Konfigurowanie laboratorium na potrzeby analizy danych big data w usłudze Azure Lab Services przy użyciu wdrożenia platformy Danych HortonWorks
Uwaga
Ten artykuł odwołuje się do funkcji dostępnych w planach laboratorium, które zastąpiły konta laboratorium.
W tym artykule pokazano, jak skonfigurować laboratorium do uczenia klasy analizy danych big data. Klasa analizy danych big data uczy użytkowników, jak obsługiwać duże ilości danych. Uczy ich również stosowania algorytmów uczenia maszynowego i statystycznego w celu uzyskania szczegółowych informacji o danych. Kluczowym celem jest poznanie sposobu używania narzędzi do analizy danych, takich jak pakiet oprogramowania open source platformy Apache Hadoop. Pakiet oprogramowania udostępnia narzędzia do przechowywania i przetwarzania danych big data oraz zarządzania nimi.
W tym laboratorium użytkownicy laboratorium pracują z popularną komercyjną wersją platformy Hadoop dostarczaną przez usługę Cloudera o nazwie Hortonworks Data Platform (HDP). W szczególności użytkownicy laboratorium używają piaskownicy HDP 3.0.1 , która jest uproszczoną, łatwą w użyciu wersją platformy. Piaskownica HDP 3.0.1 jest również bezpłatna i jest przeznaczona do nauki i eksperymentowania. Mimo że ta klasa może używać maszyn wirtualnych z systemem Windows lub Linux z wdrożonym piaskownicą usługi HDP. W tym artykule pokazano, jak używać systemu Windows.
Innym interesującym aspektem jest wdrożenie piaskownicy usługi HDP na maszynach wirtualnych laboratorium przy użyciu kontenerów platformy Docker . Każdy kontener platformy Docker udostępnia własne izolowane środowisko, w przypadku których aplikacje są uruchamiane wewnątrz. Koncepcyjnie kontenery platformy Docker są podobne do zagnieżdżonych maszyn wirtualnych i mogą służyć do łatwego wdrażania i uruchamiania wielu aplikacji oprogramowania opartych na obrazach kontenerów udostępnianych w usłudze Docker Hub. Skrypt wdrażania cloudera dla piaskownicy usługi HDP automatycznie ściąga obraz platformy Docker piaskownicy HDP 3.0.1 z usługi Docker Hub i uruchamia dwa kontenery platformy Docker:
- piaskownica —hdp
- serwer proxy piaskownicy
Wymagania wstępne
Aby skonfigurować to laboratorium, musisz mieć dostęp do subskrypcji platformy Azure. Porozmawiaj z administratorem organizacji, aby sprawdzić, czy możesz uzyskać dostęp do istniejącej subskrypcji platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Konfiguracja laboratorium
Ustawienia planu laboratorium
Po utworzeniu subskrypcji platformy Azure możesz utworzyć plan laboratorium w usłudze Azure Lab Services. Aby uzyskać więcej informacji na temat tworzenia nowego planu laboratorium, zobacz Szybki start: konfigurowanie zasobów w celu tworzenia laboratoriów. Możesz również użyć istniejącego planu laboratorium.
To laboratorium używa obrazów witryny Azure Marketplace systemu Windows 10 Pro jako podstawowego obrazu maszyny wirtualnej. Najpierw należy włączyć ten obraz w planie laboratorium. Umożliwia to twórcom laboratorium wybranie obrazu jako obrazu podstawowego dla laboratorium.
Wykonaj następujące kroki, aby włączyć te obrazy witryny Azure Marketplace dostępne dla twórców laboratorium. Wybierz jeden z obrazów witryny Azure Marketplace systemu Windows 10 .
Ustawienia laboratorium
Utwórz laboratorium dla planu laboratorium. Aby uzyskać instrukcje dotyczące tworzenia laboratorium, zobacz Samouczek: konfigurowanie laboratorium. Podczas tworzenia laboratorium użyj następujących ustawień.
| Ustawienia laboratorium | Wartość/instrukcje |
|---|---|
| Rozmiar maszyny wirtualnej | Średnia (wirtualizacja zagnieżdżona). Ten rozmiar maszyny wirtualnej najlepiej nadaje się do relacyjnych baz danych, buforowania w pamięci i analizy. Rozmiar obsługuje również wirtualizację zagnieżdżonych. |
| Obraz maszyny wirtualnej | Windows 10 Pro |
Uwaga
Użyj rozmiaru maszyny wirtualnej średniej (wirtualizacji zagnieżdżonej), ponieważ piaskownica usługi HDP korzystająca z platformy Docker wymaga funkcji Hyper-V systemu Windows z wirtualizacją zagnieżdżonych i co najmniej 10 GB pamięci RAM.
Konfiguracja maszyny szablonu
Aby skonfigurować maszynę szablonu:
- Zainstaluj platformę Docker
- Wdrażanie piaskownicy usługi HDP
- Automatyczne uruchamianie kontenerów platformy Docker przy użyciu programu PowerShell i harmonogramu zadań systemu Windows
Zainstaluj platformę Docker
Kroki opisane w tej sekcji są oparte na instrukcjach usługi Cloudera dotyczących wdrażania za pomocą kontenerów platformy Docker.
Aby korzystać z kontenerów platformy Docker, należy najpierw zainstalować program Docker Desktop na maszynie wirtualnej szablonu:
Wykonaj kroki opisane w sekcji Wymagania wstępne, aby zainstalować platformę Docker dla systemu Windows.
Ważne
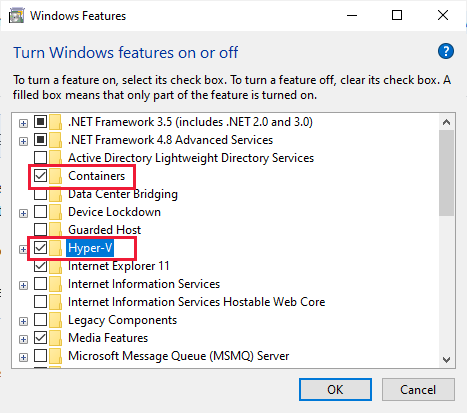
Upewnij się, że opcja Użyj kontenerów systemu Windows zamiast kontenerów systemu Linux nie jest zaznaczona.
Upewnij się, że włączono funkcje Windows Containers i Hyper-V.
Wykonaj kroki opisane w sekcji Pamięć dla systemu Windows , aby skonfigurować konfigurację pamięci platformy Docker.
Ostrzeżenie
Jeśli przypadkowo sprawdzisz opcję Użyj kontenerów systemu Windows zamiast kontenerów systemu Linux podczas instalowania platformy Docker, ustawienia konfiguracji pamięci nie będą widoczne. Aby rozwiązać ten problem, możesz przełączyć się na używanie kontenerów systemu Linux, klikając ikonę Platformy Docker na pasku zadań systemu Windows. Po otwarciu menu pulpitu platformy Docker wybierz pozycję Przełącz do kontenerów systemu Linux.
Wdrażanie piaskownicy usługi HDP
Następnie wdróż piaskownicę usługi HDP, a następnie uzyskaj dostęp do piaskownicy usługi HDP przy użyciu przeglądarki.
Upewnij się, że zainstalowano powłokę Git Bash zgodnie z opisem w sekcji Wymagania wstępne przewodnika. Zaleca się wykonanie następnych kroków.
Korzystając z przewodnika wdrażania i instalowania usługi Cloudera dla platformy Docker, wykonaj kroki opisane w następujących sekcjach:
- Wdrażanie piaskownicy usługi HDP
- Weryfikowanie piaskownicy usługi HDP
Ostrzeżenie
Po pobraniu najnowszego pliku .zip dla usługi HDP upewnij się, że nie zapisujesz pliku .zip w ścieżce katalogu zawierającej białe znaki.
Uwaga
Jeśli podczas wdrażania wystąpi wyjątek informujący , że dysk nie został udostępniony, musisz udostępnić dysk C do platformy Docker, aby kontenery systemu Linux usługi HDP mogły uzyskiwać dostęp do lokalnych plików systemu Windows. Aby rozwiązać ten problem, kliknij ikonę platformy Docker na pasku zadań systemu Windows, aby otworzyć menu pulpitu platformy Docker i wybrać Ustawienia. Po otwarciu okna dialogowego Ustawienia platformy Docker wybierz pozycję Udostępnianie plików zasobów > i sprawdź dysk C. Następnie możesz powtórzyć kroki wdrażania piaskownicy usługi HDP.
Po wdrożeniu i uruchomieniu kontenerów platformy Docker dla piaskownicy usługi HDP możesz uzyskać dostęp do środowiska, uruchamiając przeglądarkę. Postępuj zgodnie z instrukcjami usługi Cloudera dotyczącymi otwierania strony powitalnej piaskownicy i uruchamiania pulpitu nawigacyjnego usługi HDP.
Uwaga
W tych instrukcjach założono, że najpierw zamapowaliśmy lokalny adres IP środowiska piaskownicy na sandbox-hdp.hortonworks.com w pliku hosta na maszynie wirtualnej szablonu. Jeśli to mapowanie nie zostanie utworzone, możesz uzyskać dostęp do strony Powitalnej piaskownicy, przechodząc do
http://localhost:8080strony .
Automatyczne uruchamianie kontenerów platformy Docker podczas logowania użytkowników laboratorium
Aby zapewnić łatwe w użyciu środowisko dla użytkowników laboratorium, utwórz skrypt programu PowerShell, który automatycznie:
- Uruchamia kontenery platformy Docker piaskownicy usługi HDP po uruchomieniu i nawiązaniu połączenia z maszyną wirtualną laboratorium przez użytkownika laboratorium.
- Uruchamia przeglądarkę i przechodzi do strony powitalnej piaskownicy.
Użyj harmonogramu zadań systemu Windows, aby automatycznie uruchomić ten skrypt, gdy użytkownik laboratorium zaloguje się do swojej maszyny wirtualnej. Aby skonfigurować harmonogram zadań, wykonaj następujące kroki: wykonywanie skryptów analizy danych big data.
Szacowany koszt
Ta sekcja zawiera oszacowanie kosztów uruchamiania tej klasy dla 25 użytkowników laboratorium. Zaplanowany czas zajęć to 20 godzin. Ponadto każdy użytkownik otrzymuje limit przydziału 10 godzin dla pracy domowej lub przydziałów poza zaplanowanym czasem zajęć. Wybrany rozmiar maszyny wirtualnej to Średni (wirtualizacja zagnieżdżona), czyli 55 jednostek laboratorium.
- 25 użytkowników laboratorium × (20 zaplanowanych godzin + 10 godzin przydziału) × 55 jednostek laboratorium
Ważne
Oszacowanie kosztów jest przeznaczone tylko do celów przykładowych. Aby uzyskać bieżące informacje o cenach, zobacz Cennik usług Azure Lab Services.
Podsumowanie
W tym artykule przedstawiono kroki niezbędne do utworzenia laboratorium dla klasy analizy danych big data. Klasa analizy danych big data używa platformy Hortonworks Data Platform wdrożonej za pomocą platformy Docker. Konfiguracja dla tego typu klasy może być używana dla podobnych klas analizy danych. Ta konfiguracja może być również stosowana do innych typów klas, które używają platformy Docker do wdrożenia.
Następne kroki
Obraz szablonu można teraz opublikować w laboratorium. Aby uzyskać więcej informacji, zobacz Publikowanie maszyny wirtualnej szablonu.
Podczas konfigurowania laboratorium zapoznaj się z następującymi artykułami:
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla