Koordynuj akcje wykonywane przez kolekcję współpracujących wystąpień w aplikacji rozproszonej poprzez wybranie jednego wystąpienia jako lidera, który przyjmuje odpowiedzialność za zarządzanie innymi wystąpieniami. Pomaga to zapewnić, że wystąpienia nie powodują między sobą konfliktów, nie rywalizują o współdzielone zasoby ani nie zakłócają pracy innych wystąpień.
Kontekst i problem
Typowa aplikacja w chmurze ma wiele zadań działających w sposób skoordynowany. Wszystkie te zadania mogą być wystąpieniami uruchamiającymi ten sam kod i wymagać dostępu do tych samych zasobów lub mogą działać wspólnie w sposób równoległy i wykonywać poszczególne części skomplikowanego obliczenia.
Wystąpienia zadań mogą działać oddzielnie przez większą część czasu, ale może być również konieczne koordynowanie akcji każdego wystąpienia w celu zapewnienia, że nie powodują konfliktów, powodują rywalizację o udostępnione zasoby lub przypadkowo zakłócają pracę wykonywanej przez inne wystąpienia zadań.
Na przykład:
- W systemie opartym na chmurze implementującym skalowanie w poziomie wiele wystąpień tego samego zadania może działać w tym samym czasie i obsługiwać różnych użytkowników. Jeśli te wystąpienia zapisują dane we współdzielonym zasobie, konieczne jest skoordynowanie ich akcji, aby uniemożliwić każdemu wystąpieniu zastępowanie zmian wprowadzonych przez inne wystąpienia.
- Jeśli te zadania wykonują poszczególne elementy skomplikowanego obliczenia w sposób równoległy, po ich ukończeniu wyniki należy zagregować.
Wszystkie wystąpienia zadań są elementami równorzędnymi, a zatem nie ma wśród nich naturalnego lidera, który mógłby pełnić rolę koordynatora lub agregatora.
Rozwiązanie
Należy wybrać pojedyncze wystąpienie zadania, które będzie pełnić rolę lidera. Wystąpienie to powinno koordynować akcje pozostałych podrzędnych wystąpień zadań. Jeśli wszystkie wystąpienia zadań uruchamiają ten sam kod, każde z nich może zostać liderem. W związku z tym proces wyborów musi być starannie zarządzany, aby zapobiec jednoczesnemu przejęciu co najmniej dwóch wystąpień na stanowisku lidera.
System musi zapewnić niezawodny mechanizm wybierania lidera. Ta metoda musi sobie radzić z wydarzeniami takimi jak awarie sieci czy błędy procesów. W przypadku wielu rozwiązań podrzędne wystąpienia zadań monitorują lidera za pośrednictwem jakiegoś typu metody pulsu lub za pomocą sondowania. Jeśli wyznaczony lider nieoczekiwanie zakończy działanie lub jeśli stanie się niedostępny dla wystąpień podrzędnych z powodu awarii sieci, wystąpienia podrzędne będą musiały wybrać nowego lidera.
Istnieje kilka strategii wybierania lidera spośród zestawu zadań w środowisku rozproszonym, na przykład:
- Wybranie wystąpienia zadania z identyfikatorem wystąpienia lub procesu o najniższej randze.
- Wyścig o uzyskanie współdzielonego, rozproszonego elementu mutex. Pierwsze wystąpienie zadania, które uzyska element mutex, zostaje liderem. System musi jednak zapewnić, że w razie zakończenia działania lidera lub jego odłączenia od reszty systemu element mutex zostanie zwolniony, a liderem będzie mogło zostać inne wystąpienie.
- Zaimplementowanie jednego z typowych algorytmów wybierania lidera, na przykład algorytmu tyrana czy algorytmu pierścieniowego. Te algorytmy zakładają, że każdy kandydat na lidera ma unikatowy identyfikator i może niezawodnie komunikować się z innymi kandydatami.
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
- Proces wybierania lidera powinien być odporny na błędy przejściowe i trwałe.
- Musi być możliwe wykrycie awarii lidera lub jego niedostępności (np. z powodu awarii komunikacji). To, jak szybkie powinno być wykrywanie, zależy od systemu. Niektóre systemy mogą być w stanie funkcjonować przez krótki czas bez lidera i podczas tego okresu możliwe będzie naprawienie błędu przejściowego. W innych przypadkach może być konieczne natychmiastowe wykrycie błędu lidera i wyzwolenie nowego wyboru.
- W systemie implementującym skalowanie automatyczne w poziomie działanie lidera może zostać zakończone, gdy system przeprowadzi skalowanie w dół i wyłączy niektóre zasoby obliczeniowe.
- Używanie współdzielonego, rozproszonego elementu mutex wprowadza zależność od usługi zewnętrznej udostępniającej element mutex. Usługa ta stanowi pojedynczy punkt awarii. Jeśli stanie się niedostępna z jakiejkolwiek przyczyny, system nie będzie mógł wybrać lidera.
- Używanie pojedynczego dedykowanego procesu jako lidera jest prostym rozwiązaniem. Jednak jeśli proces ten ulegnie awarii, może wystąpić znaczne opóźnienie do momentu jego ponownego uruchomienia. Wynikłe opóźnienie może mieć wpływ na wydajność i czasy odpowiedzi innych procesów, jeśli oczekują one na skoordynowanie akcji przez lidera.
- Ręczne zaimplementowanie jednego z algorytmów wyboru lidera zapewnia największą elastyczność dostosowywania i optymalizowania kodu.
- Unikaj sytuacji, w których lider stanowi wąskie gardło w systemie. Celem lidera jest koordynowanie pracy podrzędnych zadań i nie musi uczestniczyć w tej pracy — chociaż powinno być w stanie to zrobić, jeśli zadanie nie zostanie wybrane jako lider.
Kiedy używać tego wzorca
Użyj tego wzorca, gdy zadania w aplikacji rozproszonej, takiej jak rozwiązanie hostowane w chmurze, wymagają dokładnej koordynacji i nie mają naturalnego lidera.
Ten wzorzec może nie być przydatny w następujących sytuacjach:
- Istnieje naturalny lider lub dedykowany proces, który zawsze może pełnić rolę lidera. Na przykład może być możliwe zaimplementowanie pojedynczego procesu koordynującego wystąpienia zadań. Jeśli ten proces ulegnie awarii lub jego kondycja się pogorszy, system może go zamknąć i uruchomić ponownie.
- Koordynację między zadaniami można osiągnąć przy użyciu prostszej metody. Jeśli na przykład kilka wystąpień zadań potrzebuje jedynie skoordynowanego dostępu do współdzielonego zasobu, lepszym rozwiązaniem będzie kontrolowanie dostępu za pomocą optymistycznego lub pesymistycznego blokowania.
- Bardziej odpowiednie będzie rozwiązanie innej firmy. Na przykład usługa Microsoft Azure HDInsight (oparta na usłudze Apache Hadoop) za pomocą usług udostępnionych przez usługę Apache Zookeeper koordynuje zadania mapowania i redukcji zbierające oraz podsumowujące dane.
Projekt obciążenia
Architekt powinien ocenić, w jaki sposób wzorzec wyboru lidera może być używany w projekcie obciążenia, aby sprostać celom i zasadom opisanym w filarach platformy Azure Well-Architected Framework. Na przykład:
| Filar | Jak ten wzorzec obsługuje cele filaru |
|---|---|
| Decyzje projektowe dotyczące niezawodności pomagają obciążeniu stać się odporne na awarię i zapewnić, że zostanie przywrócony do w pełni funkcjonalnego stanu po wystąpieniu awarii. | Ten wzorzec zmniejsza wpływ awarii węzła przez niezawodne przekierowywanie pracy. Implementuje również tryb failover za pośrednictwem algorytmów konsensusu w przypadku awarii lidera. - Nadmiarowość RE:05 - RE:07 Samonaprawiania |
Podobnie jak w przypadku każdej decyzji projektowej, należy rozważyć wszelkie kompromisy w stosunku do celów innych filarów, które mogą zostać wprowadzone przy użyciu tego wzorca.
Przykład
W przykładzie Leader Election w witrynie GitHub pokazano, jak używać dzierżawy obiektu blob usługi Azure Storage w celu zapewnienia mechanizmu implementowania udostępnionego, rozproszonego mutexu. Ten mutex może służyć do wybierania lidera wśród grupy dostępnych wystąpień procesów roboczych. Pierwsze wystąpienie do uzyskania dzierżawy jest wybierane jako lider i pozostaje liderem, dopóki dzierżawa nie zostanie zwolniona lub nie będzie mogła odnowić dzierżawy. Inne wystąpienia procesów roboczych mogą nadal monitorować dzierżawę obiektu blob, jeśli lider nie jest już dostępny.
Dzierżawa obiektu blob jest wyłączną blokadą zapisu obiektu blob. W danym momencie pojedynczy obiekt blob może być przedmiotem tylko jednej dzierżawy. Wystąpienie procesu roboczego może zażądać dzierżawy określonego obiektu blob i zostanie przyznane dzierżawie, jeśli żadne inne wystąpienie procesu roboczego nie posiada dzierżawy tego samego obiektu blob. W przeciwnym razie żądanie zgłosi wyjątek.
Aby uniknąć błędnego wystąpienia lidera, które zachowuje dzierżawę na czas nieokreślony, określ okres istnienia dzierżawy. Po jego wygaśnięciu dzierżawa stanie się dostępna. Jednak gdy wystąpienie przechowuje dzierżawę, może zażądać odnowienia dzierżawy, a dzierżawa zostanie udzielona przez kolejny okres. Wystąpienie lidera może stale powtarzać ten proces, jeśli chce zachować dzierżawę. Aby uzyskać więcej informacji na temat dzierżawienia obiektu blob, zobacz Dzierżawienie obiektu blob (interfejs API REST).
Klasa BlobDistributedMutex w poniższym przykładzie w języku C# zawiera RunTaskWhenMutexAcquired metodę, która umożliwia wystąpieniu procesu roboczego podjęcie próby uzyskania dzierżawy dla określonego obiektu blob. Szczegóły obiektu blob (nazwa, kontener i konto magazynu) są przekazywane do konstruktora w obiekcie BlobSettings po utworzeniu obiektu BlobDistributedMutex (ten obiekt jest prostą strukturą zawartą w przykładowym kodzie). Konstruktor akceptuje również element Task , który odwołuje się do kodu, który powinien zostać uruchomiony przez wystąpienie procesu roboczego, jeśli pomyślnie uzyska dzierżawę obiektu blob i zostanie wybrany liderem. Pamiętaj, że kod, który obsługuje niskopoziomowe szczegóły uzyskiwania dzierżawy, jest implementowany w osobnej klasie pomocy o nazwie BlobLeaseManager.
public class BlobDistributedMutex
{
...
private readonly BlobSettings blobSettings;
private readonly Func<CancellationToken, Task> taskToRunWhenLeaseAcquired;
...
public BlobDistributedMutex(BlobSettings blobSettings,
Func<CancellationToken, Task> taskToRunWhenLeaseAcquired, ... )
{
this.blobSettings = blobSettings;
this.taskToRunWhenLeaseAcquired = taskToRunWhenLeaseAcquired;
...
}
public async Task RunTaskWhenMutexAcquired(CancellationToken token)
{
var leaseManager = new BlobLeaseManager(blobSettings);
await this.RunTaskWhenBlobLeaseAcquired(leaseManager, token);
}
...
Metoda RunTaskWhenMutexAcquired w powyższym przykładowym kodzie wywołuje metodę RunTaskWhenBlobLeaseAcquired, która, jak pokazano w następującym przykładzie kodu, uzyskuje dzierżawę. Metoda RunTaskWhenBlobLeaseAcquired jest uruchamiana asynchronicznie. Jeśli dzierżawa zostanie pomyślnie przejęta, wystąpienie procesu roboczego zostanie wybrane jako lider. Celem delegata taskToRunWhenLeaseAcquired jest wykonanie pracy, która koordynuje inne wystąpienia procesów roboczych. Jeśli dzierżawa nie zostanie przejęta, inne wystąpienie procesu roboczego zostało wybrane jako lider, a bieżące wystąpienie procesu roboczego pozostaje podrzędne. Pamiętaj, że metoda TryAcquireLeaseOrWait jest metodą pomocnika uzyskującą dzierżawę za pomocą obiektu BlobLeaseManager.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (!token.IsCancellationRequested)
{
// Try to acquire the blob lease.
// Otherwise wait for a short time before trying again.
string? leaseId = await this.TryAcquireLeaseOrWait(leaseManager, token);
if (!string.IsNullOrEmpty(leaseId))
{
// Create a new linked cancellation token source so that if either the
// original token is canceled or the lease can't be renewed, the
// leader task can be canceled.
using (var leaseCts =
CancellationTokenSource.CreateLinkedTokenSource(new[] { token }))
{
// Run the leader task.
var leaderTask = this.taskToRunWhenLeaseAcquired.Invoke(leaseCts.Token);
...
}
}
}
...
}
Zadanie uruchamiane przez lidera również jest uruchamiane asynchronicznie. Kiedy to zadanie jest uruchomione, metoda RunTaskWhenBlobLeaseAcquired przedstawiona w następującym przykładzie kodu co jakiś czas próbuje odnowić dzierżawę. Pomaga to zapewnić, że wystąpienie procesu roboczego pozostanie liderem. W przykładowym rozwiązaniu opóźnienie między żądaniami odnowienia jest mniejsze niż czas określony przez czas trwania dzierżawy, aby zapobiec wybraniu innego wystąpienia procesu roboczego jako lidera. Jeśli odnowienie zakończy się niepowodzeniem z jakiegokolwiek powodu, zadanie specyficzne dla lidera zostanie anulowane.
Jeśli dzierżawa nie zostanie odnowiona lub zadanie zostanie anulowane (prawdopodobnie w wyniku zamknięcia wystąpienia procesu roboczego), dzierżawa zostanie zwolniona. W tym momencie można wybrać to lub inne wystąpienie procesu roboczego jako lider. W poniższym wyodrębnionym kodzie przedstawiono część tego procesu.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (...)
{
...
if (...)
{
...
using (var leaseCts = ...)
{
...
// Keep renewing the lease in regular intervals.
// If the lease can't be renewed, then the task completes.
var renewLeaseTask =
this.KeepRenewingLease(leaseManager, leaseId, leaseCts.Token);
// When any task completes (either the leader task itself or when it
// couldn't renew the lease) then cancel the other task.
await CancelAllWhenAnyCompletes(leaderTask, renewLeaseTask, leaseCts);
}
}
}
}
...
}
Metoda KeepRenewingLease jest kolejną metodą pomocnika odnawiającą dzierżawę za pomocą obiektu BlobLeaseManager. Metoda CancelAllWhenAnyCompletes anuluje zadania określone jako dwa pierwsze parametry. Na poniższym diagramie przedstawiono wybieranie lidera i uruchamianie zadania koordynującego operacje przy użyciu klasy BlobDistributedMutex.
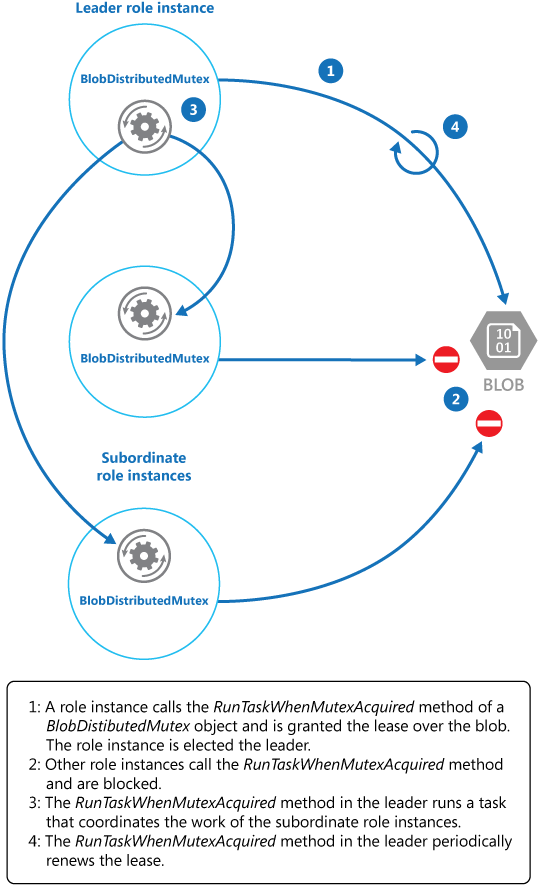
W poniższym przykładzie kodu pokazano, jak używać BlobDistributedMutex klasy w wystąpieniu procesu roboczego. Ten kod uzyskuje dzierżawę obiektu blob o nazwie MyLeaderCoordinatorTask w kontenerze dzierżawy usługi Azure Blob Storage i określa, że kod zdefiniowany w MyLeaderCoordinatorTask metodzie powinien zostać uruchomiony, jeśli wystąpienie procesu roboczego zostanie wybrane jako lider.
