Niestandardowe modele analizy dokumentów
Ważne
- Publiczne wersje zapoznawcze analizy dokumentów zapewniają wczesny dostęp do funkcji, które są aktywnie opracowywane.
- Funkcje, podejścia i procesy mogą ulec zmianie przed ogólną dostępnością na podstawie opinii użytkowników.
- Publiczna wersja zapoznawcza bibliotek klienckich usługi Document Intelligence jest domyślna dla interfejsu API REST w wersji 2024-02-29-preview.
- Publiczna wersja zapoznawcza 2024-02-29-preview jest obecnie dostępna tylko w następujących regionach świadczenia usługi Azure:
- Wschodnie stany USA
- Zachodnie stany USA 2
- Europa Zachodnia
Ta zawartość dotyczy:v4.0 (wersja zapoznawcza) | Poprzednie wersje:![]()
![]() v3.1 (GA)v3.0 (GA)
v3.1 (GA)v3.0 (GA)![]()
![]() v2.1 (GA)
v2.1 (GA)
Ta zawartość dotyczy:v3.1 (GA)Najnowsza wersja:![]()
![]() v4.0 (wersja zapoznawcza) | | Poprzednie wersje:
v4.0 (wersja zapoznawcza) | | Poprzednie wersje:![]() v3.0
v3.0![]() v2.1
v2.1
Ta zawartość dotyczy:v3.0 (GA) | Najnowsze wersje:![]()
![]() v4.0 (wersja zapoznawcza)
v4.0 (wersja zapoznawcza)![]() v3.1 | Poprzednia wersja:
v3.1 | Poprzednia wersja:![]() v2.1
v2.1
Ta zawartość dotyczy:v2.1 Najnowsza wersja:![]()
![]() v4.0 (wersja zapoznawcza) |
v4.0 (wersja zapoznawcza) |
Analiza dokumentów używa zaawansowanej technologii uczenia maszynowego do identyfikowania dokumentów, wykrywania i wyodrębniania informacji z formularzy i dokumentów oraz zwracania wyodrębnionych danych w danych wyjściowych ze strukturą JSON. Za pomocą analizy dokumentów można używać modeli analizy dokumentów, wstępnie utworzonych/wstępnie wytrenowanych lub wytrenowanych autonomicznych modeli niestandardowych.
Modele niestandardowe obejmują teraz niestandardowe modele klasyfikacji dla scenariuszy, w których należy zidentyfikować typ dokumentu przed wywołaniem modelu wyodrębniania. Modele klasyfikatora są dostępne od interfejsu 2023-07-31 (GA) API. Model klasyfikacji może być sparowany z niestandardowym modelem wyodrębniania w celu analizowania i wyodrębniania pól z formularzy i dokumentów specyficznych dla Twojej firmy w celu utworzenia rozwiązania do przetwarzania dokumentów. Autonomiczne niestandardowe modele wyodrębniania można łączyć w celu utworzenia modeli złożonych.
Niestandardowe typy modeli dokumentów
Niestandardowe modele dokumentów mogą być jednym z dwóch typów, szablonu niestandardowego lub niestandardowego formularza oraz niestandardowych modeli dokumentów neuronowych lub niestandardowych. Proces etykietowania i trenowania obu modeli jest identyczny, ale modele różnią się w następujący sposób:
Niestandardowe modele wyodrębniania
Aby utworzyć niestandardowy model wyodrębniania, oznacz zestaw danych dokumentów wartościami, które chcesz wyodrębnić i wytrenować model w oznaczonym zestawie danych. Do rozpoczęcia pracy potrzebujesz tylko pięciu przykładów tego samego formularza lub typu dokumentu.
Niestandardowy model neuronowy
Ważne
Począwszy od wersji 4.0 — 2024-02-29-preview API, niestandardowe modele neuronowe obsługują teraz nakładające się pola i tabele, pewność na poziomie wiersza i komórki.
Niestandardowy model neuronowy (niestandardowy dokument) używa modeli uczenia głębokiego i modelu podstawowego przeszkolonego w dużej kolekcji dokumentów. Ten model jest następnie dostrojony lub dostosowany do danych podczas trenowania modelu za pomocą oznaczonego zestawu danych. Niestandardowe modele neuronowe obsługują dokumenty ustrukturyzowane, częściowo ustrukturyzowane i nieustrukturyzowane w celu wyodrębniania pól. Niestandardowe modele neuronowe obsługują obecnie dokumenty w języku angielskim. Po wybraniu między dwoma typami modeli zacznij od modelu neuronowego, aby określić, czy spełnia ona twoje potrzeby funkcjonalne. Zobacz modele neuronowe, aby dowiedzieć się więcej o niestandardowych modelach dokumentów.
Niestandardowy model szablonu
Szablon niestandardowy lub niestandardowy model formularza opiera się na spójnym szablonie wizualizacji w celu wyodrębnienia oznaczonych danych. Wariancja w strukturze wizualnej dokumentów wpływa na dokładność modelu. Formularze ustrukturyzowane, takie jak kwestionariusze lub aplikacje, to przykłady spójnych szablonów wizualnych.
Zestaw szkoleniowy składa się z dokumentów strukturalnych, w których formatowanie i układ są statyczne i stałe z jednego wystąpienia dokumentu do następnego. Niestandardowe modele szablonów obsługują pary klucz-wartość, znaczniki wyboru, tabele, pola podpisu i regiony. Modele szablonów i można je wytrenować na dokumentach w dowolnym z obsługiwanych języków. Aby uzyskać więcej informacji, zobaczniestandardowe modele szablonów.
Jeśli język dokumentów i scenariuszy wyodrębniania obsługuje niestandardowe modele neuronowe, zalecamy użycie niestandardowych modeli neuronowych w modelach szablonów w celu zwiększenia dokładności.
Napiwek
Aby potwierdzić, że dokumenty szkoleniowe przedstawiają spójny szablon wizualizacji, usuń wszystkie dane wprowadzone przez użytkownika z każdego formularza w zestawie. Jeśli puste formularze są identyczne w wyglądzie, reprezentują spójny szablon wizualizacji.
Aby uzyskać więcej informacji, zobaczInterpretowanie i zwiększanie dokładności i pewności dla modeli niestandardowych.
Wymagania dotyczące danych wejściowych
Aby uzyskać najlepsze wyniki, podaj jedno jasne zdjęcie lub wysokiej jakości skanowanie na dokument.
Obsługiwane formaty plików:
Model PDF Obraz:
jpeg/jpg, png, bmp, tiff, heifMicrosoft Office:
Word (docx), Excel (xlsx), PowerPoint (pptx)Przeczytaj ✔ ✔ ✔ Układ ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview i nowsze) Dokument ogólny ✔ ✔ Wstępnie utworzona ✔ ✔ Niestandardowe wyodrębnianie ✔ ✔ Klasyfikacja niestandardowa ✔ ✔ ✔ ✱ Pliki pakietu Microsoft Office nie są obecnie obsługiwane w przypadku innych modeli lub wersji.
W przypadku plików PDF i TIFF można przetworzyć maksymalnie 2000 stron (w przypadku subskrypcji warstwy Bezpłatna przetwarzane są tylko pierwsze dwie strony).
Rozmiar pliku do analizowania dokumentów wynosi 500 MB dla warstwy płatnej (S0) i 4 MB za bezpłatną (F0).
Wymiary obrazu muszą mieć od 50 x 50 pikseli do 10 000 pikseli x 10 000 pikseli.
Jeśli pliki PDF są zablokowane hasłem, przed ich przesłaniem usuń blokadę.
Minimalna wysokość tekstu do wyodrębnienia to 12 pikseli dla obrazu o rozmiarze 1024 x 768 pikseli. Ten wymiar odpowiada około
8-point text na 150 kropek na cal.W przypadku trenowania modelu niestandardowego maksymalna liczba stron dla danych szkoleniowych wynosi 500 dla niestandardowego modelu szablonu i 50 000 dla niestandardowego modelu neuronowego.
W przypadku trenowania niestandardowego modelu wyodrębniania łączny rozmiar danych treningowych wynosi 50 MB dla modelu szablonu i 1G-MB dla modelu neuronowego.
W przypadku trenowania niestandardowego modelu klasyfikacji całkowity rozmiar danych treningowych wynosi
1GBmaksymalnie 10 000 stron.
Tryb kompilacji
Operacja tworzenia niestandardowego modelu dodaje obsługę szablonu i modeli niestandardowych neuronowych. Poprzednie wersje interfejsu API REST i bibliotek klienckich obsługiwały tylko jeden tryb kompilacji, który jest teraz znany jako tryb szablonu.
Modele szablonów akceptują tylko dokumenty, które mają tę samą podstawową strukturę strony — jednolity wygląd wizualny — lub takie samo względne pozycjonowanie elementów w dokumencie.
Modele neuronowe obsługują dokumenty, które mają te same informacje, ale różne struktury stron. Przykłady tych dokumentów obejmują formularze Stany Zjednoczone W2, które mają te same informacje, ale różnią się wyglądem w różnych firmach. Modele neuronowe obsługują obecnie tylko tekst w języku angielskim.
Ta tabela zawiera linki do odwołań do zestawu SDK języka programowania trybu kompilacji i przykładów kodu w witrynie GitHub:
| Język programowania | Dokumentacja zestawu SDK | Przykładowy kod |
|---|---|---|
| C#/.NET | DocumentBuildMode, struktura | Sample_BuildCustomModelAsync.cs |
| Java | DocumentBuildMode, klasa | BuildModel.java |
| JavaScript | Typ DocumentBuildMode | buildModel.js |
| Python | DocumentBuildMode, wyliczenie | sample_build_model.py |
Porównanie funkcji modelu
W poniższej tabeli porównaliśmy szablon niestandardowy i niestandardowe funkcje neuronowe:
| Funkcja | Szablon niestandardowy (formularz) | Niestandardowe neuronowe (dokument) |
|---|---|---|
| Struktura dokumentu | Szablon, formularz i struktura | Ustrukturyzowane, częściowo ustrukturyzowane i nieustrukturyzowane |
| Czas trenowania | Od 1 do 5 minut | Od 20 minut do 1 godziny |
| Wyodrębnianie danych | Pary klucz-wartość, tabele, znaczniki wyboru, współrzędne i podpisy | Pary klucz-wartość, znaczniki wyboru i tabele |
| Nakładające się pola | Nieobsługiwane | Obsługiwane |
| Odmiany dokumentu | Wymaga modelu dla każdej odmiany | Używa pojedynczego modelu dla wszystkich odmian |
| Obsługa języków | Obsługa wielu języków | Obsługa języka angielskiego z obsługą wersji zapoznawczej języka hiszpańskiego, francuskiego, niemieckiego, włoskiego i holenderskiego |
Niestandardowy model klasyfikacji
Klasyfikacja dokumentów to nowy scenariusz obsługiwany przez analizę dokumentów za pomocą interfejsu 2023-07-31 API (wersja 3.1 ogólna dostępność). Interfejs API klasyfikatora dokumentów obsługuje scenariusze klasyfikacji i dzielenia. Trenowanie modelu klasyfikacji w celu zidentyfikowania różnych typów dokumentów, które obsługuje aplikacja. Plik wejściowy modelu klasyfikacji może zawierać wiele dokumentów i klasyfikuje każdy dokument w skojarzonym zakresie stron. Aby dowiedzieć się więcej, zobaczniestandardowe modele klasyfikacji .
Uwaga
Począwszy od klasyfikacji dokumentów wersji interfejsu 2024-02-29-preview API, obsługuje teraz typy dokumentów pakietu Office do klasyfikacji. Ta wersja interfejsu API wprowadza również trenowanie przyrostowe dla modelu klasyfikacji.
Niestandardowe narzędzia modelu
Modele analizy dokumentów w wersji 3.1 lub nowszej obsługują następujące narzędzia, aplikacje i biblioteki, programy i biblioteki:
| Funkcja | Zasoby | Model ID |
|---|---|---|
| Model niestandardowy | • Document Intelligence Studio• REST API • C# SDK • Python SDK |
custom-model-id |
Narzędzie Document Intelligence w wersji 2.1 obsługuje następujące narzędzia, aplikacje i biblioteki:
Uwaga
Niestandardowe typy modeli niestandardowego neuronowego i niestandardowego szablonu są dostępne w interfejsach API analizy dokumentów w wersji 3.1 i 3.0.
| Funkcja | Zasoby |
|---|---|
| Model niestandardowy | • Narzędzie do etykietowania analizy dokumentów• Interfejs API REST• Zestaw SDK biblioteki klienta• Kontener docker analizy dokumentów |
Tworzenie modelu niestandardowego
Wyodrębnianie danych z określonych lub unikatowych dokumentów przy użyciu modeli niestandardowych. Potrzebne są następujące zasoby:
Subskrypcja Azure. Możesz utworzyć go bezpłatnie.
Wystąpienie analizy dokumentów w witrynie Azure Portal. Aby wypróbować usługę, możesz użyć bezpłatnej warstwy cenowej (
F0). Po wdrożeniu zasobu wybierz pozycję Przejdź do zasobu , aby uzyskać klucz i punkt końcowy.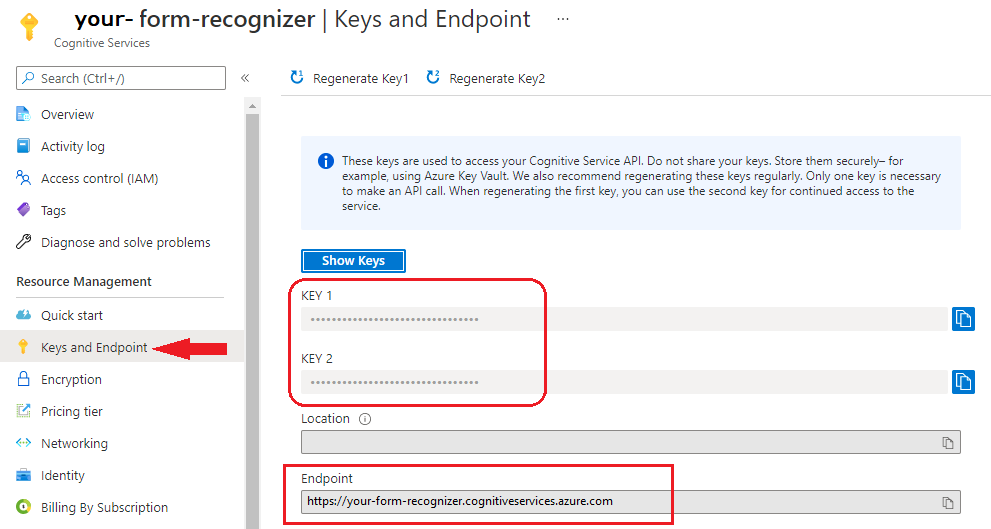
Przykładowe narzędzie do etykietowania
Napiwek
- Aby uzyskać ulepszone środowisko i zaawansowaną jakość modelu, wypróbuj narzędzie Document Intelligence w wersji 3.0 Studio.
- Program Studio w wersji 3.0 obsługuje dowolny model trenowany z danymi oznaczonymi etykietami w wersji 2.1.
- Szczegółowe informacje na temat migracji z wersji 2.1 do wersji 3.0 można znaleźć w przewodniku migracji interfejsu API.
- Zobacz przewodniki Szybki start dotyczące interfejsu API REST lub języka C#, Java, JavaScript lub Python SDK, aby rozpocząć pracę z wersją 3.0.
Narzędzie do etykietowania przykładowego analizy dokumentów to narzędzie typu open source, które umożliwia testowanie najnowszych funkcji funkcji analizy dokumentów i optycznego rozpoznawania znaków (OCR).
Wypróbuj przewodnik Szybki start dotyczący przykładowego narzędzia etykietowania, aby rozpocząć tworzenie i używanie modelu niestandardowego.
Document Intelligence Studio
Uwaga
Program Document Intelligence Studio jest dostępny z interfejsami API w wersji 3.1 i 3.0.
Na stronie głównej narzędzia Document Intelligence Studio wybierz pozycję Niestandardowe modele wyodrębniania.
W obszarze Moje projekty wybierz pozycję Utwórz projekt.
Wypełnij pola szczegółów projektu.
Skonfiguruj zasób usługi, dodając konto usługi Storage i kontener obiektów blob, aby Połączenie źródle danych szkoleniowych.
Przejrzyj i utwórz projekt.
Dodaj przykładowe dokumenty do etykiet, kompilowania i testowania modelu niestandardowego.
Aby zapoznać się ze szczegółowym przewodnikiem tworzenia pierwszego niestandardowego modelu wyodrębniania, zobaczHow to create a custom extraction model (Jak utworzyć niestandardowy model wyodrębniania).
Podsumowanie wyodrębniania modelu niestandardowego
W tej tabeli porównaliśmy obsługiwane obszary wyodrębniania danych:
| Model | Pola formularza | Znaczniki zaznaczenia | Pola ustrukturyzowane (tabele) | Podpis | Etykietowanie regionów | Nakładające się pola |
|---|---|---|---|---|---|---|
| Szablon niestandardowy | ✔ | ✔ | ✔ | ✔ | ✔ | N/a |
| Niestandardowe neuronowe | ✔ | ✔ | ✔ | N/a | * | ✔ (2024-02-29-preview) |
Symbole tabeli:
✔ — Obsługiwane
**n/a — obecnie niedostępne;
*-Zachowuje się inaczej w zależności od modelu. W przypadku modeli szablonów syntetyczne dane są generowane w czasie trenowania. W przypadku modeli neuronowych zaznaczono tekst rozpoznany w regionie.
Napiwek
Podczas wybierania między dwoma typami modeli zacznij od niestandardowego modelu neuronowego, jeśli spełnia twoje potrzeby funkcjonalne. Zobacz niestandardowe neuronowe, aby dowiedzieć się więcej o niestandardowych modelach neuronowych.
Opcje tworzenia niestandardowych modeli
W poniższej tabeli opisano funkcje dostępne w skojarzonych narzędziach i bibliotekach klienckich. Najlepszym rozwiązaniem jest upewnienie się, że używasz zgodnych narzędzi wymienionych tutaj.
| Document type | Interfejs API REST | SDK | Etykietowanie i testowanie modeli |
|---|---|---|---|
| Szablon niestandardowy w wersji 4.0 3.1 w wersji 3.0 | Analiza dokumentów 3.1 | Zestaw SDK analizy dokumentów | Document Intelligence Studio |
| Niestandardowe neuronowe v4.0 v3.1 v3.0 | Analiza dokumentów 3.1 | Zestaw SDK analizy dokumentów | Document Intelligence Studio |
| Formularz niestandardowy w wersji 2.1 | Interfejs API analizy dokumentów 2.1 (ogólna dostępność) | Zestaw SDK analizy dokumentów | Narzędzie do etykietowania próbek |
Uwaga
Niestandardowe modele szablonów trenowane za pomocą interfejsu API 3.0 będą miały kilka ulepszeń interfejsu API 2.1 wynikających z ulepszeń aparatu OCR. Zestawy danych używane do trenowania niestandardowego modelu szablonu przy użyciu interfejsu API 2.1 mogą być nadal używane do trenowania nowego modelu przy użyciu interfejsu API 3.0.
Aby uzyskać najlepsze wyniki, podaj jedno jasne zdjęcie lub wysokiej jakości skanowanie na dokument.
Obsługiwane formaty plików to JPEG/JPG, PNG, BMP, TIFF i PDF (tekst osadzony lub skanowany). Pliki PDF z osadzonym tekstem są najlepsze, aby wyeliminować możliwość błędów podczas wyodrębniania i lokalizowania znaków.
W przypadku plików PDF i TIFF można przetworzyć maksymalnie 2000 stron. W przypadku subskrypcji w warstwie Bezpłatna przetwarzane są tylko dwie pierwsze strony.
Rozmiar pliku musi być mniejszy niż 500 MB dla warstwy płatnej (S0) i 4 MB za bezpłatną (F0).
Obrazy muszą mieć wymiary od 50 x 50 pikseli do 10 000 x 10 000 pikseli.
Wymiary formatu PDF są do 17 x 17 cali, co odpowiada rozmiarowi papieru Legal lub A3 lub mniejszemu.
Łączny rozmiar danych treningowych wynosi 500 stron lub mniej.
Jeśli pliki PDF są zablokowane hasłem, przed ich przesłaniem usuń blokadę.
Napiwek
Dane szkoleniowe:
- Jeśli to możliwe, użyj dokumentów tekstowych w formacie PDF zamiast dokumentów opartych na obrazach. Zeskanowane pliki PDF są obsługiwane jako obrazy.
- Podaj tylko jedno wystąpienie formularza na dokument.
- W przypadku formularzy wypełnionych użyj przykładów z wypełnionymi polami.
- Używaj formularzy z różnymi wartościami w każdym polu.
- Jeśli obrazy formularzy są niższej jakości, użyj większego zestawu danych. Na przykład użyj 10 do 15 obrazów.
Obsługiwane języki i ustawienia regionalne
Zobacz naszą stronę Obsługa języków — modele niestandardowe, aby uzyskać pełną listę obsługiwanych języków.
Następne kroki
Spróbuj przetwarzać własne formularze i dokumenty za pomocą narzędzia do etykietowania przykładowego analizy dokumentów.
Ukończ przewodnik Szybki start dotyczący analizy dokumentów i rozpocznij tworzenie aplikacji do przetwarzania dokumentów w wybranym języku programowania.
Spróbuj przetwarzać własne formularze i dokumenty za pomocą programu Document Intelligence Studio.
Ukończ przewodnik Szybki start dotyczący analizy dokumentów i rozpocznij tworzenie aplikacji do przetwarzania dokumentów w wybranym języku programowania.