Uruchamianie modeli usługi Azure Machine Edukacja z sieci szkieletowej przy użyciu punktów końcowych wsadowych (wersja zapoznawcza)
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Z tego artykułu dowiesz się, jak korzystać z usługi Azure Machine Edukacja wdrożeń wsadowych z usługi Microsoft Fabric. Mimo że przepływ pracy korzysta z modeli wdrożonych w punktach końcowych wsadowych, obsługuje również korzystanie z wdrożeń potoków wsadowych z sieci szkieletowej.
Ważne
Ta funkcja jest obecnie w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone.
Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Wymagania wstępne
- Uzyskaj subskrypcję usługi Microsoft Fabric. Możesz też zarejestrować się w celu uzyskania bezpłatnej wersji próbnej usługi Microsoft Fabric.
- Zaloguj się do usługi Microsoft Fabric.
- Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto. Wypróbuj bezpłatną lub płatną wersję usługi Azure Machine Edukacja.
- Obszar roboczy usługi Azure Machine Learning. Jeśli go nie masz, wykonaj kroki opisane w temacie Jak zarządzać obszarami roboczymi , aby je utworzyć.
- Upewnij się, że masz następujące uprawnienia w obszarze roboczym:
- Tworzenie/zarządzanie punktami końcowymi i wdrożeniami wsadowymi: użyj ról właściciel, współautor lub rola niestandardowa zezwalająca na
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*usługę . - Tworzenie wdrożeń usługi ARM w grupie zasobów obszaru roboczego: użyj ról Właściciel, Współautor lub rola niestandardowa zezwalająca
Microsoft.Resources/deployments/writew grupie zasobów, w której wdrożono obszar roboczy.
- Tworzenie/zarządzanie punktami końcowymi i wdrożeniami wsadowymi: użyj ról właściciel, współautor lub rola niestandardowa zezwalająca na
- Upewnij się, że masz następujące uprawnienia w obszarze roboczym:
- Model wdrożony w punkcie końcowym wsadowym. Jeśli go nie masz, wykonaj kroki opisane w artykule Wdrażanie modeli na potrzeby oceniania w punktach końcowych wsadowych , aby je utworzyć.
- Pobierz przykładowy zestaw danych heart-unlabeled.csv do użycia do oceniania.
Architektura
Usługa Azure Machine Edukacja nie może bezpośrednio uzyskać dostępu do danych przechowywanych w usłudze OneLake w usłudze Fabric. Można jednak użyć możliwości usługi OneLake do tworzenia skrótów w usłudze Lakehouse w celu odczytywania i zapisywania danych przechowywanych w usłudze Azure Data Lake Gen2. Ponieważ usługa Azure Machine Edukacja obsługuje magazyn usługi Azure Data Lake Gen2, ta konfiguracja umożliwia używanie usługi Fabric i azure Machine Edukacja razem. Architektura danych jest następująca:

Konfigurowanie dostępu do danych
Aby umożliwić usłudze Fabric i usłudze Azure Machine Edukacja odczytywanie i zapisywanie tych samych danych bez konieczności kopiowania ich, możesz skorzystać ze skrótów usługi OneLake i magazynów danych usługi Azure Machine Edukacja. Wskazując skrót OneLake i magazyn danych do tego samego konta magazynu, możesz upewnić się, że zarówno sieć szkieletowa, jak i usługa Azure Machine Edukacja odczytywać i zapisywać w tych samych danych bazowych.
W tej sekcji utworzysz lub zidentyfikujesz konto magazynu do użycia na potrzeby przechowywania informacji używanych przez punkt końcowy wsadowy i że użytkownicy usługi Fabric zobaczą w usłudze OneLake. Sieć szkieletowa obsługuje tylko konta magazynu z włączonymi nazwami hierarchicznymi, takimi jak usługa Azure Data Lake Gen2.
Tworzenie skrótu oneLake do konta magazynu
Otwórz środowisko inżynierowie danych usługi Synapse w usłudze Fabric.
W panelu po lewej stronie wybierz obszar roboczy Sieć szkieletowa, aby go otworzyć.
Otwórz usługę Lakehouse, której użyjesz do skonfigurowania połączenia. Jeśli nie masz już jeziora, przejdź do środowiska inżynierowie danych, aby utworzyć jezioro. W tym przykładzie użyjesz usługi Lakehouse o nazwie trusted.
Na pasku nawigacyjnym po lewej stronie otwórz więcej opcji dla pozycjiPliki, a następnie wybierz pozycję Nowy skrót , aby wyświetlić kreatora.
