W tym artykule opisano architekturę, która używa usługi Azure Machine Edukacja do przewidywania delinquency i domyślnych prawdopodobieństwa wnioskodawców pożyczki. Przewidywania modelu są oparte na zachowaniu fiskalnym wnioskodawcy. Model używa ogromnego zestawu punktów danych do klasyfikowania wnioskodawców i zapewniania wyniku kwalifikowalności dla każdego wnioskodawcy.
Apache®, Spark i logo płomienia są zastrzeżonymi znakami towarowymi lub znakami towarowymi fundacji Apache Software Foundation w Stany Zjednoczone i/lub innych krajach. Użycie tych znaków nie jest dorozumiane przez fundację Apache Software Foundation.
Architektura

Pobierz plik programu Visio z tą architekturą.
Przepływ danych
Poniższy przepływ danych odpowiada powyższemu diagramowi:
Magazyn: dane są przechowywane w bazie danych, takiej jak pula usługi Azure Synapse Analytics, jeśli jest ona ustrukturyzowana. Starsze bazy danych SQL można zintegrować z systemem. Dane częściowo ustrukturyzowane i nieustrukturyzowane można załadować do usługi Data Lake.
Pozyskiwanie i wstępne przetwarzanie: potoki przetwarzania usługi Azure Synapse Analytics i przetwarzanie ETL mogą łączyć się z danymi przechowywanymi na platformie Azure lub źródłach innych firm za pośrednictwem wbudowanych łączników. Usługa Azure Synapse Analytics obsługuje wiele metodologii analizy korzystających z usług SQL, Spark, Azure Data Explorer i Power BI. Możesz również użyć istniejącej aranżacji usługi Azure Data Factory dla potoków danych.
Przetwarzanie: usługa Azure Machine Edukacja służy do tworzenia modeli uczenia maszynowego i zarządzania nimi.
Przetwarzanie początkowe: na tym etapie nieprzetworzone dane są przetwarzane w celu utworzenia wyselekcjonowanych zestawów danych, które wytrenują model uczenia maszynowego. Typowe operacje obejmują formatowanie typów danych, imputację brakujących wartości, inżynierię cech, wybór cech i zmniejszenie wymiarowości.
Szkolenie: na etapie trenowania usługa Azure Machine Edukacja używa przetworzonego zestawu danych do trenowania modelu ryzyka kredytowego i wybierania najlepszego modelu.
Trenowanie modelu: można używać wielu modeli uczenia maszynowego, w tym klasycznych modeli uczenia maszynowego i uczenia głębokiego. Do optymalizacji wydajności modelu można użyć dostrajania hiperparametrów.
Ocena modelu: usługa Azure Machine Edukacja ocenia wydajność każdego wytrenowanego modelu, dzięki czemu można wybrać najlepszy model do wdrożenia.
Rejestracja modelu: rejestrujesz model, który działa najlepiej w usłudze Azure Machine Edukacja. Ten krok udostępnia model do wdrożenia.
c. Odpowiedzialne używanie sztucznej inteligencji: Odpowiedzialne używanie sztucznej inteligencji to podejście do opracowywania, oceniania i wdrażania systemów sztucznej inteligencji w bezpieczny, godny zaufania i etyczny sposób. Ponieważ ten model wywnioskuje zatwierdzenie lub decyzję o odmowie żądania pożyczki, musisz zaimplementować zasady odpowiedzialnej sztucznej inteligencji.
Metryki sprawiedliwości oceniają wpływ nieuczciwego zachowania i umożliwiają strategie ograniczania ryzyka. Poufne funkcje i atrybuty są identyfikowane w zestawie danych i kohortach (podzestawach) danych. Aby uzyskać więcej informacji, zobacz Wydajność i sprawiedliwość modelu.
