Samouczek: prognozowanie zapotrzebowania przy użyciu zautomatyzowanego uczenia maszynowego bez kodu w usłudze Azure Machine Edukacja Studio
Dowiedz się, jak utworzyć model prognozowania szeregów czasowych bez konieczności pisania pojedynczego wiersza kodu przy użyciu zautomatyzowanego uczenia maszynowego w usłudze Azure Machine Edukacja Studio. Ten model przewiduje zapotrzebowanie na wynajem usługi udostępniania rowerów.
W tym samouczku nie piszesz żadnego kodu. Do przeprowadzenia trenowania używasz interfejsu studio. Dowiesz się, jak wykonywać następujące zadania:
- Tworzenie i ładowanie zestawu danych.
- Konfigurowanie i uruchamianie zautomatyzowanego eksperymentu uczenia maszynowego.
- Określ ustawienia prognozowania.
- Zapoznaj się z wynikami eksperymentu.
- Wdrażanie najlepszego modelu.
Wypróbuj również zautomatyzowane uczenie maszynowe dla tych innych typów modeli:
- Aby zapoznać się z przykładem modelu klasyfikacji bez kodu, zobacz Samouczek: tworzenie modelu klasyfikacji za pomocą zautomatyzowanego uczenia maszynowego w usłudze Azure Machine Edukacja.
- Aby zapoznać się z pierwszym przykładem kodu modelu wykrywania obiektów, zobacz Samouczek: trenowanie modelu wykrywania obiektów przy użyciu rozwiązania AutoML i języka Python.
Wymagania wstępne
Obszar roboczy usługi Azure Machine Learning. Zobacz Tworzenie zasobów obszaru roboczego.
Zaloguj się do studia
W tym samouczku utworzysz przebieg eksperymentu zautomatyzowanego uczenia maszynowego w usłudze Azure Machine Edukacja Studio, skonsolidowany interfejs internetowy zawierający narzędzia uczenia maszynowego do wykonywania scenariuszy nauki o danych dla praktyków nauki o danych na wszystkich poziomach umiejętności. Studio nie jest obsługiwane w przeglądarkach programu Internet Explorer.
Zaloguj się do usługi Azure Machine Edukacja Studio.
Wybierz subskrypcję i utworzony obszar roboczy.
Wybierz Rozpocznij.
W okienku po lewej stronie wybierz pozycję Zautomatyzowane uczenie maszynowe w sekcji Autor .
Wybierz pozycję +Nowe zadanie zautomatyzowanego uczenia maszynowego.
Tworzenie i ładowanie zestawu danych
Przed skonfigurowaniem eksperymentu przekaż plik danych do obszaru roboczego w postaci zestawu danych usługi Azure Machine Edukacja. Dzięki temu można mieć pewność, że dane są odpowiednio sformatowane dla eksperymentu.
W formularzu Wybieranie zestawu danych wybierz pozycję Z plików lokalnych z listy rozwijanej +Utwórz zestaw danych .
W formularzu Informacje podstawowe nadaj zestawowi danych nazwę i podaj opcjonalny opis. Typ zestawu danych powinien być domyślny dla tabelarycznego, ponieważ zautomatyzowane uczenie maszynowe w usłudze Azure Machine Edukacja Studio obecnie obsługuje tylko tabelaryczne zestawy danych.
Wybierz pozycję Dalej w lewym dolnym rogu
W formularzu Wyboru magazynu danych i pliku wybierz domyślny magazyn danych, który został automatycznie skonfigurowany podczas tworzenia obszaru roboczego, workspaceblobstore (Azure Blob Storage). Jest to lokalizacja magazynu, w której przekazujesz plik danych.
Wybierz pozycję Przekaż pliki z listy rozwijanej Przekaż .
Wybierz plik bike-no.csv na komputerze lokalnym. Jest to plik pobrany jako warunek wstępny.
Wybierz Dalej
Po zakończeniu przekazywania formularz Ustawienia i podgląd zostanie wstępnie wypełniony na podstawie typu pliku.
Sprawdź, czy formularz Ustawienia i podgląd został wypełniony w następujący sposób, a następnie wybierz przycisk Dalej.
Pole opis Wartość dla samouczka File format Definiuje układ i typ danych przechowywanych w pliku. Rozdzielane Ogranicznik Co najmniej jeden znak określający granicę między oddzielnymi, niezależnymi regionami w postaci zwykłego tekstu lub innych strumieni danych. Comma Kodowanie Określa, jakiego bitu do tabeli schematów znaków używać do odczytywania zestawu danych. UTF-8 Nagłówki kolumn Wskazuje, jak będą traktowane nagłówki zestawu danych, jeśli istnieją. Tylko pierwszy plik ma nagłówki Pomiń wiersze Wskazuje, ile wierszy zostanie pominiętych w zestawie danych, jeśli istnieje. Brak Formularz Schemat umożliwia dalszą konfigurację danych dla tego eksperymentu.
W tym przykładzie wybierz opcję ignorowania zwykłych i zarejestrowanych kolumn. Te kolumny są podziałem kolumny cnt , dlatego nie uwzględniamy ich.
W tym przykładzie pozostaw wartości domyślne właściwości i typ.
Wybierz Dalej.
W formularzu Potwierdź szczegóły sprawdź, czy informacje są zgodne z informacjami wcześniej wypełnionymi w formularzach Podstawowe informacje i Ustawienia i podglądu.
Wybierz pozycję Utwórz , aby ukończyć tworzenie zestawu danych.
Wybierz zestaw danych po wyświetleniu go na liście.
Wybierz Dalej.
Konfigurowanie zadania
Po załadowaniu i skonfigurowaniu danych skonfiguruj docelowy obiekt obliczeniowy zdalny i wybierz kolumnę w danych, które chcesz przewidzieć.
- Wypełnij formularz Konfigurowanie zadania w następujący sposób:
Wprowadź nazwę eksperymentu:
automl-bikeshareWybierz pozycję cnt jako kolumnę docelową, co chcesz przewidzieć. Ta kolumna wskazuje łączną liczbę wypożyczeń udziałów rowerów.
Wybierz klaster obliczeniowy jako typ obliczeniowy.
Wybierz pozycję +Nowy , aby skonfigurować docelowy obiekt obliczeniowy. Zautomatyzowane uczenie maszynowe obsługuje tylko środowisko obliczeniowe usługi Azure Machine Edukacja.
Wypełnij formularz Select virtual machine (Wybieranie maszyny wirtualnej), aby skonfigurować obliczenia.
Pole opis Wartość dla samouczka Warstwa maszyny wirtualnej Wybierz priorytet, jaki powinien mieć eksperyment Dedykowane Typ maszyny wirtualnej Wybierz typ maszyny wirtualnej dla obliczeń. Procesor CPU (centralna jednostka przetwarzania) Rozmiar maszyny wirtualnej Wybierz rozmiar maszyny wirtualnej dla obliczeń. Lista zalecanych rozmiarów jest udostępniana na podstawie danych i typu eksperymentu. Standard_DS12_V2 Wybierz przycisk Dalej , aby wypełnić formularz Konfigurowanie ustawień.
Pole opis Wartość dla samouczka Nazwa obiektu obliczeniowego Unikatowa nazwa identyfikująca kontekst obliczeniowy. bike-compute Minimalna/maksymalna liczba węzłów Aby profilować dane, należy określić co najmniej jeden węzeł. Minimalna liczba węzłów: 1
Maksymalna liczba węzłów: 6Bezczynność sekund przed skalowaniem w dół Czas bezczynności przed automatycznym skalowaniem klastra w dół do minimalnej liczby węzłów. 120 (ustawienie domyślne) Ustawienia zaawansowane Ustawienia skonfigurować i autoryzować sieć wirtualną na potrzeby eksperymentu. Brak Wybierz pozycję Utwórz , aby uzyskać docelowy obiekt obliczeniowy.
Ukończenie tego procesu może potrwać kilka minut.
Po utworzeniu wybierz nowy docelowy obiekt obliczeniowy z listy rozwijanej.
Wybierz Dalej.
Wybieranie ustawień prognozy
Ukończ konfigurację eksperymentu zautomatyzowanego uczenia maszynowego, określając typ zadania uczenia maszynowego i ustawienia konfiguracji.
W formularzu Typ zadania i ustawienia wybierz pozycję Prognozowanie szeregów czasowych jako typ zadania uczenia maszynowego.
Wybierz datę jako kolumnęGodzina i pozostaw puste identyfikatory szeregów czasowych.
Częstotliwość to częstotliwość zbierania danych historycznych. Zachowaj zaznaczoną opcję Autowykrywanie .
Horyzont prognozy to czas na przyszłość, który chcesz przewidzieć. Usuń zaznaczenie pola Autowykrywanie i wpisz 14.
Wybierz pozycję Wyświetl dodatkowe ustawienia konfiguracji i wypełnij pola w następujący sposób. Te ustawienia umożliwiają lepszą kontrolę nad zadaniem trenowania i określanie ustawień prognozy. W przeciwnym razie wartości domyślne są stosowane na podstawie wyboru eksperymentu i danych.
Dodatkowe konfiguracje opis Wartość dla samouczka Metryka podstawowa Metryka oceny mierzona przez algorytm uczenia maszynowego. Znormalizowany błąd średniokwadratowy z średnią główną Wyjaśnienie najlepszego modelu Automatycznie pokazuje możliwość wyjaśnienia najlepszego modelu utworzonego przez zautomatyzowane uczenie maszynowe. Włączanie Zablokowane algorytmy Algorytmy, które mają zostać wykluczone z zadania trenowania Skrajne losowe drzewa Dodatkowe ustawienia prognozowania Te ustawienia pomagają zwiększyć dokładność modelu.
Opóźnienie wartości docelowej prognozy: jak daleko chcesz skonstruować opóźnienia zmiennej docelowej
Docelowe okno stopniowe: określa rozmiar okna kroczącego, w którym są generowane funkcje, takie jak maksymalna, minimalna i suma.
Opóźnienie wartości docelowej prognozy: Brak
Docelowy rozmiar okna kroczącego: BrakKryterium wyjścia Jeśli zostaną spełnione kryteria, zadanie trenowania zostanie zatrzymane. Czas zadania szkolenia (godziny): 3
Próg oceny metryki: BrakWspółbieżność Maksymalna liczba wykonanych iteracji równoległych na iterację Maksymalna liczba iteracji współbieżnych: 6 Wybierz pozycję Zapisz.
Wybierz Dalej.
Na formularzu weryfikacji i testowania [opcjonalnie]
- Wybierz k-fold krzyżową walidację jako typ walidacji.
- Wybierz wartość 5 jako liczbę krzyżowych walidacji.
Uruchom eksperyment
Aby uruchomić eksperyment, wybierz pozycję Zakończ. Zostanie otwarty ekran Szczegóły zadania ze stanem zadania u góry obok numeru zadania. Ten stan jest aktualizowany w miarę postępu eksperymentu. Powiadomienia są również wyświetlane w prawym górnym rogu programu Studio, aby poinformować Cię o stanie eksperymentu.
Ważne
Przygotowanie trwa od 10 do 15 minut , aby przygotować zadanie eksperymentu.
Po uruchomieniu kolejne 2–3 minuty dla każdej iteracji trwa 2–3 minuty.
W środowisku produkcyjnym prawdopodobnie odejdziesz trochę, ponieważ ten proces zajmuje trochę czasu. Podczas oczekiwania zalecamy rozpoczęcie eksplorowania przetestowanych algorytmów na karcie Modele w miarę ich ukończenia.
Eksplorowanie modeli
Przejdź do karty Modele , aby zobaczyć przetestowane algorytmy (modele). Domyślnie modele są uporządkowane według wyniku metryki w miarę ich ukończenia. W tym samouczku model, który ocenia najwyższą wartość na podstawie wybranej metryki błędu średniokwadratowego znormalizowanego głównego, znajduje się na początku listy.
Podczas oczekiwania na zakończenie wszystkich modeli eksperymentów wybierz nazwę algorytmu ukończonego modelu, aby zapoznać się ze szczegółami wydajności.
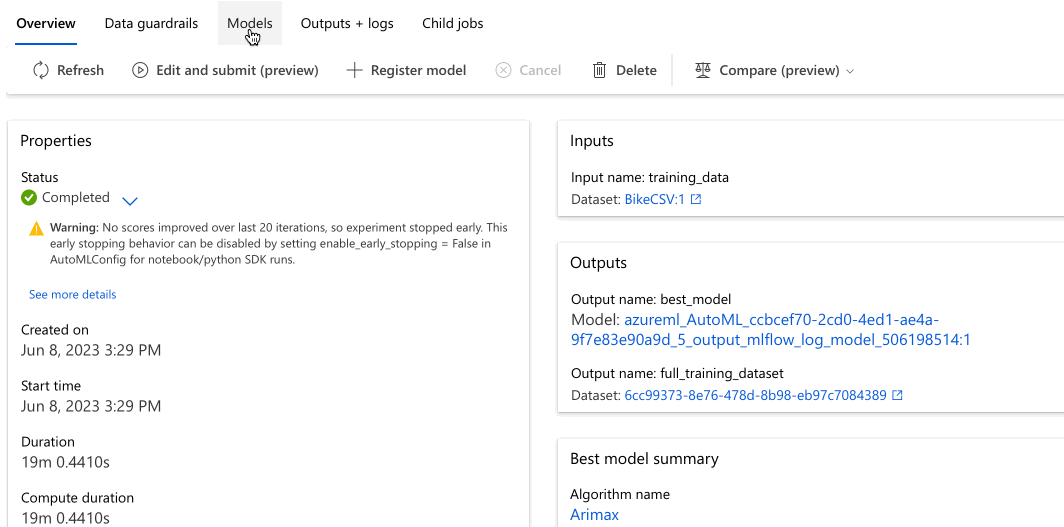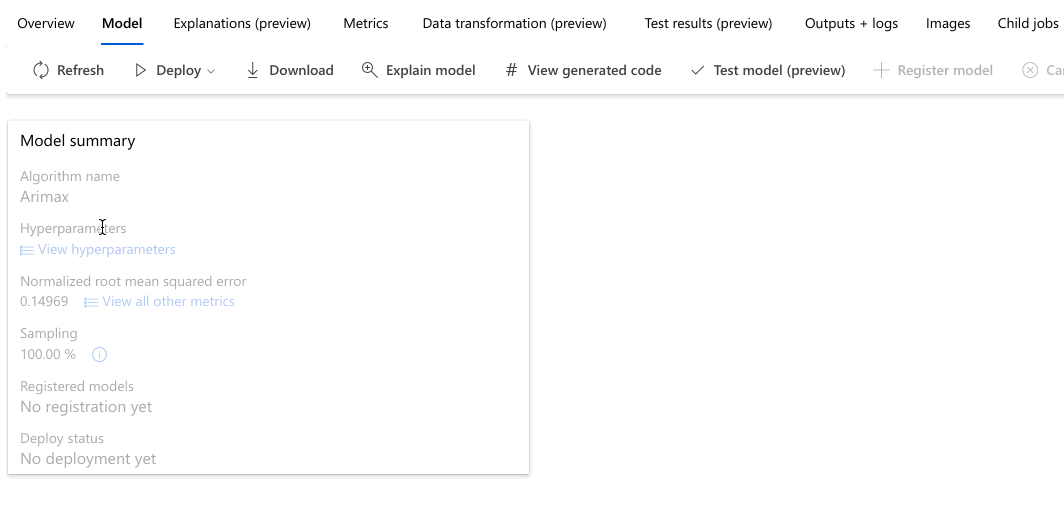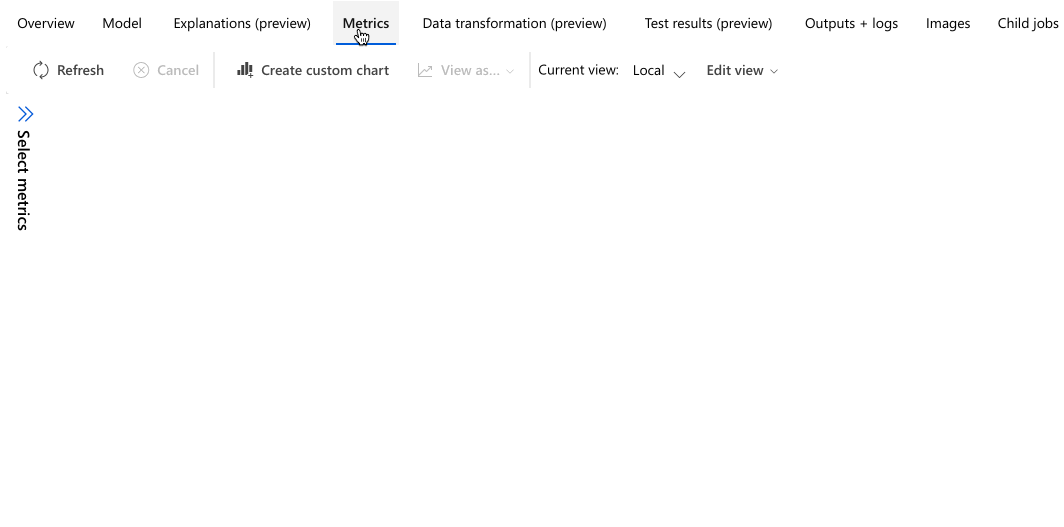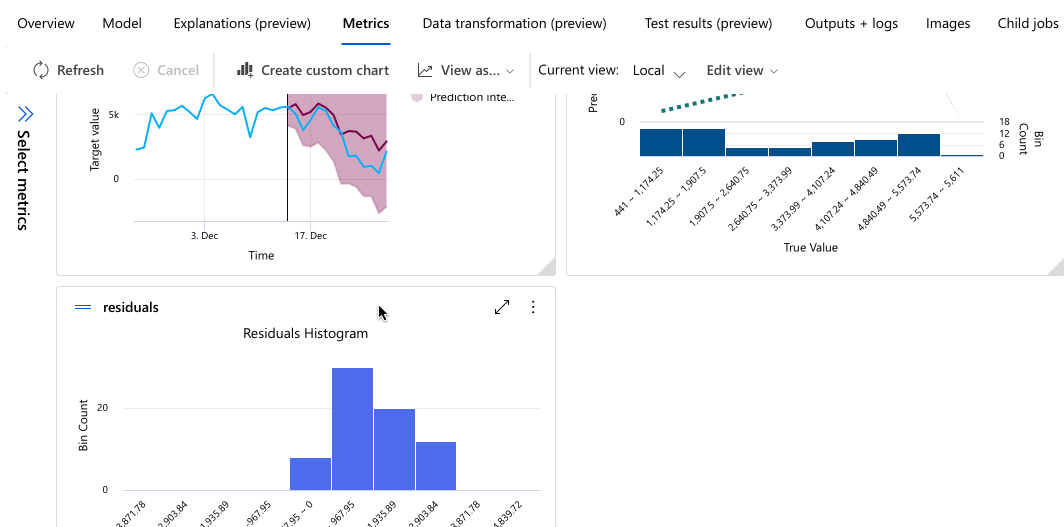
Poniższy przykład umożliwia wybranie modelu z listy modeli utworzonych przez zadanie. Następnie wybierz kartę Przegląd i Metryki , aby wyświetlić właściwości, metryki i wykresy wydajności wybranego modelu.
Wdrażanie modelu
Zautomatyzowane uczenie maszynowe w usłudze Azure Machine Edukacja Studio umożliwia wdrożenie najlepszego modelu jako usługi internetowej w kilku krokach. Wdrożenie to integracja modelu, dzięki czemu może przewidywać nowe dane i identyfikować potencjalne obszary możliwości.
W tym eksperymencie wdrożenie w usłudze internetowej oznacza, że firma zajmująca się udostępnianiem rowerów ma teraz iteracyjne i skalowalne rozwiązanie internetowe do prognozowania zapotrzebowania na wypożyczanie udziałów rowerów.
Po zakończeniu zadania przejdź z powrotem do strony nadrzędnego zadania, wybierając pozycję Zadanie 1 w górnej części ekranu.
W sekcji Podsumowanie najlepszego modelu najlepszy model w kontekście tego eksperymentu jest wybierany na podstawie metryki znormalizowanego błędu średniokwadratowego znormalizowanego elementu głównego.
Wdrożenie tego modelu trwa około 20 minut. Proces wdrażania obejmuje kilka kroków, w tym rejestrowanie modelu, generowanie zasobów i konfigurowanie ich dla usługi internetowej.
Wybierz najlepszy model , aby otworzyć stronę specyficzną dla modelu.
Wybierz przycisk Wdróż znajdujący się w lewym górnym obszarze ekranu.
Wypełnij okienko Wdrażanie modelu w następujący sposób:
Pole Wartość Nazwa wdrożenia bikeshare-deploy Opis wdrożenia wdrażanie popytu na udział rowerów Typ środowiska obliczeniowego Wybieranie wystąpienia obliczeniowego platformy Azure (ACI) Włącz uwierzytelnianie Wyłącz. Korzystanie z niestandardowych zasobów wdrażania Wyłącz. Wyłączenie umożliwia automatyczne generowanie domyślnego pliku sterownika (skryptu oceniania) i pliku środowiska. W tym przykładzie użyjemy wartości domyślnych podanych w menu Zaawansowane .
Wybierz Wdróż.
Zielony komunikat o powodzeniu pojawia się w górnej części ekranu Zadanie z informacją, że wdrożenie zostało pomyślnie uruchomione. Postęp wdrażania można znaleźć w okienku podsumowania modelu w obszarze Stan wdrożenia.
Po pomyślnym wdrożeniu masz działającą usługę internetową do generowania przewidywań.
Przejdź do następnych kroków, aby dowiedzieć się więcej na temat korzystania z nowej usługi internetowej i przetestować przewidywania przy użyciu wbudowanej obsługi usługi Azure Machine Edukacja usługi Power BI.
Czyszczenie zasobów
Pliki wdrażania są większe niż pliki danych i eksperymentów, więc kosztują więcej do przechowywania. Usuń tylko pliki wdrażania, aby zminimalizować koszty na koncie lub jeśli chcesz zachować obszar roboczy i pliki eksperymentów. W przeciwnym razie usuń całą grupę zasobów, jeśli nie planujesz używać żadnego z plików.
Usuwanie wystąpienia wdrożenia
Usuń tylko wystąpienie wdrożenia z usługi Azure Machine Edukacja Studio, jeśli chcesz zachować grupę zasobów i obszar roboczy na potrzeby innych samouczków i eksploracji.
Przejdź do usługi Azure Machine Edukacja Studio. Przejdź do obszaru roboczego i po lewej stronie w okienku Zasoby wybierz pozycję Punkty końcowe.
Wybierz wdrożenie, które chcesz usunąć, a następnie wybierz pozycję Usuń.
Wybierz pozycję Kontynuuj.
Usuwanie grupy zasobów
Ważne
Utworzone zasoby mogą być używane jako wymagania wstępne w innych samouczkach usługi Azure Machine Edukacja i artykułach z instrukcjami.
Jeśli nie planujesz korzystać z żadnych utworzonych zasobów, usuń je, aby nie ponosić żadnych opłat:
W witrynie Azure Portal na końcu z lewej strony wybierz pozycję Grupy zasobów.
Z listy wybierz utworzoną grupę zasobów.
Wybierz pozycję Usuń grupę zasobów.
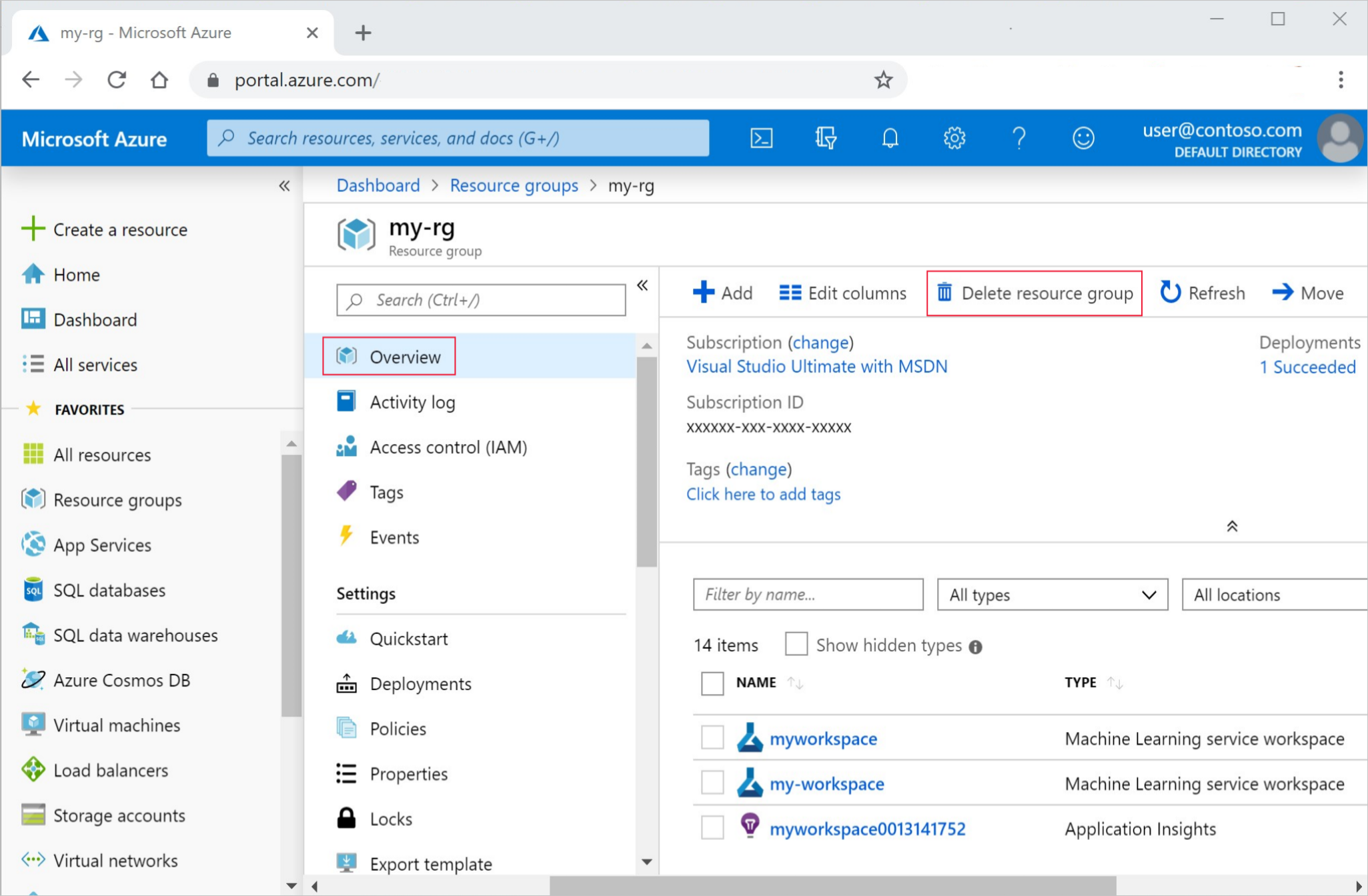
Wpisz nazwę grupy zasobów. Następnie wybierz Usuń.
Następne kroki
W tym samouczku użyto zautomatyzowanego uczenia maszynowego w usłudze Azure Machine Edukacja Studio do utworzenia i wdrożenia modelu prognozowania szeregów czasowych, który przewiduje zapotrzebowanie na udostępnianie rowerów.
Zobacz ten artykuł, aby uzyskać instrukcje dotyczące tworzenia obsługiwanego schematu usługi Power BI w celu ułatwienia użycia nowo wdrożonej usługi internetowej:
- Dowiedz się więcej na temat zautomatyzowanego uczenia maszynowego.
- Aby uzyskać więcej informacji na temat metryk klasyfikacji i wykresów, zobacz artykuł Omówienie wyników zautomatyzowanego uczenia maszynowego.
Uwaga
Ten zestaw danych udziału rowerów został zmodyfikowany na potrzeby tego samouczka. Ten zestaw danych został udostępniony w ramach konkursu Kaggle i był pierwotnie dostępny za pośrednictwem Capital Bikeshare. Można go również znaleźć w usłudze UCI Machine Edukacja Database.
Źródło: Fanaee-T, Hadi i Gama, Joao, Etykietowanie zdarzeń łączące detektory zespołów i wiedzę w tle, Postęp w sztucznej inteligencji (2013): pp. 1-15, Springer Berlin Heidelberg.