Tworzenie szablonów usługi ARM na potrzeby spójności chmury
Ważne
Korzystanie z tej funkcji platformy Azure z programu PowerShell wymaga zainstalowania modułu AzureRM . Jest to starszy moduł dostępny tylko dla Windows PowerShell 5.1, który nie otrzymuje już nowych funkcji.
Moduły Az i AzureRMnie są zgodne w przypadku instalacji dla tych samych wersji programu PowerShell.
Jeśli potrzebujesz obu wersji:
- Odinstaluj moduł Az z sesji programu PowerShell 5.1.
- Zainstaluj moduł AzureRM z sesji programu PowerShell 5.1.
- Pobierz i zainstaluj program PowerShell Core 6.x lub nowszy.
- Zainstaluj moduł Az w sesji programu PowerShell Core.
Kluczową zaletą platformy Azure jest spójność. Inwestycje programistyczne dla jednej lokalizacji są wielokrotnego użytku w innym. Szablon usługi Azure Resource Manager (ARM) sprawia, że wdrożenia są spójne i powtarzalne w różnych środowiskach, w tym globalne platformy Azure, suwerenne chmury platformy Azure i usługi Azure Stack. Aby ponownie używać szablonów w chmurach, należy jednak wziąć pod uwagę zależności specyficzne dla chmury, jak wyjaśniono w tym przewodniku.
Firma Microsoft oferuje inteligentne, gotowe do przedsiębiorstwa usługi w chmurze w wielu lokalizacjach, w tym:
- Globalna platforma Azure obsługiwana przez rosnącą sieć zarządzanych przez firmę Microsoft centrów danych w regionach na całym świecie.
- Odizolowane suwerenne chmury, takie jak Azure Germany, Azure Government i Microsoft Azure obsługiwane przez firmę 21Vianet. Suwerenne chmury zapewniają spójną platformę z większością tych samych wspaniałych funkcji, do których mają dostęp globalni klienci platformy Azure.
- Azure Stack to hybrydowa platforma w chmurze, która umożliwia dostarczanie usług platformy Azure z centrum danych organizacji. Przedsiębiorstwa mogą konfigurować usługę Azure Stack we własnych centrach danych lub korzystać z usług platformy Azure od dostawców usług, uruchamiając usługę Azure Stack w swoich obiektach (czasami nazywanymi regionami hostowanymi).
W centrum wszystkich tych chmur platforma Azure Resource Manager udostępnia interfejs API, który umożliwia szeroką gamę interfejsów użytkownika do komunikowania się z platformą Azure. Ten interfejs API zapewnia zaawansowane możliwości infrastruktury jako kodu. Każdy typ zasobu, który jest dostępny na platformie Azure w chmurze, można wdrożyć i skonfigurować za pomocą usługi Azure Resource Manager. Za pomocą jednego szablonu można wdrożyć i skonfigurować pełną aplikację do stanu zakończenia operacyjnego.
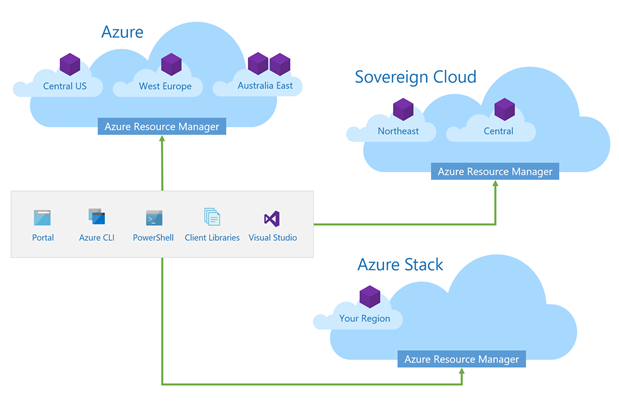
Spójność globalnej platformy Azure, suwerennych chmur, chmur hostowanych i chmury w centrum danych ułatwia korzystanie z usługi Azure Resource Manager. Możesz ponownie wykorzystać inwestycje programistyczne w tych chmurach podczas konfigurowania wdrażania i konfigurowania zasobów opartych na szablonach.
Jednak mimo że globalne, suwerenne, hostowane i hybrydowe chmury zapewniają spójne usługi, nie wszystkie chmury są identyczne. W związku z tym można utworzyć szablon z zależnościami dotyczącymi funkcji dostępnych tylko w określonej chmurze.
W pozostałej części tego przewodnika opisano obszary, które należy wziąć pod uwagę podczas planowania tworzenia nowych lub aktualizowania istniejących szablonów usługi ARM dla usługi Azure Stack. Ogólnie rzecz biorąc, lista kontrolna powinna zawierać następujące elementy:
- Sprawdź, czy funkcje, punkty końcowe, usługi i inne zasoby w szablonie są dostępne w docelowych lokalizacjach wdrożenia.
- Przechowuj zagnieżdżone szablony i artefakty konfiguracji w dostępnych lokalizacjach, zapewniając dostęp między chmurami.
- Użyj odwołań dynamicznych zamiast twardych linków i elementów.
- Upewnij się, że parametry szablonu, których używasz, działają w chmurach docelowych.
- Sprawdź, czy właściwości specyficzne dla zasobów są dostępne w chmurach docelowych.
Aby zapoznać się z wprowadzeniem do szablonów usługi ARM, zobacz Wdrażanie szablonów.
Upewnij się, że funkcje szablonu działają
Podstawowa składnia szablonu usługi ARM to JSON. Szablony używają nadzbioru kodu JSON, rozszerzając składnię za pomocą wyrażeń i funkcji. Procesor języka szablonu jest często aktualizowany w celu obsługi dodatkowych funkcji szablonu. Aby uzyskać szczegółowe wyjaśnienie dostępnych funkcji szablonu, zobacz Funkcje szablonu usługi ARM.
Nowe funkcje szablonu wprowadzone do usługi Azure Resource Manager nie są natychmiast dostępne w suwerennych chmurach ani w usłudze Azure Stack. Aby pomyślnie wdrożyć szablon, wszystkie funkcje, do których odwołuje się szablon, muszą być dostępne w chmurze docelowej.
Możliwości platformy Azure Resource Manager będą zawsze wprowadzane do globalnej platformy Azure. Możesz użyć następującego skryptu programu PowerShell, aby sprawdzić, czy nowo wprowadzone funkcje szablonu są również dostępne w usłudze Azure Stack:
Sklonuj repozytorium GitHub: https://github.com/marcvaneijk/arm-template-functions.
Po utworzeniu lokalnego klonu repozytorium nawiąż połączenie z usługą Azure Resource Manager miejsca docelowego za pomocą programu PowerShell.
Zaimportuj moduł psm1 i wykonaj polecenie cmdlet Test-AzureRmTemplateFunctions:
# Import the module Import-module <path to local clone>\AzTemplateFunctions.psm1 # Execute the Test-AzureRmTemplateFunctions cmdlet Test-AzureRmTemplateFunctions -path <path to local clone>
Skrypt wdraża wiele, zminimalizowanych szablonów, z których każdy zawiera tylko unikatowe funkcje szablonu. Dane wyjściowe skryptu zgłasza obsługiwane i niedostępne funkcje szablonu.
Praca z połączonymi artefaktami
Szablon może zawierać odwołania do połączonych artefaktów i zawiera zasób wdrożenia, który łączy się z innym szablonem. Połączone szablony (nazywane również szablonem zagnieżdżonym) są pobierane przez Resource Manager w czasie wykonywania. Szablon może również zawierać odwołania do artefaktów dla rozszerzeń maszyny wirtualnej. Te artefakty są pobierane przez rozszerzenie maszyny wirtualnej uruchomione wewnątrz maszyny wirtualnej na potrzeby konfiguracji rozszerzenia maszyny wirtualnej podczas wdrażania szablonu.
W poniższych sekcjach opisano zagadnienia dotyczące spójności chmury podczas tworzenia szablonów zawierających artefakty zewnętrzne dla głównego szablonu wdrożenia.
Używanie szablonów zagnieżdżonych w różnych regionach
Szablony można rozdzielić na małe szablony wielokrotnego użytku, z których każdy ma określony cel i może być ponownie używany w różnych scenariuszach wdrażania. Aby wykonać wdrożenie, należy określić pojedynczy szablon nazywany głównym lub głównym szablonem. Określa zasoby do wdrożenia, takie jak sieci wirtualne, maszyny wirtualne i aplikacje internetowe. Główny szablon może również zawierać link do innego szablonu, co oznacza, że można zagnieżdżać szablony. Podobnie szablon zagnieżdżony może zawierać linki do innych szablonów. Można zagnieżdżać maksymalnie pięć poziomów głębokości.
Poniższy kod pokazuje, jak parametr templateLink odwołuje się do zagnieżdżonego szablonu:
"resources": [
{
"type": "Microsoft.Resources/deployments",
"apiVersion": "2020-10-01",
"name": "linkedTemplate",
"properties": {
"mode": "incremental",
"templateLink": {
"uri":"https://mystorageaccount.blob.core.windows.net/AzureTemplates/vNet.json",
"contentVersion":"1.0.0.0"
}
}
}
]
Usługa Azure Resource Manager ocenia główny szablon w czasie wykonywania i pobiera i ocenia każdy zagnieżdżony szablon. Po pobraniu wszystkich zagnieżdżonych szablonów szablon jest spłaszczony, a dalsze przetwarzanie jest inicjowane.
Udostępnianie połączonych szablonów w chmurach
Zastanów się, gdzie i jak przechowywać używane połączone szablony. W czasie wykonywania usługa Azure Resource Manager pobiera i dlatego wymaga bezpośredniego dostępu do dowolnych połączonych szablonów. Typowym rozwiązaniem jest użycie usługi GitHub do przechowywania zagnieżdżonych szablonów. Repozytorium GitHub może zawierać pliki, które są dostępne publicznie za pośrednictwem adresu URL. Mimo że ta technika działa dobrze w przypadku chmury publicznej i suwerennych chmur, środowisko usługi Azure Stack może znajdować się w sieci firmowej lub w rozłączonej lokalizacji zdalnej, bez żadnego wychodzącego dostępu do Internetu. W takich przypadkach usługa Azure Resource Manager nie może pobrać zagnieżdżonych szablonów.
Lepszym rozwiązaniem w przypadku wdrożeń między chmurami jest przechowywanie połączonych szablonów w lokalizacji dostępnej dla chmury docelowej. W idealnym przypadku wszystkie artefakty wdrażania są przechowywane i wdrażane z potoku ciągłej integracji/ciągłego programowania (CI/CD). Alternatywnie można przechowywać zagnieżdżone szablony w kontenerze magazynu obiektów blob, z którego można pobrać usługę Azure Resource Manager.
Ponieważ magazyn obiektów blob w każdej chmurze używa innej w pełni kwalifikowanej nazwy domeny punktu końcowego (FQDN), skonfiguruj szablon z lokalizacją połączonych szablonów z dwoma parametrami. Parametry mogą akceptować dane wejściowe użytkownika w czasie wdrażania. Szablony są zwykle tworzone i współużytkowane przez wiele osób, dlatego najlepszym rozwiązaniem jest użycie standardowej nazwy tych parametrów. Konwencje nazewnictwa pomagają zwiększyć wielokrotne użycie szablonów w różnych regionach, chmurach i autorach.
W poniższym kodzie _artifactsLocation służy do wskazywania pojedynczej lokalizacji zawierającej wszystkie artefakty związane z wdrażaniem. Zwróć uwagę, że podano wartość domyślną. W czasie wdrażania, jeśli nie określono żadnej wartości wejściowej dla _artifactsLocationparametru , zostanie użyta wartość domyślna. Parametr _artifactsLocationSasToken jest używany jako dane wejściowe dla elementu sasToken. Wartość domyślna powinna być pustym ciągiem dla scenariuszy, w których _artifactsLocation nie jest zabezpieczony — na przykład publiczne repozytorium GitHub.
"parameters": {
"_artifactsLocation": {
"type": "string",
"metadata": {
"description": "The base URI where artifacts required by this template are located."
},
"defaultValue": "https://raw.githubusercontent.com/Azure/azure-quickstart-templates/master/quickstarts/microsoft.compute/vm-custom-script-windows/"
},
"_artifactsLocationSasToken": {
"type": "securestring",
"metadata": {
"description": "The sasToken required to access _artifactsLocation."
},
"defaultValue": ""
}
}
W całym szablonie linki są generowane przez połączenie podstawowego identyfikatora URI (z parametru _artifactsLocation ) ze ścieżką względną artefaktu i _artifactsLocationSasToken. Poniższy kod pokazuje, jak określić link do zagnieżdżonego szablonu przy użyciu funkcji szablonu identyfikatora URI:
"resources": [
{
"type": "Microsoft.Resources/deployments",
"apiVersion": "2020-10-01",
"name": "shared",
"properties": {
"mode": "Incremental",
"templateLink": {
"uri": "[uri(parameters('_artifactsLocation'), concat('nested/vnet.json', parameters('_artifactsLocationSasToken')))]",
"contentVersion": "1.0.0.0"
}
}
}
]
Korzystając z tego podejścia, jest używana wartość domyślna parametru _artifactsLocation . Jeśli połączone szablony muszą zostać pobrane z innej lokalizacji, dane wejściowe parametru mogą być używane w czasie wdrażania, aby zastąpić wartość domyślną — nie trzeba zmieniać samego szablonu.
Użyj _artifactsLocation zamiast łączy twardych
Poza użyciem szablonów zagnieżdżonych adres URL w parametrze _artifactsLocation jest używany jako podstawa dla wszystkich powiązanych artefaktów szablonu wdrożenia. Niektóre rozszerzenia maszyn wirtualnych zawierają link do skryptu przechowywanego poza szablonem. W przypadku tych rozszerzeń nie należy kodować linków na stałe. Na przykład rozszerzenia DSC niestandardowego skryptu i programu PowerShell mogą łączyć się ze skryptem zewnętrznym w usłudze GitHub, jak pokazano poniżej:
"properties": {
"publisher": "Microsoft.Compute",
"type": "CustomScriptExtension",
"typeHandlerVersion": "1.9",
"autoUpgradeMinorVersion": true,
"settings": {
"fileUris": [
"https://raw.githubusercontent.com/Microsoft/dotnet-core-sample-templates/master/dotnet-core-music-windows/scripts/configure-music-app.ps1"
]
}
}
Hardcoding linków do skryptu potencjalnie uniemożliwia pomyślne wdrożenie szablonu w innej lokalizacji. Podczas konfigurowania zasobu maszyny wirtualnej agent maszyny wirtualnej uruchomiony wewnątrz maszyny wirtualnej inicjuje pobieranie wszystkich skryptów połączonych w rozszerzeniu maszyny wirtualnej, a następnie przechowuje skrypty na dysku lokalnym maszyny wirtualnej. Takie podejście działa podobnie jak linki szablonu zagnieżdżonego opisane wcześniej w sekcji "Korzystanie z szablonów zagnieżdżonych w różnych regionach".
Resource Manager pobiera zagnieżdżone szablony w czasie wykonywania. W przypadku rozszerzeń maszyn wirtualnych pobieranie wszelkich artefaktów zewnętrznych jest wykonywane przez agenta maszyny wirtualnej. Oprócz innego inicjatora pobierania artefaktu rozwiązanie w definicji szablonu jest takie samo. Użyj parametru _artifactsLocation z wartością domyślną ścieżki podstawowej, w której są przechowywane wszystkie artefakty (w tym skrypty rozszerzenia maszyny wirtualnej) i _artifactsLocationSasToken parametr wejściowy dla sygnatury dostępu współdzielonego.
"parameters": {
"_artifactsLocation": {
"type": "string",
"metadata": {
"description": "The base URI where artifacts required by this template are located."
},
"defaultValue": "https://raw.githubusercontent.com/Microsoft/dotnet-core-sample-templates/master/dotnet-core-music-windows/"
},
"_artifactsLocationSasToken": {
"type": "securestring",
"metadata": {
"description": "The sasToken required to access _artifactsLocation."
},
"defaultValue": ""
}
}
Aby utworzyć bezwzględny identyfikator URI artefaktu, preferowaną metodą jest użycie funkcji szablonu identyfikatora URI zamiast funkcji szablonu concat. Zastępując zakodowane na stałe linki do skryptów w rozszerzeniu maszyny wirtualnej funkcją szablonu identyfikatora URI, ta funkcja w szablonie jest skonfigurowana pod kątem spójności w chmurze.
"properties": {
"publisher": "Microsoft.Compute",
"type": "CustomScriptExtension",
"typeHandlerVersion": "1.9",
"autoUpgradeMinorVersion": true,
"settings": {
"fileUris": [
"[uri(parameters('_artifactsLocation'), concat('scripts/configure-music-app.ps1', parameters('_artifactsLocationSasToken')))]"
]
}
}
Dzięki temu podejściu wszystkie artefakty wdrażania, w tym skrypty konfiguracji, mogą być przechowywane w tej samej lokalizacji z samym szablonem. Aby zmienić lokalizację wszystkich łączy, wystarczy określić inny podstawowy adres URL dla parametrów artifactsLocation.
Czynnik w różnych możliwościach regionalnych
Dzięki elastycznemu programowi i ciągłemu przepływowi aktualizacji i nowych usług wprowadzonych na platformie Azure regiony mogą różnić się w dostępności usług lub aktualizacji. Po rygorystycznym testowaniu wewnętrznym nowe usługi lub aktualizacje istniejących usług są zwykle wprowadzane do niewielkiej liczby klientów uczestniczących w programie weryfikacji. Po pomyślnej weryfikacji klienta usługi lub aktualizacje są udostępniane w podzestawie regionów platformy Azure, a następnie wprowadzane do większej liczby regionów, wdrażane w suwerennych chmurach i potencjalnie udostępniane klientom usługi Azure Stack.
Wiedząc, że regiony i chmury platformy Azure mogą różnić się w ich dostępnych usługach, możesz podejmować pewne proaktywne decyzje dotyczące szablonów. Dobrym miejscem do rozpoczęcia jest sprawdzenie dostępnych dostawców zasobów dla chmury. Dostawca zasobów informuje o zestawie zasobów i operacji dostępnych dla usługi platformy Azure.
Szablon wdraża i konfiguruje zasoby. Typ zasobu jest dostarczany przez dostawcę zasobów. Na przykład dostawca zasobów obliczeniowych (Microsoft.Compute) udostępnia wiele typów zasobów, takich jak virtualMachines i availabilitySets. Każdy dostawca zasobów udostępnia interfejs API platformy Azure Resource Manager zdefiniowany przez wspólny kontrakt, umożliwiając spójne, ujednolicone środowisko tworzenia we wszystkich dostawcach zasobów. Jednak dostawca zasobów dostępny w globalnej platformie Azure może nie być dostępny w suwerennej chmurze lub regionie usługi Azure Stack.
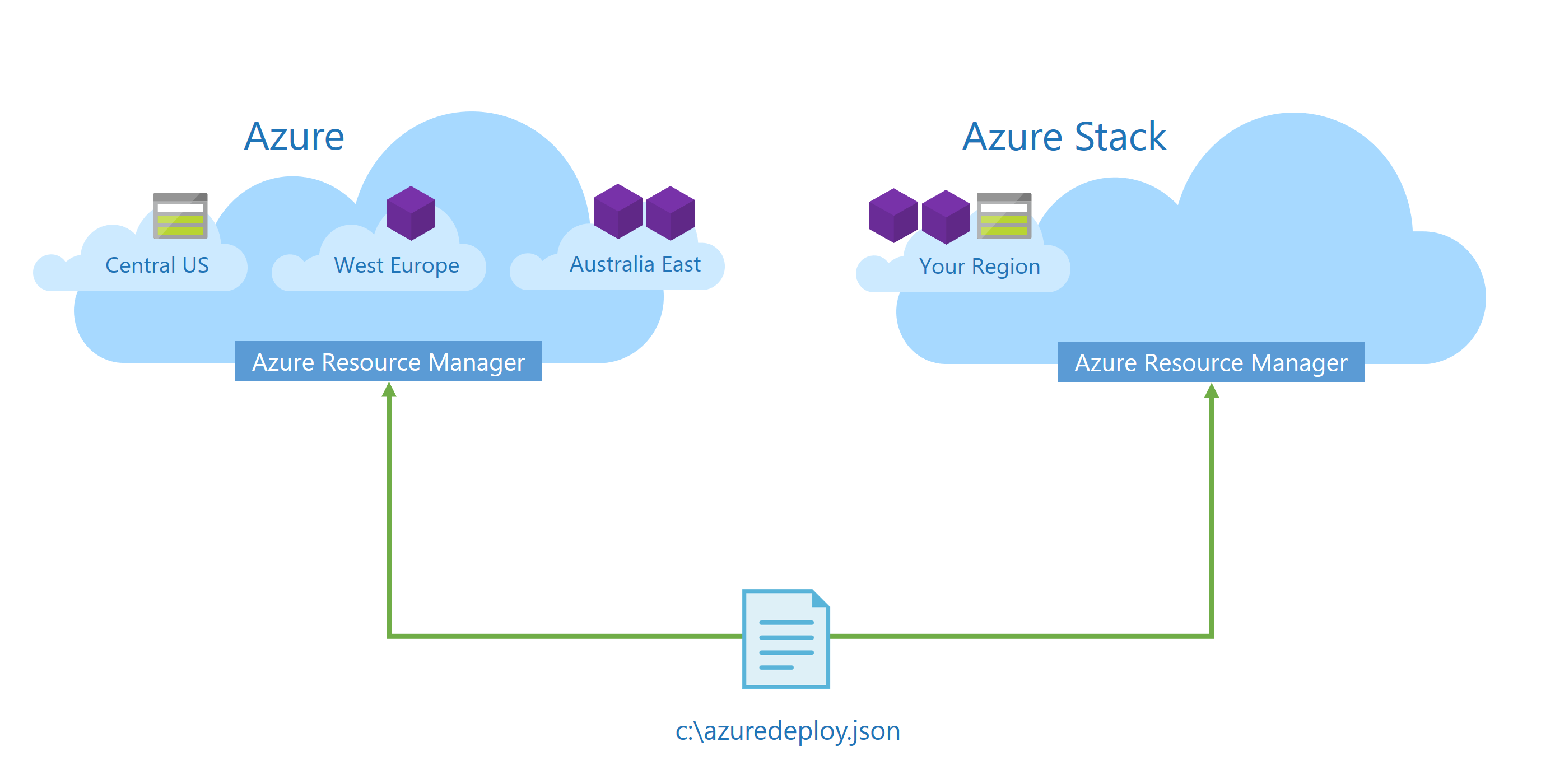
Aby sprawdzić dostawców zasobów dostępnych w danej chmurze, uruchom następujący skrypt w interfejsie wiersza polecenia platformy Azure:
az provider list --query "[].{Provider:namespace, Status:registrationState}" --out table
Możesz również użyć następującego polecenia cmdlet programu PowerShell, aby wyświetlić dostępnych dostawców zasobów:
Get-AzureRmResourceProvider -ListAvailable | Select-Object ProviderNamespace, RegistrationState
Weryfikowanie wersji wszystkich typów zasobów
Zestaw właściwości jest wspólny dla wszystkich typów zasobów, ale każdy zasób ma również własne właściwości. Nowe funkcje i powiązane właściwości są dodawane do istniejących typów zasobów czasami za pośrednictwem nowej wersji interfejsu API. Zasób w szablonie ma własną właściwość wersji interfejsu API — apiVersion. Ta obsługa wersji gwarantuje, że istniejąca konfiguracja zasobów w szablonie nie ma wpływu na zmiany na platformie.
Nowe wersje interfejsu API wprowadzone do istniejących typów zasobów na globalnej platformie Azure mogą nie być natychmiast dostępne we wszystkich regionach, suwerennych chmurach lub usłudze Azure Stack. Aby wyświetlić listę dostępnych dostawców zasobów, typów zasobów i wersji interfejsu API dla chmury, możesz użyć Eksploratora zasobów w Azure Portal. Wyszukaj Eksplorator zasobów w menu Wszystkie usługi. Rozwiń węzeł Dostawcy w Eksploratorze zasobów, aby zwrócić wszystkich dostępnych dostawców zasobów, ich typów zasobów i wersji interfejsu API w tej chmurze.
Aby wyświetlić listę dostępnych wersji interfejsu API dla wszystkich typów zasobów w danej chmurze w interfejsie wiersza polecenia platformy Azure, uruchom następujący skrypt:
az provider list --query "[].{namespace:namespace, resourceType:resourceType[]}"
Można również użyć następującego polecenia cmdlet programu PowerShell:
Get-AzureRmResourceProvider | select-object ProviderNamespace -ExpandProperty ResourceTypes | ft ProviderNamespace, ResourceTypeName, ApiVersions
Zapoznaj się z lokalizacjami zasobów za pomocą parametru
Szablon jest zawsze wdrażany w grupie zasobów, która znajduje się w regionie. Oprócz samego wdrożenia każdy zasób w szablonie ma również właściwość lokalizacji, która służy do określania regionu do wdrożenia. Aby opracować szablon pod kątem spójności w chmurze, potrzebny jest dynamiczny sposób odwoływania się do lokalizacji zasobów, ponieważ każda usługa Azure Stack może zawierać unikatowe nazwy lokalizacji. Zwykle zasoby są wdrażane w tym samym regionie co grupa zasobów, ale w celu obsługi scenariuszy, takich jak dostępność aplikacji między regionami, przydatne może być rozłożenie zasobów w różnych regionach.
Mimo że nazwy regionów można zakodować podczas określania właściwości zasobu w szablonie, takie podejście nie gwarantuje, że szablon można wdrożyć w innych środowiskach usługi Azure Stack, ponieważ nazwa regionu najprawdopodobniej nie istnieje.
Aby uwzględnić różne regiony, dodaj lokalizację parametru wejściowego do szablonu z wartością domyślną. Wartość domyślna będzie używana, jeśli podczas wdrażania nie określono żadnej wartości.
Funkcja [resourceGroup()] szablonu zwraca obiekt zawierający następujące pary klucz/wartość:
{
"id": "/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}",
"name": "{resourceGroupName}",
"location": "{resourceGroupLocation}",
"tags": {
},
"properties": {
"provisioningState": "{status}"
}
}
Odwołując się do klucza lokalizacji obiektu w wartości domyślnej parametru wejściowego, usługa Azure Resource Manager zastąpi [resourceGroup().location] funkcję szablonu nazwą lokalizacji grupy zasobów, w ramach których zostanie wdrożony szablon.
"parameters": {
"location": {
"type": "string",
"metadata": {
"description": "Location the resources will be deployed to."
},
"defaultValue": "[resourceGroup().location]"
}
},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2015-06-15",
"name": "storageaccount1",
"location": "[parameters('location')]",
...
Ta funkcja szablonu umożliwia wdrożenie szablonu w dowolnej chmurze bez wcześniejszej znajomości nazw regionów. Ponadto lokalizacja określonego zasobu w szablonie może różnić się od lokalizacji grupy zasobów. W takim przypadku można ją skonfigurować przy użyciu dodatkowych parametrów wejściowych dla tego konkretnego zasobu, podczas gdy inne zasoby w tym samym szablonie nadal używają początkowego parametru wejściowego lokalizacji.
Śledzenie wersji przy użyciu profilów interfejsu API
Śledzenie wszystkich dostępnych dostawców zasobów i powiązanych wersji interfejsu API znajdujących się w usłudze Azure Stack może być bardzo trudne. Na przykład w momencie pisania najnowsza wersja interfejsu API dla zestawu Microsoft.Compute/availabilitySets na platformie Azure to 2018-04-01, a dostępna wersja interfejsu API typowa dla platformy Azure i usługi Azure Stack to 2016-03-30. Typowa wersja interfejsu API dla usługi Microsoft.Storage/storageAccounts udostępniona we wszystkich lokalizacjach platformy Azure i usługi Azure Stack to 2016-01-01, podczas gdy najnowsza wersja interfejsu API na platformie Azure to 2018-02-01.
Z tego powodu Resource Manager wprowadził pojęcie profilów interfejsu API do szablonów. Bez profilów interfejsu API każdy zasób w szablonie jest skonfigurowany z elementem apiVersion opisujący wersję interfejsu API dla tego konkretnego zasobu.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"location": {
"type": "string",
"metadata": {
"description": "Location the resources will be deployed to."
},
"defaultValue": "[resourceGroup().location]"
}
},
"variables": {},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2016-01-01",
"name": "mystorageaccount",
"location": "[parameters('location')]",
"properties": {
"accountType": "Standard_LRS"
}
},
{
"type": "Microsoft.Compute/availabilitySets",
"apiVersion": "2016-03-30",
"name": "myavailabilityset",
"location": "[parameters('location')]",
"properties": {
"platformFaultDomainCount": 2,
"platformUpdateDomainCount": 2
}
}
],
"outputs": {}
}
Wersja profilu interfejsu API działa jako alias dla pojedynczej wersji interfejsu API dla typu zasobu wspólnego dla platformy Azure i usługi Azure Stack. Zamiast określać wersję interfejsu API dla każdego zasobu w szablonie, należy określić tylko wersję profilu interfejsu API w nowym elemecie głównym o nazwie apiProfile i pominąć apiVersion element dla poszczególnych zasobów.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"apiProfile": "2018–03-01-hybrid",
"parameters": {
"location": {
"type": "string",
"metadata": {
"description": "Location the resources will be deployed to."
},
"defaultValue": "[resourceGroup().location]"
}
},
"variables": {},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"name": "mystorageaccount",
"location": "[parameters('location')]",
"properties": {
"accountType": "Standard_LRS"
}
},
{
"type": "Microsoft.Compute/availabilitySets",
"name": "myavailabilityset",
"location": "[parameters('location')]",
"properties": {
"platformFaultDomainCount": 2,
"platformUpdateDomainCount": 2
}
}
],
"outputs": {}
}
Profil interfejsu API zapewnia, że wersje interfejsu API są dostępne w różnych lokalizacjach, więc nie trzeba ręcznie weryfikować interfejsów APIVersion, które są dostępne w określonej lokalizacji. Aby upewnić się, że wersje interfejsu API, do których odwołuje się twój profil interfejsu API, znajdują się w środowisku usługi Azure Stack, operatorzy usługi Azure Stack muszą zachować aktualność rozwiązania na podstawie zasad pomocy technicznej. Jeśli system jest nieaktualny niż sześć miesięcy, jest uznawany za nieaktualny, a środowisko musi zostać zaktualizowane.
Profil interfejsu API nie jest wymaganym elementem w szablonie. Nawet jeśli dodasz element, będzie on używany tylko dla zasobów, dla których nie określono.apiVersion Ten element umożliwia stopniowe zmiany, ale nie wymaga żadnych zmian w istniejących szablonach.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"apiProfile": "2018–03-01-hybrid",
"parameters": {
"location": {
"type": "string",
"metadata": {
"description": "Location the resources will be deployed to."
},
"defaultValue": "[resourceGroup().location]"
}
},
"variables": {},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2016-01-01",
"name": "mystorageaccount",
"location": "[parameters('location')]",
"properties": {
"accountType": "Standard_LRS"
}
},
{
"type": "Microsoft.Compute/availabilitySets",
"name": "myavailabilityset",
"location": "[parameters('location')]",
"properties": {
"platformFaultDomainCount": 2,
"platformUpdateDomainCount": 2
}
}
],
"outputs": {}
}
Sprawdzanie odwołań do punktu końcowego
Zasoby mogą mieć odwołania do innych usług na platformie. Na przykład publiczny adres IP może mieć przypisaną do niego publiczną nazwę DNS. Chmura publiczna, suwerenne chmury i rozwiązania usługi Azure Stack mają własne odrębne przestrzenie nazw punktów końcowych. W większości przypadków zasób wymaga tylko prefiksu jako danych wejściowych w szablonie. W czasie wykonywania usługa Azure Resource Manager dołącza do niej wartość punktu końcowego. Niektóre wartości punktu końcowego muszą być jawnie określone w szablonie.
Uwaga
Aby tworzyć szablony na potrzeby spójności chmury, nie należy kodować przestrzeni nazw punktów końcowych.
Następujące dwa przykłady to typowe przestrzenie nazw punktów końcowych, które należy jawnie określić podczas tworzenia zasobu:
- Konta magazynu (obiekty blob, kolejka, tabela i plik)
- Parametry połączenia dla baz danych i Azure Cache for Redis
Przestrzenie nazw punktów końcowych mogą być również używane w danych wyjściowych szablonu jako informacje dla użytkownika po zakończeniu wdrażania. Poniżej przedstawiono typowe przykłady:
- Konta magazynu (obiekty blob, kolejka, tabela i plik)
- Parametry połączenia (MySql, SQLServer, SQLAzure, Custom, NotificationHub, ServiceBus, EventHub, ApiHub, DocDb, RedisCache, PostgreSQL)
- Traffic Manager
- domainNameLabel publicznego adresu IP
- Usługi w chmurze
Ogólnie rzecz biorąc, unikaj zakodowanych na stałe punktów końcowych w szablonie. Najlepszym rozwiązaniem jest użycie funkcji szablonu referencyjnego w celu dynamicznego pobierania punktów końcowych. Na przykład punkt końcowy najczęściej zakodowany na stałe to przestrzeń nazw punktu końcowego dla kont magazynu. Każde konto magazynu ma unikatową nazwę FQDN, która jest tworzona przez połączenie nazwy konta magazynu z przestrzenią nazw punktu końcowego. Konto magazynu obiektów blob o nazwie mystorageaccount1 powoduje różne nazwy FQDN w zależności od chmury:
mystorageaccount1.blob.core.windows.netpodczas tworzenia w globalnej chmurze platformy Azure.mystorageaccount1.blob.core.chinacloudapi.cnpodczas tworzenia na platformie Azure obsługiwanej przez chmurę 21Vianet.
Następująca funkcja szablonu referencyjnego pobiera przestrzeń nazw punktu końcowego od dostawcy zasobów magazynu:
"diskUri":"[concat(reference(resourceId('Microsoft.Storage/storageAccounts', variables('storageAccountName'))).primaryEndpoints.blob, 'container/myosdisk.vhd')]"
Zastępując zakodowaną na stałe wartość punktu końcowego konta magazynu funkcją reference szablonu, możesz użyć tego samego szablonu do pomyślnego wdrożenia w różnych środowiskach bez wprowadzania żadnych zmian w odwołaniu do punktu końcowego.
Zapoznaj się z istniejącymi zasobami według unikatowego identyfikatora
Możesz również odwołać się do istniejącego zasobu z tej samej lub innej grupy zasobów oraz w ramach tej samej subskrypcji lub innej subskrypcji w tej samej dzierżawie w tej samej chmurze. Aby pobrać właściwości zasobu, musisz użyć unikatowego identyfikatora dla samego zasobu. Funkcja resourceId szablonu pobiera unikatowy identyfikator zasobu, takiego jak SQL Server, jak pokazano w poniższym kodzie:
"outputs": {
"resourceId":{
"type": "string",
"value": "[resourceId('otherResourceGroup', 'Microsoft.Sql/servers', parameters('serverName'))]"
}
}
Następnie możesz użyć resourceId funkcji wewnątrz funkcji szablonu reference , aby pobrać właściwości bazy danych. Obiekt zwracany zawiera fullyQualifiedDomainName właściwość, która przechowuje pełną wartość punktu końcowego. Ta wartość jest pobierana w czasie wykonywania i zapewnia przestrzeń nazw punktu końcowego specyficznego dla środowiska w chmurze. Aby zdefiniować parametry połączenia bez kodowania przestrzeni nazw punktu końcowego, można odwoływać się do właściwości obiektu zwracanego bezpośrednio w parametrach połączenia, jak pokazano poniżej:
"[concat('Server=tcp:', reference(resourceId('sql', 'Microsoft.Sql/servers', parameters('test')), '2015-05-01-preview').fullyQualifiedDomainName, ',1433;Initial Catalog=', parameters('database'),';User ID=', parameters('username'), ';Password=', parameters('pass'), ';Encrypt=True;')]"
Rozważ właściwości zasobu
Określone zasoby w środowiskach usługi Azure Stack mają unikatowe właściwości, które należy wziąć pod uwagę w szablonie.
Upewnij się, że obrazy maszyn wirtualnych są dostępne
Platforma Azure udostępnia bogaty wybór obrazów maszyn wirtualnych. Te obrazy są tworzone i przygotowane do wdrożenia przez firmę Microsoft i partnerów. Obrazy tworzą podstawę maszyn wirtualnych na platformie. Jednak szablon spójny z chmurą powinien odnosić się tylko do dostępnych parametrów — w szczególności wydawcy, oferty i jednostki SKU obrazów maszyn wirtualnych dostępnych dla globalnych chmur platformy Azure, suwerennych platformy Azure lub rozwiązania usługi Azure Stack.
Aby pobrać listę dostępnych obrazów maszyn wirtualnych w lokalizacji, uruchom następujące polecenie interfejsu wiersza polecenia platformy Azure:
az vm image list -all
Możesz pobrać tę samą listę za pomocą polecenia cmdlet Azure PowerShell Get-AzureRmVMImagePublisher i określić lokalizację, którą chcesz za pomocą parametru -Location . Na przykład:
Get-AzureRmVMImagePublisher -Location "West Europe" | Get-AzureRmVMImageOffer | Get-AzureRmVMImageSku | Get-AzureRmVMImage
To polecenie zajmuje kilka minut, aby zwrócić wszystkie dostępne obrazy w regionie Europa Zachodnia globalnej chmury platformy Azure.
Jeśli te obrazy maszyn wirtualnych zostaną udostępnione usłudze Azure Stack, zostanie użyty cały dostępny magazyn. Aby pomieścić nawet najmniejszą jednostkę skalowania, usługa Azure Stack umożliwia wybranie obrazów, które chcesz dodać do środowiska.
Poniższy przykładowy kod przedstawia spójne podejście do odwoływania się do parametrów wydawcy, oferty i jednostki SKU w szablonach usługi ARM:
"storageProfile": {
"imageReference": {
"publisher": "MicrosoftWindowsServer",
"offer": "WindowsServer",
"sku": "2016-Datacenter",
"version": "latest"
}
}
Sprawdzanie rozmiarów lokalnych maszyn wirtualnych
Aby utworzyć szablon na potrzeby spójności chmury, musisz upewnić się, że żądany rozmiar maszyny wirtualnej jest dostępny we wszystkich środowiskach docelowych. Rozmiary maszyn wirtualnych to grupa cech wydajności i możliwości. Niektóre rozmiary maszyn wirtualnych zależą od sprzętu, na którego działa maszyna wirtualna. Jeśli na przykład chcesz wdrożyć maszynę wirtualną zoptymalizowaną pod kątem procesora GPU, sprzęt z uruchomioną funkcją hypervisor musi mieć sprzętowe procesory GPU.
Gdy firma Microsoft wprowadza nowy rozmiar maszyny wirtualnej, która ma pewne zależności sprzętowe, rozmiar maszyny wirtualnej jest zwykle udostępniany jako pierwszy w małym podzestawie regionów w chmurze platformy Azure. Później jest ona udostępniana innym regionom i chmurom. Aby upewnić się, że rozmiar maszyny wirtualnej istnieje w każdej wdrożonej chmurze, możesz pobrać dostępne rozmiary za pomocą następującego polecenia interfejsu wiersza polecenia platformy Azure:
az vm list-sizes --location "West Europe"
W przypadku programu Azure PowerShell użyj polecenia:
Get-AzureRmVMSize -Location "West Europe"
Aby uzyskać pełną listę dostępnych usług, zobacz Produkty dostępne według regionów.
Sprawdzanie użycia usługi Azure Dyski zarządzane w usłudze Azure Stack
Dyski zarządzane obsługują magazyn dla dzierżawy platformy Azure. Zamiast jawnie tworzyć konto magazynu i określać identyfikator URI wirtualnego dysku twardego (VHD), możesz użyć dysków zarządzanych do niejawnego wykonywania tych akcji podczas wdrażania maszyny wirtualnej. Dyski zarządzane zwiększają dostępność, umieszczając wszystkie dyski z maszyn wirtualnych w tym samym zestawie dostępności w różnych jednostkach magazynu. Ponadto istniejące dyski VHD można przekonwertować z warstwy Standardowa na Magazyn w warstwie Premium z znacznie mniejszym przestojem.
Mimo że dyski zarządzane znajdują się w harmonogramie działania usługi Azure Stack, nie są one obecnie obsługiwane. Dopóki nie zostaną utworzone szablony spójne z chmurą dla usługi Azure Stack, jawnie określając wirtualne dyski twarde przy użyciu vhd elementu w szablonie zasobu maszyny wirtualnej, jak pokazano poniżej:
"storageProfile": {
"imageReference": {
"publisher": "MicrosoftWindowsServer",
"offer": "WindowsServer",
"sku": "[parameters('windowsOSVersion')]",
"version": "latest"
},
"osDisk": {
"name": "osdisk",
"vhd": {
"uri": "[concat(reference(resourceId('Microsoft.Storage/storageAccounts/', variables('storageAccountName')), '2015-06-15').primaryEndpoints.blob, 'vhds/osdisk.vhd')]"
},
"caching": "ReadWrite",
"createOption": "FromImage"
}
}
Natomiast aby określić konfigurację dysku zarządzanego w szablonie, usuń vhd element z konfiguracji dysku.
"storageProfile": {
"imageReference": {
"publisher": "MicrosoftWindowsServer",
"offer": "WindowsServer",
"sku": "[parameters('windowsOSVersion')]",
"version": "latest"
},
"osDisk": {
"caching": "ReadWrite",
"createOption": "FromImage"
}
}
Te same zmiany dotyczą również dysków danych.
Sprawdź, czy rozszerzenia maszyn wirtualnych są dostępne w usłudze Azure Stack
Inną kwestią dotyczącą spójności chmury jest użycie rozszerzeń maszyn wirtualnych do konfigurowania zasobów wewnątrz maszyny wirtualnej. Nie wszystkie rozszerzenia maszyn wirtualnych są dostępne w usłudze Azure Stack. Szablon może określać zasoby dedykowane dla rozszerzenia maszyny wirtualnej, tworząc zależności i warunki w szablonie.
Jeśli na przykład chcesz skonfigurować maszynę wirtualną z systemem Microsoft SQL Server, rozszerzenie maszyny wirtualnej może skonfigurować SQL Server w ramach wdrożenia szablonu. Zastanów się, co się stanie, jeśli szablon wdrożenia zawiera również serwer aplikacji skonfigurowany do utworzenia bazy danych na maszynie wirtualnej z uruchomionym SQL Server. Poza tym przy użyciu rozszerzenia maszyny wirtualnej dla serwerów aplikacji można skonfigurować zależność serwera aplikacji na pomyślnym powrocie zasobu rozszerzenia maszyny wirtualnej SQL Server. Takie podejście zapewnia, że maszyna wirtualna z systemem SQL Server jest skonfigurowana i dostępna, gdy serwer aplikacji zostanie poinstruowany o utworzeniu bazy danych.
Deklaratywne podejście szablonu umożliwia zdefiniowanie stanu końcowego zasobów i ich zależności, podczas gdy platforma zajmuje się logiką wymaganą dla zależności.
Sprawdź, czy rozszerzenia maszyn wirtualnych są dostępne
Istnieje wiele typów rozszerzeń maszyn wirtualnych. Podczas tworzenia szablonu na potrzeby spójności chmury upewnij się, że używasz tylko rozszerzeń, które są dostępne we wszystkich regionach docelowych szablonów.
Aby pobrać listę rozszerzeń maszyn wirtualnych dostępnych dla określonego regionu (w tym przykładzie myLocation), uruchom następujące polecenie interfejsu wiersza polecenia platformy Azure:
az vm extension image list --location myLocation
Można również wykonać Azure PowerShell polecenie cmdlet Get-AzureRmVmImagePublisher i użyć -Location polecenia cmdlet , aby określić lokalizację obrazu maszyny wirtualnej. Na przykład:
Get-AzureRmVmImagePublisher -Location myLocation | Get-AzureRmVMExtensionImageType | Get-AzureRmVMExtensionImage | Select Type, Version
Upewnij się, że wersje są dostępne
Ponieważ rozszerzenia maszyn wirtualnych są zasobami Resource Manager pierwszej firmy, mają własne wersje interfejsu API. Jak pokazano w poniższym kodzie, typ rozszerzenia maszyny wirtualnej jest zagnieżdżonym zasobem dostawcy zasobów Microsoft.Compute.
{
"type": "Microsoft.Compute/virtualMachines/extensions",
"apiVersion": "2015-06-15",
"name": "myExtension",
"location": "[parameters('location')]",
...
Wersja interfejsu API zasobu rozszerzenia maszyny wirtualnej musi znajdować się we wszystkich lokalizacjach, które mają być przeznaczone dla szablonu. Zależność lokalizacji działa podobnie jak dostępność wersji interfejsu API dostawcy zasobów omówiona wcześniej w sekcji "Weryfikowanie wersji wszystkich typów zasobów".
Aby pobrać listę dostępnych wersji interfejsu API dla zasobu rozszerzenia maszyny wirtualnej, użyj polecenia cmdlet Get-AzureRmResourceProvider z dostawcą zasobów Microsoft.Compute , jak pokazano:
Get-AzureRmResourceProvider -ProviderNamespace "Microsoft.Compute" | Select-Object -ExpandProperty ResourceTypes | Select ResourceTypeName, Locations, ApiVersions | where {$_.ResourceTypeName -eq "virtualMachines/extensions"}
Rozszerzenia maszyn wirtualnych można również używać w zestawach skalowania maszyn wirtualnych. Obowiązują te same warunki lokalizacji. Aby opracować szablon na potrzeby spójności chmury, upewnij się, że wersje interfejsu API są dostępne we wszystkich lokalizacjach, w których planujesz wdrożenie. Aby pobrać wersje interfejsu API zasobu rozszerzenia maszyny wirtualnej dla zestawów skalowania, użyj tego samego polecenia cmdlet co wcześniej, ale określ typ zasobu zestawów skalowania maszyn wirtualnych, jak pokazano:
Get-AzureRmResourceProvider -ProviderNamespace "Microsoft.Compute" | Select-Object -ExpandProperty ResourceTypes | Select ResourceTypeName, Locations, ApiVersions | where {$_.ResourceTypeName -eq "virtualMachineScaleSets/extensions"}
Każde określone rozszerzenie jest również w wersji. Ta wersja jest wyświetlana typeHandlerVersion we właściwości rozszerzenia maszyny wirtualnej. Upewnij się, że wersja określona w elemecie rozszerzeń maszyn wirtualnych szablonu jest dostępna w typeHandlerVersion lokalizacjach, w których planujesz wdrożyć szablon. Na przykład następujący kod określa wersję 1.7:
{
"type": "extensions",
"apiVersion": "2016-03-30",
"name": "MyCustomScriptExtension",
"location": "[parameters('location')]",
"dependsOn": [
"[concat('Microsoft.Compute/virtualMachines/myVM', copyindex())]"
],
"properties": {
"publisher": "Microsoft.Compute",
"type": "CustomScriptExtension",
"typeHandlerVersion": "1.7",
...
Aby pobrać listę dostępnych wersji dla określonego rozszerzenia maszyny wirtualnej, użyj polecenia cmdlet Get-AzureRmVMExtensionImage . Poniższy przykład pobiera dostępne wersje rozszerzenia DSC programu PowerShell (Desired State Configuration) z myLocation:
Get-AzureRmVMExtensionImage -Location myLocation -PublisherName Microsoft.PowerShell -Type DSC | FT
Aby uzyskać listę wydawców, użyj polecenia Get-AzureRmVmImagePublisher . Aby zażądać typu, użyj pochwały Get-AzureRmVMExtensionImageType .
Porady dotyczące testowania i automatyzacji
Jest to wyzwanie, aby śledzić wszystkie powiązane ustawienia, możliwości i ograniczenia podczas tworzenia szablonu. Typowym podejściem jest opracowywanie i testowanie szablonów w jednej chmurze przed ukierunkowaniem innych lokalizacji. Jednak wcześniej testy są wykonywane w procesie tworzenia, tym mniej będzie konieczne rozwiązywanie problemów i ponowne zapisywanie kodu przez zespół deweloperów. Wdrożenia, które kończą się niepowodzeniem z powodu zależności lokalizacji, mogą być czasochłonne do rozwiązywania problemów. Dlatego zalecamy automatyczne testowanie tak wcześnie, jak to możliwe w cyklu tworzenia. Ostatecznie będziesz potrzebować mniej czasu programowania i mniejszej ilości zasobów, a artefakty spójne z chmurą staną się jeszcze cenniejsze.
Na poniższej ilustracji przedstawiono typowy przykład procesu programowania dla zespołu przy użyciu zintegrowanego środowiska projektowego (IDE). Na różnych etapach na osi czasu są wykonywane różne typy testów. W tym miejscu dwóch deweloperów pracuje nad tym samym rozwiązaniem, ale ten scenariusz ma zastosowanie równie do jednego dewelopera lub dużego zespołu. Każdy deweloper zazwyczaj tworzy lokalną kopię centralnego repozytorium, umożliwiając każdemu z nich pracę nad kopią lokalną bez wpływu na inne osoby, które mogą pracować nad tymi samymi plikami.
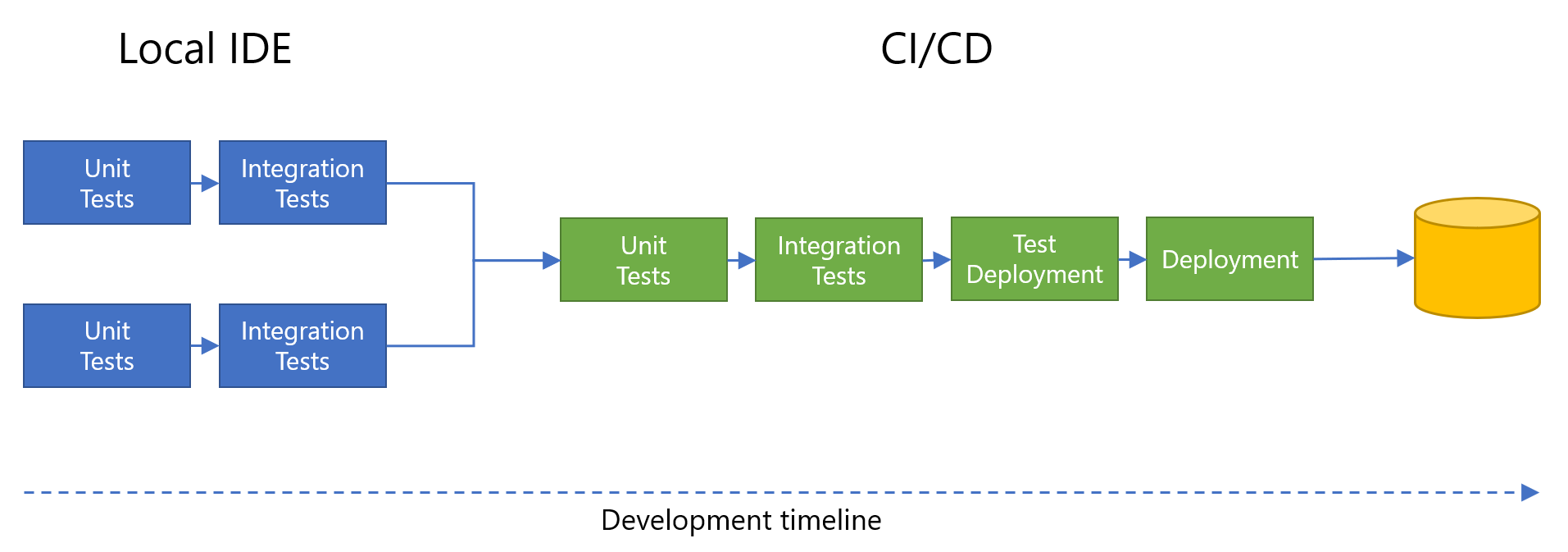
Weź pod uwagę następujące wskazówki dotyczące testowania i automatyzacji:
- Korzystaj z narzędzi do testowania. Na przykład Visual Studio Code i Visual Studio obejmują funkcję IntelliSense i inne funkcje, które mogą pomóc w weryfikowaniu szablonów.
- Aby poprawić jakość kodu podczas programowania w lokalnym środowisku IDE, przeprowadź analizę kodu statycznego przy użyciu testów jednostkowych i testów integracji.
- Aby uzyskać jeszcze lepsze środowisko podczas początkowego programowania, testy jednostkowe i testy integracji powinny ostrzegać tylko wtedy, gdy problem zostanie znaleziony i przejdziesz do testów. W ten sposób można zidentyfikować problemy, które należy rozwiązać i określić kolejność zmian, nazywanych również wdrażaniem opartym na testach (TDD).
- Należy pamiętać, że niektóre testy można wykonać bez połączenia z usługą Azure Resource Manager. Inne, takie jak testowanie wdrożenia szablonu, wymagają Resource Manager do wykonania pewnych akcji, których nie można wykonać w trybie offline.
- Testowanie szablonu wdrożenia względem interfejsu API weryfikacji nie jest równe rzeczywistemu wdrożeniu. Ponadto nawet w przypadku wdrożenia szablonu z pliku lokalnego wszystkie odwołania do zagnieżdżonych szablonów w szablonie są pobierane bezpośrednio przez Resource Manager, a artefakty przywoływane przez rozszerzenia maszyn wirtualnych są pobierane przez agenta maszyny wirtualnej uruchomionego wewnątrz wdrożonej maszyny wirtualnej.