Architektura danych big data została zaprojektowana do obsługi wprowadzania, przetwarzania i analizy danych, które są zbyt duże lub zbyt złożone dla tradycyjnych systemów baz danych. Próg, który muszą osiągnąć organizacje, aby wejść do obszaru danych big data, różni się w zależności od możliwości użytkowników i ich narzędzi. W niektórych przypadkach może oznaczać setki gigabajtów danych, a w innych setki terabajtów. Ponieważ narzędzia do pracy z dużymi zestawami danych są zaawansowane, tak samo znaczenie danych big data. Coraz bardziej określenie to odnosi się do wartości, które można wyodrębnić z zestawów danych za pośrednictwem zaawansowanych metod analizy, a nie wyłącznie rozmiaru danych, mimo że w takich przypadkach jest on zwykle dość duży.
W ciągu lat środowisko danych uległo zmianie. Zmieniły się możliwości i oczekiwania względem operacji wykonywanych na danych. Koszty związane z magazynowaniem znacznie spadły, ale istnieje teraz zdecydowanie więcej sposobów zbierania danych. Niektóre dane docierają bardzo szybko i stale wymagane jest ich zbieranie i obserwowanie. Inne dane docierają wolniej, ale w bardzo dużych fragmentach, często w postaci dekad danych historycznych. Mogą pojawić się skomplikowane problemy analityczne lub wymagające użycia uczenia maszynowego. To właśnie tego typu wyzwania pomagają pokonywać architektury danych big data.
Rozwiązania do obsługi danych big data obejmują na ogół co najmniej jeden z następujących typów obciążenia:
- Przetwarzanie wsadowe źródeł danych big data w stanie spoczynku.
- Przetwarzanie w czasie rzeczywistym danych big data w ruchu.
- Interakcyjna eksploracja danych big data.
- Analiza predykcyjna i uczenie maszynowe.
Rozważ użycie architektur danych big data, gdy potrzebujesz:
- Przechowywać i przetwarzać dane w ilościach zbyt dużych dla tradycyjnych baz danych.
- Przekształcać dane nieustrukturyzowane na potrzeby analizy i raportowania.
- Przechwytywać, przetwarzać i analizować niepowiązane strumienie danych w czasie rzeczywistym lub z niewielkim opóźnieniem.
Składniki architektury danych big data
Na poniższym diagramie przedstawiono składniki logiczne, które są zgodne z architekturą danych big data. Poszczególne rozwiązania mogą nie zawierać wszystkich elementów znajdujących się na tym diagramie.
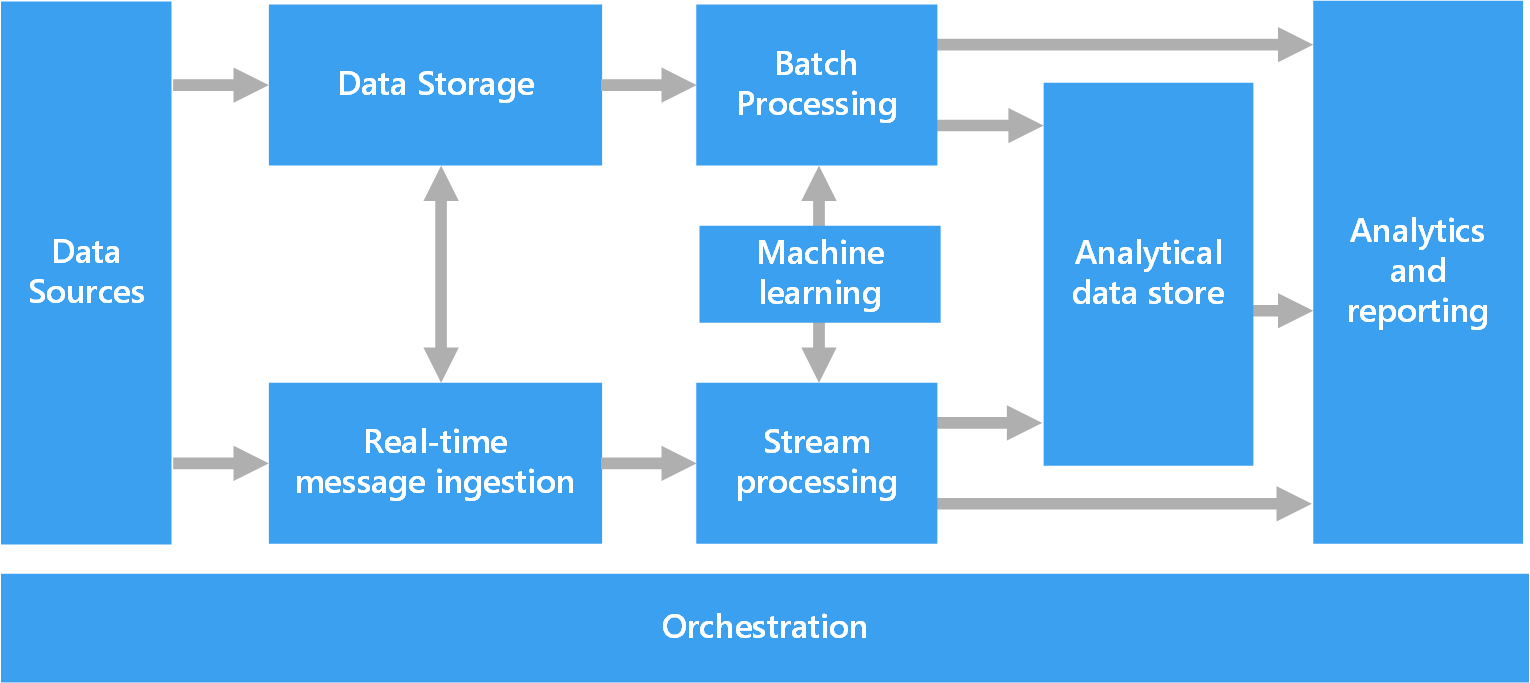
Większość architektur big data zawiera niektóre lub wszystkie z następujących składników:
Źródła danych. Wszystkie rozwiązania typu big data powstają w oparciu o co najmniej jedno źródło danych. Oto kilka przykładów:
- Magazyny danych aplikacji, takie jak relacyjne bazy danych.
- Pliki statyczne tworzone przez aplikacje, takie jak pliki dzienników serwerów internetowych.
- Źródła danych czasu rzeczywistego, np. urządzenia IoT.
Magazyn danych. Dane do operacji przetwarzania wsadowego są na ogół przechowywane w rozproszonym magazynie plików, który może pomieścić duże ilości dużych plików w różnych formatach. Taki rodzaj magazynu jest często określany jako data lake. Opcje implementacji tego magazynu obejmują usługę Azure Data Lake Store lub kontenery obiektów blob w usłudze Azure Storage.
Przetwarzanie wsadowe. Z powodu tak dużych zestawów danych rozwiązanie do obsługi danych big data musi często przetwarzać pliki danych przy użyciu długotrwałych zadań wsadowych, aby filtrować, agregować i przygotowywać w inny sposób dane do analizy. Na ogół zadania te obejmują odczytywanie plików źródłowych, przetwarzanie ich i zapisywanie danych wyjściowych do nowych plików. Opcje obejmują uruchamianie zadań U-SQL w usłudze Azure Data Lake Analytics, używanie programów Hive, Pig, niestandardowych zadań Map/Reduce w klastrze usługi HDInsight Hadoop lub wykorzystanie programów Java, Scala lub Python w klastrze usługi HDInsight Spark.
Wprowadzanie komunikatów w czasie rzeczywistym. Jeśli rozwiązanie zawiera źródła danych czasu rzeczywistego, architektura musi obejmować sposób na przechwytywanie i przechowywanie komunikatów w czasie rzeczywistym do przetwarzania strumieniowego. Może to być zwykły magazyn danych, gdzie przychodzące komunikaty są umieszczane w folderze w celu przetworzenia. Jednak wiele rozwiązań wymaga, aby magazyn wprowadzający komunikaty pełnił rolę bufora dla komunikatów, a także oferował zwiększanie w poziomie skali przetwarzania, niezawodne dostarczanie i inne elementy semantyki kolejkowania komunikatów. Ta część architektury przesyłania strumieniowego jest często określana jako buforowanie strumienia. Opcje obejmują usługi Azure Event Hubs, Azure IoT Hub i Kafka.
Przetwarzanie strumienia. Po przechwyceniu komunikatów w czasie rzeczywistym rozwiązanie musi je przetworzyć, filtrując, agregując i przygotowując w inny sposób dane do analizy. Przetworzony strumień danych zostaje następnie zapisany do ujścia danych wyjściowych. Usługa Azure Stream Analytics to usługa zarządzanego przetwarzania strumienia w oparciu o stale działające zapytania SQL pracujące na niepowiązanych strumieniach. Możesz również użyć technologii przesyłania strumieniowego Apache typu open source, takich jak przesyłanie strumieniowe spark w klastrze usługi HDInsight.
Uczenie maszynowe. Odczytywanie przygotowanych danych do analizy (z przetwarzania wsadowego lub strumieniowego) algorytmy uczenia maszynowego mogą służyć do tworzenia modeli, które mogą przewidywać wyniki lub klasyfikować dane. Modele te można wytrenować na dużych zestawach danych, a wynikowe modele mogą służyć do analizowania nowych danych i tworzenia przewidywań. Można to zrobić przy użyciu usługi Azure Machine Edukacja
Magazyny danych analitycznych. Wiele rozwiązań do obsługi danych big data przygotowuje dane do analizy, a następnie przekazuje przetworzone dane w formacie ustrukturyzowanym, który może być odpytywany za pomocą narzędzi analitycznych. Magazynem danych analitycznych używanym do obsługi tych zapytań może być relacyjny magazyn danych w architekturze Kimballa, stosowany w tradycyjnych rozwiązaniach z zakresu analizy biznesowej (BI). Dane mogą być także przedstawiane za pomocą zapewniającej niskie opóźnienia technologii NoSQL, np. HBase, lub interakcyjnej bazy danych Hive zapewniającej abstrakcję metadanych nad plikami danych w rozproszonym magazynie danych. Usługa Azure Synapse Analytics oferuje zarządzaną usługę magazynowania danych na dużą skalę w oparciu o chmurę. Usługa HDInsight obsługuje interakcyjne klastry Hive, HBase i Spark SQL, które można także wykorzystać do obsługi danych do analizy.
Analiza i raportowanie. Celem większości rozwiązań typu big data jest udostępnienie szczegółowych informacji na temat danych przy użyciu analizy i raportowania. Aby dać użytkownikom możliwość analizowania danych, architektura może obejmować warstwę modelowania danych, np. wielowymiarowy moduł OLAP lub model danych tabelarycznych w usłudze Azure Analysis Services. Może również obsługiwać samoobsługową analizę biznesową, korzystając z technologii wizualizacji i modelowania w usłudze Microsoft Power BI lub Microsoft Excel. Analiza i raportowanie może również przyjmować formę interakcyjnej eksploracji danych przez analityków danych i naukowców pracujących z danymi. Pod kątem takich scenariuszy wiele usług platformy Azure obsługuje notesy analityczne, takie jak Jupyter, pozwalając użytkownikom na wykorzystanie posiadanych umiejętności z użyciem języka Python lub R. W przypadku eksploracji danych na dużą skalę można użyć platformy Microsoft R Server, samodzielnie lub wraz z platformą Spark.
Aranżacja. Większość rozwiązań typu big data składa się z powtarzanych operacji przetwarzania danych, zhermetyzowanych w ramach przepływów pracy, które przetwarzają dane źródłowe, przenoszą dane między różnymi źródłami i ujściami, ładują przetworzone dane do magazynu danych analitycznych lub wypychają wyniki bezpośrednio do raportu lub pulpitu nawigacyjnego. Aby zautomatyzować te przepływy pracy, można użyć technologii aranżacji, takich Azure Data Factory, Apache Oozie i Sqoop.
Architektura lambda
Podczas pracy z bardzo dużymi zestawami danych uruchomienie żądań potrzebnych klientom może zająć dużo czasu. Te zapytania nie mogą być wykonywane w czasie rzeczywistym i często wymagają algorytmów, takich jak MapReduce, które działają równolegle w ramach całego zestawu danych. Wyniki są następnie przechowywane oddzielnie od danych pierwotnych i używane do wykonywania zapytań.
Jedną z wad tego podejścia jest wprowadzenie opóźnienia — jeśli przetwarzanie trwa kilka godzin, zapytanie może zwrócić wyniki, które mają kilka godzin. Idealnym rozwiązaniem jest uzyskanie niektórych wyników w czasie rzeczywistym (być może z pewną utratą dokładności) i połączenie tych wyników z wynikami z analiz wsadowych.
Architektura lambda, która została po raz pierwszy zaproponowana przez Nathana Marza, rozwiązuje ten problem, tworząc dwie ścieżki przepływu danych. Wszystkie dane przesyłane do systemu przechodzą przez te dwie ścieżki:
W warstwie wsadowej (ścieżka nieaktywna) wszystkie dane przychodzące są przechowywane w postaci pierwotnej i wykonywane jest przetwarzanie wsadowe na danych. Wynik tego przetwarzania jest przechowywany jako widok wsadowy.
W warstwie szybkiej (ścieżka aktywna) ma miejsce analizowanie danych w czasie rzeczywistym. Ta warstwa jest przeznaczona na potrzeby małych opóźnień kosztem dokładności.
Warstwa wsadowa trafia do warstwy obsługi, w której indeksowany jest widok wsadowy na potrzeby efektywnego wykonywania zapytań. Warstwa szybka aktualizuje warstwę obsługi za pomocą aktualizacji przyrostowych opartych na najnowszych danych.
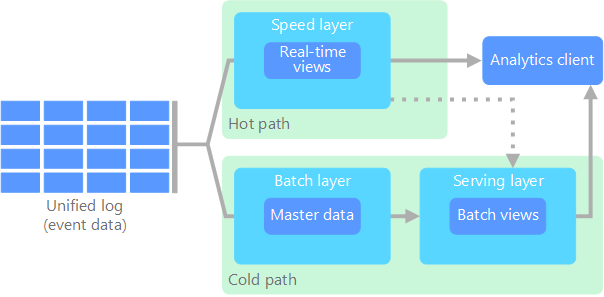
Dane trafiające do ścieżki aktywnej są ograniczane przez wymagania dotyczące opóźnień nakładane przez warstwę szybką, dzięki czemu mogą być przetwarzane tak szybko, jak to możliwe. Często wymaga to pewnej utraty dokładności na rzecz jak najszybszego uzyskania danych. Rozważmy na przykład scenariusz IoT, gdzie duża liczba czujników temperatury wysyła dane telemetryczne. Warstwa szybka może służyć do przetwarzania przesuwającego się okna czasowego danych przychodzących.
Dane trafiające do ścieżki nieaktywnej nie podlegają natomiast tym samym wymaganiom dotyczącym małych opóźnień. Pozwala to zapewnić wysoką dokładność obliczeń w ramach dużych zestawów danych, co może być bardzo czasochłonne.
Ostatecznie ścieżka aktywna i nieaktywna zbiegają się w aplikacji klienta do analizy. Jeśli klient wymaga wyświetlania aktualnych, ale potencjalnie mniej dokładnych danych w czasie rzeczywistym, pobierane będą wyniki ze ścieżki aktywnej. W przeciwnym razie wybrane zostaną wyniki ze ścieżki nieaktywnej w celu wyświetlenia mniej aktualnych, ale bardziej dokładnych danych. Innymi słowy, ścieżka aktywna zawiera dane dla stosunkowo małego okna czasowego, po czym wyniki mogą zostać zaktualizowane za pomocą dokładniejszych danych ze ścieżki nieaktywnej.
Nieprzetworzone dane przechowywane w warstwie wsadowej nie mogą być modyfikowane. Dane przychodzące są zawsze dodawane do istniejących danych, a wcześniej pozyskane dane nigdy nie są zastępowane. Wszelkie zmiany na wartość określonego elementu danych są przechowywane jako nowy rekord zdarzenia oznaczony sygnaturą czasową. Umożliwia to przeprowadzanie ponownego obliczania w dowolnym momencie w czasie w ramach historii zebranych danych. Możliwość ponownego obliczenia widoku wsadowego na podstawie oryginalnych danych pierwotnych jest ważna, ponieważ umożliwia tworzenie nowych widoków w miarę rozwoju systemu.
Architektura kappa
Wadą architektury lambda jest jej złożoność. Logika przetwarzania jest wyświetlana w dwóch różnych miejscach — zimnych i gorących ścieżkach — przy użyciu różnych struktur. Prowadzi to do duplikowania logiki obliczeń i złożoności zarządzania architektury dla obu ścieżek.
Architekturę kappa jako alternatywę do architektury lambda zaproponował Jay Kreps. Ma ona te same podstawowe cele, co architektura lambda, ale z jedną istotną różnicą: wszystkie dane przepływają przez pojedynczą ścieżkę przy użyciu systemu przetwarzania strumienia.

Istnieją pewne podobieństwa do warstwy wsadowej architektura lambda: dane zdarzeń są również niemodyfikowalne i wszystkie są zbierane (w przeciwieństwie do podzbioru). Dane są pozyskiwane jako strumień zdarzeń do rozproszonego i odpornego na błędy ujednoliconego dziennika. Te zdarzenia są uporządkowane i ich bieżący stan jest zmieniany tylko przez dołączanie nowego zdarzenia. Podobnie jak w przypadku warstwy szybkiej architektury lambda wszystkie operacje przetwarzania zdarzeń są wykonywane względem strumienia wejściowego i utrwalane jako widok w czasie rzeczywistym.
Jeśli chcesz ponownie obliczyć cały zestaw danych (co jest równoznaczne z warstwą wsadową w architekturze lambda), wystarczy po prostu odtworzyć strumień, zwykle korzystając z równoległości do przeprowadzania obliczeń w odpowiednim czasie.
Internet rzeczy (IoT)
Z praktycznego punktu widzenia Internet rzeczy (IoT) reprezentuje dowolne urządzenie połączone z Internetem. Obejmuje to Twój komputer, telefon komórkowy, inteligentne zegarki, inteligentne termostaty, inteligentne lodówki, połączone samochody, implanty służące do monitorowania pracy serca i dowolne inne urządzenia łączące się z Internetem oraz wysyłające lub odbierające dane. Liczba połączonych urządzeń rośnie z dnia na dzień, a wraz z nią ilość danych zbieranych przez te urządzenia. Często dane są zbierane w środowiskach bardzo ograniczonych, czasami z dużym opóźnieniem. W innych przypadkach dane są wysyłane ze środowisk z niskimi opóźnieniami przez tysiące lub miliony urządzeń, co wymaga możliwości szybkiego pozyskiwania danych i ich odpowiedniego przetwarzania. W związku z tym do obsługi tych ograniczeń i unikalnych wymagań konieczne jest odpowiednie planowanie.
Architektury sterowane zdarzeniami są kluczowym elementem rozwiązań IoT. Na poniższym diagramie przedstawiono przykładową architekturę logiczną dla IoT. Diagram kładzie nacisk na składniki strumienia zdarzeń architektury.

Brama w chmurze pozyskuje zdarzenia urządzenia na granicy chmury, używając niezawodnego systemu obsługi komunikatów o niskich opóźnieniach.
Urządzenia mogą wysyłać zdarzenia bezpośrednio do bramy w chmurze lub za pośrednictwem bramy działającej w terenie. Brama działająca w terenie to wyspecjalizowane urządzenie lub oprogramowanie, zwykle kolokowane z urządzeniami, które odbiera zdarzenia i przekazuje je do bramy w chmurze. Brama działająca w terenie może również wstępnie przetwarzać nieprzetworzone zdarzenia urządzenia, wykonując takie funkcje jak filtrowanie, agregacja lub przekształcanie protokołu.
Po pozyskaniu zdarzenia przechodzą przez co najmniej jeden procesor strumieni, który może kierować dane (na przykład do magazynu) lub wykonywać analizy i inne procesy.
Poniżej przedstawiono niektóre typowe typy przetwarzania. (Ta lista na pewno nie jest wyczerpująca).
Zapisywanie danych zdarzeń do zimnego magazynu w celu zarchiwizowania lub przeprowadzenia analizy partii.
Analiza ścieżki aktywnej badająca strumień zdarzeń (prawie) w czasie rzeczywistym w celu wykrycia anomalii, rozpoznania wzorców na przestrzeni przedziałów czasu lub wyzwolenia alertów po wystąpieniu w strumieniu określonego warunku.
Obsługa specjalnych typów komunikatów nietelemetrycznych z urządzeń, takich jak powiadomienia i alarmy.
Uczenie maszynowe.
W wyszarzonych polach przedstawiono składniki systemu IoT, które nie są bezpośrednio związane z przesyłaniem strumieniowym zdarzeń, ale zostały uwzględnione, aby informacje były kompletne.
Rejestr urządzenia to baza danych aprowizowanych urządzeń, w tym identyfikatorów urządzeń i zwykle metadanych urządzeń, takich jak lokalizacja.
Aprowizujący interfejs API to wspólny interfejs zewnętrzny aprowizujący i rejestrujący nowe urządzenia.
Niektóre rozwiązania IoT umożliwiają wysyłanie komunikatów poleceń i komunikatów sterujących do urządzeń.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Główny autor:
- Zoiner Tejada | Dyrektor generalny i architekt
Następne kroki
Zapoznaj się z następującymi odpowiednimi usługami platformy Azure: