Funkcje wielomodelowe usług Azure SQL Database i SQL Managed Instance
Dotyczy:![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Wielomodelowe bazy danych umożliwiają przechowywanie i pracę z danymi w wielu formatach, takich jak dane relacyjne, grafy, dokumenty JSON lub XML, dane przestrzenne i pary klucz-wartość.
Rodzina produktów Azure SQL używa modelu relacyjnego, który zapewnia najlepszą wydajność dla różnych aplikacji ogólnego przeznaczenia. Jednak produkty Azure SQL, takie jak Azure SQL Database i SQL Managed Instance, nie są ograniczone do danych relacyjnych. Umożliwiają one używanie formatów nierelacyjnych, które są ściśle zintegrowane z modelem relacyjnym.
Rozważ użycie funkcji wielomodelowych usługi Azure SQL w następujących przypadkach:
- Masz pewne informacje lub struktury, które są lepiej dopasowane do modeli NoSQL i nie chcesz używać oddzielnej bazy danych NoSQL.
- Większość danych jest odpowiednia dla modelu relacyjnego i trzeba modelować niektóre części danych w stylu NoSQL.
- Chcesz użyć języka Transact-SQL do wykonywania zapytań i analizowania danych relacyjnych i NoSQL, a następnie zintegrować te dane z narzędziami i aplikacjami, które mogą używać języka SQL.
- Chcesz zastosować funkcje bazy danych, takie jak technologie w pamięci, aby zwiększyć wydajność analizy lub przetwarzania struktur danych NoSQL. Replikacja transakcyjna lub repliki z możliwością odczytu umożliwiają tworzenie kopii danych i odciążanie niektórych obciążeń analitycznych z podstawowej bazy danych.
W poniższych sekcjach opisano najważniejsze funkcje wielomodelowe usługi Azure SQL.
Uwaga
Możesz użyć wyrażeń JSONPath, wyrażeń XQuery/XPath, funkcji przestrzennych i wyrażeń zapytań grafów w tym samym zapytaniu Języka Transact-SQL, aby uzyskać dostęp do dowolnych danych przechowywanych w bazie danych. Każde narzędzie lub język programowania, które może wykonywać zapytania Języka Transact-SQL, może również używać tego interfejsu zapytań do uzyskiwania dostępu do danych wielomodelowych. Jest to kluczowa różnica między wielomodelowymi bazami danych, takimi jak usługa Azure Cosmos DB, która udostępnia wyspecjalizowane interfejsy API dla modeli danych.
Funkcjonalności grafu
Produkty Azure SQL oferują możliwości grafowej bazy danych do modelowania relacji wiele-do-wielu w bazie danych. Graf to kolekcja węzłów (lub wierzchołków) i krawędzi (lub relacji). Węzeł reprezentuje jednostkę (na przykład osobę lub organizację). Krawędź reprezentuje relację między dwoma węzłami, z którymi się łączy (na przykład polubień lub znajomych).
Poniżej przedstawiono niektóre funkcje, które sprawiają, że grafowa baza danych jest unikatowa:
- Krawędzie to jednostki pierwszej klasy w grafowej bazie danych. Mogą mieć skojarzone atrybuty lub właściwości.
- Pojedyncza krawędź może elastycznie łączyć wiele węzłów w grafowej bazie danych.
- Możesz łatwo wyrazić dopasowywanie wzorców i zapytania nawigacji z wieloma przeskoku.
- Możesz łatwo wyrazić przejściowe zamknięcie i zapytania polimorficzne.
Relacje grafu i możliwości zapytań grafów są zintegrowane z programem Transact-SQL i otrzymują korzyści wynikające z używania aparatu bazy danych programu SQL Server jako podstawowego systemu zarządzania bazami danych. Funkcje grafu używają standardowych zapytań Języka Transact-SQL rozszerzonych za pomocą operatora grafu w celu wykonywania zapytań względem danych grafu MATCH .
Relacyjna baza danych może osiągnąć wszystko, co może zrobić grafowa baza danych. Jednak grafowa baza danych może ułatwić wyrażanie niektórych zapytań. Decyzja o wyborze jednej z pozostałych może być oparta na następujących czynnikach:
- Musisz modelować dane hierarchiczne, w których jeden węzeł może mieć wiele elementów nadrzędnych, więc nie można użyć typu danych hierarchyId.
- Aplikacja ma złożone relacje wiele-do-wielu. W miarę rozwoju aplikacji dodawane są nowe relacje.
- Musisz analizować połączone dane i relacje.
- Chcesz użyć warunków wyszukiwania T-SQL specyficznych dla grafu, takich jak SHORTEST_PATH.
Funkcje JSON
W produktach Azure SQL można analizować i wykonywać zapytania dotyczące danych reprezentowanych w formacie JavaScript Object Notation (JSON) i eksportować dane relacyjne jako tekst JSON. JSON to podstawowa funkcja aparatu bazy danych programu SQL Server.
Funkcje JSON umożliwiają umieszczanie dokumentów JSON w tabelach, przekształcanie danych relacyjnych w dokumenty JSON i przekształcanie dokumentów JSON w dane relacyjne. Do analizowania dokumentów można użyć standardowego języka Transact-SQL rozszerzonego za pomocą funkcji JSON. Można również użyć indeksów nieklasterowanych, indeksów magazynu kolumn lub tabel zoptymalizowanych pod kątem pamięci, aby zoptymalizować zapytania.
JSON to popularny format danych do wymiany danych w nowoczesnych aplikacjach internetowych i mobilnych. Kod JSON jest również używany do przechowywania danych częściowo struktury w plikach dziennika lub w bazach danych NoSQL. Wiele usług internetowych REST zwraca wyniki sformatowane jako tekst JSON lub akceptują dane sformatowane jako JSON.
Większość usług platformy Azure ma punkty końcowe REST, które zwracają lub używają kodu JSON. Te usługi obejmują usługę Azure Cognitive Search, usługę Azure Storage i usługę Azure Cosmos DB.
Jeśli masz tekst JSON, możesz wyodrębnić dane z formatu JSON lub sprawdzić, czy kod JSON jest poprawnie sformatowany przy użyciu wbudowanych funkcji JSON_VALUE, JSON_QUERY i ISJSON. Inne funkcje to:
- JSON_MODIFY: umożliwia aktualizowanie wartości wewnątrz tekstu JSON.
- OPENJSON: może przekształcić tablicę obiektów JSON w zestaw wierszy w celu uzyskania bardziej zaawansowanych zapytań i analizy. Każde zapytanie SQL można wykonać na zwróconym zestawie wyników.
- W formacie JSON: umożliwia formatowanie danych przechowywanych w tabelach relacyjnych jako tekst JSON.
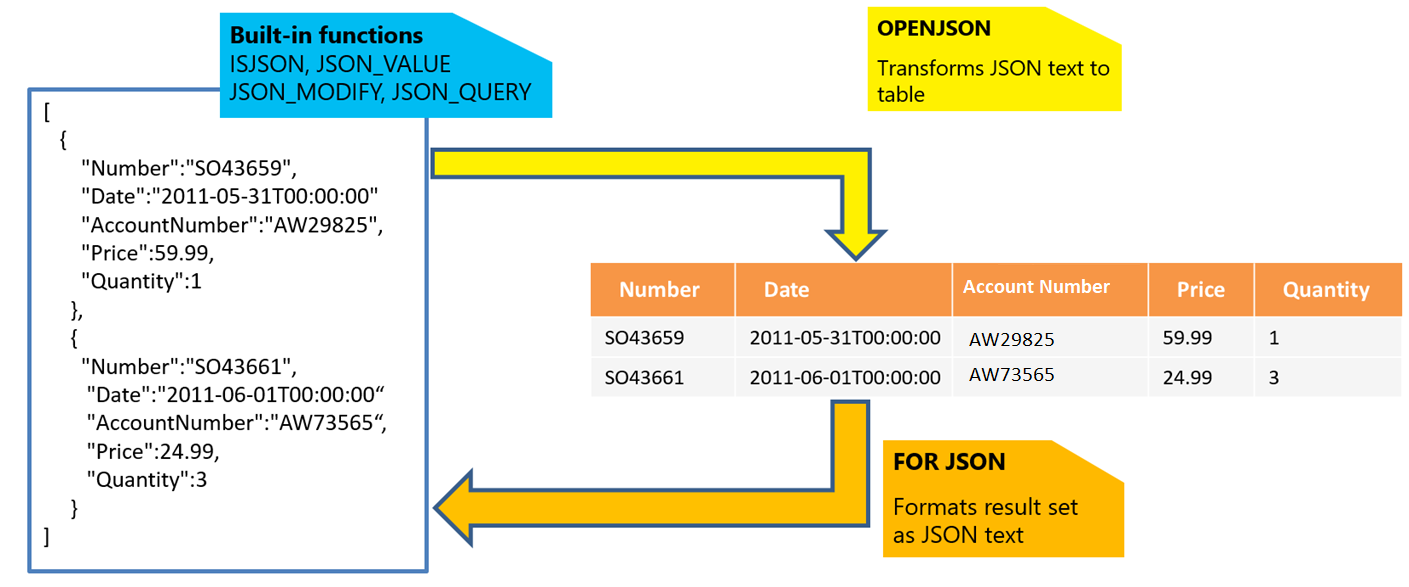
Aby uzyskać więcej informacji, zobacz How to work with JSON data (Jak pracować z danymi JSON).
Modele dokumentów można używać zamiast modeli relacyjnych w niektórych konkretnych scenariuszach:
- Wysoka normalizacja schematu nie przynosi znaczących korzyści, ponieważ uzyskujesz dostęp do wszystkich pól obiektów jednocześnie lub nigdy nie aktualizujesz znormalizowanych części obiektów. Jednak znormalizowany model zwiększa złożoność zapytań, ponieważ należy połączyć dużą liczbę tabel w celu pobrania danych.
- Pracujesz z aplikacjami, które natywnie używają dokumentów JSON do komunikacji lub modeli danych i nie chcesz wprowadzać większej liczby warstw, które przekształcają dane relacyjne w format JSON i odwrotnie.
- Aby uprościć model danych, należy zdenormalizować tabele podrzędne lub wzorce Entity-Object-Value.
- Musisz załadować lub wyeksportować dane przechowywane w formacie JSON bez dodatkowego narzędzia, które analizuje dane.
Funkcje XML
Funkcje XML umożliwiają przechowywanie i indeksowanie danych XML w bazie danych oraz używanie natywnych operacji XQuery/XPath do pracy z danymi XML. Produkty Azure SQL mają wyspecjalizowany, wbudowany typ danych XML i funkcje zapytań, które przetwarzają dane XML.
Aparat bazy danych programu SQL Server udostępnia zaawansowaną platformę do tworzenia aplikacji do zarządzania danymi częściowo ze strukturą. Obsługa kodu XML jest zintegrowana ze wszystkimi składnikami aparatu bazy danych i obejmuje:
- Możliwość przechowywania wartości XML natywnie w kolumnie typu danych XML, którą można wpisać zgodnie z kolekcją schematów XML lub pozostawioną bez typu. Możesz indeksować kolumnę XML.
- Możliwość określenia zapytania XQuery względem danych XML przechowywanych w kolumnach i zmiennych typu XML. Funkcji XQuery można używać w dowolnym zapytaniu Języka Transact-SQL, które uzyskuje dostęp do modelu danych używanego w bazie danych.
- Automatyczne indeksowanie wszystkich elementów w dokumentach XML przy użyciu podstawowego indeksu XML. Możesz też określić dokładne ścieżki, które mają być indeksowane przy użyciu pomocniczego indeksu XML.
OPENROWSET, który umożliwia zbiorcze ładowanie danych XML.- Możliwość przekształcania danych relacyjnych w format XML.
