Ocena wyników eksperymentu zautomatyzowanego uczenia maszynowego
W tym artykule dowiesz się, jak oceniać i porównywać modele trenowane przez eksperyment zautomatyzowanego uczenia maszynowego (zautomatyzowanego uczenia maszynowego). W trakcie zautomatyzowanego eksperymentu uczenia maszynowego tworzonych jest wiele zadań, a każde zadanie tworzy model. Dla każdego modelu zautomatyzowane uczenie maszynowe generuje metryki oceny i wykresy, które pomagają dokonać pomiaru wydajności modelu. Możesz jeszcze bardziej wygenerować pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji, aby przeprowadzić całościową ocenę i debugowanie zalecanego najlepszego modelu domyślnie. Obejmuje to szczegółowe informacje, takie jak wyjaśnienia modelu, sprawiedliwość i eksplorator wydajności, eksplorator danych, analiza błędów modelu. Dowiedz się więcej na temat sposobu generowania pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji.
Na przykład zautomatyzowane uczenie maszynowe generuje następujące wykresy na podstawie typu eksperymentu.
Ważne
Elementy oznaczone (wersja zapoznawcza) w tym artykule są obecnie dostępne w publicznej wersji zapoznawczej. Wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie jest zalecana w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Wymagania wstępne
- Subskrypcja platformy Azure. (Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto )
- Eksperyment usługi Azure Machine Edukacja utworzony za pomocą jednego z następujących obiektów:
- Azure Machine Edukacja Studio (bez wymaganego kodu)
- Zestaw AZURE Machine Edukacja Python SDK
Wyświetlanie wyników zadania
Po zakończeniu eksperymentu zautomatyzowanego uczenia maszynowego można znaleźć historię zadań:
- Przeglądarka z usługą Azure Machine Edukacja Studio
- Notes Jupyter korzystający z widżetu JobDetails Jupyter
W poniższych krokach i filmie wideo pokazano, jak wyświetlić historię uruchamiania i metryki oceny modelu oraz wykresy w studio:
- Zaloguj się do programu Studio i przejdź do obszaru roboczego.
- W menu po lewej stronie wybierz pozycję Zadania.
- Wybierz swój eksperyment z listy eksperymentów.
- W tabeli w dolnej części strony wybierz zadanie zautomatyzowanego uczenia maszynowego.
- Na karcie Modele wybierz nazwę algorytmu dla modelu, który chcesz ocenić.
- Na karcie Metryki użyj pól wyboru po lewej stronie, aby wyświetlić metryki i wykresy.
Metryki klasyfikacji
Zautomatyzowane uczenie maszynowe oblicza metryki wydajności dla każdego modelu klasyfikacji wygenerowanego na potrzeby eksperymentu. Te metryki są oparte na implementacji biblioteki scikit learn.
Wiele metryk klasyfikacji jest zdefiniowanych dla klasyfikacji binarnej w dwóch klasach i wymaga średniej dla klas w celu wygenerowania jednego wyniku klasyfikacji wieloklasowej. Biblioteka Scikit-learn udostępnia kilka metod średniej, z których trzy automatyczne uczenie maszynowe uwidacznia: makro, mikro i ważone.
- Makro — oblicz metryki dla każdej klasy i weź średnią bez wagi
- Micro — oblicz metryki globalnie, zliczając łączne wyniki prawdziwie dodatnie, fałszywie ujemne i fałszywie dodatnie (niezależnie od klas).
- Ważone — oblicz metryki dla każdej klasy i weź średnią ważoną na podstawie liczby próbek na klasę.
Chociaż każda metoda średniej ma swoje zalety, jedną z typowych kwestii podczas wybierania odpowiedniej metody jest nierównowaga klas. Jeśli klasy mają różne liczby próbek, może to być bardziej informacyjne, aby użyć średniej makro, w której klasy mniejszości mają równe wagi do klas większościowych. Dowiedz się więcej o metrykach binarnych i wieloklasowych w zautomatyzowanym uczeniu maszynowym.
W poniższej tabeli podsumowano metryki wydajności modelu, które zautomatyzowane uczenie maszynowe oblicza dla każdego modelu klasyfikacji wygenerowanego na potrzeby eksperymentu. Aby uzyskać więcej informacji, zobacz dokumentację biblioteki scikit-learn połączoną w polu Obliczenia każdej metryki.
Uwaga
Zobacz sekcję metryki obrazów, aby uzyskać dodatkowe szczegółowe informacje na temat metryk dla modeli klasyfikacji obrazów.
| Jednostki metryczne | opis | Obliczenia |
|---|---|---|
| AUC | AUC to obszar pod krzywą charakterystyki operacyjnej odbiornika. Cel: Bliżej 1 tym lepiej Zakres: [0, 1] Obsługiwane nazwy metryk obejmują: AUC_macro, arytmetyczna średnia AUC dla każdej klasy.AUC_micro, obliczony przez zliczanie łącznych wyników prawdziwie dodatnich, wyników fałszywie ujemnych i wyników fałszywie dodatnich. AUC_weighted, arytmetyczna średnia wyniku dla każdej klasy, ważona przez liczbę wystąpień true w każdej klasie. AUC_binary, wartość AUC, traktując jedną konkretną klasę jako true klasę i łącząc wszystkie inne klasy jako false klasę. |
Obliczenia |
| accuracy | Dokładność to stosunek przewidywań, które dokładnie pasują do rzeczywistych etykiet klas. Cel: Bliżej 1 tym lepiej Zakres: [0, 1] |
Obliczenia |
| average_precision | Średnia precyzja podsumowuje krzywą precyzji jako średnią ważoną precyzji osiąganą przy każdym progu, a wzrost kompletności z poprzedniego progu używany jako waga. Cel: Bliżej 1 tym lepiej Zakres: [0, 1] Obsługiwane nazwy metryk obejmują: average_precision_score_macro, średnia arytmetyczna średniej średniej precyzji dla każdej klasy.average_precision_score_micro, obliczony przez zliczanie łącznych wyników prawdziwie dodatnich, wyników fałszywie ujemnych i wyników fałszywie dodatnich.average_precision_score_weighted, średnia arytmetyczna średniego wyniku dokładności dla każdej klasy, ważona liczbą wystąpień true w każdej klasie. average_precision_score_binary, wartość średniej dokładności, traktując jedną konkretną klasę jako true klasę i łącząc wszystkie inne klasy jako false klasę. |
Obliczenia |
| balanced_accuracy | Zrównoważona dokładność to średnia arytmetyczna kompletności dla każdej klasy. Cel: Bliżej 1 tym lepiej Zakres: [0, 1] |
Obliczenia |
| f1_score | Wynik F1 to średnia harmoniczna precyzji i kompletności. Jest to dobra zrównoważona miara zarówno wyników fałszywie dodatnich, jak i wyników fałszywie ujemnych. Nie uwzględnia jednak rzeczywistych wartości ujemnych. Cel: Bliżej 1 tym lepiej Zakres: [0, 1] Obsługiwane nazwy metryk obejmują: f1_score_macro: średnia arytmetyczna wyniku F1 dla każdej klasy. f1_score_micro: obliczany przez zliczanie wszystkich wyników prawdziwie dodatnich, wyników fałszywie ujemnych i wyników fałszywie dodatnich. f1_score_weighted: średnia ważona według częstotliwości klas oceny F1 dla każdej klasy. f1_score_binary, wartość f1, traktując jedną konkretną klasę jako true klasę i łącząc wszystkie inne klasy jako false klasę. |
Obliczenia |
| log_loss | Jest to funkcja straty używana w regresji logistycznej (wielomianowej) i rozszerzeniach jej, takich jak sieci neuronowe, zdefiniowane jako ujemne prawdopodobieństwo rejestrowania prawdziwych etykiet, biorąc pod uwagę przewidywania klasyfikatora probabilistycznego. Cel: Bliżej 0 tym lepiej Zakres: [0, inf) |
Obliczenia |
| norm_macro_recall | Znormalizowane kompletność makr przypomina średnie makro i znormalizowane, dzięki czemu losowa wydajność ma wynik 0, a doskonała wydajność ma wynik 1. Cel: Bliżej 1 tym lepiej Zakres: [0, 1] |
(recall_score_macro - R) / (1 - R) R gdzie jest oczekiwaną wartością recall_score_macro dla przewidywań losowych.R = 0.5 dla klasyfikacji binarnej. R = (1 / C) w przypadku problemów z klasyfikacją klas C. |
| matthews_correlation | Współczynnik korelacji Matthews jest zrównoważoną miarą dokładności, która może być używana nawet wtedy, gdy jedna klasa ma o wiele więcej próbek niż inne. Współczynnik 1 wskazuje idealne przewidywanie, przewidywanie losowe 0 i -1 odwrotne przewidywanie. Cel: Bliżej 1 tym lepiej Zakres: [-1, 1] |
Obliczenia |
| precyzja | Precyzja to zdolność modelu do unikania etykietowania próbek ujemnych jako dodatnich. Cel: Bliżej 1 tym lepiej Zakres: [0, 1] Obsługiwane nazwy metryk obejmują: precision_score_macro, arytmetyczna średnia precyzji dla każdej klasy. precision_score_micro, obliczany globalnie przez zliczanie wszystkich wyników prawdziwie dodatnich i wyników fałszywie dodatnich. precision_score_weighted, arytmetyczna średnia precyzji dla każdej klasy, ważona liczbą wystąpień true w każdej klasie. precision_score_binary, wartość precyzji, traktując jedną konkretną klasę jako true klasę i łącząc wszystkie inne klasy jako false klasę. |
Obliczenia |
| trafność | Kompletność to zdolność modelu do wykrywania wszystkich dodatnich próbek. Cel: Bliżej 1 tym lepiej Zakres: [0, 1] Obsługiwane nazwy metryk obejmują: recall_score_macro: arytmetyczna średnia kompletności dla każdej klasy. recall_score_micro: obliczany globalnie przez zliczanie łącznej liczby wyników prawdziwie dodatnich, wyników fałszywie ujemnych i wyników fałszywie dodatnich.recall_score_weighted: średnia arytmetyczna kompletności dla każdej klasy ważona liczbą wystąpień true w każdej klasie. recall_score_binary, wartość kompletności, traktując jedną konkretną klasę jako true klasę i łącząc wszystkie inne klasy jako false klasę. |
Obliczenia |
| weighted_accuracy | Dokładność ważona to dokładność, w której każda próbka jest ważona całkowitą liczbą próbek należących do tej samej klasy. Cel: Bliżej 1 tym lepiej Zakres: [0, 1] |
Obliczenia |
Metryki klasyfikacji binarnej a wieloklasowej
Zautomatyzowane uczenie maszynowe automatycznie wykrywa, czy dane są binarne, a także umożliwia użytkownikom aktywowanie metryk klasyfikacji binarnej, nawet jeśli dane są wieloklasowe, określając klasę true . Metryki klasyfikacji wieloklasowej są zgłaszane, jeśli zestaw danych ma co najmniej dwie klasy. Metryki klasyfikacji binarnej są zgłaszane tylko wtedy, gdy dane są binarne.
Należy pamiętać, że metryki klasyfikacji wieloklasowej są przeznaczone do klasyfikacji wieloklasowej. W przypadku zastosowania do binarnego zestawu danych te metryki nie traktują żadnej klasy jako true klasy, jak można się spodziewać. Metryki, które są wyraźnie przeznaczone dla wielu klas, mają sufiks , micromacrolub weighted. Przykłady obejmują average_precision_score, , f1_score, recall_scoreprecision_score, i AUC. Na przykład zamiast obliczać kompletność jako tp / (tp + fn)średnia kompletność wieloklasowa (micro, macrolub weighted) średnia w obu klasach zestawu danych klasyfikacji binarnej. Jest to równoważne obliczaniu odwołania dla true klasy i false klasy oddzielnie, a następnie biorąc średnią z dwóch.
Poza tym, mimo że automatyczne wykrywanie klasyfikacji binarnej jest obsługiwane, nadal zaleca się ręczne określenie true klasy w celu upewnienia się, że metryki klasyfikacji binarnej są obliczane dla prawidłowej klasy.
Aby aktywować metryki dla zestawów danych klasyfikacji binarnej, gdy sam zestaw danych jest wieloklasowy, użytkownicy muszą określić klasę, która ma być traktowana jako true klasa, a te metryki zostaną obliczone.
Macierz pomyłek
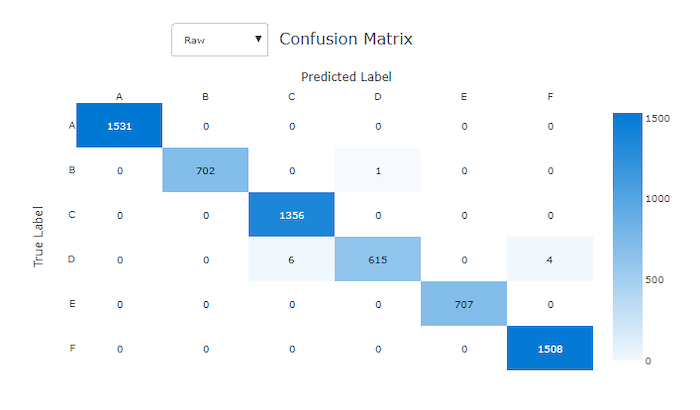
Macierze pomyłek zapewniają wizualizację sposobu, w jaki model uczenia maszynowego popełnia systematyczne błędy w przewidywaniach modeli klasyfikacji. Słowo "zamieszanie" w nazwie pochodzi od modelu "mylące" lub błędnie oznaczającego przykłady. Komórka w wierszu i i kolumnie w macierzy j pomyłek zawiera liczbę próbek w zestawie danych oceny, które należą do klasy C_i i zostały sklasyfikowane przez model jako klasę C_j.
W studio ciemniejsze komórki wskazują większą liczbę próbek. Wybranie pozycji Znormalizowany widok na liście rozwijanej spowoduje normalizację dla każdego wiersza macierzy, aby pokazać procent klasy przewidywanej jako klasa C_iC_j. Zaletą domyślnego widoku Nieprzetworzone jest to, że można sprawdzić, czy nierównowaga rozkładu rzeczywistych klas spowodowała, że model błędnie sklasyfikował próbki z klasy mniejszości, co jest typowym problemem w niezrównoważonych zestawach danych.
Macierz pomyłek dobrego modelu będzie miała większość próbek wzdłuż przekątnej.
Macierz pomyłek dla dobrego modelu
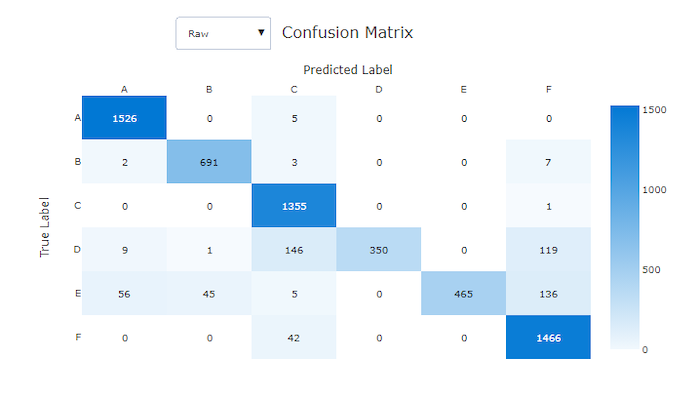
Macierz pomyłek dla złego modelu
Krzywa ROC
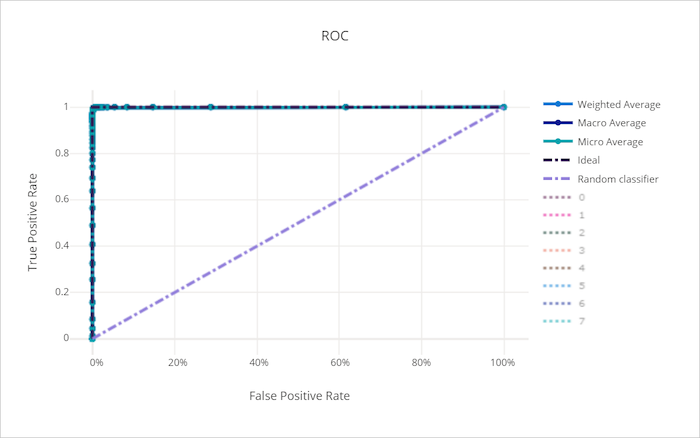
Krzywa właściwości operacyjnej odbiornika (ROC) kreśli relację między prawdziwie dodatnim współczynnikiem (TPR) i fałszywie dodatnim współczynnikiem (FPR) w miarę zmiany progu decyzyjnego. Krzywa ROC może być mniej informacyjna podczas trenowania modeli na zestawach danych z dysproporcją wysokiej klasy, ponieważ klasa większości może utonąć wkład z klas mniejszościowych.
Obszar pod krzywą (AUC) można interpretować jako proporcję poprawnie sklasyfikowanych próbek. Dokładniej mówiąc, AUC jest prawdopodobieństwem, że klasyfikator plasuje losowo wybraną dodatnią próbkę wyższą niż losowo wybrana próbka ujemna. Kształt krzywej daje intuicję dla relacji między TPR i FPR jako funkcją progu klasyfikacji lub granicy decyzyjnej.
Krzywa zbliża się do lewego górnego rogu wykresu zbliża się do 100% TPR i 0% FPR, najlepiej możliwego modelu. Losowy model tworzy krzywą ROC wzdłuż y = x linii z lewego dolnego rogu do prawego górnego rogu. Gorszy niż losowy model miałby krzywą ROC, która spada poniżej y = x linii.
Napiwek
W przypadku eksperymentów klasyfikacji każdy wykres liniowy utworzony dla zautomatyzowanych modeli uczenia maszynowego może służyć do oceny modelu na klasę lub uśrednionej dla wszystkich klas. Możesz przełączać się między tymi różnymi widokami, klikając etykiety klas w legendzie po prawej stronie wykresu.
Krzywa ROC dla dobrego modelu
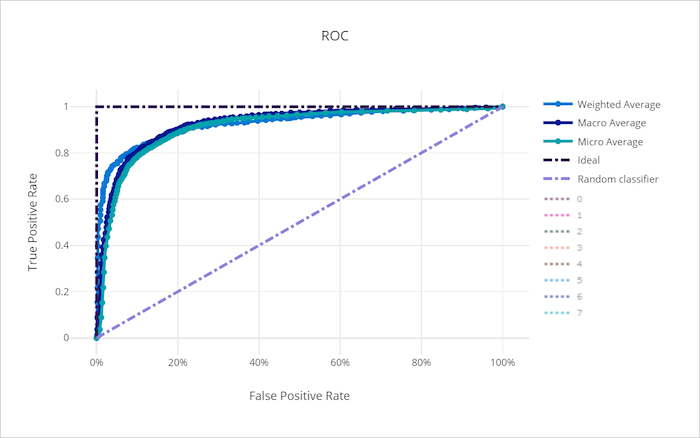
Krzywa ROC dla złego modelu
Krzywa kompletności precyzji
Krzywa precyzji kompletności kreśli relację między precyzją i kompletnością, gdy zmienia się próg decyzyjny. Kompletność to zdolność modelu do wykrywania wszystkich dodatnich próbek i precyzji jest zdolność modelu do unikania etykietowania negatywnych próbek jako dodatnich. Niektóre problemy biznesowe mogą wymagać większej kompletności i większej precyzji w zależności od względnego znaczenia unikania wyników fałszywie ujemnych i fałszywie dodatnich.
Napiwek
W przypadku eksperymentów klasyfikacji każdy wykres liniowy utworzony dla zautomatyzowanych modeli uczenia maszynowego może służyć do oceny modelu na klasę lub uśrednionej dla wszystkich klas. Możesz przełączać się między tymi różnymi widokami, klikając etykiety klas w legendzie po prawej stronie wykresu.
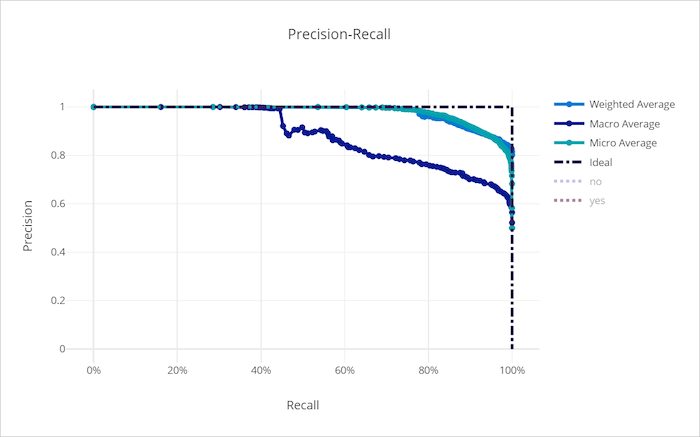
Krzywa precyzji kompletności dla dobrego modelu
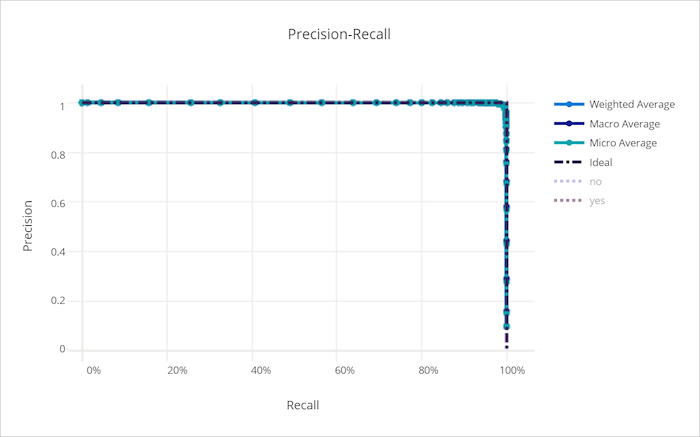
Krzywa kompletności dla nieprawidłowego modelu
Krzywa skumulowanego zysku
Krzywa skumulowanych zysków wykreśli procent próbek dodatnich prawidłowo sklasyfikowanych jako funkcja procentu próbek rozważanych w przypadku, gdy rozważamy próbki w kolejności przewidywanego prawdopodobieństwa.
Aby obliczyć zysk, najpierw posortuj wszystkie próbki z najwyższego do najniższego prawdopodobieństwa przewidywanego przez model. Następnie weź pod uwagę x% najwyższe przewidywania ufności. Podziel liczbę próbek dodatnich wykrytych w tym x% celu przez łączną liczbę dodatnich próbek w celu uzyskania zysku. Skumulowany przyrost jest procentem dodatnich próbek wykrywanych podczas rozważania pewnego procentu danych, które najprawdopodobniej należą do klasy dodatniej.
Idealny model będzie klasyfikować wszystkie dodatnie próbki powyżej wszystkich próbek ujemnych, dając krzywą skumulowanych zysków składających się z dwóch segmentów prostych. Pierwszy to linia ze nachyleniem 1 / x od (0, 0) do (x, 1) miejsca, w którym x jest ułamek próbek należących do klasy dodatniej (1 / num_classes jeśli klasy są zrównoważone). Drugi to linia pozioma od (x, 1) do (1, 1). W pierwszym segmencie wszystkie próbki dodatnie są klasyfikowane poprawnie, a skumulowany zysk przechodzi do 100% pierwszego x% z rozważanych próbek.
Model losowy linii bazowej będzie miał krzywą skumulowanych zysków po y = x tym, jak wykryto x% tylko x% liczbę próbek dodatnich. Idealny model dla zrównoważonego zestawu danych będzie miał krzywą mikrośrednią i średnią linię makro, która ma nachylenie num_classes do skumulowanego zysku wynosi 100%, a następnie pozioma, aż procent danych będzie wynosić 100.
Napiwek
W przypadku eksperymentów klasyfikacji każdy wykres liniowy utworzony dla zautomatyzowanych modeli uczenia maszynowego może służyć do oceny modelu na klasę lub uśrednionej dla wszystkich klas. Możesz przełączać się między tymi różnymi widokami, klikając etykiety klas w legendzie po prawej stronie wykresu.
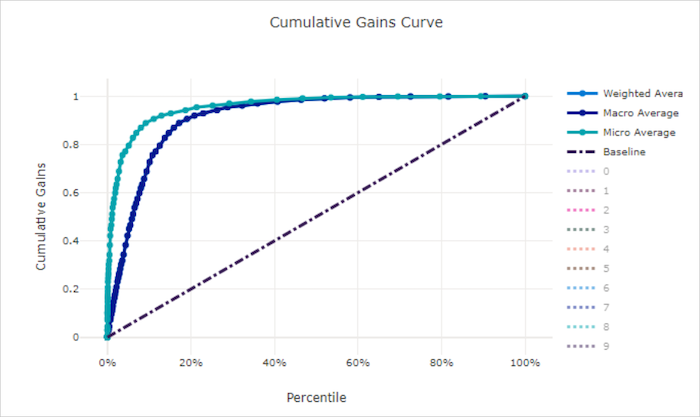
Krzywa skumulowanych zysków dla dobrego modelu
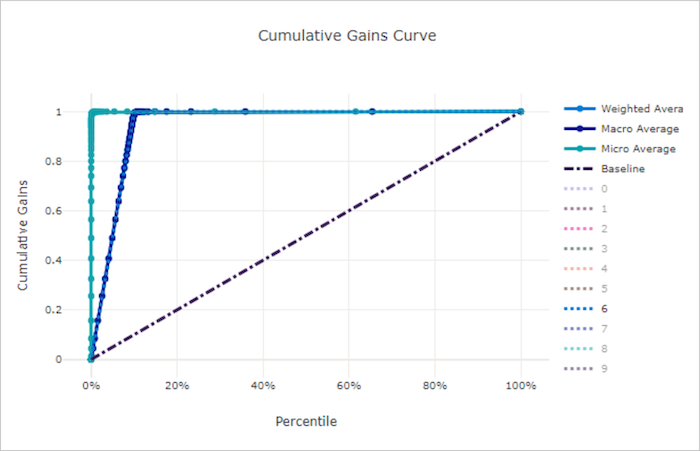
Krzywa skumulowanych zysków dla złego modelu
Krzywa przyrostu
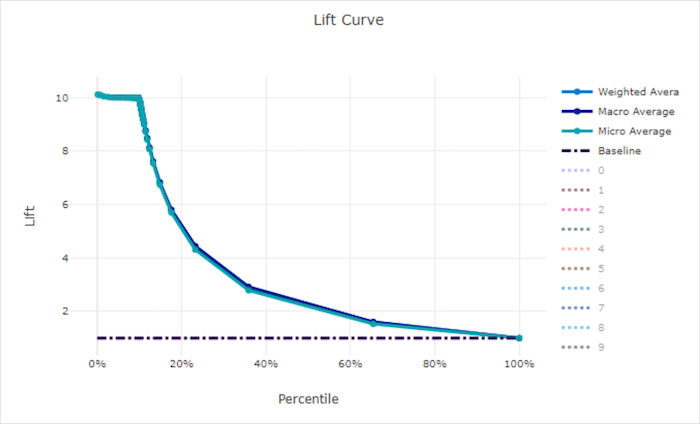
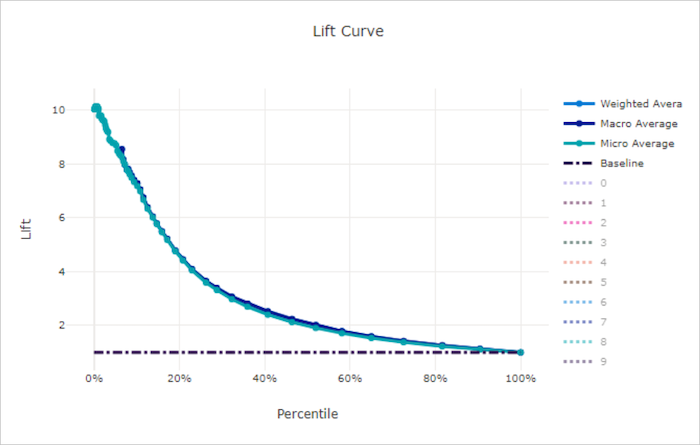
Krzywa podnoszenia pokazuje, ile razy lepiej działa model w porównaniu z modelem losowym. Lift jest definiowany jako stosunek skumulowanego zysku do skumulowanego zysku modelu losowego (który zawsze powinien mieć wartość 1).
Ta względna wydajność uwzględnia fakt, że klasyfikacja staje się trudniejsza w miarę zwiększania liczby klas. (Model losowy niepoprawnie przewiduje wyższy ułamek próbek z zestawu danych z 10 klasami w porównaniu z zestawem danych z dwiema klasami)
Krzywa podnoszenia linii bazowej y = 1 to linia, w której wydajność modelu jest zgodna z modelem losowym. Ogólnie rzecz biorąc, krzywa podnoszenia dla dobrego modelu będzie wyższa na tym wykresie i dalej od osi x, pokazując, że gdy model jest najbardziej pewny swoich przewidywań, wykonuje wiele razy lepiej niż losowe zgadywanie.
Napiwek
W przypadku eksperymentów klasyfikacji każdy wykres liniowy utworzony dla zautomatyzowanych modeli uczenia maszynowego może służyć do oceny modelu na klasę lub uśrednionej dla wszystkich klas. Możesz przełączać się między tymi różnymi widokami, klikając etykiety klas w legendzie po prawej stronie wykresu.
Krzywa podnoszenia dla dobrego modelu
Krzywa podnoszenia dla złego modelu
Krzywa kalibracyjna
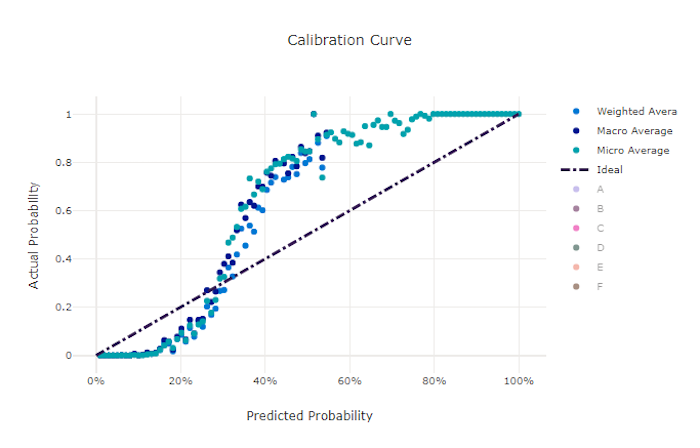
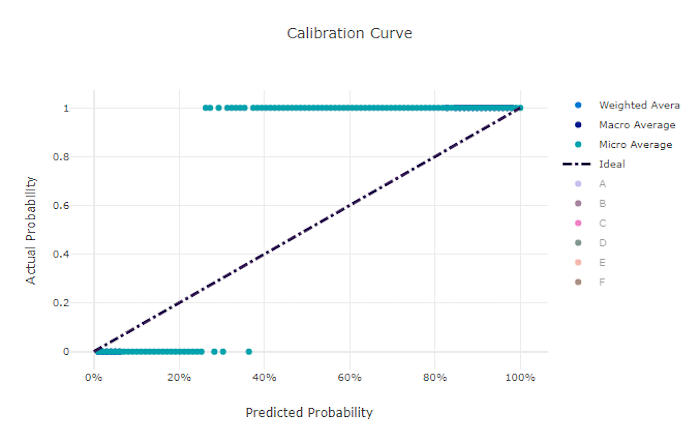
Krzywa kalibracji kreśli zaufanie modelu do przewidywań względem proporcji próbek dodatnich na każdym poziomie ufności. Dobrze skalibrowany model prawidłowo klasyfikuje 100% przewidywań, do których przypisuje 100% ufności, 50% przewidywań, które przypisuje 50% ufności, 20% przewidywań, do których przypisuje 20% ufności itd. Idealnie skalibrowany model będzie miał krzywą kalibracji po y = x linii, w której model doskonale przewiduje prawdopodobieństwo, że próbki należą do każdej klasy.
Nadmiernie pewny siebie model będzie przewidywał prawdopodobieństwa zbliżone do zera i jeden, rzadko nie jest pewien klasy każdej próbki, a krzywa kalibracji będzie wyglądać podobnie do odwrotnej "S". Model o niższym poziomie pewności przypisze średnie niższe prawdopodobieństwo do klasy, która przewiduje, a skojarzona krzywa kalibracji będzie wyglądać podobnie do "S". Krzywa kalibracji nie przedstawia zdolności modelu do poprawnego klasyfikowania, ale zamiast tego jego zdolność do poprawnego przypisywania zaufania do przewidywań. Nieprawidłowy model może nadal mieć dobrą krzywą kalibracji, jeśli model prawidłowo przypisuje niską pewność i wysoką niepewność.
Uwaga
Krzywa kalibracji jest wrażliwa na liczbę próbek, więc mały zestaw weryfikacyjny może generować hałaśliwe wyniki, które mogą być trudne do zinterpretowania. Niekoniecznie oznacza to, że model nie jest dobrze skalibrowany.
Krzywa kalibracji dla dobrego modelu
Krzywa kalibracji dla złego modelu
Metryki regresji/prognozowania
Zautomatyzowane uczenie maszynowe oblicza te same metryki wydajności dla każdego wygenerowanego modelu, niezależnie od tego, czy jest to eksperyment regresji lub prognozowania. Te metryki są również poddawane normalizacji, aby umożliwić porównywanie modeli wytrenowanych na danych z różnymi zakresami. Aby dowiedzieć się więcej, zobacz Normalizacja metryk.
W poniższej tabeli podsumowano metryki wydajności modelu wygenerowane na potrzeby eksperymentów regresji i prognozowania. Podobnie jak metryki klasyfikacji, te metryki są również oparte na implementacjach biblioteki scikit learn. Odpowiednia dokumentacja biblioteki scikit learn jest odpowiednio połączona w polu Obliczenia .
| Jednostki metryczne | opis | Obliczenia |
|---|---|---|
| explained_variance | Wyjaśniona wariancja mierzy zakres, w jakim model odpowiada za odmianę zmiennej docelowej. Jest to procent spadku wariancji oryginalnych danych do wariancji błędów. Gdy średnia błędów wynosi 0, jest równa współczynnikowi determinacji (patrz r2_score poniżej). Cel: Bliżej 1 tym lepiej Zakres: (-inf, 1] |
Obliczenia |
| mean_absolute_error | Średni błąd bezwzględny to oczekiwana wartość bezwzględnej różnicy między wartością docelową a przewidywaniem. Cel: Bliżej 0 tym lepiej Zakres: [0, inf) Typy: mean_absolute_error normalized_mean_absolute_error, mean_absolute_error podzielona przez zakres danych. |
Obliczenia |
| mean_absolute_percentage_error | Średni bezwzględny błąd procentowy (MAPE) to miara średniej różnicy między przewidywaną wartością a rzeczywistą wartością. Cel: Bliżej 0 tym lepiej Zakres: [0, inf) |
|
| median_absolute_error | Mediana błędu bezwzględnego to mediana wszystkich bezwzględnych różnic między wartością docelową a przewidywaniem. Ta utrata jest niezawodna dla wartości odstających. Cel: Bliżej 0 tym lepiej Zakres: [0, inf) Typy: median_absolute_errornormalized_median_absolute_error: median_absolute_error podzielona przez zakres danych. |
Obliczenia |
| r2_score | R2 (współczynnik determinacji) mierzy proporcjonalny spadek błędu średniokwadratowego (MSE) względem całkowitej wariancji obserwowanych danych. Cel: Bliżej 1 tym lepiej Zakres: [-1, 1] Uwaga: R2 często ma zakres (-inf, 1). MsE może być większa niż obserwowana wariancja, więc R2 może mieć dowolnie duże wartości ujemne, w zależności od danych i przewidywań modelu. Zautomatyzowane klipy ML zgłosiły wyniki R2 na -1, więc wartość -1 dla R2 prawdopodobnie oznacza, że prawdziwy wynik R2 jest mniejszy niż -1. Podczas interpretowania negatywnego wyniku R2 należy wziąć pod uwagę inne wartości metryk i właściwości danych. |
Obliczenia |
| root_mean_squared_error | Główny błąd średniokwadratowy (RMSE) to pierwiastek kwadratowy oczekiwanej kwadratowej różnicy między wartością docelową a przewidywaniem. W przypadku niebiałego narzędzia do szacowania rmsE jest równe odchyleniu standardowemu. Cel: Bliżej 0 tym lepiej Zakres: [0, inf) Typy: root_mean_squared_error normalized_root_mean_squared_error: root_mean_squared_error podzielona przez zakres danych. |
Obliczenia |
| root_mean_squared_log_error | Błąd dziennika średniokwadratowego głównego jest pierwiastek kwadratowym oczekiwanego błędu logarytmicznych kwadratu. Cel: Bliżej 0 tym lepiej Zakres: [0, inf) Typy: root_mean_squared_log_error normalized_root_mean_squared_log_error: root_mean_squared_log_error podzielona przez zakres danych. |
Obliczenia |
| spearman_correlation | Korelacja Spearman to nieparametryczna miara monotoniczności relacji między dwoma zestawami danych. W przeciwieństwie do korelacji Pearson korelacja Spearman nie zakłada, że oba zestawy danych są zwykle rozproszone. Podobnie jak inne współczynniki korelacji, Spearman różni się w zakresie od -1 do 1 z 0 co oznacza brak korelacji. Korelacje -1 lub 1 oznaczają dokładną relację monotoniczną. Spearman to metryka korelacji kolejności rangi, co oznacza, że zmiany wartości przewidywanych lub rzeczywistych nie spowodują zmiany wyniku Spearman, jeśli nie zmienią kolejności klasyfikacji przewidywanych lub rzeczywistych wartości. Cel: Bliżej 1 tym lepiej Zakres: [-1, 1] |
Obliczenia |
Normalizacja metryk
Zautomatyzowane uczenie maszynowe normalizuje metryki regresji i prognozowania, które umożliwiają porównywanie modeli wytrenowanych na danych z różnymi zakresami. Model wytrenowany na danych z większym zakresem ma większy błąd niż ten sam model trenowany na danych z mniejszym zakresem, chyba że ten błąd jest znormalizowany.
Chociaż nie ma standardowej metody normalizacji metryk błędów, zautomatyzowane uczenie maszynowe przyjmuje typowe podejście dzielenia błędu przez zakres danych: normalized_error = error / (y_max - y_min)
Uwaga
Zakres danych nie jest zapisywany w modelu. Jeśli wnioskowanie z tym samym modelem w zestawie testów wstrzymania może ulec zmianie zgodnie z danymi testowymi, y_miny_max a znormalizowane metryki mogą nie być bezpośrednio używane do porównywania wydajności modelu na zestawach treningowych i testowych. Możesz przekazać wartość i y_max z zestawu treningowegoy_min, aby dokonać sprawiedliwego porównania.
Metryki prognozowania: normalizacja i agregacja
Obliczanie metryk na potrzeby oceny modelu prognozowania wymaga pewnych specjalnych zagadnień, gdy dane zawierają wiele szeregów czasowych. Istnieją dwie naturalne opcje agregowania metryk w wielu seriach:
- Średnia makro, w której metryki oceny z każdej serii mają taką samą wagę,
- Średnia mikroprzeciętna, w której metryki oceny dla każdego przewidywania mają taką samą wagę.
Te przypadki mają bezpośrednie analogie do makra i mikroskładu w klasyfikacji wieloklasowej.
Podczas wybierania podstawowej metryki do wyboru modelu może być ważne rozróżnienie między makro i mikrosprawnością. Rozważmy na przykład scenariusz sprzedaży detalicznej, w którym chcesz prognozować zapotrzebowanie na wybór produktów konsumenckich. Niektóre produkty sprzedają się w znacznie wyższych ilościach niż inne. W przypadku wybrania mikrosredniej metryki RMSE jako podstawowej metryki możliwe jest, że elementy o dużej ilości będą przyczyniać się do większości błędów modelowania i w związku z tym zdominować metrykę. Algorytm wyboru modelu może następnie faworyzować modele o większej dokładności w przypadku elementów o dużej ilości niż w przypadku małych woluminów. Z kolei znormalizowane elementy RMSE w skali makra dają elementy o małej ilości w przybliżeniu równej wadze do elementów o dużej ilości.
W poniższej tabeli przedstawiono, które metryki prognozowania rozwiązania AutoML używają makr a mikroskładnika:
| Średnia makra | Mikroprześrednie |
|---|---|
normalized_mean_absolute_error, normalized_median_absolute_error, normalized_root_mean_squared_error, normalized_root_mean_squared_log_error |
mean_absolute_error, median_absolute_error, root_mean_squared_error, root_mean_squared_log_error, r2_score, explained_variance, spearman_correlation, mean_absolute_percentage_error |
Należy pamiętać, że metryki uśrednione dla makr normalizują każdą serię oddzielnie. Znormalizowane metryki z każdej serii są następnie uśrednione, aby dać wynik końcowy. Prawidłowy wybór makr a mikro zależy od scenariusza biznesowego, ale ogólnie zalecamy użycie polecenia normalized_root_mean_squared_error.
Wartości resztkowe
Wykres reszt jest histogramem błędów przewidywania (reszt) generowanych na potrzeby eksperymentów regresji i prognozowania. Reszty są obliczane jako y_predicted - y_true dla wszystkich próbek, a następnie wyświetlane jako histogram w celu pokazania stronniczy modelu.
W tym przykładzie należy pamiętać, że oba modele są nieco stronnicze, aby przewidzieć niższą niż rzeczywista wartość. Nie jest to rzadkością w przypadku zestawu danych ze niesymetrycznym rozkładem rzeczywistych celów, ale wskazuje na gorzej wydajność modelu. Dobry model będzie miał rozkład reszt, który osiąga szczyt z zera z kilkoma resztami w skrajnościach. Gorszy model będzie miał rozkład reszt z mniejszą liczbą próbek około zera.
Wykres reszt dla dobrego modelu
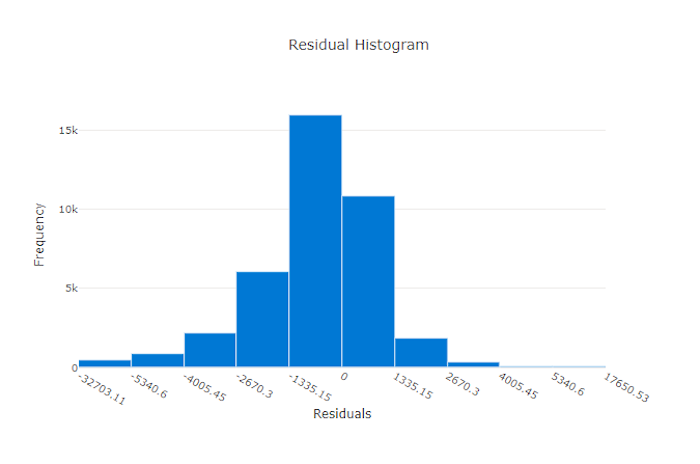
Wykres reszt dla złego modelu

Wartości przewidywane a prawda
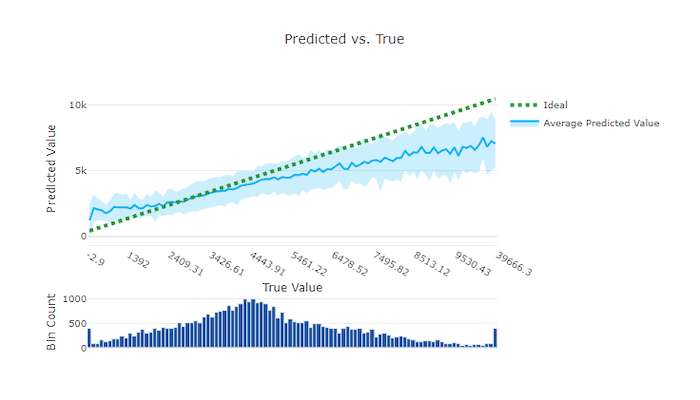
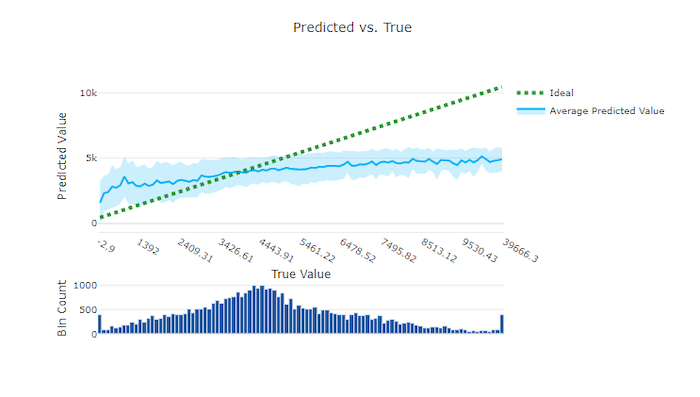
W przypadku regresji i prognozowania eksperyment przewidywane a prawdziwe wykresy kreślą relację między funkcją docelową (wartościami rzeczywistymi/rzeczywistymi) i przewidywaniami modelu. Wartości true są binned wzdłuż osi x, a dla każdego pojemnika średnia przewidywana wartość jest wykreślina z paskami błędów. Dzięki temu można sprawdzić, czy model jest stronniczy w kierunku przewidywania określonych wartości. Wiersz wyświetla średnią prognozę, a zacieniony obszar wskazuje wariancję przewidywań wokół tej średniej.
Często najbardziej typowa wartość true będzie miała najdokładniejsze przewidywania z najniższą wariancją. Odległość linii trendu od idealnej y = x linii, w której istnieje kilka wartości rzeczywistych, to dobra miara wydajności modelu dla wartości odstających. Możesz użyć histogramu w dolnej części wykresu, aby poznać rzeczywisty rozkład danych. W tym więcej przykładów danych, w których rozkład jest rozrzedzone, może zwiększyć wydajność modelu na niezaużynych danych.
W tym przykładzie zwróć uwagę, że lepszy model ma przewidywaną i prawdziwą linię, która jest bliżej idealnej y = x linii.
Przewidywany i prawdziwy wykres dla dobrego modelu
Przewidywany a prawdziwy wykres dla złego modelu
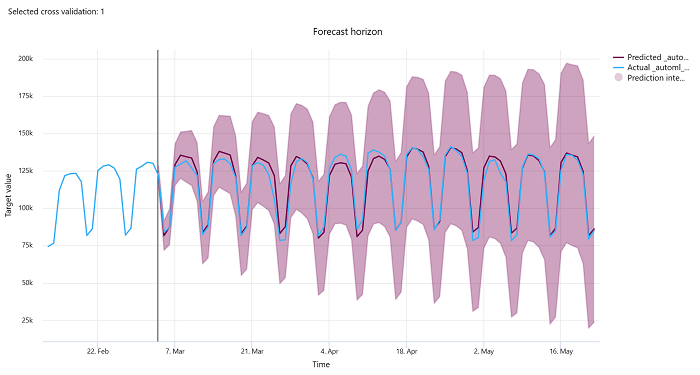
Horyzont prognozy
W przypadku eksperymentów prognozowania wykres horyzontu prognozy wykreśli relację między przewidywaną wartością modeli a rzeczywistymi wartościami zamapowanym w czasie na jedną jedną akcję weryfikacji krzyżowej, maksymalnie 5 razy. Oś x mapuje czas na podstawie częstotliwości podanej podczas konfigurowania trenowania. Linia pionowa na wykresie oznacza również punkt horyzontu prognozy nazywany również linią horyzontu, czyli okresem, w którym chcesz rozpocząć generowanie przewidywań. Po lewej stronie linii horyzontu prognozy możesz wyświetlić historyczne dane szkoleniowe, aby lepiej wizualizować wcześniejsze trendy. Po prawej stronie horyzontu prognozy można wizualizować przewidywania (fioletową linię) względem wartości rzeczywistych (niebieskiej linii) dla różnych składań krzyżowych i identyfikatorów szeregów czasowych. Zacieniony fioletowy obszar wskazuje interwały ufności lub wariancję przewidywań wokół tej średniej.
Możesz wybrać kombinacje składania krzyżowego i identyfikatora szeregów czasowych do wyświetlenia, klikając ikonę ołówka edycji w prawym górnym rogu wykresu. Wybierz z pierwszych 5 składanych krzyżowych i maksymalnie 20 różnych identyfikatorów szeregów czasowych, aby zwizualizować wykres dla różnych szeregów czasowych.
Ważne
Ten wykres jest dostępny w przebiegu trenowania dla modeli generowanych na podstawie danych trenowania i walidacji, a także w przebiegu testu na podstawie danych treningowych i danych testowych. Zezwalamy na maksymalnie 20 punktów danych przed i do 80 punktów danych po wystąpieniu prognozy. W przypadku modeli sieci rozproszonej ten wykres w przebiegu trenowania przedstawia dane z ostatniej epoki, tj. po całkowitym wytrenowanym modelu. Ten wykres w przebiegu testu może mieć lukę przed wierszem horyzontu, jeśli dane weryfikacji zostały jawnie dostarczone podczas przebiegu trenowania. Wynika to z faktu, że dane treningowe i dane testowe są używane w przebiegu testu, pomijając dane weryfikacji, co skutkuje luką.
Metryki dla modeli obrazów (wersja zapoznawcza)
Zautomatyzowane uczenie maszynowe używa obrazów z zestawu danych weryfikacji do oceny wydajności modelu. Wydajność modelu jest mierzona na poziomie epoki, aby zrozumieć postęp trenowania. Epoka upłynie, gdy cały zestaw danych jest przekazywany do przodu i do tyłu przez sieć neuronową dokładnie raz.
Metryki klasyfikacji obrazów
Podstawowa metryka oceny to dokładność modeli klasyfikacji binarnej i wieloklasowej oraz IoU (Skrzyżowanie przez Unię) dla modeli klasyfikacji wieloskładowej. Metryki klasyfikacji modeli klasyfikacji obrazów są takie same jak te zdefiniowane w sekcji metryki klasyfikacji. Rejestrowane są również wartości strat skojarzone z epoką, które mogą pomóc monitorować postęp trenowania i określić, czy model jest zbyt dopasowany, czy niedopasowany.
Każde przewidywanie z modelu klasyfikacji jest skojarzone z współczynnikiem ufności, który wskazuje poziom zaufania, z którym przewidywano. Modele klasyfikacji obrazów wielobelowych są domyślnie oceniane z progiem oceny 0,5, co oznacza, że tylko przewidywania z co najmniej tym poziomem ufności będą traktowane jako pozytywne przewidywanie dla skojarzonej klasy. Klasyfikacja wieloklasowa nie używa progu oceny, ale klasa z maksymalnym współczynnikiem ufności jest traktowana jako przewidywanie.
Metryki na poziomie epoki dla klasyfikacji obrazów
W przeciwieństwie do metryk klasyfikacji dla tabelarycznych zestawów danych modele klasyfikacji obrazów rejestrują wszystkie metryki klasyfikacji na poziomie epoki, jak pokazano poniżej.
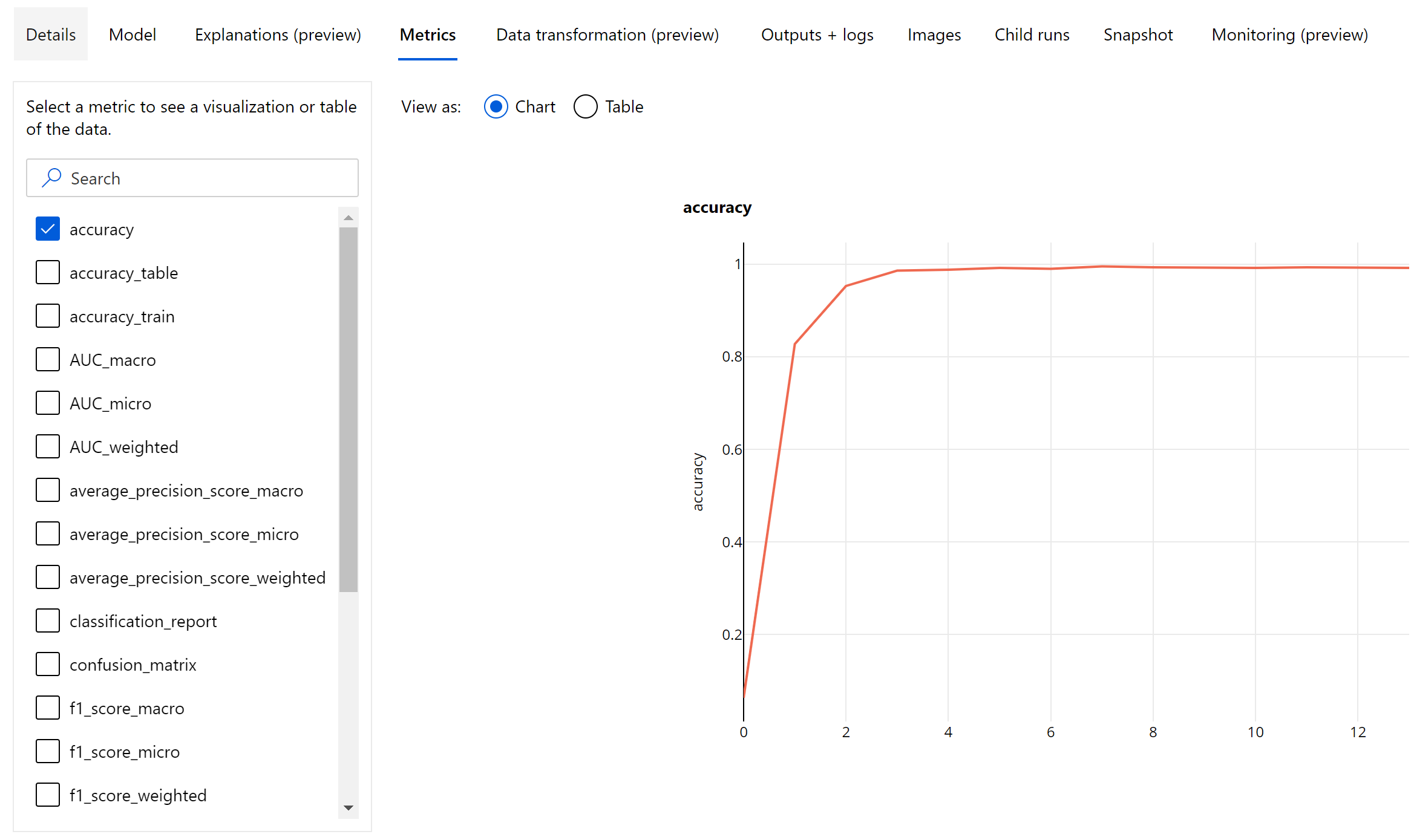
Metryki podsumowania klasyfikacji obrazów
Oprócz metryk skalarnych rejestrowanych na poziomie epoki model klasyfikacji obrazów rejestruje również metryki podsumowania, takie jak macierz pomyłek, wykresy klasyfikacji, w tym krzywa ROC, krzywa kompletności precyzji i raport klasyfikacji dla modelu z najlepszej epoki, w której uzyskujemy najwyższy wynik podstawowej metryki (dokładności).
Raport klasyfikacji zawiera wartości na poziomie klasy dla metryk, takich jak precyzja, kompletność, ocena f1, obsługa, auc i average_precision z różnymi poziomami średniej — mikro, makro i ważone, jak pokazano poniżej. Zapoznaj się z definicjami metryk w sekcji metryki klasyfikacji.

Metryki wykrywania obiektów i segmentacji wystąpień
Każde przewidywanie na podstawie wykrywania obiektu obrazu lub modelu segmentacji wystąpienia jest skojarzone z współczynnikiem ufności.
Przewidywania z współczynnikiem ufności większym niż próg oceny są danymi wyjściowymi jako przewidywaniami i używanymi w obliczeniach metryk, wartością domyślną, która jest specyficzna dla modelu i może być odwoływała się ze strony dostrajania hiperparametrów(box_score_threshold hiperparametrów).
Obliczanie metryki modelu wykrywania obiektów obrazów i segmentacji wystąpień opiera się na nakładającym się pomiarze zdefiniowanym przez metrykę o nazwie IoU (skrzyżowanie w unii), która jest obliczana przez podzielenie obszaru nakładania się między prawdzie naziemnej i przewidywania według obszaru unii podstawy i przewidywań. Jednostka IoU obliczona na podstawie każdego przewidywania jest porównywana z progiem nakładania się nazywanym progiem IoU, który określa, ile przewidywań powinno nakładać się na wartość ground-truth z adnotacjami użytkownika, aby można je było uznać za pozytywną prognozę. Jeśli wartość IoU obliczona na podstawie przewidywania jest mniejsza niż próg nakładania się, przewidywanie nie zostanie uznane za pozytywne przewidywanie dla skojarzonej klasy.
Podstawowa metryka oceny modeli segmentacji obiektów obrazów i wystąpień to średnia precyzja (mAP). Protokół mAP to średnia wartość średniej precyzji (AP) we wszystkich klasach. Zautomatyzowane modele wykrywania obiektów uczenia maszynowego obsługują obliczenia mAP przy użyciu poniższych dwóch popularnych metod.
Metryki VOC Pascal:
Pascal VOC mAP to domyślny sposób obliczania mAP dla modeli wykrywania obiektów/segmentacji wystąpień. Pascal VOC style mAP metoda oblicza obszar pod wersją krzywej precyzji kompletności. Pierwszy p(ri), który jest precyzją kompletności i jest obliczany dla wszystkich unikatowych wartości kompletności. P(ri) jest następnie zastępowany maksymalną precyzją uzyskaną dla każdego odwołania r' >= ri. Wartość precyzji jest monotonicznie malejąca w tej wersji krzywej. Metryka Pascal VOC mAP jest domyślnie obliczana przy użyciu progu IoU wynoszącego 0,5. Szczegółowe wyjaśnienie tej koncepcji jest dostępne w tym blogu.
Metryki coco:
Metoda oceny COCO używa metody interpolowanej 101-punktowej dla obliczeń AP wraz ze średnio ponad dziesięcioma progami operacji we/wy. AP@[.5:.95] odpowiada średniej wartości AP dla jednostek IoU z zakresu od 0,5 do 0,95 z rozmiarem kroku 0,05. Zautomatyzowane uczenie maszynowe rejestruje wszystkie dwanaście metryk zdefiniowanych przez metodę COCO, w tym AP i AR(średnia kompletność) w różnych skalach w dziennikach aplikacji, podczas gdy interfejs użytkownika metryk pokazuje tylko protokół mAP przy progu 0,5 jednostek we/wy.
Napiwek
Ocena modelu wykrywania obiektów obrazu może używać metryk coco, jeśli validation_metric_type hiperparametr ma wartość "coco", jak wyjaśniono w sekcji dostrajania hiperparametrów.
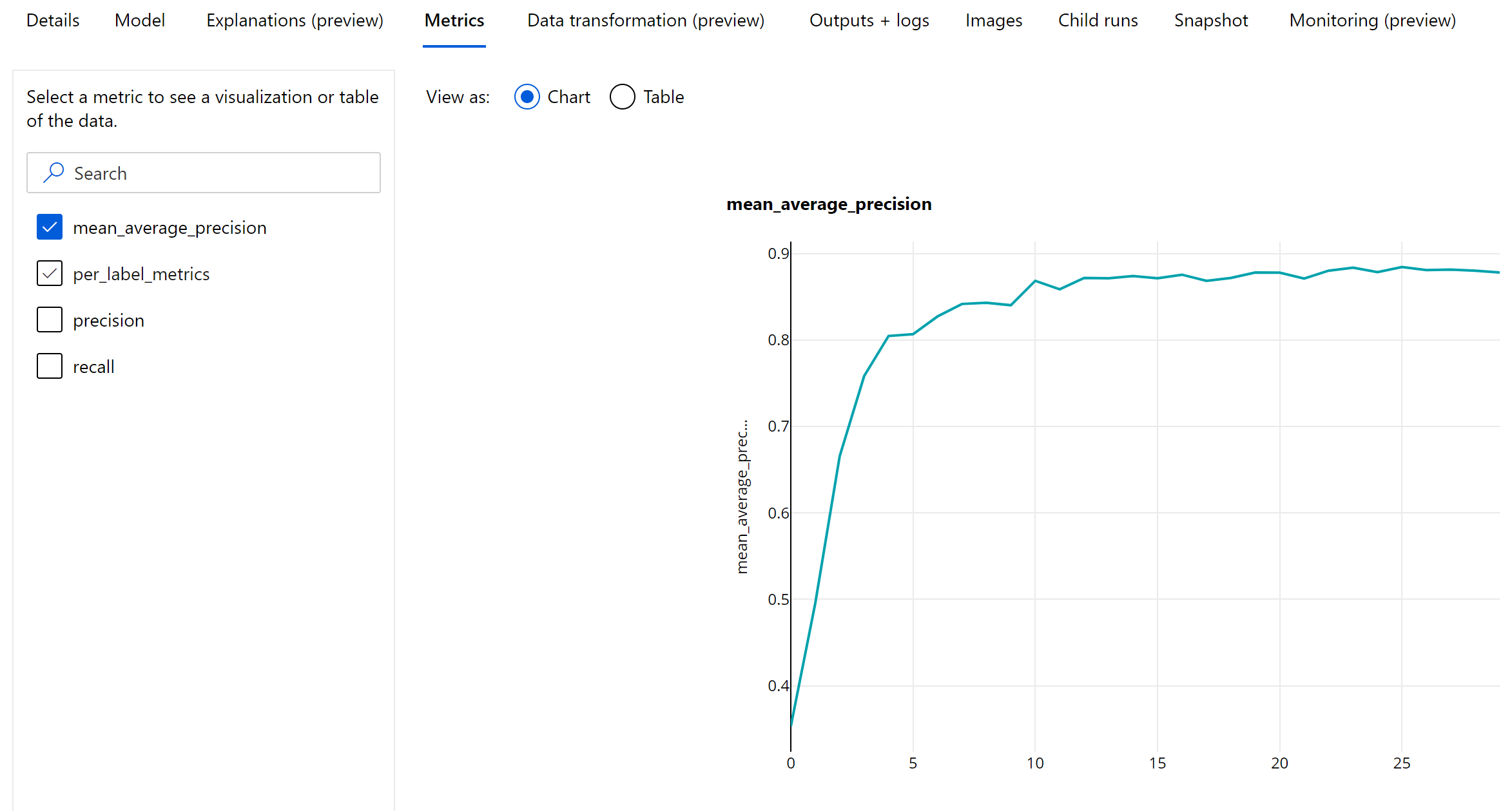
Metryki na poziomie epoki na potrzeby wykrywania obiektów i segmentacji wystąpień
Wartości mAP, precyzji i kompletności są rejestrowane na poziomie epoki dla modeli segmentacji obiektów obrazów/wystąpień. Metryki mAP, precyzji i kompletności są również rejestrowane na poziomie klasy o nazwie "per_label_metrics". Element "per_label_metrics" powinien być wyświetlany jako tabela.
Uwaga
Metryki na poziomie epoki dla precyzji, kompletności i per_label_metrics nie są dostępne w przypadku używania metody "coco".
Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji dla najlepszego zalecanego modelu automatycznego uczenia maszynowego (wersja zapoznawcza)
Pulpit nawigacyjny azure Machine Edukacja Responsible AI (Odpowiedzialne używanie sztucznej inteligencji) udostępnia jeden interfejs, który ułatwia efektywne i wydajne wdrażanie odpowiedzialnej sztucznej inteligencji. Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji jest obsługiwany tylko przy użyciu danych tabelarycznych i jest obsługiwany tylko w modelach klasyfikacji i regresji. Łączy ona kilka dojrzałych narzędzi odpowiedzialnej sztucznej inteligencji w następujących obszarach:
- Ocena wydajności i sprawiedliwości modelu
- eksploracja danych
- Możliwość interpretacji uczenia maszynowego
- Analiza błędów
Chociaż metryki i wykresy oceny modelu są dobre do mierzenia ogólnej jakości modelu, operacje takie jak inspekcja sprawiedliwości modelu, wyświetlanie wyjaśnień (znanych również jako zestaw danych wyposażonych w model używany do przewidywania), sprawdzanie błędów i potencjalnych niewidomych punktów jest niezbędne podczas praktykowania odpowiedzialnej sztucznej inteligencji. Dlatego zautomatyzowane uczenie maszynowe udostępnia pulpit nawigacyjny Odpowiedzialne używanie sztucznej inteligencji, który ułatwia obserwowanie różnych szczegółowych informacji dla modelu. Zobacz, jak wyświetlić pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji w usłudze Azure Machine Edukacja Studio.
Zobacz, jak można wygenerować ten pulpit nawigacyjny za pośrednictwem interfejsu użytkownika lub zestawu SDK.
Wyjaśnienia modelu i znaczenie cech
Chociaż metryki i wykresy oceny modelu są dobre do mierzenia ogólnej jakości modelu, sprawdzanie, które zestawy danych zawiera model używany do przewidywania, jest niezbędne podczas praktykowania odpowiedzialnej sztucznej inteligencji. Dlatego zautomatyzowane uczenie maszynowe udostępnia pulpit nawigacyjny wyjaśnień modelu do mierzenia i zgłaszania względnych wkładów funkcji zestawu danych. Zobacz, jak wyświetlić pulpit nawigacyjny wyjaśnień w usłudze Azure Machine Edukacja Studio.
Uwaga
Możliwość interpretacji, najlepsze wyjaśnienie modelu, nie jest dostępna w przypadku eksperymentów zautomatyzowanego prognozowania uczenia maszynowego, które zalecają następujące algorytmy jako najlepszy model lub zespół:
- TCNForecaster
- Autoarima
- ExponentialSmoothing
- Proroka
- Średnia
- Naiwny
- Średnia sezonowa
- Sezonowa naiwna
Następne kroki
- Wypróbuj przykładowe notesy z przykładowymi przykładami zautomatyzowanego modelu uczenia maszynowego.
- W przypadku pytań specyficznych dla zautomatyzowanego uczenia maszynowego skontaktuj się z usługą askautomatedml@microsoft.com.