Możliwość interpretacji to miara tego, jak dobrze można zrozumieć zachowanie modelu uczenia maszynowego. Ten składnik odpowiedzialnej sztucznej inteligencji generuje zrozumiałe dla człowieka opisy przewidywań modelu. Aby uzyskać więcej informacji, zobacz Interpretacja modelu.
Wdrażanie uczenia maszynowego w czasie rzeczywistym: należy użyć wnioskowania modelu w czasie rzeczywistym, gdy żądanie musi zostać natychmiast przejrzene w celu zatwierdzenia.
- Zarządzany punkt końcowy online uczenia maszynowego. W przypadku oceniania w czasie rzeczywistym należy wybrać odpowiedni docelowy obiekt obliczeniowy.
- Żądania online dotyczące pożyczek korzystają z oceniania w czasie rzeczywistym na podstawie danych wejściowych od formularza wnioskodawcy lub wniosku o pożyczkę.
- Decyzja i dane wejściowe używane do oceniania modelu są przechowywane w magazynie trwałym i można je pobrać na potrzeby przyszłego odwołania.
Wdrażanie uczenia maszynowego w usłudze Batch: w przypadku przetwarzania pożyczek w trybie offline model jest uruchamiany w regularnych odstępach czasu.
- Zarządzany punkt końcowy partii. Wnioskowanie wsadowe jest zaplanowane i tworzony jest zestaw danych wyników. Decyzje opierają się na zdolnościach wnioskodawcy.
- Zestaw wyników oceniania z przetwarzania wsadowego jest utrwalany w bazie danych lub magazynie danych usługi Azure Synapse Analytics.
Interfejs do danych dotyczących aktywności wnioskodawcy: dane wejściowe przez wnioskodawcę, wewnętrzny profil kredytowy i decyzja modelu są przygotowane i przechowywane w odpowiednich usługach danych. Te szczegóły są używane w akarcie decyzyjnym na potrzeby przyszłego oceniania, więc są one udokumentowane.
- Magazyn: wszystkie szczegóły przetwarzania środków są przechowywane w magazynie trwałym.
- Interfejs użytkownika: decyzja o zatwierdzeniu lub odmów jest przedstawiana wnioskodawcy.
Raportowanie: szczegółowe informacje w czasie rzeczywistym dotyczące liczby przetworzonych i zatwierdzanych lub odrzucanych wyników są stale prezentowane menedżerom i kierownictwu. Przykłady raportowania obejmują raporty niemal w czasie rzeczywistym dotyczące zatwierdzonych kwot, utworzonego portfela pożyczki i wydajności modelu.
Składniki
- Usługa Azure Blob Storage zapewnia skalowalny magazyn obiektów dla danych bez struktury. Jest zoptymalizowany pod kątem przechowywania plików, takich jak pliki binarne, dzienniki aktywności i pliki, które nie są zgodne z określonym formatem.
- Usługa Azure Data Lake Storage jest podstawą magazynu do tworzenia ekonomicznych magazynów typu data lake na platformie Azure. Zapewnia magazyn obiektów blob z hierarchiczną strukturą folderów oraz zwiększoną wydajnością, zarządzaniem i zabezpieczeniami. Obsługuje wiele petabajtów informacji przy jednoczesnym utrzymaniu setek gigabitów przepływności.
- Azure Synapse Analytics to usługa analityczna, która łączy najlepsze technologie SQL i Spark oraz ujednolicone środowisko użytkownika dla usługi Azure Synapse Data Explorer i potoków. Integruje się z usługami Power BI, Azure Cosmos DB i Azure Machine Edukacja. Usługa obsługuje modele zasobów dedykowanych i bezserwerowych oraz możliwość przełączania się między tymi modelami.
- Usługa Azure SQL Database to zawsze aktualna, w pełni zarządzana relacyjna baza danych utworzona dla chmury.
- Azure Machine Edukacja to usługa w chmurze do zarządzania cyklami życia projektu uczenia maszynowego. Zapewnia zintegrowane środowisko do eksploracji danych, tworzenia modeli i zarządzania nimi oraz wdrażania oraz obsługuje podejścia do uczenia maszynowego oparte na kodzie i małym kodzie/bez kodu.
- Power BI to narzędzie do wizualizacji, które zapewnia łatwą integrację z zasobami platformy Azure.
- usługa aplikacja systemu Azure umożliwia tworzenie i hostowanie aplikacji internetowych, zapleczy mobilnych i interfejsów API RESTful bez zarządzania infrastrukturą. Obsługiwane języki to .NET, .NET Core, Java, Ruby, Node.js, PHP i Python.
Alternatywy
Usługa Azure Databricksumożliwia tworzenie i wdrażanie modeli uczenia maszynowego oraz obciążeń analitycznych oraz zarządzanie nimi. Usługa zapewnia ujednolicone środowisko do tworzenia modeli.
Szczegóły scenariusza
Organizacje w branży finansowej muszą przewidzieć ryzyko kredytowe osób fizycznych lub firm, które żądają kredytu. Ten model ocenia delinquency i domyślne prawdopodobieństwa wnioskodawców pożyczki.
Przewidywanie ryzyka kredytowego obejmuje głęboką analizę zachowania populacji i klasyfikację bazy klientów w segmentach na podstawie odpowiedzialności fiskalnej. Inne zmienne obejmują czynniki rynkowe i warunki ekonomiczne, które mają znaczący wpływ na wyniki.
Wyzwania. Dane wejściowe obejmują dziesiątki milionów profilów klientów i dane dotyczące zachowania kredytowego klientów i nawyków wydatków opartych na miliardach rekordów z różnych systemów, takich jak wewnętrzne systemy aktywności klientów. Dane innych firm dotyczące warunków ekonomicznych i analizy rynku kraju/regionu mogą pochodzić z miesięcznych lub kwartalnych migawek, które wymagają ładowania i konserwacji setek gb plików. Potrzebne są informacje biura kredytowego dotyczące wnioskodawcy lub częściowo ustrukturyzowanych wierszy danych klienta oraz sprzężenia krzyżowe między tymi zestawami danych i kontroli jakości w celu zweryfikowania integralności danych.
Dane zwykle składają się z szerokiej kolumny informacji o klientach z biur kredytowych wraz z analizą rynku. Działanie klienta składa się z rekordów z układem dynamicznym, który może nie być ustrukturyzowany. Dane są również dostępne w postaci wolnego tekstu z notatek obsługi klienta i formularzy interakcji wnioskodawcy.
Przetwarzanie tych dużych ilości danych i zapewnienie, że wyniki są aktualne, wymaga usprawnionego przetwarzania. Potrzebujesz magazynu o małych opóźnieniach i procesu pobierania. Infrastruktura danych powinna mieć możliwość skalowania w celu obsługi różnych źródeł danych i zapewnienia możliwości zarządzania i zabezpieczania obwodu danych. Platforma uczenia maszynowego musi obsługiwać złożoną analizę wielu modeli, które są trenowane, testowane i weryfikowane w wielu segmentach populacji.
Poufność i prywatność danych. Przetwarzanie danych dla tego modelu obejmuje dane osobowe i szczegóły demograficzne. Należy unikać profilowania populacji. Bezpośredni wgląd we wszystkie dane osobowe musi być ograniczony. Przykładami danych osobowych są numery kont, szczegóły karty kredytowej, numery ubezpieczenia społecznego, nazwiska, adresy i kody pocztowe.
Karty kredytowe i numery kont bankowych muszą być zawsze zaciemnione. Niektóre elementy danych muszą być maskowane i zawsze szyfrowane, nie zapewniając dostępu do podstawowych informacji, ale dostępne do analizy.
Dane muszą być szyfrowane w spoczynku, podczas przesyłania i podczas przetwarzania za pośrednictwem bezpiecznych enklaw. Dostęp do elementów danych jest rejestrowany w rozwiązaniu do monitorowania. System produkcyjny należy skonfigurować przy użyciu odpowiednich potoków ciągłej integracji/ciągłego wdrażania z zatwierdzeniami wyzwalanymi wdrożeniami i procesami modelu. Inspekcja dzienników i przepływu pracy powinna zapewnić interakcje z danymi dla wszelkich potrzeb dotyczących zgodności.
Przetwarzanie. Ten model wymaga dużej mocy obliczeniowej na potrzeby analizy, kontekstualizacji oraz trenowania i wdrażania modelu. Ocena modelu jest weryfikowana względem losowych próbek, aby upewnić się, że decyzje kredytowe nie obejmują żadnej rasy, płci, pochodzenia etnicznego lub stronniczość lokalizacji geograficznej. Model decyzyjny musi być udokumentowany i zarchiwizowany na potrzeby przyszłego dokumentacji. Każdy czynnik biorący udział w wynikach decyzyjnych jest przechowywany.
Przetwarzanie danych wymaga wysokiego użycia procesora CPU. Obejmuje ona przetwarzanie SQL danych ustrukturyzowanych w formacie DB i JSON, przetwarzanie platformy Spark ramek danych lub analizę danych big data na terabajtach informacji w różnych formatach dokumentów. Zadania ELT/ETL danych są zaplanowane lub wyzwalane w regularnych odstępach czasu lub w czasie rzeczywistym, w zależności od wartości najnowszych danych.
Zgodność i ramy regulacyjne. Każdy szczegół przetwarzania pożyczek musi być udokumentowany, w tym przesłana aplikacja, funkcje używane w ocenianiu modelu i zestaw wyników modelu. Informacje o trenowaniu modelu, dane używane do trenowania i wyniki trenowania powinny być rejestrowane w celu uzyskania przyszłych żądań referencyjnych i inspekcji i zgodności.
Wsadowe a ocenianie w czasie rzeczywistym. Niektóre zadania są aktywne i mogą być przetwarzane jako zadania wsadowe, takie jak wstępnie zatwierdzone transfery sald. Niektóre żądania, takie jak wzrost linii kredytowej online, wymagają zatwierdzenia w czasie rzeczywistym.
Dostęp w czasie rzeczywistym do stanu wniosków o pożyczkę online musi być dostępny dla wnioskodawcy. Instytucja finansowa wystawiająca pożyczki stale monitoruje wyniki modelu kredytowego i potrzebuje wglądu w metryki, takie jak stan zatwierdzenia pożyczki, liczba zatwierdzonych pożyczek, kwoty wydane w dolarach i jakość nowych pochodzących z pożyczek.
Odpowiedzialne AI
Pulpit nawigacyjny Odpowiedzialne używanie sztucznej inteligencji udostępnia jeden interfejs dla wielu narzędzi, które mogą ułatwić implementowanie odpowiedzialnej sztucznej inteligencji. Standard Odpowiedzialnej sztucznej inteligencji jest oparty na sześciu zasadach:
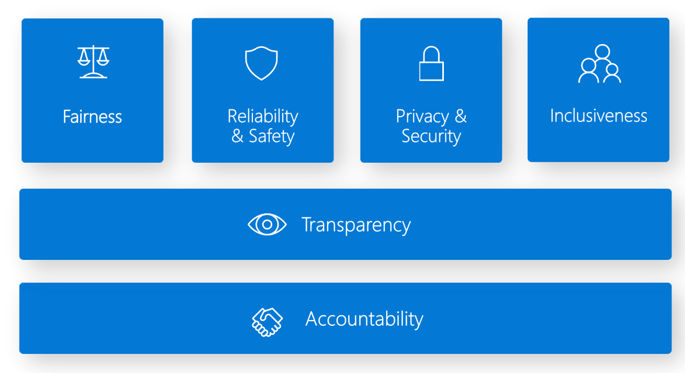
Sprawiedliwość i inkluzywność w usłudze Azure Machine Edukacja. Ten składnik pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji pomaga ocenić niesprawiedliwe zachowania, unikając szkód w alokacji i szkodach dotyczących jakości usług. Można jej użyć do oceny sprawiedliwości między poufnymi grupami zdefiniowanymi pod względem płci, wieku, pochodzenia etnicznego i innych cech. Podczas oceny sprawiedliwość jest kwantyfikowana za pośrednictwem metryk różnic. Algorytmy ograniczania ryzyka należy zaimplementować w pakiecie open source Fairlearn , które używają ograniczeń parzystości.
Niezawodność i bezpieczeństwo w usłudze Azure Machine Edukacja. Składnik analizy błędów odpowiedzialnej sztucznej inteligencji może pomóc:
- Dowiedz się, jak awaria jest dystrybuowana dla modelu.
- Zidentyfikuj kohorty danych, które mają wyższy współczynnik błędów niż ogólny test porównawczy.
Przezroczystość w usłudze Azure Machine Edukacja. Kluczową częścią przejrzystości jest zrozumienie, w jaki sposób funkcje wpływają na model uczenia maszynowego.
- Możliwość interpretacji modelu pomaga zrozumieć, co wpływa na zachowanie modelu. Generuje zrozumiałe dla człowieka opisy przewidywań modelu. To zrozumienie pomaga zagwarantować, że możesz ufać modelowi i pomóc w debugowanie i ulepszanie go. InterpretML może pomóc zrozumieć strukturę modeli szklanych lub relacji między funkcjami w modelach głębokiej sieci neuronowej w czarnych skrzynkach.
- Kontraktualne analizy co-jeżeli mogą pomóc zrozumieć i debugować model uczenia maszynowego pod względem sposobu reagowania na zmiany funkcji i perturbacje.
Prywatność i zabezpieczenia w usłudze Azure Machine Edukacja. Administratorzy uczenia maszynowego muszą utworzyć bezpieczną konfigurację do tworzenia modeli i zarządzania nimi. Funkcje zabezpieczeń i ładu mogą pomóc w przestrzeganiu zasad zabezpieczeń organizacji. Inne narzędzia mogą pomóc w ocenie i zabezpieczeniu modeli.
Odpowiedzialność w usłudze Azure Machine Edukacja. Operacje uczenia maszynowego (MLOps) są oparte na zasadach i praktykach metodyki DevOps, które zwiększają wydajność przepływów pracy sztucznej inteligencji. Usługa Azure Machine Edukacja może pomóc w zaimplementowaniu możliwości metodyki MLOps:
- Rejestrowanie, pakowanie i wdrażanie modeli
- Uzyskiwanie powiadomień i alertów dotyczących zmian w modelach
- Przechwytywanie danych ładu dla kompleksowego cyklu życia
- Monitorowanie aplikacji pod kątem problemów operacyjnych
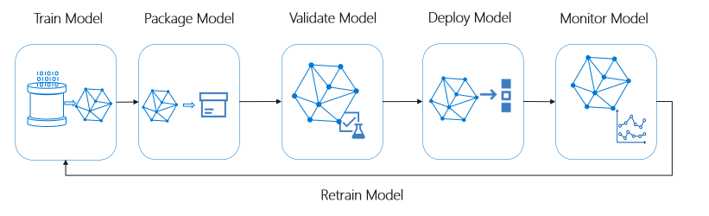
Na tym diagramie przedstawiono możliwości metodyki MLOps usługi Azure Machine Edukacja:
Potencjalne przypadki użycia
To rozwiązanie można zastosować do następujących scenariuszy:
- Finanse: uzyskaj analizę finansową klientów lub analizę międzysprzedażową klientów na potrzeby ukierunkowanych kampanii marketingowych.
- Opieka zdrowotna: użyj informacji o pacjentach jako danych wejściowych, aby zasugerować oferty leczenia.
