Infrastruktura Integration Runtime w usłudze Azure Data Factory
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Środowisko Integration Runtime (IR) to infrastruktura obliczeniowa używana przez potoki usługi Azure Data Factory i Azure Synapse w celu zapewnienia następujących funkcji integracji danych w różnych środowiskach sieciowych:
- Przepływ danych: wykonaj Przepływ danych w zarządzanym środowisku obliczeniowym platformy Azure.
- Przenoszenie danych: kopiowanie danych między magazynami danych w sieciach publicznych lub prywatnych (zarówno w przypadku lokalnych, jak i wirtualnych sieci prywatnych). Usługa zapewnia obsługę wbudowanych łączników, konwersji formatu, mapowania kolumn oraz wydajnego i skalowalnego transferu danych.
- Wysyłanie działań: wysyłanie i monitorowanie działań przekształcania uruchomionych w różnych usługach obliczeniowych, takich jak Azure Databricks, Azure HDInsight, ML Studio (wersja klasyczna), Azure SQL Database, SQL Server i nie tylko.
- Wykonanie pakietów SSIS: natywne wykonywanie pakietów SQL Server Integration Services (SSIS) w zarządzanym środowisku obliczeniowym platformy Azure.
W potokach usługi Data Factory i Synapse działanie definiuje akcję do wykonania. Połączona usługa definiuje docelowy magazyn danych lub usługę obliczeniową. Środowisko Integration Runtime zapewnia most między działaniami i połączonymi usługami. Odwołuje się do niej połączona usługa lub działanie i udostępnia środowisko obliczeniowe, w którym działanie jest uruchamiane bezpośrednio lub wysyłane. Dzięki temu działanie może być wykonywane w najbliższym możliwym regionie docelowym magazynem danych lub usługą obliczeniową w celu zmaksymalizowania wydajności, jednocześnie umożliwiając elastyczność spełnienia wymagań dotyczących zabezpieczeń i zgodności.
Środowiska Integration Runtime można tworzyć w interfejsie użytkownika usługi Azure Data Factory i Azure Synapse za pośrednictwem centrum zarządzania bezpośrednio, a także z dowolnych działań, zestawów danych lub przepływów danych, które się do nich odwołują.
Typy infrastruktury Integration Runtime
Usługa Data Factory oferuje trzy typy środowiska Integration Runtime (IR) i należy wybrać typ, który najlepiej spełnia wymagania dotyczące integracji danych i środowiska sieciowego. Trzy typy środowiska IR to:
- Azure
- Samodzielne hostowanie
- Azure-SSIS
Uwaga
Potoki usługi Synapse obsługują obecnie tylko środowiska Azure lub self-hosted Integration Runtime.
W poniższej tabeli opisano możliwości i obsługę sieci dla każdego typu infrastruktury Integration Runtime:
| Typ IR | Obsługa sieci publicznej | Obsługa usługi Private Link |
|---|---|---|
| Azure | Przepływ danych Przenoszenie danych Wysyłanie działania |
Przepływ danych Przenoszenie danych Wysyłanie działania |
| Samodzielne hostowanie | Przenoszenie danych Wysyłanie działania |
Przenoszenie danych Wysyłanie działania |
| Azure-SSIS | Wykonanie pakietu SSIS | Wykonanie pakietu SSIS |
Uwaga
Kontrolki ruchu wychodzącego różnią się w zależności od usługi dla środowiska Azure IR. W usłudze Synapse obszary robocze mają opcje ograniczania ruchu wychodzącego z zarządzanej sieci wirtualnej podczas korzystania z środowiska Azure IR. W usłudze Data Factory wszystkie porty są otwierane dla komunikacji wychodzącej podczas korzystania z środowiska Azure IR. Środowisko Azure-SSIS IR można zintegrować z siecią wirtualną w celu zapewnienia kontroli komunikacji wychodzącej.
Azure Integration Runtime
Środowisko Azure Integration Runtime może wykonywać następujące czynności:
- Uruchamianie Przepływ danych na platformie Azure
- Uruchamianie działań kopiowania między magazynami danych w chmurze
- Wyślij następujące działania przekształcania w sieci publicznej:
- Niestandardowe działanie platformy .NET
- Działanie funkcji platformy Azure
- Działanie Notes usługi Databricks/Jar/Python
- działanie języka U-SQL usługi Data Lake Analytics
- działanie Get Metadata
- Działanie Hive w usłudze HDInsight
- Działanie usługi HDInsight Pig
- Działanie MapReduce w usłudze HDInsight
- Działanie platformy Spark w usłudze HDInsight
- Aktywność przesyłania strumieniowego w usłudze HDInsight
- działanie Lookup
- Działanie wykonywania wsadowego maszyny Edukacja Studio (wersja klasyczna)
- Działanie aktualizacji zasobu usługi Machine Edukacja Studio (wersja klasyczna)
- działanie procedury składowanej
- Działanie weryfikacji
- Działanie w sieci Web
Środowisko sieciowe IR Azure
Środowisko Azure Integration Runtime obsługuje łączenie się z magazynami danych i usługami obliczeniowymi z publicznymi dostępnymi punktami końcowymi. Włączenie zarządzanej sieci wirtualnej, środowisko Azure Integration Runtime obsługuje łączenie się z magazynami danych przy użyciu usługi private link w środowisku sieci prywatnej. W usłudze Synapse obszary robocze mają opcje ograniczania ruchu wychodzącego z zarządzanej sieci wirtualnej IR. W usłudze Data Factory wszystkie porty są otwierane dla komunikacji wychodzącej. Środowisko Azure-SSIS IR można zintegrować z siecią wirtualną w celu zapewnienia kontroli komunikacji wychodzącej.
Zasoby obliczeniowe i skalowanie środowiska IR Azure
Infrastruktura Integration Runtime zapewnia w pełni zarządzane obliczenia bez serwera na platformie Azure. Nie musisz martwić się o aprowizację infrastruktury, instalację oprogramowania, stosowanie poprawek ani skalowanie pojemności. Dodatkowo płacisz tylko za czas rzeczywistego wykorzystania.
Produkt Azure Integration Runtime zapewnia natywne możliwości obliczeniowe przenoszenia danych między magazynami danych w chmurze w sposób bezpieczny, niezawodny i wydajny. Można ustawić liczbę jednostek integracji danych do użycia w działaniu kopiowania, a rozmiar obliczeniowy środowiska Azure IR jest odpowiednio skalowany w górę bez konieczności jawnego dostosowywania rozmiaru środowiska Azure Integration Runtime.
Wysyłanie działań to uproszczona operacja kierowania działania do docelowej usługi obliczeniowej, więc nie trzeba skalować w górę rozmiaru obliczeniowego dla tego scenariusza.
Aby uzyskać informacje na temat tworzenia i konfigurowania środowiska Azure IR, zobacz Jak utworzyć i skonfigurować środowisko Azure Integration Runtime.
Uwaga
Środowisko Azure Integration Runtime ma właściwości związane ze środowiskiem uruchomieniowym Przepływ danych, które definiuje podstawową infrastrukturę obliczeniową, która będzie używana do uruchamiania przepływów danych.
Infrastruktura Integration Runtime (Self-hosted)
Infrastruktura IR (Self-hosted) oferuje następujące możliwości:
- Uruchamianie działania kopiowania między magazynami danych w chmurze i magazynem danych w sieci prywatnej.
- Wysyłanie następujących działań przekształcania względem zasobów obliczeniowych w środowisku lokalnym lub w usłudze Azure Virtual Network:
- Działanie funkcji platformy Azure
- działanie niestandardowe (działa w usłudze Azure Batch)
- działanie języka U-SQL usługi Data Lake Analytics
- działanie Get Metadata
- Działanie hive usługi HDInsight (BYOC-Bring Your Own Cluster)
- działanie programu Pig w usłudze HDInsight (BYOC)
- działanie MapReduce w usłudze HDInsight (BYOC)
- działanie platformy Spark w usłudze HDInsight (BYOC)
- działanie przesyłania strumieniowego w usłudze HDInsight (BYOC)
- działanie Lookup
- Działanie wykonywania wsadowego maszyny Edukacja Studio (wersja klasyczna)
- Działanie aktualizacji zasobu usługi Machine Edukacja Studio (wersja klasyczna)
- Działanie Wykonywanie potoku maszyny Edukacja
- działanie procedury składowanej
- Działanie weryfikacji
- Działanie w sieci Web
Uwaga
Użyj własnego środowiska Integration Runtime do obsługi magazynów danych, które wymagają własnego sterownika, takiego jak SAP Hana, MySQL itp. Aby uzyskać więcej informacji, zobacz obsługiwane magazyny danych.
Uwaga
Środowisko Java Runtime Environment (JRE) jest zależnością własnego środowiska IR. Upewnij się, że środowisko JRE jest zainstalowane na tym samym hoście.
Własne środowisko sieciowe IR
Jeśli chcesz bezpiecznie przeprowadzić integrację danych w środowisku sieci prywatnej, które nie ma bezpośredniego widoku ze środowiska chmury publicznej, możesz zainstalować własne środowisko IR w środowisku lokalnym za zaporą lub wewnątrz wirtualnej sieci prywatnej. Własne środowisko Integration Runtime wykonuje tylko wychodzące połączenia oparte na protokole HTTP z Internetem.
Zasoby obliczeniowe i skalowanie własnego środowiska IR
Zainstaluj własne środowisko IR na maszynie lokalnej lub maszynie wirtualnej w sieci prywatnej. Obecnie własne środowisko IR jest obsługiwane tylko w systemie operacyjnym Windows.
W celu zapewnienia wysokiej dostępności i skalowalności można zmienić skalowanie środowiska IR (Self-hosted), łącząc wystąpienie logiczne z wieloma maszynami lokalnymi w trybie aktywny-aktywny. Aby uzyskać więcej informacji, zobacz artykuł dotyczący tworzenia i konfigurowania własnego środowiska IR , aby uzyskać szczegółowe informacje.
Azure-SSIS integration runtime (Środowisko Azure SSIS Integration Runtime)
Aby zmniejszyć i przenieść obecne obciążenie SSIS, można utworzyć środowisko IR Azure-SSIS w celu natywnego wykonywania pakietów SSIS.
Środowisko sieciowe IR Azure-SSIS
Środowisko Azure-SSIS IR można aprowizować w sieci publicznej lub prywatnej. Dostęp do danych lokalnych jest obsługiwany przez dołączenie środowiska Azure-SSIS IR do sieci wirtualnej połączonej z siecią lokalną.
Zasoby obliczeniowe i skalowanie środowiska IR Azure-SSIS
Środowisko Azure-SSIS IR to w pełni zarządzany klaster maszyn wirtualnych platformy Azure przeznaczony do uruchamiania pakietów usług SSIS. Możesz przenieść własną usługę Azure SQL Database lub SQL Managed Instance do katalogu projektów/pakietów usług SSIS (SSISDB). Możesz skalować moc obliczeniową, określając rozmiar węzłów, a także liczbę węzłów w klastrze. Możesz zarządzać kosztami uruchamiania środowiska Azure-SSIS Integration Runtime, zatrzymując je i uruchamiając zgodnie z wymaganiami.
Aby uzyskać więcej informacji, zobacz How to create and configure the Azure-SSIS IR (Jak utworzyć i skonfigurować środowisko Azure-SSIS IR). Po utworzeniu można wdrażać istniejące pakiety usług SSIS i zarządzać nimi bez zmian przy użyciu znanych narzędzi, takich jak SQL Server Data Tools (SSDT) i SQL Server Management Studio (SSMS), podobnie jak w przypadku korzystania z usług SSIS w środowisku lokalnym.
Aby uzyskać więcej informacji na temat środowiska uruchomieniowego Azure-SSIS, zobacz następujące artykuły:
- Samouczek: Wdrażanie pakietów usług SSIS na platformie Azure. Ten artykuł zawiera instrukcje krok po kroku dotyczące tworzenia środowiska Azure-SSIS IR i hostowania katalogu usług SSIS przy użyciu usługi Azure SQL Database.
- How to: Create an Azure-SSIS integration runtime (Jak: Tworzenie środowiska Azure SSIS Integration Runtime). W tym artykule omówiono samouczek i przedstawiono instrukcje dotyczące korzystania z usługi SQL Managed Instance i dołączania środowiska IR do sieci wirtualnej.
- Monitor an Azure-SSIS IR (Monitorowanie środowiska Azure-SSIS IR). W tym artykule pokazano, jak pobrać informacje o środowisku Azure-SSIS IR i opisano stany w zwróconych informacjach.
- Manage an Azure-SSIS IR (Zarządzanie środowiskiem Azure-SSIS IR). W tym artykule przedstawiono sposób zatrzymywania, uruchamiania lub usuwania środowiska Azure-SSIS IR. Zawiera on również instrukcje skalowania środowiska Azure-SSIS IR do wewnątrz za pomocą dodawania do niego węzłów.
- Join an Azure-SSIS IR to a virtual network (Dołączanie środowiska IR Azure SSIS do sieci wirtualnej). Ten artykuł zawiera podstawowe informacje na temat dołączania środowiska IR Azure-SSIS do sieci wirtualnej platformy Azure. Zawiera on również kroki konfigurowania sieci wirtualnej i dołączania do niego środowiska Azure-SSIS IR za pomocą witryny Azure Portal.
Lokalizacja środowiska Integration Runtime
Relacja między lokalizacją fabryki a lokalizacją środowiska IR
Podczas tworzenia wystąpienia usługi Data Factory lub obszaru roboczego usługi Synapse należy określić jego lokalizację. Metadane wystąpienia są tutaj przechowywane i wyzwalanie potoku jest inicjowane z tego miejsca. Metadane są przechowywane tylko w wybranym regionie i nie będą przechowywane w innych regionach.
Tymczasem potok może uzyskiwać dostęp do magazynów danych i usług obliczeniowych w innych regionach świadczenia usługi Azure w celu przenoszenia danych między magazynami danych lub przetwarzania danych przy użyciu usług obliczeniowych. To zachowanie jest wykonywane przez dostępne globalnie środowisko IR, co zapewnia zgodność danych, wydajność i niższe koszty wyjścia z sieci.
Lokalizacja środowiska IR definiuje lokalizację obliczeń zaplecza oraz miejsce wykonywania przenoszenia danych, wysyłania działań i wykonywania pakietów SSIS. Lokalizacja środowiska IR może być inna niż lokalizacja fabryki danych, do którego należy.
Lokalizacja środowiska IR Azure
Możesz ustawić region lokalizacji środowiska Azure IR, w tym przypadku wykonanie lub wysłanie działań nastąpi w wybranym regionie.
Ustawieniem domyślnym jest automatyczne rozpoznawanie środowiska Azure IR w sieci publicznej. Z tą opcją:
W przypadku działania kopiowania najlepiej jest automatycznie wykryć lokalizację magazynu danych ujścia, a następnie użyć środowiska IR w tym samym regionie, jeśli jest dostępny, lub najbliższego w tej samej lokalizacji geograficznej, w przeciwnym razie; Jeśli region magazynu danych ujścia nie jest wykrywalny, zamiast tego używane jest środowisko IR w regionie wystąpienia.
Na przykład usługa Data Factory lub obszar roboczy usługi Synapse została utworzona w regionie Wschodnie stany USA,
- Podczas kopiowania danych do obiektu blob platformy Azure w regionie Zachodnie stany USA, jeśli obiekt blob zostanie wykryty w regionie Zachodnie stany USA, działanie kopiowania jest wykonywane na środowisku IR w regionie Zachodnie stany USA; Jeśli wykrywanie regionów zakończy się niepowodzeniem, działanie kopiowania jest wykonywane na środowisku IR w regionie Wschodnie stany USA.
- Podczas kopiowania danych do usługi Salesforce, dla której region nie jest wykrywalny, działanie kopiowania jest wykonywane na środowisku IR w regionie Wschodnie stany USA.
Napiwek
Jeśli masz ścisłe wymagania dotyczące zgodności danych i musisz upewnić się, że dane nie opuszczają określonej lokalizacji geograficznej, możesz jawnie utworzyć środowisko Azure IR w określonym regionie i wskazać połączoną usługę do tego środowiska IR przy użyciu właściwości Połączenie Via. Jeśli na przykład chcesz skopiować dane z obiektu blob w Południowej Wielkiej Brytanii do obszaru roboczego usługi Azure Synapse w Południowej Wielkiej Brytanii i chcesz zapewnić, że dane nie opuszczają Wielkiej Brytanii, utwórz środowisko Azure IR w Południowej Wielkiej Brytanii i połącz obie połączone usługi z tym środowiskiem IR.
W przypadku wykonywania działań Lookup/GetMetadata/Delete (działania potoku), wysyłania działań przekształcania (działań zewnętrznych) i operacji tworzenia (połączenia testowego, listy folderów przeglądania i listy tabel oraz danych podglądu) środowisko IR w tym samym regionie, w którym jest używana usługa Data Factory lub Obszar roboczy usługi Synapse.
W przypadku Przepływ danych używane jest środowisko IR w regionie fabryka danych lub obszar roboczy usługi Synapse.
Napiwek
Najlepszym rozwiązaniem jest zapewnienie, że przepływy danych działają w tym samym regionie co odpowiednie magazyny danych, gdy jest to możliwe. Można to osiągnąć za pomocą automatycznego rozpoznawania dla środowiska Azure IR (jeśli lokalizacja magazynu danych jest taka sama jak lokalizacja usługi Data Factory lub obszaru roboczego usługi Synapse), albo tworząc nowe wystąpienie środowiska Azure IR w tym samym regionie co magazyny danych, a następnie wykonując przepływy danych na nim.
Jeśli włączysz zarządzaną sieć wirtualną z automatycznym rozpoznawaniem dla środowiska Azure IR, używane jest środowisko IR w regionie data factory lub obszaru roboczego usługi Synapse.
Lokalizację środowiska IR można monitorować podczas wykonywania działań w widoku monitorowania aktywności potoku w narzędziu Data Factory Studio lub Synapse Studio albo w ładunku monitorowania aktywności.
Lokalizacja własnego środowiska IR
Własne środowisko IR jest logicznie rejestrowane w obszarze roboczym usługi Data Factory lub Synapse, a zasoby obliczeniowe używane do obsługi jego funkcji są udostępniane przez Użytkownika. W związku z tym nie istnieje wyraźna właściwość lokalizacji środowiska IR (Self-hosted).
W przypadku zastosowania do wykonania przenoszenia danych, środowisko IR (Self-hosted) pobiera dane ze źródła i zapisuje je w miejscu docelowym.
Lokalizacja środowiska IR Azure-SSIS
Uwaga
Środowiska Azure-SSIS Integration Runtime nie są obecnie obsługiwane w potokach usługi Synapse.
Wybór odpowiedniej lokalizacji dla środowiska IR Azure-SSIS jest kluczowy dla osiągnięcia wysokiej wydajności obciążeń wyodrębnianie-przekształcanie-ładowanie (ETL).
- Lokalizacja środowiska Azure-SSIS IR nie musi być taka sama jak lokalizacja usługi Data Factory, ale powinna być taka sama jak lokalizacja własnego środowiska Azure SQL Database lub wystąpienia zarządzanego SQL, w którym znajduje się baza danych SSISDB. Dzięki temu środowisko Azure-SSIS Integration Runtime może łatwo uzyskać dostęp do bazy danych SSISDB bez ponoszenia nadmiernego ruchu między różnymi lokalizacjami.
- Jeśli nie masz istniejącej usługi SQL Database lub wystąpienia zarządzanego SQL, ale masz lokalne źródła danych/lokalizacje docelowe, utwórz nową usługę Azure SQL Database lub wystąpienie zarządzane SQL w tej samej lokalizacji sieci wirtualnej połączonej z siecią lokalną. W ten sposób możesz utworzyć środowisko IR Azure-SSIS przy użyciu nowej usługi Azure SQL Database lub wystąpienia zarządzanego SQL i dołączyć do tej sieci wirtualnej. Wszystko będzie znajdować się w tej samej lokalizacji, minimalizując przenoszenie danych i powiązane koszty, jednocześnie maksymalizując wydajność.
- Jeśli lokalizacja istniejącej usługi Azure SQL Database lub wystąpienia zarządzanego SQL nie jest taka sama jak lokalizacja sieci wirtualnej połączonej z siecią lokalną, najpierw utwórz środowisko Azure-SSIS IR przy użyciu istniejącej usługi Azure SQL Database lub usługi SQL Managed Instance i dołącz inną sieć wirtualną w tej samej lokalizacji. Następnie skonfiguruj sieć wirtualną do połączenia sieci wirtualnej między różnymi lokalizacjami.
Na poniższym diagramie przedstawiono ustawienia lokalizacji dla usługi Data Factory i jej środowisk Integration Runtime:
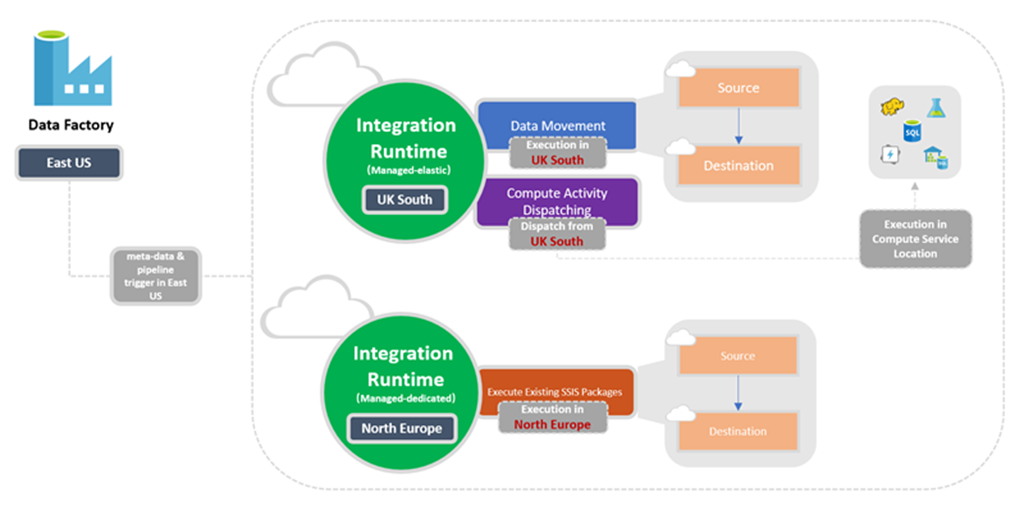
Wybór środowiska IR do użycia
Jeśli działanie kojarzy się z więcej niż jednym typem środowiska Integration Runtime, zostanie rozpoznane jako jedno z nich. Własne środowisko Integration Runtime ma pierwszeństwo przed środowiskiem Azure Integration Runtime w wystąpieniach usługi Azure Data Factory lub obszaru roboczego usługi Synapse przy użyciu zarządzanej sieci wirtualnej. Ten ostatni ma pierwszeństwo przed globalnym środowiskiem Azure Integration Runtime.
