Wnioskowanie i ocena modeli prognozowania (wersja zapoznawcza)
Ważne
Ta funkcja jest obecnie w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone.
Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
W tym artykule przedstawiono pojęcia związane z wnioskowaniem i oceną modelu w zadaniach prognozowania. Instrukcje i przykłady dotyczące modeli prognozowania trenowania w rozwiązaniu AutoML można znaleźć w artykule dotyczącym konfigurowania automatycznego uczenia maszynowego na potrzeby prognozowania szeregów czasowych .
Po użyciu rozwiązania AutoML do trenowania i wybrania najlepszego modelu następnym krokiem jest wygenerowanie prognoz, a następnie, jeśli to możliwe, ocenę ich dokładności na zestawie testowym przeprowadzonym na podstawie danych treningowych. Aby dowiedzieć się, jak skonfigurować i uruchomić ocenę modelu prognozowania w zautomatyzowanym uczeniu maszynowym, zobacz nasz przewodnik dotyczący składników wnioskowania i oceny.
Scenariusze wnioskowania
W uczeniu maszynowym wnioskowanie to proces generowania przewidywań modelu dla nowych danych, które nie są używane podczas trenowania. Istnieje wiele sposobów generowania przewidywań w prognozowaniu ze względu na zależność czasu od danych. Najprostszym scenariuszem jest to, że okres wnioskowania jest bezpośrednio zgodny z okresem trenowania i generujemy przewidywania do horyzontu prognozy. Ten scenariusz przedstawiono na poniższym diagramie:
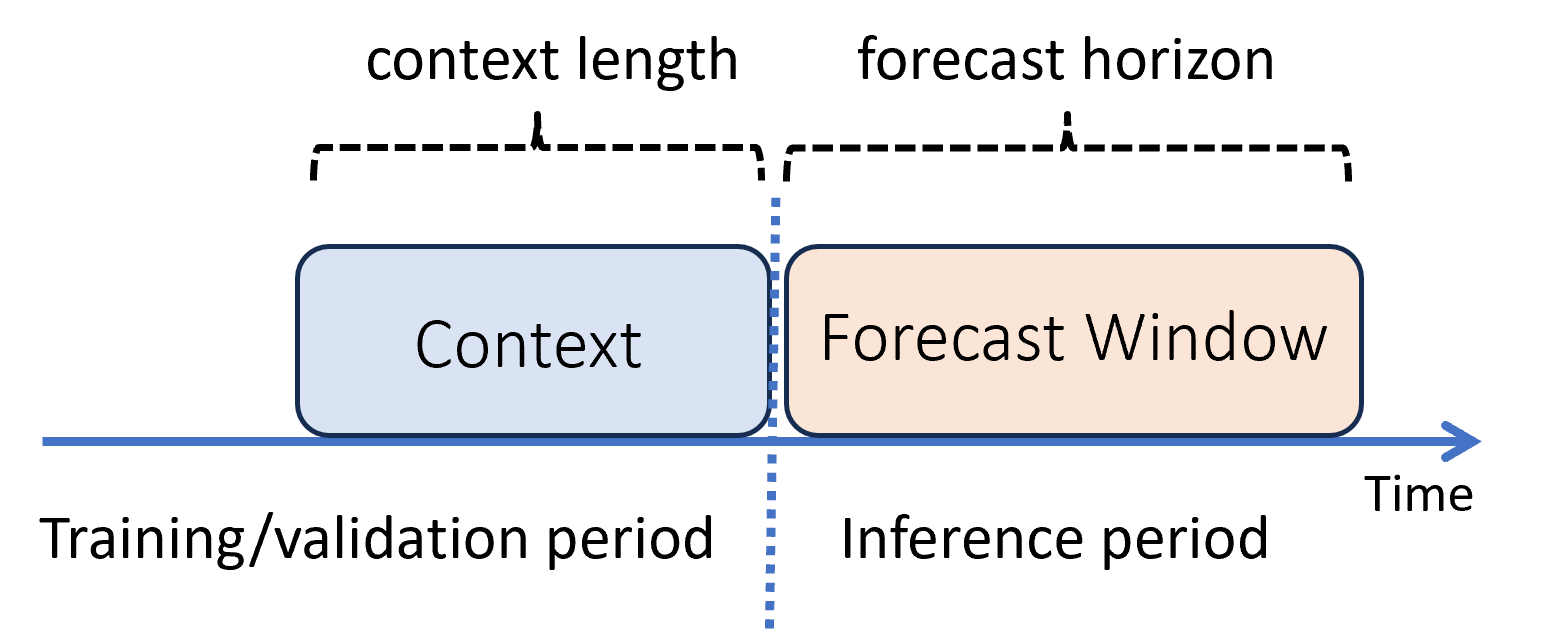
Na diagramie przedstawiono dwa ważne parametry wnioskowania:
- Długość kontekstu lub ilość historii wymaganej przez model do utworzenia prognozy,
- Horyzont prognozy, który jest jak daleko w czasie prognostyk jest szkolony do przewidywania.
Modele prognozowania zwykle używają pewnych informacji historycznych, kontekstu, aby przewidywać z wyprzedzeniem do horyzontu prognozy. Gdy kontekst jest częścią danych treningowych, rozwiązanie AutoML zapisuje to, czego potrzebuje do tworzenia prognoz, więc nie ma potrzeby jawnego podawania go.
Istnieją dwa inne scenariusze wnioskowania, które są bardziej skomplikowane:
- Generowanie przewidywań dalej w przyszłość niż horyzont prognozy,
- Przewidywanie w przypadku różnic między okresami trenowania i wnioskowania.
Przejrzymy te przypadki w poniższych sekcjach podrzędnych.
Przewidywanie poza horyzontem prognozy: prognozowanie cyklicznego
Gdy potrzebujesz prognoz po horyzoncie, rozwiązanie AutoML stosuje model rekursywnie w okresie wnioskowania. Oznacza to, że przewidywania z modelu są przekazywane z powrotem jako dane wejściowe w celu wygenerowania przewidywań dla kolejnych okien prognozowania. Na poniższym diagramie przedstawiono prosty przykład:
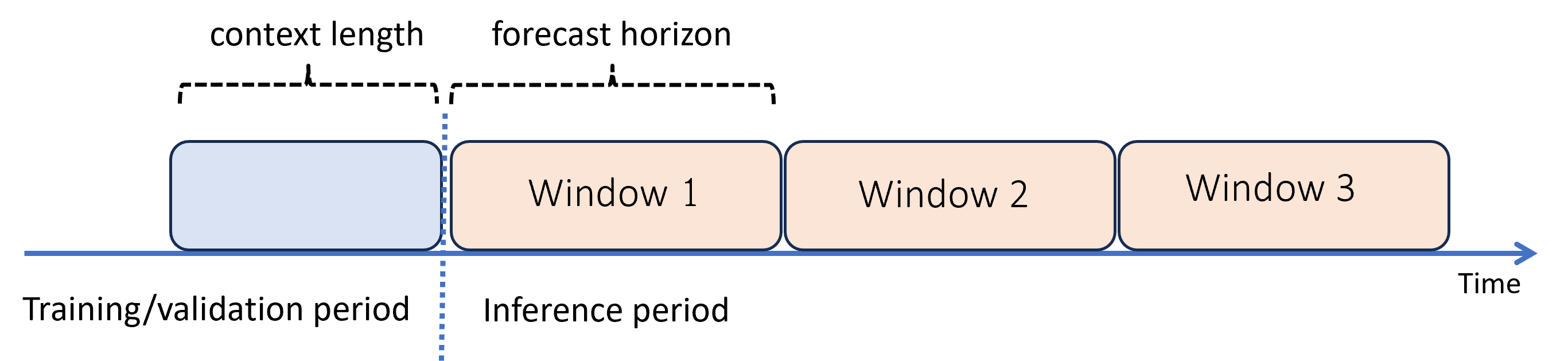
W tym miejscu generujemy prognozy dla okresu trzy razy długości horyzontu przy użyciu przewidywań z jednego okna jako kontekstu następnego okna.
Ostrzeżenie
Rekursywne prognozowanie złożonych błędów modelowania, więc przewidywania stają się mniej dokładne, im dalej pochodzą z pierwotnego horyzontu prognozy. W tym przypadku można znaleźć bardziej dokładny model, ponownie trenowając z dłuższym horyzontem.
Przewidywanie z luką między okresami trenowania i wnioskowania
Załóżmy, że w przeszłości wytrenowano model i chcesz użyć go do przewidywania na podstawie nowych obserwacji, które nie były jeszcze dostępne podczas trenowania. W tym przypadku między okresami trenowania i wnioskowania występuje luka czasowa:
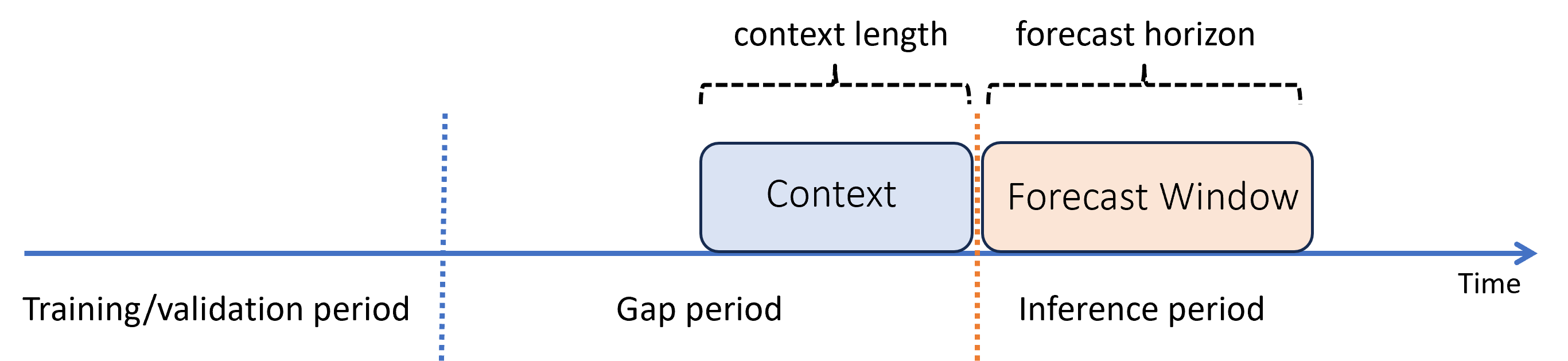
Rozwiązanie AutoML obsługuje ten scenariusz wnioskowania, ale musisz podać dane kontekstowe w okresie przerwy, jak pokazano na diagramie. Dane przewidywania przekazane do składnika wnioskowania wymagają wartości dla funkcji i obserwowanych wartości docelowych w luki oraz brakujących wartości lub wartości "NaN" dla celu w okresie wnioskowania. W poniższej tabeli przedstawiono przykład tego wzorca:

W tym miejscu dostępne są znane wartości elementu docelowego i funkcji w wersji 2023-05-01 do 2023-05-03. Brakujące wartości docelowe rozpoczynające się od 2023-05-04 wskazują, że okres wnioskowania rozpoczyna się od tej daty.
Rozwiązanie AutoML używa nowych danych kontekstowych do aktualizowania opóźnień i innych funkcji wyszukiwania, a także do aktualizowania modeli, takich jak ARIMA, które zachowują stan wewnętrzny. Ta operacja nie aktualizuje ani nie dopasowuje parametrów modelu.
Ocena modelu
Ocena to proces generowania przewidywań na zestawie testowym przechowywanym na podstawie danych treningowych i metryk obliczeniowych z tych przewidywań, które kierują decyzjami wdrażania modelu. W związku z tym istnieje tryb wnioskowania dostosowany do oceny modelu — prognozy stopniowej. Zapoznamy się z nią w poniższej sekcji podrzędnej.
Prognoza stopniowa
Najlepszym rozwiązaniem w celu oceny modelu prognozowania jest przerzucanie wytrenowanego prognosta w czasie w czasie w zestawie testowym, średnio metryki błędów w kilku oknach przewidywania. Ta procedura jest czasami nazywana backtestem w zależności od kontekstu. Najlepiej, aby zestaw testowy dla oceny był długi względem horyzontu prognozy modelu. W przeciwnym razie oszacowania błędu prognozowania mogą być statystycznie hałaśliwy i dlatego mniej wiarygodne.
Na poniższym diagramie przedstawiono prosty przykład z trzema oknami prognozowania:

Diagram przedstawia trzy parametry oceny stopniowej:
- Długość kontekstu lub ilość historii wymaganej przez model do utworzenia prognozy,
- Horyzont prognozy, czyli jak daleko w czasie prognostyk jest szkolony do przewidywania,
- Rozmiar kroku, który jest daleko przed upływem czasu, gdy okno kroczące przechodzi w każdej iteracji zestawu testowego.
Co ważne, kontekst jest rozwijany wraz z oknem prognozowania. Oznacza to, że rzeczywiste wartości z zestawu testowego są używane do tworzenia prognoz, gdy mieszczą się w bieżącym oknie kontekstu. Najnowsza data rzeczywistych wartości używanych dla danego okna prognozy jest nazywana godziną pochodzenia okna. W poniższej tabeli przedstawiono przykładowe dane wyjściowe z prognozy kroczącej z trzema oknami z horyzontem trzech dni i rozmiarem kroku jednego dnia:
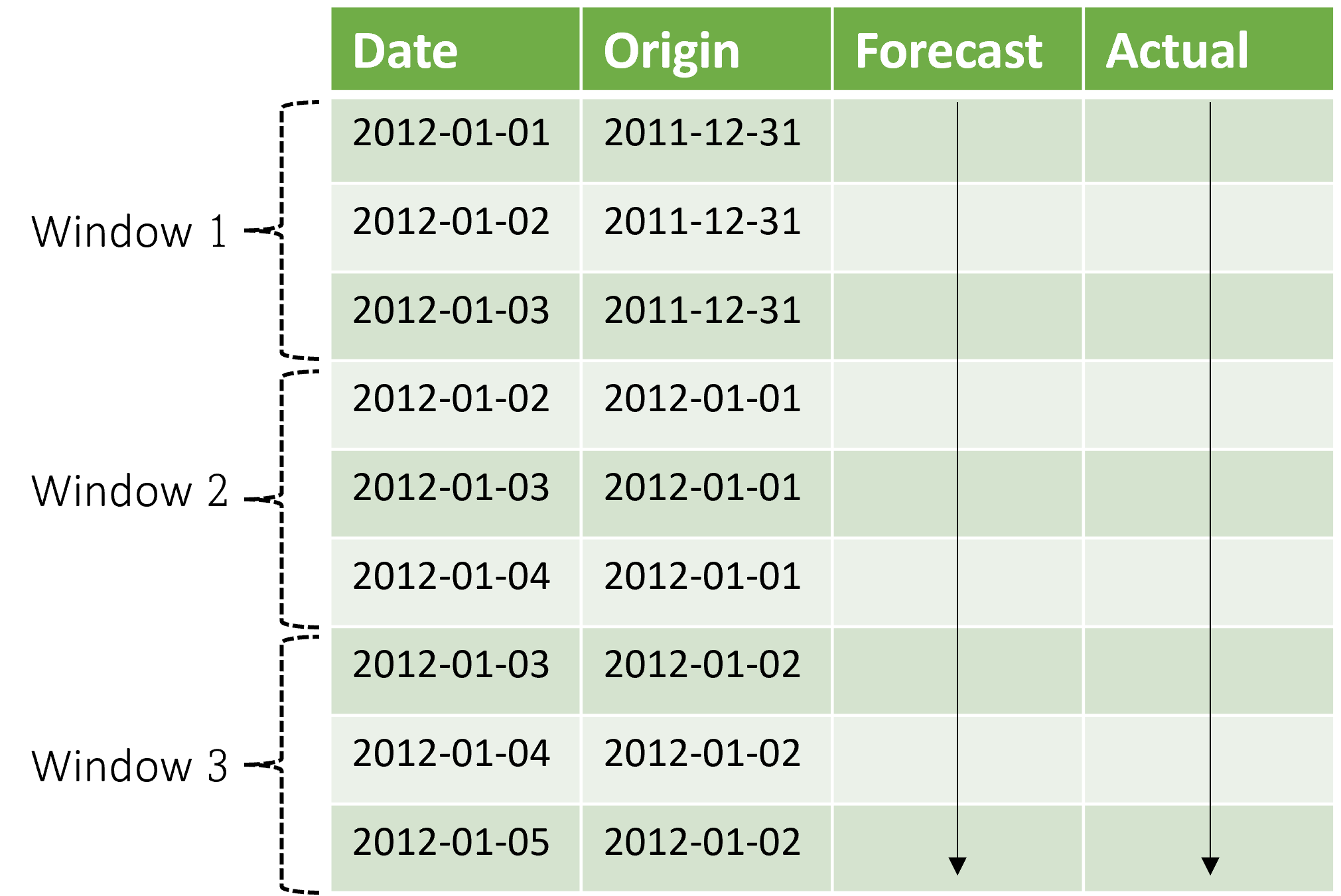
W takiej tabeli możemy zwizualizować prognozy w porównaniu z rzeczywistymi i obliczonymi żądanymi metrykami oceny. Potoki automatycznego uczenia maszynowego mogą generować prognozy stopniowe w zestawie testowym ze składnikiem wnioskowania.
Uwaga
Gdy okres testowy jest taka sama jak horyzont prognozy, prognoza krocząca daje pojedyncze okno prognoz aż do horyzontu.
Metryki oceny
Wybór podsumowania lub metryki oceny jest zwykle oparty na konkretnym scenariuszu biznesowym. Oto kilka typowych opcji:
- Wykresy obserwowanych wartości docelowych i prognozowanych w celu sprawdzenia, czy niektóre dynamiki danych są przechwytywane przez model,
- MAPE (średni bezwzględny błąd procentowy) między wartościami rzeczywistymi i prognozowanym,
- RMSE (główny błąd średniokwadratowy), prawdopodobnie z normalizacją, między wartościami rzeczywistymi i prognozowanymi,
- MAE (średni błąd bezwzględny), prawdopodobnie z normalizacją, między wartościami rzeczywistymi i prognozowanymi.
Istnieje wiele innych możliwości, w zależności od scenariusza biznesowego. Może być konieczne utworzenie własnych narzędzi przetwarzania końcowego na potrzeby obliczania metryk oceny na podstawie wyników wnioskowania lub prognoz kroczących. Aby uzyskać więcej informacji na temat metryk, zobacz sekcję dotyczącą metryk regresji i prognozowania .
Następne kroki
- Dowiedz się więcej o sposobie konfigurowania rozwiązania AutoML do trenowania modelu prognozowania szeregów czasowych.
- Dowiedz się, jak rozwiązanie AutoML używa uczenia maszynowego do tworzenia modeli prognozowania.
- Przeczytaj odpowiedzi na często zadawane pytania dotyczące prognozowania w rozwiązaniu AutoML.