Modele dokumentów można używać zamiast modeli relacyjnych w niektórych konkretnych scenariuszach:
- Wysoka normalizacja schematu nie przynosi znaczących korzyści, ponieważ uzyskujesz dostęp do wszystkich pól obiektów jednocześnie lub nigdy nie aktualizujesz znormalizowanych części obiektów. Jednak znormalizowany model zwiększa złożoność zapytań, ponieważ należy połączyć dużą liczbę tabel w celu pobrania danych.
- Pracujesz z aplikacjami, które natywnie używają dokumentów XML do komunikacji lub modeli danych, i nie chcesz wprowadzać większej liczby warstw, które przekształcają dane relacyjne w format JSON i odwrotnie.
- Aby uprościć model danych, należy zdenormalizować tabele podrzędne lub wzorce Entity-Object-Value.
- Musisz załadować lub wyeksportować dane przechowywane w formacie XML bez dodatkowego narzędzia, które analizuje dane.
Funkcje przestrzenne
Dane przestrzenne reprezentują informacje o fizycznej lokalizacji i kształcie obiektów. Obiekty te mogą być lokalizacjami punktowymi lub bardziej złożonymi obiektami, takimi jak kraje/regiony, drogi lub jeziora.
Usługa Azure SQL obsługuje dwa typy danych przestrzennych:
- Typ geometrii reprezentuje dane w euklidesowym (płaskim) układzie współrzędnych.
- Typ geografii reprezentuje dane w układzie współrzędnych okrągłych ziemi.
Funkcje przestrzenne w usłudze Azure SQL umożliwiają przechowywanie danych geometrycznych i geograficznych. Obiekty przestrzenne w usłudze Azure SQL umożliwiają analizowanie i wykonywanie zapytań dotyczących danych reprezentowanych w formacie JSON oraz eksportowanie danych relacyjnych jako tekstu JSON. Te obiekty przestrzenne obejmują punkty, ciągi liniowe i wielokąt. Usługa Azure SQL udostępnia również wyspecjalizowane indeksy przestrzenne, których można użyć do poprawy wydajności zapytań przestrzennych.
Obsługa przestrzenna to podstawowa funkcja aparatu bazy danych programu SQL Server.
Pary klucz-wartość
Produkty Azure SQL nie mają wyspecjalizowanych typów ani struktur, które obsługują pary klucz-wartość, ponieważ struktury klucz-wartość mogą być natywnie reprezentowane jako standardowe tabele relacyjne:
CREATE TABLE Collection (
Id int identity primary key,
Data nvarchar(max)
)
Tę strukturę klucz-wartość można dostosować do własnych potrzeb bez żadnych ograniczeń. Na przykład wartość może być dokumentem XML zamiast nvarchar(max) typu. Jeśli wartość jest dokumentem JSON, możesz użyć CHECK ograniczenia sprawdzającego ważność zawartości JSON. W dodatkowych kolumnach można umieścić dowolną liczbę wartości związanych z jednym kluczem. Na przykład:
- Dodaj obliczone kolumny i indeksy, aby uprościć i zoptymalizować dostęp do danych.
- Zdefiniuj tabelę jako tabelę zoptymalizowaną pod kątem pamięci, tylko schemat, aby uzyskać lepszą wydajność.
Aby zapoznać się z przykładem efektywnego użycia modelu relacyjnego jako rozwiązania pary klucz-wartość, zobacz Jak bwin używa metody OLTP w pamięci programu SQL Server 2016 w celu osiągnięcia bezprecedensowej wydajności i skali. W tym badaniu przypadku bwin użył modelu relacyjnego dla swojego rozwiązania ASP.NET buforowania, aby osiągnąć 1,2 miliona partii na sekundę.
Następne kroki
Funkcje wielomodelowe to podstawowe funkcje aparatu bazy danych programu SQL Server, które są współużytkowane przez produkty Azure SQL. Aby dowiedzieć się więcej o tych funkcjach, zobacz następujące artykuły:
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla