Samouczek: kompleksowe rozwiązanie korzystające z usługi Azure Machine Learning i IoT Edge
Dotyczy ikony:![]() IoT Edge 1.1
IoT Edge 1.1
Ważne
IoT Edge 1.1 data zakończenia wsparcia wynosiła 13 grudnia 2022 r. Zapoznaj się z cyklem życia produktów firmy Microsoft, aby uzyskać informacje na temat sposobu obsługi tego produktu lub interfejsu API albo tej usługi lub technologii. Aby uzyskać więcej informacji na temat aktualizowania do najnowszej wersji IoT Edge, zobacz Update IoT Edge.
Często aplikacje IoT chcą korzystać z inteligentnej chmury i inteligentnej krawędzi. W tym samouczku przeprowadzimy Cię przez trenowanie modelu uczenia maszynowego przy użyciu danych zebranych z urządzeń IoT w chmurze, wdrażania tego modelu w IoT Edge oraz okresowego utrzymywania i udoskonalania modelu.
Uwaga
Pojęcia w tym zestawie samouczków dotyczą wszystkich wersji IoT Edge, ale przykładowe urządzenie utworzone do wypróbowania scenariusza działa IoT Edge wersji 1.1.
Głównym celem tego samouczka jest wprowadzenie przetwarzania danych IoT przy użyciu uczenia maszynowego, w szczególności na brzegu sieci. Chociaż dotykamy wielu aspektów ogólnego przepływu pracy uczenia maszynowego, ten samouczek nie jest przeznaczony jako szczegółowe wprowadzenie do uczenia maszynowego. W tym przypadku nie próbujemy utworzyć wysoce zoptymalizowanego modelu dla przypadku użycia — wystarczy zilustrować proces tworzenia i używania opłacalnego modelu przetwarzania danych IoT.
W tej sekcji samouczka omówiono następujące zagadnienia:
- Wymagania wstępne dotyczące ukończenia kolejnych części samouczka.
- Docelowi odbiorcy samouczka.
- Przypadek użycia symulowany przez samouczek.
- Ogólny proces samouczka jest następujący, aby spełnić przypadek użycia.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto platformy Azure.
Wymagania wstępne
Aby ukończyć samouczek, musisz mieć dostęp do subskrypcji platformy Azure, w której masz uprawnienia do tworzenia zasobów. Kilka usług używanych w tym samouczku spowoduje naliczanie opłat za platformę Azure. Jeśli nie masz jeszcze subskrypcji platformy Azure, możesz rozpocząć pracę z bezpłatnym kontem platformy Azure.
Potrzebujesz również maszyny z zainstalowanym programem PowerShell, na którym można uruchamiać skrypty, aby skonfigurować maszynę wirtualną platformy Azure jako maszynę dewelopera.
W tym dokumencie używamy następującego zestawu narzędzi:
Centrum Azure IoT na potrzeby przechwytywania danych
Usługa Azure Notebooks jako główny fronton na potrzeby przygotowywania danych i eksperymentowania uczenia maszynowego. Uruchamianie kodu w języku Python w notesie w podzestawie przykładowych danych to doskonały sposób na szybkie iteracyjne i interaktywne przygotowanie danych. Notesy Jupyter mogą również służyć do przygotowywania skryptów do uruchamiania na dużą skalę w zapleczu obliczeniowym.
Usługa Azure Machine Learning jako zaplecze uczenia maszynowego na dużą skalę i generowania obrazów uczenia maszynowego. Prowadzimy zaplecze usługi Azure Machine Learning przy użyciu skryptów przygotowanych i przetestowanych w notesach Jupyter.
Azure IoT Edge dla aplikacji poza chmurą obrazu uczenia maszynowego
Oczywiście dostępne są inne opcje. W niektórych scenariuszach na przykład usługa IoT Central może służyć jako alternatywa bez kodu do przechwytywania początkowych danych treningowych z urządzeń IoT.
Docelowi odbiorcy i role
Ten zestaw artykułów jest przeznaczony dla deweloperów bez wcześniejszego doświadczenia w tworzeniu i uczeniu maszynowym IoT. Wdrażanie uczenia maszynowego na brzegu wymaga znajomości sposobu łączenia szerokiej gamy technologii. W związku z tym w tym samouczku omówiono cały kompletny scenariusz, aby zademonstrować jeden sposób łączenia tych technologii ze sobą na potrzeby rozwiązania IoT. W rzeczywistym środowisku te zadania mogą być dystrybuowane między kilka osób z różnymi specjalizacjami. Na przykład deweloperzy skupiliby się na kodzie urządzenia lub chmury, podczas gdy analitycy danych zaprojektowali modele analityczne. Aby umożliwić poszczególnym deweloperom pomyślne ukończenie tego samouczka, udostępniliśmy dodatkowe wskazówki ze szczegółowymi informacjami i linkiem do dodatkowych informacji, które mamy nadzieję, wystarczy zrozumieć, co jest wykonywane, a także dlaczego.
Alternatywnie możesz współpracować z współpracownikami różnych ról, aby wspólnie wykonać samouczek, łącząc pełną wiedzę i ucząc się jako zespół, jak rzeczy pasują do siebie.
W obu przypadkach, aby ułatwić orientację czytelników, każdy artykuł w tym samouczku wskazuje rolę użytkownika. Te role obejmują:
- Programowanie w chmurze (w tym deweloper chmury pracujący w pojemności DevOps)
- Analiza danych
Przypadek użycia: Konserwacja predykcyjna
W tym scenariuszu przedstawiono przypadek użycia przedstawiony na konferencji prognostycznej i zarządzania zdrowiem (PHM08) w 2008 roku. Celem jest przewidywanie pozostałego okresu eksploatacji (RUL) zestawu silników samolotowych turbofan. Te dane zostały wygenerowane przy użyciu C-MAPSS, komercyjnej wersji oprogramowania MAPSS (Modular Aero-Propulsion System Simulation). To oprogramowanie zapewnia elastyczne środowisko symulacji silnika turbofanowego, aby wygodnie symulować parametry kondycji, sterowania i silnika.
Dane używane w tym samouczku pochodzą z zestawu danych symulacji degradacji silnika Turbofan.
Z pliku readme:
Scenariusz eksperymentalny
Zestawy danych składają się z wielu wielowariancji szeregów czasowych. Każdy zestaw danych jest dalej podzielony na podzestawy trenowania i testowania. Każda seria czasowa pochodzi z innego silnika — tj. dane można uznać za pochodzące z floty silników tego samego typu. Każdy silnik zaczyna się od różnych stopni początkowego zużycia i odmiany produkcyjnej, która jest nieznana użytkownikowi. To zużycie i odmiana są uważane za normalne, tj. nie jest uważane za stan błędu. Istnieją trzy ustawienia operacyjne, które mają znaczący wpływ na wydajność aparatu. Te ustawienia są również uwzględniane w danych. Dane są zanieczyszczone szumem czujnika.
Silnik działa normalnie na początku każdej serii czasowej i rozwija usterkę w pewnym momencie podczas serii. W zestawie treningowym błąd rośnie o skalę do czasu awarii systemu. W zestawie testowym szereg czasowy kończy się jakiś czas przed awarią systemu. Celem konkurencji jest przewidywanie liczby pozostałych cykli operacyjnych przed awarią w zestawie testowym, tj. liczba cykli operacyjnych po ostatnim cyklu, że silnik będzie nadal działać. Podano również wektor wartości true Remaining Useful Life (RUL) dla danych testowych.
Ponieważ dane zostały opublikowane w konkursie, kilka podejść do tworzenia modeli uczenia maszynowego zostało opublikowanych niezależnie. Odkryliśmy, że badanie przykładów jest pomocne w zrozumieniu procesu i rozumowania związanego z tworzeniem określonego modelu uczenia maszynowego. Zobacz na przykład:
Model przewidywania awarii silnika samolotu przez użytkownika usługi GitHub jancervenka.
Degradacja silnika turbofan przez użytkownika github hankroark.
Proces
Na poniższej ilustracji przedstawiono przybliżone kroki wykonywane w tym samouczku:
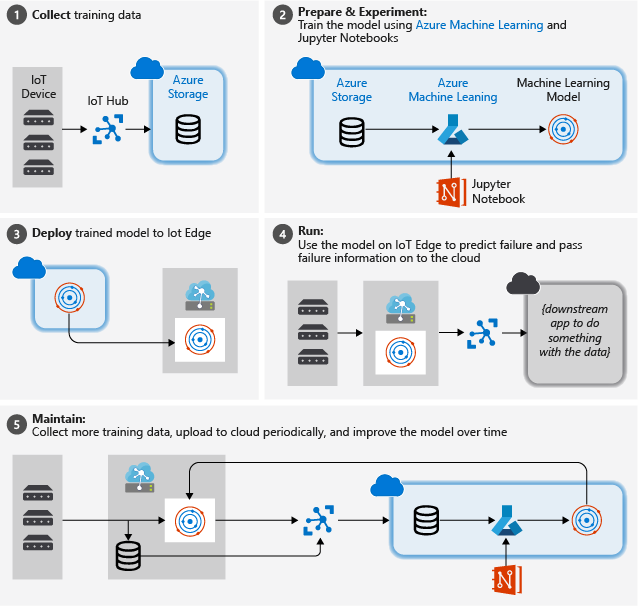
Zbieranie danych szkoleniowych: proces rozpoczyna się od zbierania danych treningowych. W niektórych przypadkach dane zostały już zebrane i są dostępne w bazie danych lub w postaci plików danych. W innych przypadkach, szczególnie w przypadku scenariuszy IoT, dane muszą być zbierane z urządzeń IoT i czujników oraz przechowywanych w chmurze.
Zakładamy, że nie masz kolekcji silników turbofanowych, więc pliki projektu zawierają prosty symulator urządzenia, który wysyła dane urządzenia NASA do chmury.
Przygotowywanie danych. W większości przypadków dane pierwotne zebrane z urządzeń i czujników będą wymagały przygotowania do uczenia maszynowego. Ten krok może obejmować czyszczenie danych, ponowne formatowanie danych lub wstępne przetwarzanie w celu wstrzyknięcia dodatkowych informacji uczenia maszynowego może być wyłączone.
W przypadku danych maszyny lotniczej przygotowanie danych obejmuje obliczanie jawnych czasów awarii dla każdego punktu danych w próbce na podstawie rzeczywistych obserwacji danych dotyczących danych. Te informacje umożliwiają algorytmowi uczenia maszynowego znajdowanie korelacji między rzeczywistymi wzorcami danych czujnika a oczekiwanym pozostałym czasem życia aparatu. Ten krok jest bardzo specyficzny dla domeny.
Tworzenie modelu uczenia maszynowego. Na podstawie przygotowanych danych możemy teraz eksperymentować z różnymi algorytmami uczenia maszynowego i parametryzacji w celu trenowania modeli i porównywania wyników ze sobą.
W tym przypadku na potrzeby testowania porównujemy przewidywany wynik obliczony przez model z rzeczywistym wynikiem obserwowanym na zestawie aparatów. W usłudze Azure Machine Learning możemy zarządzać różnymi iteracji modeli tworzonych w rejestrze modeli.
Wdrażanie modelu. Gdy mamy model spełniający nasze kryteria sukcesu, możemy przejść do wdrożenia. Obejmuje to zawijanie modelu do aplikacji usługi internetowej, która może być karmiona danymi przy użyciu wywołań REST i zwracania wyników analizy. Następnie aplikacja usługi internetowej jest pakowana do kontenera platformy Docker, który z kolei można wdrożyć w chmurze lub jako moduł IoT Edge. W tym przykładzie koncentrujemy się na wdrażaniu w celu IoT Edge.
Zachowaj i uściślij model. Nasza praca nie jest wykonywana po wdrożeniu modelu. W wielu przypadkach chcemy kontynuować zbieranie danych i okresowo przekazywać te dane do chmury. Następnie możemy użyć tych danych do ponownego trenowania i uściślinia naszego modelu, który następnie możemy ponownie wdrożyć, aby IoT Edge.
Czyszczenie zasobów
Ten samouczek jest częścią zestawu, w którym każdy artykuł opiera się na pracy wykonanej w poprzednich. Poczekaj, aż ukończysz ostatni samouczek, zaczekaj na oczyszczenie wszystkich zasobów.
Następne kroki
Ten samouczek jest podzielony na następujące sekcje:
- Konfigurowanie maszyny deweloperskich i usług platformy Azure.
- Wygeneruj dane szkoleniowe dla modułu uczenia maszynowego.
- Trenowanie i wdrażanie modułu uczenia maszynowego.
- Skonfiguruj urządzenie IoT Edge do działania jako przezroczysta brama.
- Twórca i wdrażanie modułów IoT Edge.
- Wysyłanie danych do urządzenia IoT Edge.
Przejdź do następnego artykułu, aby skonfigurować maszynę deweloperów i aprowizować zasoby platformy Azure.