Samouczek: korzystanie z usługi Personalizacja w usłudze Azure Notebook
Ważne
Od 20 września 2023 r. nie będzie można tworzyć nowych zasobów usługi Personalizacja. Usługa Personalizacja jest wycofywana 1 października 2026 r.
W tym samouczku jest uruchamiana pętla personalizacji w notesie platformy Azure, przedstawiająca koniec cyklu życia pętli personalizacji.
Pętla sugeruje, który typ kawy klient powinien zamówić. Użytkownicy i ich preferencje są przechowywane w zestawie danych użytkownika. Informacje o kawie są przechowywane w zestawie danych kawy.
Użytkownicy i kawa
Notes, symulując interakcję użytkownika z witryną internetową, wybiera losowego użytkownika, godzinę dnia i typ pogody z zestawu danych. Podsumowanie informacji o użytkowniku to:
| Klienci — funkcje kontekstowe | Godziny dnia | Typy pogody |
|---|---|---|
| Alicja Robert Cathy Dave |
Rano Po południu Wieczorem |
Słoneczny Deszczowy Snowy |
Aby ułatwić personalizację nauki, z upływem czasu system wie również szczegółowe informacje na temat wyboru kawy dla każdej osoby.
| Kawa — funkcje akcji | Typy temperatury | Miejsca pochodzenia | Rodzaje prażenia | Organicznych |
|---|---|---|---|---|
| Cappacino | Duże zainteresowanie | Kenia | Ciemny | Organicznych |
| Zimny napar | Brak zainteresowania | Brazylia | Jasny | Organicznych |
| Na lodzie makiety | Brak zainteresowania | Etiopia | Jasny | Nie organiczny |
| Latte | Duże zainteresowanie | Brazylia | Ciemny | Nie organiczny |
Celem pętli Personalizacja jest znalezienie najlepszego dopasowania między użytkownikami a kawą jak najwięcej czasu.
Kod tego samouczka jest dostępny w repozytorium GitHub z przykładami usługi Personalizacja.
Jak działa symulacja
Na początku uruchomionego systemu sugestie z usługi Personalizacja kończą się powodzeniem tylko z zakresu od 20% do 30%. Ten sukces jest wskazywany przez nagrodę wysłaną z powrotem do interfejsu API nagrody personalizacji z wynikiem 1. Po kilku wywołaniach rangi i nagrody system się poprawia.
Po początkowych żądaniach uruchom ocenę offline. Dzięki temu usługa Personalizacja może przeglądać dane i sugerować lepsze zasady uczenia się. Zastosuj nowe zasady szkoleniowe i ponownie uruchom notes z 20% poprzedniej liczby żądań. Pętla będzie działać lepiej dzięki nowym zasadom uczenia się.
Ranga i połączenia nagród
Dla każdego z kilku tysięcy wywołań usługi Personalizacja usługa Azure Notebook wysyła żądanie rangi do interfejsu API REST:
- Unikatowy identyfikator zdarzenia Rank/Request
- Funkcje kontekstowe — losowy wybór użytkownika, pogody i godziny dnia — symulowanie użytkownika w witrynie internetowej lub urządzeniu przenośnym
- Akcje z funkcjami — wszystkie dane dotyczące kawy — z których usługa Personalizacja wysyła sugestię
System odbiera żądanie, a następnie porównuje to przewidywanie ze znanym wyborem użytkownika o tej samej porze dnia i pogody. Jeśli znany wybór jest taki sam jak przewidywany wybór, nagroda 1 zostanie odesłana do personalizacji. W przeciwnym razie nagroda wysłana z powrotem wynosi 0.
Uwaga
Jest to symulacja, więc algorytm nagrody jest prosty. W rzeczywistym scenariuszu algorytm powinien używać logiki biznesowej, prawdopodobnie z wagami dla różnych aspektów środowiska klienta, aby określić wynik nagrody.
Wymagania wstępne
- Konto usługi Azure Notebook.
- Zasób usługi Personalizacja sztucznej inteligencji platformy Azure.
- Jeśli zasób personalizacji został już użyty, upewnij się, że dane zostały wyczyszczane w witrynie Azure Portal dla zasobu.
- Przekaż wszystkie pliki dla tego przykładu do projektu usługi Azure Notebook.
Opisy plików:
- Personalr.ipynb to notes Jupyter na potrzeby tego samouczka.
- Zestaw danych użytkownika jest przechowywany w obiekcie JSON.
- Zestaw danych kawy jest przechowywany w obiekcie JSON.
- Przykładowy format JSON żądania to oczekiwany format żądania POST do interfejsu API rangi.
Konfigurowanie zasobu usługi Personalizacja
W witrynie Azure Portal skonfiguruj zasób personalizacji z częstotliwością aktualizacji modelu ustawioną na 15 sekund i czas oczekiwania na nagrodę 10 minut. Te wartości znajdują się na stronie Konfiguracja.
| Ustawienie | Wartość |
|---|---|
| częstotliwość aktualizacji modelu | 15 sekund |
| czas oczekiwania na nagrody | 10 min |
Te wartości mają bardzo krótki czas trwania, aby pokazać zmiany w tym samouczku. Te wartości nie powinny być używane w scenariuszu produkcyjnym bez sprawdzania ich poprawności, aby osiągnąć cel za pomocą pętli personalizacji.
Konfigurowanie notesu platformy Azure
- Zmień jądro na
Python 3.6. - Otwórz plik
Personalizer.ipynb.
Uruchamianie komórek notesu
Uruchom każdą komórkę wykonywalną i poczekaj na jej powrót. Wiesz, że jest to wykonywane, gdy nawiasy obok komórki wyświetlają liczbę zamiast *. W poniższych sekcjach opisano, co każda komórka wykonuje programowo i czego można oczekiwać dla danych wyjściowych.
Dołączanie modułów języka Python
Uwzględnij wymagane moduły języka Python. Komórka nie ma danych wyjściowych.
import json
import matplotlib.pyplot as plt
import random
import requests
import time
import uuid
Ustawianie klucza zasobu i nazwy usługi Personalizacja
W witrynie Azure Portal znajdź swój klucz i punkt końcowy na stronie Szybki start zasobu usługi Personalizacja. Zmień wartość <your-resource-name> na nazwę zasobu usługi Personalizacja. Zmień wartość <your-resource-key> na klucz personalizacji.
# Replace 'personalization_base_url' and 'resource_key' with your valid endpoint values.
personalization_base_url = "https://<your-resource-name>.cognitiveservices.azure.com/"
resource_key = "<your-resource-key>"
Drukuj bieżącą datę i godzinę
Użyj tej funkcji, aby zanotować czasy rozpoczęcia i zakończenia funkcji iteracyjnej, iteracji.
Te komórki nie mają danych wyjściowych. Funkcja generuje bieżącą datę i godzinę wywołania.
# Print out current datetime
def currentDateTime():
currentDT = datetime.datetime.now()
print (str(currentDT))
Pobieranie czasu ostatniej aktualizacji modelu
Gdy funkcja get_last_updated, jest wywoływana, funkcja wyświetla ostatnią zmodyfikowaną datę i godzinę aktualizacji modelu.
Te komórki nie mają danych wyjściowych. Funkcja generuje ostatnią datę trenowania modelu po wywołaniu.
Funkcja używa interfejsu API REST GET do pobierania właściwości modelu.
# ititialize variable for model's last modified date
modelLastModified = ""
def get_last_updated(currentModifiedDate):
print('-----checking model')
# get model properties
response = requests.get(personalization_model_properties_url, headers = headers, params = None)
print(response)
print(response.json())
# get lastModifiedTime
lastModifiedTime = json.dumps(response.json()["lastModifiedTime"])
if (currentModifiedDate != lastModifiedTime):
currentModifiedDate = lastModifiedTime
print(f'-----model updated: {lastModifiedTime}')
Uzyskiwanie konfiguracji zasad i usług
Zweryfikuj stan usługi przy użyciu tych dwóch wywołań REST.
Te komórki nie mają danych wyjściowych. Funkcja generuje wartości usługi po wywołaniu.
def get_service_settings():
print('-----checking service settings')
# get learning policy
response = requests.get(personalization_model_policy_url, headers = headers, params = None)
print(response)
print(response.json())
# get service settings
response = requests.get(personalization_service_configuration_url, headers = headers, params = None)
print(response)
print(response.json())
Konstruowanie adresów URL i odczytywanie plików danych JSON
Ta komórka
- tworzy adresy URL używane w wywołaniach REST
- Ustawia nagłówek zabezpieczeń przy użyciu klucza zasobu usługi Personalizacja
- ustawia losowe inicjator dla identyfikatora zdarzenia Ranga
- odczytuje w plikach danych JSON
- metoda wywołań
get_last_updated— zasady uczenia zostały usunięte w przykładowych danych wyjściowych - wywołania
get_service_settingsmetody
Komórka zawiera dane wyjściowe z wywołania funkcji get_last_updated i .get_service_settings
# build URLs
personalization_rank_url = personalization_base_url + "personalizer/v1.0/rank"
personalization_reward_url = personalization_base_url + "personalizer/v1.0/events/" #add "{eventId}/reward"
personalization_model_properties_url = personalization_base_url + "personalizer/v1.0/model/properties"
personalization_model_policy_url = personalization_base_url + "personalizer/v1.0/configurations/policy"
personalization_service_configuration_url = personalization_base_url + "personalizer/v1.0/configurations/service"
headers = {'Ocp-Apim-Subscription-Key' : resource_key, 'Content-Type': 'application/json'}
# context
users = "users.json"
# action features
coffee = "coffee.json"
# empty JSON for Rank request
requestpath = "example-rankrequest.json"
# initialize random
random.seed(time.time())
userpref = None
rankactionsjsonobj = None
actionfeaturesobj = None
with open(users) as handle:
userpref = json.loads(handle.read())
with open(coffee) as handle:
actionfeaturesobj = json.loads(handle.read())
with open(requestpath) as handle:
rankactionsjsonobj = json.loads(handle.read())
get_last_updated(modelLastModified)
get_service_settings()
print(f'User count {len(userpref)}')
print(f'Coffee count {len(actionfeaturesobj)}')
Sprawdź, czy dane wyjściowe rewardWaitTime są ustawione na 10 minut i modelExportFrequency ustawiono wartość 15 sekund.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:10:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:00:15', 'logRetentionDays': -1}
User count 4
Coffee count 4
Rozwiązywanie problemów z pierwszym wywołaniem REST
Ta poprzednia komórka jest pierwszą komórką, która wywołuje element Personalizacja. Upewnij się, że kod stanu REST w danych wyjściowych to <Response [200]>. Jeśli wystąpi błąd, taki jak 404, ale masz pewność, że klucz zasobu i nazwa są poprawne, załaduj ponownie notes.
Upewnij się, że liczba kawy i użytkowników wynosi 4. Jeśli wystąpi błąd, sprawdź, czy przekazano wszystkie 3 pliki JSON.
Konfigurowanie wykresu metryk w witrynie Azure Portal
W dalszej części tego samouczka długotrwały proces 10 000 żądań jest widoczny w przeglądarce z zaktualizowanym polem tekstowym. Może być łatwiej zobaczyć na wykresie lub jako sumę całkowitą, gdy kończy się długotrwały proces. Aby wyświetlić te informacje, użyj metryk dostarczonych z zasobem. Możesz teraz utworzyć wykres, po zakończeniu żądania do usługi, a następnie okresowo odświeżyć wykres podczas długotrwałego procesu.
W witrynie Azure Portal wybierz zasób Personalizacja.
W obszarze nawigacji zasobów wybierz pozycję Metryki poniżej pozycji Monitorowanie.
Na wykresie wybierz pozycję Dodaj metryki.
Przestrzeń nazw zasobów i metryk jest już ustawiona. Wystarczy wybrać metryę pomyślnych wywołań i agregację sumy.
Zmień filtr czasu na ostatnie 4 godziny.
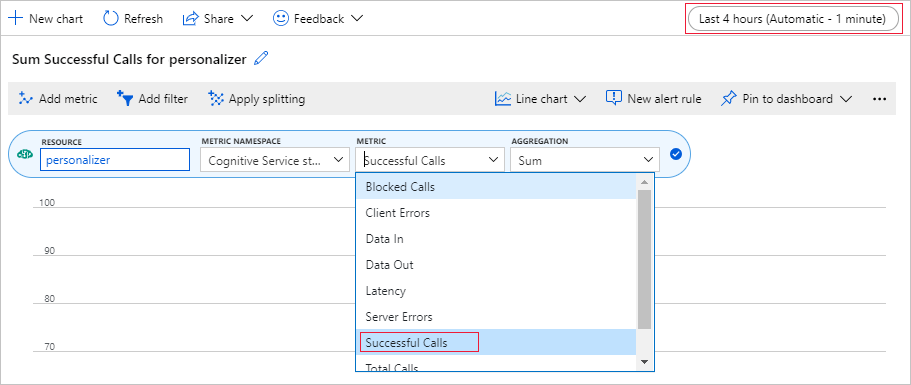
Na wykresie powinny zostać wyświetlone trzy pomyślne wywołania.
Generowanie unikatowego identyfikatora zdarzenia
Ta funkcja generuje unikatowy identyfikator dla każdego wywołania rangi. Identyfikator służy do identyfikowania informacji o rangi i wywołaniu nagrody. Ta wartość może pochodzić z procesu biznesowego, takiego jak identyfikator widoku sieci Web lub identyfikator transakcji.
Komórka nie ma danych wyjściowych. Funkcja generuje unikatowy identyfikator po wywołaniu.
def add_event_id(rankjsonobj):
eventid = uuid.uuid4().hex
rankjsonobj["eventId"] = eventid
return eventid
Pobieranie losowego użytkownika, pogody i godziny dnia
Ta funkcja wybiera unikatowego użytkownika, pogodę i godzinę dnia, a następnie dodaje te elementy do obiektu JSON w celu wysłania do żądania rangi.
Komórka nie ma danych wyjściowych. Gdy funkcja jest wywoływana, zwraca nazwę losowego użytkownika, losową pogodę i losową godzinę dnia.
Lista 4 użytkowników i ich preferencji — tylko niektóre preferencje są wyświetlane w celu zwięzłości:
{
"Alice": {
"Sunny": {
"Morning": "Cold brew",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Bob": {
"Sunny": {
"Morning": "Cappucino",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Cathy": {
"Sunny": {
"Morning": "Latte",
"Afternoon": "Cold brew",
"Evening": "Cappucino"
}...
},
"Dave": {
"Sunny": {
"Morning": "Iced mocha",
"Afternoon": "Iced mocha",
"Evening": "Iced mocha"
}...
}
}
def add_random_user_and_contextfeatures(namesoption, weatheropt, timeofdayopt, rankjsonobj):
name = namesoption[random.randint(0,3)]
weather = weatheropt[random.randint(0,2)]
timeofday = timeofdayopt[random.randint(0,2)]
rankjsonobj['contextFeatures'] = [{'timeofday': timeofday, 'weather': weather, 'name': name}]
return [name, weather, timeofday]
Dodawanie wszystkich danych kawy
Ta funkcja dodaje całą listę kawy do obiektu JSON, który ma być wysyłany do żądania rangi.
Komórka nie ma danych wyjściowych. Funkcja zmienia wartość po wywołaniu rankjsonobj .
Przykładem funkcji pojedynczej kawy jest:
{
"id": "Cappucino",
"features": [
{
"type": "hot",
"origin": "kenya",
"organic": "yes",
"roast": "dark"
}
}
def add_action_features(rankjsonobj):
rankjsonobj["actions"] = actionfeaturesobj
Porównanie przewidywania ze znanymi preferencjami użytkownika
Ta funkcja jest wywoływana po wywołaniu interfejsu API rangi dla każdej iteracji.
Ta funkcja porównuje preferencje użytkownika dotyczące kawy w oparciu o pogodę i godzinę dnia z sugestią personalizatora dla użytkownika dla tych filtrów. Jeśli sugestia jest zgodna, zostanie zwrócony wynik 1, w przeciwnym razie wynik wynosi 0. Komórka nie ma danych wyjściowych. Funkcja generuje wynik po wywołaniu.
def get_reward_from_simulated_data(name, weather, timeofday, prediction):
if(userpref[name][weather][timeofday] == str(prediction)):
return 1
return 0
Pętla przez wywołania rangi i nagrody
Następna komórka to główna praca notesu, pobieranie losowego użytkownika, pobieranie listy kawy, wysyłanie obu do interfejsu API rangi. Porównanie przewidywania ze znanymi preferencjami użytkownika, a następnie wysłanie nagrody z powrotem do usługi Personalizacja.
Pętla jest uruchamiana przez num_requests czasy. Usługa Personalizacja potrzebuje kilku tysięcy wywołań do elementu Rank and Reward w celu utworzenia modelu.
Poniżej znajduje się przykład kodu JSON wysłanego do interfejsu API rangi. Lista kawy nie jest kompletna, dla zwięzłości. Cały kod JSON dla kawy można zobaczyć w pliku coffee.json.
Kod JSON wysłany do interfejsu API rangi:
{
'contextFeatures':[
{
'timeofday':'Evening',
'weather':'Snowy',
'name':'Alice'
}
],
'actions':[
{
'id':'Cappucino',
'features':[
{
'type':'hot',
'origin':'kenya',
'organic':'yes',
'roast':'dark'
}
]
}
...rest of coffee list
],
'excludedActions':[
],
'eventId':'b5c4ef3e8c434f358382b04be8963f62',
'deferActivation':False
}
Odpowiedź JSON z interfejsu API rangi:
{
'ranking': [
{'id': 'Latte', 'probability': 0.85 },
{'id': 'Iced mocha', 'probability': 0.05 },
{'id': 'Cappucino', 'probability': 0.05 },
{'id': 'Cold brew', 'probability': 0.05 }
],
'eventId': '5001bcfe3bb542a1a238e6d18d57f2d2',
'rewardActionId': 'Latte'
}
Na koniec każda pętla pokazuje losowy wybór użytkownika, pogody, godziny dnia i ustalonej nagrody. Nagroda 1 wskazuje zasób personalizacji wybrany prawidłowy typ kawy dla danego użytkownika, pogody i godziny dnia.
1 Alice Rainy Morning Latte 1
Funkcja używa następujących funkcji:
- Ranga: interfejs API REST POST, aby uzyskać rangę.
- Nagroda: interfejs API REST POST do raportowania nagrody.
def iterations(n, modelCheck, jsonFormat):
i = 1
# default reward value - assumes failed prediction
reward = 0
# Print out dateTime
currentDateTime()
# collect results to aggregate in graph
total = 0
rewards = []
count = []
# default list of user, weather, time of day
namesopt = ['Alice', 'Bob', 'Cathy', 'Dave']
weatheropt = ['Sunny', 'Rainy', 'Snowy']
timeofdayopt = ['Morning', 'Afternoon', 'Evening']
while(i <= n):
# create unique id to associate with an event
eventid = add_event_id(jsonFormat)
# generate a random sample
[name, weather, timeofday] = add_random_user_and_contextfeatures(namesopt, weatheropt, timeofdayopt, jsonFormat)
# add action features to rank
add_action_features(jsonFormat)
# show JSON to send to Rank
print('To: ', jsonFormat)
# choose an action - get prediction from Personalizer
response = requests.post(personalization_rank_url, headers = headers, params = None, json = jsonFormat)
# show Rank prediction
print ('From: ',response.json())
# compare personalization service recommendation with the simulated data to generate a reward value
prediction = json.dumps(response.json()["rewardActionId"]).replace('"','')
reward = get_reward_from_simulated_data(name, weather, timeofday, prediction)
# show result for iteration
print(f' {i} {currentDateTime()} {name} {weather} {timeofday} {prediction} {reward}')
# send the reward to the service
response = requests.post(personalization_reward_url + eventid + "/reward", headers = headers, params= None, json = { "value" : reward })
# for every N rank requests, compute total correct total
total = total + reward
# every N iteration, get last updated model date and time
if(i % modelCheck == 0):
print("**** 10% of loop found")
get_last_updated(modelLastModified)
# aggregate so chart is easier to read
if(i % 10 == 0):
rewards.append( total)
count.append(i)
total = 0
i = i + 1
# Print out dateTime
currentDateTime()
return [count, rewards]
Uruchamianie dla 10 000 iteracji
Uruchom pętlę Personalizacja dla 10 000 iteracji. Jest to długotrwałe zdarzenie. Nie zamykaj przeglądarki z uruchomionym notesem. Okresowo odśwież wykres metryk w witrynie Azure Portal, aby wyświetlić łączne wywołania usługi. Gdy masz około 20 000 połączeń, ranga i wezwanie do nagrody dla każdej iteracji pętli, iteracji są wykonywane.
# max iterations
num_requests = 200
# check last mod date N% of time - currently 10%
lastModCheck = int(num_requests * .10)
jsonTemplate = rankactionsjsonobj
# main iterations
[count, rewards] = iterations(num_requests, lastModCheck, jsonTemplate)
Wyniki wykresu w celu wyświetlenia poprawy
Utwórz wykres na podstawie i countrewards.
def createChart(x, y):
plt.plot(x, y)
plt.xlabel("Batch of rank events")
plt.ylabel("Correct recommendations per batch")
plt.show()
Uruchamianie wykresu dla żądań rangi 10 000
createChart Uruchom funkcję .
createChart(count,rewards)
Odczytywanie wykresu
Ten wykres przedstawia powodzenie modelu dla bieżących domyślnych zasad uczenia.
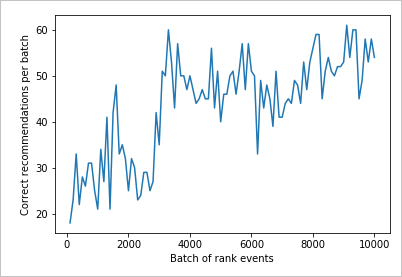
Idealny cel, który do końca testu, pętla jest średnio wskaźnik powodzenia, który jest zbliżony do 100 procent pomniejszone o eksplorację. Wartość domyślna eksploracji to 20%.
100-20=80
Ta wartość eksploracji znajduje się w witrynie Azure Portal dla zasobu Personalizacja na stronie Konfiguracja .
Aby znaleźć lepsze zasady uczenia na podstawie danych interfejsu API rangi, uruchom ocenę w trybie offline w portalu dla pętli personalizacji.
Uruchamianie oceny w trybie offline
W witrynie Azure Portal otwórz stronę Oceny zasobu usługi Personalizacja.
Wybierz pozycję Utwórz ocenę.
Wprowadź wymagane dane nazwy oceny i zakres dat dla oceny pętli. Zakres dat powinien zawierać tylko dni, na których koncentrujesz się na ocenie.
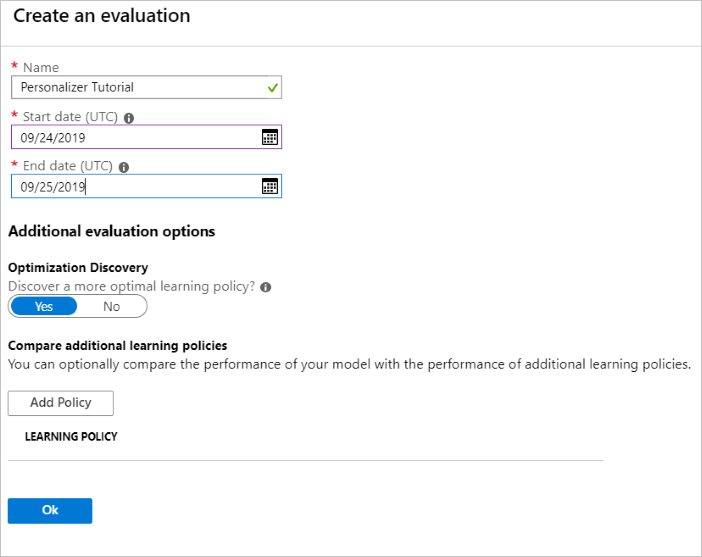
Celem uruchomienia tej oceny w trybie offline jest ustalenie, czy istnieją lepsze zasady uczenia się dla funkcji i akcji używanych w tej pętli. Aby znaleźć te lepsze zasady uczenia się, upewnij się, że odnajdywanie optymalizacji jest włączone.
Wybierz przycisk OK , aby rozpocząć ocenę.
Ta strona Oceny zawiera listę nowej oceny i jej bieżącego stanu. W zależności od ilości posiadanych danych ocena może zająć trochę czasu. Po kilku minutach możesz wrócić do tej strony, aby zobaczyć wyniki.
Po zakończeniu oceny wybierz ocenę, a następnie wybierz pozycję Porównanie różnych zasad szkoleniowych. Spowoduje to wyświetlenie dostępnych zasad szkoleniowych i sposobu ich zachowania z danymi.
Wybierz najważniejsze zasady szkoleniowe w tabeli i wybierz pozycję Zastosuj. Dotyczy to najlepszych zasad uczenia się do modelu i ponownego trenowania.
Zmień częstotliwość aktualizacji modelu na 5 minut
- W witrynie Azure Portal nadal w zasobie Personalizacja wybierz stronę Konfiguracja .
- Zmień częstotliwość aktualizacji modelu i czas oczekiwania nagrody na 5 minut, a następnie wybierz pozycję Zapisz.
Dowiedz się więcej o czasie oczekiwania na nagrody i częstotliwości aktualizacji modelu.
#Verify new learning policy and times
get_service_settings()
Sprawdź, czy dane wyjściowe rewardWaitTime są modelExportFrequency ustawione na 5 minut.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:05:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:05:00', 'logRetentionDays': -1}
User count 4
Coffee count 4
Weryfikowanie nowych zasad szkoleniowych
Wróć do pliku usługi Azure Notebooks i kontynuuj, uruchamiając tę samą pętlę, ale tylko dla 2000 iteracji. Okresowo odśwież wykres metryk w witrynie Azure Portal, aby wyświetlić łączne wywołania usługi. Gdy masz około 4000 wywołań, ranga i wezwanie do nagrody dla każdej iteracji pętli, iteracji są wykonywane.
# max iterations
num_requests = 2000
# check last mod date N% of time - currently 10%
lastModCheck2 = int(num_requests * .10)
jsonTemplate2 = rankactionsjsonobj
# main iterations
[count2, rewards2] = iterations(num_requests, lastModCheck2, jsonTemplate)
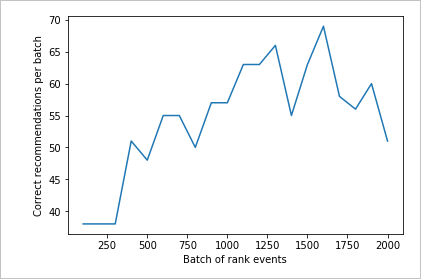
Uruchamianie wykresu dla żądań rangi 2000
createChart Uruchom funkcję .
createChart(count2,rewards2)
Przejrzyj drugi wykres
Drugi wykres powinien pokazywać widoczny wzrost przewidywań rangi dopasowanych do preferencji użytkownika.
Czyszczenie zasobów
Jeśli nie zamierzasz kontynuować serii samouczków, wyczyść następujące zasoby:
- Usuń projekt usługi Azure Notebook.
- Usuń zasób personalizacji.
Następne kroki
Notes Jupyter i pliki danych używane w tym przykładzie są dostępne w repozytorium GitHub dla usługi Personalizacja.