionego zasobu może określać, czy należy użyć pojedynczego wystąpienia, czy utworzyć pulę. Klasa
HttpClientjest przeznaczona do udostępniania, a nie buforowania (łączenia w pulę). Inne obiekty mogą obsługiwać łączenie w pulę, umożliwiając systemowi rozkładanie obciążenia na wiele wystąpień.Obiekty udostępniane wielu żądaniom muszą być bezpieczne wątkowo. Klasa
HttpClientjest przeznaczona do używania w ten sposób, ale inne klasy mogą nie obsługiwać żądań współbieżnych, dlatego należy sprawdzić dostępną dokumentację.Należy zachować ostrożność przy ustawianiu właściwości obiektów udostępnionych, ponieważ może to prowadzić do sytuacji wyścigu. Na przykład do sytuacji wyścigu może doprowadzić ustawienie właściwości
DefaultRequestHeadersw klasieHttpClientprzed każdym żądaniem. Ustaw taką właściwość raz (na przykład podczas uruchamiania), a następnie twórz oddzielne wystąpienia, gdy zajdzie konieczność skonfigurowania innych ustawień.Niektóre typy zasobów są ograniczone i nie powinny być wstrzymywane. Przykładem są połączenia bazy danych. Utrzymywanie otwartego połączenia bazy danych, które nie jest wymagane, może uniemożliwić innym równoczesnym użytkownikom uzyskanie dostępu do bazy danych.
W programie .NET Framework wiele obiektów, które nawiązują połączenia z zasobami zewnętrznymi, jest tworzonych za pomocą statycznych metod fabryki innych klas, które zarządzają tymi połączeniami. Te obiekty powinny być zapisywane i używane ponownie, a nie usuwane i tworzone ponownie. Na przykład w usłudze Azure Service Bus obiekt
QueueClientjest tworzony za pomocą obiektuMessagingFactory. WewnętrznieMessagingFactoryzarządza połączeniami. Aby uzyskać więcej informacji, zobacz Najlepsze rozwiązania dotyczące zwiększania wydajności przy użyciu komunikatów usługi Service Bus.
Jak wykryć nieprawidłowe wystąpienie antywzorzec
Ten problem objawia się spadkiem przepustowości lub zwiększonym współczynnikiem błędów, wraz z co najmniej jednym z następujących symptomów:
- Wzrost liczby wyjątków, które wskazują na wyczerpanie zasobów takich jak gniazda, połączenia z bazą danych, dojścia do plików itd.
- Zwiększone użycie pamięci i odzyskiwanie pamięci.
- Wzrost aktywności sieci, dysku lub bazy danych.
Możesz wykonać następujące kroki, aby ułatwić zidentyfikowanie tego problemu:
- Wykonać monitorowanie procesów systemu produkcyjnego, aby zidentyfikować punkty, w których czasy reakcji się wydłużają lub system zgłasza niepowodzenie z powodu braku zasobów.
- Przeanalizować dane telemetryczne przechwycone w tych punktach w celu określenia, jakie operacje tworzą i niszczą obiekty korzystające z zasobów.
- Przetestować pod kątem obciążenia każdą podejrzaną operację kontrolowanym w środowisku testowym, a nie w systemie produkcyjnym.
- Przejrzeć kod źródłowy i sprawdzić, jak zarządzane są obiekty brokera.
Przejrzeć ślady stosu dla operacji, które działają wolno lub generują wyjątki, gdy system jest obciążony. Te informacje ułatwiają określenie, jak te operacje korzystają z zasobów. Wyjątki mogą pomóc ustalić, czy błędy są spowodowane wyczerpywaniem udostępnionych zasobów.
Przykładowa diagnostyka
W poniższych sekcjach zastosowano te kroki do opisanej wcześniej przykładowej aplikacji.
Identyfikowanie punktów spowolnienia lub niepowodzenia
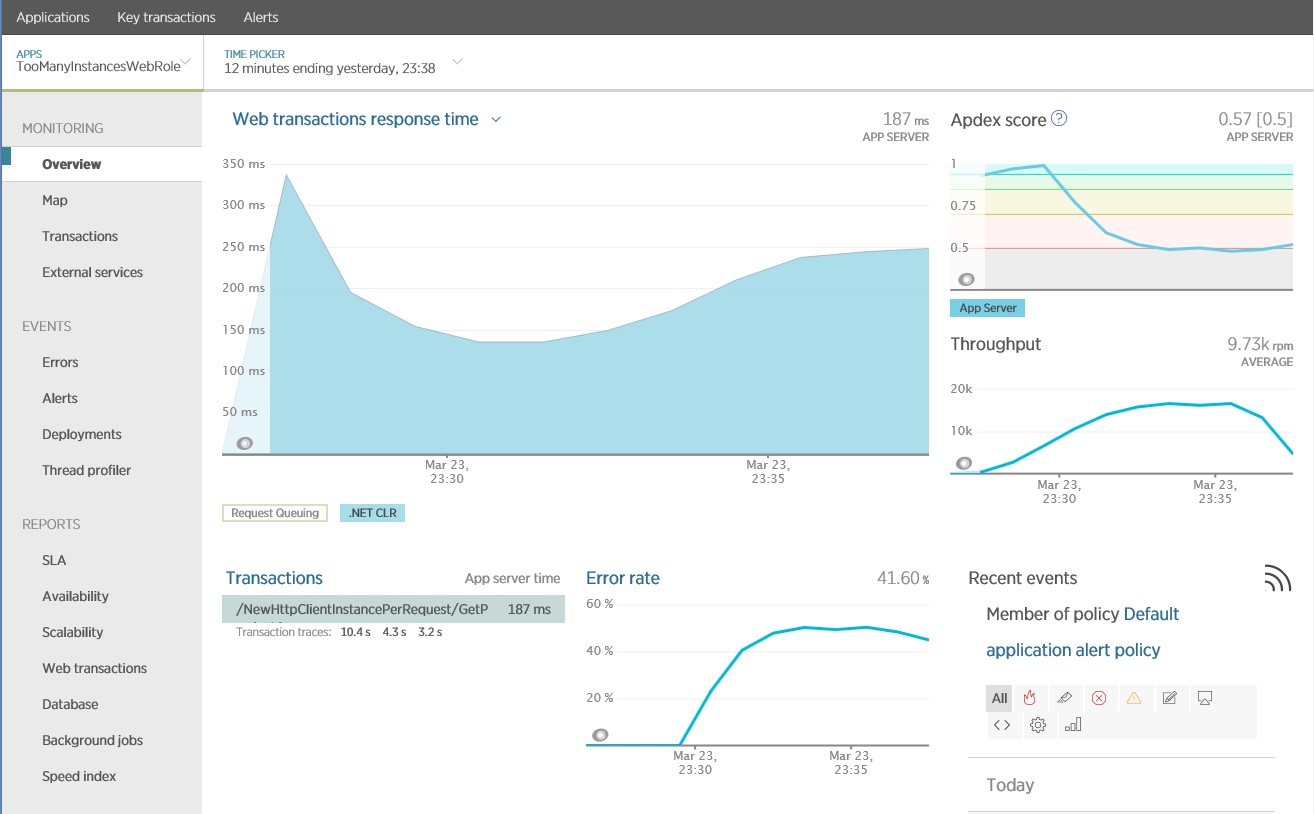
Na poniższej ilustracji przedstawiono wyniki wygenerowane przy użyciu usługi APM New Relic, przedstawiające operacje, które mają długi czas odpowiedzi. W tym przypadku warto dokładniej zbadać metodę GetProductAsync w kontrolerze NewHttpClientInstancePerRequest. Należy zauważyć, że współczynnik błędów również zwiększa się, kiedy te operacje są uruchomione.
Sprawdzanie danych telemetrycznych i znajdowanie korelacji
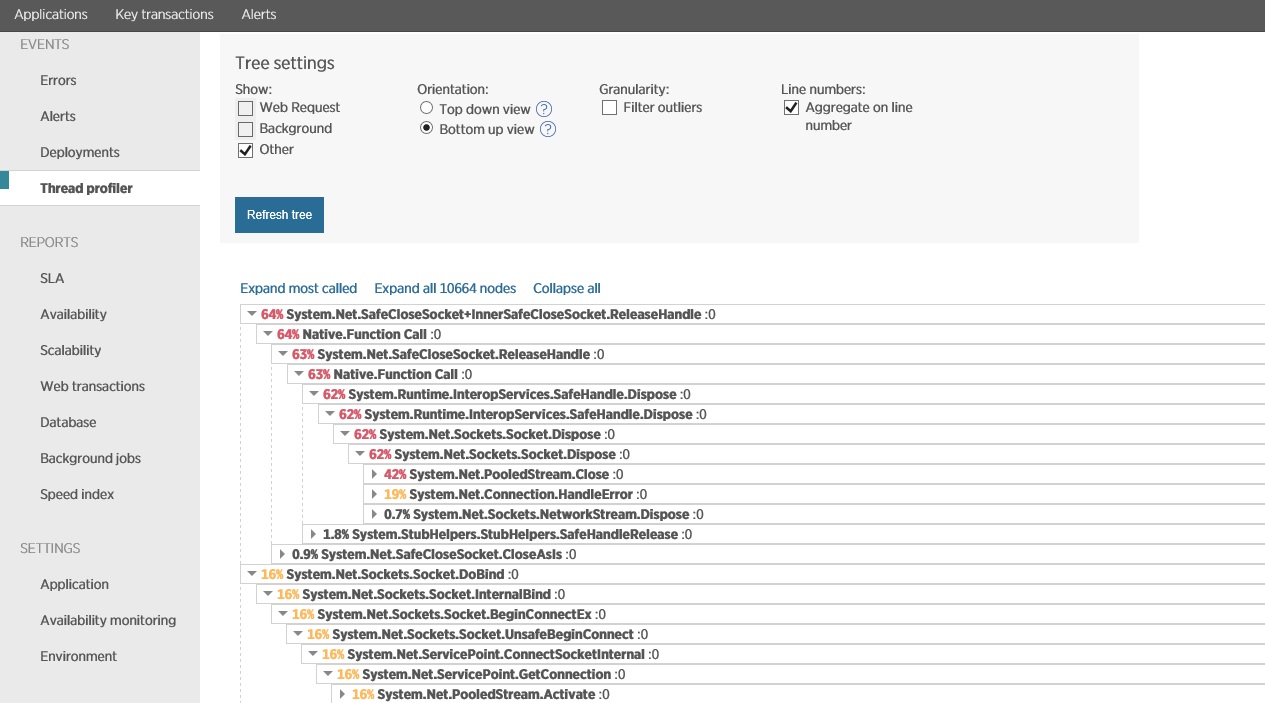
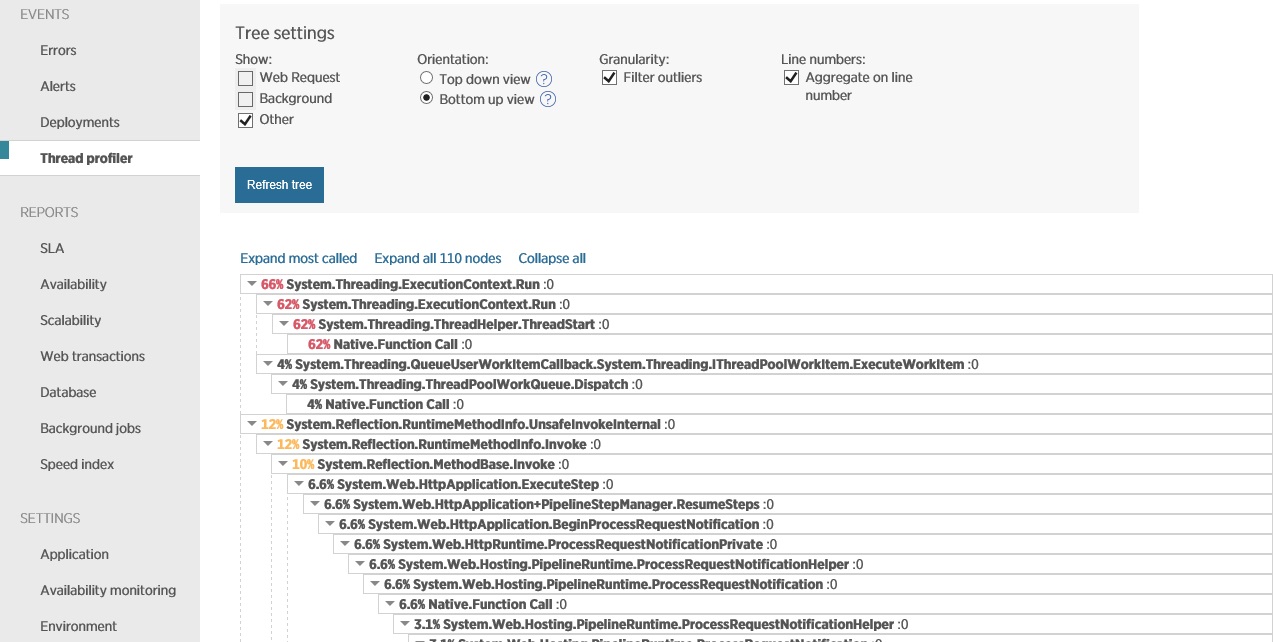
Następna ilustracja pokazuje dane przechwycone przy użyciu profilowania wątków w tym samym okresie, odpowiadającym temu na poprzedniej ilustracji. System poświęca znaczną ilość czasu na otwieranie połączeń gniazd, a jeszcze więcej na ich zamykanie i obsługiwanie wyjątków gniazd.
Wykonywanie testów obciążenia
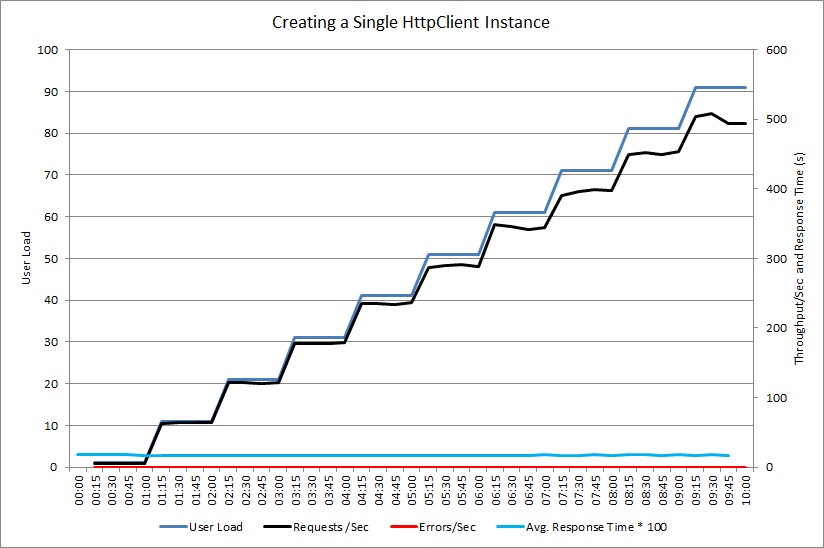
Testy obciążenia służą do symulowania typowych operacji, które mogą wykonywać użytkownicy. Może to ułatwić ustalenie, które części systemu borykają się z wyczerpaniem zasobów przy różnych obciążeniach. Te testy należy wykonać w kontrolowanym środowisku, a nie w systemie produkcyjnym. Poniższy wykres pokazuje przepływność żądań obsługiwanych przez kontroler NewHttpClientInstancePerRequest, gdy obciążenie użytkownikami wzrasta do 100 równoczesnych użytkowników.
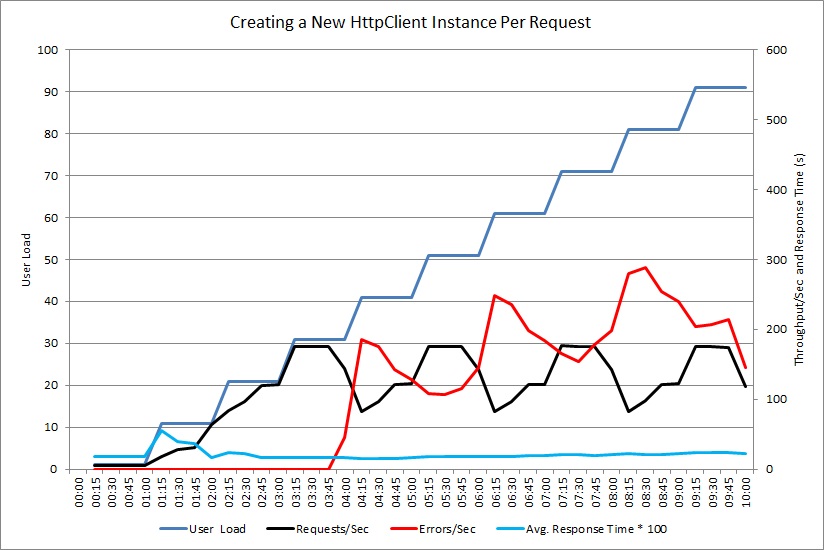
Na początku liczba obsłużonych żądań na sekundę rośnie wraz ze wzrostem obciążenia. Jednak przy liczbie około 30 użytkowników liczba pomyślnych żądań osiąga limit, a system zaczyna generować wyjątki. Od tego momentu liczba wyjątków stopniowo zwiększa się w miarę wzrostu obciążenia użytkownikami.
Test obciążenia zgłosił te błędy jako błędy HTTP 500 (wewnętrzny błąd serwera). Przeglądanie danych telemetrycznych wykazało, że te błędy były spowodowane wyczerpaniem zasobów gniazda przez system, ponieważ tworzonych było coraz więcej obiektów HttpClient.
Następny wykres przedstawia podobny test dla kontrolera, który tworzy niestandardowy obiekt ExpensiveToCreateService.
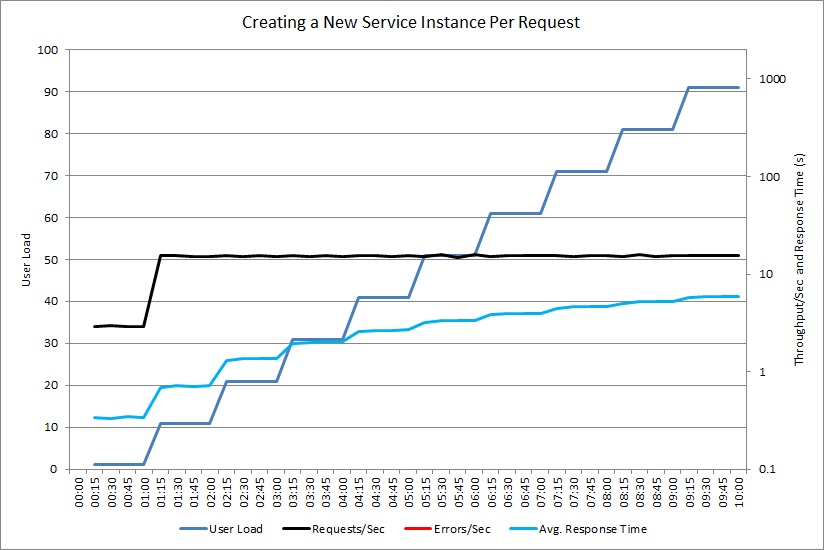
Tym razem kontroler nie generuje żadnych wyjątków, ale przepływność nadal osiąga pułap możliwości, gdy współczynnik średniego czasu odpowiedzi zwiększa się o 20. (Wykres używa skali logarytmicznej dla czasu odpowiedzi i przepływności). Telemetria wykazała, że tworzenie nowych wystąpień obiektu ExpensiveToCreateService było główną przyczyną problemu.
Implementowanie rozwiązania i weryfikowanie wyniku
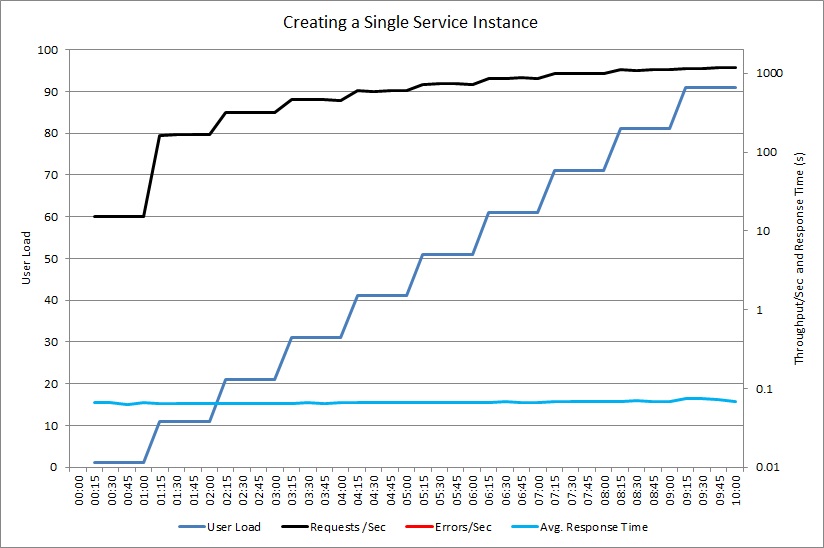
Po przełączeniu metody GetProductAsync w celu udostępniania pojedynczego wystąpienia HttpClient drugi test obciążenia wykazał poprawę wydajności. Nie zgłoszono żadnych błędów, a system był w stanie obsłużyć rosnące obciążenie do 500 żądań na sekundę. Średni czas odpowiedzi skrócił się o połowę w porównaniu z poprzednim testem.
Dla porównania na poniższej ilustracji przedstawiono dane telemetryczne śledzenia stosu. Tym razem system poświęca większość czasu na wykonywanie prawdziwej pracy, a nie na otwieranie i zamykanie gniazd.
Następny wykres przedstawia podobny test obciążenia przy użyciu współdzielonego wystąpienia obiektu ExpensiveToCreateService. Ponownie liczba żądań obsłużonych rośnie wraz ze wzrostem obciążenia użytkownikami, podczas gdy średni czas odpowiedzi jest krótki.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla