Metodyka DevOps dla potoku pozyskiwania danych
W większości scenariuszy rozwiązanie do pozyskiwania danych to kompozycja skryptów, wywołań usługi i potoku organizujący wszystkie działania. Z tego artykułu dowiesz się, jak zastosować rozwiązania DevOps do cyklu projektowania wspólnego potoku pozyskiwania danych, który przygotowuje dane do trenowania modelu uczenia maszynowego. Potok jest tworzony przy użyciu następujących usług platformy Azure:
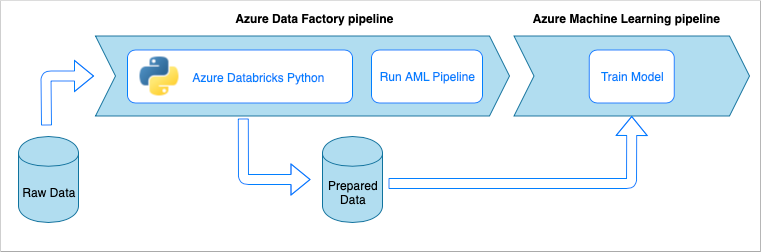
- Azure Data Factory: odczytuje nieprzetworzone dane i organizuje przygotowywanie danych.
- Azure Databricks: uruchamia notes języka Python, który przekształca dane.
- Azure Pipelines: automatyzuje proces ciągłej integracji i programowania.
Przepływ pracy potoku pozyskiwania danych
Potok pozyskiwania danych implementuje następujący przepływ pracy:
- Nieprzetworzone dane są odczytywane do potoku usługi Azure Data Factory (ADF).
- Potok usługi ADF wysyła dane do klastra usługi Azure Databricks, który uruchamia notes języka Python w celu przekształcenia danych.
- Dane są przechowywane w kontenerze obiektów blob, gdzie mogą być używane przez usługę Azure Machine Edukacja do trenowania modelu.
Omówienie ciągłej integracji i dostarczania
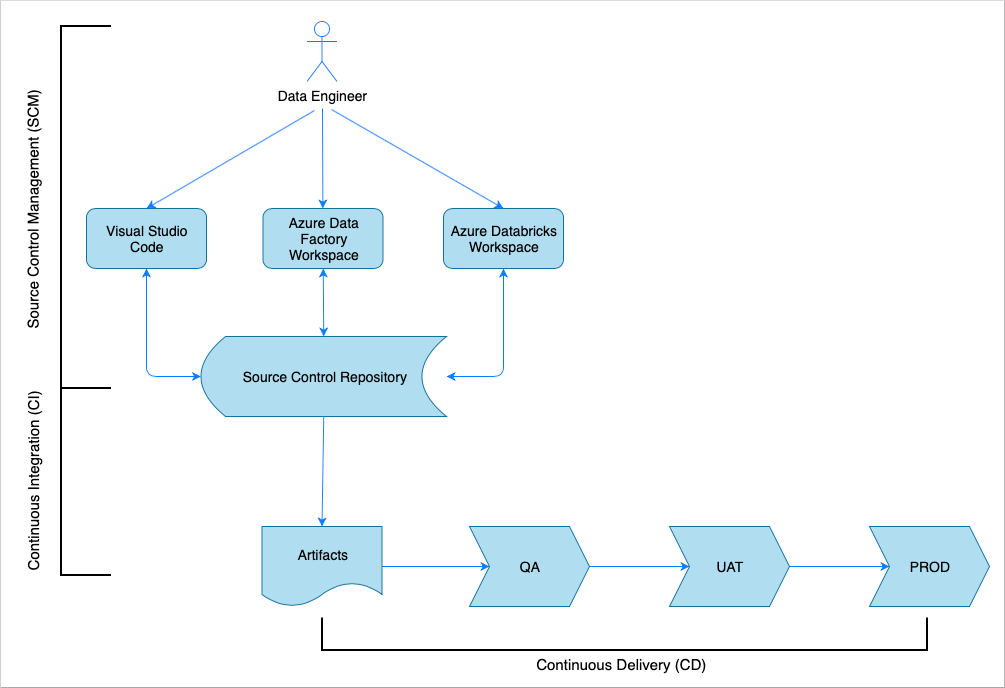
Podobnie jak w przypadku wielu rozwiązań programowych, istnieje zespół (na przykład inżynierowie danych s) pracujący nad nim. Współpracują i współdzielą te same zasoby platformy Azure, takie jak Azure Data Factory, Azure Databricks i Azure Storage. Kolekcja tych zasobów to środowisko programistyczne. Inżynierowie danych współtworzyją tę samą bazę kodu źródłowego.