- Gościnność: Utwórz profil klienta, aby zasugerować oferty dla hoteli, lotów, pakietów wycieczkowych i członkostwa.
Kwestie wymagające rozważenia
Te zagadnienia implementują filary platformy Azure Well-Architected Framework, która jest zestawem wytycznych, których można użyć do poprawy jakości obciążenia. Aby uzyskać więcej informacji, zobacz Microsoft Azure Well-Architected Framework.
Zabezpieczenia
Zabezpieczenia zapewniają ochronę przed celowymi atakami i nadużyciami cennych danych i systemów. Aby uzyskać więcej informacji, zobacz Omówienie filaru zabezpieczeń.
Rozwiązania platformy Azure zapewniają ochronę w głębi systemu i podejście zero trust.
Rozważ zaimplementowanie następujących funkcji zabezpieczeń w tej architekturze:
- Wdrażanie dedykowanych usług platformy Azure w sieciach wirtualnych
- Możliwości zabezpieczeń usługi Azure SQL Database
- Zabezpieczanie poświadczeń w fabryce danych przy użyciu usługi Key Vault
- Zabezpieczenia przedsiębiorstwa i ład dla usługi Azure Machine Learning
- Punkt odniesienia zabezpieczeń platformy Azure dla obszaru roboczego usługi Synapse Analytics
Optymalizacja kosztów
Optymalizacja kosztów polega na zmniejszeniu niepotrzebnych wydatków i poprawie wydajności operacyjnej. Aby uzyskać więcej informacji, zobacz Omówienie filaru optymalizacji kosztów.
Aby oszacować koszt implementacji tego rozwiązania, użyj kalkulatora cen platformy Azure.
Należy również wziąć pod uwagę następujące zasoby:
- Planowanie kosztów i zarządzanie nimi dla usługi Azure Synapse Analytics
- Planowanie kosztów usługi Azure Machine Edukacja i zarządzanie nimi
Doskonałość operacyjna
Doskonałość operacyjna obejmuje procesy operacyjne, które wdrażają aplikację i działają w środowisku produkcyjnym. Aby uzyskać więcej informacji, zobacz Omówienie filaru doskonałości operacyjnej.
Rozwiązania uczenia maszynowego muszą być skalowalne i ustandaryzowane w celu łatwiejszego zarządzania i konserwacji. Upewnij się, że rozwiązanie obsługuje ciągłe wnioskowanie przy użyciu cykli ponownego trenowania i automatycznego ponownego wdrażania modeli.
Aby uzyskać więcej informacji, zobacz Akcelerator rozwiązań usługi Azure MLOps (wersja 2).
Efektywność wydajności
Efektywność wydajności to możliwość skalowania obciążenia w celu zaspokojenia zapotrzebowania użytkowników w wydajny sposób. Aby uzyskać więcej informacji, zobacz Omówienie filaru wydajności.
- Aby uzyskać więcej informacji na temat projektowania skalowalnych rozwiązań, zobacz Lista kontrolna wydajności.
- Aby uzyskać informacje o regulowanych branżach, zobacz Scale AI and machine learning initiatives in regulated industries (Skalowanie sztucznej inteligencji i uczenia maszynowego w branżach regulowanych).
- Zarządzanie środowiskiem usługi Azure Synapse Analytics przy użyciu pul SQL, Spark lub bezserwerowych pul SQL .
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Główny autor:
- Charitha Basani | Starszy architekt rozwiązań w chmurze
Inny współautor:
- Mick Alberts | Składnik zapisywania technicznego
Aby wyświetlić niepubalne profile serwisu LinkedIn, zaloguj się do serwisu LinkedIn.
Następne kroki
- Plan bazowy zabezpieczeń platformy Azure dla usługi Azure Machine Learning
- Azure Synapse Analytics
- Wdrażanie modeli uczenia maszynowego na platformie Azure
- Co to jest odpowiedzialna sztuczna inteligencja?