Wprowadzenie do przepływów pracy usługi Azure Databricks
Przepływy pracy usługi Azure Databricks organizuje potoki przetwarzania danych, uczenia maszynowego i analizy na platformie analizy danych usługi Databricks. Przepływy pracy mają w pełni zarządzane usługi orkiestracji zintegrowane z platformą Databricks, w tym zadania usługi Azure Databricks do uruchamiania nieinterakcyjnego kodu w obszarze roboczym usługi Azure Databricks i tabel delta Live Tables w celu tworzenia niezawodnych i konserwowalnych potoków ETL.
Aby dowiedzieć się więcej o zaletach organizowania przepływów pracy za pomocą platformy databricks, zobacz Przepływy pracy usługi Databricks.
Przykładowy przepływ pracy usługi Azure Databricks
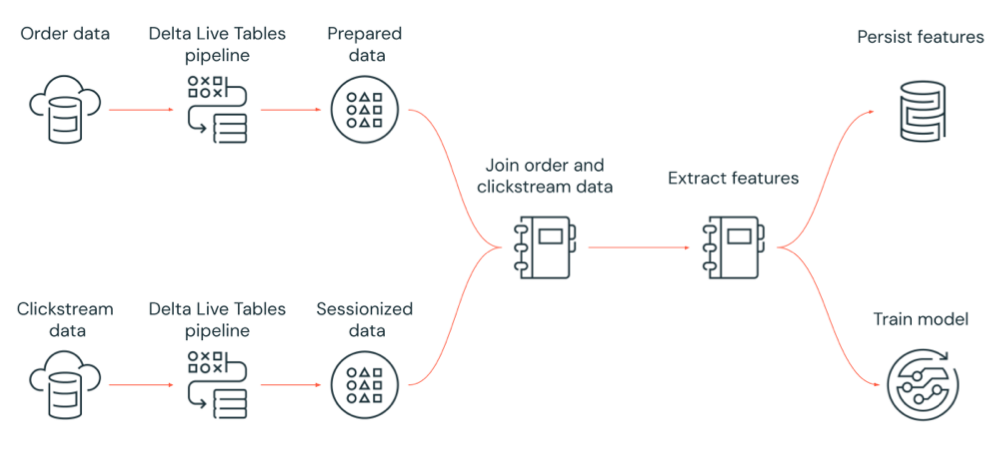
Na poniższym diagramie przedstawiono przepływ pracy zorganizowany przez zadanie usługi Azure Databricks w celu:
- Uruchom potok Delta Live Tables, który pozyskuje nieprzetworzone dane strumienia kliknięć z magazynu w chmurze, czyści i przygotowuje dane, sesjonuje dane i utrwala końcowy zestaw danych sesji na usługę Delta Lake.
- Uruchom potok Delta Live Tables, który pozysuje dane zamówienia z magazynu w chmurze, czyści i przekształca dane na potrzeby przetwarzania, a następnie utrwala końcowy zestaw danych na usługę Delta Lake.
- Dołącz do kolejności i sesyjne dane strumienia kliknięć, aby utworzyć nowy zestaw danych na potrzeby analizy.
- Wyodrębnianie funkcji z przygotowanych danych.
- Równoległe wykonywanie zadań w celu utrwalania funkcji i trenowania modelu uczenia maszynowego.
Co to są zadania usługi Azure Databricks?
Zadanie usługi Azure Databricks to sposób uruchamiania aplikacji do przetwarzania i analizy danych w obszarze roboczym usługi Azure Databricks. Zadanie może być pojedyncze lub może być dużym, wielozadaniowym przepływem pracy ze złożonymi zależnościami. Usługa Azure Databricks zarządza orkiestracją zadań, zarządzaniem klastrem, monitorowaniem i raportowaniem błędów dla wszystkich zadań. Zadania można uruchamiać natychmiast, okresowo za pomocą łatwego w użyciu systemu planowania, gdy nowe pliki docierają do lokalizacji zewnętrznej lub stale, aby zapewnić, że wystąpienie zadania jest zawsze uruchomione. Zadania można również uruchamiać interaktywnie w interfejsie użytkownika notesu.
Zadanie można utworzyć i uruchomić przy użyciu interfejsu użytkownika zadań, interfejsu wiersza polecenia usługi Databricks lub wywołując interfejs API zadań. Aby naprawić i ponownie uruchomić zadanie, które zakończyło się niepowodzeniem lub zostało anulowane, można użyć interfejsu użytkownika lub interfejsu API. Wyniki uruchomienia zadania można monitorować przy użyciu interfejsu użytkownika, interfejsu wiersza polecenia, interfejsu API i powiadomień (na przykład wiadomości e-mail, miejsca docelowego elementu webhook lub powiadomień usługi Slack).
Aby dowiedzieć się więcej na temat korzystania z interfejsu wiersza polecenia usługi Databricks, zobacz Co to jest interfejs wiersza polecenia usługi Databricks?. Aby dowiedzieć się więcej o korzystaniu z interfejsu API zadań, zobacz Interfejs API zadań.
W poniższych sekcjach omówiono ważne funkcje zadań usługi Azure Databricks.
Ważne
- Obszar roboczy jest ograniczony do 1000 współbieżnych uruchomień zadań. Odpowiedź
429 Too Many Requestsjest zwracana po zażądaniu uruchomienia, gdy natychmiastowe uruchomienie nie jest możliwe. - Liczba zadań, które można utworzyć w obszarze roboczym w ciągu godziny, jest ograniczona do 10000 (obejmuje "przesyłanie przebiegów"). Ten limit wpływa również na zadania utworzone przez przepływy pracy notesu i interfejsu API REST.
Implementowanie przetwarzania i analizy danych za pomocą zadań podrzędnych
Zaimplementujesz przepływ pracy przetwarzania i analizy danych przy użyciu zadań podrzędnych. Zadanie składa się z co najmniej jednego zadania. Możesz tworzyć zadania podrzędne, które uruchamiają notesy, pliki JARS, potoki delta live tables lub Python, Scala, Spark submit i Java. Zadania podrzędne zadania mogą również organizować zapytania SQL usługi Databricks, alerty i pulpity nawigacyjne w celu tworzenia analiz i wizualizacji lub użyć zadania dbt do uruchamiania przekształceń dbt w przepływie pracy. Obsługiwane są również starsze aplikacje do przesyłania platformy Spark.
Możesz również dodać zadanie do zadania, które uruchamia inne zadanie. Ta funkcja umożliwia podzielenie dużego procesu na wiele mniejszych zadań lub utworzenie uogólnionych modułów, które mogą być ponownie używane przez wiele zadań.
Kolejność wykonywania zadań można kontrolować, określając zależności między zadaniami. Zadania można skonfigurować do uruchamiania w sekwencji lub równolegle.
Uruchamianie zadań interakcyjnych, ciągłych lub przy użyciu wyzwalaczy zadań
Zadania można uruchamiać interaktywnie z poziomu interfejsu użytkownika zadań, interfejsu API lub interfejsu wiersza polecenia albo uruchamiać zadanie ciągłe. Możesz utworzyć harmonogram , aby okresowo uruchamiać zadanie lub uruchamiać zadanie po nadejściu nowych plików w lokalizacji zewnętrznej, takiej jak Amazon S3, Azure Storage lub Google Cloud Storage.
Monitorowanie postępu zadania za pomocą powiadomień
Powiadomienia można otrzymywać, gdy zadanie lub zadanie rozpoczyna się, kończy lub kończy się niepowodzeniem. Powiadomienia można wysyłać do co najmniej jednego adresu e-mail lub miejsc docelowych systemu (na przykład miejsc docelowych elementu webhook lub usługi Slack). Zobacz Dodawanie wiadomości e-mail i powiadomień systemowych dotyczących zdarzeń zadań.
Uruchamianie zadań za pomocą zasobów obliczeniowych usługi Azure Databricks
Klastry usługi Databricks i magazyny SQL zapewniają zasoby obliczeniowe dla zadań. Zadania można uruchamiać za pomocą klastra zadań, klastra ogólnego przeznaczenia lub usługi SQL Warehouse:
- Klaster zadań jest dedykowanym klastrem dla zadania lub poszczególnych zadań podrzędnych. Zadanie może używać klastra zadań współużytkowanego przez wszystkie zadania lub można skonfigurować klaster dla poszczególnych zadań podczas tworzenia lub edytowania zadania. Klaster zadań jest tworzony, gdy zadanie lub zadanie zostanie uruchomione i zakończone po zakończeniu zadania lub zadania.
- Klaster ogólnego przeznaczenia to udostępniony klaster, który jest ręcznie uruchamiany i przerywany i może być współużytkowany przez wielu użytkowników i zadań.
Aby zoptymalizować użycie zasobów, usługa Databricks zaleca używanie klastra zadań dla zadań. Aby skrócić czas oczekiwania na uruchomienie klastra, rozważ użycie klastra ogólnego przeznaczenia. Zobacz Use Azure Databricks compute with your jobs (Używanie obliczeń usługi Azure Databricks z zadaniami).
Usługa SQL Warehouse służy do uruchamiania zadań SQL usługi Databricks, takich jak zapytania, pulpity nawigacyjne lub alerty. Za pomocą usługi SQL Warehouse można również uruchamiać przekształcenia dbt za pomocą zadania dbt.
Następne kroki
Aby rozpocząć pracę z zadaniami usługi Azure Databricks:
Utwórz swoje pierwsze zadanie usługi Azure Databricks przy użyciu przewodnika Szybki start.
Dowiedz się, jak tworzyć i uruchamiać przepływy pracy za pomocą interfejsu użytkownika zadań usługi Azure Databricks.
Dowiedz się, jak uruchomić zadanie bez konieczności konfigurowania zasobów obliczeniowych usługi Azure Databricks przy użyciu przepływów pracy bezserwerowych.
Dowiedz się więcej na temat uruchamiania zadań monitorowania w interfejsie użytkownika zadań usługi Azure Databricks.
Dowiedz się więcej o opcjach konfiguracji zadań.
Dowiedz się więcej o tworzeniu przepływów pracy, zarządzaniu nimi i rozwiązywaniu problemów z nimi za pomocą zadań usługi Azure Databricks:
- Dowiedz się, jak komunikować informacje między zadaniami w zadaniu usługi Azure Databricks przy użyciu wartości zadań.
- Dowiedz się, jak przekazać kontekst zadania podrzędnego do zadań podrzędnych ze zmiennymi parametrów zadania.
- Dowiedz się, jak skonfigurować zadania podrzędne do uruchamiania warunkowo na podstawie stanu zależności zadania.
- Dowiedz się, jak rozwiązywać problemy i naprawiać zadania, które zakończyły się niepowodzeniem.
- Otrzymuj powiadomienia o uruchomieniu zadania, zakończeniu lub niepomyślnym uruchomieniu zadania z powiadomieniami o uruchomieniu zadania.
- Wyzwalanie zadań zgodnie z niestandardowym harmonogramem lub uruchamianie zadania ciągłego.
- Dowiedz się, jak uruchomić zadanie usługi Azure Databricks po nadejściu nowych danych z wyzwalaczami nadejścia pliku.
- Dowiedz się, jak używać zasobów obliczeniowych usługi Databricks do uruchamiania zadań.
- Dowiedz się więcej o aktualizacjach interfejsu API zadań w celu obsługi tworzenia przepływów pracy i zarządzania nimi za pomocą zadań usługi Azure Databricks.
- Skorzystaj z przewodników z instrukcjami i samouczkami , aby dowiedzieć się więcej na temat implementowania przepływów pracy danych za pomocą zadań usługi Azure Databricks.
Co to są tabele na żywo usługi Delta?
Uwaga
Delta Live Tables wymaga planu Premium. Aby uzyskać więcej informacji, skontaktuj się z zespołem ds. kont usługi Databricks.
Delta Live Tables to struktura, która upraszcza proces ETL i przetwarzanie danych przesyłanych strumieniowo. Delta Live Tables zapewnia wydajne pozyskiwanie danych z wbudowaną obsługą automatycznego modułu ładującego, interfejsów SQL i Python obsługujących deklaratywną implementację przekształceń danych oraz obsługę zapisywania przekształconych danych w usłudze Delta Lake. Przekształcenia do wykonania na danych są definiowane, a usługa Delta Live Tables zarządza aranżacją zadań, zarządzaniem klastrem, monitorowaniem, jakością danych i obsługą błędów.
Aby rozpocząć, zobacz Co to jest delta live tables?.
Zadania usługi Azure Databricks i tabele delta live
Zadania usługi Azure Databricks i tabele delta live zapewniają kompleksową strukturę tworzenia i wdrażania kompleksowych przepływów pracy przetwarzania i analizy danych.
Użyj funkcji Delta Live Tables, aby uzyskać wszystkie pozyskiwanie i przekształcanie danych. Za pomocą zadań usługi Azure Databricks można organizować obciążenia składające się z jednego zadania lub wielu zadań przetwarzania i analizy danych na platformie Databricks, w tym pozyskiwania i przekształcania tabel delta live.
Jako system aranżacji przepływu pracy usługa Azure Databricks Jobs obsługuje również następujące funkcje:
- Uruchamianie zadań na podstawie wyzwalanej, na przykład uruchamianie przepływu pracy zgodnie z harmonogramem.
- Analiza danych za pomocą zapytań SQL, uczenia maszynowego i analizy danych za pomocą notesów, skryptów lub bibliotek zewnętrznych itd.
- Uruchamianie zadania składającego się z jednego zadania, na przykład uruchomienia zadania platformy Apache Spark spakowanego w pliku JAR.
Orkiestracja przepływu pracy za pomocą platformy Apache AirFlow
Mimo że usługa Databricks zaleca używanie zadań usługi Azure Databricks do organizowania przepływów pracy danych, możesz również użyć platformy Apache Airflow do zarządzania przepływami pracy danych i planowania ich. Za pomocą funkcji Airflow definiujesz przepływ pracy w pliku języka Python, a aplikacja Airflow zarządza planowaniem i uruchamianiem przepływu pracy. Zobacz Orchestrate Azure Databricks jobs with Apache Airflow (Organizowanie zadań usługi Azure Databricks za pomocą platformy Apache Airflow).
Orkiestracja przepływu pracy za pomocą usługi Azure Data Factory
Azure Data Factory (ADF) to usługa integracji danych w chmurze, która umożliwia tworzenie usług magazynu, przenoszenia i przetwarzania danych do zautomatyzowanych potoków danych. Usługi ADF można użyć do organizowania zadania usługi Azure Databricks w ramach potoku usługi ADF.
Aby dowiedzieć się, jak uruchomić zadanie przy użyciu działania internetowego usługi ADF, w tym sposobu uwierzytelniania w usłudze Azure Databricks z usługi ADF, zobacz Korzystanie z aranżacji zadań usługi Azure Databricks z usługi Azure Data Factory.
Usługa ADF zapewnia również wbudowaną obsługę uruchamiania notesów usługi Databricks, skryptów języka Python lub kodu spakowanego w plikach JAR w potoku usługi ADF.
Aby dowiedzieć się, jak uruchomić notes usługi Databricks w potoku usługi ADF, zobacz Uruchamianie notesu usługi Databricks przy użyciu działania notesu usługi Databricks w usłudze Azure Data Factory, a następnie przekształcanie danych przez uruchomienie notesu usługi Databricks.
Aby dowiedzieć się, jak uruchomić skrypt języka Python w potoku usługi ADF, zobacz Przekształcanie danych przez uruchomienie działania języka Python w usłudze Azure Databricks.
Aby dowiedzieć się, jak uruchomić kod spakowany w pliku JAR w potoku usługi ADF, zobacz Przekształcanie danych przez uruchomienie działania JAR w usłudze Azure Databricks.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla