Rozwiązanie monitor wydajności sieci: Monitorowanie wydajności
Ważne
Od 1 lipca 2021 r. nie będzie można dodawać nowych testów w istniejącym obszarze roboczym ani włączać nowego obszaru roboczego w obszarze Network monitor wydajności. Możesz nadal używać testów utworzonych przed 1 lipca 2021 r. Aby zminimalizować zakłócenia usługi w bieżących obciążeniach, przeprowadź migrację testów z usługi Network monitor wydajności do nowej Monitor połączenia na platformie Azure Network Watcher przed 29 lutego 2024 r.
Funkcja monitor wydajności w monitor wydajności sieci pomaga monitorować łączność sieciową między różnymi punktami w sieci. Możesz monitorować wdrożenia w chmurze i lokalizacje lokalne, wiele centrów danych i oddziałów oraz wielowarstwowe aplikacje lub mikrousługi o znaczeniu krytycznym. Dzięki monitor wydajności można wykrywać problemy z siecią, zanim użytkownicy będą narzekać. Najważniejsze zalety są następujące:
- Monitorowanie utraty i opóźnień w różnych podsieciach i ustawianie alertów.
- Monitoruj wszystkie ścieżki (w tym nadmiarowe ścieżki) w sieci.
- Rozwiązywanie przejściowych i przejściowych problemów z siecią w czasie, które są trudne do replikacji.
- Określ konkretny segment w sieci, który jest odpowiedzialny za obniżoną wydajność.
- Monitoruj kondycję sieci bez konieczności korzystania z protokołu SNMP.
Konfiguracja
Aby otworzyć konfigurację monitor wydajności sieci, otwórz rozwiązanie Monitor wydajności sieci i wybierz pozycję Konfiguruj.
Tworzenie nowych sieci
Sieć w monitor wydajności sieci jest kontenerem logicznym dla podsieci. Ułatwia ona organizowanie monitorowania infrastruktury sieciowej zgodnie z potrzebami. Możesz utworzyć sieć z przyjazną nazwą i dodać do niej podsieci zgodnie z logiką biznesową. Możesz na przykład utworzyć sieć o nazwie Londyn i dodać wszystkie podsieci w centrum danych w Londynie. Możesz też utworzyć sieć o nazwie ContosoFrontEnd i dodać do niej wszystkie podsieci o nazwie Contoso, które obsługują fronton aplikacji. Rozwiązanie automatycznie tworzy sieć domyślną, która zawiera wszystkie podsieci odnalezione w danym środowisku.
Za każdym razem, gdy tworzysz sieć, dodasz do niej podsieć. Następnie ta podsieć zostanie usunięta z sieci domyślnej. Jeśli usuniesz sieć, wszystkie jej podsieci zostaną automatycznie zwrócone do sieci domyślnej. Domyślna sieć działa jako kontener dla wszystkich podsieci, które nie są zawarte w żadnej sieci zdefiniowanej przez użytkownika. Nie można edytować ani usuwać domyślnej sieci. Zawsze pozostaje w systemie. Możesz utworzyć dowolną liczbę sieci niestandardowych. W większości przypadków podsieci w organizacji są rozmieszczone w więcej niż jednej sieci. Utwórz co najmniej jedną sieć, aby pogrupować podsieci dla logiki biznesowej.
Aby utworzyć nową sieć:
- Wybierz kartę Sieci .
- Wybierz pozycję Dodaj sieć, a następnie wprowadź nazwę sieci i opis.
- Wybierz co najmniej jedną podsieć, a następnie wybierz pozycję Dodaj.
- Wybierz pozycję Zapisz , aby zapisać konfigurację.
Tworzenie reguł monitorowania
monitor wydajności generuje zdarzenia kondycji, gdy próg wydajności połączeń sieciowych między dwiema podsieciami lub między dwiema sieciami zostanie naruszony. System może automatycznie uczyć się tych progów. Można również podać niestandardowe progi. System automatycznie tworzy regułę domyślną, która generuje zdarzenie kondycji za każdym razem, gdy utrata lub opóźnienie między dowolną parą łączy sieci lub podsieci narusza próg poznany przez system. Ten proces pomaga rozwiązaniu monitorować infrastrukturę sieci, dopóki nie utworzono jawnie żadnych reguł monitorowania. Jeśli reguła domyślna jest włączona, wszystkie węzły wysyłają transakcje syntetyczne do wszystkich pozostałych węzłów, które włączono na potrzeby monitorowania. Domyślna reguła jest przydatna w przypadku małych sieci. Przykładem jest scenariusz, w którym masz niewielką liczbę serwerów z uruchomioną mikrousługą i chcesz upewnić się, że wszystkie serwery mają łączność ze sobą.
Uwaga
Zalecamy wyłączenie reguły domyślnej i utworzenie niestandardowych reguł monitorowania, szczególnie w przypadku dużych sieci, w których do monitorowania jest używana duża liczba węzłów. Niestandardowe reguły monitorowania mogą zmniejszyć ruch generowany przez rozwiązanie i ułatwić organizowanie monitorowania sieci.
Utwórz reguły monitorowania zgodnie z logiką biznesową. Przykładem może być monitorowanie wydajności łączności sieciowej dwóch biur z siedzibą firmy. Grupuj wszystkie podsieci w lokacji biurowej1 w sieci O1. Następnie pogrupuj wszystkie podsieci w lokacji biurowej2 w sieci O2. Na koniec pogrupuj wszystkie podsieci w siedzibie głównej w sieci H. Utwórz dwie reguły monitorowania — jedną między O1 i H a drugą między O2 i H.
Aby utworzyć niestandardowe reguły monitorowania:
- Wybierz pozycję Dodaj regułę na karcie Monitor i wprowadź nazwę i opis reguły.
- Wybierz parę linków sieci lub podsieci do monitorowania z list.
- Wybierz sieć zawierającą odpowiednią podsieć z listy rozwijanej sieć. Następnie wybierz podsieć z odpowiedniej listy rozwijanej podsieci. Jeśli chcesz monitorować wszystkie podsieci w linku sieciowym, wybierz pozycję Wszystkie podsieci. Podobnie wybierz inną odpowiednią podsieć. Aby wykluczyć monitorowanie dla określonych linków podsieci z wybranych opcji, wybierz pozycję Dodaj wyjątek.
- Wybierz między protokołami ICMP i TCP, aby wykonywać transakcje syntetyczne.
- Jeśli nie chcesz tworzyć zdarzeń kondycji dla wybranych elementów, wyczyść pole Wyboru Włącz monitorowanie kondycji dla linków objętych tą regułą.
- Wybierz warunki monitorowania. Aby ustawić niestandardowe progi generowania zdarzeń kondycji, wprowadź wartości progowe. Zawsze, gdy wartość warunku przekracza wybrany próg dla wybranej pary sieci lub podsieci, generowane jest zdarzenie kondycji.
- Wybierz pozycję Zapisz , aby zapisać konfigurację.
Po zapisaniu reguły monitorowania możesz zintegrować tę regułę z usługą Alert Management, wybierając pozycję Utwórz alert. Reguła alertu jest tworzona automatycznie za pomocą zapytania wyszukiwania. Inne wymagane parametry są wypełniane automatycznie. Korzystając z reguły alertu, oprócz istniejących alertów w monitor wydajności sieci można odbierać alerty oparte na wiadomościach e-mail. Alerty mogą również wyzwalać akcje korygujące za pomocą elementów Runbook lub integrować je z istniejącymi rozwiązaniami do zarządzania usługami przy użyciu elementów webhook. Wybierz pozycję Zarządzaj alertem , aby edytować ustawienia alertu.
Teraz możesz utworzyć więcej reguł monitor wydajności lub przejść do pulpitu nawigacyjnego rozwiązania, aby korzystać z możliwości.
Wybieranie protokołu
Monitor wydajności sieci używa transakcji syntetycznych do obliczania metryk wydajności sieci, takich jak utrata pakietów i opóźnienie łącza. Aby lepiej zrozumieć tę koncepcję, rozważ użycie agenta sieci monitor wydajności połączonego z jednym końcem połączenia sieciowego. Ten agent sieci monitor wydajności wysyła pakiety sondy do drugiego agenta sieci monitor wydajności podłączonego do innego końca sieci. Drugi agent odpowiada pakietami odpowiedzi. Ten proces powtarza się kilka razy. Mierząc liczbę odpowiedzi i czas potrzebny na odebranie każdej odpowiedzi, pierwszy agent sieci monitor wydajności ocenia opóźnienie łącza i spadki pakietów.
Format, rozmiar i sekwencja tych pakietów zależy od protokołu wybranego podczas tworzenia reguł monitorowania. Na podstawie protokołu pakietów pośrednie urządzenia sieciowe, takie jak routery i przełączniki, mogą przetwarzać te pakiety inaczej. W związku z tym wybór protokołu wpływa na dokładność wyników. Wybór protokołu określa również, czy po wdrożeniu rozwiązania Network monitor wydajności należy wykonać jakiekolwiek czynności ręczne.
Monitor wydajności sieci oferuje wybór między protokołami ICMP i TCP na potrzeby wykonywania transakcji syntetycznych. W przypadku wybrania protokołu ICMP podczas tworzenia reguły transakcji syntetycznej agenci sieci monitor wydajności używają komunikatów ECHO protokołu ICMP do obliczania opóźnienia sieci i utraty pakietów. ICMP ECHO używa tego samego komunikatu, który jest wysyłany przez konwencjonalne narzędzie ping. W przypadku używania protokołu TCP jako protokołu agenci sieci monitor wydajności wysyłają pakiety TCP SYN za pośrednictwem sieci. Po tym kroku następuje ukończenie uzgadniania PROTOKOŁU TCP, a połączenie jest usuwane przy użyciu pakietów RST.
Przed wybraniem protokołu należy wziąć pod uwagę następujące informacje:
Odnajdywanie wielu tras sieciowych. Protokół TCP jest dokładniejszy podczas odnajdywania wielu tras i potrzebuje mniejszej liczby agentów w każdej podsieci. Na przykład jeden lub dwóch agentów korzystających z protokołu TCP może odnaleźć wszystkie nadmiarowe ścieżki między podsieciami. Potrzebujesz kilku agentów, którzy używają protokołu ICMP, aby osiągnąć podobne wyniki. Korzystając z protokołu ICMP, jeśli masz wiele tras między dwiema podsieciami, potrzebujesz więcej niż 5N agentów w podsieci źródłowej lub docelowej.
Dokładność wyników. Routery i przełączniki mają tendencję do przypisywania niższego priorytetu do pakietów ECHO ICMP w porównaniu z pakietami TCP. W niektórych sytuacjach, gdy urządzenia sieciowe są mocno ładowane, dane uzyskane przez protokół TCP ściślej odzwierciedlają utratę i opóźnienie występujące w aplikacjach. Dzieje się tak, ponieważ większość ruchu aplikacji przepływa za pośrednictwem protokołu TCP. W takich przypadkach protokół ICMP zapewnia mniej dokładne wyniki w porównaniu z protokołem TCP.
Konfiguracja zapory. Protokół TCP wymaga, aby pakiety TCP zostały wysłane do portu docelowego. Domyślny port używany przez agentów monitor wydajności sieci to 8084. Port można zmienić podczas konfigurowania agentów. Upewnij się, że zapory sieciowe lub reguły sieciowej grupy zabezpieczeń (na platformie Azure) zezwalają na ruch na porcie. Należy również upewnić się, że lokalna zapora na komputerach, na których są zainstalowani agenci, jest skonfigurowana tak, aby zezwalała na ruch na tym porcie. Skrypty programu PowerShell umożliwiają konfigurowanie reguł zapory na komputerach z systemem Windows, ale należy ręcznie skonfigurować zaporę sieciową. Z kolei ICMP nie działa przy użyciu portu. W większości scenariuszy przedsiębiorstwa ruch ICMP jest dozwolony przez zapory, aby umożliwić korzystanie z narzędzi diagnostycznych sieci, takich jak narzędzie ping. Jeśli możesz wysłać polecenie ping do jednej maszyny z innej, możesz użyć protokołu ICMP bez konieczności ręcznego konfigurowania zapór.
Uwaga
Niektóre zapory mogą blokować ICMP, co może prowadzić do ponownej transmisji, co powoduje dużą liczbę zdarzeń w systemie zarządzania informacjami i zdarzeniami zabezpieczeń. Upewnij się, że wybrany protokół nie jest blokowany przez zaporę sieciową lub sieciową grupę zabezpieczeń. W przeciwnym razie monitor wydajności sieci nie może monitorować segmentu sieci. Zalecamy używanie protokołu TCP do monitorowania. Użyj protokołu ICMP w scenariuszach, w których nie można użyć protokołu TCP, na przykład w następujących sytuacjach:
- Węzły oparte na kliencie systemu Windows są używane, ponieważ nieprzetworzone gniazda TCP nie są dozwolone na klientach systemu Windows.
- Zapora sieciowa lub sieciowa grupa zabezpieczeń blokuje protokół TCP.
- Nie wiesz, jak przełączyć protokół.
Jeśli podczas wdrażania wybrano opcję używania protokołu ICMP, możesz w dowolnym momencie przełączyć się na protokół TCP, edytując domyślną regułę monitorowania.
- Przejdź do pozycjiMonitor>wydajności> sieciKonfigurowanie monitora>. Następnie wybierz pozycję Reguła domyślna.
- Przewiń do sekcji Protokół i wybierz protokół, którego chcesz użyć.
- Wybierz pozycję Zapisz , aby zastosować ustawienie.
Nawet jeśli reguła domyślna używa określonego protokołu, możesz utworzyć nowe reguły z innym protokołem. Możesz nawet utworzyć kombinację reguł, w których niektóre reguły używają protokołu ICMP, a inne używają protokołu TCP.
Przewodnik
Teraz przyjrzyj się prostej badaniu głównej przyczyny zdarzenia kondycji.
Na pulpicie nawigacyjnym rozwiązania zdarzenie kondycji pokazuje, że link sieciowy jest w złej kondycji. Aby zbadać problem, wybierz kafelek Monitorowane linki sieciowe .
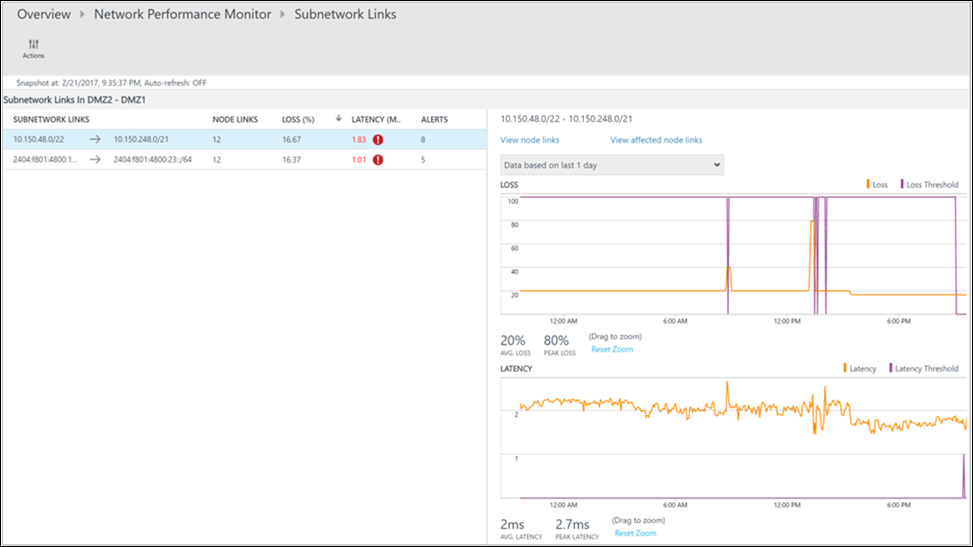
Na stronie przechodzenia do szczegółów widać, że połączenie sieciowe DMZ2-DMZ1 jest w złej kondycji. Wybierz pozycję Wyświetl łącza podsieci dla tego linku sieciowego.
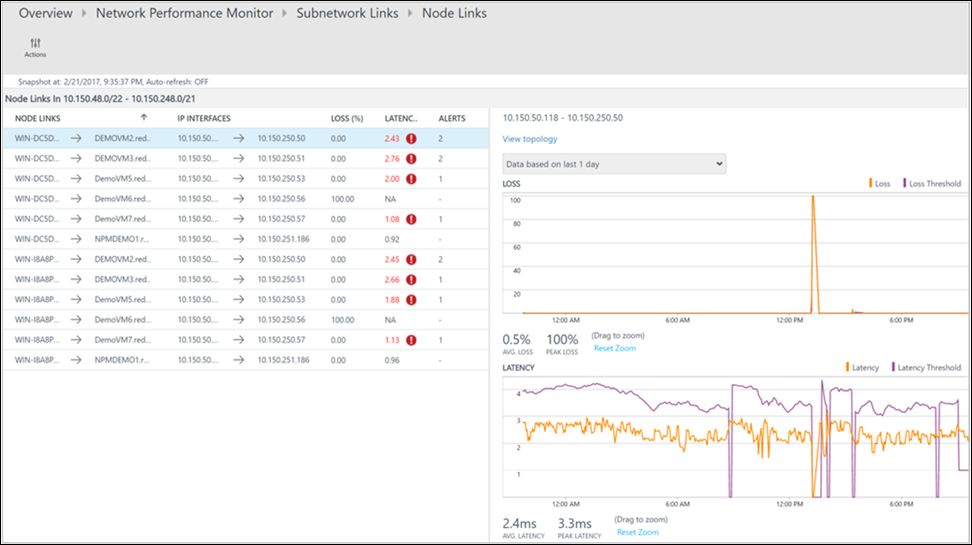
Na stronie przechodzenia do szczegółów są wyświetlane wszystkie linki podsieci w linku sieciOWYM DMZ2-DMZ1 . W przypadku obu łączy podsieci opóźnienie przekroczyło próg, co sprawia, że połączenie sieciowe jest w złej kondycji. Można również zobaczyć trendy opóźnień dla obu linków podsieci. Użyj kontrolki wyboru czasu na wykresie, aby skoncentrować się na wymaganym zakresie czasu. Możesz zobaczyć czas dnia, kiedy opóźnienie osiągnęło szczyt. Przeszukaj dzienniki później w tym okresie, aby zbadać problem. Wybierz pozycję Wyświetl łącza węzła , aby przejść do szczegółów.
Podobnie jak na poprzedniej stronie, strona przechodzenia do szczegółów dla konkretnego linku podsieci zawiera linki węzłów składowych. Podobne akcje można wykonać w tym miejscu, tak jak w poprzednim kroku. Wybierz pozycję Wyświetl topologię , aby wyświetlić topologię między dwoma węzłami.
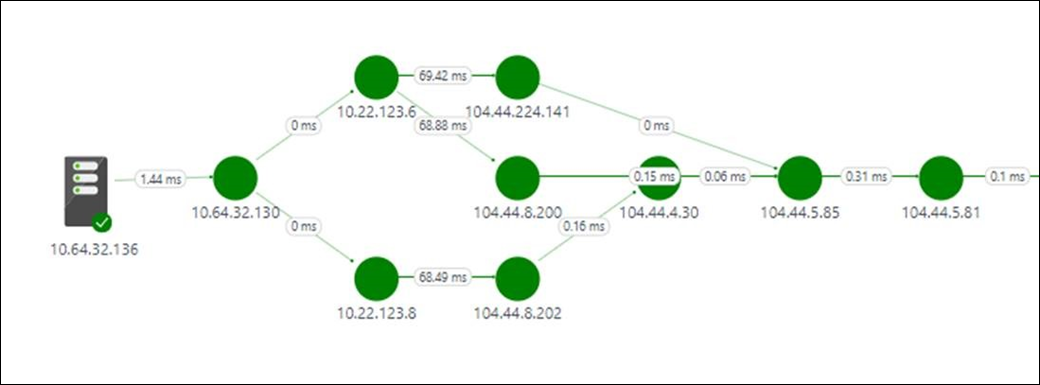
Wszystkie ścieżki między dwoma wybranymi węzłami są wykreśliane na mapie topologii. Topologię przeskoku tras między dwoma węzłami na mapie topologii można wizualizować. Zapewnia on jasny obraz liczby tras między dwoma węzłami i ścieżek, które przyjmują pakiety danych. Wąskie gardła wydajności sieci są wyświetlane na czerwono. Aby zlokalizować wadliwe połączenie sieciowe lub wadliwe urządzenie sieciowe, zapoznaj się z czerwonymi elementami na mapie topologii.
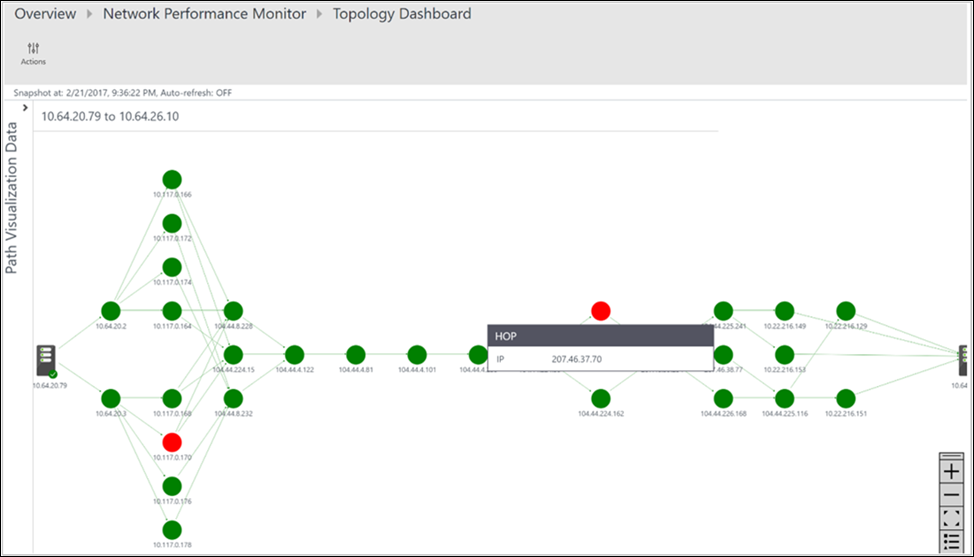
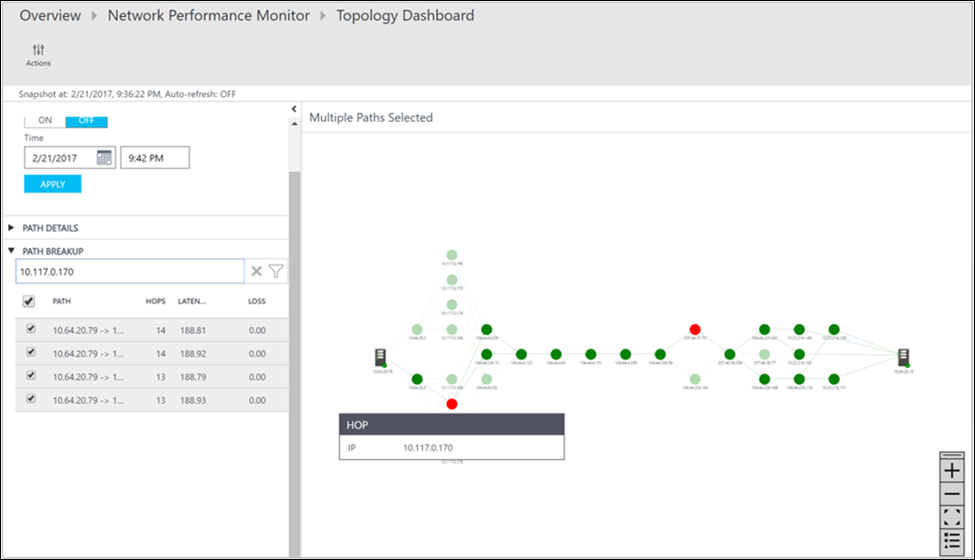
Możesz przejrzeć utratę, opóźnienie i liczbę przeskoków w każdej ścieżce w okienku Akcja . Użyj paska przewijania, aby wyświetlić szczegóły ścieżek w złej kondycji. Użyj filtrów, aby wybrać ścieżki z przeskokiem w złej kondycji, aby topologia tylko dla wybranych ścieżek została wykreślina. Aby powiększyć lub usunąć mapę topologii, użyj kółka myszy.
Na poniższej ilustracji główna przyczyna obszarów problemu do określonej sekcji sieci pojawia się w czerwonych ścieżkach i przeskokach. Wybierz węzeł na mapie topologii, aby wyświetlić właściwości węzła, w tym nazwę FQDN i adres IP. Wybranie przeskoku spowoduje wyświetlenie adresu IP przeskoku.
Następne kroki
Przeszukiwanie dzienników w celu wyświetlenia szczegółowych rekordów danych dotyczących wydajności sieci.