Zestawy danych w usługach Azure Data Factory i Azure Synapse Analytics
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano zestawy danych, sposób ich definiowania w formacie JSON oraz sposób ich użycia w potokach usługi Azure Data Factory i Synapse.
Jeśli dopiero zaczynasz korzystać z usługi Data Factory, zobacz Wprowadzenie do usługi Azure Data Factory , aby zapoznać się z omówieniem. Aby uzyskać więcej informacji na temat usługi Azure Synapse, zobacz Co to jest usługa Azure Synapse
Omówienie
Obszar roboczy usługi Azure Data Factory lub Synapse może mieć co najmniej jeden potok. Potok to logiczne grupowanie działań, które razem wykonują zadanie. Działania w potoku określają akcje do wykonania na danych. Teraz zestaw danych jest nazwanym widokiem danych, który po prostu wskazuje lub odwołuje się do danych, które mają być używane w działaniach jako dane wejściowe i wyjściowe. Zestawy danych identyfikują dane w różnych magazynach danych, takich jak tabele, pliki, foldery i dokumenty. Na przykład zestaw danych obiektów blob platformy Azure określa kontener obiektów blob i folder w usłudze Blob Storage, z którego działanie powinno odczytywać dane.
Przed utworzeniem zestawu danych należy utworzyć połączoną usługę, aby połączyć magazyn danych z usługą. Połączone usługi są podobne do parametry połączenia, które definiują informacje o połączeniu wymagane do nawiązania połączenia z zasobami zewnętrznymi. Pomyśl o tym w ten sposób; zestaw danych reprezentuje strukturę danych w połączonych magazynach danych, a połączona usługa definiuje połączenie ze źródłem danych. Na przykład połączona usługa Azure Storage łączy konto magazynu. Zestaw danych obiektów blob platformy Azure reprezentuje kontener obiektów blob i folder w ramach tego konta usługi Azure Storage, który zawiera wejściowe obiekty blob do przetworzenia.
Oto przykładowy scenariusz. Aby skopiować dane z usługi Blob Storage do usługi SQL Database, należy utworzyć dwie połączone usługi: Azure Blob Storage i Azure SQL Database. Następnie utwórz dwa zestawy danych: rozdzielany zestaw danych tekstowych (który odnosi się do połączonej usługi Azure Blob Storage, przy założeniu, że masz pliki tekstowe jako źródło) i zestaw danych tabel Azure SQL (który odnosi się do połączonej usługi Azure SQL Database). Połączone usługi Azure Blob Storage i Azure SQL Database zawierają parametry połączenia, których usługa używa w czasie wykonywania do łączenia się z usługami Azure Storage i Azure SQL Database. Rozdzielany zestaw danych tekstowych określa kontener obiektów blob i folder obiektów blob zawierający wejściowe obiekty blob w usłudze Blob Storage wraz z ustawieniami powiązanymi z formatem. Zestaw danych azure SQL Table określa tabelę SQL w usłudze SQL Database, do której mają zostać skopiowane dane.
Na poniższym diagramie przedstawiono relacje między potokami, działaniami, zestawem danych i połączonymi usługami:

Tworzenie zestawu danych za pomocą interfejsu użytkownika
Aby utworzyć zestaw danych za pomocą programu Azure Data Factory Studio, wybierz kartę Autor (z ikoną ołówka), a następnie ikonę znaku plus, aby wybrać pozycję Zestaw danych.
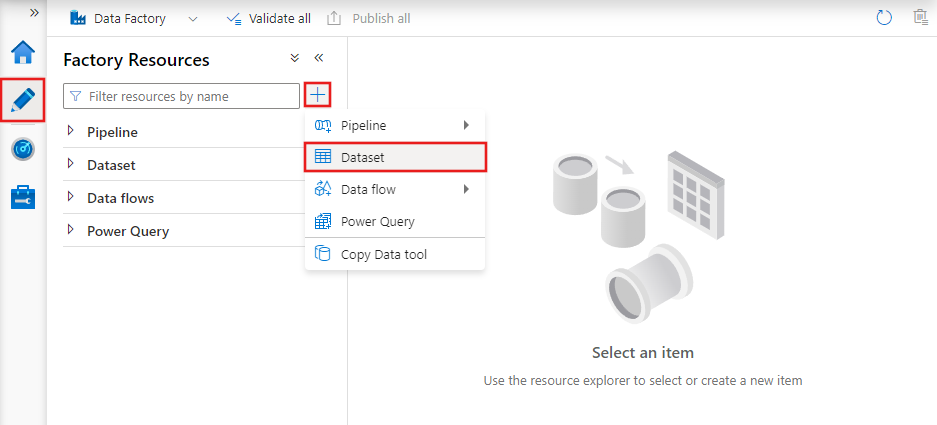
Zostanie wyświetlone nowe okno zestawu danych umożliwiające wybranie dowolnego łącznika dostępnego w usłudze Azure Data Factory w celu skonfigurowania istniejącej lub nowej połączonej usługi.

Następnie zostanie wyświetlony monit o wybranie formatu zestawu danych.

Na koniec możesz wybrać istniejącą połączoną usługę typu wybranego dla zestawu danych lub utworzyć nową, jeśli nie została jeszcze zdefiniowana.

Po utworzeniu zestawu danych można go używać w dowolnych potokach w usłudze Azure Data Factory.


Dane JSON zestawu danych
Zestaw danych jest zdefiniowany w następującym formacie JSON:
{
"name": "<name of dataset>",
"properties": {
"type": "<type of dataset: DelimitedText, AzureSqlTable etc...>",
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference",
},
"schema":[
],
"typeProperties": {
"<type specific property>": "<value>",
"<type specific property 2>": "<value 2>",
}
}
}
W poniższej tabeli opisano właściwości powyższego kodu JSON:
| Właściwości | Opis | Wymagania |
|---|---|---|
| name | Nazwa zestawu danych. Zobacz Reguły nazewnictwa. | Tak |
| type | Typ zestawu danych. Określ jeden z typów obsługiwanych przez usługę Data Factory (na przykład: DelimitedText, AzureSqlTable). Aby uzyskać szczegółowe informacje, zobacz Typy zestawów danych. |
Tak |
| schema | Schemat zestawu danych reprezentuje fizyczny typ danych i kształt. | Nie. |
| typeProperties | Właściwości typu są różne dla każdego typu. Aby uzyskać szczegółowe informacje na temat obsługiwanych typów i ich właściwości, zobacz Typ zestawu danych. | Tak |
Po zaimportowaniu schematu zestawu danych wybierz przycisk Importuj schemat i wybierz opcję importu ze źródła lub z pliku lokalnego. W większości przypadków zaimportujesz schemat bezpośrednio ze źródła. Jeśli jednak masz już lokalny plik schematu (plik Parquet lub CSV z nagłówkami), możesz skierować usługę do oparcia schematu w tym pliku.
W działaniu kopiowania zestawy danych są używane w źródle i ujściu. Schemat zdefiniowany w zestawie danych jest opcjonalny jako odwołanie. Jeśli chcesz zastosować mapowanie kolumn/pól między źródłem i ujściem, zapoznaj się z tematem Schemat i mapowanie typów.
W Przepływ danych zestawy danych są używane w przekształceniach źródła i ujścia. Zestawy danych definiują podstawowe schematy danych. Jeśli dane nie mają schematu, możesz użyć dryfu schematu dla źródła i ujścia. Metadane z zestawów danych są wyświetlane w transformacji źródłowej jako projekcja źródłowa. Projekcja w transformacji źródłowej reprezentuje dane Przepływ danych ze zdefiniowanymi nazwami i typami.
Typ zestawu danych
Usługa obsługuje wiele różnych typów zestawów danych, w zależności od używanych magazynów danych. Listę obsługiwanych magazynów danych można znaleźć w artykule Połączenie or overview (Omówienie programu Połączenie or). Wybierz magazyn danych, aby dowiedzieć się, jak utworzyć połączoną usługę i zestaw danych.
Na przykład w przypadku zestawu danych rozdzielanego tekstem typ zestawu danych jest ustawiony na rozdzielany tekst , jak pokazano w poniższym przykładzie JSON:
{
"name": "DelimitedTextInput",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorage",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": "input.log",
"folderPath": "inputdata",
"container": "adfgetstarted"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"quoteChar": "\""
},
"schema": []
}
}
Tworzenie zestawów danych
Zestawy danych można tworzyć przy użyciu jednego z następujących narzędzi lub zestawów SDK: interfejsu API platformy .NET, programu PowerShell, interfejsu API REST, szablonu usługi Azure Resource Manager i witryny Azure Portal
Bieżąca wersja a zestawy danych w wersji 1
Poniżej przedstawiono pewne różnice między zestawami danych w bieżącej wersji usługi Data Factory (i azure Synapse) oraz starszą wersją usługi Data Factory w wersji 1:
- Właściwość zewnętrzna nie jest obsługiwana w bieżącej wersji. Jest on zastępowany przez wyzwalacz.
- Właściwości zasad i dostępności nie są obsługiwane w bieżącej wersji. Czas rozpoczęcia potoku zależy od wyzwalaczy.
- Zestawy danych o określonym zakresie (zestawy danych zdefiniowane w potoku) nie są obsługiwane w bieżącej wersji.
Powiązana zawartość
Zapoznaj się z poniższym samouczkiem, aby uzyskać instrukcje krok po kroku dotyczące tworzenia potoków i zestawów danych przy użyciu jednego z tych narzędzi lub zestawów SDK.
- Quickstart: create a data factory using .NET (Szybki start: tworzenie fabryki danych przy użyciu platformy .NET)
- Szybki start: tworzenie fabryki danych przy użyciu programu PowerShell
- Szybki start: tworzenie fabryki danych przy użyciu interfejsu API REST
- Szybki start: tworzenie fabryki danych przy użyciu witryny Azure Portal