Co to jest uzdatnianie danych?
DOTYCZY: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Organizacje muszą mieć możliwość eksplorowania kluczowych danych biznesowych na potrzeby przygotowywania i uzdatniania danych w celu zapewnienia dokładnej analizy złożonych danych, które nadal rosną każdego dnia. Przygotowanie danych jest wymagane, aby organizacje mogły korzystać z danych w różnych procesach biznesowych i skrócić czas na wartość.
Usługa Data Factory umożliwia iteracyjne przygotowywanie danych bez użycia kodu w skali chmury przy użyciu dodatku Power Query. Usługa Data Factory integruje się z usługą Power Query Online i udostępnia funkcje dodatku Power Query M jako działanie potoku.
Usługa Data Factory tłumaczy język M wygenerowany przez edytor mashup usługi Power Query Online na kod spark na potrzeby wykonywania skalowania w chmurze, tłumacząc język M na Przepływ danych usługi Azure Data Factory. Uzdatnianie danych za pomocą dodatku Power Query i przepływów danych jest szczególnie przydatne dla inżynierów danych lub "integratorów danych obywateli".
Przypadki użycia
Szybka interaktywna eksploracja i przygotowywanie danych
Wielu inżynierów danych i integratorów danych obywateli może interaktywnie eksplorować i przygotowywać zestawy danych w skali chmury. Wraz ze wzrostem ilości, różnorodności i szybkości danych w magazynach data lake użytkownicy potrzebują efektywnego sposobu eksplorowania i przygotowywania zestawów danych. Na przykład może być konieczne utworzenie zestawu danych zawierającego wszystkie informacje demograficzne klientów dla nowych klientów od 2017 roku. Nie mapujesz na znany element docelowy. Eksplorujesz, rozmieszczasz i preppingujesz zestawy danych, aby spełnić wymagania przed ich opublikowaniem w jeziorze. Wrangling jest często używany w przypadku mniej formalnych scenariuszy analitycznych. Wstępnie utworzone zestawy danych mogą służyć do wykonywania przekształceń i operacji uczenia maszynowego podrzędnych.
Elastyczne przygotowywanie danych bez kodu
Integratorzy danych obywateli poświęcają ponad 60% czasu na szukanie i przygotowywanie danych. Chcą to zrobić w dowolny sposób, aby zwiększyć produktywność operacyjną. Umożliwienie integratorom danych obywateli wzbogacania, kształtowania i publikowania danych przy użyciu znanych narzędzi, takich jak Power Query Online, w sposób skalowalny znacząco poprawia ich produktywność. Wrangling w usłudze Azure Data Factory umożliwia znanemu edytorowi mashupów usługi Power Query Online umożliwienie integratorom danych obywatelom szybkiego naprawiania błędów, standaryzacji danych i generowania wysokiej jakości danych w celu wspierania decyzji biznesowych.
Walidacja i eksploracja danych
Wizualnie skanuj dane w sposób wolny od kodu, aby usunąć wszelkie wartości odstające, anomalie i dostosować je do kształtu na potrzeby szybkiej analizy.
Obsługiwane źródła
| Łącznik | Format danych | Authentication type |
|---|---|---|
| Azure Blob Storage | CSV, Parquet, Excel | Klucz konta, jednostka usługi, msi |
| Usługa Azure Data Lake Storage 1. generacji | CSV, Parquet, Excel | Jednostka usługi, tożsamość usługi zarządzanej |
| Azure Data Lake Storage Gen2 | CSV, Parquet, Excel | Klucz konta, jednostka usługi, msi |
| Azure SQL Database | - | Uwierzytelnianie SQL, msi, jednostka usługi |
| Azure Synapse Analytics | - | Uwierzytelnianie SQL, msi, jednostka usługi |
Edytor mashupów
Podczas tworzenia działania Dodatku Power Query wszystkie źródłowe zestawy danych stają się zapytaniami zestawów danych i są umieszczane w folderze ADFResource . Domyślnie zapytanie UserQuery będzie wskazywać pierwsze zapytanie zestawu danych. Wszystkie przekształcenia należy wykonać w trybie UserQuery, ponieważ zmiany zapytań dotyczących zestawu danych nie są obsługiwane ani nie będą utrwalane. Zmiana nazwy, dodawanie i usuwanie zapytań nie jest obecnie obsługiwane.
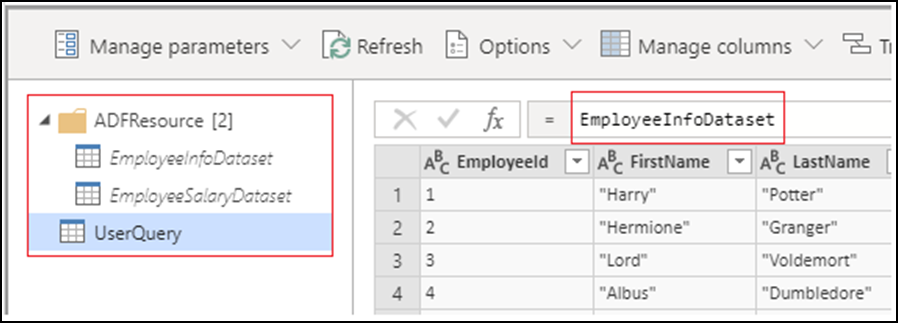
Obecnie nie wszystkie funkcje języka Power Query M są obsługiwane w przypadku uzdatniania danych, mimo że są dostępne podczas tworzenia. Podczas tworzenia działań dodatku Power Query zostanie wyświetlony następujący komunikat o błędzie, jeśli funkcja nie jest obsługiwana:
The Power Query Spark Runtime does not support the function
Aby uzyskać więcej informacji na temat obsługiwanych przekształceń, zobacz Funkcje uzdatniania danych dodatku Power Query.
Powiązana zawartość
Dowiedz się, jak utworzyć uzdatnianie danych za pomocą mash-upu dodatku Power Query.