Przyrostowe ładowanie danych z usługi Azure SQL Database do usługi Azure Blob Storage przy użyciu witryny Azure Portal
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym samouczku utworzysz usługę Azure Data Factory z potokiem, który ładuje dane różnicowe z tabeli w usłudze Azure SQL Database do usługi Azure Blob Storage.
Ten samouczek obejmuje następujące procedury:
- Przygotowywanie magazynu danych do przechowywania wartości limitu.
- Tworzenie fabryki danych.
- Tworzenie połączonych usług.
- Tworzenie zestawów danych źródła, ujścia i limitu.
- Tworzenie potoku.
- Uruchom potok.
- Monitorowanie uruchomienia potoku.
- Przegląd wyników
- Dodawanie większej ilości danych do źródła.
- Ponowne uruchamianie potoku.
- Monitorowanie drugiego uruchomienia potoku
- Przegląd wyników drugiego uruchomienia
Omówienie
Diagram ogólny rozwiązania wygląda następująco:

Poniżej przedstawiono ważne czynności związane z tworzeniem tego rozwiązania:
Wybierz kolumnę limitu. Wybierz jedną kolumnę w magazynie danych źródłowych, która może służyć do tworzenia wycinków nowych lub zaktualizowanych rekordów dla każdego przebiegu. Zazwyczaj dane w tej wybranej kolumnie (na przykład last_modify_time lub ID) rosną wraz z tworzeniem i aktualizacją wierszy. Maksymalna wartość w tej kolumnie jest używana jako limit.
Przygotuj magazyn danych do przechowywania wartości limitu. W tym samouczku wartość limitu jest przechowywana w bazie danych SQL.
Utwórz potok z następującym przepływem pracy:
Potok w tym rozwiązaniu obejmuje następujące działania:
- Utwórz dwa działania Lookup. Użyj pierwszego działania Lookup do pobrania ostatniej wartości limitu. Użyj drugiego działania Lookup do pobrania nowej wartości limitu. Te wartości limitu są przekazywane do działania Copy.
- Utwórz działanie Copy, które kopiuje wiersze z magazynu danych źródłowych o wartości kolumny limitu większej niż poprzednia wartość limitu i mniejszej niż nowa wartość limitu. Następnie kopiuje dane różnicowe ze źródłowego magazynu danych do usługi Blob Storage jako nowy plik.
- Utwórz działanie StoredProcedure, które aktualizuje wartość limitu dla potoku przy następnym uruchomieniu.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
- Usługa Azure SQL Database. Baza danych jest używana jako źródłowy magazyn danych. Jeśli nie masz bazy danych w usłudze Azure SQL Database, zobacz Tworzenie bazy danych w usłudze Azure SQL Database , aby uzyskać instrukcje tworzenia bazy danych.
- Azure Storage. Magazyn obiektów blob jest używany jako magazyn danych ujścia. Jeśli nie masz konta magazynu, utwórz je, wykonując czynności przedstawione w artykule Tworzenie konta magazynu. Utwórz kontener o nazwie adftutorial.
Tworzenie tabeli danych źródłowych w bazie danych SQL
Otwórz program SQL Server Management Studio. W Eksploratorze serwera kliknij prawym przyciskiem myszy bazę danych, a następnie wybierz pozycję Nowe zapytanie.
Uruchom następujące polecenie SQL względem bazy danych SQL, aby utworzyć tabelę o nazwie
data_source_tablejako źródłowy magazyn danych:create table data_source_table ( PersonID int, Name varchar(255), LastModifytime datetime ); INSERT INTO data_source_table (PersonID, Name, LastModifytime) VALUES (1, 'aaaa','9/1/2017 12:56:00 AM'), (2, 'bbbb','9/2/2017 5:23:00 AM'), (3, 'cccc','9/3/2017 2:36:00 AM'), (4, 'dddd','9/4/2017 3:21:00 AM'), (5, 'eeee','9/5/2017 8:06:00 AM');W tym samouczku użyjesz kolumny LastModifytime jako kolumny limitu. Dane w źródłowym magazynie danych zostały przedstawione w poniższej tabeli:
PersonID | Name | LastModifytime -------- | ---- | -------------- 1 | aaaa | 2017-09-01 00:56:00.000 2 | bbbb | 2017-09-02 05:23:00.000 3 | cccc | 2017-09-03 02:36:00.000 4 | dddd | 2017-09-04 03:21:00.000 5 | eeee | 2017-09-05 08:06:00.000
Tworzenie innej tabeli w bazie danych SQL do przechowywania wartości górnego limitu
Uruchom następujące polecenie SQL względem bazy danych SQL, aby utworzyć tabelę o nazwie
watermarktablew celu przechowywania wartości limitu:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Ustaw domyślną wartość górnego limitu z nazwą tabeli źródłowego magazynu danych. W tym samouczku nazwa tabeli to data_source_table.
INSERT INTO watermarktable VALUES ('data_source_table','1/1/2010 12:00:00 AM')Sprawdź dane w tabeli
watermarktable.Select * from watermarktableDane wyjściowe:
TableName | WatermarkValue ---------- | -------------- data_source_table | 2010-01-01 00:00:00.000
Tworzenie procedur składowanych w bazie danych SQL
Uruchom następujące polecenie, aby utworzyć procedurę składowaną w bazie danych SQL:
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Tworzenie fabryki danych
Uruchom przeglądarkę internetową Microsoft Edge lub Google Chrome. Obecnie interfejs użytkownika usługi Data Factory jest obsługiwany tylko przez przeglądarki internetowe Microsoft Edge i Google Chrome.
W menu po lewej stronie wybierz pozycję Utwórz zasób>Integration>Data Factory:
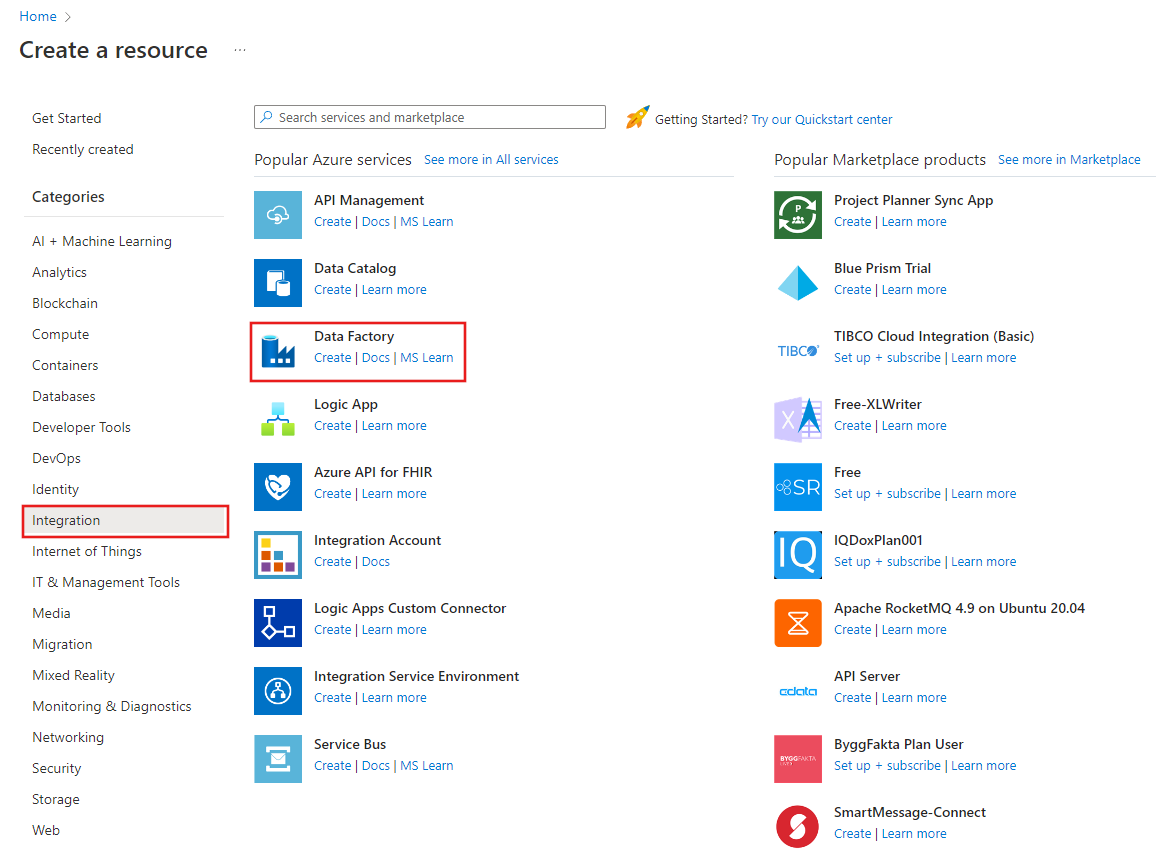
Na stronie Nowa fabryka danych jako nazwę wprowadź wartość ADFIncCopyTutorialDF.
Nazwa usługi Azure Data Factory musi być globalnie unikatowa. Jeśli pojawi się czerwony wykrzyknik z poniższym błędem, zmień nazwę fabryki danych (np. twojanazwaADFIncCopyTutorialDF) i spróbuj utworzyć ją ponownie. Artykuł Data Factory — Naming Rules (Usługa Data Factory — reguły nazewnictwa) zawiera reguły nazewnictwa artefaktów usługi Data Factory.
Nazwa fabryki danych "ADFIncCopyTutorialDF" jest niedostępna
Wybierz subskrypcję Azure, w której chcesz utworzyć fabrykę danych.
Dla opcji Grupa zasobów wykonaj jedną z następujących czynności:
Wybierz pozycję Użyj istniejącej, a następnie wybierz istniejącą grupę zasobów z listy rozwijanej.
Wybierz pozycję Utwórz nową, a następnie wprowadź nazwę grupy zasobów.
Informacje na temat grup zasobów znajdują się w artykule Using resource groups to manage your Azure resources (Używanie grup zasobów do zarządzania zasobami platformy Azure).
Wybierz opcję V2 w obszarze Wersja.
Na liście lokalizacja wybierz lokalizację fabryki danych. Na liście rozwijanej są wyświetlane tylko obsługiwane lokalizacje. Magazyny danych (Azure Storage, Azure SQL Database, Azure SQL Managed Instance itd.) i obliczenia (HDInsight itp.) używane przez fabrykę danych mogą znajdować się w innych regionach.
Kliknij pozycję Utwórz.
Po zakończeniu tworzenia zostanie wyświetlona strona Fabryka danych, jak pokazano na poniższej ilustracji.
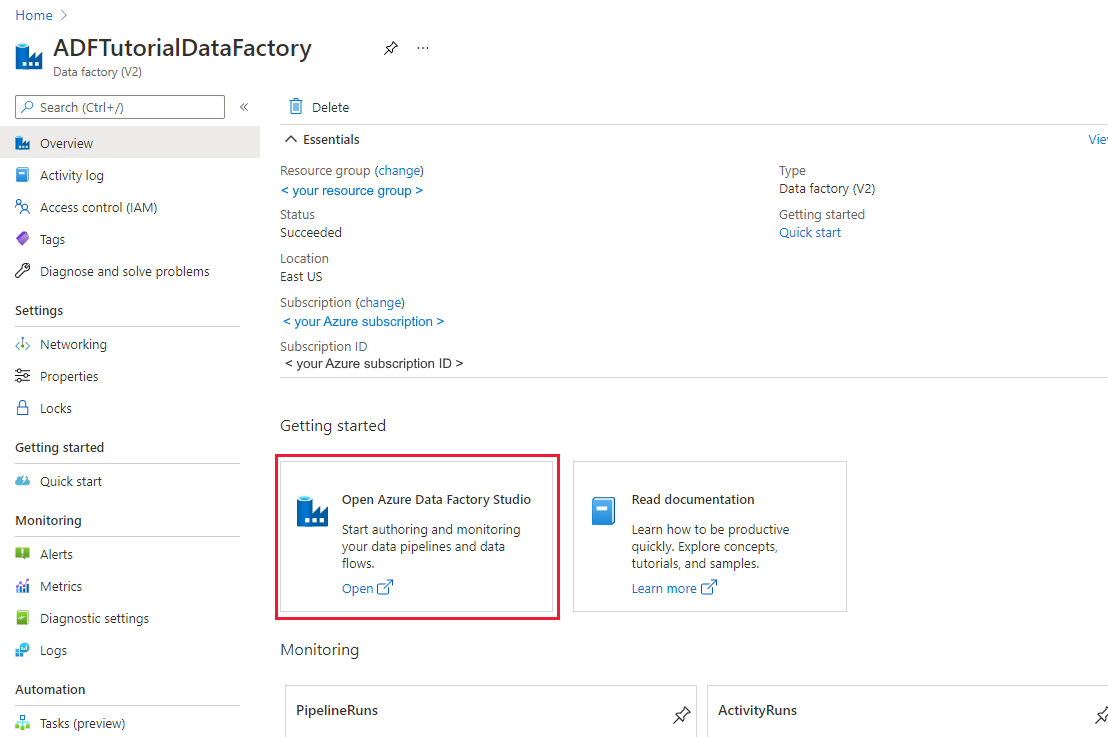
Wybierz pozycję Otwórz na kafelku Otwórz usługę Azure Data Factory Studio , aby uruchomić interfejs użytkownika usługi Azure Data Factory na osobnej karcie.
Tworzenie potoku
W tym samouczku utworzysz potok z dwoma działaniami Lookup, jednym działaniem Copy i jednym działaniem StoredProcedure, połączonymi w jednym potoku.
Na stronie głównej interfejsu użytkownika usługi Data Factory kliknij kafelek Orkiestracja .
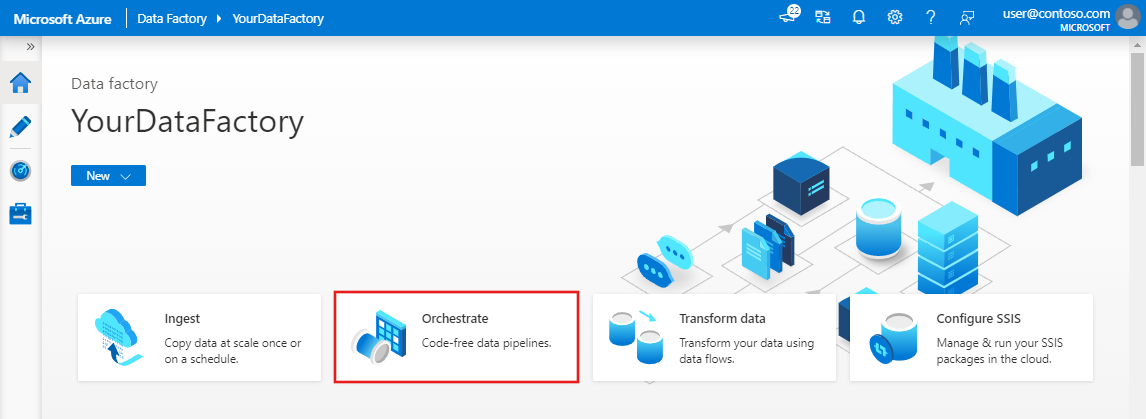
W panelu Ogólne w obszarze Właściwości określ wartość IncrementalCopyPipeline w polu Nazwa. Następnie zwiń panel, klikając ikonę Właściwości w prawym górnym rogu.