System ciągłej integracji i dostarczania automatyzuje proces tworzenia, testowania i dostarczania (wdrażania) rozwiązania. Proces ciągłej integracji wykonuje następujące zadania:
- Tworzy kod
- Sprawdza je przy użyciu testów jakości kodu
- Uruchamia testy jednostkowe
- Tworzy artefakty, takie jak przetestowany kod i szablony usługi Azure Resource Manager
Proces ciągłego dostarczania (CD) wdraża artefakty w środowiskach podrzędnych.
W tym artykule pokazano, jak zautomatyzować procesy ciągłej integracji i ciągłego wdrażania za pomocą usługi Azure Pipelines.
Zarządzanie kontrolą źródła
Zarządzanie kontrolą źródła jest potrzebne do śledzenia zmian i włączania współpracy między członkami zespołu. Na przykład kod będzie przechowywany w repozytorium Azure DevOps, GitHub lub GitLab. Przepływ pracy współpracy jest oparty na modelu rozgałęziania.
Kod źródłowy notesu języka Python
Inżynierowie danych pracują z kodem źródłowym notesu języka Python lokalnie w środowisku IDE (na przykład Visual Studio Code) lub bezpośrednio w obszarze roboczym usługi Databricks. Po zakończeniu wprowadzania zmian kodu zostaną one scalone z repozytorium zgodnie z zasadami rozgałęziania.
Napiwek
Zalecamy przechowywanie kodu w .py plikach, a nie w .ipynb formacie jupyter Notebook. Poprawia czytelność kodu i umożliwia automatyczne sprawdzanie jakości kodu w procesie ciągłej integracji.
Kod źródłowy usługi Azure Data Factory
Kod źródłowy potoków usługi Azure Data Factory to kolekcja plików JSON generowanych przez obszar roboczy usługi Azure Data Factory. Zwykle inżynierowie danych pracują z projektantem wizualnym w obszarze roboczym usługi Azure Data Factory, a nie bezpośrednio z plikami kodu źródłowego.
Aby skonfigurować obszar roboczy do korzystania z repozytorium kontroli źródła, zobacz Tworzenie za pomocą integracji usługi Git z usługą Azure Repos.
Ciągła integracja (CI)
Ostatecznym celem procesu ciągłej integracji jest zebranie wspólnej pracy zespołu z kodu źródłowego i przygotowanie go do wdrożenia w środowiskach podrzędnych. Podobnie jak w przypadku zarządzania kodem źródłowym ten proces różni się w przypadku notesów języka Python i potoków usługi Azure Data Factory.
Ciągła integracja notesu języka Python
Proces ciągłej integracji notesów języka Python pobiera kod z gałęzi współpracy (na przykład master lub develop) i wykonuje następujące działania:
- Linting kodu
- Testowanie jednostek
- Zapisywanie kodu jako artefaktu
Poniższy fragment kodu przedstawia implementację tych kroków w potoku yaml usługi Azure DevOps:
steps:
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
- publish: $(Build.SourcesDirectory)
artifact: di-notebooks
Potok używa flake8 do tworzenia lintingu kodu w języku Python. Uruchamia testy jednostkowe zdefiniowane w kodzie źródłowym i publikuje wyniki lintingu i testu, aby były dostępne na ekranie wykonywania usługi Azure Pipelines.
