Uczenie głębokie przy użyciu prognozowania zautomatyzowanego uczenia maszynowego
Ten artykuł koncentruje się na metodach uczenia głębokiego na potrzeby prognozowania szeregów czasowych w rozwiązaniu AutoML. Instrukcje i przykłady dotyczące modeli prognozowania trenowania w rozwiązaniu AutoML można znaleźć w artykule dotyczącym konfigurowania automatycznego uczenia maszynowego na potrzeby prognozowania szeregów czasowych .
Uczenie głębokie ma duży wpływ na pola, od modelowania języka po składanie białek, między innymi. Prognozowanie szeregów czasowych również skorzystało z ostatnich postępów w technologii uczenia głębokiego. Na przykład modele głębokiej sieci neuronowej (DNN) są widoczne w najlepiej wydajnych modelach z czwartej i piątej iteracji wysokiego profilu konkurencji prognozowania Makridakis.
W tym artykule opiszemy strukturę i działanie modelu TCNForecaster w rozwiązaniu AutoML, aby ułatwić najlepsze zastosowanie modelu do danego scenariusza.
Wprowadzenie do TCNForecaster
TCNForecaster to tymczasowa sieć splotowa lub TCN, która ma architekturę sieci rozproszonej specjalnie zaprojektowaną dla danych szeregów czasowych. Model używa danych historycznych dla ilości docelowej, wraz z powiązanymi funkcjami, aby przewidywać probabilistyczne wartości docelowej do określonego horyzontu prognozy. Na poniższej ilustracji przedstawiono główne składniki architektury TCNForecaster:
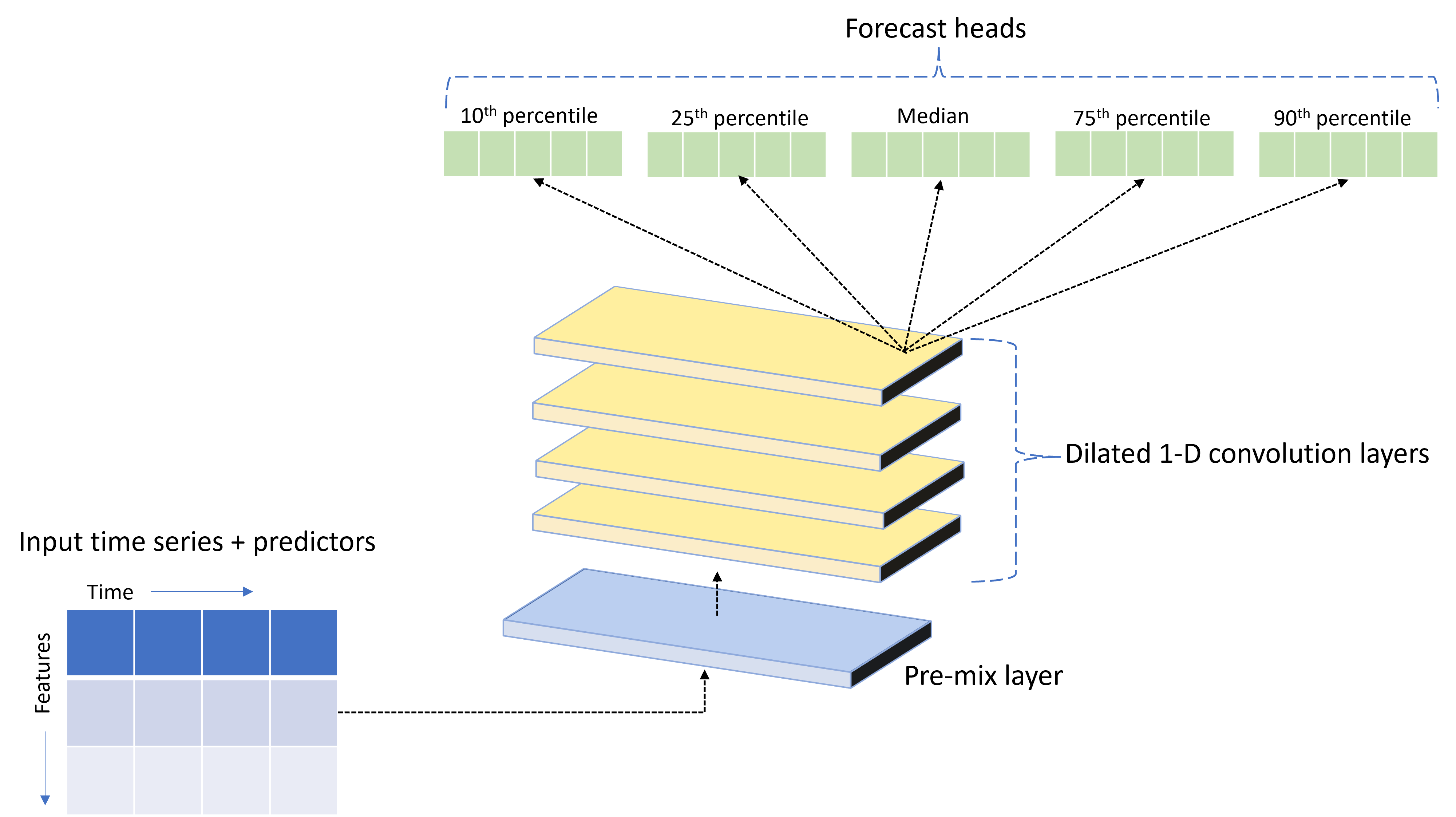
TCNForecaster ma następujące główne składniki:
- Wstępnie wymieszana warstwa, która łączy wejściowe szeregi czasowe i dane funkcji w tablicę kanałów sygnałowych, które będą przetwarzane przez stos konwolucyjny.
- Stos warstw konwolucji rozszerzonej , który przetwarza tablicę kanałów sekwencyjnie; każda warstwa w stosie przetwarza dane wyjściowe poprzedniej warstwy w celu utworzenia nowej tablicy kanałów. Każdy kanał w tych danych wyjściowych zawiera mieszaninę sygnałów filtrowanych za pomocą konwolucji z kanałów wejściowych.
- Kolekcja jednostek głowy prognozy , które łączą sygnały wyjściowe z warstw konwolucji i generują prognozy ilości docelowej z tej ukrytej reprezentacji. Każda jednostka główna generuje prognozy do horyzontu dla kwantylu rozkładu przewidywania.
Dylatowana konwolucja przyczynowa
Centralna operacja TCN jest dylatacją przyczynową wraz z wymiarem czasu sygnału wejściowego. Intuicyjnie konwolucja łączy wartości z pobliskich punktów czasowych w danych wejściowych. Proporcje w mieszaninie to jądro lub wagi konwolucji, podczas gdy rozdzielenie między punktami w mieszaninie jest dylatacją. Sygnał wyjściowy jest generowany na podstawie danych wejściowych przez przesunięcie jądra w czasie wzdłuż danych wejściowych i gromadzenie mieszaniny w każdej pozycji. Konwolucja przyczynowa jest jednym, w którym jądro miesza tylko wartości wejściowe w przeszłości względem każdego punktu wyjściowego, uniemożliwiając wyjście "patrząc" w przyszłość.
Skumulowanie dylatowanych konwolucji daje TCN możliwość modelowania korelacji w długich okresach w sygnałach wejściowych z stosunkowo niewielką wagą jądra. Na przykład na poniższej ilustracji przedstawiono trzy skumulowane warstwy z dwuważnym jądrem w każdej warstwie i wykładniczo zwiększające się czynniki dilacji:
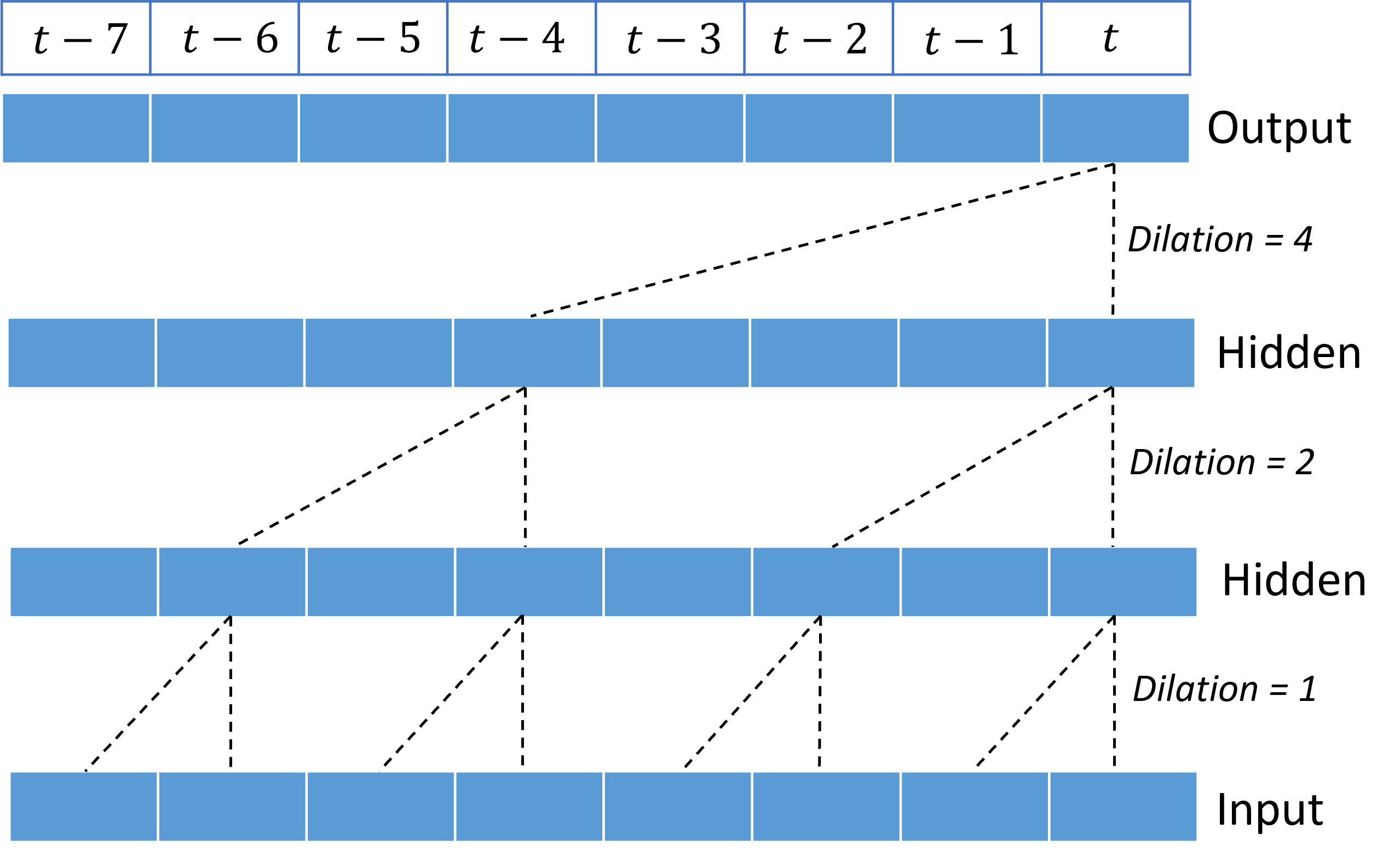
Linie przerywane pokazują ścieżki przez sieć, która kończy się na danych wyjściowych w czasie $t$. Te ścieżki obejmują ostatnie osiem punktów w danych wejściowych, ilustrując, że każdy punkt wyjściowy jest funkcją ośmiu stosunkowo ostatnich punktów w danych wejściowych. Długość historii lub "spójrz wstecz", że sieć konwolucyjna używa do przewidywania jest nazywana polem otwartym i jest określana całkowicie przez architekturę TCN.
Architektura TCNForecaster
Rdzeń architektury TCNForecaster jest stosem warstw splotowych między pre-mix a głowicami prognoz. Stos jest logicznie podzielony na powtarzające się jednostki nazywane blokami , które z kolei składają się z komórek reszt. Komórka reszt stosuje konwolucje przyczynowe podczas trwania zestawu wraz z normalizacją i aktywacją nieliniową. Co ważne, każda komórka reszt dodaje swoje dane wyjściowe do danych wejściowych przy użyciu tak zwanego połączenia reszt. Te połączenia okazały się korzystne dla trenowania sieci rozproszonej, być może dlatego, że ułatwiają one bardziej wydajny przepływ informacji przez sieć. Na poniższej ilustracji przedstawiono architekturę warstw splotowych dla przykładowej sieci z dwoma blokami i trzema komórkami reszt w każdym bloku:

Liczba bloków i komórek wraz z liczbą kanałów sygnału w każdej warstwie kontroluje rozmiar sieci. Parametry architektury TCNForecaster zostały podsumowane w poniższej tabeli:
| Parametr | Opis |
|---|---|
| $n_{b}$ | Liczba bloków w sieci; nazywana również głębokością |
| $n_{c}$ | Liczba komórek w każdym bloku |
| $n_{\text{ch}}$ | Liczba kanałów w ukrytych warstwach |
Pole otwarte zależy od parametrów głębokości i jest podane przez formułę,
$t_{\text{rf}} = 4n_{b}\left(2^{n_{c}} - 1\right) + 1,$
Możemy podać bardziej precyzyjną definicję architektury TCNForecaster pod względem formuł. Pozwól $X$ jako tablicę wejściową, w której każdy wiersz zawiera wartości funkcji z danych wejściowych. Możemy podzielić $X$ na tablice cech liczbowych i kategorialnych, $X_{\text{num}}$ i $X_{\text{cat}}$. Następnie TCNForecaster jest podawany przez formuły,
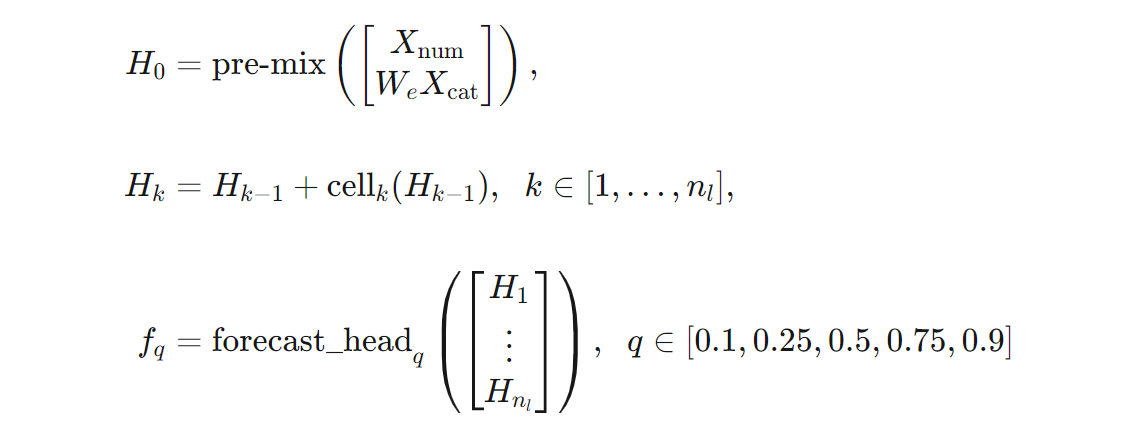
gdzie $W_{e}$ jest macierzą osadzania dla cech podzielonych na kategorie, $n_{l} = n_{b}n_{c}$ jest całkowitą liczbą komórek reszt, $H_{k}$ oznacza ukryte dane wyjściowe warstwy, a $f_{q}$ to dane wyjściowe prognozy dla danych kwantyli rozkładu przewidywania. Aby ułatwić zrozumienie, wymiary tych zmiennych znajdują się w poniższej tabeli:
| Zmienna | Opis | Wymiary |
|---|---|---|
| $X$ | Tablica wejściowa | $n_{\text{input}} \times t_{\text{rf}}$ |
| $H_{i}$ | Ukryte dane wyjściowe warstwy dla $i=0,1,\ldots,n_{l}$ | $n_{\text{ch}} \times t_{\text{rf}}$ |
| $f_{q}$ | Prognozowanie danych wyjściowych kwantylu $q$ | $h$ |
W tabeli $n_{\text{input}} = n_{\text{features}} + 1$, liczba zmiennych predyktor/cech oraz ilość docelowa. Szefowie prognoz generują wszystkie prognozy do maksymalnego horyzontu, $h$, w jednym przebiegu, więc TCNForecaster jest bezpośrednim prognostykiem.
TCNForecaster w rozwiązaniu AutoML
TCNForecaster jest opcjonalnym modelem w rozwiązaniu AutoML. Aby dowiedzieć się, jak go używać, zobacz włączanie uczenia głębokiego.
W tej sekcji opiszemy, jak rozwiązanie AutoML tworzy modele TCNForecaster przy użyciu Twoich danych, w tym wyjaśnienia przetwarzania wstępnego danych, trenowania i wyszukiwania modeli.
Kroki przetwarzania wstępnego danych
Rozwiązanie AutoML wykonuje kilka kroków przetwarzania wstępnego na danych, aby przygotować się do trenowania modelu. W poniższej tabeli opisano następujące kroki w kolejności, w której są wykonywane:
| Krok | Opis |
|---|---|
| Wypełnianie brakujących danych | Uzupełnij brakujące wartości i luki obserwacyjne oraz opcjonalnie uzupełnij lub upuść krótki szereg czasowy |
| Tworzenie funkcji kalendarza | Rozszerzanie danych wejściowych za pomocą funkcji pochodzących z kalendarza , takiego jak dzień tygodnia, oraz opcjonalnie dni wolne dla określonego kraju/regionu. |
| Kodowanie danych kategorii | Kodowanie ciągów etykiet i innych typów kategorii; Obejmuje to wszystkie kolumny identyfikatorów szeregów czasowych. |
| Transformacja docelowa | Opcjonalnie zastosuj funkcję logarytmu naturalnego do celu w zależności od wyników niektórych testów statystycznych. |
| Normalizacja | Wynik Z normalizuje wszystkie dane liczbowe; Normalizacja jest wykonywana na funkcję i grupę szeregów czasowych zgodnie z definicją w kolumnach identyfikatorów szeregów czasowych. |
Te kroki są uwzględniane w potokach przekształcania rozwiązania AutoML, więc są one automatycznie stosowane w razie potrzeby w czasie wnioskowania. W niektórych przypadkach operacja odwrotna do kroku jest uwzględniana w potoku wnioskowania. Jeśli na przykład rozwiązanie AutoML zastosowało przekształcenie $\log$ do celu podczas trenowania, nieprzetworzone prognozy są wykładniczo w potoku wnioskowania.
Szkolenie
TCNForecaster jest zgodny z najlepszymi rozwiązaniami dotyczącymi trenowania sieci DNN typowymi dla innych aplikacji w obrazach i języku. Rozwiązanie AutoML dzieli wstępnie przetworzone dane treningowe na przykłady , które są mieszane i łączone w partie. Sieć przetwarza partie sekwencyjnie przy użyciu propagacji wstecznej i stochastycznego spadku gradientu, aby zoptymalizować wagi sieci w odniesieniu do funkcji straty. Trenowanie może wymagać wielu przejść przez pełne dane szkoleniowe; każdy pass jest nazywany epoką.
W poniższej tabeli wymieniono i opisano ustawienia danych wejściowych oraz parametry trenowania TCNForecaster:
| Dane wejściowe trenowania | Opis | Wartość |
|---|---|---|
| Dane weryfikacji | Część danych, które są utrzymywane z trenowania, aby kierować optymalizacją sieci i ograniczać ich dopasowanie. | Dostarczone przez użytkownika lub automatycznie utworzone na podstawie danych treningowych, jeśli nie zostaną podane. |
| Metryka podstawowa | Metryka obliczana na podstawie prognoz wartości mediany na danych walidacji na końcu każdej epoki trenowania; służy do wczesnego zatrzymywania i wybierania modelu. | Wybrany przez użytkownika; znormalizowany błąd średniokwadratowy lub znormalizowany błąd bezwzględny średniej. |
| Epoki trenowania | Maksymalna liczba epok do uruchomienia w celu optymalizacji wagi sieci. | 100; automatyczna logika wczesnego zatrzymywania może zakończyć trenowanie w mniejszej liczbie epok. |
| Wczesna cierpliwość | Liczba epok oczekiwania na poprawa podstawowej metryki przed zatrzymanie trenowania. | 20 |
| Loss, funkcja | Funkcja celu optymalizacji wagi sieci. | Strata kwantyla wynosiła ponad 10, 25, 50, 75 i 90. percentyl prognoz. |
| Rozmiar partii | Liczba przykładów w partii. Każdy przykład ma wymiary $n_{\text{input}} \times t_{\text{rf}}$ dla danych wejściowych i $h$ dla danych wyjściowych. | Określana automatycznie na podstawie całkowitej liczby przykładów w danych treningowych; wartość maksymalna 1024. |
| Osadzanie wymiarów | Wymiary miejsc osadzania dla cech podzielonych na kategorie. | Automatycznie ustaw wartość czwartego katalogu głównego liczby odrębnych wartości w każdej funkcji zaokrąglonej w górę do najbliższej liczby całkowitej. Progi są stosowane przy wartości minimalnej 3 i maksymalnej 100. |
| Architektura sieci* | Parametry kontrolujące rozmiar i kształt sieci: głębokość, liczba komórek i liczba kanałów. | Określana przez wyszukiwanie modelu. |
| Wagi sieci | Parametry kontrolujące mieszaniny sygnałów, osadzania podzielone na kategorie, wagi jądra konwolucji i mapowania na wartości prognozowane. | Losowo zainicjowane, a następnie zoptymalizowane pod kątem funkcji straty. |
| Szybkość nauki* | Określa, ile wag sieci można dostosować w każdej iteracji spadku gradientu; dynamicznie zmniejszona niemal zbieżność. | Określana przez wyszukiwanie modelu. |
| Współczynnik spadku* | Steruje stopniem uregulowania dropout zastosowanym do wag sieci. | Określana przez wyszukiwanie modelu. |
Dane wejściowe oznaczone gwiazdką (*) są określane przez wyszukiwanie hiperparametrów opisane w następnej sekcji.
Wyszukiwanie modelu
Rozwiązanie AutoML używa metod wyszukiwania modelu do znajdowania wartości następujących hiperparatek:
- Głębokość sieci lub liczba splotowych bloków,
- Liczba komórek na blok,
- Liczba kanałów w każdej ukrytej warstwie,
- Współczynnik spadku dla uregulowania sieci,
- Szybkość nauki.
Optymalne wartości tych parametrów mogą się znacznie różnić w zależności od scenariusza problemu i danych treningowych, dlatego rozwiązanie AutoML trenuje kilka różnych modeli w przestrzeni wartości hiperparametrów i wybiera najlepsze według podstawowego wyniku metryki na danych walidacji.
Wyszukiwanie modelu ma dwie fazy:
- Rozwiązanie AutoML wykonuje wyszukiwanie ponad 12 modeli "charakterystycznych". Modele punktów orientacyjnych są statyczne i wybierane do rozsądnego zakresu przestrzeni hiperparametrów.
- Rozwiązanie AutoML kontynuuje wyszukiwanie w przestrzeni hiperparametrów przy użyciu wyszukiwania losowego.
Wyszukiwanie kończy się po spełnieniu kryteriów zatrzymania. Kryteria zatrzymywania zależą od konfiguracji zadania trenowania prognozy, ale niektóre przykłady obejmują limity czasu, limity liczby prób wyszukiwania do wykonania i wczesną logikę zatrzymywania, gdy metryka walidacji nie poprawia się.
Następne kroki
- Dowiedz się, jak skonfigurować rozwiązanie AutoML do trenowania modelu prognozowania szeregów czasowych.
- Dowiedz się więcej o metodologii prognozowania w rozwiązaniu AutoML.
- Przeglądaj często zadawane pytania dotyczące prognozowania w rozwiązaniu AutoML.