Grupowanie danych w składnik Pojemniki
W tym artykule opisano sposób użycia składnika Grupowanie danych do pojemników w projektancie usługi Azure Machine Learning w celu grupowania liczb lub zmieniania rozkładu ciągłych danych.
Składnik Grupuj dane w pojemniki obsługuje wiele opcji kwantowania danych. Możesz dostosować sposób ustawiania krawędzi pojemnika i sposobu, w jaki wartości są rozdzielane do pojemników. Można na przykład:
- Ręcznie wpisz serię wartości, które mają służyć jako granice pojemnika.
- Przypisz wartości do pojemników przy użyciu kwantyli lub rang percentylu.
- Wymuś równomierny rozkład wartości w pojemnikach.
Więcej informacji na temat kwantowania i grupowania
Kwantowanie lub grupowanie danych (czasami nazywanych kwantyzacją) to ważne narzędzie do przygotowywania danych liczbowych do uczenia maszynowego. Jest to przydatne w takich scenariuszach:
Kolumna liczb ciągłych zawiera zbyt wiele unikatowych wartości do efektywnego modelowania. Dlatego automatycznie lub ręcznie przypiszesz wartości do grup, aby utworzyć mniejszy zestaw zakresów dyskretnych.
Chcesz zastąpić kolumnę liczb wartościami kategorialnymi reprezentującymi określone zakresy.
Na przykład możesz pogrupować wartości w kolumnie wiekowej, określając niestandardowe zakresy, takie jak 1-15, 16-22, 23-30 itd. dla danych demograficznych użytkowników.
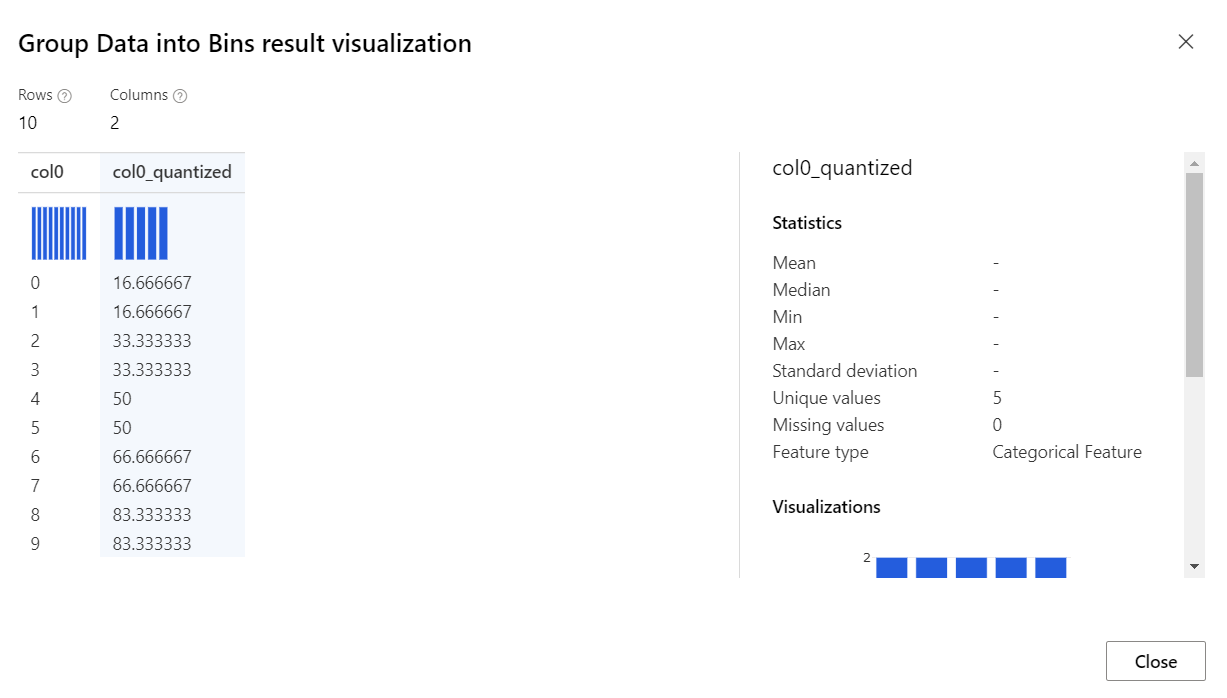
Zestaw danych ma kilka skrajnych wartości, wszystkie spoza oczekiwanego zakresu, a te wartości mają wpływ na wytrenowany model. Aby wyeliminować odchylenie w modelu, możesz przekształcić dane w jednolity rozkład przy użyciu metody quantiles.
W przypadku tej metody składnik Grupuj dane w pojemniki określa idealne lokalizacje pojemnika i szerokość pojemnika, aby upewnić się, że w przybliżeniu ta sama liczba próbek mieści się w każdym pojemniku. Następnie, w zależności od wybranej metody normalizacji, wartości w pojemnikach są przekształcane na percentyle lub mapowane na liczbę pojemników.
Przykłady kwantowania
Na poniższym diagramie przedstawiono rozkład wartości liczbowych przed i po kwantyle metodą kwantyli . Zwróć uwagę, że w porównaniu z nieprzetworzonymi danymi po lewej stronie dane zostały odsuwane i przekształcane w skalę normalną.
Ponieważ istnieje tak wiele sposobów grupowania danych, wszystkie możliwe do dostosowania zalecamy eksperymentowanie z różnymi metodami i wartościami.
Jak skonfigurować grupowanie danych w pojemnikach
Dodaj składnik Grupuj dane do pojemników do potoku w projektancie. Ten składnik można znaleźć w kategorii Przekształcanie danych.
Połącz zestaw danych zawierający dane liczbowe z pojemnikiem. Kwantyzacja może być stosowana tylko do kolumn zawierających dane liczbowe.
Jeśli zestaw danych zawiera kolumny nieliczbowe, użyj składnika Select Columns in Dataset (Wybieranie kolumn w zestawie danych ), aby wybrać podzbiór kolumn do pracy.
Określ tryb kwantowania. Tryb kwantowania określa inne parametry, dlatego najpierw wybierz opcję Tryb kwantowania . Obsługiwane są następujące typy kwantowania:
Quantiles: metoda kwantylu przypisuje wartości do pojemników na podstawie klasyfikacji percentylu. Ta metoda jest również znana jako kwantowanie o równej wysokości.
Równa szerokość: w przypadku tej opcji należy określić łączną liczbę pojemników. Wartości z kolumny danych są umieszczane w pojemnikach, tak aby każdy przedział miał ten sam interwał między wartościami początkowymi i końcowymi. W związku z tym niektóre pojemniki mogą mieć więcej wartości, jeśli dane są zrzucane wokół określonego punktu.
Niestandardowe krawędzie: możesz określić wartości, które zaczynają się od każdego pojemnika. Wartość krawędzi jest zawsze dolną granicą pojemnika.
Załóżmy na przykład, że chcesz zgrupować wartości w dwa pojemniki. Jedna z nich będzie mieć wartości większe niż 0, a jedna z nich będzie mieć wartości mniejsze lub równe 0. W tym przypadku w przypadku krawędzi pojemnika należy wprowadzić wartość 0 na liście krawędzi pojemnika rozdzielanych przecinkami. Dane wyjściowe składnika będą mieć wartość 1 i 2, co wskazuje indeks bin dla każdej wartości wiersza. Należy pamiętać, że lista wartości rozdzielonych przecinkami musi znajdować się w kolejności rosnącej, takiej jak 1, 3, 5, 7.
Uwaga
Tryb Entropy MDL jest zdefiniowany w programie Studio (klasycznym) i nie ma odpowiedniego pakietu open source, który można jeszcze wykorzystać do obsługi w projektancie.
Jeśli używasz trybów kwantyli i kwantyluo równej szerokości , użyj opcji Liczba pojemników , aby określić liczbę pojemników lub kwantyli, które chcesz utworzyć.
W obszarze Kolumny do pojemnika użyj selektora kolumn, aby wybrać kolumny, które mają wartości, które chcesz binować. Kolumny muszą być numerycznym typem danych.
Ta sama reguła kwantowania jest stosowana do wszystkich odpowiednich kolumn, które wybierzesz. Jeśli musisz podzielić niektóre kolumny przy użyciu innej metody, użyj oddzielnego wystąpienia składnika Grupuj dane do pojemników dla każdego zestawu kolumn.
Ostrzeżenie
Jeśli wybierzesz kolumnę, która nie jest dozwolonym typem, zostanie wygenerowany błąd środowiska uruchomieniowego. Składnik zwraca błąd, gdy tylko znajdzie dowolną kolumnę niedozwolonego typu. Jeśli wystąpi błąd, przejrzyj wszystkie wybrane kolumny. Błąd nie zawiera listy wszystkich nieprawidłowych kolumn.
W obszarze Tryb danych wyjściowych wskaż sposób wyprowadzania kwantyzowanych wartości:
Dołącz: tworzy nową kolumnę z wartościami binned i dołącza je do tabeli wejściowej.
Miejsce: zastępuje oryginalne wartości nowymi wartościami w zestawie danych.
ResultOnly: zwraca tylko kolumny wyników.
Jeśli wybierzesz tryb kwantylu kwantyli , użyj opcji Normalizacja kwantylu , aby określić, jak wartości są znormalizowane przed sortowaniem w kwantyle. Należy pamiętać, że normalizacja wartości przekształca wartości, ale nie ma wpływu na ostateczną liczbę pojemników.
Obsługiwane są następujące typy normalizacji:
Procent: wartości są znormalizowane w zakresie [0,100].
PQuantile: Wartości są znormalizowane w zakresie [0,1].
QuantileIndex: wartości są znormalizowane w zakresie [1,liczba pojemników].
Jeśli wybierzesz opcję Niestandardowe krawędzie , wprowadź rozdzielaną przecinkami listę liczb do użycia jako krawędzie pojemnika w polu tekstowym Rozdzielane przecinkami krawędzie pojemnika .
Wartości oznaczają punkt dzielący pojemniki. Jeśli na przykład wprowadzisz jedną wartość krawędzi pojemnika, zostaną wygenerowane dwa pojemniki. Jeśli wprowadzisz dwie wartości krawędzi pojemnika, zostaną wygenerowane trzy pojemniki.
Wartości muszą być sortowane w kolejności, w jakiej są tworzone pojemniki, od najniższego do najwyższego.
Wybierz opcję Oznacz kolumny jako kategorialne , aby wskazać, że kwantyzowane kolumny powinny być obsługiwane jako zmienne kategorii.
Prześlij potok.
Wyniki
Składnik Grupuj dane do pojemników zwraca zestaw danych, w którym każdy element został z binowany zgodnie z określonym trybem.
Zwraca również transformację kwantowania. Tę funkcję można przekazać do składnika Zastosuj transformację , aby binować nowe próbki danych przy użyciu tego samego trybu i parametrów kwantowania.
Porada
Jeśli używasz kwantowania danych treningowych, musisz użyć tej samej metody kwantowania dla danych używanych do testowania i przewidywania. Należy również użyć tych samych lokalizacji pojemnika i szerokości pojemnika.
Aby zapewnić, że dane są zawsze przekształcane przy użyciu tej samej metody kwantowania, zalecamy zapisanie przydatnych przekształceń danych. Następnie zastosuj je do innych zestawów danych przy użyciu składnika Zastosuj przekształcenie .
Następne kroki
Zobacz zestaw składników dostępnych dla usługi Azure Machine Learning.