Ręczne skalowanie klastrów usługi Azure HDInsight
Usługa HDInsight zapewnia elastyczność dzięki opcjom skalowania w górę i skalowania w dół liczby węzłów roboczych w klastrach. Ta elastyczność pozwala zmniejszyć klaster po godzinach lub w weekendy. I rozszerzać go w szczytowych wymaganiach biznesowych.
Skaluj klaster w górę przed okresowym przetwarzaniem wsadowym, aby klaster miał odpowiednie zasoby. Po zakończeniu przetwarzania i spadku użycia przeskaluj klaster usługi HDInsight w dół do mniejszej liczby węzłów roboczych.
Klaster można skalować ręcznie przy użyciu jednej z następujących metod. Możesz również użyć opcji automatycznego skalowania , aby automatycznie skalować w górę i w dół w odpowiedzi na określone metryki.
Uwaga
Obsługiwane są tylko klastry z usługą HDInsight w wersji 3.1.3 lub nowszej. Jeśli nie masz pewności co do wersji klastra, możesz sprawdzić stronę Właściwości.
Narzędzia do skalowania klastrów
Firma Microsoft udostępnia następujące narzędzia do skalowania klastrów:
| Narzędzie | opis |
|---|---|
| PowerShell Az | Set-AzHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| PowerShell AzureRM | Set-AzureRmHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| Interfejs wiersza polecenia platformy Azure | az hdinsight resize --resource-group RESOURCEGROUP --name CLUSTERNAME --workernode-count NEWSIZE |
| Klasyczny interfejs wiersza polecenia platformy Azure | azure hdinsight cluster resize CLUSTERNAME NEWSIZE |
| Witryna Azure Portal | Otwórz okienko klastra usługi HDInsight, wybierz pozycję Rozmiar klastra w menu po lewej stronie, a następnie w okienku Rozmiar klastra wpisz liczbę węzłów roboczych i wybierz pozycję Zapisz. |
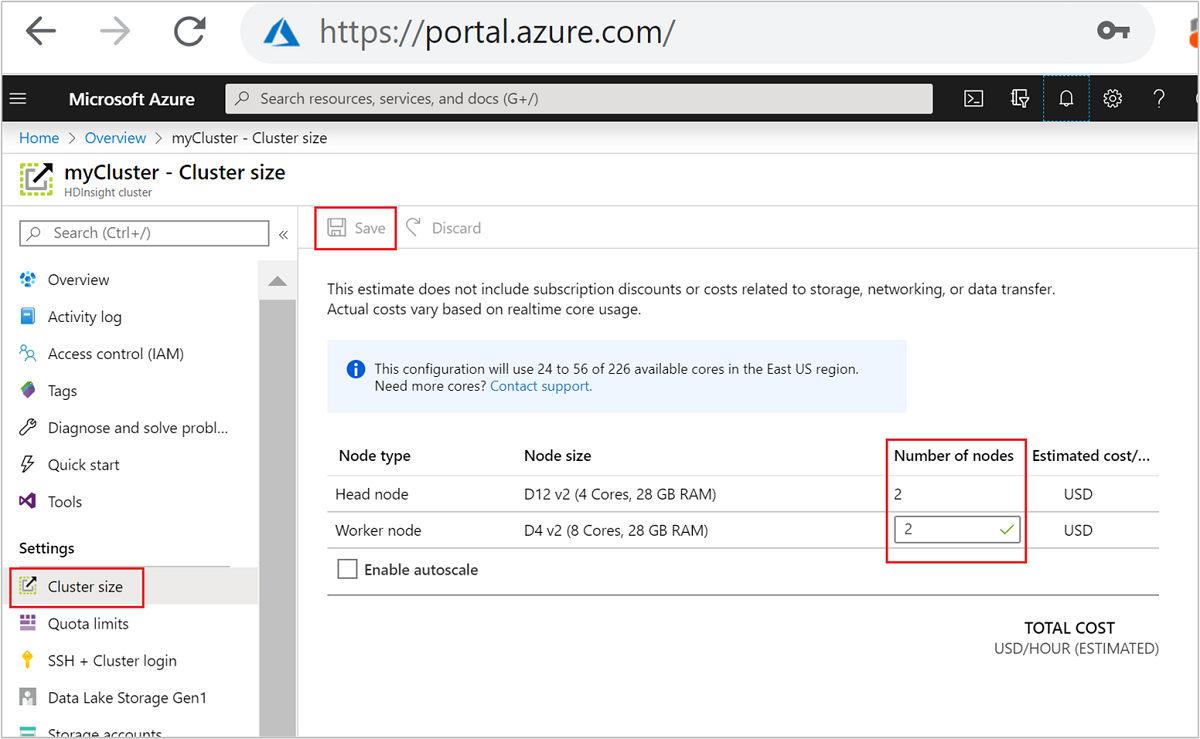
Korzystając z dowolnej z tych metod, możesz skalować klaster usługi HDInsight w górę lub w dół w ciągu kilku minut.
Ważne
- Klasyczny interfejs wiersza polecenia platformy Azure jest przestarzały i powinien być używany tylko z klasycznym modelem wdrażania. W przypadku wszystkich innych wdrożeń stosuj interfejs wiersza polecenia platformy Azure.
- Moduł AzureRM programu PowerShell jest przestarzały. Jeśli to możliwe, użyj modułu Az.
Wpływ operacji skalowania
W przypadku dodawania węzłów do uruchomionego klastra usługi HDInsight (skalowanie w górę) zadania pozostają nienaruszone. Nowe zadania można bezpiecznie przesłać, gdy proces skalowania jest uruchomiony. Jeśli operacja skalowania zakończy się niepowodzeniem, awaria pozostawi klaster w stanie funkcjonalnym.
Jeśli usuniesz węzły (skalowanie w dół), oczekujące lub uruchomione zadania zakończą się niepowodzeniem po zakończeniu operacji skalowania. Ten błąd jest spowodowany ponownym uruchomieniem niektórych usług podczas procesu skalowania. Klaster może zostać zablokowany w trybie awaryjnym podczas ręcznej operacji skalowania.
Wpływ zmiany liczby węzłów danych zależy od każdego typu klastra obsługiwanego przez usługę HDInsight:
Apache Hadoop
Możesz bezproblemowo zwiększyć liczbę węzłów roboczych w uruchomionym klastrze hadoop bez wpływu na żadne zadania. Nowe zadania można również przesyłać, gdy operacja jest w toku. Błędy w operacji skalowania są bezpiecznie obsługiwane. Klaster jest zawsze pozostawiony w stanie funkcjonalnym.
Gdy klaster Hadoop jest skalowany w dół z mniejszą liczbą węzłów danych, niektóre usługi są ponownie uruchamiane. To zachowanie powoduje, że wszystkie uruchomione i oczekujące zadania zakończą się niepowodzeniem po zakończeniu operacji skalowania. Można jednak ponownie przesłać zadania po zakończeniu operacji.
Apache HBase
Możesz bezproblemowo dodawać lub usuwać węzły do klastra HBase podczas jego działania. Serwery regionalne są automatycznie zrównoważone w ciągu kilku minut od ukończenia operacji skalowania. Można jednak ręcznie zrównoważyć serwery regionalne. Zaloguj się do węzła głównego klastra i uruchom następujące polecenia:
pushd %HBASE_HOME%\bin hbase shell balancerAby uzyskać więcej informacji na temat korzystania z powłoki HBase, zobacz Wprowadzenie do przykładu bazy danych Apache HBase w usłudze HDInsight.
Kafka
Repliki partycji należy ponownie zrównoważyć po operacjach skalowania. Aby uzyskać więcej informacji, zobacz dokument Wysoka dostępność danych za pomocą platformy Apache Kafka w usłudze HDInsight .
Apache Hive
Po skalowaniu do
Nwęzłów roboczych usługa HDInsight automatycznie ustawi następujące konfiguracje i uruchom ponownie program Hive.- Maksymalna łączna liczba współbieżnych zapytań:
hive.server2.tez.sessions.per.default.queue = min(N, 32) - Liczba węzłów używanych przez llAP programu Hive:
num_llap_nodes = N - Liczba węzłów do uruchamiania demona LLAP programu Hive:
num_llap_nodes_for_llap_daemons = N
- Maksymalna łączna liczba współbieżnych zapytań:
Jak bezpiecznie skalować klaster w dół
Skalowanie klastra w dół przy użyciu uruchomionych zadań
Aby uniknąć niepowodzenia uruchomionych zadań podczas operacji skalowania w dół, możesz wypróbować trzy elementy:
- Poczekaj na zakończenie zadań przed skalowaniem klastra w dół.
- Ręcznie zakończ zadania.
- Prześlij ponownie zadania po zakończeniu operacji skalowania.
Aby wyświetlić listę oczekujących i uruchomionych zadań, możesz użyć interfejsu użytkownika usługi Resource Manager usługi YARN, wykonując następujące kroki:
W witrynie Azure Portal wybierz klaster. Klaster zostanie otwarty na nowej stronie portalu.
W widoku głównym przejdź do pulpitów nawigacyjnych klastra>Ambari home. Wprowadź poświadczenia klastra.
W interfejsie użytkownika systemu Ambari wybierz pozycję YARN na liście usług w menu po lewej stronie.
Na stronie YARN wybierz pozycję Szybkie linki i umieść kursor na aktywnym węźle głównym, a następnie wybierz pozycję Interfejs użytkownika usługi Resource Manager.
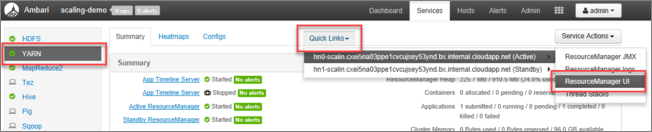
Możesz bezpośrednio uzyskać dostęp do interfejsu użytkownika usługi Resource Manager za pomocą polecenia https://<HDInsightClusterName>.azurehdinsight.net/yarnui/hn/cluster.
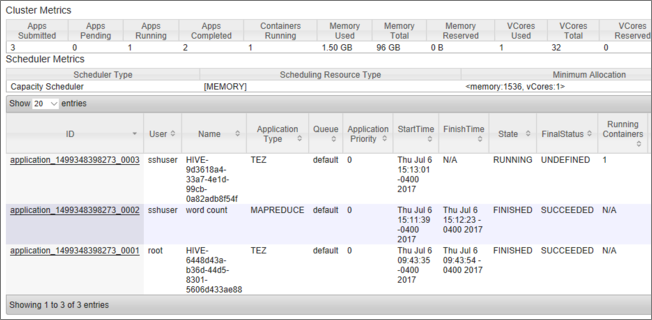
Zostanie wyświetlona lista zadań wraz z ich bieżącym stanem. Na zrzucie ekranu jest aktualnie uruchomione jedno zadanie:
Aby ręcznie zabić uruchomioną aplikację, wykonaj następujące polecenie w powłoce SSH:
yarn application -kill <application_id>
Na przykład:
yarn application -kill "application_1499348398273_0003"
Utknięcie w trybie awaryjnym
Podczas skalowania klastra w dół usługa HDInsight używa interfejsów zarządzania apache Ambari, aby najpierw zlikwidować dodatkowe węzły robocze. Węzły replikują swoje bloki systemu plików HDFS do innych węzłów procesu roboczego w trybie online. Następnie usługa HDInsight bezpiecznie skaluje klaster w dół. System plików HDFS przechodzi w tryb awaryjny podczas operacji skalowania. System plików HDFS ma wyjść po zakończeniu skalowania. W niektórych przypadkach system plików HDFS jest jednak zablokowany w trybie awaryjnym podczas operacji skalowania z powodu podciągnięcia bloku plików.
Domyślnie system plików HDFS jest skonfigurowany z ustawieniem dfs.replication 1, które steruje liczbą dostępnych kopii każdego bloku plików. Każda kopia bloku plików jest przechowywana w innym węźle klastra.
Gdy oczekiwana liczba kopii blokowych nie jest dostępna, system plików HDFS przechodzi w tryb awaryjny, a system Ambari generuje alerty. System plików HDFS może wprowadzać tryb awaryjny dla operacji skalowania. Klaster może zostać zablokowany w trybie awaryjnym, jeśli wymagana liczba węzłów nie zostanie wykryta na potrzeby replikacji.
Przykładowe błędy po włączeniu trybu bezpiecznego
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/hive/819c215c-6d87-4311-97c8-4f0b9d2adcf0. Name node is in safe mode.
org.apache.http.conn.HttpHostConnectException: Connect to active-headnode-name.servername.internal.cloudapp.net:10001 [active-headnode-name.servername. internal.cloudapp.net/1.1.1.1] failed: Connection refused
Możesz przejrzeć dzienniki węzłów nazw z /var/log/hadoop/hdfs/ folderu w pobliżu czasu skalowania klastra, aby sprawdzić, kiedy został on wprowadzony w tryb awaryjny. Pliki dziennika mają nazwę Hadoop-hdfs-namenode-<active-headnode-name>.*.
Główną przyczyną było to, że hive zależy od plików tymczasowych w systemie plików HDFS podczas uruchamiania zapytań. Gdy system plików HDFS przechodzi w tryb awaryjny, program Hive nie może uruchamiać zapytań, ponieważ nie może zapisywać w systemie plików HDFS. Pliki tymczasowe w systemie plików HDFS znajdują się na dysku lokalnym zainstalowanym na poszczególnych maszynach wirtualnych węzła roboczego. Pliki są replikowane między innymi węzłami roboczymi w trzech replikach, co najmniej.
Jak zapobiec zablokowaniu usługi HDInsight w trybie awaryjnym
Istnieje kilka sposobów zapobiegania pozostawieniu usługi HDInsight w trybie awaryjnym:
- Zatrzymaj wszystkie zadania hive przed skalowaniem w dół usługi HDInsight. Możesz też zaplanować proces skalowania w dół, aby uniknąć konfliktu z uruchomionymi zadaniami programu Hive.
- Ręcznie wyczyść pliki katalogów tymczasowych
tmpprogramu Hive w systemie plików HDFS przed skalowaniem w dół. - Skalowanie w dół usługi HDInsight do trzech węzłów roboczych, co najmniej. Unikaj przechodzenia tak małej ilości jak jednego węzła roboczego.
- W razie potrzeby uruchom polecenie , aby opuścić tryb awaryjny.
W poniższych sekcjach opisano te opcje.
Zatrzymaj wszystkie zadania hive
Zatrzymaj wszystkie zadania hive przed skalowaniem w dół do jednego węzła roboczego. Jeśli obciążenie jest zaplanowane, wykonaj skalowanie w dół po zakończeniu pracy programu Hive.
Zatrzymanie zadań Hive przed skalowaniem pomaga zminimalizować liczbę plików tymczasowych w folderze tmp (jeśli istnieje).
Ręczne czyszczenie plików tymczasowych programu Hive
Jeśli program Hive pozostawił pliki tymczasowe, możesz ręcznie wyczyścić te pliki przed skalowaniem w dół, aby uniknąć trybu bezpiecznego.
Sprawdź, która lokalizacja jest używana dla plików tymczasowych programu Hive, przeglądając
hive.exec.scratchdirwłaściwość konfiguracji. Ten parametr jest ustawiany w pliku/etc/hive/conf/hive-site.xml:<property> <name>hive.exec.scratchdir</name> <value>hdfs://mycluster/tmp/hive</value> </property>Zatrzymaj usługi Hive i upewnij się, że wszystkie zapytania i zadania zostały ukończone.
Wyświetl listę zawartości katalogu plików tymczasowych znalezionych powyżej, aby sprawdzić,
hdfs://mycluster/tmp/hive/czy zawiera on jakiekolwiek pliki:hadoop fs -ls -R hdfs://mycluster/tmp/hive/hiveOto przykładowe dane wyjściowe, gdy istnieją pliki:
sshuser@scalin:~$ hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/_tmp_space.db -rw-r--r-- 3 hive hdfs 27 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.info -rw-r--r-- 3 hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.lck drwx------ - hive hdfs 0 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699 -rw-r--r-- 3 hive hdfs 26 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699/inuse.infoJeśli wiesz, że program Hive jest wykonywany z tymi plikami, możesz je usunąć. Upewnij się, że usługa Hive nie ma żadnych zapytań uruchomionych, patrząc na stronę interfejsu użytkownika usługi Resource Manager usługi Yarn.
Przykładowy wiersz polecenia do usuwania plików z systemu plików HDFS:
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/
Skalowanie usługi HDInsight do co najmniej trzech węzłów procesu roboczego
Jeśli klastry są często zablokowane w trybie awaryjnym podczas skalowania w dół do mniej niż trzech węzłów roboczych, zachowaj co najmniej trzy węzły robocze.
Posiadanie trzech węzłów roboczych jest bardziej kosztowne niż skalowanie w dół do tylko jednego węzła roboczego. Jednak ta akcja uniemożliwia zablokowanie klastra w trybie awaryjnym.
Skalowanie usługi HDInsight w dół do jednego węzła roboczego
Nawet jeśli klaster jest skalowany w dół do jednego węzła, węzeł roboczy 0 nadal przetrwa. Nie można zlikwidować węzła roboczego 0.
Uruchom polecenie , aby opuścić tryb awaryjny
Ostateczną opcją jest wykonanie polecenia pozostaw tryb awaryjny. Jeśli system plików HDFS wprowadził tryb awaryjny z powodu pod replikacji pliku Hive, wykonaj następujące polecenie, aby opuścić tryb awaryjny:
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -safemode leave
Skalowanie klastra Apache HBase w dół
Serwery regionów są automatycznie zrównoważone w ciągu kilku minut po zakończeniu operacji skalowania. Aby ręcznie zrównoważyć serwery regionów, wykonaj następujące kroki:
Połączenie do klastra usługi HDInsight przy użyciu protokołu SSH. Aby uzyskać więcej informacji, zobacz Używanie protokołu SSH w usłudze HDInsight.
Uruchom powłokę HBase:
hbase shellUżyj następującego polecenia, aby ręcznie zrównoważyć serwery regionów:
balancer
Następne kroki
Aby uzyskać szczegółowe informacje na temat skalowania klastra usługi HDInsight, zobacz: