Importowanie danych szkoleniowych do usługi Machine Learning Studio (klasycznej) z różnych źródeł danych
DOTYCZY:Dotyczy Usługa Machine Learning Studio (klasyczna)
Usługa Machine Learning Studio (klasyczna)  Azure Machine Learning
Azure Machine Learning
Ważne
Obsługa programu Machine Learning Studio (wersja klasyczna) zakończy się 31 sierpnia 2024 r. Zalecamy przejście do usługi Azure Machine Learning przed tym terminem.
Od 1 grudnia 2021 r. nie będzie można tworzyć nowych zasobów programu Machine Learning Studio (wersja klasyczna). Do 31 sierpnia 2024 r. można będzie nadal korzystać z istniejących zasobów programu Machine Learning Studio (wersja klasyczna).
- Zobacz informacje dotyczące przenoszenia projektów uczenia maszynowego z usługi ML Studio (klasycznej) do usługi Azure Machine Learning.
- Dowiedz się więcej o usłudze Azure Machine Learning
Dokumentacja programu ML Studio (wersja klasyczna) jest wycofywana i może nie być aktualizowana w przyszłości.
Aby użyć własnych danych w usłudze Machine Learning Studio (wersja klasyczna) do tworzenia i trenowania rozwiązania analizy predykcyjnej, możesz użyć danych z:
- Plik lokalny — załaduj dane lokalne przed upływem czasu z dysku twardego, aby utworzyć moduł zestawu danych w obszarze roboczym
- Źródła danych online — użyj modułu Importuj dane , aby uzyskać dostęp do danych z jednego z kilku źródeł online podczas wykonywania eksperymentu
- Eksperyment usługi Machine Learning Studio (klasyczny) — używanie danych zapisanych jako zestaw danych w usłudze Machine Learning Studio (wersja klasyczna)
- SQL Server bazy danych — używanie danych z bazy danych SQL Server bez konieczności ręcznego kopiowania danych
Uwaga
W usłudze Machine Learning Studio (klasycznym) dostępnych jest wiele przykładowych zestawów danych, których można użyć do trenowania danych. Aby uzyskać informacje na ten temat, zobacz Korzystanie z przykładowych zestawów danych w usłudze Machine Learning Studio (wersja klasyczna).
Przygotowywanie danych
Usługa Machine Learning Studio (klasyczna) jest przeznaczona do pracy z danymi prostokątnymi lub tabelarycznymi, takimi jak dane tekstowe rozdzielane lub ustrukturyzowane z bazy danych, chociaż w niektórych okolicznościach mogą być używane dane niekątne.
Najlepiej jest, jeśli dane są stosunkowo czyste przed zaimportowanie ich do programu Studio (wersja klasyczna). Na przykład należy dbać o problemy, takie jak ciągi niekwestionowane.
Istnieją jednak moduły dostępne w programie Studio (klasycznym), które umożliwiają manipulowanie danymi w eksperymencie po zaimportowaniu danych. W zależności od używanych algorytmów uczenia maszynowego może być konieczne podjęcie decyzji o sposobie obsługi problemów strukturalnych danych, takich jak brakujące wartości i rozrzednione dane, a także istnieją moduły, które mogą z tym pomóc. Zapoznaj się z sekcją Przekształcanie danych palety modułów dla modułów, które wykonują te funkcje.
W dowolnym momencie eksperymentu możesz wyświetlić lub pobrać dane utworzone przez moduł, klikając port wyjściowy. W zależności od modułu mogą istnieć różne opcje pobierania lub wizualizacja danych w przeglądarce internetowej w programie Studio (wersja klasyczna).
Obsługiwane formaty danych i typy danych
Do eksperymentu można zaimportować wiele typów danych, w zależności od mechanizmu używanego do importowania danych i lokalizacji, z której pochodzą:
- Zwykły tekst (.txt)
- Wartości rozdzielane przecinkami (CSV) z nagłówkiem (.csv) lub bez (.nh.csv)
- Wartości rozdzielane tabulatorami (TSV) z nagłówkiem (tsv) lub bez (.nh.tsv)
- Plik programu Excel
- Tabela platformy Azure
- Tabela Hive
- Tabela bazy danych SQL
- Wartości OData
- SvMLight data (svmlight) (zobacz definicję SVMLight , aby uzyskać informacje o formacie)
- Dane formatu pliku relacyjnej atrybutu (ARFF) (zobacz definicję ARFF , aby uzyskać informacje o formacie)
- Plik zip (.zip)
- Plik obiektu lub obszaru roboczego języka R (. RData)
W przypadku importowania danych w formacie, takim jak ARFF, który zawiera metadane, program Studio (klasyczny) używa tych metadanych do zdefiniowania nagłówka i typu danych każdej kolumny.
Jeśli importujesz dane, takie jak TSV lub FORMAT CSV, które nie zawierają tych metadanych, program Studio (klasyczny) wywnioskuje typ danych dla każdej kolumny, próbkując dane. Jeśli dane również nie mają nagłówków kolumn, program Studio (wersja klasyczna) udostępnia nazwy domyślne.
Można jawnie określić lub zmienić nagłówki i typy danych dla kolumn przy użyciu modułu Edytuj metadane .
Następujące typy danych są rozpoznawane przez program Studio (klasyczny):
- Ciąg
- Liczba całkowita
- Double
- Boolean (wartość logiczna)
- Data/godzina
- przedział_czasu
Program Studio używa wewnętrznego typu danych nazywanego tabelą danych do przekazywania danych między modułami. Dane można jawnie przekonwertować na format tabeli danych przy użyciu modułu Konwertuj na zestaw danych .
Każdy moduł, który akceptuje formaty inne niż tabela danych, przekonwertuje dane na tabelę danych w trybie dyskretnym przed przekazaniem go do następnego modułu.
W razie potrzeby możesz przekonwertować format tabeli danych z powrotem na format CSV, TSV, ARFF lub SVMLight przy użyciu innych modułów konwersji. Zapoznaj się z sekcją Konwersje formatu danych palety modułów dla modułów wykonujących te funkcje.
Pojemności danych
Moduły w usłudze Machine Learning Studio (wersja klasyczna) obsługują zestawy danych z maksymalnie 10 GB gęstych danych liczbowych dla typowych przypadków użycia. Jeśli moduł przyjmuje więcej niż jedną operację wprowadzania danych wejściowych, wówczas 10 GB to łączny rozmiar wszystkich danych wejściowych. Większe zestawy danych można próbkować przy użyciu zapytań z programu Hive lub bazy danych Azure SQL lub użyć usługi Learning by Counts preprocess przed zaimportowaniem danych.
Podczas normalizacji funkcji następujące typy danych mogą ulegać rozszerzaniu do większych zestawów danych. Takie dane muszą być mniejsze niż 10 GB:
- Rozrzedzone
- Podzielone na kategorie
- Ciągi
- Dane binarne
W przypadku następujących modułów obowiązuje ograniczenie do zestawów danych mniejszych niż 10 GB:
- Moduły polecania
- Moduł Synthetic Minority Oversampling Technique (SMOTE)
- Moduły skryptów: R, Python, SQL
- Moduły, w których rozmiar danych wyjściowych może być większy niż rozmiar danych wejściowych, na przykład Przyłączenie lub Tworzenie skrótu funkcji
- Krzyżowa weryfikacja, Hiperparametry modelu strojenia, Regresja porządkowa oraz Multiklasa Jedna kontra wszystkie, gdy liczba iteracji jest bardzo duża
W przypadku zestawów danych, które są większe niż kilka baz danych, przekaż dane do usługi Azure Storage lub Azure SQL Database lub użyj usługi Azure HDInsight, a nie przekaż bezpośrednio z pliku lokalnego.
Informacje o danych obrazów można znaleźć w dokumentacji modułu Importowanie obrazów .
Importowanie z pliku lokalnego
Plik danych można przekazać z dysku twardego do użycia jako dane treningowe w programie Studio (klasycznym). Podczas importowania pliku danych utworzysz moduł zestawu danych gotowy do użycia w eksperymentach w obszarze roboczym.
Aby zaimportować dane z lokalnego dysku twardego, wykonaj następujące czynności:
- Kliknij pozycję +NOWY w dolnej części okna Studio (wersja klasyczna).
- Wybierz pozycję ZESTAW DANYCH i Z PLIKU LOKALNEGO.
- W oknie dialogowym Przekazywanie nowego zestawu danych przejdź do pliku, który chcesz przekazać.
- Wprowadź nazwę, zidentyfikuj typ danych i opcjonalnie wprowadź opis. Zalecany jest opis — umożliwia zarejestrowanie wszelkich cech dotyczących danych, które mają być zapamiętane podczas korzystania z danych w przyszłości.
- Pole wyboru Ta nowa wersja istniejącego zestawu danych umożliwia zaktualizowanie istniejącego zestawu danych przy użyciu nowych danych. Aby to zrobić, kliknij to pole wyboru, a następnie wprowadź nazwę istniejącego zestawu danych.
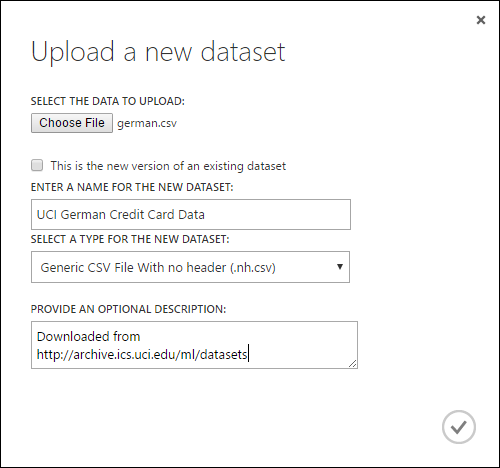
Czas przekazywania zależy od rozmiaru danych i szybkości połączenia z usługą. Jeśli wiesz, że plik zajmie dużo czasu, możesz wykonać inne czynności w programie Studio (klasycznym) podczas oczekiwania. Jednak zamknięcie przeglądarki przed zakończeniem przekazywania danych powoduje niepowodzenie przekazywania.
Po przekazaniu danych są przechowywane w module zestawu danych i są dostępne dla każdego eksperymentu w obszarze roboczym.
Podczas edytowania eksperymentu możesz znaleźć zestawy danych przekazane na liście Moje zestawy danych na liście Zapisane zestawy danych na palecie modułów. Możesz przeciągać i upuszczać zestaw danych na kanwę eksperymentu, gdy chcesz użyć zestawu danych do dalszej analizy i uczenia maszynowego.
Importowanie ze źródeł danych online
Korzystając z modułu Import Data (Importowanie danych ), eksperyment może importować dane z różnych źródeł danych online podczas wykonywania eksperymentu.
Uwaga
Ten artykuł zawiera ogólne informacje na temat modułu Import Data (Importowanie danych ). Aby uzyskać bardziej szczegółowe informacje na temat typów danych, do których można uzyskać dostęp, formaty, parametry i odpowiedzi na typowe pytania, zobacz temat referencyjny modułu dla modułu Import Data (Importowanie danych ).
Za pomocą modułu Import Data (Importowanie danych ) możesz uzyskać dostęp do danych z jednego z kilku źródeł danych online, gdy eksperyment jest uruchomiony:
- Adres URL sieci Web korzystający z protokołu HTTP
- Hadoop przy użyciu technologii HiveQL
- Azure Blob Storage
- Tabela platformy Azure
- Azure SQL Database. SQL Managed Instance lub SQL Server
- Dostawca źródła danych, OData obecnie
- Azure Cosmos DB
Ponieważ te dane szkoleniowe są dostępne podczas wykonywania eksperymentu, są dostępne tylko w tym eksperymencie. Dla porównania dane przechowywane w module zestawu danych są dostępne dla każdego eksperymentu w obszarze roboczym.
Aby uzyskać dostęp do źródeł danych online w eksperymencie studio (klasycznym), dodaj moduł Import Data (Importuj dane ) do eksperymentu. Następnie wybierz pozycję Uruchom Kreatora importu danych w obszarze Właściwości , aby uzyskać instrukcje krok po kroku, aby wybrać i skonfigurować źródło danych. Alternatywnie możesz ręcznie wybrać źródło danych w obszarze Właściwości i podać parametry wymagane do uzyskania dostępu do danych.
Obsługiwane źródła danych online są wyszczególnione w poniższej tabeli. Ta tabela zawiera również podsumowanie obsługiwanych formatów plików i parametrów używanych do uzyskiwania dostępu do danych.
Ważne
Obecnie moduły Importuj dane i Eksportuj dane mogą odczytywać i zapisywać dane tylko z usługi Azure Storage utworzonej przy użyciu klasycznego modelu wdrażania. Innymi słowy, nowy typ konta Azure Blob Storage, który oferuje warstwę dostępu do magazynu gorącą lub warstwę dostępu do magazynu chłodnego, nie jest jeszcze obsługiwany.
Ogólnie rzecz biorąc, wszystkie konta usługi Azure Storage, które mogły zostać utworzone przed udostępnieniem tej opcji usługi, nie powinny mieć wpływu. Jeśli musisz utworzyć nowe konto, wybierz pozycję Klasyczny dla modelu wdrażania lub użyj usługi Resource Manager i wybierz pozycję Ogólnego przeznaczenia , a nie usługę Blob Storage w polu Rodzaj konta.
Aby uzyskać więcej informacji, zobacz Azure Blob Storage: Warstwy magazynowania Gorąca i Chłodna.
Obsługiwane źródła danych online
Moduł Importowanie danych w usłudze Machine Learning Studio (wersja klasyczna) obsługuje następujące źródła danych:
| Źródło danych | Opis | Parametry |
|---|---|---|
| Adres URL sieci Web za pośrednictwem protokołu HTTP | Odczytuje dane w formatach wartości rozdzielanych przecinkami (CSV), wartości rozdzielanych tabulatorami (TSV), formatu pliku relacji atrybutów (ARFF) i formatu wektorów nośnych (SVM-light) z dowolnego internetowego adresu URL, który używa protokołu HTTP | Adres URL: określa pełną nazwę pliku, w tym adres URL witryny i nazwę pliku z dowolnym rozszerzeniem. Format danych: określa jeden z obsługiwanych formatów danych: CSV, TSV, ARFF lub SVM-light. Jeśli dane mają wiersz nagłówka, służy do przypisywania nazw kolumn. |
| Hadoop/HDFS | Odczytuje dane z magazynu rozproszonego w usłudze Hadoop. Należy określić żądane dane przy użyciu języka zapytań HiveQL, przypominającego język zapytań SQL. HiveQL może również służyć do agregowania danych i przeprowadzania filtrowania danych przed dodaniem danych do programu Studio (wersja klasyczna). | Zapytanie bazy danych Hive: określa zapytanie Hive używane do generowania danych. Identyfikator URI serwera HCatalog : określ nazwę klastra przy użyciu formatu <nazwy> klastra.azurehdinsight.net. Nazwa konta użytkownika usługi Hadoop: określa nazwę konta użytkownika usługi Hadoop używaną do aprowizowania klastra. Hasło konta użytkownika usługi Hadoop : określa poświadczenia używane podczas aprowizacji klastra. Aby uzyskać więcej informacji, zobacz Tworzenie klastrów Hadoop w usłudze HDInsight. Lokalizacja danych wyjściowych: określa, czy dane są przechowywane w rozproszonym systemie plików Hadoop (HDFS) lub na platformie Azure.
W przypadku przechowywania danych wyjściowych na platformie Azure należy określić nazwę konta usługi Azure Storage, klucz dostępu do usługi Storage i nazwę kontenera usługi Storage. |
| Baza danych SQL | Odczytuje dane przechowywane w usłudze Azure SQL Database, SQL Managed Instance lub w bazie danych SQL Server uruchomionej na maszynie wirtualnej platformy Azure. | Nazwa serwera bazy danych: określa nazwę serwera, na którym działa baza danych.
W przypadku serwera SQL hostowanego na maszynie wirtualnej platformy Azure wprowadź nazwę DNS> tcp:<Virtual Machine, 1433 Nazwa bazy danych : określa nazwę bazy danych na serwerze. Nazwa konta użytkownika serwera: określa nazwę użytkownika dla konta, które ma uprawnienia dostępu do bazy danych. Hasło konta użytkownika serwera: określa hasło dla konta użytkownika. Zapytanie bazy danych: wprowadź instrukcję SQL opisową danych, które chcesz odczytać. |
| Lokalna baza danych SQL | Odczytuje dane przechowywane w bazie danych SQL. | Brama danych: określa nazwę bramy Zarządzanie danymi zainstalowanej na komputerze, na którym może uzyskać dostęp do bazy danych SQL Server. Aby uzyskać informacje na temat konfigurowania bramy, zobacz Wykonywanie zaawansowanej analizy za pomocą usługi Machine Learning Studio (klasycznej) przy użyciu danych z serwera SQL. Nazwa serwera bazy danych: określa nazwę serwera, na którym działa baza danych. Nazwa bazy danych : określa nazwę bazy danych na serwerze. Nazwa konta użytkownika serwera: określa nazwę użytkownika dla konta, które ma uprawnienia dostępu do bazy danych. Nazwa użytkownika i hasło: kliknij pozycję Wprowadź wartości, aby wprowadzić poświadczenia bazy danych. W zależności od konfiguracji SQL Server można użyć uwierzytelniania zintegrowanego systemu Windows lub uwierzytelniania SQL Server. Zapytanie bazy danych: wprowadź instrukcję SQL opisową danych, które chcesz odczytać. |
| Tabela platformy Azure | Odczytuje dane z usługi Table Service w usłudze Azure Storage. Jeśli często odczytujesz duże ilości danych, użyj usługi Azure Table Service. Zapewnia ona elastyczne, nierelacyjne (NoSQL), wysoce skalowalne, niedrogie i wysoce dostępne rozwiązanie magazynu. |
Opcje w importowaniu danych zmieniają się w zależności od tego, czy uzyskujesz dostęp do informacji publicznych, czy prywatnego konta magazynu, które wymaga poświadczeń logowania. Jest to określane przez typ uwierzytelniania , który może mieć wartość "PublicOrSAS" lub "Konto", z których każdy ma własny zestaw parametrów. Identyfikator URI sygnatury dostępu publicznego lub współdzielonego (SAS): parametry to:
Określa wiersze do skanowania pod kątem nazw właściwości: wartości to TopN do skanowania określonej liczby wierszy lub ScanAll w celu pobrania wszystkich wierszy w tabeli. Jeśli dane są jednorodne i przewidywalne, zaleca się wybranie pozycji TopN i wprowadzenie liczby N. W przypadku dużych tabel może to spowodować szybsze odczytywanie. Jeśli dane są ustrukturyzowane z zestawami właściwości, które różnią się w zależności od głębokości i położenia tabeli, wybierz opcję ScanAll , aby skanować wszystkie wiersze. Zapewnia to integralność wynikowej właściwości i konwersji metadanych.
Klucz konta: określa klucz magazynu skojarzony z kontem. Nazwa tabeli : określa nazwę tabeli zawierającej dane do odczytania. Wiersze do skanowania nazw właściwości: wartości to TopN do skanowania określonej liczby wierszy lub ScanAll w celu pobrania wszystkich wierszy w tabeli. Jeśli dane są jednorodne i przewidywalne, zalecamy wybranie pozycji TopN i wprowadzenie liczby N. W przypadku dużych tabel może to spowodować szybsze odczytywanie. Jeśli dane są ustrukturyzowane z zestawami właściwości, które różnią się w zależności od głębokości i położenia tabeli, wybierz opcję ScanAll , aby skanować wszystkie wiersze. Zapewnia to integralność wynikowej właściwości i konwersji metadanych. |
| Azure Blob Storage | Odczytuje dane przechowywane w usłudze Blob w usłudze Azure Storage, w tym obrazy, tekst bez struktury lub dane binarne. Za pomocą usługi Blob można publicznie uwidaczniać dane lub prywatnie przechowywać dane aplikacji. Dostęp do danych można uzyskać z dowolnego miejsca przy użyciu połączeń HTTP lub HTTPS. |
Opcje w module Importuj dane zmieniają się w zależności od tego, czy uzyskujesz dostęp do informacji publicznych, czy prywatnego konta magazynu, które wymaga poświadczeń logowania. Jest to określane przez typ uwierzytelniania , który może mieć wartość "PublicOrSAS" lub "Konto". Identyfikator URI sygnatury dostępu publicznego lub współdzielonego (SAS): parametry to:
Format pliku: określa format danych w usłudze Blob Service. Obsługiwane formaty to CSV, TSV i ARFF.
Klucz konta: określa klucz magazynu skojarzony z kontem. Ścieżka do kontenera, katalogu lub obiektu blob : określa nazwę obiektu blob zawierającego dane do odczytu. Format pliku obiektu blob: określa format danych w usłudze blob. Obsługiwane formaty danych to CSV, TSV, ARFF, CSV z określonym kodowaniem i programem Excel.
Możesz użyć opcji programu Excel do odczytywania danych ze skoroszytów programu Excel. W opcji format danych programu Excel wskaż, czy dane są w zakresie arkusza programu Excel, czy w tabeli programu Excel. W opcji Arkusz programu Excel lub tabela osadzona określ nazwę arkusza lub tabeli, z której chcesz odczytać. |
| Dostawca źródła danych | Odczytuje dane od obsługiwanego dostawcy kanału informacyjnego. Obecnie obsługiwany jest tylko format OData (Open Data Protocol). | Typ zawartości danych: określa format OData. Źródłowy adres URL: określa pełny adres URL źródła danych. Na przykład następujący adres URL jest odczytywany z przykładowej bazy danych Northwind: https://services.odata.org/northwind/northwind.svc/ |
Importowanie z innego eksperymentu
Będą czasy, kiedy zechcesz wykonać wynik pośredni z jednego eksperymentu i użyć go w ramach innego eksperymentu. W tym celu zapiszesz moduł jako zestaw danych:
- Kliknij dane wyjściowe modułu, który chcesz zapisać jako zestaw danych.
- Kliknij pozycję Zapisz jako zestaw danych.
- Po wyświetleniu monitu wprowadź nazwę i opis, który umożliwi łatwe zidentyfikowanie zestawu danych.
- Kliknij znacznik wyboru OK .
Po zakończeniu zapisywania zestaw danych będzie dostępny do użycia w dowolnym eksperymencie w obszarze roboczym. Możesz go znaleźć na liście Zapisane zestawy danych na palecie modułów.