Rejestrowanie przykładów głosowych dla niestandardowego neuronowego głosu
Ten artykuł zawiera instrukcje dotyczące przygotowywania wysokiej jakości próbek głosowych do tworzenia profesjonalnego modelu głosu przy użyciu niestandardowego projektu neuronowego voice Pro.
Tworzenie wysokiej jakości niestandardowego neuronowego głosu od podstaw nie jest przypadkowym przedsięwzięciem. Centralnym składnikiem niestandardowego neuronowego głosu jest duża kolekcja próbek audio ludzkiej mowy. Ważne jest, aby te nagrania dźwiękowe były wysokiej jakości. Wybierz talent głosowy, który ma doświadczenie w tworzeniu tego rodzaju nagrań i mają je nagrane przez inżyniera nagrywania przy użyciu profesjonalnego sprzętu.
Zanim jednak będzie można utworzyć te nagrania, potrzebujesz skryptu: słowa są wypowiadane przez talent głosu, aby utworzyć próbki audio.
Wiele małych, ale ważnych szczegółów przechodzi do tworzenia profesjonalnego nagrywania głosu. Ten przewodnik jest planem dla procesu, który pomoże Ci uzyskać dobre, spójne wyniki.
Wskazówki do przygotowywania danych do wysokiej jakości głosu
Bardzo naturalny niestandardowy neuronowy głos zależy od kilku czynników, takich jak jakość i rozmiar danych treningowych.
Jakość danych treningowych jest podstawowym czynnikiem. Na przykład w tym samym zestawie treningowym spójność głośności, szybkość mówienia, ton i styl mówienia są niezbędne do utworzenia wysokiej jakości niestandardowego neuronowego głosu. Należy również unikać szumu tła w nagraniu i upewnić się, że skrypt i nagranie są zgodne. Aby zapewnić jakość danych, należy przestrzegać kryteriów wyboru skryptu i wymagań dotyczących rejestrowania.
Jeśli chodzi o rozmiar danych treningowych, w większości przypadków można utworzyć rozsądny niestandardowy neuronowy głos z 500 wypowiedziami. Zgodnie z naszymi testami dodanie większej liczby danych szkoleniowych w większości języków niekoniecznie poprawia naturalność samego głosu (testowane przy użyciu wyniku MOS), jednak z większą ilością danych szkoleniowych, które obejmują więcej wystąpień słów, masz wyższą możliwość zmniejszenia współczynnika niezadowalającej części mowy dla głosu, takich jak usterki. Aby dowiedzieć się, jak niezadowalająca część dźwięku mowy, zapoznaj się z przykładami usługi GitHub.
W niektórych przypadkach możesz chcieć osobę głosową o unikatowych cechach. Na przykład persona kreskówek potrzebuje głosu ze specjalnym stylem mówienia lub głosem dynamicznym w intonacji. W takich przypadkach zalecamy przygotowanie co najmniej 1000 (najlepiej 2000) wypowiedzi i zarejestrowanie ich w profesjonalnym studiu nagraniowym. Aby dowiedzieć się więcej na temat poprawiania jakości modelu głosu, zobacz charakterystykę i ograniczenia dotyczące używania niestandardowego neuronowego głosu.
Role nagrywania głosu
W projekcie niestandardowego neuronowego rejestrowania głosu istnieją cztery podstawowe role:
| Role | Purpose |
|---|---|
| Talent głosowy | Głos tej osoby stanowi podstawę niestandardowego neuronowego głosu. |
| Inżynier nagrywania | Nadzoruje techniczne aspekty nagrania i obsługuje sprzęt rejestrujący. |
| Dyrektor | Przygotowuje skrypt i trenerów występ talentów głosowych. |
| Redaktor | Finalizuje pliki audio i przygotowuje je do przekazania do usługi Speech Studio |
Osoba może wypełnić więcej niż jedną rolę. W tym przewodniku założono, że wypełniasz rolę reżysera i zatrudniasz zarówno talent głosowy, jak i inżyniera nagrywania. Jeśli chcesz zrobić nagrania samodzielnie, ten artykuł zawiera kilka informacji o roli inżyniera nagrywania. Rola edytora nie jest potrzebna dopiero po zakończeniu sesji nagrywania. W międzyczasie reżyser lub inżynier nagrywania mogą wypełnić tę rolę.
Wybieranie talentu głosowego
Aktorzy z doświadczeniem w pracy głosowej, pracy głosowej, ogłaszaniu lub odczytywaniu wiadomości sprawiają, że dobry talent głosowy. Wybierz talent głosowy, którego naturalny głos ci się podoba. Istnieje możliwość utworzenia unikatowych "znaków" głosów, ale trudniej jest większości talentów, aby wykonać je spójnie, a wysiłek może spowodować obciążenie głosu. Jednym najważniejszym czynnikiem do wyboru talentów głosowych jest spójność. Nagrania w tym samym stylu głosu powinny brzmieć tak, jakby zostały wykonane w tym samym dniu w tym samym pokoju. Możesz podejść do tego idealnego za pomocą dobrych praktyk rejestrowania i inżynierii.
Twój talent głosowy musi być w stanie mówić ze stałym współczynnikiem, poziomem głośności, skokiem i tonem z wyraźnym dyktacją. Muszą również być w stanie kontrolować ich zmienność boiska, efekt emocjonalny i maniery mowy. Nagrywanie próbek głosowych może być bardziej fatiguing niż inne rodzaje pracy głosowej, więc większość talentów głosowych może rejestrować tylko przez dwie lub trzy godziny dziennie. Ogranicz sesje do trzech lub czterech dni w tygodniu, z dniem wolnym między, jeśli to możliwe.
Współpracuj z talentem głosowym, aby rozwinąć osobę, która definiuje ogólny dźwięk i emocjonalny ton niestandardowego neuronowego głosu, upewniając się, jak brzmi "neutralny" dla tej osoby. Definiujesz style mówienia swojej osoby i pytasz swój talent głosowy, aby przeczytać skrypt w sposób, który rezonuje ze stylami, które chcesz.
Na przykład persona z naturalnie optymistyczną osobowością nosiłaby nutę optymizmu nawet wtedy, gdy mówią neutralnie. Jednak ta cecha osobowości powinna być subtelna i spójna. Słuchaj odczytów przez istniejące głosy, aby zrozumieć, do czego dążysz.
Napiwek
Zazwyczaj chcesz być właścicielem nagrań głosowych, które wykonujesz. Twój talent głosowy powinien być możliwy do zawarcia umowy o pracę na wynajem w projekcie.
Tworzenie skryptu
Punktem wyjścia każdej niestandardowej sesji neuronowego rejestrowania głosu jest skrypt, który zawiera wypowiedzi, które mają być wypowiadane przez talent głosowy. Termin "wypowiedzi" obejmuje zarówno pełne zdania, jak i krótsze frazy. Tworzenie niestandardowego neuronowego głosu wymaga co najmniej 300 zarejestrowanych wypowiedzi jako danych treningowych.
Wypowiedzi w skrypcie mogą pochodzić z dowolnego miejsca: fikcja, non-fiction, transkrypcje mowy, raporty informacyjne i wszystkie inne dostępne w formie drukowanej. Aby zapoznać się z krótką dyskusją na temat potencjalnych problemów prawnych, zobacz sekcję "Legalities". Możesz również napisać własny tekst.
Twoje wypowiedzi nie muszą pochodzić z tego samego źródła, tego samego rodzaju źródła lub mieć coś wspólnego ze sobą. Jeśli jednak używasz ustawionych fraz (na przykład "Udało Ci się zalogować") w aplikacji mowy, pamiętaj, aby dołączyć je do skryptu. Daje to niestandardowemu neuronowemu głosowi większe szanse na dobrze wymawianie tych fraz.
Zalecamy, aby skrypty nagrywania zawierały zarówno zdania ogólne, jak i zdania specyficzne dla domeny. Jeśli na przykład planujesz rejestrować 2000 zdań, 1000 z nich może być zdaniami ogólnymi, kolejne 1000 z nich może być zdaniami z domeny docelowej lub przypadkiem użycia aplikacji.
Udostępniamy przykładowe skrypty w domenach "Ogólne", "Chat" i "Customer Service" dla każdego języka , aby ułatwić przygotowanie skryptów nagrywania. Możesz użyć tych udostępnionych skryptów firmy Microsoft do nagrań bezpośrednio lub użyć ich jako odwołania do utworzenia własnego.
Kryteria wyboru skryptu
Poniżej przedstawiono kilka ogólnych wytycznych, które można wykonać w celu utworzenia dobrego korpusu (nagranych próbek dźwiękowych) na potrzeby niestandardowego trenowania neuronowego głosu.
Zrównoważ skrypt, aby obejmował różne typy zdań w domenie, w tym instrukcje, pytania, wykrzykniki, długie zdania i krótkie zdania.
Każde zdanie powinno zawierać cztery wyrazy do 30 wyrazów, a w skrycie nie powinny być uwzględniane zduplikowane zdania.
Aby zrównoważyć różne typy zdań, zapoznaj się z następującą tabelą:Typy zdań Zakres Zdania instrukcji Zdania instrukcji powinny wynosić 70–80% skryptu. Zdania pytań Zdania pytań powinny wynosić około 10%-20% skryptu domeny, w tym 5%-10% wzrostu i 5%-10% spadku tonów. Wykrzyknik zdania Wykrzykniki powinny wynosić około 10%-20% skryptu. Krótkie słowo/fraza Krótkie skrypty wyrazów/fraz powinny mieć około 10% całkowitej wypowiedzi, z 5 do 7 wyrazów na przypadek. Uwaga
Krótkie wyrazy/frazy powinny być oddzielone przecinkami. Pomagają przypomnieć swój talent głosowy, aby zatrzymać się na krótko podczas ich czytania.
Najlepsze rozwiązania obejmują:
- Zrównoważone pokrycie dla części mowy, takich jak czasowniki, rzeczowniki, przymiotniki itd.
- Zrównoważone pokrycie wymowy. Uwzględnij wszystkie litery od A do Z, aby aparat zamiany tekstu na mowę nauczył się wymawiać każdą literę w swoim stylu.
- Czytelne, zrozumiałe skrypty zdrowego rozsądku dla osoby mówiącej do odczytania.
- Unikaj zbyt wielu podobnych wzorców dla słów/fraz, takich jak "łatwe" i "łatwiejsze".
- Uwzględnij różne formaty liczb: adres, jednostka, telefon, ilość, data itd. we wszystkich typach zdań.
- Uwzględnij zdania pisowni, jeśli jest to coś, co odczytuje niestandardowy neuronowy głos. Na przykład "Pisownia Apple to P P L E".
Nie umieszczaj wielu zdań w jednej wierszu/jednej wypowiedzi. Oddziel każdy wiersz według wypowiedzi.
Upewnij się, że zdanie jest czyste. Ogólnie rzecz biorąc, nie dołączaj zbyt wielu niestandardowych słów, takich jak liczby lub skróty, ponieważ trudno je odczytać. Niektóre aplikacje mogą wymagać odczytywania wielu liczb lub akronimów. W takich przypadkach można uwzględnić te słowa, ale znormalizować je w postaci mówionej.
Poniżej przedstawiono kilka najlepszych rozwiązań, na przykład:
- W przypadku wierszy ze skrótami zamiast "BTW" wpisz ciąg "by the way".
- W przypadku wierszy z cyframi zamiast "911" wpisz "dziewięć jeden".
- W przypadku wierszy z akronimami zamiast "ABC" wpisz "A B C".
Dzięki temu upewnij się, że twój talent głosowy wymawia te słowa w oczekiwany sposób. Zachowaj dopasowanie skryptu i nagrań podczas procesu trenowania.
Skrypt powinien zawierać wiele różnych słów i zdań o różnych rodzajach długości zdań, struktur i nastrojów.
Dokładnie sprawdź skrypt pod kątem błędów. Jeśli to możliwe, poproś kogoś innego, aby go również sprawdzić. Po uruchomieniu skryptu z talentem głosowym możesz złapać więcej błędów.
Różnica między skryptem talentu głosowego a skryptem treningu
Skrypt szkoleniowy może różnić się od skryptu talentu głosowego, zwłaszcza w przypadku skryptów zawierających cyfry, symbole, skróty, datę i godzinę. Skrypty przygotowane dla talentów głosowych muszą przestrzegać natywnych konwencji czytania, takich jak 50% i 45 dolarów. Skrypty używane do trenowania muszą być znormalizowane w celu dopasowania do nagrania audio, takiego jak pięćdziesiąt procent i czterdzieści pięć dolarów.
Uwaga
Udostępniamy przykładowe skrypty dla talentów głosowych w usłudze GitHub. Aby użyć przykładowych skryptów do trenowania, należy je znormalizować zgodnie z nagraniami talentu głosowego przed przekazaniem pliku.
W poniższej tabeli przedstawiono różnicę między skryptami dla talentów głosowych a znormalizowany skrypt do trenowania.
| Kategoria | Przykładowy skrypt talentu głosowego | Przykładowy skrypt trenowania (znormalizowany) |
|---|---|---|
| Cyfry | 123 | sto dwudziestu trzech |
| Symbole | 50% | pięćdziesiąt procent |
| Skrót | ASAP | Jak najwcześniej |
| Data i godzina | 3 marca o 17:00 | Trzeci marzec o pięciu pm |
Typowe wady skryptu
Niska jakość skryptu może niekorzystnie wpłynąć na wyniki trenowania. Aby uzyskać wysokiej jakości wyniki trenowania, ważne jest, aby uniknąć wad.
Wady skryptu zazwyczaj należą do następujących kategorii:
| Kategoria | Przykład |
|---|---|
| Bezsensowna zawartość. | "Kolorowe zielone pomysły śpią wściekle." |
| Niepełne zdania. | - "To była moja ostatnia wigilia" (bez tematu, bez konkretnego znaczenia) - "Są już zabawne (bez znaku cudzysłowu w końcu, to nie jest pełne zdanie) |
| Literówka w zdaniach. | — Zacznij od małej litery - Brak zakończenia interpunkcji w razie potrzeby -Błąd pisowni - Brak interpunkcji: brak kropki w końcu (z wyjątkiem tytułu wiadomości) - Koniec z symbolami, z wyjątkiem przecinka, pytanie, wykrzyknik - Nieprawidłowy format, taki jak: - 45$ (powinno wynosić 45 USD) - Brak spacji lub nadmiaru odstępu między wyrazami/interpunkcjami |
| Duplikowanie w podobnym formacie wystarczy jeden na każdy wzorzec. | - "Teraz jest 1pm w Nowym Jorku" - "Teraz jest 2pm w Nowym Jorku" - "Teraz jest 15:00 w Nowym Jorku" - "Teraz jest 1pm w Seattle" - "Teraz jest 1pm w Waszyngtonie." |
| Nietypowe wyrazy obce: w skrycie dopuszczalne są tylko często używane słowa obce. | W języku angielskim można użyć francuskiego słowa "faux" w wspólnym przemówieniu, ale francuskie wyrażenie, takie jak "coincer la bulle" byłoby rzadkością. |
| Emoji lub inne nietypowe symbole |
Format skryptu
Skrypt jest używany podczas sesji nagrywania, dzięki czemu można go skonfigurować w dowolny sposób, z którym można łatwo pracować. Utwórz oddzielnie plik tekstowy wymagany przez program Speech Studio.
Podstawowy format skryptu zawiera trzy kolumny:
- Liczba wypowiedzi rozpoczynająca się od 1. Numerowanie ułatwia wszystkim osobom w studio odwoływanie się do określonej wypowiedzi ("spróbujmy ponownie numer 356"). Funkcja numerowania akapitów programu Microsoft Word umożliwia automatyczne numerowanie wierszy tabeli.
- Pusta kolumna, w której zapisujesz kod liczby lub czasu każdej wypowiedzi, aby ułatwić znalezienie go w zakończeniu nagrywania.
- Tekst samej wypowiedzi.
Uwaga
Większość studiów rejestruje się w krótkich segmentach znanych jako "takes". Każde z nich zwykle zawiera od 10 do 24 wypowiedzi. Po prostu zauważanie liczby podjęcia jest wystarczające, aby znaleźć wypowiedź później. Jeśli nagrywasz w studio, które preferuje dłuższe nagrania, warto zanotować kod czasu. Studio będzie miało widoczny czas wyświetlania.
Pozostaw wystarczającą ilość miejsca po każdym wierszu, aby zapisywać notatki. Upewnij się, że żadna wypowiedź nie jest podzielona między stronami. Numeruj strony i wydrukuj skrypt po jednej stronie papieru.
Drukuj trzy kopie skryptu: jeden dla talentu głosowego, jeden dla inżyniera nagrywania i jeden dla reżysera (ty). Użyj klipu papieru zamiast zszywek: doświadczony artysta głosowy oddziela strony, aby uniknąć szumu, gdy strony są obracane.
Instrukcja talentu głosowego
Aby wytrenować głos neuronowy, należy utworzyć profil talentów głosowych z plikiem audio zarejestrowanym przez talent głosowy wyrażający zgodę na użycie danych mowy w celu wytrenowania niestandardowego modelu głosu. Podczas przygotowywania skryptu nagrywania upewnij się, że zawierasz zdanie instrukcji.
Legalności
Zgodnie z prawem autorskim czytanie tekstu chronionego prawem autorskim przez aktora może być występem, dla którego autor pracy powinien zostać zrekompensowany. Ta wydajność nie będzie rozpoznawalna w końcowym produkcie, niestandardowym neuronowym głosie. Mimo to legalność korzystania z pracy chronionej prawem autorskim w tym celu nie jest dobrze ugruntowana. Firma Microsoft nie może udzielić porad prawnych dotyczących tego problemu; skontaktuj się z własnym radcą prawnym.
Na szczęście można całkowicie uniknąć tych problemów. Istnieje wiele źródeł tekstu, których można używać bez uprawnień lub licencji.
| Źródło tekstu | opis |
|---|---|
| Korpus arktyczny CMU | Około 1100 zdań wybranych z poza prawami autorskimi działa specjalnie do użytku w projektach syntezy mowy. Doskonały punkt wyjścia. |
| Działa już nie zgodnie z prawami autorskimi |
Zazwyczaj prace opublikowane przed 1923 roku. W przypadku języka angielskiego projekt Gutenberg oferuje dziesiątki tysięcy takich prac. Możesz skupić się na nowszych pracach, ponieważ język jest bliżej nowoczesnego języka angielskiego. |
| Prace rządowe | Prace utworzone przez rząd Stany Zjednoczone nie są chronione prawami autorskimi w Stany Zjednoczone, choć rząd może ubiegać się o prawa autorskie w innych krajach/regionach. |
| Domena publiczna | Działa, dla których prawa autorskie są jawnie niedozwolone lub przeznaczone dla domeny publicznej. Nie można całkowicie zrezygnować z praw autorskich w niektórych jurysdykcjach. |
| Permissively licencjonowane prace | Prace rozpowszechniane na podstawie licencji, takiej jak Creative Commons lub licencja GFDL (GNU Free Documentation License). Wikipedia używa języka GFDL. Niektóre licencje mogą jednak nakładać ograniczenia dotyczące wydajności licencjonowanej zawartości, która może mieć wpływ na tworzenie niestandardowego modelu neuronowego głosu, więc uważnie przeczytaj licencję. |
Rejestrowanie skryptu
Nagraj swój skrypt w profesjonalnym studio nagraniowym, które specjalizuje się w pracy głosowej. Mają kabinę do nagrywania, odpowiedni sprzęt i odpowiednie osoby, aby go obsługiwać. Zaleca się, aby nie pomijać nagrywania.
Porozmawiaj o projekcie z inżynierem nagrywania studia i posłuchaj swoich porad. Nagranie powinno mieć małą lub brak kompresji zakresu dynamicznego (maksymalnie 4:1). Ważne jest, aby dźwięk miał stały głośność i wysoki współczynnik sygnału do szumu, a jednocześnie jest wolny od niechcianych dźwięków.
Wymagania dotyczące rejestrowania
Aby uzyskać wysokiej jakości wyniki szkolenia, wykonaj następujące wymagania podczas rejestrowania lub przygotowywania danych:
Jasne i dobrze wymawiane
Szybkość naturalna: zbyt wolno lub zbyt szybko między plikami audio.
Odpowiedni wolumin, prosody i przerwanie: stabilne w obrębie tego samego zdania lub między zdaniami, poprawną przerwę dla interpunkcji.
Brak szumu podczas nagrywania
Dopasuj projekt osoby
Brak nieprawidłowego akcentu: dopasowanie do projektu docelowego
Brak nieprawidłowej wymowy
Poniżej przedstawiono specyfikację, aby przygotować się do przykładów dźwiękowych jako najlepsze rozwiązanie.
| Właściwości | Wartość |
|---|---|
| File format | *.wav, Mono |
| Częstotliwość próbkowania | 24 KHz |
| Format próbki | 16-bitowy, PCM |
| Szczytowe poziomy woluminu | -3 dB do -6 dB |
| SNR | > 35 dB |
| Wyciszyć | - Powinna istnieć cisza (zalecane 100 ms) na początku i na końcu, ale nie dłużej niż 200 ms - Milczenie między wyrazami lub frazami < -30 dB - Milczenie na fali po ostatnim słowie mówi <-60 dB |
| Szum środowiska lub echo | - Poziom hałasu na początku fali przed mówieniem < -70 dB |
Uwaga
Można rejestrować przy większej szybkości próbkowania i głębokości bitów, na przykład w formacie 48 KHz 24-bitowej PCM. Podczas niestandardowego trenowania neuronowego głosu będziemy automatycznie próbkować go do 24 KHz 16-bitowego PCM.
Wyższy współczynnik sygnału do szumu (SNR) wskazuje niższy szum w dźwięku. Zazwyczaj można dotrzeć do 35+ SNR, nagrywając w profesjonalnych studiach. Dźwięk ze snr poniżej 20 może spowodować oczywisty szum w wygenerowanym głosie.
Rozważ ponowne rejestrowanie wszystkich wypowiedzi z niskimi wynikami wymowy lub słabymi współczynnikami sygnału do szumu. Jeśli nie możesz ponownie rejestrować, rozważ wykluczenie tych wypowiedzi z danych.
Typowe błędy audio
W przypadku wyników treningowych wysokiej jakości zdecydowanie zaleca się unikanie błędów dźwięku. Błędy audio są zwykle w następujących kategoriach:
Nazwa pliku audio nie jest zgodna z identyfikatorem skryptu.
Plik WAR ma nieprawidłowy format i nie można go odczytać.
Częstotliwość próbkowania audio jest niższa niż 16 KHz. Zaleca się, aby częstotliwość próbkowania plików .wav była równa lub wyższa niż 24 KHz dla wysokiej jakości głosu neuronowego.
Szczyt woluminu nie mieści się w zakresie -3 dB (70% maksymalnej objętości) do -6 dB (50%).
Przepełnienie kształtów falowych: kształt fali jest wycinany z wartością szczytową i dlatego nie jest kompletny.
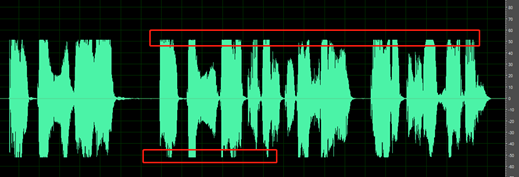
Ciche części nagrania nie są czyste; można usłyszeć dźwięki, takie jak hałas otoczenia, szum jamy ustnej i echo.
Na przykład poniższy dźwięk zawiera szum środowiska między wystąpieniami.
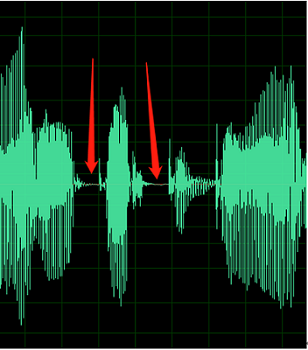
Poniższy przykład zawiera oznaki przesunięcia kontrolera domeny lub echa.
Ogólny wolumin jest zbyt niski. Dane są oznaczone jako problem, jeśli wolumin jest mniejszy niż -18 dB (10% maksymalnego woluminu). Upewnij się, że wszystkie pliki audio powinny być spójne na tym samym poziomie głośności.
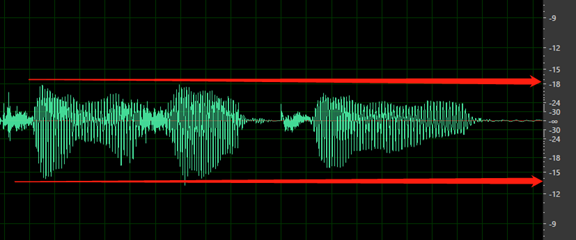
Brak ciszy przed pierwszym słowem lub po ostatnim słowie. Ponadto cisza początkowa lub końcowa nie powinna być dłuższa niż 200 ms lub krótsza niż 100 ms.
Zrób to sam
Jeśli chcesz zrobić nagranie samodzielnie, zamiast iść do studia nagraniowego, oto krótki primer. Dzięki wzrostowi nagrywania i podkastowania do domu łatwiej niż kiedykolwiek znaleźć dobre porady i zasoby nagrywania online.
"Kabina nagrywania" powinna być małym pokojem bez zauważalnego echa ani "tonu pomieszczenia". Powinno to być tak ciche i dźwiękoszczelne, jak to możliwe. Drapes na ścianach może służyć do zmniejszenia echa i neutralizacji lub "martwy" dźwięk pokoju.
Używaj wysokiej jakości mikrofonu kondensera studio ("mikrofon" w skrócie) przeznaczonego do nagrywania głosu. Sennheiser, AKG, a nawet nowsze mikrofony Zoom mogą przynieść dobre wyniki. Możesz kupić mikrofon lub wynająć go z lokalnej firmy wynajmu audio-wizualnej. Poszukaj jednego z interfejsem USB. Ten typ mikrofonu wygodnie łączy element mikrofonu, preamp i konwerter analogowy-cyfrowy w jednym pakiecie, upraszczając podłączanie.
Możesz również użyć mikrofonu analogowych. Wiele domów wynajmu oferuje "vintage" mikrofony znane ze swojego charakteru głosowego. Profesjonalny sprzęt analogowy używa zrównoważonych łączników XLR, a nie 1/4-calowej wtyczki używanej w sprzęcie konsumenckim. Jeśli przejdziesz analogowo, będziesz również potrzebować preamp i interfejsu audio komputera z tymi łącznikami.
Zainstaluj mikrofon na stojaku lub boomie i zainstaluj filtr pop przed mikrofonem, aby wyeliminować szum z "plosive" konspekty, takie jak "p" i "b". Niektóre mikrofony są wyposażone w zawieszenie, które izolują je od drgań w stojaku, co jest pomocne.
Talent głosu musi pozostać w stałej odległości od mikrofonu. Użyj taśmy na podłodze, aby zaznaczyć, gdzie powinny stać. Jeśli talent woli usiąść, należy zachować szczególną ostrożność, aby monitorować odległość mikrofonu i unikać szumu krzesła.
Użyj stoiska do przechowywania skryptu. Unikaj angling stojaka, aby odzwierciedlał dźwięk w kierunku mikrofonu.
Osoba obsługująca sprzęt nagraniowy — inżynier nagrywania — powinna znajdować się w osobnym pomieszczeniu od talentu, a w jakiś sposób porozmawiać z talentem w kabinie nagrywania ( obwód talkbacku).
Nagranie powinno zawierać jak najmniej szumu, z celem -80 dB.
Uważnie słuchaj nagrania ciszy w "kabinie", dowiedzieć się, skąd pochodzi jakikolwiek hałas, i wyeliminować przyczynę. Typowe źródła hałasu to otwory wentylacyjne, świetlówki światła, ruch na pobliskich drogach i wentylatory sprzętu (nawet komputery notebookowe mogą mieć wentylatory). Mikrofony i kable mogą odbierać szum elektryczny z pobliskiego okablowania AC, zwykle hum lub buzz. Szum może być również spowodowany przez pętlę naziemną, która jest spowodowana tym, że sprzęt jest podłączony do więcej niż jednego obwodu elektrycznego.
Napiwek
W niektórych przypadkach można użyć wtyczki do korektora lub oprogramowania redukcji szumu, aby pomóc usunąć szum z nagrań, chociaż zawsze najlepiej zatrzymać go w jego źródle.
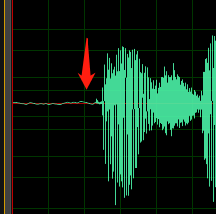
Ustaw poziomy tak, aby większość dostępnego zakresu dynamicznego nagrywania cyfrowego była używana bez nadmiernego zwiększania. Oznacza to, że dźwięk jest głośny, ale nie tak głośny, że staje się zniekształcony. Przykładowy kształt fali dobrego nagrania przedstawiono na poniższej ilustracji:
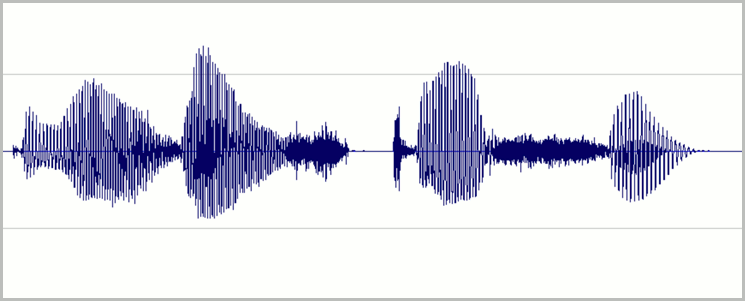
W tym przypadku większość zakresu (wysokość) jest używana, ale najwyższe szczyty sygnału nie docierają do góry ani dolnej części okna. Widać również, że cisza w nagraniu przybliża cienką linię poziomą wskazującą niską podłogę szumu. To nagranie ma akceptowalny zakres dynamiczny i współczynnik sygnału do szumu.
Zarejestruj bezpośrednio w komputerze za pośrednictwem wysokiej jakości interfejsu audio lub portu USB, w zależności od używanego mikrofonu. W przypadku analogii zachowaj prosty łańcuch audio: mikrofon, preamp, interfejs dźwiękowy, komputer. Możesz licencjonować zarówno narzędzia Avid Pro, jak i program Adobe Audition miesięcznie przy rozsądnym koszcie. Jeśli budżet jest bardzo napięty, spróbuj wolnej Audacity.
Nagrywaj przy 44,1 KHz 16-bitowej monofonicznej (jakości CD) lub lepszej. Aktualny stan sprzętu to 48 KHz 24-bitowy, jeśli twój sprzęt go obsługuje. Przed przesłaniem go do usługi Speech Studio próbkujesz dźwięk do 24 KHz 16-bitowego. Mimo to, opłaca się mieć wysokiej jakości oryginalne nagranie w przypadku, że edycje są potrzebne.
Najlepiej mieć różne osoby pełnią rolę reżysera, inżyniera i talentu. Nie próbuj robić tego wszystkiego samodzielnie. W szczypce jedna osoba może być zarówno dyrektorem, jak i inżynierem.
Przed sesją
Aby uniknąć marnowania czasu studio, uruchom skrypt z talentem głosowym przed sesją nagrywania. Podczas gdy talent głosowy staje się zaznajomiony z tekstem, może wyjaśnić wymowę jakichkolwiek nieznanych słów.
Uwaga
Większość studiów nagraniowych oferuje elektroniczny wyświetlacz skryptów w kabinie nagraniowej. W takim przypadku wpisz notatki uruchamiane bezpośrednio w dokumencie skryptu. Nadal jednak chcesz, aby kopia papieru sporządzała notatki podczas sesji. Większość inżynierów będzie również chciała użyć kopii twardej. W przypadku, gdy komputer nie działa, nadal potrzebujesz trzeciej drukowanej kopii zapasowej dla talentu.
Twój talent głosowy może zapytać, które słowo chcesz podkreślić w wypowiedzi ("słowo operacyjne"). Powiedz im, że chcesz naturalne czytanie bez szczególnego nacisku. Wyróżnienie można dodać, gdy mowa jest syntetyzowana; nie powinien być częścią oryginalnego nagrania.
Przekierowuj talent, aby wyraźnie wymawiać słowa. Każde słowo skryptu powinno być wymawiane jako napisane. Dźwięki nie powinny być pomijane ani oszczerzone razem, jak to jest powszechne w swobodnej mowie, chyba że zostały napisane w ten sposób w skrypcie.
| Tekst pisany | Niechciany przypadkowy wymowa |
|---|---|
| nigdy się nie podda | nigdy się nie podda |
| istnieją cztery światła | są cztery światła |
| jak pogoda dzisiaj | jak dziś jest pogoda |
| powiedz cześć mojemu małemu przyjacielowi | powiedz cześć mojemu przyjacielowi lil |
Talent nie powinien* dodać odrębnych pauzy między słowami. Zdanie powinno nadal płynąć naturalnie, nawet gdy brzmi trochę formalnie. To drobne rozróżnienie może podjąć praktykę, aby uzyskać rację.
Sesja nagrywania
Utwórz nagranie odwołania lub plik dopasowania typowej wypowiedzi na początku sesji. Poproś talent o powtórzenie tego wiersza na każdej stronie. Za każdym razem porównaj nowe nagranie z odwołaniem. Ta praktyka pomaga talentowi zachować spójność objętości, tempa, skoku i intonacji. W międzyczasie inżynier może użyć pliku dopasowania jako odwołania do poziomów i ogólnej spójności dźwięku.
Plik dopasowania jest szczególnie ważny, gdy wznowisz nagrywanie po przerwie lub w innym dniu. Graj to kilka razy dla talentu i mają je powtarzać za każdym razem, aż pasują dobrze.
Aby nagrać korpus z określonym stylem, starannie wybierz skrypty, które prezentują żądany styl. Podczas nagrywania upewnij się, że talent głosowy utrzymuje się na stałym poziomie głośności, tempa, skoku i tonu, aby osiągnąć nagrania, które uosabiają zamierzony styl.
Trenowanie talentu, aby wziąć głęboki oddech i wstrzymać się na chwilę przed każdą wypowiedzią. Nagraj kilka sekund ciszy między wypowiedziami. Wyrazy powinny być wymawiane w taki sam sposób, gdy pojawiają się, biorąc pod uwagę kontekst. Na przykład "rekord" jako czasownik jest wymawiany inaczej niż "record" jako rzeczownik.
Nagraj około pięciu sekund ciszy przed pierwszym nagraniem, aby uchwycić "ton pokoju". Ta praktyka pomaga usłudze Speech Studio zrekompensować hałas w nagraniach.
Napiwek
Wszystko, co musisz uchwycić, to talent głosowy, dzięki czemu można zrobić monofoniczne (jednokanałowe) nagranie tylko ich linii. Jeśli jednak rejestrujesz w stereo, możesz użyć drugiego kanału, aby nagrać gawędę w pomieszczeniu sterowania, aby przechwycić dyskusję na temat określonych linii lub przyjmuje. Usuń ten utwór z wersji przekazanej do programu Speech Studio.
Uważnie słuchaj, korzystając ze słuchawek, do występu talentów głosowych. Szukasz dobrego, ale naturalnego słownika, poprawnej wymowy i braku niechcianych dźwięków. Nie wahaj się poprosić swojego talentu o ponowne zarejestrowanie wypowiedzi, która nie spełnia tych standardów.
Napiwek
Jeśli używasz dużej liczby wypowiedzi, pojedyncza wypowiedź może nie mieć zauważalnego wpływu na wynikowy niestandardowy neuronowy głos. Może to być bardziej celowe, aby po prostu zanotować wszelkie wypowiedzi z problemami, wykluczyć je z zestawu danych i zobaczyć, jak okazuje się niestandardowy neuronowy głos. Zawsze możesz wrócić do studia i nagrać pominięte próbki później.
Zanotuj liczbę lub kod czasu w skrycie dla każdej wypowiedzi. Poproś inżyniera, aby oznaczył każdą wypowiedź w metadanych nagrania lub arkuszu wskazówek.
Podjąć regularne przerwy i zapewnić napój, aby pomóc talentowi głosu utrzymać swój głos w dobrej formie.
Po sesji
Nowoczesne studia nagraniowe działają na komputerach. Na końcu sesji otrzymasz co najmniej jeden plik audio, a nie taśmę. Te pliki są prawdopodobnie formatami WAV lub AIFF w jakości CD (44,1 KHz 16-bitowej) lub lepszej. 16-bitowa 24 KHz jest powszechna i pożądana. Domyślna częstotliwość próbkowania niestandardowego neuronowego głosu wynosi 24 KHz. Zaleca się użycie częstotliwości próbkowania wynoszącej 24 KHz dla danych treningowych. Wyższe częstotliwości próbkowania, takie jak 96 KHz, nie są zwykle potrzebne.
Usługa Speech Studio wymaga, aby każda podana wypowiedź znajdowała się we własnym pliku. Każdy plik dźwiękowy dostarczony przez studio zawiera wiele wypowiedzi. Dlatego podstawowym zadaniem poprodukcyjnym jest podzielenie nagrań i przygotowanie ich do przesłania. Inżynier nagrywania mógł umieścić znaczniki w pliku (lub pod warunkiem oddzielnego arkusza wskazówek), aby wskazać, gdzie rozpoczyna się każda wypowiedź.
Użyj notatek, aby znaleźć dokładnie wybrane elementy, a następnie użyj narzędzia do edycji dźwięku, takiego jak Avid Pro Tools, Adobe Audition lub free Audacity, aby skopiować każdą wypowiedź do nowego pliku.
Uważnie słuchaj każdego pliku. Na tym etapie można edytować małe niechciane dźwięki, które przegapiłeś podczas nagrywania, jak lekki smack warg przed linią, ale uważaj, aby nie usunąć żadnej rzeczywistej mowy. Jeśli nie możesz naprawić pliku, usuń go z zestawu danych i zwróć uwagę, że to zrobiono.
Przekonwertuj każdy plik na 16 bitów i częstotliwość próbkowania wynoszącą 24 KHz przed zapisaniem, a jeśli nagrano czatter studio, usuń drugi kanał. Zapisz każdy plik w formacie WAV, nazewając pliki numerem wypowiedzi ze skryptu.
Na koniec utwórz transkrypcję, która kojarzy każdy plik WAV z wersją tekstową odpowiadającej mu wypowiedzi. Trenowanie modelu głosu zawiera szczegóły wymaganego formatu. Tekst można skopiować bezpośrednio ze skryptu. Następnie utwórz plik Zip plików WAV i transkrypcję tekstową.
Zarchiwizuj oryginalne nagrania w bezpiecznym miejscu, jeśli będą potrzebne później. Zachowaj również skrypt i notatki.
Następne kroki
Możesz przekazać nagrania i utworzyć niestandardowy neuronowy głos.