Dodajmy pierwsze działanie wyszukiwania w celu pobrania starej wartości limitu. W przyborniku Działania rozwiń pozycję Ogólne, a następnie przeciągnij działanie Lookup (Wyszukiwanie) i upuść je na powierzchni projektanta potoku. Zmień nazwę działania na LookupOldWaterMarkActivity.
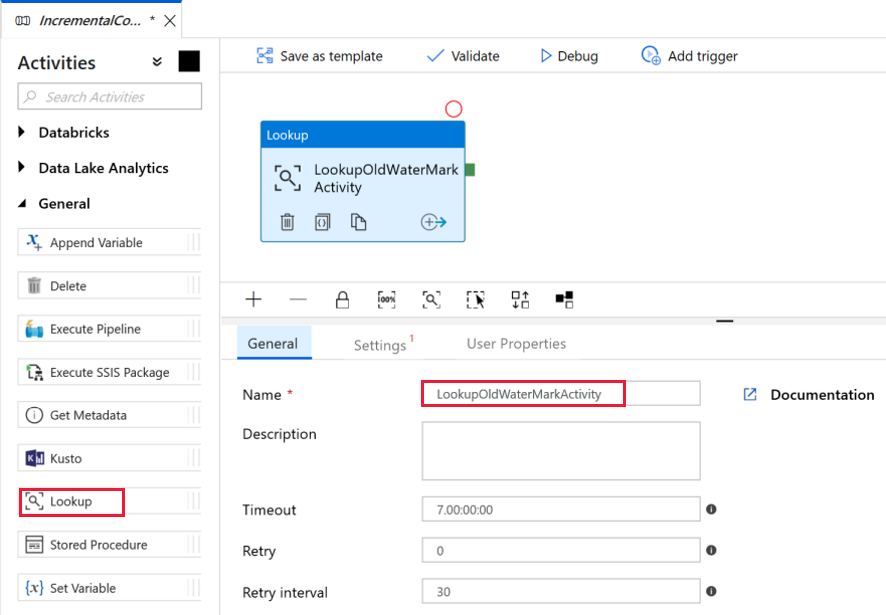
Przejdź do karty Ustawienia, a następnie kliknij pozycję +Nowy dla pozycji Źródłowy zestaw danych. W tym kroku utworzysz zestaw danych reprezentujący dane w tabeli watermarktable. Ta tabela zawiera stary limit, który był używany w poprzedniej operacji kopiowania.
W oknie Nowy zestaw danych wybierz pozycję Azure SQL Database, a następnie kliknij przycisk Kontynuuj. Zostanie otwarte nowe okno dla zestawu danych.
W oknie Ustawianie właściwości zestawu danych wprowadź wartość WatermarkDataset w polu Nazwa.
W obszarze Połączona usługa wybierz pozycję Nowa, a następnie wykonaj następujące czynności:
Wprowadź wartość AzureSqlDatabaseLinkedService w polu Nazwa.
Wybierz serwer w polu Nazwa serwera.
Wybierz swoją nazwę bazy danych z listy rozwijanej.
Wprowadź nazwę użytkownika i hasło.
Aby przetestować połączenie z bazą danych SQL, kliknij pozycję Testuj połączenie.
Kliknij przycisk Zakończ.
Upewnij się, że dla połączonej usługi wybrano pozycję AzureSqlDatabaseLinkedService.
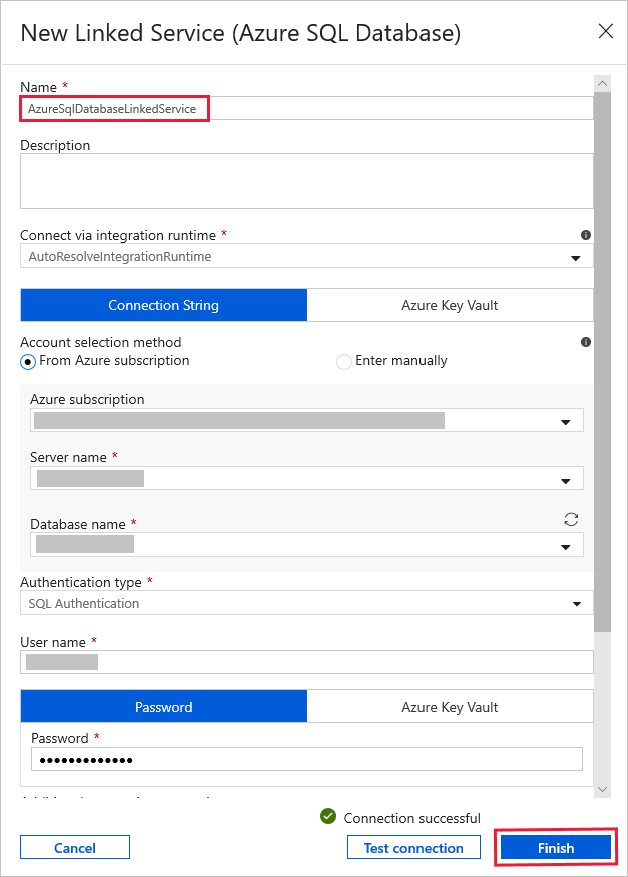
Wybierz Zakończ.
Na karcie Połączenie ion wybierz pozycję [dbo].[ waterstadtable] dla tabeli. Jeśli chcesz wyświetlić podgląd danych w tabeli, kliknij przycisk Podgląd danych.
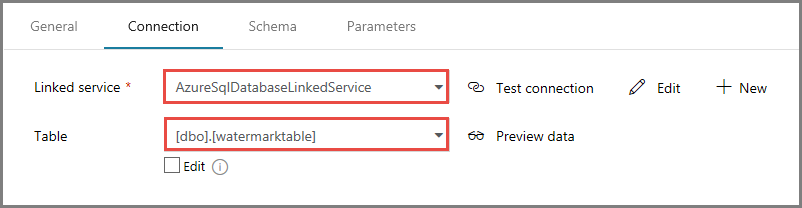
Przejdź do edytora potoku, klikając kartę potoku u góry lub klikając nazwę potoku w widoku drzewa po lewej stronie. W oknie dialogowym właściwości działania Lookup (Wyszukiwanie) upewnij się, że dla pola Zestaw danych źródłowych wybrano wartość WatermarkDataset.
W przyborniku Działania rozwiń pozycję Ogólne, a następnie przeciągnij i upuść kolejne działanie Lookup (Wyszukiwanie) na powierzchni projektanta potoku. Na karcie Ogólne okna właściwości ustaw nazwę LookupNewWaterMarkActivity. To działanie wyszukiwania pobiera nową wartość limitu z tabeli zawierającej dane źródłowe do skopiowania do miejsca docelowego.
W oknie właściwości dla drugiego działania Lookup (Wyszukiwania) przejdź do karty Ustawienia, a następnie kliknij pozycję Nowy. Utworzysz zestaw danych wskazujący tabelę źródłową zawierającą nową wartość limitu (wartość maksymalna elementu LastModifyTime).
W oknie Nowy zestaw danych wybierz pozycję Azure SQL Database, a następnie kliknij przycisk Kontynuuj.
W oknie Ustawianie właściwości wprowadź wartość SourceDataset w polu Nazwa. Wybierz wartość AzureSqlDatabaseLinkedService w polu Połączona usługa.
Wybierz element [dbo].[data_source_table] dla pozycji Tabela. Zapytanie zostanie wprowadzone w tym zestawie danych później w tym samouczku. Zapytanie ma pierwszeństwo przed tabelą określaną w tym kroku.
Wybierz Zakończ.
Przejdź do edytora potoku, klikając kartę potoku u góry lub klikając nazwę potoku w widoku drzewa po lewej stronie. W oknie dialogowym właściwości działania Lookup (Wyszukiwanie) upewnij się, że dla pola Zestaw danych źródłowych wybrano wartość SourceDataset.
Wybierz wartość Zapytanie w polu Użyj zapytania, a następnie wprowadź następujące zapytanie: wybierasz tylko maksymalną wartość LastModifytime z tabeli data_source_table. Upewnij się, że zaznaczono również tylko pierwszy wiersz.
select MAX(LastModifytime) as NewWatermarkvalue from data_source_table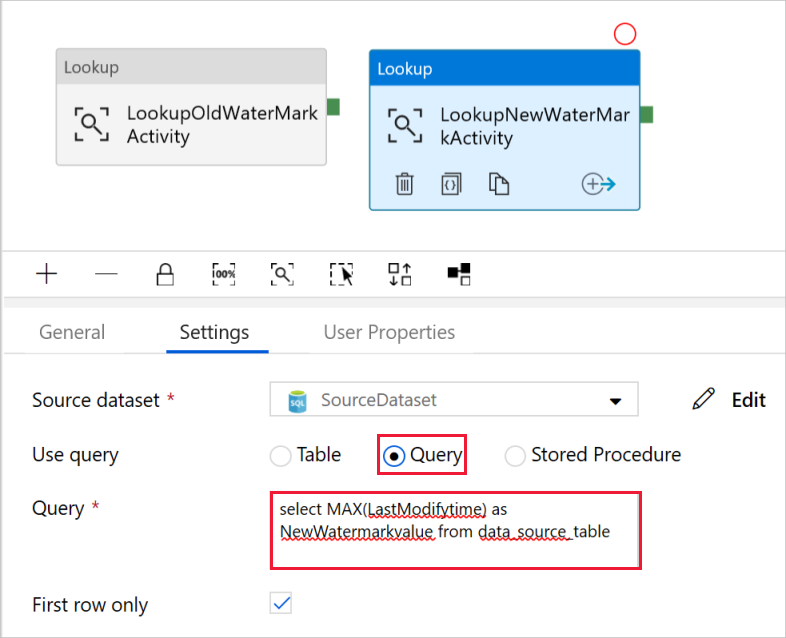
W przyborniku Działania rozwiń pozycję Przenieś i przekształć, a następnie przeciągnij działanie Kopiuj z przybornika Działania i ustaw nazwę na IncrementalCopyActivity.
Połącz oba działania wyszukiwania z działaniem kopiowania, przeciągając do działania kopiowania zielony przycisk dołączony do działania wyszukiwania. Po zmianie koloru obramowania działania kopiowania na niebieski zwolnij przycisk myszy.
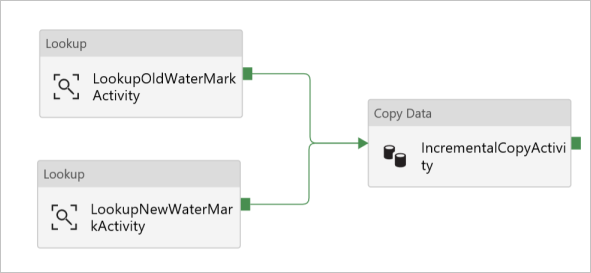
Wybierz działanie kopiowania i upewnij się, że w oknie Właściwości widać właściwości działania.
Przejdź do karty Źródło w oknie Właściwości i wykonaj następujące czynności:
Wybierz pozycję SourceDataset dla pola Zestaw danych będący źródłem.
Wybierz pozycję Zapytanie dla pola Użyj zapytania.
W polu Zapytanie wprowadź następujące zapytanie SQL.
select * from data_source_table where LastModifytime > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and LastModifytime <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'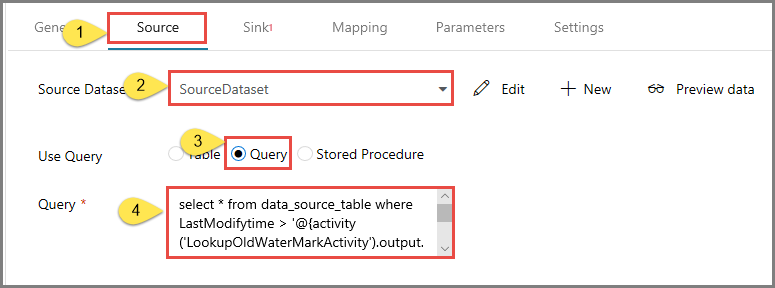
Przejdź do karty Ujście i kliknij pozycję +Nowy dla pola Zestaw danych ujścia.
W tym samouczku magazyn danych ujścia jest typu Azure Blob Storage. W związku z tym wybierz pozycję Azure Blob Storage i kliknij przycisk Kontynuuj w oknie Nowy zestaw danych .
W oknie Wybieranie formatu wybierz typ formatu danych, a następnie kliknij przycisk Kontynuuj.
W oknie Ustawianie właściwości wprowadź wartość SinkDataset w polu Nazwa. W obszarze Połączona usługa wybierz pozycję + Nowa. W tym kroku tworzysz połączenie (usługę połączoną) z magazynem Azure Blob Storage.
W oknie Nowa połączona usługa (Azure Blob Storage) wykonaj następujące czynności:
- Wprowadź wartość AzureStorageLinkedService w polu Nazwa.
- W polu Nazwa konta magazynu wybierz konto usługi Azure Storage.
- Przetestuj Połączenie ion, a następnie kliknij przycisk Zakończ.
W oknie Ustawianie właściwości upewnij się, że dla połączonej usługi wybrano pozycję AzureStorageLinkedService. Następnie wybierz pozycję Zakończ.
Przejdź do karty Połączenie ion zestawu SinkDataset i wykonaj następujące czynności:
- W polu Ścieżka pliku wprowadź wartość adftutorial/incrementalcopy. Kontenerem obiektów blob jest adftutorial, a nazwą folderu — incrementalcopy. W tym fragmencie kodu założono, że w masz kontener obiektów blob o nazwie adftutorial w magazynie obiektów blob. Utwórz ten kontener, jeśli nie istnieje, lub zastąp go nazwą istniejącego kontenera. Jeśli folder wyjściowy incrementalcopy nie istnieje, usługa Azure Data Factory automatycznie go utworzy. Można również za pomocą przycisku Przeglądaj pola Ścieżka pliku przejść do folderu w kontenerze obiektów blob.
- W polu Plik w polu Ścieżka pliku wybierz pozycję Dodaj zawartość dynamiczną [Alt+P], a następnie wprowadź
@CONCAT('Incremental-', pipeline().RunId, '.txt')ciąg w otwartym oknie. Następnie wybierz pozycję Zakończ. Nazwa pliku jest generowana dynamicznie przy użyciu wyrażenia. Każde uruchomienie potoku ma unikatowy identyfikator. Działanie kopiowania używa identyfikatora uruchomienia do wygenerowania nazwy pliku.
Przejdź do edytora potoku, klikając kartę potoku u góry lub klikając nazwę potoku w widoku drzewa po lewej stronie.
W przyborniku Działania rozwiń pozycję Ogólne, a następnie przeciągnij i upuść działanie Stored Procedure (Procedura składowana) z przybornika Działania na powierzchnię projektanta potoku. Połącz zielone (Powodzenie) wyjście działania kopiowania z działaniem procedury składowanej.
Wybierz działanie procedury składowanej w Projektancie potoku i zmień jego nazwę na StoredProceduretoWriteWatermarkActivity.
Przejdź do karty Konto SQL i wybierz pozycję AzureSqlDatabaseLinkedService dla pozycji Połączona usługa.
Przejdź do karty Procedura składowana i wykonaj następujące czynności:
W polu Nazwa procedury składowanej wybierz wartość usp_write_watermark.
Aby określić wartości parametrów procedury składowanej, kliknij pozycję Importuj parametr, a następnie wprowadź następujące wartości parametrów:
Nazwisko Typ Wartość LastModifiedtime DateTime @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue} TableName String @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName} 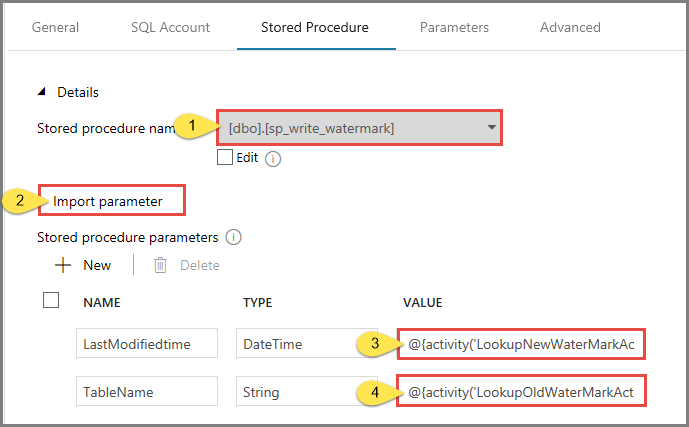
Aby zweryfikować ustawienia potoku, kliknij pozycję Weryfikuj na pasku narzędzi. Potwierdź, że weryfikacja nie zwróciła błędów. Aby zamknąć okno Raport weryfikacji potoku, kliknij przycisk >>.
Opublikuj jednostki (usługi połączone, zestawy danych i potoki) w usłudze Azure Data Factory, wybierając przycisk Opublikuj wszystko. Poczekaj, aż zostanie wyświetlony komunikat o pomyślnym opublikowaniu.
Wyzwalanie uruchomienia potoku
Kliknij pozycję Dodaj wyzwalacz na pasku narzędzi, a następnie kliknij pozycję Wyzwól teraz.
W oknie Uruchomienie potoku wybierz pozycję Zakończ.
Monitorowanie działania potoku
Przejdź do karty Monitorowanie po lewej stronie. Zostanie wyświetlony stan uruchomienia potoku wyzwalanego przez wyzwalacz ręczny. Możesz użyć linków w kolumnie NAZWA POTOKu, aby wyświetlić szczegóły przebiegu i ponownie uruchomić potok.
Aby wyświetlić uruchomienia działań skojarzone z uruchomieniem potoku, wybierz link w kolumnie NAZWA POTOKU. Aby uzyskać szczegółowe informacje na temat przebiegów działań, wybierz link Szczegóły (ikona okularów) w kolumnie NAZWA DZIAŁANIA. Wybierz pozycję Wszystkie uruchomienia potoku u góry, aby wrócić do widoku Uruchomienia potoku. Aby odświeżyć widok, wybierz pozycję Odśwież.
Sprawdzanie wyników
Połącz się z kontem usługi Azure Storage za pomocą narzędzi, takich jak Eksplorator usługi Azure Storage. Sprawdź, czy plik wyjściowy został utworzony w folderze incrementalcopy w kontenerze adftutorial.
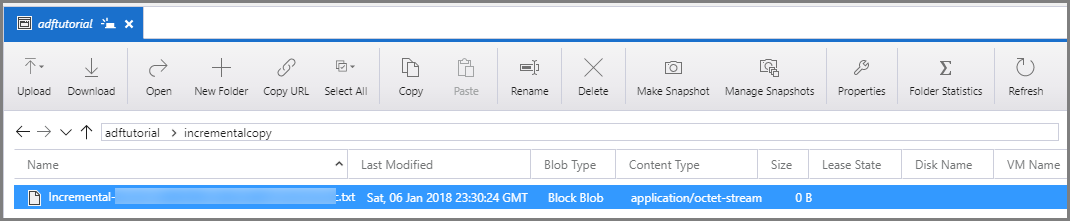
Otwórz plik wyjściowy i zwróć uwagę na to, że do pliku obiektu blob skopiowano wszystkie dane z tabeli data_source_table.
1,aaaa,2017-09-01 00:56:00.0000000 2,bbbb,2017-09-02 05:23:00.0000000 3,cccc,2017-09-03 02:36:00.0000000 4,dddd,2017-09-04 03:21:00.0000000 5,eeee,2017-09-05 08:06:00.0000000Sprawdź najnowszą wartość w tabeli
watermarktable. Zobaczysz, że wartość limitu została zaktualizowana.Select * from watermarktableOto dane wyjściowe:
| TableName | WatermarkValue | | --------- | -------------- | | data_source_table | 2017-09-05 8:06:00.000 |
Dodawanie większej ilości danych do źródła
Wstaw nowe dane do bazy danych (magazyn źródeł danych).
INSERT INTO data_source_table
VALUES (6, 'newdata','9/6/2017 2:23:00 AM')
INSERT INTO data_source_table
VALUES (7, 'newdata','9/7/2017 9:01:00 AM')
Zaktualizowane dane w bazie danych to:
PersonID | Name | LastModifytime
-------- | ---- | --------------
1 | aaaa | 2017-09-01 00:56:00.000
2 | bbbb | 2017-09-02 05:23:00.000
3 | cccc | 2017-09-03 02:36:00.000
4 | dddd | 2017-09-04 03:21:00.000
5 | eeee | 2017-09-05 08:06:00.000
6 | newdata | 2017-09-06 02:23:00.000
7 | newdata | 2017-09-07 09:01:00.000
Wyzwalanie kolejnego uruchomienia potoku
Przejdź do karty Edycja . Kliknij potok w widoku drzewa, jeśli nie został otwarty w projektancie.
Kliknij pozycję Dodaj wyzwalacz na pasku narzędzi, a następnie kliknij pozycję Wyzwól teraz.
Monitorowanie drugiego uruchomienia potoku
Przejdź do karty Monitorowanie po lewej stronie. Zostanie wyświetlony stan uruchomienia potoku wyzwalanego przez wyzwalacz ręczny. Możesz użyć linków w kolumnie NAZWA POTOKu, aby wyświetlić szczegóły działania i ponownie uruchomić potok.
Aby wyświetlić uruchomienia działań skojarzone z uruchomieniem potoku, wybierz link w kolumnie NAZWA POTOKU. Aby uzyskać szczegółowe informacje na temat przebiegów działań, wybierz link Szczegóły (ikona okularów) w kolumnie NAZWA DZIAŁANIA. Wybierz pozycję Wszystkie uruchomienia potoku u góry, aby wrócić do widoku Uruchomienia potoku. Aby odświeżyć widok, wybierz pozycję Odśwież.
Weryfikowanie drugiego zestawu danych wyjściowych
W magazynie obiektów blob zobaczysz, że utworzono kolejny plik. W tym samouczku nazwa nowego pliku to
Incremental-<GUID>.txt. Otwórz ten plik — zobaczysz w nim dwa wiersze rekordów.6,newdata,2017-09-06 02:23:00.0000000 7,newdata,2017-09-07 09:01:00.0000000Sprawdź najnowszą wartość w tabeli
watermarktable. Zobaczysz, że wartość limitu została ponownie zaktualizowana.Select * from watermarktablePrzykładowe dane wyjściowe:
| TableName | WatermarkValue | | --------- | -------------- | | data_source_table | 2017-09-07 09:01:00.000 |
Powiązana zawartość
W ramach tego samouczka wykonano następujące procedury:
- Przygotowywanie magazynu danych do przechowywania wartości limitu.
- Tworzenie fabryki danych.
- Tworzenie połączonych usług.
- Tworzenie zestawów danych źródła, ujścia i limitu.
- Tworzenie potoku.
- Uruchom potok.
- Monitorowanie uruchomienia potoku.
- Przegląd wyników
- Dodawanie większej ilości danych do źródła.
- Ponowne uruchamianie potoku.
- Monitorowanie drugiego uruchomienia potoku
- Przegląd wyników drugiego uruchomienia
W tym samouczku potok skopiował dane z pojedynczej tabeli w usłudze SQL Database do usługi Blob Storage. Przejdź do poniższego samouczka, aby dowiedzieć się, jak kopiować dane z wielu tabel w bazie danych programu SQL Server do usługi SQL Database.