Na przykład jedno działanie kopiowania służy do kopiowania danych ze źródła do ujścia. Globalne środowisko Azure Integration Runtime jest skojarzone z połączoną usługą ze źródłem i środowiskiem Azure Integration Runtime w zarządzanej sieci wirtualnej usługi Azure Data Factory kojarzy się z połączoną usługą do ujścia, a następnie wynika z tego, że zarówno połączone usługi źródłowe, jak i ujścia korzystają ze środowiska Azure Integration Runtime w zarządzanej sieci wirtualnej usługi Azure Data Factory. Jeśli jednak własne środowisko Integration Runtime skojarzy połączoną usługę dla źródła, zarówno źródłowa, jak i połączona usługa ujścia używają własnego środowiska Integration Runtime.
Działanie kopiowania
Działanie Kopiuj wymaga zarówno połączonych usług źródłowych, jak i ujściowych w celu zdefiniowania kierunku przepływu danych. Poniższa logika jest stosowana do określenia, które wystąpienie środowiska IR jest używane do wykonania kopii:
- Kopiowanie między dwoma źródłami danych w chmurze: jeśli zarówno źródłowe, jak i połączone usługi ujścia korzystają z środowiska Azure IR, regionalne środowisko Azure IR jest używane, jeśli zostało określone, lub lokalizacja środowiska Azure IR jest automatycznie określana, czy opcja automatycznego rozpoznawania środowiska IR (ustawienie domyślne) została wybrana zgodnie z opisem w sekcji Lokalizacja środowiska Integration Runtime.
- Kopiowanie między źródłem danych w chmurze a źródłem danych w sieci prywatnej: jeśli źródło lub ujście połączone usługi wskazuje własne środowisko IR, działanie kopiowania jest wykonywane na własnym środowisku IR.
- Kopiowanie między dwoma źródłami danych w sieci prywatnej: zarówno połączona usługa źródłowa, jak i ujściowa muszą wskazywać to samo wystąpienie środowiska Integration Runtime, a środowisko IR jest używane do wykonywania działania kopiowania.
Działanie wyszukiwania i uzyskiwania metadanych
Działanie wyszukiwania i uzyskiwania metadanych jest wykonywane w środowisku Integration Runtime skojarzonym z połączoną usługą magazynu danych.
Działanie transformacji zewnętrznej
Każde działanie transformacji zewnętrznej korzystające z zewnętrznego aparatu obliczeniowego ma docelową połączoną usługę obliczeniową, która wskazuje na środowisko Integration Runtime. To wystąpienie środowiska IR określa lokalizację, z której jest wysyłane zewnętrzne działanie przekształcania zakodowane ręcznie.
działanie Przepływ danych
Przepływ danych działania są wykonywane w skojarzonym środowisku Azure Integration Runtime. Obliczenia platformy Spark używane przez Przepływ danych są określane przez właściwości przepływu danych w środowisku Azure IR i są w pełni zarządzane przez usługę.
Środowisko Integration Runtime w ciągłej integracji/ciągłego wdrażania
Środowiska Integration Runtime nie zmieniają się często i są podobne we wszystkich etapach ciągłej integracji/ciągłego wdrażania. Usługa Data Factory wymaga, aby środowisko Integration Runtime miało taką samą nazwę i typ środowiska Integration Runtime na wszystkich etapach ciągłej integracji/ciągłego wdrażania. Jeśli chcesz udostępnić środowiska Integration Runtime na wszystkich etapach, rozważ użycie dedykowanej fabryki tylko do przechowywania udostępnionych środowisk Integration Runtime. Następnie możesz użyć tej udostępnionej fabryki we wszystkich środowiskach jako połączonego typu środowiska Integration Runtime.
Powiązana zawartość
Odwiedź następujące artykuły:
- Tworzenie środowiska Azure Integration Runtime
- Create self-hosted integration runtime (Tworzenie środowiska Integration Runtime (Self-hosted)
- Create an Azure-SSIS integration runtime (Tworzenie środowiska Azure-SSIS Integration Runtime) W tym artykule omówiono samouczek i przedstawiono instrukcje dotyczące korzystania z usługi SQL Managed Instance i dołączania środowiska IR do sieci wirtualnej.