Wdrażanie modelu w punkcie końcowym online przy użyciu niestandardowego kontenera
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Dowiedz się, jak za pomocą kontenera niestandardowego wdrożyć model w punkcie końcowym online w usłudze Azure Machine Edukacja.
Wdrożenia kontenerów niestandardowych mogą używać serwerów internetowych innych niż domyślny serwer platformy Python Flask używany przez usługę Azure Machine Edukacja. Użytkownicy tych wdrożeń nadal mogą korzystać z wbudowanych funkcji monitorowania, skalowania, alertów i uwierzytelniania usługi Azure Machine Edukacja.
W poniższej tabeli wymieniono różne przykłady wdrożenia, które używają kontenerów niestandardowych, takich jak TensorFlow Serving, TorchServe, Triton Inference Server, Plumber R package i Azure Machine Edukacja Inference Minimal image.
| Przykład | Skrypt (interfejs wiersza polecenia) | opis |
|---|---|---|
| minimalna/wielomodelowa | deploy-custom-container-minimal-multimodel | Wdróż wiele modeli w jednym wdrożeniu, rozszerzając obraz Azure Machine Edukacja Inference Minimal. |
| minimalny/pojedynczy model | deploy-custom-container-minimal-single-model | Wdróż pojedynczy model, rozszerzając obraz Azure Machine Edukacja Wnioskowanie minimalne. |
| mlflow/multideployment-scikit | deploy-custom-container-mlflow-multideployment-scikit | Wdróż dwa modele MLFlow z różnymi wymaganiami języka Python w dwóch oddzielnych wdrożeniach za jednym punktem końcowym przy użyciu usługi Azure Machine Edukacja obrazu minimalnego wnioskowania. |
| r/multimodel-plumber | deploy-custom-container-r-multimodel-plumber | Wdrażanie trzech modeli regresji w jednym punkcie końcowym przy użyciu pakietu Plumber R |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | Wdróż model Half Plus Two przy użyciu kontenera niestandardowego Obsługującego bibliotekę TensorFlow przy użyciu standardowego procesu rejestracji modelu. |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | Wdróż model Half Plus Two przy użyciu kontenera niestandardowego TensorFlow Obsługującego model zintegrowany z obrazem. |
| torchserve/gęsta sieć | deploy-custom-container-torchserve-densenet | Wdrażanie pojedynczego modelu przy użyciu niestandardowego kontenera TorchServe. |
| torchserve/huggingface-textgen | deploy-custom-container-torchserve-huggingface-textgen | Wdróż modele rozpoznawania twarzy w punkcie końcowym online i postępuj zgodnie z przykładem Hugging Face Transformers TorchServe. |
| triton/pojedynczy model | deploy-custom-container-triton-single-model | Wdrażanie modelu Triton przy użyciu kontenera niestandardowego |
Ten artykuł koncentruje się na obsłudze modelu TensorFlow za pomocą usługi TensorFlow (TF).
Ostrzeżenie
Firma Microsoft może nie być w stanie rozwiązać problemów spowodowanych przez obraz niestandardowy. Jeśli wystąpią problemy, może zostać wyświetlony monit o użycie obrazu domyślnego lub jednego z obrazów, które firma Microsoft udostępnia, aby sprawdzić, czy problem jest specyficzny dla twojego obrazu.
Wymagania wstępne
Przed wykonaniem kroków opisanych w tym artykule upewnij się, że masz następujące wymagania wstępne:
Obszar roboczy usługi Azure Machine Learning. Jeśli go nie masz, wykonaj kroki opisane w artykule Szybki start: tworzenie zasobów obszaru roboczego, aby je utworzyć.
Interfejs wiersza polecenia platformy
mlAzure i rozszerzenie lub zestaw Azure Machine Edukacja python SDK w wersji 2:Aby zainstalować interfejs wiersza polecenia platformy Azure i rozszerzenie, zobacz Instalowanie, konfigurowanie i używanie interfejsu wiersza polecenia (wersja 2).
Ważne
W przykładach interfejsu wiersza polecenia w tym artykule założono, że używasz powłoki Bash (lub zgodnej). Na przykład z systemu Linux lub Podsystem Windows dla systemu Linux.
Aby zainstalować zestaw PYTHON SDK w wersji 2, użyj następującego polecenia:
pip install azure-ai-ml azure-identityAby zaktualizować istniejącą instalację zestawu SDK do najnowszej wersji, użyj następującego polecenia:
pip install --upgrade azure-ai-ml azure-identityAby uzyskać więcej informacji, zobacz Install the Python SDK v2 for Azure Machine Edukacja (Instalowanie zestawu SDK języka Python w wersji 2 dla usługi Azure Machine Edukacja).
Użytkownik lub używana jednostka usługi musi mieć dostęp współautora do grupy zasobów platformy Azure, która zawiera obszar roboczy. Jeśli skonfigurowano obszar roboczy przy użyciu artykułu Szybki start, masz taką grupę zasobów.
Aby wdrożyć lokalnie, aparat platformy Docker musi działać lokalnie. Ten krok jest zdecydowanie zalecany. Pomaga to debugować problemy.
Pobieranie kodu źródłowego
Aby wykonać czynności opisane w tym samouczku, sklonuj kod źródłowy z usługi GitHub.
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Inicjowanie zmiennych środowiskowych
Zdefiniuj zmienne środowiskowe:
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
Pobieranie modelu TensorFlow
Pobierz i rozpakuj model, który dzieli dane wejściowe przez dwa i dodaje 2 do wyniku:
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
Uruchamianie obrazu obsługującego tf lokalnie w celu przetestowania, czy działa
Użyj platformy Docker, aby uruchomić obraz lokalnie na potrzeby testowania:
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
Sprawdź, czy możesz wysyłać żądania liveness i oceniania do obrazu
Najpierw sprawdź, czy kontener jest aktywny, co oznacza, że proces wewnątrz kontenera jest nadal uruchomiony. Powinna zostać wyświetlona odpowiedź 200 (OK).
curl -v http://localhost:8501/v1/models/$MODEL_NAME
Następnie sprawdź, czy możesz uzyskać przewidywania dotyczące danych bez etykiet:
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
Zatrzymywanie obrazu
Po przetestowaniu lokalnie zatrzymaj obraz:
docker stop tfserving-test
Wdrażanie punktu końcowego online na platformie Azure
Następnie wdróż punkt końcowy online na platformie Azure.
Tworzenie pliku YAML dla punktu końcowego i wdrożenia
Wdrożenie w chmurze można skonfigurować przy użyciu języka YAML. Zapoznaj się z przykładowym kodem YAML w tym przykładzie:
tfserving-endpoint.yml
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
tfserving-deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: {{MODEL_VERSION}}
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/{{MODEL_VERSION}}
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
Istnieje kilka ważnych pojęć, które należy zauważyć w tym parametrze YAML/Python:
Trasa gotowości a trasa aktualności
Serwer HTTP definiuje ścieżki zarówno dla gotowości na żywo, jak i gotowości. Trasa aktualności służy do sprawdzania, czy serwer jest uruchomiony. Trasa gotowości służy do sprawdzania, czy serwer jest gotowy do pracy. W wnioskowaniu uczenia maszynowego serwer może odpowiedzieć 200 OK na żądanie aktualności przed załadowaniem modelu. Serwer może odpowiedzieć 200 OK na żądanie gotowości dopiero po załadowaniu modelu do pamięci.
Aby uzyskać więcej informacji na temat sond na żywo i gotowości, zobacz dokumentację platformy Kubernetes.
Zwróć uwagę, że to wdrożenie używa tej samej ścieżki zarówno dla gotowości, jak i dostępności, ponieważ obsługa serwera TF definiuje tylko trasę aktualności.
Lokalizowanie zainstalowanego modelu
Podczas wdrażania modelu jako punktu końcowego online usługa Azure Machine Edukacja instaluje model w punkcie końcowym. Instalowanie modelu umożliwia wdrażanie nowych wersji modelu bez konieczności tworzenia nowego obrazu platformy Docker. Domyślnie model zarejestrowany przy użyciu nazwy foo i wersji 1 znajduje się w następującej ścieżce wewnątrz wdrożonego kontenera: /var/azureml-app/azureml-models/foo/1
Jeśli na przykład masz strukturę katalogów /azureml-examples/cli/endpoints/online/custom-container na komputerze lokalnym, gdzie model ma nazwę half_plus_two:
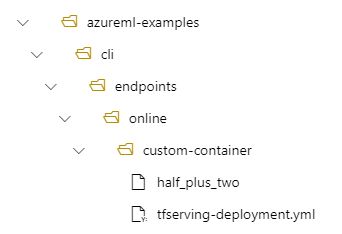
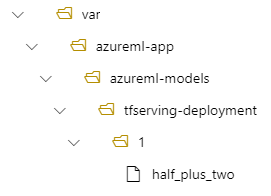
A tfserving-deployment.yml zawiera:
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
Następnie model będzie znajdować się w obszarze /var/azureml-app/azureml-models/tfserving-deployment/1 we wdrożeniu:
Opcjonalnie możesz skonfigurować plik model_mount_path. Umożliwia zmianę ścieżki, w której jest zainstalowany model.
Ważne
Musi model_mount_path być prawidłową ścieżką bezwzględną w systemie Linux (system operacyjny obrazu kontenera).
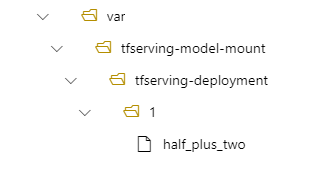
Na przykład możesz mieć model_mount_path parametr w tfserving-deployment.yml:
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
model_mount_path: /var/tfserving-model-mount
.....
Następnie model znajduje się w lokalizacji /var/tfserving-model-mount/tfserving-deployment/1 we wdrożeniu. Pamiętaj, że nie jest już w obszarze azureml-app/azureml-models, ale w określonej ścieżce instalacji:
Tworzenie punktu końcowego i wdrożenia
Teraz, gdy już wiesz, jak utworzono kod YAML, utwórz punkt końcowy.
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving-endpoint.yml
Tworzenie wdrożenia może potrwać kilka minut.
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving-deployment.yml --all-traffic
Wywoływanie punktu końcowego
Po zakończeniu wdrażania sprawdź, czy możesz wysłać żądanie oceniania do wdrożonego punktu końcowego.
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
Usuwanie punktu końcowego
Teraz, gdy punkt końcowy został pomyślnie wygenerowany, możesz go usunąć:
az ml online-endpoint delete --name tfserving-endpoint