Wyszukiwanie wektorów usługi Databricks
Ważne
Ta funkcja jest dostępna w publicznej wersji zapoznawczej w następujących regionach: canadacentral, , centralus, southeastasiaeastusnortheuropewesteuropeeastus2, , . westus2westus
Ten artykuł zawiera omówienie rozwiązania bazy danych wektorów usługi Databricks, wyszukiwania wektorowego usługi Databricks, w tym tego, co to jest i jak działa.
Co to jest wyszukiwanie wektorów usługi Databricks?
Wyszukiwanie wektorów usługi Databricks to wektorowa baza danych wbudowana w platformę analizy usługi Databricks i zintegrowana z jej narzędziami do zapewniania ładu i produktywności. Wektorowa baza danych to baza danych zoptymalizowana pod kątem przechowywania i pobierania osadzonych. Osadzanie to matematyczne reprezentacje semantycznej zawartości danych, zwykle danych tekstowych lub obrazów. Osadzanie jest generowane przez duży model językowy i jest kluczowym składnikiem wielu aplikacji GenAI, które zależą od znajdowania dokumentów lub obrazów, które są podobne do siebie. Przykłady to systemy RAG, systemy rekomendacji oraz rozpoznawanie obrazów i wideo.
Wyszukiwanie wektorowe umożliwia utworzenie indeksu wyszukiwania wektorów na podstawie tabeli delty. Indeks zawiera osadzone dane z metadanymi. Następnie możesz wykonać zapytanie względem indeksu przy użyciu interfejsu API REST, aby zidentyfikować najbardziej podobne wektory i zwrócić skojarzone dokumenty. Indeks można strukturę do automatycznego synchronizowania po zaktualizowaniu bazowej tabeli delty.
Wyszukiwanie wektorów usługi Databricks używa algorytmu Hierarchiczny mały świat (HNSW) dla przybliżonego wyszukiwania najbliższych sąsiadów oraz metryki odległości L2 do mierzenia podobieństwa wektora osadzania. Jeśli chcesz użyć podobieństwa cosinus, musisz znormalizować osadzanie punktu danych przed ich wprowadzeniem do wyszukiwania wektorowego. Gdy punkty danych są znormalizowane, klasyfikacja wygenerowana przez odległość L2 jest taka sama, jak klasyfikacja tworzy podobieństwo cosinusu.
Jak działa wyszukiwanie wektorów?
Aby utworzyć bazę danych wektorów w usłudze Databricks, musisz najpierw zdecydować, jak zapewnić osadzanie wektorów. Usługa Databricks obsługuje trzy opcje:
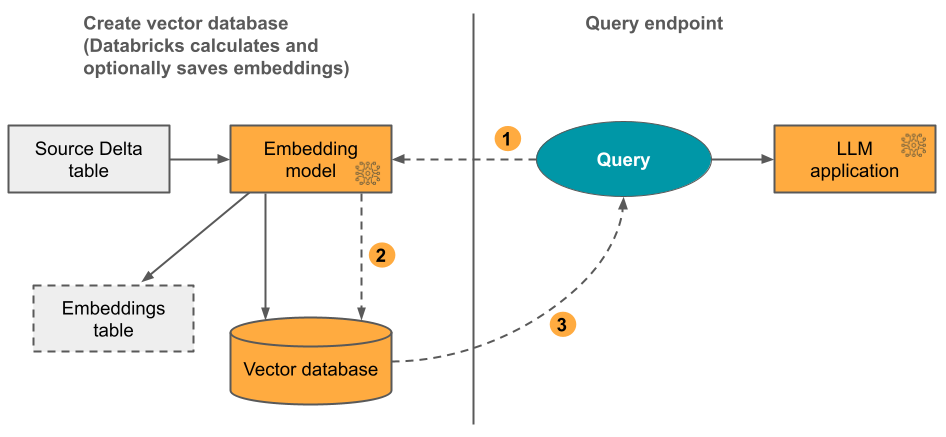
Opcja 1 Należy podać źródłową tabelę delty zawierającą dane w formacie tekstowym. Usługa Databricks oblicza osadzanie przy użyciu określonego modelu. Podczas aktualizowania tabeli delty indeks pozostaje zsynchronizowany z tabelą delty.
Na poniższym diagramie przedstawiono proces:
- Obliczanie osadzania zapytań. Zapytanie może zawierać filtry metadanych.
- Wykonaj wyszukiwanie podobieństwa, aby zidentyfikować najbardziej odpowiednie dokumenty.
- Zwróć najbardziej odpowiednie dokumenty i dołącz je do zapytania.