// Create a BlobSettings object with the connection string or managed identity and the name of the blob to use for the lease
BlobSettings blobSettings = new BlobSettings(storageConnStr, "leases", "MyLeaderCoordinatorTask");
// Create a new BlobDistributedMutex object with the BlobSettings object and a task to run when the lease is acquired
var distributedMutex = new BlobDistributedMutex(
blobSettings, MyLeaderCoordinatorTask);
// Wait for completion of the DistributedMutex and the UI task before exiting
await distributedMutex.RunTaskWhenMutexAcquired(cancellationToken);
...
// Method that runs if the worker instance is elected the leader
private static async Task MyLeaderCoordinatorTask(CancellationToken token)
{
...
}
Pamiętaj o następujących kwestiach dotyczących tego przykładowego rozwiązania:
- Obiekt blob jest potencjalnym pojedynczym punktem awarii. Jeśli usługa blob stanie się niedostępna lub jest niedostępna, lider nie będzie mógł odnowić dzierżawy, a żadne inne wystąpienie procesu roboczego nie będzie mogło uzyskać dzierżawy. W takim przypadku żadne wystąpienie procesu roboczego nie będzie mogło działać jako lider. Jednak usługę blob zaprojektowano pod kątem niezawodności, dlatego całkowita awaria usługi blob jest bardzo mało prawdopodobna.
- Jeśli zadanie wykonywane przez lidera zostanie zatrzymane, lider może nadal odnowić dzierżawę, uniemożliwiając innym wystąpieniom procesu roboczego uzyskanie dzierżawy i przejęcie pozycji lidera w celu koordynowania zadań. W rzeczywistych warunkach kondycję lidera należy sprawdzać z dużą częstotliwością.
- Proces wyboru jest niedeterministyczny. Nie można podjąć żadnych założeń dotyczących tego, które wystąpienie procesu roboczego uzyska dzierżawę obiektu blob i stanie się liderem.
- Obiekt blob będący elementem docelowym dzierżawy obiektu blob nie powinien być używany do żadnych innych celów. Jeśli wystąpienie procesu roboczego próbuje przechowywać dane w tym obiekcie blob, te dane nie będą dostępne, chyba że wystąpienie procesu roboczego jest liderem i przechowuje dzierżawę obiektu blob.
Następne kroki
Podczas implementowania tego wzorca mogą być istotne następujące wskazówki:
- Ten wzorzec zawiera przykładową aplikację do pobrania.
- Autoscaling Guidance (Wskazówki dotyczące skalowania automatycznego). Możliwe jest uruchamianie i zatrzymywanie wystąpień hostów zadań w miarę zmian obciążenia aplikacji. Automatyczne skalowanie może ułatwić utrzymanie przepływności i wydajności w godzinach szczytu przetwarzania.
- Wzorzec asynchroniczny oparty na zadaniach.
- Przykład przedstawiający algorytm tyrana.
- Przykład przedstawiający algorytm pierścieniowy.
- Apache Curator — biblioteka klienta dla usługi Apache ZooKeeper.
- Artykuł Dzierżawienie obiektu blob (interfejs API REST) w witrynie MSDN.