Przesyłanie zadań platformy Spark w usłudze Azure Machine Edukacja
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Usługa Azure Machine Edukacja obsługuje przesyłanie autonomicznych zadań uczenia maszynowego i tworzenie potoków uczenia maszynowego obejmujących wiele kroków przepływu pracy uczenia maszynowego. Usługa Azure Machine Edukacja obsługuje zarówno autonomiczne tworzenie zadań platformy Spark, jak i tworzenie składników platformy Spark wielokrotnego użytku, których mogą używać potoki usługi Azure Machine Edukacja. W tym artykule dowiesz się, jak przesyłać zadania platformy Spark przy użyciu:
- Interfejs użytkownika usługi Azure Machine Edukacja Studio
- Interfejs wiersza polecenia usługi Azure Machine Learning
- Azure Machine Learning SDK
Aby uzyskać więcej informacji o pojęciach dotyczących platformy Apache Spark w usłudze Azure Machine Edukacja, zobacz ten zasób.
Wymagania wstępne
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (bieżąca)
- Subskrypcja platformy Azure; Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto .
- Obszar roboczy usługi Azure Machine Learning. Zobacz Tworzenie zasobów obszaru roboczego.
- Utwórz wystąpienie obliczeniowe usługi Azure Machine Edukacja.
- Zainstaluj interfejs wiersza polecenia usługi Azure Machine Edukacja.
- (Opcjonalnie): dołączona pula platformy Synapse Spark w obszarze roboczym usługi Azure Machine Edukacja.
Uwaga
- Aby dowiedzieć się więcej na temat dostępu do zasobów podczas korzystania z usługi Azure Machine Edukacja bezserwerowych obliczeń platformy Spark i dołączonej puli platformy Synapse Spark, zobacz Zapewnianie dostępu do zasobów dla zadań platformy Spark.
- Usługa Azure Machine Edukacja udostępnia udostępnioną pulę przydziałów, z której wszyscy użytkownicy mogą uzyskiwać dostęp do limitu przydziału zasobów obliczeniowych w celu przeprowadzania testów przez ograniczony czas. W przypadku korzystania z bezserwerowych obliczeń platformy Spark usługa Azure Machine Edukacja umożliwia krótki dostęp do tego udostępnionego limitu przydziału.
Dołączanie tożsamości zarządzanej przypisanej przez użytkownika przy użyciu interfejsu wiersza polecenia w wersji 2
- Utwórz plik YAML, który definiuje tożsamość zarządzaną przypisaną przez użytkownika, która powinna być dołączona do obszaru roboczego:
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} - Za pomocą parametru
--fileużyj pliku YAML w poleceniuaz ml workspace update, aby dołączyć tożsamość zarządzaną przypisaną przez użytkownika:az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
Dołączanie tożsamości zarządzanej przypisanej przez użytkownika przy użyciu polecenia ARMClient
- Zainstaluj
ARMClientprogram , proste narzędzie wiersza polecenia, które wywołuje interfejs API usługi Azure Resource Manager. - Utwórz plik JSON, który definiuje tożsamość zarządzaną przypisaną przez użytkownika, która powinna być dołączona do obszaru roboczego:
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - Aby dołączyć tożsamość zarządzaną przypisaną przez użytkownika do obszaru roboczego, wykonaj następujące polecenie w wierszu polecenia programu PowerShell lub wierszu polecenia.
armclient PATCH https://management.azure.com/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
Uwaga
- Aby zapewnić pomyślne wykonanie zadania platformy Spark, przypisz role Współautor i Współautor danych obiektu blob usługi Storage na koncie usługi Azure Storage używanym na potrzeby danych wejściowych i wyjściowych do tożsamości używanej przez zadanie platformy Spark
- Dostęp do sieci publicznej powinien być włączony w obszarze roboczym usługi Azure Synapse, aby zapewnić pomyślne wykonanie zadania platformy Spark przy użyciu dołączonej puli usługi Synapse Spark.
- Jeśli dołączona pula usługi Synapse Spark wskazuje pulę usługi Synapse Spark, w obszarze roboczym usługi Azure Synapse, z którą jest skojarzona zarządzana sieć wirtualna, należy skonfigurować zarządzany prywatny punkt końcowy do konta magazynu w celu zapewnienia dostępu do danych.
- Przetwarzanie bezserwerowe platformy Spark obsługuje usługę Azure Machine Edukacja zarządzaną siecią wirtualną. Jeśli sieć zarządzana jest aprowizowana dla bezserwerowych obliczeń platformy Spark, odpowiednie prywatne punkty końcowe dla konta magazynu powinny być również aprowizowane w celu zapewnienia dostępu do danych.
Przesyłanie autonomicznego zadania platformy Spark
Po wprowadzeniu niezbędnych zmian w parametryzacji skryptów języka Python skrypt języka Python opracowany przez interakcyjne uzdatnianie danych może służyć do przesyłania zadania wsadowego do przetwarzania większej ilości danych. Proste zadanie rozmieszczania danych wsadowych można przesłać jako autonomiczne zadanie platformy Spark.
Zadanie platformy Spark wymaga skryptu języka Python, który przyjmuje argumenty, które można opracowywać przy użyciu modyfikacji kodu języka Python opracowanego na podstawie interakcyjnego uzdatniania danych. Przykładowy skrypt języka Python jest pokazany tutaj.
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Uwaga
Ten przykładowy kod w języku Python używa metody pyspark.pandas. Obsługuje to tylko środowisko uruchomieniowe platformy Spark w wersji 3.2 lub nowszej.
Powyższy skrypt przyjmuje dwa argumenty --titanic_data i --wrangled_data, które przekazują odpowiednio ścieżkę danych wejściowych i folderu wyjściowego.
- Interfejs wiersza polecenia platformy Azure
- Zestaw SDK dla języka Python
- Interfejs użytkownika programu Studio
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (bieżąca)
Aby utworzyć zadanie, autonomiczne zadanie platformy Spark można zdefiniować jako plik specyfikacji YAML, którego można użyć w poleceniu az ml job create za pomocą parametru --file . Zdefiniuj te właściwości w pliku YAML:
Właściwości YAML w specyfikacji zadania platformy Spark
type- ustaw wartośćspark.code— definiuje lokalizację folderu zawierającego kod źródłowy i skrypty dla tego zadania.entry— definiuje punkt wejścia dla zadania. Powinna obejmować jedną z następujących właściwości:file— definiuje nazwę skryptu języka Python, który służy jako punkt wejścia dla zadania.
py_files— definiuje listę.zipplików ,.egglub.py, które mają zostać umieszczone wPYTHONPATHobiekcie , w celu pomyślnego wykonania zadania. Ta właściwość jest opcjonalna.jars— definiuje listę.jarplików, które mają być uwzględniane w sterowniku Spark, oraz funkcja wykonawczaCLASSPATH, w celu pomyślnego wykonania zadania. Ta właściwość jest opcjonalna.files— definiuje listę plików, które powinny zostać skopiowane do katalogu roboczego każdego wykonawcy, w celu pomyślnego wykonania zadania. Ta właściwość jest opcjonalna.archives— definiuje listę archiwów, które powinny zostać wyodrębnione do katalogu roboczego każdego wykonawcy, w celu pomyślnego wykonania zadania. Ta właściwość jest opcjonalna.conf— definiuje następujące właściwości sterownika i funkcji wykonawczej platformy Spark:spark.driver.cores: liczba rdzeni sterownika Spark.spark.driver.memory: przydzielona pamięć dla sterownika Spark w gigabajtach (GB).spark.executor.cores: liczba rdzeni funkcji wykonawczej platformy Spark.spark.executor.memory: alokacja pamięci dla funkcji wykonawczej platformy Spark w gigabajtach (GB).spark.dynamicAllocation.enabled— określa, czy funkcje wykonawcze powinny być przydzielane dynamicznie, jakoTruewartość lubFalse.- Jeśli włączono dynamiczną alokację funkcji wykonawczych, zdefiniuj następujące właściwości:
spark.dynamicAllocation.minExecutors— minimalna liczba wystąpień funkcji wykonawczych platformy Spark dla alokacji dynamicznej.spark.dynamicAllocation.maxExecutors— maksymalna liczba wystąpień funkcji wykonawczych platformy Spark dla alokacji dynamicznej.
- Jeśli dynamiczna alokacja funkcji wykonawczych jest wyłączona, zdefiniuj tę właściwość:
spark.executor.instances— liczba wystąpień funkcji wykonawczej platformy Spark.
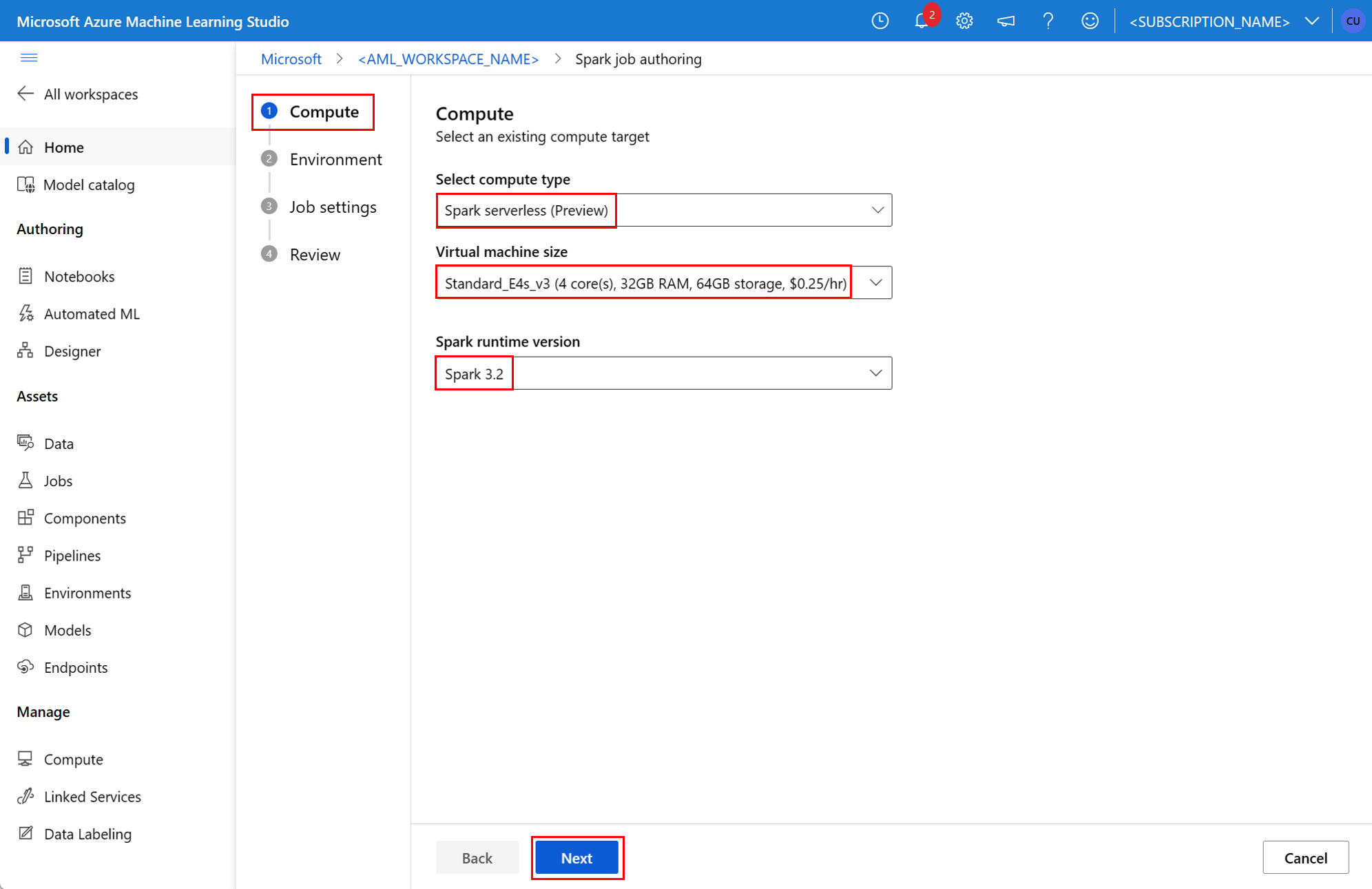
environment— środowisko usługi Azure Machine Edukacja do uruchamiania zadania.args— argumenty wiersza polecenia, które powinny zostać przekazane do skryptu języka Python punktu wejścia zadania. Zobacz plik specyfikacji YAML podany tutaj, aby zapoznać się z przykładem.resources— ta właściwość definiuje zasoby, które mają być używane przez maszynę platformy Azure Edukacja bezserwerowych obliczeń platformy Spark. Używa on następujących właściwości:instance_type— typ wystąpienia obliczeniowego, który ma być używany dla puli Spark. Obecnie obsługiwane są następujące typy wystąpień:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
runtime_version— definiuje wersję środowiska uruchomieniowego platformy Spark. Obecnie obsługiwane są następujące wersje środowiska uruchomieniowego platformy Spark:3.23.3Ważne
Środowisko uruchomieniowe usługi Azure Synapse dla platformy Apache Spark: anonsy
- Środowisko uruchomieniowe usługi Azure Synapse dla platformy Apache Spark 3.2:
- Data ogłoszenia EOLA: 8 lipca 2023 r.
- Data zakończenia wsparcia: 8 lipca 2024 r. Po tej dacie środowisko uruchomieniowe zostanie wyłączone.
- Aby zapewnić ciągłą obsługę i optymalną wydajność, zalecamy migrację do platformy Apache Spark 3.3.
- Środowisko uruchomieniowe usługi Azure Synapse dla platformy Apache Spark 3.2:
Oto przykład:
resources: instance_type: standard_e8s_v3 runtime_version: "3.3"compute— ta właściwość definiuje nazwę dołączonej puli platformy Synapse Spark, jak pokazano w tym przykładzie:compute: mysparkpoolinputs— ta właściwość definiuje dane wejściowe dla zadania platformy Spark. Dane wejściowe zadania platformy Spark mogą być wartością literału lub danymi przechowywanymi w pliku lub folderze.- Wartość literału może być liczbą, wartością logiczną lub ciągiem. Poniżej przedstawiono kilka przykładów:
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value - Dane przechowywane w pliku lub folderze powinny być zdefiniowane przy użyciu następujących właściwości:
type- ustaw tę właściwość nauri_file, luburi_folder, dla danych wejściowych zawartych odpowiednio w pliku lub folderze.path— identyfikator URI danych wejściowych, takich jakazureml://,abfss://lubwasbs://.mode- ustaw tę właściwość nadirect. W tym przykładzie przedstawiono definicję danych wejściowych zadania, które mogą być określane jako$${inputs.titanic_data}}:inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
- Wartość literału może być liczbą, wartością logiczną lub ciągiem. Poniżej przedstawiono kilka przykładów:
outputs— ta właściwość definiuje dane wyjściowe zadania platformy Spark. Dane wyjściowe zadania platformy Spark można zapisywać w pliku lub w lokalizacji folderu, która jest zdefiniowana przy użyciu następujących trzech właściwości:type— tę właściwość można ustawić nauri_fileluburi_folderdo zapisywania danych wyjściowych odpowiednio do pliku lub folderu.path— ta właściwość definiuje identyfikator URI lokalizacji wyjściowej, taki jakazureml://,abfss://lubwasbs://.mode- ustaw tę właściwość nadirect. W tym przykładzie przedstawiono definicję danych wyjściowych zadania, które mogą być określane jako${{outputs.wrangled_data}}:outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
identity— ta opcjonalna właściwość definiuje tożsamość używaną do przesyłania tego zadania. Może zawieraćuser_identitywartości imanaged. Jeśli specyfikacja YAML nie definiuje tożsamości, zadanie platformy Spark używa tożsamości domyślnej.
Autonomiczne zadanie platformy Spark
W tym przykładzie specyfikacja YAML przedstawia autonomiczne zadanie platformy Spark. Korzysta ona z usługi Azure Machine Edukacja bezserwerowych zasobów obliczeniowych platformy Spark:
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.3"
Uwaga
Aby użyć dołączonej puli usługi Synapse Spark, zdefiniuj compute właściwość w przykładowym pliku specyfikacji YAML pokazanym wcześniej, a nie we resources właściwości .
Pokazane wcześniej pliki YAML mogą być używane w az ml job create poleceniu z parametrem --file w celu utworzenia autonomicznego zadania platformy Spark, jak pokazano poniżej:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Powyższe polecenie można wykonać za pomocą polecenia:
- terminal wystąpienia obliczeniowego usługi Azure Machine Edukacja.
- terminal programu Visual Studio Code połączony z wystąpieniem obliczeniowym usługi Azure Machine Edukacja.
- komputer lokalny z zainstalowanym interfejsem wiersza polecenia usługi Azure Machine Edukacja.
Składnik platformy Spark w zadaniu potoku
Składnik platformy Spark zapewnia elastyczność używania tego samego składnika w wielu potokach usługi Azure Machine Edukacja jako krok potoku.
- Interfejs wiersza polecenia platformy Azure
- Zestaw SDK dla języka Python
- Interfejs użytkownika programu Studio
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (bieżąca)
Składnia YAML składnika platformy Spark przypomina składnię YAML dla specyfikacji zadania platformy Spark na większość sposobów. Te właściwości są definiowane inaczej w specyfikacji YAML składnika Spark:
name— nazwa składnika Spark.version— wersja składnika Spark.display_name— nazwa składnika Spark do wyświetlenia w interfejsie użytkownika i gdzie indziej.description— opis składnika Spark.inputs— ta właściwość jest podobna doinputswłaściwości opisanej w składni YAML dla specyfikacji zadania platformy Spark, z tą różnicą, że nie definiujepathwłaściwości. Ten fragment kodu przedstawia przykład właściwości składnikainputsplatformy Spark:inputs: titanic_data: type: uri_file mode: directoutputs— ta właściwość jest podobna do właściwości opisanejoutputsw składni YAML dla specyfikacji zadania platformy Spark, z tą różnicą, że nie definiujepathwłaściwości. Ten fragment kodu przedstawia przykład właściwości składnikaoutputsplatformy Spark:outputs: wrangled_data: type: uri_folder mode: direct
Uwaga
Składnik platformy Spark nie definiuje identitywłaściwości ani resourcescompute . Plik specyfikacji YAML potoku definiuje te właściwości.
Ten plik specyfikacji YAML zawiera przykład składnika platformy Spark:
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
Składnik Spark zdefiniowany w powyższym pliku specyfikacji YAML może być używany w zadaniu potoku usługi Azure Machine Edukacja. Zobacz schemat YAML zadania potoku , aby dowiedzieć się więcej o składni YAML definiującej zadanie potoku. W tym przykładzie przedstawiono plik specyfikacji YAML dla zadania potoku z składnikiem Platformy Spark i maszyną azure Edukacja bezserwerową platformę Spark:
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.3"
Uwaga
Aby użyć dołączonej puli platformy Synapse Spark, zdefiniuj compute właściwość w przykładowym pliku specyfikacji YAML pokazanym powyżej zamiast resources właściwości.
Powyższy plik specyfikacji YAML można użyć w az ml job create poleceniu przy użyciu parametru --file , aby utworzyć zadanie potoku, jak pokazano poniżej:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Powyższe polecenie można wykonać za pomocą polecenia:
- terminal wystąpienia obliczeniowego usługi Azure Machine Edukacja.
- terminal programu Visual Studio Code połączony z wystąpieniem obliczeniowym usługi Azure Machine Edukacja.
- komputer lokalny z zainstalowanym interfejsem wiersza polecenia usługi Azure Machine Edukacja.
Rozwiązywanie problemów z zadaniami platformy Spark
Aby rozwiązać problemy z zadaniem platformy Spark, możesz uzyskać dostęp do dzienników wygenerowanych dla tego zadania w usłudze Azure Machine Edukacja Studio. Aby wyświetlić dzienniki zadania platformy Spark:
- Przejdź do pozycji Zadania z panelu po lewej stronie w interfejsie użytkownika usługi Azure Machine Edukacja Studio
- Wybierz kartę Wszystkie zadania
- Wybierz wartość Nazwa wyświetlana zadania
- Na stronie szczegółów zadania wybierz kartę Dane wyjściowe i dzienniki
- W Eksploratorze plików rozwiń folder logs, a następnie rozwiń folder azureml
- Uzyskiwanie dostępu do dzienników zadań platformy Spark wewnątrz folderów sterownika i menedżera biblioteki
Uwaga
Aby rozwiązać problemy z zadaniami platformy Spark utworzonymi podczas interakcyjnego rozmieszczania danych w sesji notesu, wybierz pozycję Szczegóły zadania w prawym górnym rogu interfejsu użytkownika notesu. Zadania platformy Spark z interakcyjnej sesji notesu są tworzone w obszarze nazwa eksperymentu notebook-runs.