Wykonywanie składnika skryptu języka R
W tym artykule opisano, jak używać składnika Execute R Script do uruchamiania kodu języka R w potoku projektanta usługi Azure Machine Learning.
Za pomocą języka R można wykonywać zadania, które nie są obsługiwane przez istniejące składniki, takie jak:
- Tworzenie niestandardowych przekształceń danych
- Ocenianie przewidywań przy użyciu własnych metryk
- Tworzenie modeli przy użyciu algorytmów, które nie są implementowane jako składniki autonomiczne w projektancie
Obsługa wersji języka R
Projektant usługi Azure Machine Learning korzysta z dystrybucji RRAN (kompleksowej sieci archiwum R). Obecnie używana wersja to CRAN 3.5.1.
Obsługiwane pakiety języka R
Środowisko języka R jest wstępnie zainstalowane z ponad 100 pakietami. Aby uzyskać pełną listę, zobacz sekcję Preinstalled R packages (Wstępnie zainstalowane pakiety języka R).
Możesz również dodać następujący kod do dowolnego składnika Execute R Script, aby wyświetlić zainstalowane pakiety.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
dataframe1 <- data.frame(installed.packages())
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Uwaga
Jeśli potok zawiera wiele składników execute R Script, które wymagają pakietów, które nie znajdują się na liście preinstalowanej, zainstaluj pakiety w każdym składniku.
Instalowanie pakietów języka R
Aby zainstalować dodatkowe pakiety języka R, użyj install.packages() metody . Pakiety są instalowane dla każdego składnika Execute R Script. Nie są one współużytkowane przez inne składniki wykonywania skryptu języka R.
Uwaga
Nie zaleca się instalowania pakietu języka R z pakietu skryptów. Zaleca się instalowanie pakietów bezpośrednio w edytorze skryptów.
Określ repozytorium CRAN podczas instalowania pakietów, takich jak install.packages("zoo",repos = "https://cloud.r-project.org").
Ostrzeżenie
Składnik skryptu języka R excute nie obsługuje instalowania pakietów wymagających kompilacji natywnej, takich jak qdap pakiet, który wymaga języka JAVA i drc pakietu, który wymaga języka C++. Jest to spowodowane tym, że ten składnik jest wykonywany w środowisku wstępnie zainstalowanym z uprawnieniami innych niż administrator.
Nie instaluj pakietów, które są wstępnie wbudowane w systemie Windows/dla systemu Windows, ponieważ składniki projektanta są uruchomione w systemie Ubuntu. Aby sprawdzić, czy pakiet jest wstępnie utworzony w systemie Windows, możesz przejść do sieci CRAN i wyszukać pakiet, pobrać jeden plik binarny zgodnie z systemem operacyjnym, a następnie zaznaczyć pozycję Skompiluj: część w pliku DESCRIPTION . Oto przykład: 
W tym przykładzie pokazano, jak zainstalować usługę Zoo:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
if(!require(zoo)) install.packages("zoo",repos = "https://cloud.r-project.org")
library(zoo)
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Uwaga
Przed zainstalowaniem pakietu sprawdź, czy już istnieje, aby nie powtarzać instalacji. Powtórzenie instalacji może spowodować przekroczenie limitu czasu żądań usług internetowych.
Dostęp do zarejestrowanego zestawu danych
Aby uzyskać dostęp do zarejestrowanych zestawów danych w obszarze roboczym, możesz odwołać się do następującego przykładowego kodu:
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
run = get_current_run()
ws = run$experiment$workspace
dataset = azureml$core$dataset$Dataset$get_by_name(ws, "YOUR DATASET NAME")
dataframe2 <- dataset$to_pandas_dataframe()
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Jak skonfigurować wykonywanie skryptu języka R
Składnik Execute R Script (Wykonywanie skryptu języka R) zawiera przykładowy kod jako punkt wyjścia.
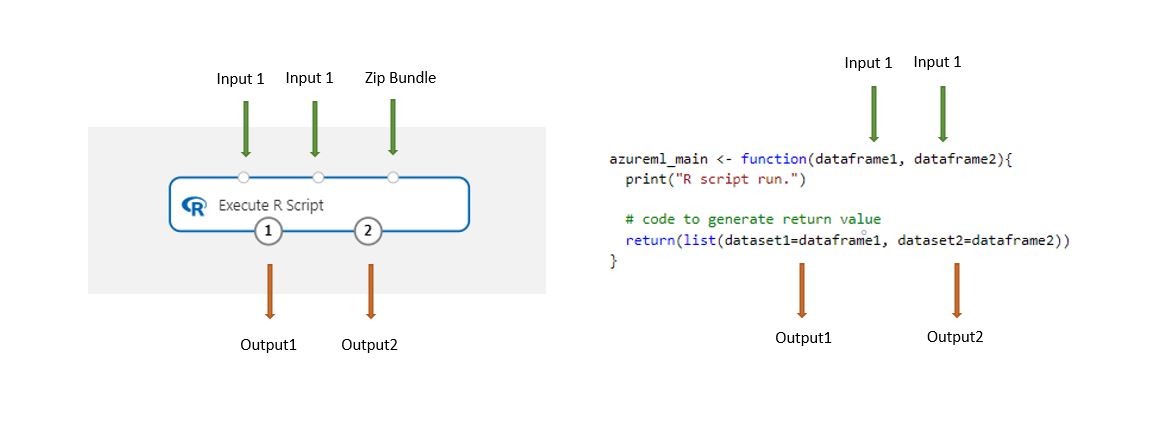
Zestawy danych przechowywane w projektancie są automatycznie konwertowane na ramkę danych języka R podczas ładowania z tym składnikiem.
Dodaj składnik Execute R Script (Wykonywanie skryptu języka R ) do potoku.
Połącz wszystkie dane wejściowe wymagane przez skrypt. Dane wejściowe są opcjonalne i mogą zawierać dane i dodatkowy kod języka R.
Dataset1: odwoływanie się do pierwszych danych wejściowych jako
dataframe1. Wejściowy zestaw danych musi być sformatowany jako plik CSV, TSV lub ARFF. Możesz też połączyć zestaw danych usługi Azure Machine Learning.Dataset2: odwoływanie się do drugiego elementu wejściowego jako
dataframe2. Ten zestaw danych musi być również sformatowany jako plik CSV, TSV lub ARFF albo jako zestaw danych usługi Azure Machine Learning.Pakiet skryptów: trzecie dane wejściowe akceptują pliki .zip. Spakowany plik może zawierać wiele plików i wiele typów plików.
W polu tekstowym Skrypt języka R wpisz lub wklej prawidłowy skrypt języka R.
Uwaga
Podczas pisania skryptu należy zachować ostrożność. Upewnij się, że nie ma żadnych błędów składniowych, takich jak używanie niezdecydowanych zmiennych lub nieimportowanych składników lub funkcji. Zwróć szczególną uwagę na listę wstępnie zainstalowanych pakietów na końcu tego artykułu. Aby używać pakietów, których nie ma na liście, zainstaluj je w skrycie. Może to być na przykład
install.packages("zoo",repos = "https://cloud.r-project.org").Aby ułatwić rozpoczęcie pracy, pole tekstowe Skrypt języka R jest wstępnie wypełniane przykładowym kodem, który można edytować lub zastąpić.
# R version: 3.5.1 # The script MUST contain a function named azureml_main, # which is the entry point for this component. # Note that functions dependent on the X11 library, # such as "View," are not supported because the X11 library # is not preinstalled. # The entry point function MUST have two input arguments. # If the input port is not connected, the corresponding # dataframe argument will be null. # Param<dataframe1>: a R DataFrame # Param<dataframe2>: a R DataFrame azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # If a .zip file is connected to the third input port, it's # unzipped under "./Script Bundle". This directory is added # to sys.path. # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }Funkcja punktu wejścia musi mieć argumenty
Param<dataframe1>wejściowe iParam<dataframe2>, nawet jeśli te argumenty nie są używane w funkcji.Uwaga
Dane przekazane do składnika Execute R Script są przywoływane jako
dataframe1idataframe2, które różnią się od projektanta usługi Azure Machine Learning (odwołanie projektanta jakodataset1,dataset2). Upewnij się, że w skrycie poprawnie odwołuje się do danych wejściowych.Uwaga
Istniejący kod języka R może wymagać drobnych zmian do uruchomienia w potoku projektanta. Na przykład dane wejściowe podane w formacie CSV powinny zostać jawnie przekonwertowane na zestaw danych przed użyciem ich w kodzie. Typy danych i kolumn używane w języku R różnią się również pod pewnymi względami od typów danych i kolumn używanych w projektancie.
Jeśli skrypt jest większy niż 16 KB, użyj portu pakietu skryptów , aby uniknąć błędów, takich jak Wiersz polecenia przekracza limit 16597 znaków.
- Spakuj skrypt i inne zasoby niestandardowe do pliku zip.
- Przekaż plik zip jako zestaw danych plików do studia.
- Przeciągnij składnik zestawu danych z listy Zestawy danych w okienku składników po lewej stronie na stronie tworzenia projektanta.
- Połącz składnik zestawu danych z portem pakietu skryptów składnika Wykonaj skrypt języka R .
Poniżej przedstawiono przykładowy kod do korzystania ze skryptu w pakiecie skryptów:
azureml_main <- function(dataframe1, dataframe2){ # Source the custom R script: my_script.R source("./Script Bundle/my_script.R") # Use the function that defined in my_script.R dataframe1 <- my_func(dataframe1) sample <- readLines("./Script Bundle/my_sample.txt") return (list(dataset1=dataframe1, dataset2=data.frame("Sample"=sample))) }W polu Inicjator losowy wprowadź wartość, która ma być używana w środowisku języka R jako losowa wartość inicjowania. Ten parametr jest odpowiednikiem wywołania
set.seed(value)w kodzie języka R.Prześlij potok.
Wyniki
Wykonywanie składników skryptu języka R może zwracać wiele danych wyjściowych, ale muszą być podane jako ramki danych języka R. Projektant automatycznie konwertuje ramki danych na zestawy danych w celu zachowania zgodności z innymi składnikami.
Standardowe komunikaty i błędy z języka R są zwracane do dziennika składnika.
Jeśli chcesz wydrukować wyniki w skryscie języka R, możesz znaleźć wydrukowane wyniki w 70_driver_log na karcie Dane wyjściowe i dzienniki w prawym panelu składnika.
Przykładowe skrypty
Istnieje wiele sposobów rozszerzania potoku przy użyciu niestandardowych skryptów języka R. Ta sekcja zawiera przykładowy kod dla typowych zadań.
Dodawanie skryptu języka R jako danych wejściowych
Składnik Execute R Script obsługuje dowolne pliki skryptów języka R jako dane wejściowe. Aby ich używać, należy przekazać je do obszaru roboczego w ramach pliku .zip.
Aby przekazać plik .zip zawierający kod języka R do obszaru roboczego, przejdź do strony elementów zawartości Zestawy danych . Wybierz pozycję Utwórz zestaw danych, a następnie wybierz pozycję Z pliku lokalnego i opcję Typ zestawu danych Plik .
Sprawdź, czy spakowany plik jest wyświetlany w obszarze Moje zestawy danych w kategorii Zestawy danych w drzewie składników po lewej stronie.
Połącz zestaw danych z portem wejściowym pakietu skryptów .
Wszystkie pliki w pliku .zip są dostępne w czasie wykonywania potoku.
Jeśli plik pakietu skryptów zawiera strukturę katalogów, struktura zostanie zachowana. Należy jednak zmienić kod, aby wstępnie dołączyć katalog ./Script Bundle do ścieżki.
Przetwarzanie danych
W poniższym przykładzie pokazano, jak skalować i normalizować dane wejściowe:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
# If a .zip file is connected to the third input port, it's
# unzipped under "./Script Bundle". This directory is added
# to sys.path.
series <- dataframe1$width
# Find the maximum and minimum values of the width column in dataframe1
max_v <- max(series)
min_v <- min(series)
# Calculate the scale and bias
scale <- max_v - min_v
bias <- min_v / dis
# Apply min-max normalizing
dataframe1$width <- dataframe1$width / scale - bias
dataframe2$width <- dataframe2$width / scale - bias
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Odczytywanie pliku .zip jako danych wejściowych
W tym przykładzie pokazano, jak używać zestawu danych w pliku .zip jako dane wejściowe składnika Execute R Script.
- Utwórz plik danych w formacie CSV i nadaj mu nazwę mydatafile.csv.
- Utwórz plik .zip i dodaj plik CSV do archiwum.
- Przekaż spakowany plik do obszaru roboczego usługi Azure Machine Learning.
- Połącz wynikowy zestaw danych z danymi wejściowymi ScriptBundle składnika Execute R Script .
- Użyj następującego kodu, aby odczytać dane CSV z pliku zip.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
mydataset<-read.csv("./Script Bundle/mydatafile.csv",encoding="UTF-8");
# Return datasets as a Named List
return(list(dataset1=mydataset, dataset2=dataframe2))
}
Replikowanie wierszy
W tym przykładzie pokazano, jak replikować dodatnie rekordy w zestawie danych, aby zrównoważyć przykład:
azureml_main <- function(dataframe1, dataframe2){
data.set <- dataframe1[dataframe1[,1]==-1,]
# positions of the positive samples
pos <- dataframe1[dataframe1[,1]==1,]
# replicate the positive samples to balance the sample
for (i in 1:20) data.set <- rbind(data.set,pos)
row.names(data.set) <- NULL
# Return datasets as a Named List
return(list(dataset1=data.set, dataset2=dataframe2))
}
Przekazywanie obiektów języka R między składnikami wykonywania skryptu języka R
Obiekty języka R można przekazywać między wystąpieniami składnika Execute R Script przy użyciu wewnętrznego mechanizmu serializacji. W tym przykładzie przyjęto założenie, że chcesz przenieść obiekt języka R o nazwie A między dwoma składnikami Execute R Script.
Dodaj pierwszy składnik Execute R Script do potoku. Następnie wprowadź następujący kod w polu tekstowym Skrypt języka R , aby utworzyć serializowany obiekt
Ajako kolumnę w tabeli danych wyjściowych składnika:azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # some codes generated A serialized <- as.integer(serialize(A,NULL)) data.set <- data.frame(serialized,stringsAsFactors=FALSE) return(list(dataset1=data.set, dataset2=dataframe2)) }Jawna konwersja na typ liczby całkowitej jest wykonywana, ponieważ funkcja serializacji generuje dane w formacie języka R
Raw, którego projektant nie obsługuje.Dodaj drugie wystąpienie składnika Execute R Script i połącz je z portem wyjściowym poprzedniego składnika.
Wpisz następujący kod w polu tekstowym Skrypt języka R , aby wyodrębnić obiekt
Az tabeli danych wejściowych.azureml_main <- function(dataframe1, dataframe2){ print("R script run.") A <- unserialize(as.raw(dataframe1$serialized)) # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }
Wstępnie zainstalowane pakiety języka R
Obecnie dostępne są następujące wstępnie zainstalowane pakiety języka R:
| Pakiet | Wersja |
|---|---|
| askpass | 1,1 |
| assertthat | 0.2.1 |
| backports | 1.1.4 |
| base | 3.5.1 |
| base64enc | 0.1-3 |
| BH | 1.69.0-1 |
| bindr | 0.1.1 |
| bindrcpp | 0.2.2 |
| bitops | 1.0-6 |
| boot | 1.3-22 |
| broom | 0.5.2 |
| callr | 3.2.0 |
| daszek | 6.0-84 |
| caTools | 1.17.1.2 |
| cellranger | 1.1.0 |
| class | 7.3-15 |
| cli | 1.1.0 |
| clipr | 0.6.0 |
| cluster | 2.0.7-1 |
| codetools | 0.2-16 |
| colorspace | 1.4-1 |
| compiler | 3.5.1 |
| crayon | 1.3.4 |
| curl | 3.3 |
| data.table | 1.12.2 |
| zestawy danych | 3.5.1 |
| DBI | 1.0.0 |
| dbplyr | 1.4.1 |
| digest | 0.6.19 |
| dplyr | 0.7.6 |
| e1071 | 1.7-2 |
| evaluate | 0.14 |
| fansi | 0.4.0 |
| forcats | 0.3.0 |
| foreach | 1.4.4 |
| foreign | 0.8-71 |
| Fs | 1.3.1 |
| gdata | 2.18.0 |
| Generyczne | 0.0.2 |
| ggplot2 | 3.2.0 |
| glmnet | 2.0-18 |
| glue | 1.3.1 |
| gower | 0.2.1 |
| gplots | 3.0.1.1 |
| grafika | 3.5.1 |
| grDevices | 3.5.1 |
| grid | 3.5.1 |
| gtable | 0.3.0 |
| gtools | 3.8.1 |
| haven | 2.1.0 |
| highr | 0,8 |
| hms | 0.4.2 |
| htmltools | 0.3.6 |
| httr | 1.4.0 |
| ipred | 0.9-9 |
| iterators | 1.0.10 |
| jsonlite | 1.6 |
| KernSmooth | 2.23-15 |
| knitr | 1,23 |
| labeling | 0.3 |
| lattice | 0.20-38 |
| lava | 1.6.5 |
| lazyeval | 0.2.2 |
| lubridate | 1.7.4 |
| magrittr | 1.5 |
| markdown | 1 |
| MASS | 7.3-51.4 |
| Macierz | 1.2-17 |
| methods | 3.5.1 |
| mgcv | 1.8-28 |
| mime | 0.7 |
| ModelMetrics | 1.2.2 |
| modelr | 0.1.4 |
| munsell | 0.5.0 |
| nlme | 3.1-140 |
| nnet | 7.3-12 |
| numDeriv | 2016.8-1.1 |
| openssl | 1.4 |
| parallel | 3.5.1 |
| pillar | 1.4.1 |
| pkgconfig | 2.0.2 |
| plogr | 0.2.0 |
| plyr | 1.8.4 |
| prettyunits | 1.0.2 |
| processx | 3.3.1 |
| prodlim | 2018.04.18 |
| progress | 1.2.2 |
| Ps | 1.3.0 |
| purrr | 0.3.2 |
| quadprog | 1.5-7 |
| quantmod | 0.4-15 |
| R6 | 2.4.0 |
| randomForest | 4.6-14 |
| RColorBrewer | 1.1-2 |
| Rcpp | 1.0.1 |
| RcppRoll | 0.3.0 |
| readr | 1.3.1 |
| readxl | 1.3.1 |
| recipes | 0.1.5 |
| rematch | 1.0.1 |
| reprex | 0.3.0 |
| reshape2 | 1.4.3 |
| reticulate | 1.12 |
| rlang | 0.4.0 |
| rmarkdown | 1.13 |
| ROCR | 1.0-7 |
| rpart | 4.1-15 |
| rstudioapi | 0.1 |
| rvest | 0.3.4 |
| scales | 1.0.0 |
| selectr | 0.4-1 |
| spatial | 7.3-11 |
| splines | 3.5.1 |
| SQUAREM | 2017.10-1 |
| stats | 3.5.1 |
| stats4 | 3.5.1 |
| stringi | 1.4.3 |
| stringr | 1.3.1 |
| survival | 2.44-1.1 |
| sys | 3,2 |
| tcltk | 3.5.1 |
| tibble | 2.1.3 |
| tidyr | 0.8.3 |
| tidyselect | 0.2.5 |
| tidyverse | 1.2.1 |
| timeDate | 3043.102 |
| tinytex | 0.13 |
| tools | 3.5.1 |
| tseries | 0.10-47 |
| TTR | 0.23-4 |
| utf8 | 1.1.4 |
| utils | 3.5.1 |
| vctrs | 0.1.0 |
| viridisLite | 0.3.0 |
| whisker | 0.3-2 |
| withr | 2.1.2 |
| xfun | 0,8 |
| xml2 | 1.2.0 |
| xts | 0.11-2 |
| yaml | 2.2.0 |
| zeallot | 0.1.0 |
| zoo | 1.8-6 |
Następne kroki
Zobacz zestaw składników dostępnych dla usługi Azure Machine Learning.