Jeśli linting i testowanie jednostkowe zakończy się pomyślnie, potok skopiuje kod źródłowy do repozytorium artefaktów, które będzie używane przez kolejne kroki wdrażania.
Ciągła integracja usługi Azure Data Factory
Proces ciągłej integracji dla potoku usługi Azure Data Factory jest wąskim gardłem dla potoku pozyskiwania danych. Nie ma ciągłej integracji. Artefakt możliwy do wdrożenia dla usługi Azure Data Factory to kolekcja szablonów usługi Azure Resource Manager. Jedynym sposobem utworzenia tych szablonów jest kliknięcie przycisku publikowania w obszarze roboczym usługi Azure Data Factory.
- Inżynierowie danych scalają kod źródłowy z gałęzi funkcji z gałęzi współpracy, na przykład master lub develop.
- Osoba mająca przyznane uprawnienia klika przycisk publikowania, aby wygenerować szablony usługi Azure Resource Manager z kodu źródłowego w gałęzi współpracy.
- Obszar roboczy weryfikuje potoki (pomyśl o nim jako o lintingu i testowaniu jednostkowym), generuje szablony usługi Azure Resource Manager (pomyśl o nim jako o kompilowaniu) i zapisuje wygenerowane szablony w gałęzi technicznej adf_publish w tym samym repozytorium kodu (pomyśl o nim jako o publikowaniu artefaktów). Ta gałąź jest tworzona automatycznie przez obszar roboczy usługi Azure Data Factory.
Aby uzyskać więcej informacji na temat tego procesu, zobacz Ciągła integracja i ciągłe dostarczanie w usłudze Azure Data Factory.
Ważne jest, aby upewnić się, że wygenerowane szablony usługi Azure Resource Manager są niezależne od środowiska. Oznacza to, że wszystkie wartości, które mogą się różnić między środowiskami, są parametryzowane. Usługa Azure Data Factory jest wystarczająco inteligentna, aby uwidocznić większość takich wartości jak parametry. Na przykład w poniższym szablonie właściwości połączenia z obszarem roboczym usługi Azure Machine Edukacja są widoczne jako parametry:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
"AzureMLService_servicePrincipalKey": {
"value": ""
},
"AzureMLService_properties_typeProperties_subscriptionId": {
"value": "0fe1c235-5cfa-4152-17d7-5dff45a8d4ba"
},
"AzureMLService_properties_typeProperties_resourceGroupName": {
"value": "devops-ds-rg"
},
"AzureMLService_properties_typeProperties_servicePrincipalId": {
"value": "6e35e589-3b22-4edb-89d0-2ab7fc08d488"
},
"AzureMLService_properties_typeProperties_tenant": {
"value": "72f988bf-86f1-41af-912b-2d7cd611db47"
}
}
}
Możesz jednak uwidocznić właściwości niestandardowe, które nie są domyślnie obsługiwane przez obszar roboczy usługi Azure Data Factory. W scenariuszu tego artykułu potok usługi Azure Data Factory wywołuje notes języka Python przetwarzający dane. Notes akceptuje parametr o nazwie pliku danych wejściowych.
import pandas as pd
import numpy as np
data_file_name = getArgument("data_file_name")
data = pd.read_csv(data_file_name)
labels = np.array(data['target'])
...
Ta nazwa różni się w przypadku środowisk deweloperskich, QA, UAT i PROD. W złożonym potoku z wieloma działaniami może istnieć kilka właściwości niestandardowych. Dobrym rozwiązaniem jest zebranie wszystkich tych wartości w jednym miejscu i zdefiniowanie ich jako zmiennych potoku:
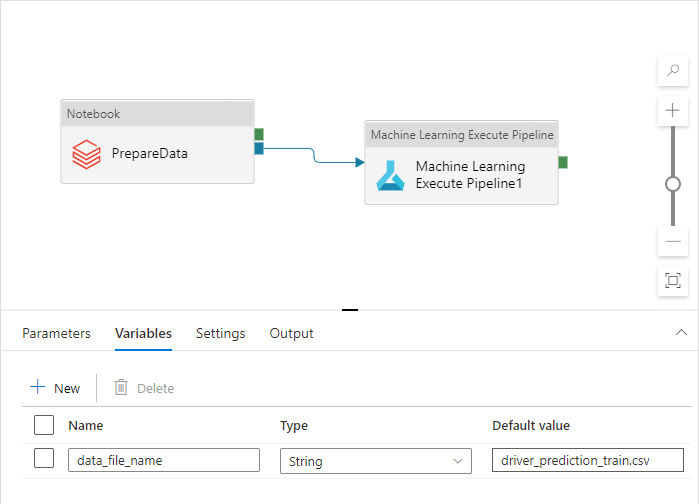
Działania potoku mogą odwoływać się do zmiennych potoku podczas ich używania:
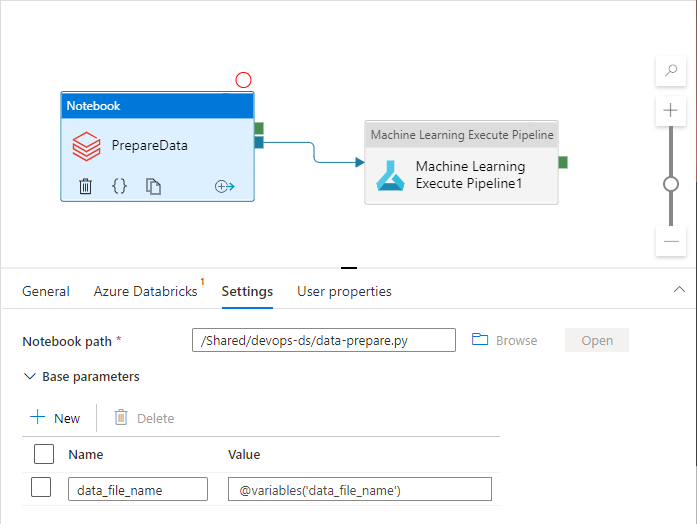
Obszar roboczy usługi Azure Data Factory domyślnie nie uwidacznia zmiennych potoku jako parametrów szablonów usługi Azure Resource Manager. Obszar roboczy używa domyślnego szablonu parametryzacji dyktując, jakie właściwości potoku powinny być uwidocznione jako parametry szablonu usługi Azure Resource Manager. Aby dodać zmienne potoku do listy, zaktualizuj "Microsoft.DataFactory/factories/pipelines" sekcję domyślnego szablonu parametryzacji przy użyciu następującego fragmentu kodu i umieść plik json wyniku w katalogu głównym folderu źródłowego:
"Microsoft.DataFactory/factories/pipelines": {
"properties": {
"variables": {
"*": {
"defaultValue": "="
}
}
}
}
Wymusi to dodanie zmiennych do listy parametrów w obszarze roboczym usługi Azure Data Factory po kliknięciu przycisku publikowania :
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
...
"data-ingestion-pipeline_properties_variables_data_file_name_defaultValue": {
"value": "driver_prediction_train.csv"
}
}
}
Wartości w pliku JSON są wartościami domyślnymi skonfigurowanymi w definicji potoku. Oczekuje się, że zostaną one zastąpione wartościami środowiska docelowego podczas wdrażania szablonu usługi Azure Resource Manager.
Ciągłe dostarczanie (CD)
Proces ciągłego dostarczania pobiera artefakty i wdraża je w pierwszym środowisku docelowym. Upewnia się, że rozwiązanie działa, uruchamiając testy. Jeśli działanie zakończy się pomyślnie, będzie kontynuowane w następnym środowisku.
Usługa Azure Pipelines usługi CD składa się z wielu etapów reprezentujących środowiska. Każdy etap zawiera wdrożenia i zadania , które wykonują następujące czynności:
- Wdrażanie notesu języka Python w obszarze roboczym usługi Azure Databricks
- Wdrażanie potoku usługi Azure Data Factory
- Uruchamianie potoku
- Sprawdzanie wyniku pozyskiwania danych
Etapy potoku można skonfigurować za pomocą zatwierdzeń i bram , które zapewniają dodatkową kontrolę nad rozwojem procesu wdrażania za pośrednictwem łańcucha środowisk.
Wdrażanie notesu języka Python
Poniższy fragment kodu definiuje wdrożenie usługi Azure Pipeline, które kopiuje notes języka Python do klastra usługi Databricks:
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
Artefakty generowane przez ciągłą integrację są automatycznie kopiowane do agenta wdrażania i są dostępne w folderze $(Pipeline.Workspace) . W takim przypadku zadanie wdrażania odwołuje się do artefaktu di-notebooks zawierającego notes języka Python. To wdrożenie używa rozszerzenia Usługi Azure DevOps usługi Databricks do kopiowania plików notesu do obszaru roboczego usługi Databricks.
Etap Deploy_to_QA zawiera odwołanie do devops-ds-qa-vg grupy zmiennych zdefiniowanej w projekcie usługi Azure DevOps. Kroki w tym etapie odnoszą się do zmiennych z tej grupy zmiennych (na przykład $(DATABRICKS_URL) i $(DATABRICKS_TOKEN)). Chodzi o to, Deploy_to_UATże następny etap (na przykład ) będzie działać z tymi samymi nazwami zmiennych zdefiniowanymi we własnej grupie zmiennych o zakresie UAT.
Wdrażanie potoku usługi Azure Data Factory
Artefakt możliwy do wdrożenia dla usługi Azure Data Factory to szablon usługi Azure Resource Manager. Zostanie wdrożona za pomocą zadania wdrażania grupy zasobów platformy Azure, jak pokazano w poniższym fragmencie kodu:
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
Wartość parametru nazwy pliku danych pochodzi ze $(DATA_FILE_NAME) zmiennej zdefiniowanej w grupie zmiennych etapowych QA. Podobnie wszystkie parametry zdefiniowane w pliku ARMTemplateForFactory.json można zastąpić. Jeśli tak nie jest, zostaną użyte wartości domyślne.
Uruchamianie potoku i sprawdzanie wyniku pozyskiwania danych
Następnym krokiem jest upewnienie się, że wdrożone rozwiązanie działa. Poniższa definicja zadania uruchamia potok usługi Azure Data Factory ze skryptem programu PowerShell i wykonuje notes języka Python w klastrze usługi Azure Databricks. Notes sprawdza, czy dane zostały pozyskane poprawnie i weryfikuje plik danych wynikowych o $(bin_FILE_NAME) nazwie.
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'
Ostatnie zadanie w zadaniu sprawdza wynik wykonania notesu. Jeśli zwraca błąd, ustawia stan wykonania potoku na niepowodzenie.
Łączenie elementów
Kompletna ciągła integracja/ciągłe wdrażanie w usłudze Azure Pipeline składa się z następujących etapów:
- ELEMENT KONFIGURACJI
- Wdrażanie w kontroli jakości
- Wdrażanie w usłudze Databricks i wdrażanie w usłudze ADF
- Test integracji
Zawiera on wiele etapów wdrażania równych liczbie posiadanych środowisk docelowych. Każdy etap wdrażania zawiera dwa wdrożenia, które są uruchamiane równolegle i zadanie uruchamiane po wdrożeniach w celu przetestowania rozwiązania w środowisku.
Przykładowa implementacja potoku jest składana w następującym fragmencie kodu yaml :
variables:
- group: devops-ds-vg
stages:
- stage: 'CI'
displayName: 'CI'
jobs:
- job: "CI_Job"
displayName: "CI Job"
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- script: pip install --upgrade flake8 flake8_formatter_junit_xml
displayName: 'Install flake8'
- checkout: self
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
# The CI stage produces two artifacts (notebooks and ADF pipelines).
# The pipelines Azure Resource Manager templates are stored in a technical branch "adf_publish"
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/code/dataingestion
artifact: di-notebooks
- checkout: git://${{variables['System.TeamProject']}}@adf_publish
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/devops-ds-adf
artifact: adf-pipelines
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'