Omówienie modelu zakupów opartego na jednostkach DTU
Dotyczy:![]() Azure SQL Database
Azure SQL Database
W tym artykule przedstawiono model zakupów oparty na jednostkach DTU dla usługi Azure SQL Database.
Aby dowiedzieć się więcej, zapoznaj się z modelem zakupów opartym na rdzeniach wirtualnych i porównaj modele zakupów.
Jednostki transakcji bazy danych (DTU)
Jednostka transakcji bazy danych (DTU) reprezentuje połączoną miarę procesora, pamięci, odczytów i zapisów. Warstwy usług w modelu zakupów opartym na jednostkach DTU są rozróżniane przez szereg rozmiarów obliczeniowych o stałej ilości dołączonego magazynu, stałego okresu przechowywania kopii zapasowych i stałej cenie. Wszystkie warstwy usług w modelu zakupów opartym na jednostkach DTU zapewniają elastyczność zmiany rozmiarów obliczeniowych przy minimalnych przestojach. Istnieje jednak zmiana w okresie, w którym łączność zostaje utracona z bazą danych przez krótki czas, co można ograniczyć przy użyciu logiki ponawiania prób. Opłaty za pojedyncze bazy danych i pule elastyczne są naliczane co godzinę na podstawie warstwy usług i rozmiaru obliczeniowego.
W przypadku pojedynczej bazy danych o określonym rozmiarze obliczeniowym w warstwie usługi usługa Azure SQL Database gwarantuje określony poziom zasobów dla tej bazy danych (niezależnie od każdej innej bazy danych). Ta gwarancja zapewnia przewidywalny poziom wydajności. Ilość zasobów przydzielonych dla bazy danych jest obliczana jako liczba jednostek DTU i jest w pakiecie miarą zasobów obliczeniowych, magazynowych i we/wy.
Stosunek między tymi zasobami jest pierwotnie określany przez obciążenie porównawcze przetwarzania transakcji online (OLTP), które ma być typowe dla rzeczywistych obciążeń OLTP. Gdy obciążenie przekracza ilość dowolnego z tych zasobów, przepływność jest ograniczana, co skutkuje wolniejszymi wydajnościami i limitami czasu.
W przypadku pojedynczych baz danych zasoby używane przez obciążenie nie mają wpływu na zasoby dostępne dla innych baz danych w chmurze platformy Azure. Podobnie zasoby używane przez inne obciążenia nie mają wpływu na zasoby dostępne dla bazy danych.
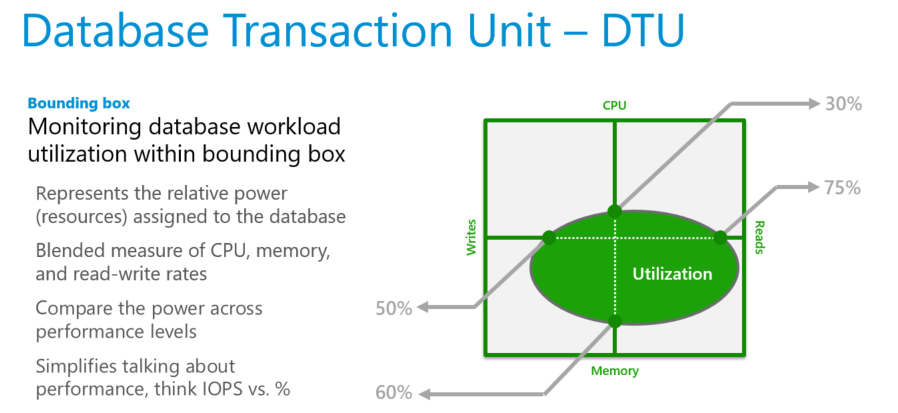
Jednostki DTU są najbardziej przydatne do zrozumienia względnych zasobów przydzielonych dla baz danych o różnych rozmiarach obliczeniowych i warstwach usług. Na przykład:
- Podwojenie jednostek DTU przez zwiększenie rozmiaru obliczeniowego bazy danych oznacza podwojenie zestawu zasobów dostępnych dla tej bazy danych.
- Baza danych P11 w warstwie Premium z 1750 jednostkami DTU zapewnia 350 razy większą moc obliczeniową jednostek DTU niż podstawowa baza danych warstwy usług z 5 jednostkami DTU.
Aby uzyskać lepszy wgląd w użycie zasobów (DTU) obciążenia, użyj szczegółowych informacji o wydajności zapytań, aby:
- Zidentyfikuj najważniejsze zapytania według liczby procesorów CPU/czasu trwania/wykonywania, które mogą być potencjalnie dostrojone w celu zwiększenia wydajności. Na przykład zapytanie intensywnie korzystające z operacji we/wy może skorzystać z technik optymalizacji w pamięci, aby lepiej wykorzystać dostępną pamięć w określonej warstwie usługi i rozmiarze obliczeniowym.
- Przejdź do szczegółów zapytania, aby wyświetlić jego tekst i historię użycia zasobów.
- Wyświetlanie zaleceń dotyczących dostrajania wydajności, które pokazują akcje wykonywane przez doradcę usługi SQL Database.
Elastyczne jednostki transakcji bazy danych (eDTU)
Zamiast udostępniać dedykowany zestaw zasobów (DTU), który może nie zawsze być potrzebny, można umieścić te bazy danych w elastycznej puli. Bazy danych w elastycznej puli używają jednego wystąpienia aparatu bazy danych i współdzielą tę samą pulę zasobów.
Udostępnione zasoby w elastycznej puli są mierzone przez elastyczne jednostki transakcji bazy danych (eDTU). Elastyczne pule zapewniają proste, ekonomiczne rozwiązanie do zarządzania celami wydajności dla wielu baz danych, które mają znacznie różne i nieprzewidywalne wzorce użycia. Elastyczna pula gwarantuje, że wszystkie zasoby nie mogą być używane przez jedną bazę danych w puli, zapewniając jednocześnie, że każda baza danych w puli zawsze ma minimalną ilość niezbędnych zasobów.
Pula ma ustawioną liczbę jednostek eDTU dla określonej ceny. W elastycznej puli poszczególne bazy danych mogą automatycznie skalować w skonfigurowanych granicach. Baza danych w większym obciążeniu zużywa więcej jednostek eDTU, aby zaspokoić zapotrzebowanie. Bazy danych w przypadku mniejszych obciążeń zużywają mniej jednostek eDTU. Bazy danych bez obciążenia nie zużywają jednostek eDTU. Ponieważ zasoby są aprowidowane dla całej puli, a nie dla bazy danych, elastyczne pule upraszczają zadania zarządzania i zapewniają przewidywalny budżet dla puli.
Możesz dodać więcej jednostek eDTU do istniejącej puli z minimalnym przestojem bazy danych. Podobnie, jeśli nie potrzebujesz już dodatkowych jednostek eDTU, usuń je z istniejącej puli w dowolnym momencie. Można również dodawać bazy danych do puli lub usuwać je z puli w dowolnym momencie. Aby zarezerwować jednostki eDTU dla innych baz danych, ogranicz liczbę baz danych jednostek eDTU, które mogą być używane w przypadku dużego obciążenia. Jeśli baza danych ma stale wysokie wykorzystanie zasobów, które ma wpływ na inne bazy danych w puli, przenieś ją z puli i skonfiguruj jako pojedynczą bazę danych z przewidywalną ilością wymaganych zasobów.
Obciążenia, które korzystają z elastycznej puli zasobów
Pule są odpowiednie dla baz danych ze średnią niskiego wykorzystania zasobów i stosunkowo rzadkimi skokami wykorzystania. Aby uzyskać więcej informacji, zobacz Kiedy należy rozważyć elastyczną pulę usługi SQL Database?
Określanie liczby jednostek DTU wymaganych przez obciążenie
Jeśli chcesz przeprowadzić migrację istniejącego obciążenia lokalnej lub maszyny wirtualnej programu SQL Server do usługi SQL Database, zapoznaj się z zaleceniami dotyczącymi jednostki SKU, aby przybliżyć wymaganą liczbę jednostek DTU. W przypadku istniejącego obciążenia usługi SQL Database użyj szczegółowych informacji o wydajności zapytań, aby zrozumieć użycie zasobów bazy danych (DTU) i uzyskać bardziej szczegółowe informacje na temat optymalizowania obciążenia. Dynamiczny widok zarządzania (DMV) sys.dm_db_resource_stats umożliwia wyświetlanie zużycia zasobów w ciągu ostatniej godziny. Widok wykazu sys.resource_stats wyświetla zużycie zasobów w ciągu ostatnich 14 dni, ale przy niższej wierności średnich pięciu minut.
Określanie wykorzystania jednostek DTU
Aby określić średni procent użycia jednostek DTU/eDTU względem limitu jednostek DTU/eDTU bazy danych lub elastycznej puli, użyj następującej formuły:
avg_dtu_percent = MAX(avg_cpu_percent, avg_data_io_percent, avg_log_write_percent)
Wartości wejściowe dla tej formuły można uzyskać z sys.dm_db_resource_stats, sys.resource_stats i widoków DMV sys.elastic_pool_resource_stats . Innymi słowy, aby określić procent użycia jednostek DTU/eDTU w kierunku limitu jednostek DTU/eDTU bazy danych lub elastycznej puli, wybierz największą wartość procentową z następujących wartości: avg_cpu_percent, avg_data_io_percenti avg_log_write_percent w danym punkcie w czasie.
Uwaga
Limit jednostek DTU bazy danych jest określany przez procesor CPU, odczyty, zapisy i pamięć dostępne dla bazy danych. Jednak ze względu na to, że aparat usługi SQL Database zwykle używa całej dostępnej pamięci podręcznej danych w celu zwiększenia wydajności, avg_memory_usage_percent wartość zwykle będzie zbliżona do 100 procent, niezależnie od bieżącego obciążenia bazy danych. W związku z tym, mimo że pamięć pośrednio wpływa na limit jednostek DTU, nie jest używana w formule wykorzystania jednostek DTU.
Zapisz konfigurację sprzętu
W modelu zakupów opartym na jednostkach DTU klienci nie mogą wybrać konfiguracji sprzętowej używanej dla baz danych. Chociaż dana baza danych zwykle pozostaje na określonym typie sprzętu przez długi czas (często przez wiele miesięcy), istnieją pewne zdarzenia, które mogą spowodować przeniesienie bazy danych do innego sprzętu.
Na przykład bazę danych można przenieść do innego sprzętu, jeśli jest skalowana w górę lub w dół do innego celu usługi, lub jeśli bieżąca infrastruktura w centrum danych zbliża się do limitów pojemności, lub jeśli obecnie używany sprzęt jest likwidowany ze względu na jego koniec życia.
Jeśli baza danych zostanie przeniesiona na inny sprzęt, wydajność obciążenia może ulec zmianie. Model jednostek DTU gwarantuje, że przepływność i czas odpowiedzi obciążenia porównawczego jednostek DTU pozostaną znacznie identyczne, ponieważ baza danych przechodzi do innego typu sprzętu, o ile jego cel usługi (liczba jednostek DTU) pozostaje taka sama.
Jednak w szerokim spektrum obciążeń klientów działających w usłudze Azure SQL Database wpływ użycia innego sprzętu dla tego samego celu usługi może być bardziej wyraźny. Różne obciążenia mogą korzystać z różnych konfiguracji i funkcji sprzętowych. W związku z tym w przypadku obciążeń innych niż test porównawczy jednostek DTU można zobaczyć różnice wydajności, jeśli baza danych przenosi się z jednego typu sprzętu do innego.
Klienci mogą użyć modelu rdzeni wirtualnych, aby wybrać preferowaną konfigurację sprzętu podczas tworzenia i skalowania bazy danych. W modelu rdzeni wirtualnych szczegółowe limity zasobów każdego celu usługi w każdej konfiguracji sprzętu są udokumentowane dla pojedynczych baz danych i pul elastycznych. Aby uzyskać więcej informacji na temat sprzętu w modelu rdzeni wirtualnych, zobacz Konfiguracja sprzętowa usługi SQL Database lub Konfiguracja sprzętowa dla usługi SQL Managed Instance.
Porównanie warstw usług
Wybór warstwy usługi zależy przede wszystkim od wymagań dotyczących ciągłości działania, magazynu i wydajności.
| Podstawowa | Standardowa (Standard) | Premium | |
|---|---|---|---|
| Obciążenie docelowe | Programowanie i produkcja | Programowanie i produkcja | Programowanie i produkcja |
| Umowa SLA dotycząca czasu pracy | 99,99% | 99,99% | 99,99% |
| Tworzenie kopii zapasowych | Wybór geograficznie nadmiarowego, strefowo nadmiarowego lub lokalnie nadmiarowego magazynu kopii zapasowych, przechowywania 1–7 dni (domyślnie 7 dni) Długoterminowe przechowywanie dostępne do 10 lat |
Wybór geograficznie nadmiarowego, strefowo nadmiarowego lub lokalnie nadmiarowego magazynu kopii zapasowych, przechowywania 1–35 dni (domyślnie 7 dni) Długoterminowe przechowywanie dostępne do 10 lat |
Wybór magazynu lokalnie nadmiarowego (LRS), strefowo nadmiarowego (ZRS) lub magazynu geograficznie nadmiarowego (GRS) Przechowywanie przez 1–35 dni (domyślnie 7 dni) z dostępnym okresem przechowywania długoterminowego do 10 lat |
| CPU | Niski | Niski, średni, wysoki | Średnie, wysokie |
| Liczba operacji we/wy na sekundę (przybliżona)* | 1–4 operacji we/wy na sekundę na jednostkę DTU | 1–4 operacji we/wy na sekundę na jednostkę DTU | >25 operacji we/wy na sekundę na jednostkę DTU |
| Opóźnienie operacji we/wy (przybliżone) | 5 ms (odczyt), 10 ms (zapis) | 5 ms (odczyt), 10 ms (zapis) | 2 ms (odczyt/zapis) |
| Indeksowanie magazynu kolumn | Nie dotyczy | Standardowa S3 i nowsze | Obsługiwane |
| OlTP w pamięci | Brak | Brak | Obsługiwane |
* Wszystkie operacje we/wy odczytu i zapisu na sekundę względem plików danych, w tym operacje we/wy w tle (punkt kontrolny i leniwy zapis).
Ważne
Cele usługi w warstwie Podstawowa, S0, S1 i S2 zapewniają mniej niż jeden rdzeń wirtualny (procesor CPU). W przypadku obciążeń intensywnie korzystających z procesora CPU zalecany jest cel usługi S3 lub nowszy.
W przypadku celów usługi Podstawowa, S0 i S1 pliki bazy danych są przechowywane w usłudze Azure Standard Storage, która używa nośnika magazynu opartego na dysku twardym (HDD). Te cele usługi najlepiej nadają się do tworzenia, testowania i innych rzadko używanych obciążeń, które są mniej wrażliwe na zmienność wydajności.
Napiwek
Aby wyświetlić rzeczywiste limity ładu zasobów dla bazy danych lub elastycznej puli, wykonaj zapytanie dotyczące widoku sys.dm_user_db_resource_governance . W przypadku pojedynczej bazy danych zwracany jest jeden wiersz. W przypadku bazy danych w elastycznej puli wiersz jest zwracany dla każdej bazy danych w puli.
Uwaga
Bezpłatna baza danych w usłudze Azure SQL Database można uzyskać w warstwie usługi Podstawowa przy użyciu bezpłatnego konta platformy Azure. Aby uzyskać informacje, zobacz Tworzenie zarządzanej bazy danych w chmurze przy użyciu bezpłatnego konta platformy Azure.
Limity zasobów
Limity zasobów różnią się w przypadku pojedynczych baz danych i baz danych w puli.
Limity magazynu pojedynczej bazy danych
W usłudze Azure SQL Database rozmiary obliczeniowe są wyrażane w jednostkach transakcji bazy danych (DTU) dla pojedynczych baz danych i elastycznych jednostek transakcji bazy danych (eDTU) dla pul elastycznych. Aby dowiedzieć się więcej, zapoznaj się z tematem Limity zasobów dla pojedynczych baz danych.
| Podstawowa | Standardowa (Standard) | Premium | |
|---|---|---|---|
| Maksymalny rozmiar magazynu | 2 GB | 1 TB | 4 TB |
| Maksymalna liczba jednostek DTU | 5 | 3000 | 4000 |
Ważne
W pewnych okolicznościach może być konieczne zmniejszenie bazy danych w celu odzyskania nieużywanego miejsca. Aby uzyskać więcej informacji, zobacz Zarządzanie miejscem na pliki w usłudze Azure SQL Database.
