Tabele wnioskowania na potrzeby monitorowania i debugowania modeli
Ważne
Ta funkcja jest dostępna w publicznej wersji zapoznawczej.
W tym artykule opisano tabele wnioskowania dotyczące monitorowania obsługiwanych modeli. Na poniższym diagramie przedstawiono typowy przepływ pracy z tabelami wnioskowania. Tabela wnioskowania automatycznie przechwytuje przychodzące żądania i odpowiedzi wychodzące dla modelu obsługującego punkt końcowy i rejestruje je jako tabelę delty wykazu aparatu Unity. Dane w tej tabeli umożliwiają monitorowanie, debugowanie i ulepszanie modeli uczenia maszynowego.
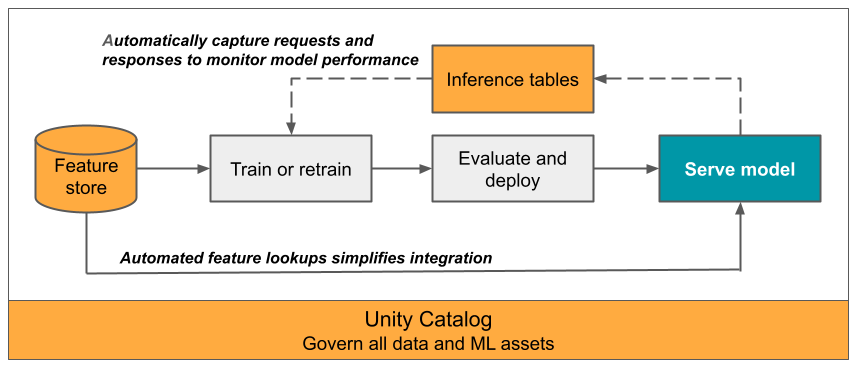
Co to są tabele wnioskowania?
Monitorowanie wydajności modeli w przepływach pracy produkcyjnych jest ważnym aspektem cyklu życia modelu sztucznej inteligencji i uczenia maszynowego. Tabele wnioskowania upraszczają monitorowanie i diagnostykę modeli przez ciągłe rejestrowanie obsługujące dane wejściowe żądań i odpowiedzi (przewidywania) z punktów końcowych obsługujących model usługi Databricks i zapisywanie ich w tabeli delty w wykazie aparatu Unity. Następnie możesz użyć wszystkich możliwości platformy Databricks, takich jak zapytania DBSQL, notesy i monitorowanie usługi Lakehouse, aby monitorować, debugować i optymalizować modele.
Tabele wnioskowania można włączyć dla dowolnego istniejącego lub nowo utworzonego modelu obsługującego punkt końcowy, a żądania do tego punktu końcowego są następnie automatycznie rejestrowane w tabeli w interfejsie użytkownika.
Niektóre typowe aplikacje dla tabel wnioskowania są następujące:
- Monitorowanie jakości danych i modelu. Możesz stale monitorować wydajność i dryf danych modelu przy użyciu monitorowania usługi Lakehouse. Monitorowanie usługi Lakehouse automatycznie generuje pulpity nawigacyjne dotyczące jakości danych i modelu, które można udostępniać uczestnikom projektu. Ponadto możesz włączyć alerty, aby wiedzieć, kiedy trzeba ponownie trenować model na podstawie zmian danych przychodzących lub zmniejszenia wydajności modelu.
- Debugowanie problemów z produkcją. Dane dziennika wnioskowania tabel, takie jak kody stanu HTTP, czas wykonywania modelu oraz kod JSON żądania i odpowiedzi. Te dane wydajności można używać do celów debugowania. Możesz również użyć danych historycznych w tabelach wnioskowania, aby porównać wydajność modelu z żądaniami historycznymi.
- Utwórz korpus treningowy. Łącząc tabele wnioskowania z etykietami podstawowych prawd, możesz utworzyć korpus szkoleniowy, którego można użyć do ponownego trenowania lub dostosowywania i ulepszania modelu. Korzystając z przepływów pracy usługi Databricks, można skonfigurować pętlę ciągłej opinii i zautomatyzować ponowne trenowanie.
Wymagania
- Obszar roboczy musi mieć włączony katalog aparatu Unity.
- Aby włączyć tabele wnioskowania w punkcie końcowym, zarówno twórca punktu końcowego, jak i modyfikator muszą mieć następujące uprawnienia:
- MOŻE ZARZĄDZAĆ uprawnieniem w punkcie końcowym.
USE CATALOGuprawnienia do określonego wykazu.USE SCHEMAuprawnienia do określonego schematu.CREATE TABLEuprawnienia w schemacie.
Włączanie i wyłączanie tabel wnioskowania
W tej sekcji pokazano, jak włączyć lub wyłączyć tabele wnioskowania przy użyciu interfejsu użytkownika usługi Databricks. Możesz również użyć interfejsu API; Aby uzyskać instrukcje, zobacz Enable inference tables on model serving endpoints using the API (Włączanie tabel wnioskowania w modelu obsługujących punkty końcowe przy użyciu interfejsu API ).
Właścicielem tabel wnioskowania jest użytkownik, który utworzył punkt końcowy. Wszystkie listy kontroli dostępu (ACL) w tabeli są zgodne ze standardowymi uprawnieniami wykazu aparatu Unity i mogą być modyfikowane przez właściciela tabeli.
Ostrzeżenie
Tabela wnioskowania może zostać uszkodzona, jeśli wykonasz dowolną z następujących czynności:
- Zmień schemat tabeli.
- Zmień nazwę tabeli.
- Usuń tabelę.
- Utrac uprawnienia do wykazu lub schematu wykazu aparatu Unity.
W takim przypadku stan auto_capture_config punktu końcowego pokazuje FAILED stan tabeli ładunku. W takim przypadku należy utworzyć nowy punkt końcowy, aby nadal korzystać z tabel wnioskowania.
Aby włączyć tabele wnioskowania podczas tworzenia punktu końcowego, wykonaj następujące kroki:
Kliknij pozycję Obsługa w interfejsie użytkownika Edukacja maszyny usługi Databricks.
Kliknij pozycję Utwórz obsługujący punkt końcowy.
Wybierz pozycję Włącz tabele wnioskowania.
W menu rozwijanych wybierz żądany wykaz i schemat, w którym ma znajdować się tabela.
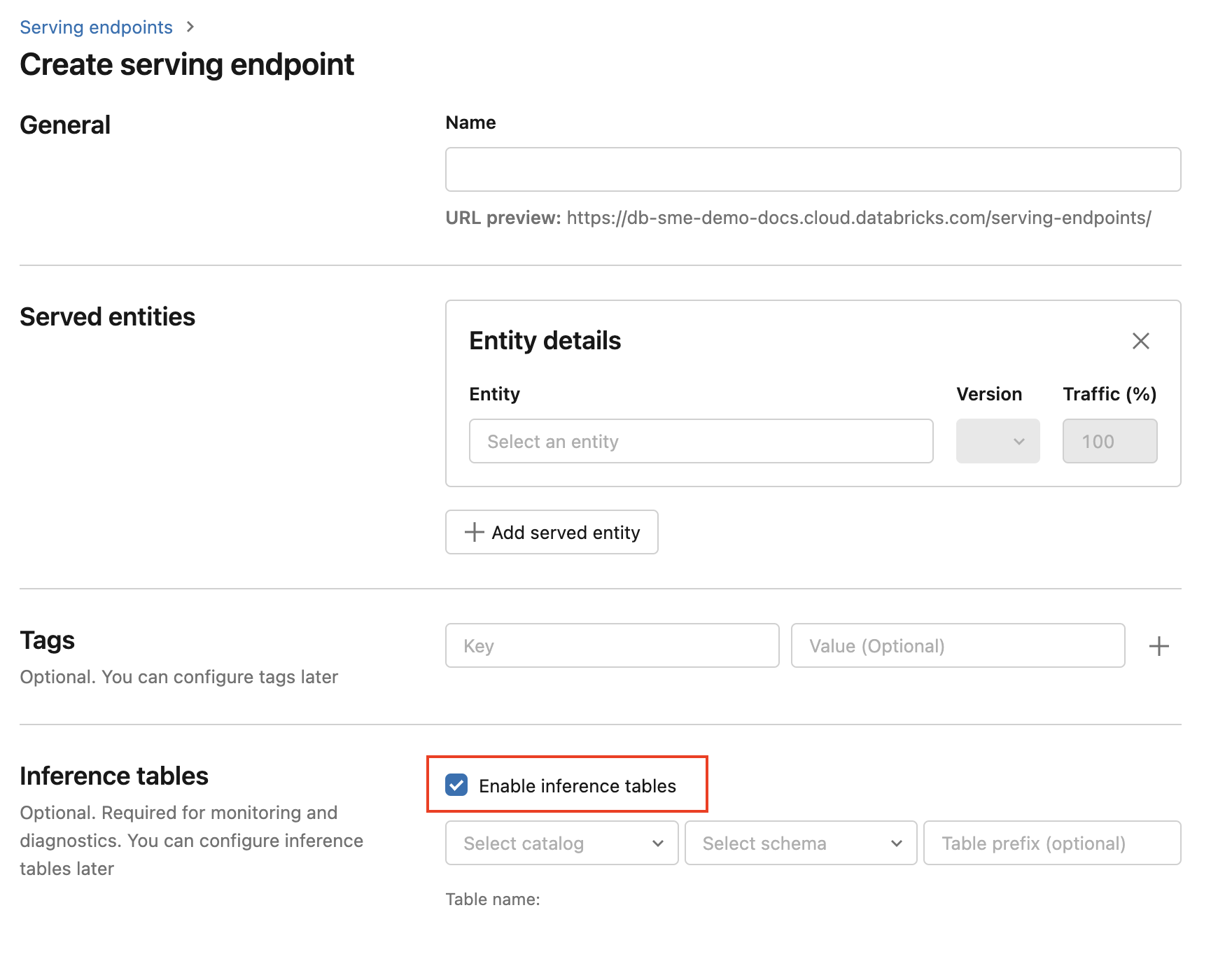
Domyślna nazwa tabeli to
<catalog>.<schema>.<endpoint-name>_payload. W razie potrzeby możesz wprowadzić niestandardowy prefiks tabeli.Kliknij pozycję Utwórz obsługujący punkt końcowy.
Tabele wnioskowania można również włączyć w istniejącym punkcie końcowym. Aby edytować istniejącą konfigurację punktu końcowego, wykonaj następujące czynności:
- Przejdź do strony punktu końcowego.
- Kliknij pozycję Edytuj konfigurację.
- Postępuj zgodnie z poprzednimi instrukcjami, zaczynając od kroku 3.
- Po zakończeniu kliknij pozycję Aktualizuj punkt końcowy obsługujący.
Postępuj zgodnie z tymi instrukcjami, aby wyłączyć tabele wnioskowania:
Ważne
Po wyłączeniu tabel wnioskowania w punkcie końcowym nie można ich ponownie włączyć. Aby kontynuować korzystanie z tabel wnioskowania, należy utworzyć nowy punkt końcowy i włączyć w nim tabele wnioskowania.
- Przejdź do strony punktu końcowego.
- Kliknij pozycję Edytuj konfigurację.
- Kliknij pozycję Włącz tabelę wnioskowania, aby usunąć znacznik wyboru.
- Po spełnieniu wymagań dotyczących specyfikacji punktu końcowego kliknij przycisk Aktualizuj.
Przepływ pracy: Monitorowanie wydajności modelu przy użyciu tabel wnioskowania
Aby monitorować wydajność modelu przy użyciu tabel wnioskowania, wykonaj następujące kroki:
- Włącz tabele wnioskowania w punkcie końcowym podczas tworzenia punktu końcowego lub aktualizując je później.
- Zaplanuj przepływ pracy, aby przetworzyć ładunki JSON w tabeli wnioskowania, rozpakując je zgodnie ze schematem punktu końcowego.
- (Opcjonalnie) Dołącz rozpakowane żądania i odpowiedzi z etykietami podstaw,aby umożliwić obliczanie metryk jakości modelu.
- Utwórz monitor nad wynikową tabelą delty i odśwież metryki.
Notesy początkowe implementują ten przepływ pracy.
Notes startowy do monitorowania tabeli wnioskowania
Poniższy notes implementuje kroki opisane powyżej w celu rozpakowywania żądań z tabeli wnioskowania monitorowania usługi Lakehouse. Notes można uruchamiać na żądanie lub zgodnie z harmonogramem cyklicznym przy użyciu przepływów pracy usługi Databricks.
Notes startowy dotyczący wnioskowania table Lakehouse Monitoring
Notes początkowy do monitorowania jakości tekstu z punktów końcowych obsługujących usługi LLMs
Poniższy notes rozpakowuje żądania z tabeli wnioskowania, oblicza zestaw metryk oceny tekstu (takich jak czytelność i toksyczność) i umożliwia monitorowanie tych metryk. Notes można uruchamiać na żądanie lub zgodnie z harmonogramem cyklicznym przy użyciu przepływów pracy usługi Databricks.
Notes startowy monitorowania usługi LLM table Lakehouse
Wykonywanie zapytań i analizowanie wyników w tabeli wnioskowania
Po dokonaniu gotowości obsługiwanych modeli wszystkie żądania wysyłane do modeli są rejestrowane automatycznie w tabeli wnioskowania wraz z odpowiedziami. Tabelę można wyświetlić w interfejsie użytkownika, wykonać zapytanie względem tabeli z bazy danych DBSQL lub notesu albo wykonać zapytanie względem tabeli przy użyciu interfejsu API REST.
Aby wyświetlić tabelę w interfejsie użytkownika: na stronie punktu końcowego kliknij nazwę tabeli wnioskowania, aby otworzyć tabelę w Eksploratorze wykazu.

Aby wykonać zapytanie dotyczące tabeli z bazy danych DBSQL lub notesu usługi Databricks: możesz uruchomić kod podobny do poniższego, aby wykonać zapytanie w tabeli wnioskowania.
SELECT * FROM <catalog>.<schema>.<payload_table>
Jeśli włączono tabele wnioskowania przy użyciu interfejsu użytkownika, payload_table to nazwa tabeli przypisana podczas tworzenia punktu końcowego. Jeśli włączono tabele wnioskowania przy użyciu interfejsu API, payload_table zostanie zgłoszone w state sekcji auto_capture_config odpowiedzi. Aby zapoznać się z przykładem, zobacz Włączanie tabel wnioskowania w modelu obsługujących punkty końcowe przy użyciu interfejsu API.
Uwaga dotycząca wydajności
Po wywołaniu punktu końcowego można zobaczyć wywołanie zarejestrowane w tabeli wnioskowania w ciągu 10 minut po wysłaniu żądania oceniania. Ponadto usługa Azure Databricks gwarantuje, że dostarczanie dzienników odbywa się co najmniej raz, więc jest możliwe, choć mało prawdopodobne, że wysyłane są zduplikowane dzienniki.
Schemat tabeli wnioskowania wykazu aparatu Unity
Każde żądanie i odpowiedź, która jest rejestrowana w tabeli wnioskowania, jest zapisywana w tabeli delty przy użyciu następującego schematu:
Uwaga
Jeśli wywołasz punkt końcowy z partią danych wejściowych, cała partia zostanie zarejestrowana jako jeden wiersz.
| Nazwa kolumny | opis | Type |
|---|---|---|
databricks_request_id |
Wygenerowany identyfikator żądania usługi Azure Databricks dołączony do wszystkich żądań obsługi modelu. | CIĄG |
client_request_id |
Opcjonalny identyfikator żądania wygenerowany przez klienta, który można określić w treści żądania obsługującego model. Zobacz Określanie client_request_id , aby uzyskać więcej informacji. |
CIĄG |
date |
Data UTC, w której odebrano żądanie obsługi modelu. | DATE |
timestamp_ms |
Sygnatura czasowa w milisekundach epoki po odebraniu żądania obsługi modelu. | DŁUGI |
status_code |
Kod stanu HTTP zwrócony z modelu. | INT |
sampling_fraction |
Ułamek próbkowania używany w przypadku, gdy żądanie zostało próbkowane w dół. Ta wartość wynosi od 0 do 1, gdzie 1 oznacza, że uwzględniono 100% żądań przychodzących. | PODWÓJNE |
execution_time_ms |
Czas wykonywania w milisekundach, dla których model wykonał wnioskowanie. Nie obejmuje to opóźnień sieci narzutów i reprezentuje tylko czas, jaki zajęło modelowi generowanie przewidywań. | DŁUGI |
request |
Treść nieprzetworzonego żądania JSON, która została wysłana do punktu końcowego obsługującego model. | CIĄG |
response |
Treść nieprzetworzonej odpowiedzi JSON zwrócona przez punkt końcowy obsługujący model. | CIĄG |
request_metadata |
Mapa metadanych związanych z modelem obsługującym punkt końcowy skojarzony z żądaniem. Ta mapa zawiera nazwę punktu końcowego, nazwę modelu i wersję modelu używaną dla punktu końcowego. | CIĄG MAPY<, CIĄG> |
Określić client_request_id
Pole client_request_id jest opcjonalną wartością, która użytkownik może podać w treści żądania obsługującego model. Dzięki temu użytkownik może podać swój własny identyfikator dla żądania, które jest wyświetlane w końcowej tabeli wnioskowania w obszarze client_request_id i może służyć do dołączania żądania do innych tabel, które używają client_request_idobiektu , takiego jak dołączenie etykiety podstawy prawdy. Aby określić element client_request_id, dołącz go jako klucz najwyższego poziomu ładunku żądania. Jeśli nie client_request_id zostanie określony, wartość będzie wyświetlana jako null w wierszu odpowiadającym żądaniu.
{
"client_request_id": "<user-provided-id>",
"dataframe_records": [
{
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.9,
"sepal width (cm)": 3,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.7,
"sepal width (cm)": 3.2,
"petal length (cm)": 1.3,
"petal width (cm)": 0.2
}
]
}
Można client_request_id go później użyć do sprzężeń etykiet prawdzie naziemnej, jeśli istnieją inne tabele, które mają etykiety skojarzone z client_request_id.
Ograniczenia
- Klucze zarządzane przez klienta nie są obsługiwane.
- W przypadku punktów końcowych hostujących modele podstaw tabel wnioskowania są obsługiwane tylko w przypadku obciążeń aprowizowanej przepływności .
- Tabele wnioskowania w punktach końcowych aprowizowanej przepływności nie obsługują rejestrowania żądań przesyłania strumieniowego.
- Tabele wnioskowania nie są obsługiwane w punktach końcowych hostujących modele zewnętrzne.
- Usługa Azure Firewall nie jest obsługiwana i może spowodować niepowodzenie tworzenia tabeli delty wykazu aparatu Unity.
- Po włączeniu tabel wnioskowania limit całkowitej maksymalnej współbieżności we wszystkich obsługiwanych modelach w jednym punkcie końcowym wynosi 128. Skontaktuj się z zespołem konta usługi Azure Databricks, aby poprosić o zwiększenie tego limitu.
- Jeśli tabela wnioskowania zawiera więcej niż 500 000 plików, żadne dodatkowe dane nie są rejestrowane. Aby uniknąć przekroczenia tego limitu, uruchom polecenie OPTIMIZE lub skonfiguruj przechowywanie w tabeli, usuwając starsze dane. Aby sprawdzić liczbę plików w tabeli, uruchom polecenie
DESCRIBE DETAIL <catalog>.<schema>.<payload_table>.
Aby uzyskać ogólne ograniczenia dotyczące obsługi punktów końcowych, zobacz Limity i regiony obsługi modeli.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla