Najlepsze rozwiązania dotyczące skalowania aprowizowanej przepływności (RU/s)
DOTYCZY: ![]() Nosql
Nosql ![]() Mongodb
Mongodb ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tabeli
Tabeli
W tym artykule opisano najlepsze rozwiązania i strategie skalowania przepływności (RU/s) bazy danych lub kontenera (kolekcji, tabeli lub grafu). Te pojęcia mają zastosowanie podczas zwiększania liczby aprowizowania ręcznie jednostek RU/s lub maksymalnej liczby jednostek RU/s autoskalowania dowolnego zasobu dla dowolnego interfejsu API usługi Azure Cosmos DB.
Wymagania wstępne
- Jeśli dopiero zaczynasz partycjonować i skalować w usłudze Azure Cosmos DB, zalecamy przeczytanie artykułu Partycjonowanie i skalowanie w poziomie w usłudze Azure Cosmos DB.
- Jeśli planujesz skalowanie jednostek RU/s z powodu wyjątków 429, zapoznaj się ze wskazówkami w artykule Diagnozowanie i rozwiązywanie problemów z zbyt dużymi (429) wyjątkami liczby żądań usługi Azure Cosmos DB. Przed zwiększeniem liczby jednostek RU/s zidentyfikuj główną przyczynę problemu i czy zwiększenie liczby jednostek RU/s jest właściwym rozwiązaniem.
Tło dotyczące skalowania jednostek RU/s
Gdy wyślesz żądanie zwiększenia liczby jednostek RU/s bazy danych lub kontenera, w zależności od żądanego ru/s i bieżącego układu partycji fizycznej, operacja skalowania w górę zostanie ukończona natychmiast lub asynchronicznie (zazwyczaj 4–6 godzin).
- Natychmiastowe skalowanie w górę
- Jeśli żądane jednostki RU/s mogą być obsługiwane przez bieżący układ partycji fizycznej, usługa Azure Cosmos DB nie musi dzielić ani dodawać nowych partycji.
- W związku z tym operacja jest wykonywana natychmiast, a ru/s są dostępne do użycia.
- Asynchroniczne skalowanie w górę
- Gdy żądana liczba jednostek RU/s jest wyższa niż to, co może być obsługiwane przez układ partycji fizycznej, usługa Azure Cosmos DB podzieli istniejące partycje fizyczne. Dzieje się tak, dopóki zasób ma minimalną liczbę partycji wymaganą do obsługi żądanej liczby jednostek RU/s.
- W rezultacie wykonanie operacji może zająć trochę czasu, zazwyczaj od 4 do 6 godzin. Każda partycja fizyczna może obsługiwać maksymalnie 10 000 RU/s (dotyczy wszystkich interfejsów API) przepływności i 50 GB magazynu (dotyczy wszystkich interfejsów API, z wyjątkiem rozwiązania Cassandra, które ma 30 GB magazynu).
Uwaga
Jeśli wykonasz ręczną operację trybu failover w regionie lub dodasz/usuń nowy region, podczas gdy operacja skalowania asynchronicznego w górę jest w toku, operacja skalowania przepływności zostanie wstrzymana. Zostanie ona wznowiona automatycznie po zakończeniu operacji przełączania w tryb failover lub dodawania/usuwania regionu.
- Natychmiastowe skalowanie w dół
- W przypadku operacji skalowania w dół usługa Azure Cosmos DB nie musi dzielić ani dodawać nowych partycji.
- W związku z tym operacja jest wykonywana natychmiast, a ru/s są dostępne do użycia,
- Kluczowym wynikiem tej operacji jest zmniejszenie liczby jednostek RU na partycję fizyczną.
Jak skalować w górę ru/s bez zmieniania układu partycji
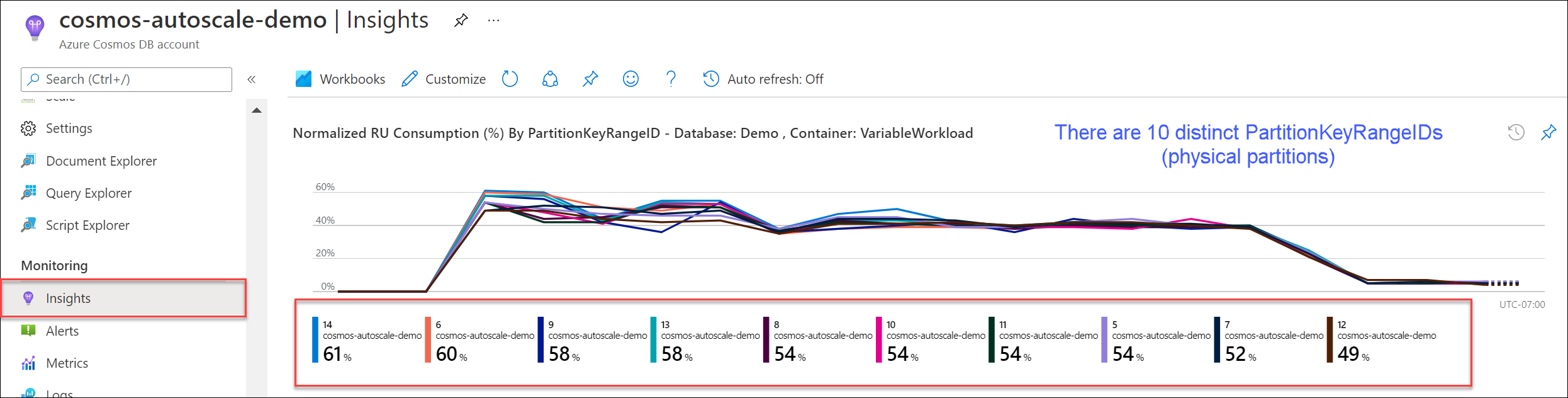
Krok 1. Znajdowanie bieżącej liczby partycji fizycznych.
Przejdź do Szczegółowe informacje> Użycie znormalizowanego jednostek RU (>%) według partitionKeyRangeID. Zlicz unikatową liczbę identyfikatorów PartitionKeyRangeId.
Uwaga
Wykres będzie zawierać maksymalnie 50 identyfikatorów PartitionKeyRangeId. Jeśli zasób ma więcej niż 50, możesz użyć interfejsu API REST usługi Azure Cosmos DB, aby zliczyć łączną liczbę partycji.
Każda partycja PartitionKeyRangeId mapuje na jedną partycję fizyczną i jest przypisywana do przechowywania danych dla zakresu możliwych wartości skrótu.
Usługa Azure Cosmos DB dystrybuuje dane między partycjami logicznymi i fizycznymi na podstawie klucza partycji, aby umożliwić skalowanie w poziomie. W miarę zapisywania danych usługa Azure Cosmos DB używa skrótu wartości klucza partycji w celu określenia, która partycja logiczna i fizyczna znajdują się w danych.
Krok 2. Obliczanie domyślnej maksymalnej przepływności
Największa liczba jednostek RU/s, do których można przeprowadzić skalowanie bez wyzwalania usługi Azure Cosmos DB w celu podzielenia partycji, jest równa Current number of physical partitions * 10,000 RU/s. Tę wartość można uzyskać od dostawcy zasobów usługi Azure Cosmos DB. Wykonaj żądanie GET dla obiektów ustawień przepływności bazy danych lub kontenerainstantMaximumThroughput i pobierz właściwość. Ta wartość jest również dostępna na stronie Skalowanie i Ustawienia bazy danych lub kontenera w portalu.
Przykład
Załóżmy, że mamy istniejący kontener z pięcioma partycjami fizycznymi i 30 000 RU/s przepływności aprowizowanej ręcznie. Możemy zwiększyć wartość RU/s do 5 * 10 000 RU/s = 50 000 RU/s natychmiast. Podobnie, jeśli mieliśmy kontener z maksymalną wartością RU/s autoskalowania 30 000 RU/s (skaluje się między 3000 a 30 000 RU/s), możemy zwiększyć maksymalną wartość RU/s do 50 000 RU/s (skalowanie z zakresu od 5000 do 50 000 RU/s).
Napiwek
W przypadku skalowania jednostek RU/s w górę w celu reagowania na zbyt duże wyjątki (429s), zaleca się najpierw zwiększenie liczby jednostek RU/s do najwyższych jednostek RU/s obsługiwanych przez bieżący układ partycji fizycznej i ocenę, czy nowe jednostki RU/s są wystarczające przed dalszym zwiększeniem.
Jak zapewnić równomierną dystrybucję danych podczas skalowania asynchronicznego
Tło
Po zwiększeniu liczby jednostek RU/s poza bieżącą liczbą partycji fizycznych * 10 000 RU/s usługa Azure Cosmos DB dzieli istniejące partycje, aż do nowej liczby partycji = ROUNDUP(requested RU/s / 10,000 RU/s). Podczas dzielenia partycje nadrzędne są podzielone na dwie partycje podrzędne.
Załóżmy na przykład, że mamy kontener z trzema partycjami fizycznymi i 30 000 RU/s przepływności aprowizowanej ręcznie. Jeśli zwiększymy przepływność do 45 000 RU/s, usługa Azure Cosmos DB podzieli dwie z istniejących partycji fizycznych, tak aby łącznie było ROUNDUP(45,000 RU/s / 10,000 RU/s) to 5 partycji fizycznych.
Uwaga
Aplikacje zawsze mogą pozyskiwać dane lub wysyłać do nich zapytania podczas dzielenia. Zestawy SDK klienta usługi Azure Cosmos DB automatycznie obsługują ten scenariusz i zapewniają kierowanie żądań do poprawnej partycji fizycznej, więc nie jest wymagana żadna dodatkowa akcja użytkownika.
Jeśli masz obciążenie, które jest bardzo równomiernie dystrybuowane w odniesieniu do magazynu i woluminu żądań — zwykle wykonywane przez partycjonowanie według pól o wysokiej kardynalności, takich jak /id — zaleca się skalowanie w górę, skonfigurowanie jednostek RU/s tak, aby wszystkie partycje zostały równomiernie podzielone.
Aby zobaczyć, dlaczego, weźmy przykład, w którym mamy istniejący kontener z 2 partycjami fizycznymi, 20 000 RU/s i 80 GB danych.
Dzięki wybraniu dobrego klucza partycji o wysokiej kardynalności dane są w przybliżeniu równomiernie dystrybuowane w obu partycjach fizycznych. Każda partycja fizyczna jest przypisywana w przybliżeniu 50% przestrzeni kluczy, która jest zdefiniowana jako całkowity zakres możliwych wartości skrótu.
Ponadto usługa Azure Cosmos DB równomiernie dystrybuuje jednostki RU/s we wszystkich partycjach fizycznych. W rezultacie każda partycja fizyczna ma 10 000 RU/s i 50% (40 GB) łącznej ilości danych. Na poniższym diagramie przedstawiono bieżący stan.

Teraz załóżmy, że chcemy zwiększyć liczbę ru/s z 20 000 RU/s do 30 000 RU/s.
Jeśli po prostu zwiększymy wartość RU/s do 30 000 RU/s, zostanie podzielona tylko jedna z partycji. Po podziale będziemy mieć następujące elementy:
- Jedna partycja zawierająca 50% danych (ta partycja nie została podzielona)
- Dwie partycje zawierające 25% danych (są to wynikowe partycje podrzędne z elementu nadrzędnego, który został podzielony)
Ponieważ usługa Azure Cosmos DB równomiernie dystrybuuje jednostki RU/s we wszystkich partycjach fizycznych, każda partycja fizyczna nadal będzie mieć 10 000 RU/s. Jednak mamy teraz niesymetryczność w magazynie i dystrybucji żądań.
Na poniższym diagramie widać, że partycje 3 i 4 (partycje podrzędne partycji 2) mają 10 000 RU/s do obsługi żądań dla 20 GB danych, podczas gdy partycja 1 ma 10 000 RU/s do obsługi żądań dwukrotnie większej ilości danych (40 GB).

Aby zachować równomierną dystrybucję magazynu, możemy najpierw skalować w górę jednostki RU/s, aby zapewnić podziały partycji. Następnie możemy obniżyć wartość RU/s z powrotem do żądanego stanu.
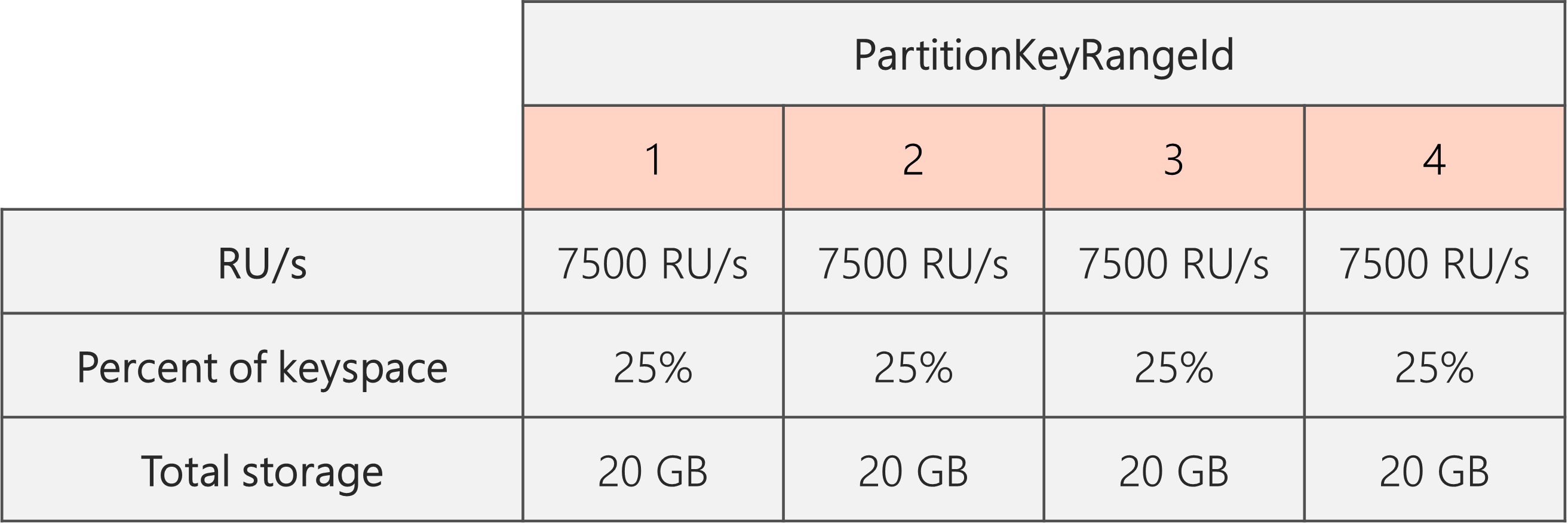
Dlatego jeśli zaczniemy od dwóch partycji fizycznych, aby zagwarantować, że partycje są nawet podzielone po podzieleniu, musimy ustawić jednostki RU/s tak, że skończymy z czterema partycjami fizycznymi. Aby to osiągnąć, najpierw ustawimy ru/s = 4 * 10 000 RU/s na partycję = 40 000 RU/s. Następnie po zakończeniu podziału możemy obniżyć wartość RU/s do 30 000 RU/s.
W rezultacie na poniższym diagramie widać, że każda partycja fizyczna pobiera 30 000 RU/s / 4 = 7500 RU/s do obsługi żądań dla 20 GB danych. Ogólnie rzecz biorąc, utrzymujemy równomierny magazyn i dystrybucję żądań między partycjami.
Formuła ogólna
Krok 1. Zwiększ liczbę jednostek RU/s, aby zagwarantować równomierne podzielenie wszystkich partycji
Ogólnie rzecz biorąc, jeśli masz początkową liczbę partycji fizycznych Pi chcesz ustawić żądaną wartość RU/s S:
Zwiększ liczbę jednostek RU/s do: 10,000 * P * (2 ^ (ROUNDUP(LOG_2 (S/(10,000 * P)))). Daje to najbliżej ru/s żądanej wartości, która zapewni równomierne podzielenie wszystkich partycji.
Uwaga
W przypadku zwiększenia liczby jednostek RU/s bazy danych lub kontenera może to mieć wpływ na minimalną liczbę jednostek RU/s, które można obniżyć w przyszłości. Zazwyczaj minimalna liczba jednostek RU/s jest równa max(400 RU/s, bieżący magazyn w GB * 1 RU/s, najwyższa liczba ru/s kiedykolwiek aprowizowana / 100). Jeśli na przykład największa liczba jednostek RU/s, do których kiedykolwiek skalowano, wynosi 100 000 RU/s, najniższa wartość RU/s, którą można ustawić w przyszłości, wynosi 1000 RU/s. Dowiedz się więcej o minimalnej jednostki RU/s.
Krok 2. Obniż wartość ru/s do żądanej jednostki RU/s
Załóżmy na przykład, że mamy pięć partycji fizycznych, 50 000 RU/s i chcemy skalować do 150 000 RU/s. Najpierw należy ustawić: 10,000 * 5 * (2 ^ (ROUND(LOG_2(150,000/(10,000 * 5)))) = 200 000 RU/s, a następnie obniżyć do 150 000 RU/s.
Gdy skalowaliśmy do 200 000 RU/s, najniższy ręczny ru/s możemy teraz ustawić w przyszłości to 2000 RU/s. Najniższa maksymalna wartość RU/s skalowania automatycznego wynosi 20 000 RU/s (skaluje się między 2000 a 20 000 RU/s). Ponieważ docelowa wartość RU/s wynosi 150 000 RU/s, nie ma to wpływu na minimalną wartość RU/s.
Jak zoptymalizować ru/s pod kątem pozyskiwania dużych danych
Podczas planowania migracji lub pozyskiwania dużej ilości danych do usługi Azure Cosmos DB zaleca się ustawienie jednostek RU/s kontenera, aby usługa Azure Cosmos DB wstępnie aprowizuje partycje fizyczne potrzebne do przechowywania całkowitej ilości danych, które mają być pozyskiwane z góry. W przeciwnym razie podczas pozyskiwania usługa Azure Cosmos DB może wymagać podziału partycji, co zwiększa czas pozyskiwania danych.
Możemy skorzystać z faktu, że podczas tworzenia kontenera usługa Azure Cosmos DB używa formuły heurystycznej uruchamiania jednostek RU/s, aby obliczyć liczbę partycji fizycznych na początek.
Krok 1. Przegląd wybranego klucza partycji
Postępuj zgodnie z najlepszymi rozwiązaniami dotyczącymi wybierania klucza partycji, aby zapewnić równomierną dystrybucję woluminu żądań i magazynu po migracji.
Krok 2. Oblicz liczbę partycji fizycznych, które będą potrzebne
Number of physical partitions = Total data size in GB / Target data per physical partition in GB
Każda partycja fizyczna może pomieścić maksymalnie 50 GB miejsca do magazynowania (30 GB dla interfejsu API dla systemu Cassandra). Wartość, którą należy wybrać, Target data per physical partition in GB zależy od tego, jak w pełni zapakowane partycje fizyczne mają być i ile oczekujesz, że magazyn wzrośnie po migracji.
Jeśli na przykład przewidujesz, że magazyn będzie nadal rosnąć, możesz ustawić wartość na 30 GB. Przy założeniu, że wybrano dobry klucz partycji, który równomiernie dystrybuuje magazyn, każda partycja będzie 60% pełna (30 GB z 50 GB). W miarę zapisywania przyszłych danych można je przechowywać w istniejącym zestawie partycji fizycznych bez konieczności natychmiastowego dodawania kolejnych partycji fizycznych przez usługę.
Natomiast jeśli uważasz, że magazyn nie będzie znacznie rosnąć po migracji, możesz ustawić wartość wyższą, na przykład 45 GB. Oznacza to, że każda partycja będzie pełna ok. 90% (45 GB z 50 GB). Minimalizuje to liczbę partycji fizycznych, w których są rozłożone dane, co oznacza, że każda partycja fizyczna może uzyskać większy ułamek całkowitej aprowizowanej liczby jednostek RU/s.
Krok 3. Obliczanie liczby jednostek RU/s na początku dla wszystkich partycji
Starting RU/s for all partitions = Number of physical partitions * Initial throughput per physical partition.
Zacznijmy od przykładu z dowolną liczbą jednostek RU/s na partycję fizyczną.
Initial throughput per physical partition= 10 000 RU/s na partycję fizyczną w przypadku korzystania z baz danych z autoskalowaniem lub współdzieloną przepływnościąInitial throughput per physical partition= 6000 RU/s na partycję fizyczną w przypadku korzystania z przepływności ręcznej
Przykład
Załóżmy, że mamy 1 TB (1000 GB) danych, które planujemy pozyskać i chcemy użyć przepływności ręcznej. Każda partycja fizyczna w usłudze Azure Cosmos DB ma pojemność 50 GB. Załóżmy, że chcemy spakować partycje na 80% pełne (40 GB), pozostawiając nam miejsce na przyszły wzrost.
Oznacza to, że w przypadku 1 TB danych potrzebujemy 1000 GB / 40 GB = 25 partycji fizycznych. Aby upewnić się, że uzyskamy 25 partycji fizycznych, jeśli używamy przepływności ręcznej, najpierw aprowizujemy 25 * 6000 RU/s = 150 000 RU/s. Następnie, po utworzeniu kontenera, aby pomóc w szybszym pozyskiwaniu, zwiększamy wartość RU/s do 250 000 RU/s przed rozpoczęciem pozyskiwania (następuje natychmiast, ponieważ mamy już 25 partycji fizycznych). Dzięki temu każda partycja może uzyskać maksymalnie 10 000 RU/s.
Jeśli używamy przepływności autoskalowania lub bazy danych z udostępnioną przepływnością, aby uzyskać 25 partycji fizycznych, najpierw aprowizujemy 25 * 10 000 RU/s = 250 000 RU/s. Ponieważ jesteśmy już na najwyższym poziomie RU/s, które mogą być obsługiwane z 25 partycjami fizycznymi, nie zwiększylibyśmy jeszcze bardziej aprowizowania jednostek RU/s przed pozyskiwaniem.
Teoretycznie, z 250.000 RU/s i 1 TB danych, jeśli zakładamy 1-kb dokumentów i 10 jednostek RU wymaganych do zapisu, pozyskiwanie może teoretycznie zakończyć się w: 1000 GB * (1 000 000 kb/ 1 GB) * (1 dokument / 1 kb) * (10 RU / dokument) * (1 s / 250 000 RU) * (1 godzina / 3600 sekund) = 11,1 godziny.
To obliczenie jest oszacowaniem przy założeniu, że klient wykonujący pozyskiwanie może w pełni usycić przepływność i dystrybuować zapisy we wszystkich partycjach fizycznych. Najlepszym rozwiązaniem jest "mieszanie" danych po stronie klienta. Gwarantuje to, że każdy drugi klient zapisuje wiele odrębnych partycji logicznych (a tym samym fizycznych).
Po zakończeniu migracji możemy zmniejszyć wartość RU/s lub włączyć skalowanie automatyczne zgodnie z potrzebami.
Następne kroki
- Monitoruj znormalizowane użycie jednostek RU/s bazy danych lub kontenera.
- Diagnozowanie i rozwiązywanie problemów z zbyt dużymi wyjątkami liczby żądań (429).
- Włącz automatyczne skalowanie w bazie danych lub kontenerze.