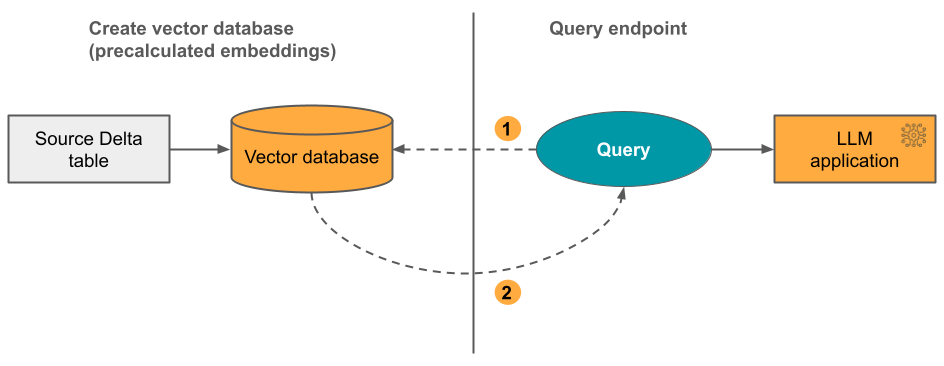
Opcja 2 Udostępniasz źródłową tabelę delty zawierającą wstępnie obliczone osadzanie. Podczas aktualizowania tabeli delty indeks pozostaje zsynchronizowany z tabelą delty.
Na poniższym diagramie przedstawiono proces:
- Zapytanie składa się z osadzania i może zawierać filtry metadanych.
- Wykonaj wyszukiwanie podobieństwa, aby zidentyfikować najbardziej odpowiednie dokumenty. Zwróć najbardziej odpowiednie dokumenty i dołącz je do zapytania.
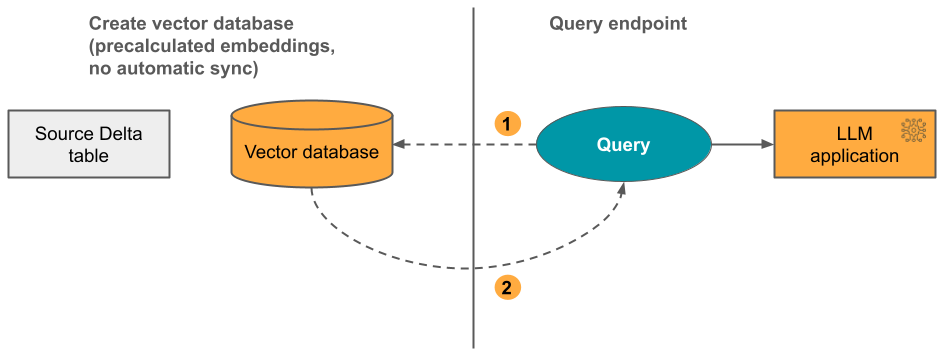
Opcja 3 Udostępniasz źródłową tabelę delty zawierającą wstępnie obliczone osadzanie. Nie ma automatycznej synchronizacji podczas aktualizowania tabeli delty. Podczas wprowadzania zmian w tabeli osadzania należy ręcznie zaktualizować indeks przy użyciu interfejsu API REST.
Na poniższym diagramie przedstawiono proces, który jest taki sam jak Opcja 2, z tą różnicą, że indeks wektorowy nie jest automatycznie aktualizowany po zmianie tabeli delty:
Jak skonfigurować wyszukiwanie wektorowe
Aby użyć funkcji Wyszukiwania wektorów usługi Databricks, należy utworzyć następujące elementy:
- Punkt końcowy wyszukiwania wektorów. Ten punkt końcowy obsługuje indeks wyszukiwania wektorowego. Punkt końcowy można wykonywać zapytania i aktualizować przy użyciu interfejsu API REST lub zestawu SDK. Punkty końcowe są skalowane automatycznie w celu obsługi rozmiaru indeksu lub liczby współbieżnych żądań. Aby uzyskać instrukcje, zobacz Tworzenie punktu końcowego wyszukiwania wektorów.
- Indeks wyszukiwania wektorowego. Indeks wyszukiwania wektorów jest tworzony na podstawie tabeli delty i jest zoptymalizowany pod kątem zapewniania przybliżonych wyszukiwań najbliższych sąsiadów w czasie rzeczywistym. Celem wyszukiwania jest zidentyfikowanie dokumentów, które są podobne do zapytania. Indeksy wyszukiwania wektorowego są wyświetlane w katalogu aparatu Unity i podlegają nim. Aby uzyskać instrukcje, zobacz Tworzenie indeksu wyszukiwania wektorów.
Ponadto jeśli zdecydujesz się, aby usługa Databricks obliczała osadzanie, musisz również utworzyć punkt końcowy obsługujący model dla modelu osadzania. Aby uzyskać instrukcje, zobacz Tworzenie modelu podstawowego obsługującego punkty końcowe.
Aby wykonać zapytanie dotyczące punktu końcowego obsługującego model, należy użyć interfejsu API REST lub zestawu SDK języka Python. Zapytanie może definiować filtry na podstawie dowolnej kolumny w tabeli delty. Aby uzyskać szczegółowe informacje, zobacz Używanie filtrów dla zapytań, dokumentacji interfejsu API lub dokumentacji zestawu SDK języka Python.
Wymagania
- Obszar roboczy z obsługą wykazu aparatu Unity.
- Włączono bezserwerowe obliczenia.
- Tabela źródłowa musi mieć włączoną opcję Zmień źródło danych.
- Tworzenie uprawnień TABELI w schematach wykazu w celu utworzenia indeksów.
- Włączone osobiste tokeny dostępu.
Ochrona i uwierzytelnianie danych
Usługa Databricks implementuje następujące mechanizmy kontroli zabezpieczeń w celu ochrony danych:
- Każde żądanie klienta do wyszukiwania wektorowego jest logicznie izolowane, uwierzytelniane i autoryzowane.
- Wyszukiwanie wektorów usługi Databricks szyfruje wszystkie dane magazynowane (AES-256) i podczas przesyłania (TLS 1.2+).
Wyszukiwanie wektorów usługi Databricks obsługuje dwa tryby uwierzytelniania:
- Osobisty token dostępu — możesz użyć osobistego tokenu dostępu do uwierzytelniania za pomocą funkcji wyszukiwania wektorowego. Zobacz osobisty token uwierzytelniania dostępu. Jeśli używasz zestawu SDK w środowisku notesu, automatycznie generuje token pat na potrzeby uwierzytelniania.
- Token jednostki usługi — administrator może wygenerować token jednostki usługi i przekazać go do zestawu SDK lub interfejsu API. Zobacz Use service principals (Używanie jednostek usługi). W przypadku przypadków użycia w środowisku produkcyjnym usługa Databricks zaleca użycie tokenu jednostki usługi.
Limity rozmiaru zasobów i danych
W poniższej tabeli przedstawiono podsumowanie limitów rozmiaru zasobów i danych dla punktów końcowych i indeksów wyszukiwania wektorów:
| Zasób | Poziom szczegółowości | Limit |
|---|---|---|
| Punkty końcowe wyszukiwania wektorowego | Na obszar roboczy | 10 |
| Osadzanie | Na punkt końcowy | 100,000,000 |
| Wymiar osadzania | Na indeks | 4096 |
| Indeksy | Na punkt końcowy | 20 |
| Kolumny | Na indeks | 20 |
| Kolumny | Obsługiwane typy: bajty, krótkie, liczba całkowita, długa, zmiennoprzecinkowa, podwójna, wartość logiczna, ciąg, sygnatura czasowa, data | |
| Pola metadanych | Na indeks | 20 |
| Nazwa indeksu | Na indeks | 128 znaków |
Następujące limity dotyczą tworzenia i aktualizowania indeksów wyszukiwania wektorowego:
| Zasób | Poziom szczegółowości | Limit |
|---|---|---|
| Rozmiar wiersza dla indeksu synchronizacji różnicowej | Na indeks | 100 KB |
| Osadzanie rozmiaru kolumny źródłowej dla indeksu usługi Delta Sync | Na indeks | 32764 bajty |
| Limit rozmiaru żądania operacji zbiorczych upsert dla indeksu wektora bezpośredniego | Na indeks | 10 MB |
| Limit rozmiaru żądania usuwania zbiorczego dla indeksu wektora bezpośredniego | Na indeks | 10 MB |
Następujące limity dotyczą interfejsu API zapytań na potrzeby wyszukiwania wektorów.
| Zasób | Poziom szczegółowości | Limit |
|---|---|---|
| Długość tekstu kwerendy | Na zapytanie | 32764 |
| Wyniki numeracji | Na zapytanie | 50 |
Ograniczenia
- Obsługa list dostępu privateLink lub IP jest obecnie ograniczona do wybranego zestawu klientów. Jeśli interesuje Cię korzystanie z funkcji z listami dostępu PrivateLink lub IP, skontaktuj się z pomocą techniczną usługi Databricks.
- Klucze zarządzane przez klienta (CMK) nie są obsługiwane w publicznej wersji zapoznawczej.
- Regulowane obszary robocze nie są obsługiwane, dlatego ta funkcja nie jest zgodna ze standardem HIPAA.
- Uprawnienia na poziomie wierszy i kolumn nie są obsługiwane. Można jednak zaimplementować własne listy ACL na poziomie aplikacji przy użyciu interfejsu API filtrowania.
Dodatkowe zasoby
- Wdróż czatbota LLM za pomocą funkcji pobierania rozszerzonej generacji (RAG), modeli podstawowych i wyszukiwania wektorów.
- Jak utworzyć indeks wyszukiwania wektorowego i wykonywać względem tego zapytania.
- Przykładowe notesy