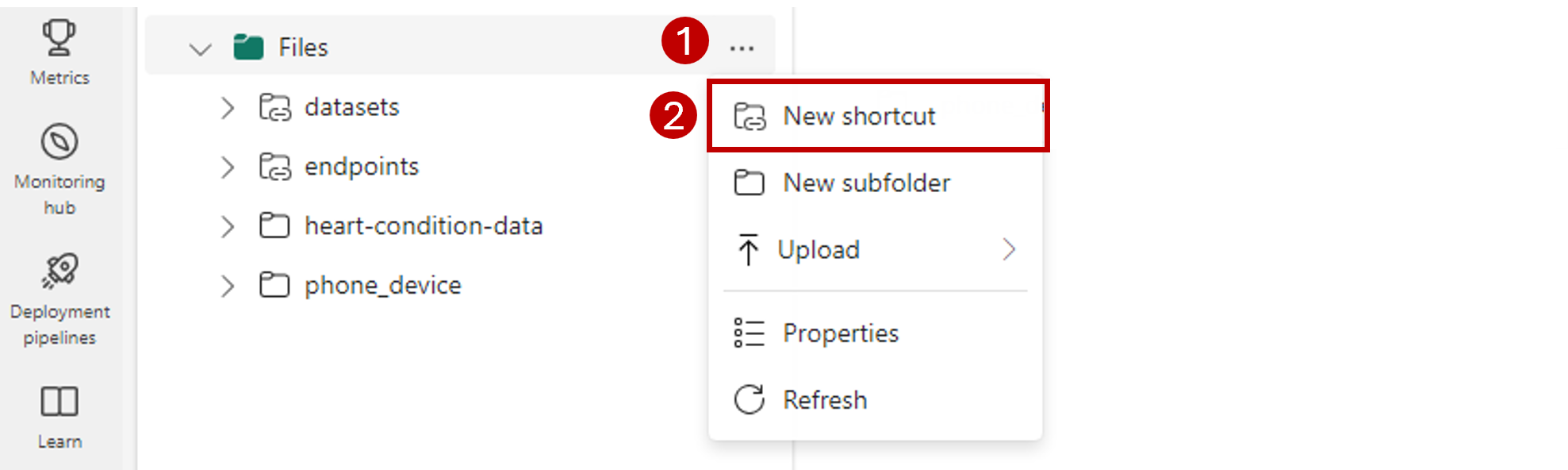
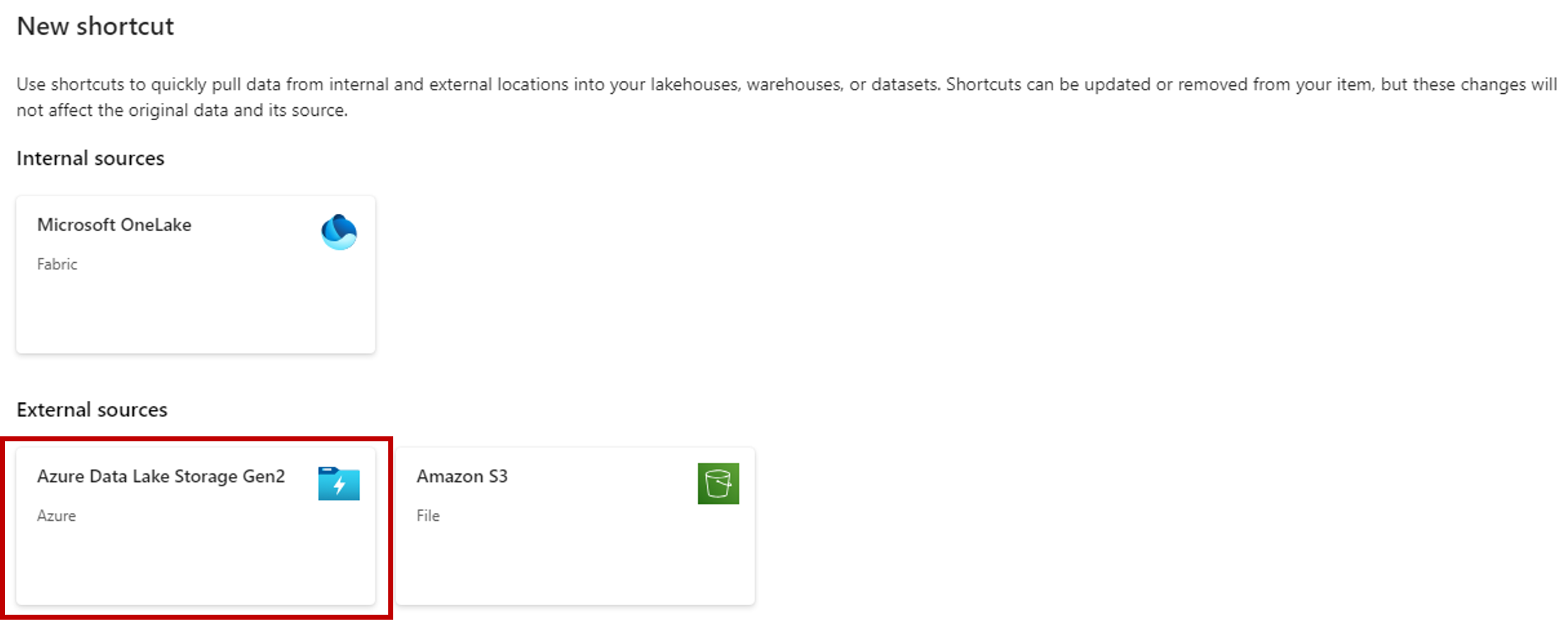
Wybierz opcję Azure Data Lake Storage Gen2.
W sekcji ustawienia Połączenie ion wklej adres URL skojarzony z kontem magazynu usługi Azure Data Lake Gen2.
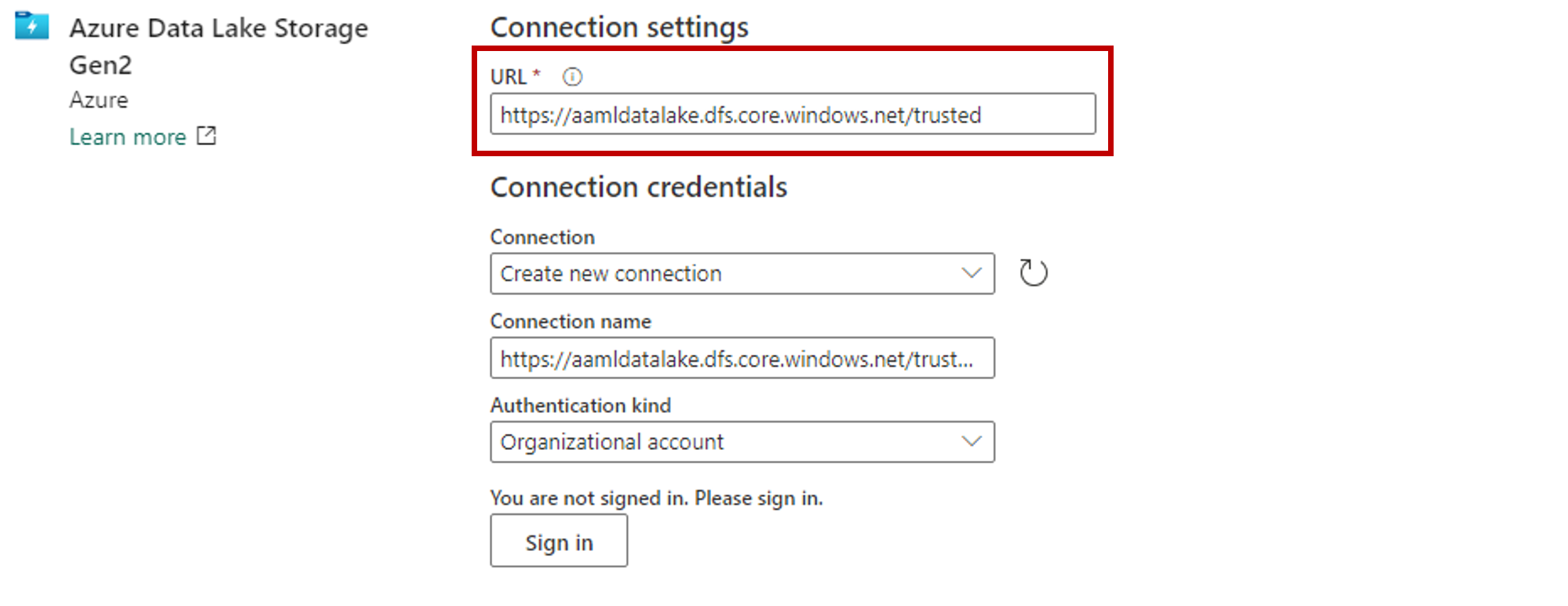
W sekcji poświadczenia Połączenie ion:
- W obszarze Połączenie ion wybierz pozycję Utwórz nowe połączenie.
- W przypadku nazwy Połączenie ion zachowaj wartość domyślną wypełniona.
- W polu Rodzaj uwierzytelniania wybierz pozycję Konto organizacyjne, aby użyć poświadczeń połączonego użytkownika za pośrednictwem protokołu OAuth 2.0.
- Wybierz pozycję Zaloguj się , aby się zalogować.
Wybierz Dalej.
W razie potrzeby skonfiguruj ścieżkę do skrótu względem konta magazynu. Użyj tego ustawienia, aby skonfigurować folder, do którego będzie wskazywany skrót.
Skonfiguruj nazwę skrótu. Ta nazwa będzie ścieżką wewnątrz jeziora. W tym przykładzie nazwij zestawy danych skrótów.
Zapisz zmiany.



Tworzenie magazynu danych wskazującego konto magazynu
Otwórz program Azure Machine Edukacja Studio.
Przejdź do obszaru roboczego usługi Azure Machine Edukacja.
Przejdź do sekcji Dane .
Wybierz kartę Magazyny danych.
Wybierz pozycję Utwórz.
Skonfiguruj magazyn danych w następujący sposób:
W polu Nazwa magazynu danych wprowadź trusted_blob.
W polu Typ magazynu danych wybierz pozycję Azure Blob Storage.
Napiwek
Dlaczego należy skonfigurować usługę Azure Blob Storage zamiast usługi Azure Data Lake Gen2? Punkty końcowe usługi Batch mogą zapisywać przewidywania tylko na kontach usługi Blob Storage. Jednak każde konto magazynu usługi Azure Data Lake Gen2 jest również kontem magazynu obiektów blob; w związku z tym można ich używać zamiennie.
Wybierz konto magazynu z kreatora przy użyciu identyfikatora subskrypcji, konta magazynu i kontenera obiektów blob (systemu plików).
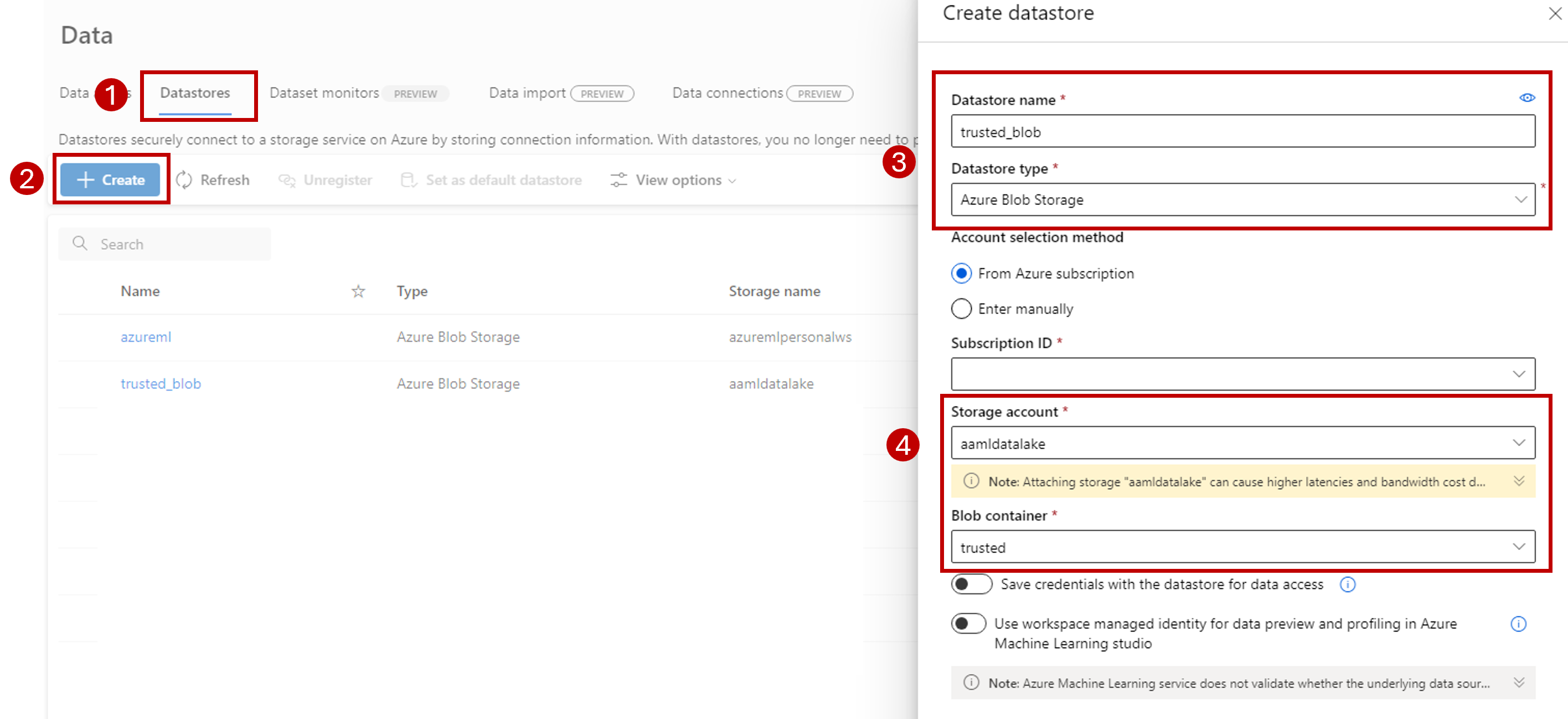
Wybierz pozycję Utwórz.
Upewnij się, że środowisko obliczeniowe, w którym działa punkt końcowy usługi Batch, ma uprawnienia do instalowania danych na tym koncie magazynu. Mimo że dostęp jest nadal udzielany przez tożsamość, która wywołuje punkt końcowy, środowisko obliczeniowe, w którym działa punkt końcowy wsadowy, musi mieć uprawnienia do zainstalowania podanego konta magazynu. Aby uzyskać więcej informacji, zobacz Uzyskiwanie dostępu do usług magazynu.
Przekazywanie przykładowego zestawu danych
Przekaż przykładowe dane punktu końcowego do użycia jako dane wejściowe:
Przejdź do obszaru roboczego sieć Szkieletowa.
Wybierz jezioro, w którym utworzono skrót.
Przejdź do skrótu zestawów danych.
Utwórz folder do przechowywania przykładowego zestawu danych, który chcesz ocenić. Nadaj folderowi nazwę uci-heart-unlabeled.
Użyj opcji Pobierz dane i wybierz pozycję Przekaż pliki, aby przekazać przykładowy zestaw danych heart-unlabeled.csv.
Przekaż przykładowy zestaw danych.
Przykładowy plik jest gotowy do użycia. Zanotuj ścieżkę do lokalizacji, w której ją zapisano.


Tworzenie sieci szkieletowej do potoku wnioskowania wsadowego
W tej sekcji utworzysz potok wnioskowania między sieciami szkieletowymi w istniejącym obszarze roboczym sieci szkieletowej i wywołasz punkty końcowe wsadowe.
Wróć do środowiska inżynierowie danych (jeśli już od niego przejdziesz), używając ikony selektora środowiska w lewym dolnym rogu strony głównej.
Otwórz obszar roboczy sieć Szkieletowa.
W sekcji Nowa strona główna wybierz pozycję Potok danych.
Nadaj potokowi nazwę i wybierz pozycję Utwórz.
Wybierz kartę Działania na pasku narzędzi na kanwie projektanta.
Wybierz więcej opcji na końcu karty i wybierz pozycję Azure Machine Edukacja.
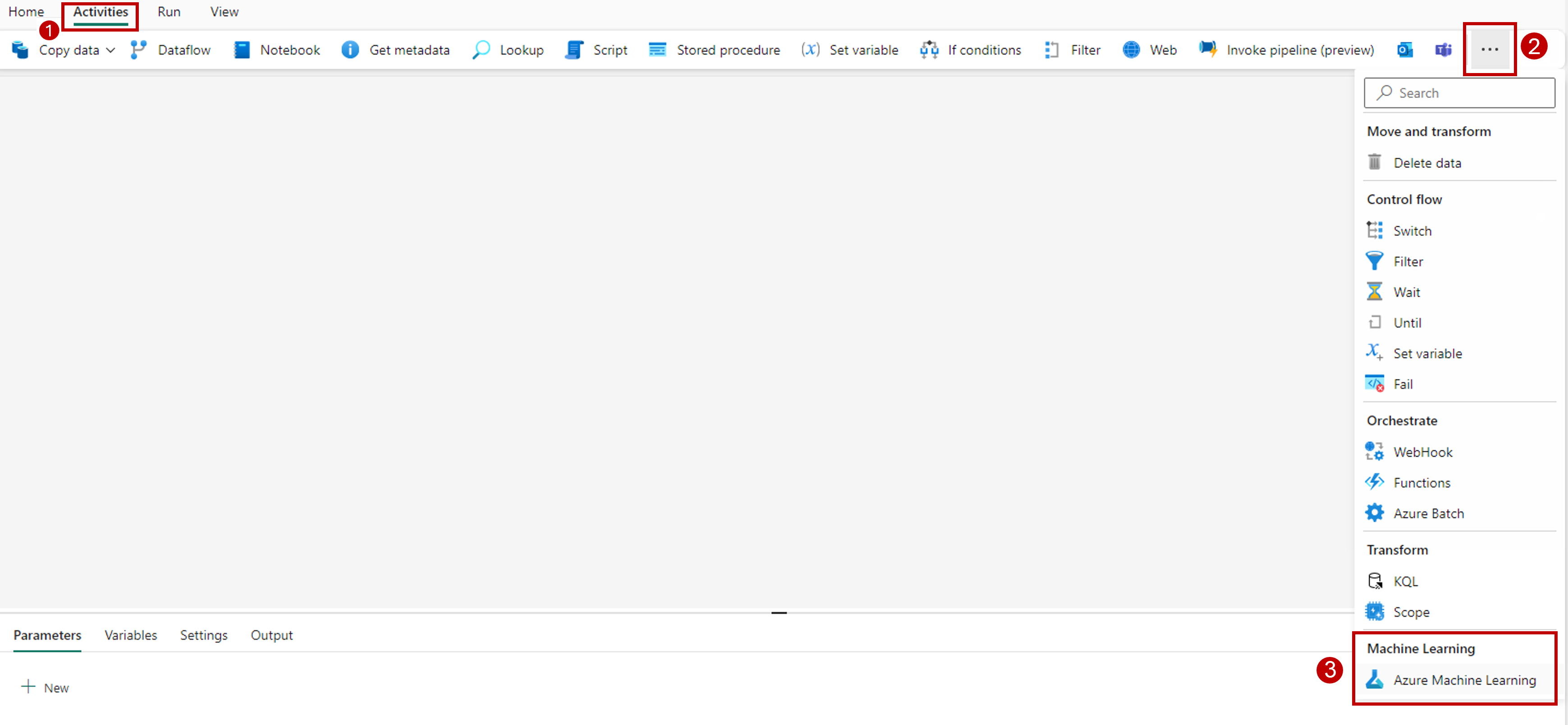
Przejdź do karty Ustawienia i skonfiguruj działanie w następujący sposób:
Wybierz pozycję Nowy obok pozycji Połączenie usługi Azure Machine Edukacja, aby utworzyć nowe połączenie z obszarem roboczym usługi Azure Machine Edukacja zawierającym wdrożenie.
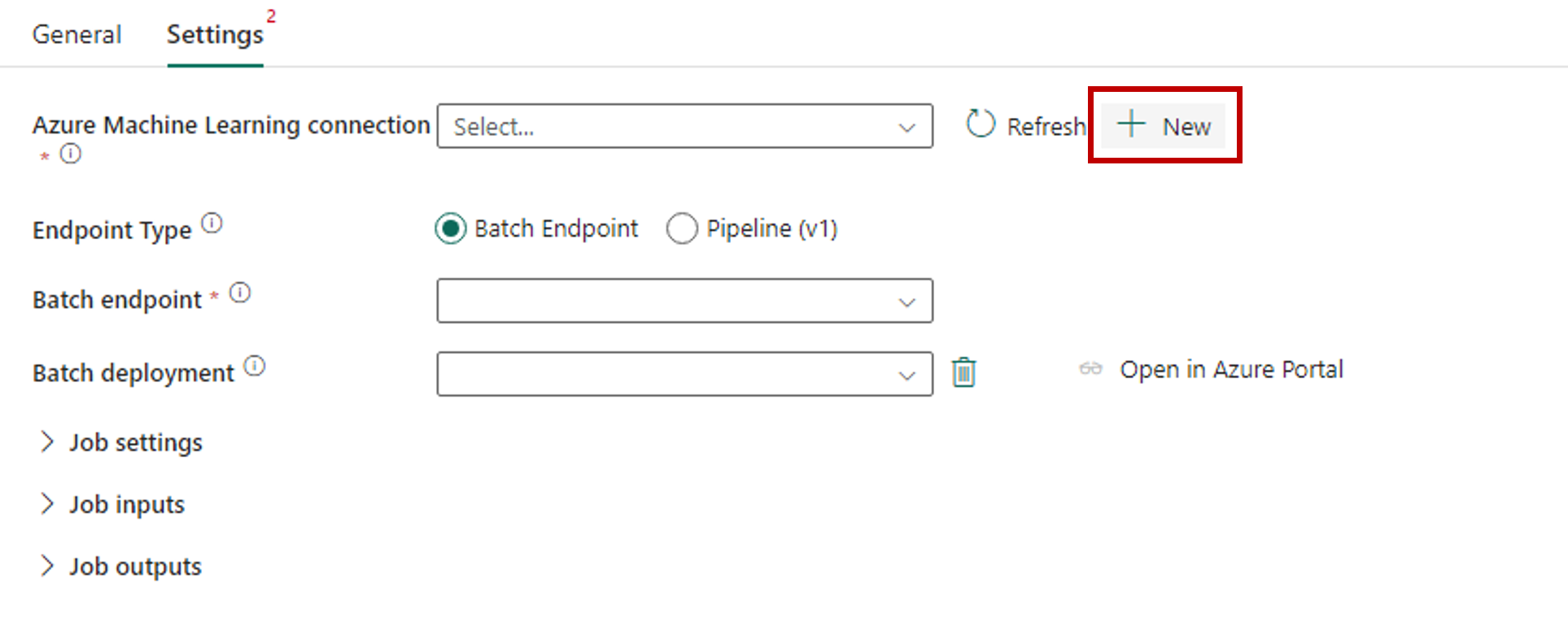
W sekcji ustawienia Połączenie ion kreatora tworzenia określ wartości identyfikatora subskrypcji, nazwy grupy zasobów i nazwy obszaru roboczego, w którym wdrożono punkt końcowy.
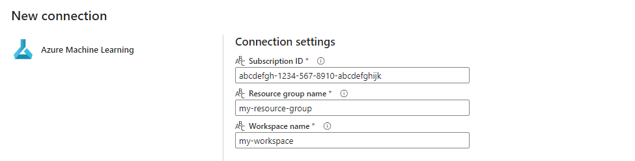
W sekcji poświadczenia Połączenie ion wybierz pozycję Konto organizacyjne jako wartość dla rodzaju uwierzytelniania dla połączenia. Konto organizacyjne używa poświadczeń połączonego użytkownika. Alternatywnie można użyć jednostki usługi. W ustawieniach produkcyjnych zalecamy użycie jednostki usługi. Niezależnie od typu uwierzytelniania upewnij się, że tożsamość skojarzona z połączeniem ma uprawnienia do wywoływania wdrożonego punktu końcowego wsadowego.
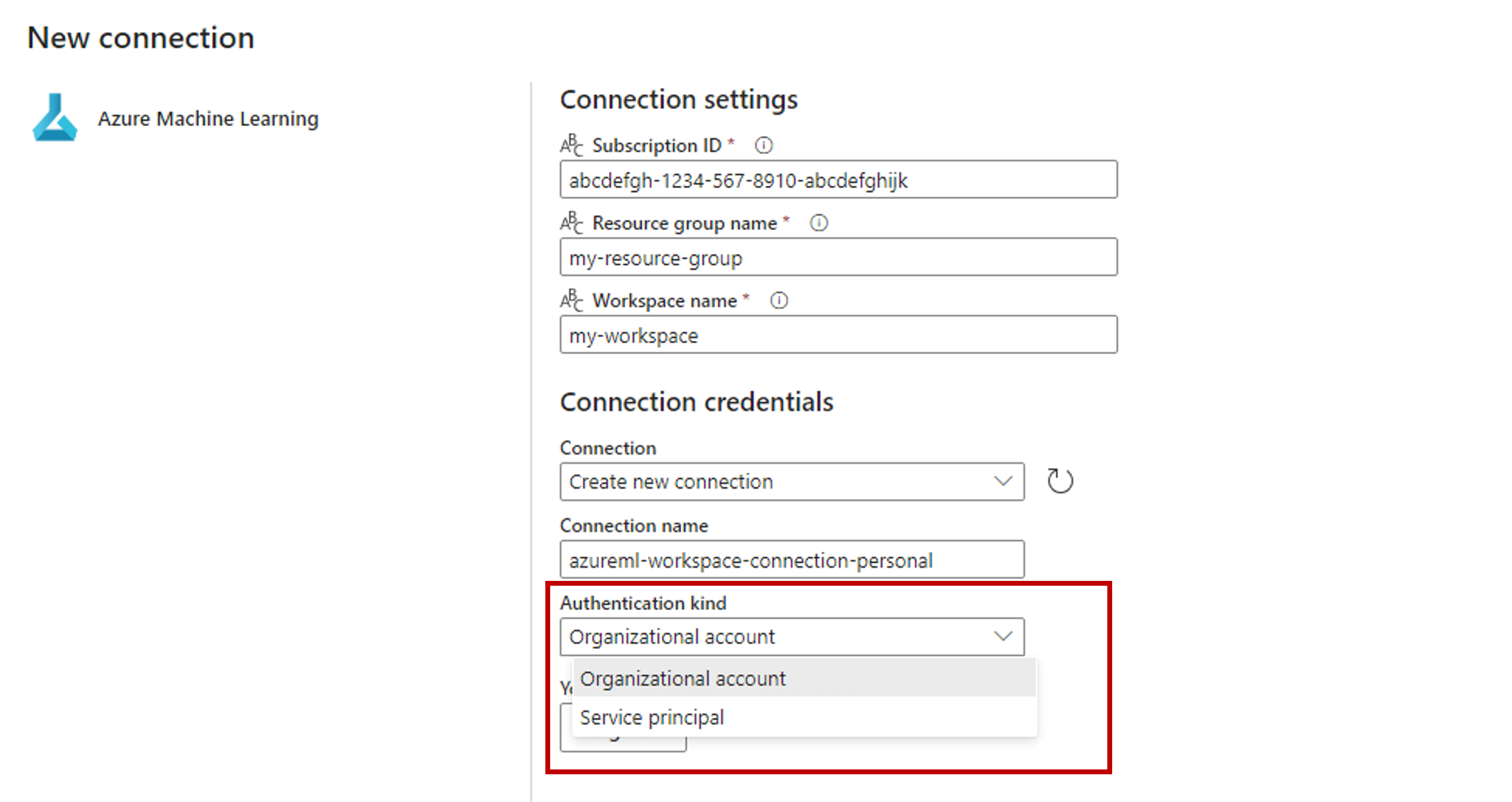
Zapisz połączenie. Po wybraniu połączenia sieć szkieletowa automatycznie wypełnia dostępne punkty końcowe wsadowe w wybranym obszarze roboczym.
W polu Punkt końcowy usługi Batch wybierz punkt końcowy partii, który chcesz wywołać. W tym przykładzie wybierz pozycję heart-classifier-....
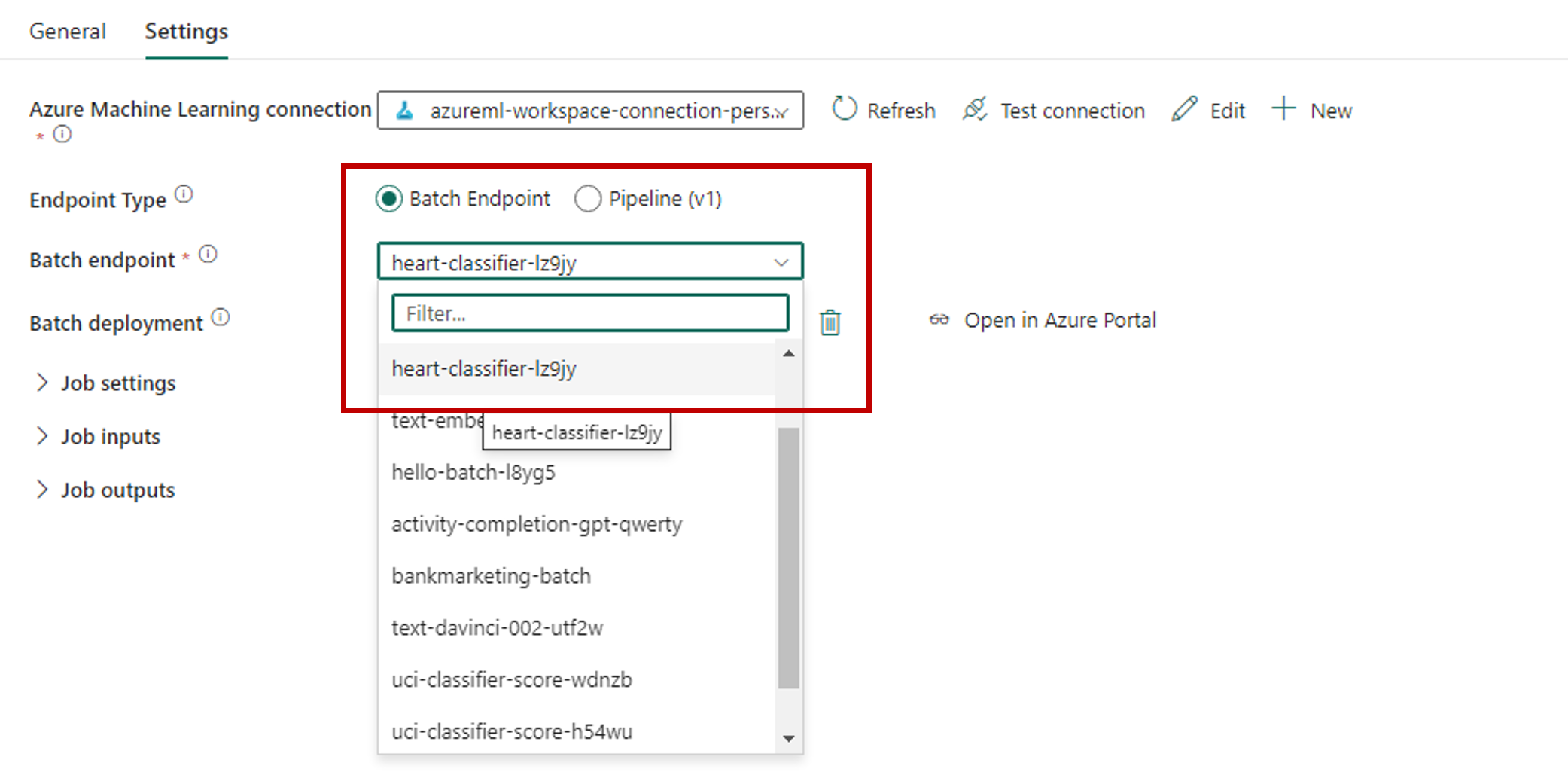
Sekcja Wdrażanie usługi Batch jest automatycznie wypełniana dostępnymi wdrożeniami w punkcie końcowym.
W przypadku wdrożenia usługi Batch wybierz określone wdrożenie z listy, jeśli jest to konieczne. Jeśli nie wybierzesz wdrożenia, sieć szkieletowa wywołuje wdrożenie domyślne w punkcie końcowym, co pozwala twórcy punktu końcowego partii zdecydować, które wdrożenie jest wywoływane. W większości scenariuszy należy zachować to domyślne zachowanie.







Konfigurowanie danych wejściowych i wyjściowych dla punktu końcowego wsadowego
W tej sekcji skonfigurujesz dane wejściowe i wyjściowe z punktu końcowego partii. Dane wejściowe do punktów końcowych wsadowych dostarczają dane i parametry potrzebne do uruchomienia procesu. Potok usługi Azure Machine Edukacja wsadowy w usłudze Fabric obsługuje wdrożenia modelu i wdrożenia potoków. Liczba i typ danych wejściowych, które podajesz, zależą od typu wdrożenia. W tym przykładzie używasz wdrożenia modelu, które wymaga dokładnie jednego danych wejściowych i generuje jedno dane wyjściowe.
Aby uzyskać więcej informacji na temat danych wejściowych i wyjściowych punktu końcowego wsadowego, zobacz Opis danych wejściowych i wyjściowych w punktach końcowych usługi Batch.
Konfigurowanie sekcji danych wejściowych
Skonfiguruj sekcję Dane wejściowe zadania w następujący sposób:
Rozwiń sekcję Dane wejściowe zadania.
Wybierz pozycję Nowy , aby dodać nowe dane wejściowe do punktu końcowego.
Nazwij dane wejściowe
input_data. Ponieważ używasz wdrożenia modelu, możesz użyć dowolnej nazwy. W przypadku wdrożeń potoków należy jednak wskazać dokładną nazwę danych wejściowych, których oczekuje model.Wybierz menu rozwijane obok właśnie dodanych danych wejściowych, aby otworzyć właściwość danych wejściowych (nazwa i wartość).
Wprowadź
JobInputTypew polu Nazwa , aby wskazać typ tworzonych danych wejściowych.Wprowadź
UriFolderw polu Wartość , aby wskazać, że dane wejściowe są ścieżką folderu. Inne obsługiwane wartości dla tego pola to UriFile (ścieżka pliku) lub Literał (dowolna wartość literału, taka jak ciąg lub liczba całkowita). Musisz użyć odpowiedniego typu, którego oczekuje wdrożenie.Wybierz znak plus obok właściwości, aby dodać inną właściwość dla tych danych wejściowych.
Wprowadź
Uriw polu Nazwa , aby wskazać ścieżkę do danych.Wprowadź
azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled, ścieżkę do zlokalizowania danych w polu Wartość . W tym miejscu użyjesz ścieżki prowadzącej do konta magazynu połączonego z usługą OneLake w sieci szkieletowej i z usługą Azure Machine Edukacja. azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled to ścieżka do plików CSV z oczekiwanymi danymi wejściowymi dla modelu wdrożonego w punkcie końcowym wsadowym. Możesz również użyć bezpośredniej ścieżki do konta magazynu, takiego jakhttps://<storage-account>.dfs.azure.com.
Napiwek
Jeśli dane wejściowe mają typ Literał, zastąp właściwość
Uriwartością "Value".
Jeśli punkt końcowy wymaga większej liczby danych wejściowych, powtórz poprzednie kroki dla każdego z nich. W tym przykładzie wdrożenia modelu wymagają dokładnie jednego danych wejściowych.
Konfigurowanie sekcji danych wyjściowych
Skonfiguruj sekcję Dane wyjściowe zadania w następujący sposób:
Rozwiń sekcję Dane wyjściowe zadania.
Wybierz pozycję Nowy , aby dodać nowe dane wyjściowe do punktu końcowego.
Nadaj danym wyjściowym nazwę
output_data. Ponieważ używasz wdrożenia modelu, możesz użyć dowolnej nazwy. W przypadku wdrożeń potoków należy jednak wskazać dokładną nazwę danych wyjściowych generowanych przez model.Wybierz menu rozwijane obok właśnie dodanych danych wyjściowych, aby otworzyć właściwość danych wyjściowych (nazwa i wartość).
Wprowadź
JobOutputTypew polu Nazwa , aby wskazać typ tworzonych danych wyjściowych.Wprowadź
UriFilew polu Wartość , aby wskazać, że dane wyjściowe są ścieżką pliku. Inną obsługiwaną wartością dla tego pola jest UriFolder (ścieżka folderu). W przeciwieństwie do sekcji danych wejściowych zadania literał (dowolna wartość literału, na przykład ciąg lub liczba całkowita) nie jest obsługiwana jako dane wyjściowe.Wybierz znak plus obok właściwości , aby dodać inną właściwość dla tych danych wyjściowych.
Wprowadź
Uriw polu Nazwa , aby wskazać ścieżkę do danych.Wprowadź
@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv'), ścieżkę do miejsca, w którym powinny zostać umieszczone dane wyjściowe, w polu Wartość . Punkty końcowe usługi Azure Machine Edukacja batch obsługują tylko używanie ścieżek magazynu danych jako danych wyjściowych. Ponieważ dane wyjściowe muszą być unikatowe, aby uniknąć konfliktów, użyto wyrażenia dynamicznego ,@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv')w celu skonstruowania ścieżki.
Jeśli punkt końcowy zwraca więcej danych wyjściowych, powtórz poprzednie kroki dla każdego z nich. W tym przykładzie wdrożenia modelu generują dokładnie jedno dane wyjściowe.
(Opcjonalnie) Konfigurowanie ustawień zadania
Możesz również skonfigurować ustawienia zadania, dodając następujące właściwości:
W przypadku wdrożeń modelu:
| Ustawienie | opis |
|---|---|
MiniBatchSize |
Rozmiar partii. |
ComputeInstanceCount |
Liczba wystąpień obliczeniowych do zapytania z wdrożenia. |
W przypadku wdrożeń potoków:
| Ustawienie | opis |
|---|---|
ContinueOnStepFailure |
Wskazuje, czy potok powinien zatrzymać przetwarzanie węzłów po awarii. |
DefaultDatastore |
Wskazuje domyślny magazyn danych do użycia dla danych wyjściowych. |
ForceRun |
Wskazuje, czy potok powinien wymusić uruchomienie wszystkich składników, nawet jeśli dane wyjściowe można wywnioskować z poprzedniego uruchomienia. |
Po skonfigurowaniu można przetestować potok.