Rozwiązywanie problemów z autoskalowaniem w usłudze Azure Monitor
Automatyczne skalowanie w usłudze Azure Monitor ułatwia obsługę obciążenia aplikacji przy użyciu odpowiedniej ilości zasobów. Umożliwia dodawanie zasobów w celu obsługi wzrostu obciążenia, a także oszczędzanie pieniędzy dzięki usunięciu zasobów, które są w stanie bezczynności. Możesz skalować na podstawie harmonogramu, stałej daty i godziny lub wybranej metryki zasobu. Aby uzyskać więcej informacji, zapoznaj się z omówieniem skalowania automatycznego.
Usługa autoskalowania udostępnia metryki i dzienniki, aby ułatwić zrozumienie, jakie akcje skalowania wystąpiły, oraz ocenę warunków, które doprowadziły do tych akcji. Odpowiedzi na pytania, takie jak:
- Dlaczego moja usługa została skalowana w poziomie lub skalowana w poziomie?
- Dlaczego moja usługa nie została skalowana?
- Dlaczego akcja automatycznego skalowania nie powiodła się?
- Dlaczego akcja autoskalowania zajmuje czas na skalowanie?
Flex Virtual Machine Scale Sets
Akcje skalowania automatycznego są opóźnione do kilku godzin po zastosowaniu akcji skalowania ręcznego do zasobu Flex Microsoft.Compute/virtualMachineScaleSets (VMSS) dla określonego zestawu operacji maszyny wirtualnej.
Na przykład usuwanie interfejsu wiersza polecenia maszyny wirtualnej platformy Azure lub usuwanie interfejsu API REST maszyny wirtualnej platformy Azure, w którym operacja jest wykonywana na pojedynczej maszynie wirtualnej.
W takich przypadkach usługa autoskalowania nie jest świadoma poszczególnych operacji maszyn wirtualnych.
Aby uniknąć tego scenariusza, użyj tej samej operacji, ale na poziomie zestawu skalowania maszyn wirtualnych. Na przykład wystąpienie usuwania interfejsu wiersza polecenia zestawu skalowania maszyn wirtualnych platformy Azure lub wystąpienie usuwania interfejsu API REST usługi Azure VMSS. Autoskalowanie wykrywa zmianę liczby wystąpień w zestawie skalowania maszyn wirtualnych i wykonuje odpowiednie akcje skalowania.
Metryki automatycznego skalowania
Automatyczne skalowanie udostępnia cztery metryki umożliwiające zrozumienie jej operacji:
- Obserwowana wartość metryki: wartość metryki wybranej do wykonania akcji skalowania, jak pokazano lub obliczono przez aparat autoskalowania. Ponieważ jedno ustawienie skalowania automatycznego może zawierać wiele reguł i w związku z tym wiele źródeł metryk, można filtrować przy użyciu "źródła metryki" jako wymiaru.
- Próg metryki: próg ustawiony na podjęcie akcji skalowania. Ponieważ jedno ustawienie skalowania automatycznego może zawierać wiele reguł i w związku z tym wiele źródeł metryk, można filtrować przy użyciu "reguły metryki" jako wymiaru.
- Obserwowana pojemność: aktywna liczba wystąpień zasobu docelowego, jak widać w aktywność aparatu skalowania automatycznego.
- Zainicjowane akcje skalowania: liczba akcji skalowania w poziomie i skalowania w poziomie zainicjowanych przez aparat autoskalowania. Można filtrować według akcji skalowania w poziomie i skalowania w poziomie.
Możesz użyć Eksploratora metryk do wykresu powyższych metryk w jednym miejscu. Wykres powinien zawierać następujące elementy:
- Rzeczywista metryka.
- Metryka jak pokazano/obliczona przez aparat skalowania automatycznego.
- Próg akcji skalowania.
- Zmiana pojemności.
Przykład 1. Analizowanie reguły skalowania automatycznego
Ustawienie skalowania automatycznego dla zestawu skalowania maszyn wirtualnych:
- Skaluje się w poziomie, gdy średni procent procesora CPU zestawu jest większy niż 70% przez 10 minut.
- Skaluje się, gdy wartość procentowa procesora CPU zestawu jest mniejsza niż 5% przez ponad 10 minut.
Przejrzyjmy metryki z usługi autoskalowania.
Na poniższym wykresie przedstawiono metrykę Procent użycia procesora CPU dla zestawu skalowania maszyn wirtualnych.

Następny wykres przedstawia metryki Obserwowana wartość metryki dla ustawienia autoskalowaniem.

Końcowy wykres przedstawia metryki Próg metryki i Obserwowana pojemność . Metryka Próg metryki u góry dla reguły skalowania w poziomie wynosi 70. Metryka Obserwowana pojemność w dolnej części przedstawia liczbę aktywnych wystąpień, czyli obecnie 3.

Uwaga
Próg metryki można filtrować według reguły wymiaru wyzwalacza metryki skalowania w poziomie (zwiększenia), aby zobaczyć próg skalowania w poziomie i według reguły skalowania w poziomie (zmniejsz).
Przykład 2. Zaawansowane skalowanie automatyczne dla zestawu skalowania maszyn wirtualnych
Ustawienie autoskalowania umożliwia zasobowi zestawu skalowania maszyn wirtualnych skalowanie w poziomie na podstawie własnej metryki Przepływy wychodzące . Wybrano opcję Podziel metryki według liczby wystąpień dla progu metryki.
Reguła akcji skalowania określa, czy wartość przepływu wychodzącego na wystąpienie jest większa niż 10, usługa autoskalowania powinna być skalowana w poziomie przez 1 wystąpienie.
W tym przypadku obserwowana wartość metryki aparatu autoskalowania jest obliczana jako rzeczywista wartość metryki podzielona przez liczbę wystąpień. Jeśli obserwowana wartość metryki jest mniejsza niż próg, nie zainicjowano żadnej akcji skalowania w poziomie.
Na poniższych zrzutach ekranu przedstawiono dwa wykresy metryk.
Wykres Avg Outbound Flows (Średnie przepływy wychodzące) przedstawia wartość metryki Przepływy wychodzące. Rzeczywista wartość to 6.

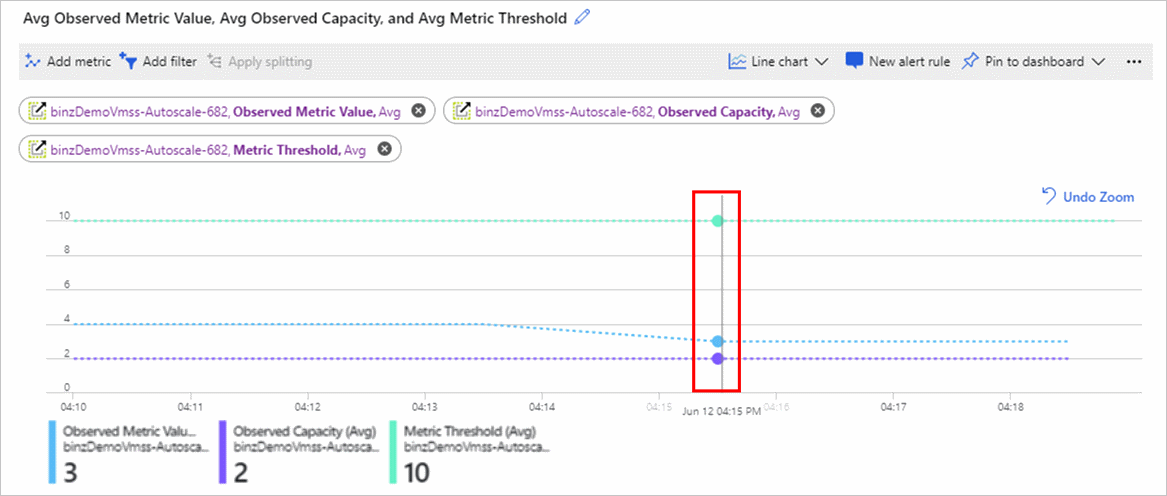
Na poniższym wykresie przedstawiono kilka wartości:
- Metryka Obserwowana wartość metryki w środku wynosi 3, ponieważ istnieje 2 aktywne wystąpienia, a 6 podzielone przez 2 to 3.
- Metryka Obserwowana pojemność u dołu pokazuje liczbę wystąpień widzianą przez aparat skalowania automatycznego.
- Metryka Próg metryki u góry jest ustawiona na 10.

Jeśli istnieje wiele reguł akcji skalowania, możesz użyć opcji dzielenia lub dodawania filtru na wykresie eksploratora metryk, aby przyjrzeć się metryce według określonego źródła lub reguły. Aby uzyskać więcej informacji na temat dzielenia wykresu metryk, zobacz Zaawansowane funkcje wykresów metryk — dzielenie.
Przykład 3. Omówienie zdarzeń skalowania automatycznego
Na ekranie ustawienia automatycznego skalowania przejdź do karty Historia uruchamiania, aby wyświetlić najnowsze akcje skalowania. Na karcie przedstawiono również zmianę obserwowanej pojemności w czasie. Aby uzyskać więcej informacji na temat wszystkich akcji autoskalowania, w tym operacji, takich jak aktualizowanie/usuwanie ustawień autoskalowania, wyświetl dziennik aktywności i filtruj według operacji autoskalowania.

Automatyczne skalowanie dzienników zasobów
Usługa autoskalowania udostępnia dzienniki zasobów. Istnieją dwie kategorie dzienników:
- Oceny automatycznego skalowania: aparat autoskalu rejestruje wpisy dziennika dla każdej oceny pojedynczego warunku za każdym razem, gdy wykonuje sprawdzanie. Wpis zawiera szczegółowe informacje o obserwowanych wartościach metryk, obliczonych reguł oraz o tym, czy ocena spowodowała działanie skalowania, czy nie.
- Akcje skalowania automatycznego: aparat rejestruje zdarzenia akcji skalowania zainicjowane przez usługę autoskalowania oraz wyniki tych akcji skalowania (powodzenie, niepowodzenie i ile skalowania wystąpiło w usłudze autoskalowania).
Podobnie jak w przypadku dowolnej obsługiwanej usługi Azure Monitor, możesz użyć ustawień diagnostycznych, aby kierować te dzienniki do:
- Obszar roboczy usługi Log Analytics do szczegółowej analizy.
- Usługa Azure Event Hubs, a następnie do narzędzi spoza platformy Azure.
- Twoje konto usługi Azure Storage na potrzeby archiwizacji.

Powyższy zrzut ekranu przedstawia okienko ustawień diagnostyki autoskalowania w witrynie Azure Portal. W tym miejscu możesz wybrać kartę Dzienniki diagnostyczne/zasobów i włączyć zbieranie dzienników i routing. Możesz również wykonać tę samą akcję przy użyciu interfejsu API REST, interfejsu wiersza polecenia platformy Azure, programu PowerShell i szablonów usługi Azure Resource Manager dla ustawień diagnostycznych, wybierając typ zasobu jako Microsoft.Szczegółowe informacje/Autoskaluj Ustawienia.
Rozwiązywanie problemów przy użyciu dzienników skalowania automatycznego
Aby uzyskać najlepsze środowisko rozwiązywania problemów, zalecamy kierowanie dzienników do dzienników usługi Azure Monitor (Log Analytics) za pośrednictwem obszaru roboczego podczas tworzenia ustawienia automatycznego skalowania. Ten proces jest wyświetlany na zrzucie ekranu w poprzedniej sekcji. Oceny i akcje skalowania można zweryfikować lepiej przy użyciu usługi Log Analytics.
Po skonfigurowaniu dzienników skalowania automatycznego do wysłania do obszaru roboczego usługi Log Analytics można wykonać następujące zapytania, aby sprawdzić dzienniki.
Aby rozpocząć, spróbuj wykonać to zapytanie, aby wyświetlić najnowsze dzienniki oceny automatycznego skalowania:
AutoscaleEvaluationsLog
| limit 50
Możesz też wypróbować następujące zapytanie, aby wyświetlić najnowsze dzienniki akcji skalowania:
AutoscaleScaleActionsLog
| limit 50
Skorzystaj z poniższych sekcji, aby odpowiedzieć na te pytania.
Wystąpiła akcja skalowania, której nie oczekiwano
Najpierw wykonaj zapytanie dla akcji skalowania, aby znaleźć odpowiednią akcję skalowania. Jeśli jest to najnowsza akcja skalowania, użyj następującego zapytania:
AutoscaleScaleActionsLog
| take 1
CorrelationId Wybierz pole z dziennika akcji skalowania. Użyj CorrelationId polecenia , aby znaleźć odpowiedni dziennik oceny. Wykonanie poniższego zapytania powoduje wyświetlenie wszystkich reguł i warunków, które zostały ocenione i doprowadziły do tej akcji skalowania.
AutoscaleEvaluationsLog
| where CorrelationId = "<correliationId>"
Jaki profil spowodował akcję skalowania?
Wystąpiła akcja skalowana, ale masz nakładające się reguły i profile i należy śledzić, które spowodowało działanie.
CorrelationId Znajdź akcję skalowania, jak wyjaśniono w przykładzie 1. Następnie wykonaj zapytanie w dziennikach oceny, aby dowiedzieć się więcej o profilu.
AutoscaleEvaluationsLog
| where CorrelationId = "<correliationId_Guid>"
| where ProfileSelected == true
| project ProfileEvaluationTime, Profile, ProfileSelected, EvaluationResult
Można również lepiej zrozumieć całą ocenę profilu, korzystając z następującego zapytania:
AutoscaleEvaluationsLog
| where TimeGenerated > ago(2h)
| where OperationName contains == "profileEvaluation"
| project OperationName, Profile, ProfileEvaluationTime, ProfileSelected, EvaluationResult
Nie wystąpiła akcja skalowania
Oczekiwano akcji skalowania i nie wystąpiła. Nie mogą istnieć żadne zdarzenia ani dzienniki akcji skalowania.
Przejrzyj metryki skalowania automatycznego, jeśli używasz reguły skalowania opartej na metrykach. Istnieje możliwość, że obserwowana wartość metryki lub obserwowana wartość pojemności nie jest taka, jaka powinna być, więc reguła skalowania nie zostanie wyzwolona. Nadal będą widoczne oceny, ale nie reguła skalowania w poziomie. Istnieje również możliwość, że czas ochładzania utrzymuje akcję skalowania przed wystąpieniem.
Przejrzyj dzienniki oceny automatycznego skalowania w okresie, w którym oczekiwano, że akcja skalowania zostanie wykonana. Przejrzyj wszystkie oceny i dlaczego zdecydowała się nie wyzwolić akcji skalowania.
AutoscaleEvaluationsLog
| where TimeGenerated > ago(2h)
| where OperationName == "MetricEvaluation" or OperationName == "ScaleRuleEvaluation"
| project OperationName, MetricData, ObservedValue, Threshold, EstimateScaleResult
Akcja skalowania nie powiodła się
Może wystąpić sytuacja, w której usługa autoskalowania podjęła akcję skalowania, ale system zdecydował się nie skalować ani nie ukończyć akcji skalowania. Użyj tego zapytania, aby znaleźć akcje skalowania, które zakończyły się niepowodzeniem:
AutoscaleScaleActionsLog
| where ResultType == "Failed"
| project ResultDescription
Utwórz reguły alertów, aby otrzymywać powiadomienia o akcjach lub niepowodzeniach autoskalowania. Możesz również utworzyć reguły alertów, aby otrzymywać powiadomienia o zdarzeniach autoskalowania.
Schemat dzienników zasobów autoskalowania
Aby uzyskać więcej informacji, zobacz Automatyczne skalowanie dzienników zasobów.
Następne kroki
Przeczytaj informacje na temat najlepszych rozwiązań dotyczących automatycznego skalowania.