Limity puli elastycznej
Aby dowiedzieć się więcej, zapoznaj się z tematem Limity zasobów dla baz danych w puli.
| Podstawowa | Standardowa | Premium | |
|---|---|---|---|
| Maksymalny rozmiar magazynu na bazę danych | 2 GB | 1 TB | 1 TB |
| Maksymalny rozmiar magazynu na pulę | 156 GB | 4 TB | 4 TB |
| Maksymalna liczba jednostek eDTU na bazę danych | 5 | 3000 | 4000 |
| Maksymalna liczba jednostek eDTU na pulę | 1600 | 3000 | 4000 |
| Maksymalna liczba baz danych na pulę | 500 | 500 | 100 |
Ważne
Ponad 1 TB magazynu w warstwie Premium jest obecnie dostępne we wszystkich regionach, z wyjątkiem: Chiny Wschodnie, Chiny Północne, Niemcy Środkowe i Niemcy Północno-Wschodnie. W tych regionach maksymalna wielkość magazynu w warstwie Premium jest ograniczona do 1 TB. Aby uzyskać więcej informacji, zobacz bieżące ograniczenia poziomów P11–P15.
Ważne
W pewnych okolicznościach może być konieczne zmniejszenie bazy danych w celu odzyskania nieużywanego miejsca. Aby uzyskać więcej informacji, zobacz zarządzanie miejscem na pliki w usłudze Azure SQL Database.
Test porównawczy jednostek DTU
Cechy fizyczne (procesor CPU, pamięć, operacje we/wy) skojarzone z każdą miarą DTU są skalibrowane przy użyciu testu porównawczego, który symuluje rzeczywiste obciążenie bazy danych.
Dowiedz się więcej na temat schematu, używanych typów transakcji, kombinacji obciążeń, użytkowników i tempa, reguł skalowania i metryk skojarzonych z testem porównawczym jednostek DTU.
Porównanie modeli zakupów opartych na jednostkach DTU i rdzeni wirtualnych
Chociaż model zakupów oparty na jednostkach DTU jest oparty na powiązanej mierze zasobów obliczeniowych, magazynowych i we/wy, porównanie modelu zakupów rdzeni wirtualnych dla usługi Azure SQL Database umożliwia niezależne wybieranie i skalowanie zasobów obliczeniowych i magazynowych.
Model zakupów oparty na rdzeniach wirtualnych umożliwia również korzystanie z Korzyść użycia hybrydowego platformy Azure dla programu SQL Server w celu oszczędzania kosztów oraz oferuje opcje bezserwerowe i hiperskala dla usługi Azure SQL Database, które nie są dostępne w modelu zakupów opartym na jednostkach DTU.
Dowiedz się więcej w artykule Porównanie modeli zakupów opartych na rdzeniach wirtualnych i jednostkach DTU w usłudze Azure SQL Database.
Następne kroki
Dowiedz się więcej na temat modeli zakupów i powiązanych pojęć w następujących artykułach:
- Aby uzyskać szczegółowe informacje na temat określonych rozmiarów obliczeniowych i opcji rozmiaru magazynu dostępnych dla pojedynczych baz danych, zobacz Limity zasobów oparte na jednostkach DTU usługi SQL Database dla pojedynczych baz danych.
- Aby uzyskać szczegółowe informacje na temat określonych rozmiarów obliczeniowych i opcji rozmiaru magazynu dostępnych dla elastycznych pul, zobacz Limity zasobów oparte na jednostkach DTU usługi SQL Database.
- Aby uzyskać informacje na temat testu porównawczego skojarzonego z modelem zakupów opartym na jednostkach DTU, zobacz Test porównawczy jednostek DTU.
- Porównanie modeli zakupów opartych na rdzeniach wirtualnych i jednostkach DTU w usłudze Azure SQL Database.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla