Operacje uczenia maszynowego
Operacje uczenia maszynowego (nazywane również metodyką MLOps) to stosowanie zasad metodyki DevOps do aplikacji z obsługą sztucznej inteligencji. Aby zaimplementować operacje uczenia maszynowego w organizacji, muszą istnieć określone umiejętności, procesy i technologia. Celem jest dostarczanie niezawodnych, skalowalnych, niezawodnych i zautomatyzowanych rozwiązań uczenia maszynowego.
W tym artykule dowiesz się, jak planować zasoby do obsługi operacji uczenia maszynowego na poziomie organizacji. Zapoznaj się z najlepszymi rozwiązaniami i zaleceniami opartymi na używaniu usługi Azure Machine Edukacja do wdrażania operacji uczenia maszynowego w przedsiębiorstwie.
Co to są operacje uczenia maszynowego?
Nowoczesne algorytmy i struktury uczenia maszynowego ułatwiają opracowywanie modeli, które mogą tworzyć dokładne przewidywania. Operacje uczenia maszynowego to ustrukturyzowany sposób dołączania uczenia maszynowego do tworzenia aplikacji w przedsiębiorstwie.
W przykładowym scenariuszu utworzono model uczenia maszynowego, który przekracza wszystkie oczekiwania dotyczące dokładności i imponuje sponsorom biznesowym. Teraz nadszedł czas, aby wdrożyć model w środowisku produkcyjnym, ale może to nie być tak proste, jak oczekiwano. Organizacja prawdopodobnie będzie musiała dysponować osobami, procesami i technologią, zanim będzie mogła korzystać z modelu uczenia maszynowego w środowisku produkcyjnym.
Z czasem ty lub współpracownik może opracować nowy model, który działa lepiej niż oryginalny model. Zastąpienie modelu uczenia maszynowego używanego w środowisku produkcyjnym wprowadza pewne obawy, które są ważne dla organizacji:
- Nowy model należy zaimplementować bez zakłócania operacji biznesowych, które opierają się na wdrożonym modelu.
- W celach regulacyjnych może być wymagane wyjaśnienie przewidywań modelu lub ponowne utworzenie modelu, jeśli nietypowe lub stronnicze przewidywania wynikają z danych w nowym modelu.
- Dane używane w trenowaniu i modelu uczenia maszynowego mogą ulec zmianie w czasie. W przypadku zmian w danych może być konieczne okresowe ponowne trenowanie modelu w celu zachowania dokładności przewidywania. Osoba lub rola musi mieć przypisaną odpowiedzialność za podawanie danych, monitorowanie wydajności modelu, ponowne trenowanie modelu i naprawianie modelu w razie awarii.
Załóżmy, że masz aplikację, która obsługuje przewidywania modelu za pośrednictwem interfejsu API REST. Nawet prosty przypadek użycia, taki jak ten, może powodować problemy w środowisku produkcyjnym. Zaimplementowanie strategii operacji uczenia maszynowego może pomóc w rozwiązaniu problemów z wdrażaniem i obsłudze operacji biznesowych opartych na aplikacjach z obsługą sztucznej inteligencji.
Niektóre zadania operacji uczenia maszynowego dobrze pasują do ogólnej struktury DevOps. Przykłady obejmują konfigurowanie testów jednostkowych i testów integracji oraz śledzenie zmian przy użyciu kontroli wersji. Inne zadania są bardziej unikatowe dla operacji uczenia maszynowego i mogą obejmować:
- Włącz ciągłe eksperymentowanie i porównanie z modelem odniesienia.
- Monitorowanie danych przychodzących w celu wykrywania dryfu danych.
- Wyzwalanie ponownego trenowania modelu i konfigurowanie wycofywania na potrzeby odzyskiwania po awarii.
- Tworzenie potoków danych wielokrotnego użytku na potrzeby trenowania i oceniania.
Celem operacji uczenia maszynowego jest zamknięcie luki między programowaniem a produkcją i szybsze dostarczanie wartości klientom. Aby osiągnąć ten cel, należy przemyśleć tradycyjne procesy programistyczne i produkcyjne.
Nie wszystkie wymagania dotyczące operacji uczenia maszynowego w organizacji są takie same. Architektura operacji uczenia maszynowego dużego, wielonarodowego przedsiębiorstwa prawdopodobnie nie będzie tą samą infrastrukturą, którą ustanawia mały startup. Organizacje zazwyczaj zaczynają się od małych i rozwija się w miarę rozwoju dojrzałości, katalogu modeli i doświadczenia.
Model dojrzałości operacji uczenia maszynowego może ułatwić sprawdzenie, gdzie twoja organizacja znajduje się w skali dojrzałości operacji uczenia maszynowego i pomoże Ci zaplanować przyszły rozwój.
Operacje uczenia maszynowego a metodyka DevOps
Operacje uczenia maszynowego różnią się od metodyki DevOps w kilku kluczowych obszarach. Operacje uczenia maszynowego mają następujące cechy:
- Eksploracja poprzedza rozwój i operacje.
- Cykl życia nauki o danych wymaga adaptacyjnego sposobu pracy.
- Limity dotyczące postępu jakości danych i limitu dostępności.
- Wymagany jest większy nakład pracy operacyjnej niż w metodyce DevOps.
- Zespoły robocze wymagają specjalistów i ekspertów z dziedziny.
Aby zapoznać się z podsumowaniem, zapoznaj się z siedmioma zasadami operacji uczenia maszynowego.
Eksploracja poprzedza programowanie i operacje
Projekty nauki o danych różnią się od projektów programistycznych aplikacji lub inżynierii danych. Projekt nauki o danych może sprawić, że zostanie on wdrożona w środowisku produkcyjnym, ale często więcej kroków jest zaangażowanych niż w tradycyjnym wdrożeniu. Po wstępnej analizie może się okazać, że wynik biznesowy nie może zostać osiągnięty przy użyciu dostępnych zestawów danych. Bardziej szczegółowa faza eksploracji zwykle jest pierwszym krokiem w projekcie nauki o danych.
Celem fazy eksploracji jest zdefiniowanie i udoskonalenie problemu. W tej fazie analitycy danych uruchamiają eksploracyjne analizy danych. Używają statystyk i wizualizacji, aby potwierdzić lub sfałszować hipotezy problemu. Uczestnicy projektu powinni zrozumieć, że projekt może nie wykraczać poza tę fazę. Jednocześnie ważne jest, aby ta faza była tak bezproblemowa, jak to możliwe w przypadku szybkiego zwrotu. Chyba że problem do rozwiązania obejmuje element zabezpieczeń, należy unikać ograniczania fazy eksploracyjnej z procesami i procedurami. Analitycy danych powinni mieć możliwość pracy z preferowanymi narzędziami i danymi. Rzeczywiste dane są potrzebne do pracy eksploracyjnej.
Projekt może przejść do etapów eksperymentowania i programowania, gdy uczestnicy projektu są pewni, że projekt nauki o danych jest wykonalny i może zapewnić rzeczywistą wartość biznesową. Na tym etapie praktyki programistyczne stają się coraz ważniejsze. Dobrym rozwiązaniem jest przechwytywanie metryk dla wszystkich eksperymentów wykonywanych na tym etapie. Ważne jest również włączenie kontroli źródła, aby można było porównać modele i przełączać się między różnymi wersjami kodu.
Działania programistyczne obejmują refaktoryzacja, testowanie i automatyzowanie kodu eksploracji w powtarzalnych potokach eksperymentowania. Aby obsługiwać modele, organizacja musi tworzyć aplikacje i potoki. Refaktoryzacja kodu w modułowych składnikach i bibliotekach ułatwia zwiększenie możliwości ponownego wykorzystania, testowania i optymalizacji wydajności.
Na koniec potoki wnioskowania wsadowego lub aplikacji, które obsługują modele, są wdrażane w środowiskach przejściowych lub produkcyjnych. Oprócz monitorowania niezawodności i wydajności infrastruktury, takiej jak w przypadku standardowej aplikacji, we wdrożeniu modelu uczenia maszynowego należy stale monitorować jakość danych, profil danych i model pod kątem pogorszenia lub dryfu. Modele uczenia maszynowego wymagają również ponownego trenowania w czasie, aby zachować odpowiednie znaczenie w zmieniającym się środowisku.
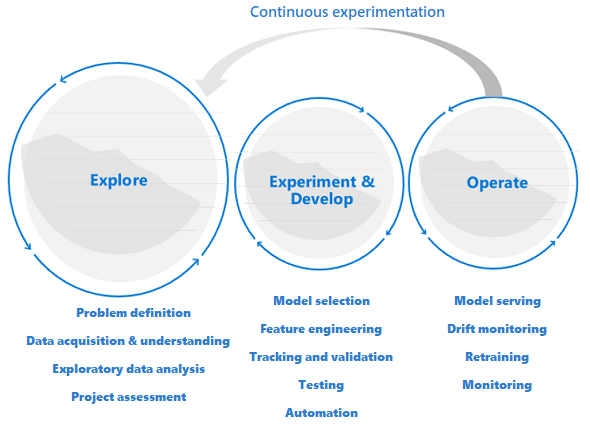
Cykl życia nauki o danych wymaga adaptacyjnego sposobu pracy
Ponieważ charakter i jakość danych początkowo są niepewne, możesz nie osiągnąć celów biznesowych, jeśli zastosujesz typowy proces DevOps do projektu nauki o danych. Eksploracja i eksperymentowanie to cykliczne działania i potrzeby w całym procesie uczenia maszynowego. Zespoły w firmie Microsoft używają cyklu życia projektu i procesu roboczego, który odzwierciedla charakter działań specyficznych dla nauki o danych. Proces Nauka o danych zespołu i proces cyklu życia Nauka o danych to przykłady implementacji referencyjnych.
Limity dotyczące postępu jakości danych i limitu dostępności
Aby zespół uczenia maszynowego skutecznie opracowywał aplikacje z obsługą uczenia maszynowego, preferowany jest dostęp do danych produkcyjnych we wszystkich odpowiednich środowiskach roboczych. Jeśli dostęp do danych produkcyjnych nie jest możliwy ze względu na wymagania dotyczące zgodności lub ograniczenia techniczne, rozważ zaimplementowanie kontroli dostępu opartej na rolach (RBAC) platformy Azure za pomocą usługi Azure Machine Edukacja, dostępu just in time lub potoków przenoszenia danych w celu utworzenia produkcyjnych replik danych i zwiększenia produktywności użytkowników.
Uczenie maszynowe wymaga większego nakładu pracy operacyjnej
W przeciwieństwie do tradycyjnego oprogramowania wydajność rozwiązania uczenia maszynowego jest stale zagrożona, ponieważ rozwiązanie zależy od jakości danych. Aby zachować jakościowe rozwiązanie w środowisku produkcyjnym, ważne jest, aby stale monitorować i ponownie oceniane zarówno dane, jak i jakość modelu. Oczekuje się, że model produkcyjny wymaga terminowego ponownego trenowania, ponownego wdrażania i dostrajania. Te zadania obejmują codzienne wymagania dotyczące zabezpieczeń, monitorowania infrastruktury i zgodności oraz wymagają specjalistycznej wiedzy.
Zespoły uczenia maszynowego wymagają specjalistów i ekspertów z dziedziny
Mimo że projekty nauki o danych współdzielą role z regularnymi projektami IT, sukces wysiłku uczenia maszynowego bardzo zależy od posiadania podstawowych specjalistów ds. technologii uczenia maszynowego i ekspertów z dziedziny dziedziny. Specjalista ds. technologii ma odpowiednie doświadczenie, aby wykonać kompleksowe eksperymenty uczenia maszynowego. Ekspert w dziedzinie może wspierać specjalistę, analizując i syntetyzując dane lub kwalifikując dane do użycia.
Typowe role techniczne, które są unikatowe dla projektów nauki o danych, to ekspert domeny, inżynier danych, analityk danych, inżynier sztucznej inteligencji, moduł sprawdzania poprawności modelu i inżynier uczenia maszynowego. Aby dowiedzieć się więcej o rolach i zadaniach w typowym zespole nauki o danych, zobacz Team Nauka o danych Process (Proces zespołu Nauka o danych).
Siedem zasad dotyczących operacji uczenia maszynowego
Jeśli planujesz wdrożyć operacje uczenia maszynowego w organizacji, rozważ zastosowanie następujących podstawowych zasad jako podstawy:
Użyj kontroli wersji dla danych wyjściowych kodu, danych i eksperymentów. W przeciwieństwie do tradycyjnego tworzenia oprogramowania dane mają bezpośredni wpływ na jakość modeli uczenia maszynowego. Należy wersję bazy kodu eksperymentowania, ale także wersję zestawów danych, aby upewnić się, że można odtworzyć eksperymenty lub wyniki wnioskowania. Wersjonowanie danych wyjściowych eksperymentowania, takich jak modele, może zaoszczędzić nakład pracy i koszt obliczeniowy ponownego ich tworzenia.
Użyj wielu środowisk. Aby oddzielić programowanie i testowanie od pracy produkcyjnej, zreplikuj infrastrukturę w co najmniej dwóch środowiskach. Kontrola dostępu dla użytkowników może być inna dla każdego środowiska.
Zarządzaj infrastrukturą i konfiguracjami jako kodem. Podczas tworzenia i aktualizowania składników infrastruktury w środowiskach roboczych należy używać infrastruktury jako kodu, aby niespójności nie opracowywały się w środowiskach. Zarządzaj specyfikacjami zadań eksperymentu uczenia maszynowego jako kodem, aby można było łatwo ponownie uruchomić i ponownie użyć wersji eksperymentu w wielu środowiskach.
Śledzenie eksperymentów uczenia maszynowego i zarządzanie nimi. Śledzenie kluczowych wskaźników wydajności i innych artefaktów dla eksperymentów uczenia maszynowego. Gdy zachowasz historię wydajności zadań, możesz przeprowadzić analizę ilościową sukcesu eksperymentowania i zwiększyć współpracę zespołową i elastyczność.
Przetestuj kod, zweryfikuj integralność danych i zapewnij jakość modelu.Przetestuj bazę kodu eksperymentowania, aby uzyskać poprawne funkcje przygotowywania i wyodrębniania funkcji, integralności danych i wydajności modelu.
Ciągła integracja i dostarczanie uczenia maszynowego. Użyj ciągłej integracji (CI), aby zautomatyzować testowanie dla twojego zespołu. Uwzględnij trenowanie modelu w ramach potoków ciągłego trenowania. Uwzględnij testy A/B w ramach wydania, aby upewnić się, że tylko model jakościowy jest używany w środowisku produkcyjnym.
Monitorowanie usług, modeli i danych. W przypadku obsługi modeli w środowisku operacyjnym uczenia maszynowego kluczowe znaczenie ma monitorowanie usług pod kątem czasu działania infrastruktury, zgodności i jakości modelu. Skonfiguruj monitorowanie , aby zidentyfikować dryf danych i modelu oraz zrozumieć, czy wymagane jest ponowne trenowanie. Rozważ skonfigurowanie wyzwalaczy automatycznego ponownego trenowania.
Najlepsze rozwiązania z usługi Azure Machine Edukacja
Usługa Azure Machine Edukacja oferuje usługi zarządzania zasobami, orkiestracji i automatyzacji, które ułatwiają zarządzanie cyklem życia przepływów pracy trenowania i wdrażania modelu uczenia maszynowego. Zapoznaj się z najlepszymi rozwiązaniami i zaleceniami dotyczącymi stosowania operacji uczenia maszynowego w obszarach zasobów osób, procesów i technologii obsługiwanych przez usługę Azure Machine Edukacja.
Osoby
Współpracuj z zespołami projektów, aby jak najlepiej wykorzystać wiedzę specjalistyczną i domenę w organizacji. Skonfiguruj obszary robocze usługi Azure Machine Edukacja dla każdego projektu, aby były zgodne z wymaganiami segregacji przypadków użycia.
Zdefiniuj zestaw obowiązków i zadań jako rolę, aby każdy członek zespołu w zespole ds. operacji uczenia maszynowego mógł zostać przypisany do wielu ról i pełnić wiele ról. Użyj ról niestandardowych na platformie Azure, aby zdefiniować zestaw szczegółowych operacji RBAC platformy Azure dla usługi Azure Machine Edukacja, które mogą wykonywać każda rola.
Standaryzacja cyklu życia projektu i metodologii Agile. Proces Nauka o danych zespołu zawiera implementację cyklu życia referencyjnego.
Zrównoważone zespoły mogą uruchamiać wszystkie etapy operacji uczenia maszynowego, w tym eksplorację, programowanie i operacje.
Przetwarzaj
Standaryzacja szablonu kodu w celu ponownego użycia kodu i skrócenie czasu pracy nad nowym projektem lub gdy nowy członek zespołu dołączy do projektu. Użyj potoków usługi Azure Machine Edukacja, skryptów przesyłania zadań i potoków ciągłej integracji/ciągłego wdrażania jako podstawy dla nowych szablonów.
Użyj kontroli wersji. Zadania przesyłane z folderu opartego na usłudze Git automatycznie śledzą metadane repozytorium za pomocą zadania w usłudze Azure Machine Edukacja w celu uzyskania powtarzalności.
Użyj przechowywania wersji dla danych wejściowych i wyjściowych eksperymentów w celu odtworzenia. Użyj usługi Azure Machine Edukacja zestawów danych, zarządzania modelami i funkcji zarządzania środowiskiem, aby ułatwić przechowywanie wersji.
Tworzenie historii przebiegów eksperymentów na potrzeby porównywania, planowania i współpracy. Użyj struktury śledzenia eksperymentów, takiej jak MLflow , aby zbierać metryki.
Ciągłe mierzenie i kontrolowanie jakości pracy zespołu za pośrednictwem ciągłej integracji w oparciu o pełną bazę kodu eksperymentowania.
Zakończenie trenowania na wczesnym etapie procesu, gdy model nie jest zbieżny. Użyj struktury śledzenia eksperymentów i historii uruchamiania w usłudze Azure Machine Edukacja do monitorowania przebiegów zadań.
Definiowanie strategii zarządzania eksperymentami i modelami. Rozważ użycie nazwy, takiej jak mistrz , aby odwołać się do bieżącego modelu odniesienia. Model challenger to model kandydata, który może przewyższać model mistrzowski w środowisku produkcyjnym. Stosowanie tagów w usłudze Azure Machine Edukacja w celu oznaczania eksperymentów i modeli. W scenariuszu, na przykład prognozowania sprzedaży, może upłynąć kilka miesięcy, aby ustalić, czy przewidywania modelu są dokładne.
Podnieś poziom ciągłej integracji na potrzeby ciągłego trenowania, włączając trenowanie modelu w kompilacji. Na przykład rozpocznij trenowanie modelu w pełnym zestawie danych przy użyciu każdego żądania ściągnięcia.
Skróć czas potrzebny na uzyskanie opinii na temat jakości potoku uczenia maszynowego, uruchamiając zautomatyzowaną kompilację na przykładzie danych. Parametry potoku usługi Azure Machine Edukacja umożliwiają sparametryzowanie wejściowych zestawów danych.
Użyj ciągłego wdrażania (CD) dla modeli uczenia maszynowego, aby zautomatyzować wdrażanie i testowanie usług oceniania w czasie rzeczywistym w środowiskach platformy Azure.
W niektórych branżach regulowanych może być wymagane wykonanie kroków weryfikacji modelu przed użyciem modelu uczenia maszynowego w środowisku produkcyjnym. Automatyzacja kroków weryfikacji może przyspieszyć czas dostarczania. Jeśli kroki ręcznego przeglądu lub weryfikacji są nadal wąskim gardłem, należy rozważyć, czy możesz certyfikować potok zautomatyzowanego sprawdzania poprawności modelu. Użyj tagów zasobów w usłudze Azure Machine Edukacja, aby wskazać zgodność zasobów i kandydatów do przeglądu lub jako wyzwalaczy wdrożenia.
Nie szkol ponownie w środowisku produkcyjnym, a następnie bezpośrednio zastąp model produkcyjny bez przeprowadzania testów integracji. Mimo że wymagania dotyczące wydajności i funkcjonalności modelu mogą wydawać się dobre, między innymi potencjalne problemy, model ponownie trenowany może mieć większy wpływ na środowisko i przerwać środowisko serwera.
Gdy dostęp do danych produkcyjnych jest dostępny tylko w środowisku produkcyjnym, użyj kontroli dostępu opartej na rolach platformy Azure i ról niestandardowych, aby nadać wybranej liczbie praktyków uczenia maszynowego dostęp do odczytu. Niektóre role mogą wymagać odczytania danych w celu eksploracji powiązanych danych. Alternatywnie udostępnij kopię danych w środowiskach nieprodukcyjnych.
Zgadzam się na konwencje nazewnictwa i tagi dla eksperymentów usługi Azure Machine Edukacja, aby odróżnić potoki uczenia maszynowego od pracy eksperymentalnej.
Technologia
Jeśli obecnie przesyłasz zadania za pośrednictwem interfejsu użytkownika lub interfejsu wiersza polecenia usługi Azure Machine Edukacja Studio, zamiast przesyłać zadania za pośrednictwem zestawu SDK, użyj interfejsu wiersza polecenia lub usługi Azure DevOps Machine Edukacja zadań w celu skonfigurowania kroków potoku automatyzacji. Ten proces może zmniejszyć ślad kodu, ponownie używając tych samych przesłanych zadań bezpośrednio z potoków automatyzacji.
Używanie programowania opartego na zdarzeniach. Na przykład wyzwalanie potoku testowania modelu offline przy użyciu usługi Azure Functions po zarejestrowaniu nowego modelu. Możesz też wysłać powiadomienie do wyznaczonego aliasu wiadomości e-mail, gdy nie można uruchomić potoku krytycznego. Usługa Azure Machine Edukacja tworzy zdarzenia w usłudze Azure Event Grid. Wiele ról może subskrybować, aby otrzymywać powiadomienia o zdarzeniu.
W przypadku korzystania z usługi Azure DevOps do automatyzacji użyj usługi Azure DevOps Tasks for Machine Edukacja, aby używać modeli uczenia maszynowego jako wyzwalaczy potoku.
Podczas tworzenia pakietów języka Python dla aplikacji uczenia maszynowego można je hostować w repozytorium Usługi Azure DevOps jako artefakty i publikować je jako źródło danych. Korzystając z tego podejścia, można zintegrować przepływ pracy DevOps na potrzeby tworzenia pakietów z obszarem roboczym usługi Azure Machine Edukacja.
Rozważ użycie środowiska przejściowego do testowania integracji systemu potoku uczenia maszynowego z składnikami aplikacji nadrzędnych lub podrzędnych.
Tworzenie testów jednostkowych i integracyjnych dla punktów końcowych wnioskowania na potrzeby rozszerzonego debugowania i przyspieszanie wdrażania.
Aby wyzwolić ponowne trenowanie, użyj monitorów zestawu danych i przepływów pracy opartych na zdarzeniach. Subskrybowanie zdarzeń dryfu danych i automatyzowanie wyzwalacza potoków uczenia maszynowego na potrzeby ponownego trenowania.
Fabryka sztucznej inteligencji na potrzeby operacji uczenia maszynowego organizacji
Zespół ds. nauki o danych może zdecydować, że może wewnętrznie zarządzać wieloma przypadkami użycia uczenia maszynowego. Wdrażanie operacji uczenia maszynowego pomaga organizacji skonfigurować zespoły projektów w celu uzyskania lepszej jakości, niezawodności i możliwości utrzymania rozwiązań. Dzięki zrównoważonym zespołom, obsługiwanym procesom i automatyzacji technologii zespół, który przyjmuje operacje uczenia maszynowego, może skalować i skupiać się na tworzeniu nowych przypadków użycia.
Wraz ze wzrostem liczby przypadków użycia w organizacji obciążenie związane z zarządzaniem przypadkami użycia rośnie liniowo lub jeszcze bardziej. Wyzwanie dla organizacji staje się tym, jak przyspieszyć czas wprowadzenia na rynek, przyspieszyć ocenę możliwości przypadków użycia, zaimplementować powtarzalność i jak najlepiej wykorzystać dostępne zasoby i zestawy umiejętności w wielu projektach. W wielu organizacjach opracowywanie fabryki sztucznej inteligencji jest rozwiązaniem.
Fabryka sztucznej inteligencji to system powtarzalnych procesów biznesowych i ustandaryzowanych artefaktów ułatwiających opracowywanie i wdrażanie dużego zestawu przypadków użycia uczenia maszynowego. Fabryka sztucznej inteligencji optymalizuje konfigurację zespołu, zalecane rozwiązania, strategię operacji uczenia maszynowego, wzorce architektury i szablony wielokrotnego użytku dostosowane do wymagań biznesowych.
Pomyślna fabryka sztucznej inteligencji opiera się na powtarzalnych procesach i zasobach wielokrotnego użytku, aby pomóc organizacji w wydajnym skalowaniu z dziesiątek przypadków użycia do tysięcy przypadków użycia.
Na poniższej ilustracji przedstawiono podsumowanie kluczowych elementów fabryki sztucznej inteligencji:

Standaryzacja powtarzalnych wzorców architektury
Powtarzalność to kluczowa cecha fabryki sztucznej inteligencji. Zespoły nauki o danych mogą przyspieszyć opracowywanie projektów i poprawić spójność w projektach, opracowując kilka powtarzalnych wzorców architektury, które obejmują większość przypadków użycia uczenia maszynowego w organizacji. Gdy te wzorce są w miejscu, większość projektów może używać wzorców, aby uzyskać następujące korzyści:
- Faza przyspieszonego projektowania
- Przyspieszone zatwierdzenia ze strony zespołów IT i zabezpieczeń podczas ponownego używania narzędzi w projektach
- Przyspieszone programowanie z powodu infrastruktury wielokrotnego użytku jako szablonów kodu i szablonów projektów
Wzorce architektury mogą obejmować, ale nie są ograniczone do następujących tematów:
- Preferowane usługi dla każdego etapu projektu
- Łączność danych i nadzór
- Strategia operacji uczenia maszynowego dopasowana do wymagań branżowych, biznesowych lub klasyfikacji danych
- Modele mistrzów zarządzania eksperymentami i pretendentów
Ułatwianie współpracy między zespołami i udostępniania
Udostępnione repozytoria kodu i narzędzia mogą przyspieszyć opracowywanie rozwiązań uczenia maszynowego. Repozytoria kodu można opracowywać w modularny sposób podczas opracowywania projektu, aby były one wystarczająco ogólne, aby były używane w innych projektach. Można je udostępnić w centralnym repozytorium, do którego mogą uzyskiwać dostęp wszyscy zespoły ds. nauki o danych.
Udostępnianie i ponowne używanie własności intelektualnej
Aby zmaksymalizować ponowne użycie kodu, zapoznaj się z następującą własnością intelektualną na początku projektu:
- Kod wewnętrzny, który został zaprojektowany do ponownego użycia w organizacji. Przykłady obejmują pakiety i moduły.
- Zestawy danych utworzone w innych projektach uczenia maszynowego lub dostępne w ekosystemie platformy Azure.
- Istniejące projekty nauki o danych, które mają podobną architekturę i problemy biznesowe.
- Repozytoria GitHub lub repozytoria open source, które mogą przyspieszyć projekt.
Każda retrospektywa projektu powinna zawierać element akcji, aby określić, czy elementy projektu mogą być współużytkowane i uogólnione w celu szerszego ponownego użycia. Lista zasobów, które organizacja może udostępniać i ponownie rozszerzać w czasie.
Aby ułatwić udostępnianie i odnajdywanie, wiele organizacji wprowadziło repozytoria udostępnione w celu organizowania fragmentów kodu i artefaktów uczenia maszynowego. Artefakty w usłudze Azure Machine Edukacja, w tym zestawy danych, modele, środowiska i potoki, można zdefiniować jako kod, aby umożliwić efektywne udostępnianie ich w projektach i obszarach roboczych.
Szablony projektu
Aby przyspieszyć proces migracji istniejących rozwiązań i zmaksymalizować ponowne użycie kodu, wiele organizacji standandaryzuje szablon projektu w celu rozpoczęcia nowych projektów. Przykłady szablonów projektów zalecanych do użycia z usługą Azure Machine Edukacja to przykłady usługi Azure Machine Edukacja, proces cyklu życia Nauka o danych oraz proces Nauka o danych zespołu.
Centralne zarządzanie danymi
Proces uzyskiwania dostępu do danych na potrzeby eksploracji lub użycia produkcyjnego może być czasochłonny. Wiele organizacji centralizuje zarządzanie danymi, aby połączyć producentów danych i użytkowników danych w celu ułatwienia dostępu do danych na potrzeby eksperymentowania z uczeniem maszynowym.
Udostępnione narzędzia
Twoja organizacja może używać scentralizowanych pulpitów nawigacyjnych w całym przedsiębiorstwie do konsolidacji informacji rejestrowania i monitorowania. Pulpity nawigacyjne mogą obejmować rejestrowanie błędów, dostępność usługi i dane telemetryczne oraz monitorowanie wydajności modelu.
Użyj metryk usługi Azure Monitor, aby utworzyć pulpit nawigacyjny dla usługi Azure Machine Edukacja i skojarzonych usług, takich jak Azure Storage. Pulpit nawigacyjny ułatwia śledzenie postępu eksperymentowania, kondycji infrastruktury obliczeniowej i wykorzystania limitu przydziału procesora GPU.
Wyspecjalizowany zespół inżynierów uczenia maszynowego
Wiele organizacji wdrożyło rolę inżyniera uczenia maszynowego. Inżynier uczenia maszynowego specjalizuje się w tworzeniu i uruchamianiu niezawodnych potoków uczenia maszynowego, monitorowania dryfu i ponownego trenowania przepływów pracy oraz monitorowania pulpitów nawigacyjnych. Inżynier ponosi ogólną odpowiedzialność za uprzemysłowienie rozwiązania uczenia maszynowego, od programowania po produkcję. Inżynier ściśle współpracuje z inżynierami danych, architektami, zabezpieczeniami i operacjami, aby zapewnić, że wszystkie niezbędne mechanizmy kontroli zostaną wprowadzone.
Chociaż nauka o danych wymaga głębokiej wiedzy z dziedziny, inżynieria uczenia maszynowego jest bardziej techniczna w centrum uwagi. Różnica sprawia, że inżynier uczenia maszynowego jest bardziej elastyczny, dzięki czemu może pracować nad różnymi projektami i różnymi działami biznesowymi. Duże praktyki w zakresie nauki o danych mogą korzystać ze specjalistycznego zespołu inżynierów uczenia maszynowego, który zwiększa powtarzalność i ponowne używanie przepływów pracy automatyzacji w różnych przypadkach użycia i obszarach biznesowych.
Włączanie i dokumentacja
Ważne jest, aby zapewnić jasne wskazówki dotyczące procesu fabryki sztucznej inteligencji dla nowych i istniejących zespołów i użytkowników. Wskazówki pomagają zapewnić spójność i zmniejszyć nakład pracy wymagany przez zespół inżynierów uczenia maszynowego podczas przemysłowego projektowania. Rozważ projektowanie zawartości specjalnie dla różnych ról w organizacji.
Każdy ma unikatowy sposób uczenia się, więc kombinacja następujących typów wskazówek może pomóc przyspieszyć wdrażanie struktury fabryki sztucznej inteligencji:
- Centrum, które zawiera łącza do wszystkich artefaktów. Na przykład to centrum może być kanałem w usłudze Microsoft Teams lub witrynie programu Microsoft SharePoint.
- Trenowanie i plan włączania przeznaczony dla każdej roli.
- Ogólne podsumowanie prezentacji podejścia i wideo towarzyszącego.
- Szczegółowy dokument lub podręcznik.
- Filmy wideo z instrukcjami.
- Oceny gotowości.
Operacje uczenia maszynowego w serii wideo platformy Azure
Seria wideo przedstawiająca operacje uczenia maszynowego na platformie Azure pokazuje, jak ustanowić operacje uczenia maszynowego dla rozwiązania uczenia maszynowego— od początkowego programowania do środowiska produkcyjnego.
Etyki
Etyka odgrywa kluczową rolę w projektowaniu rozwiązania sztucznej inteligencji. Jeśli zasady etyczne nie są implementowane, wytrenowane modele mogą wykazywać te same stronniczość, które znajdują się w danych, na których zostały przeszkolone. Może się okazać, że projekt nie zostanie przerwany. Co ważniejsze, reputacja organizacji może być zagrożona.
Aby zapewnić, że kluczowe zasady etyczne, które organizacja oznacza, są implementowane w ramach projektów, organizacja powinna udostępnić listę tych zasad i sposobów ich weryfikacji z perspektywy technicznej podczas fazy testowania. Użyj funkcji uczenia maszynowego w usłudze Azure Machine Edukacja, aby zrozumieć, czym jest odpowiedzialne uczenie maszynowe i jak utworzyć je w operacjach uczenia maszynowego.
Następne kroki
Dowiedz się więcej na temat organizowania i konfigurowania środowisk usługi Azure Machine Edukacja lub obejrzyj praktyczne serie wideo dotyczące operacji uczenia maszynowego na platformie Azure.
Dowiedz się więcej na temat zarządzania budżetami, limitami przydziału i kosztami na poziomie organizacji przy użyciu usługi Azure Machine Edukacja:
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla