Wdrażanie modelu jako punktu końcowego online
DOTYCZY: Zestaw PYTHON SDK azure-ai-ml w wersji 2 (bieżąca)
Zestaw PYTHON SDK azure-ai-ml w wersji 2 (bieżąca)
Dowiedz się, jak wdrożyć model w punkcie końcowym online przy użyciu zestawu Azure Machine Edukacja Python SDK w wersji 2.
W tym samouczku wdrożysz i użyjesz modelu, który przewiduje prawdopodobieństwo domyślnego użycia przez klienta płatności kartą kredytową.
Czynności, które należy wykonać, to:
- Rejestrowanie modelu
- Tworzenie punktu końcowego i pierwszego wdrożenia
- Wdrażanie przebiegu wersji próbnej
- Ręczne wysyłanie danych testowych do wdrożenia
- Uzyskiwanie szczegółów wdrożenia
- Tworzenie drugiego wdrożenia
- Ręczne skalowanie drugiego wdrożenia
- Aktualizowanie alokacji ruchu produkcyjnego między obydwoma wdrożeniami
- Uzyskiwanie szczegółów drugiego wdrożenia
- Wdrażanie nowego wdrożenia i usuwanie pierwszego
W tym filmie wideo pokazano, jak rozpocząć pracę w usłudze Azure Machine Edukacja Studio, aby można było wykonać kroki opisane w samouczku. W filmie wideo pokazano, jak utworzyć notes, utworzyć wystąpienie obliczeniowe i sklonować notes. Kroki zostały również opisane w poniższych sekcjach.
Wymagania wstępne
-
Aby korzystać z usługi Azure Machine Edukacja, najpierw potrzebujesz obszaru roboczego. Jeśli go nie masz, ukończ tworzenie zasobów, aby rozpocząć tworzenie obszaru roboczego i dowiedz się więcej na temat korzystania z niego.
-
Zaloguj się do programu Studio i wybierz swój obszar roboczy, jeśli jeszcze nie jest otwarty.
-
Otwórz lub utwórz notes w obszarze roboczym:
- Utwórz nowy notes, jeśli chcesz skopiować/wkleić kod do komórek.
- Możesz też otworzyć plik tutorials/get-started-notebooks/deploy-model.ipynb z sekcji Przykłady w programie Studio. Następnie wybierz pozycję Klonuj, aby dodać notes do plików. (Zobacz, gdzie znaleźć przykłady).
Wyświetl limit przydziału maszyny wirtualnej i upewnij się, że masz wystarczający limit przydziału, aby utworzyć wdrożenia online. W tym samouczku potrzebujesz co najmniej 8 rdzeni i 12 rdzeni
STANDARD_DS3_v2STANDARD_F4s_v2. Aby wyświetlić użycie limitu przydziału maszyny wirtualnej i zwiększyć limit przydziału żądań, zobacz Zarządzanie limitami przydziału zasobów.
Ustawianie jądra
Na górnym pasku powyżej otwartego notesu utwórz wystąpienie obliczeniowe, jeśli jeszcze go nie masz.

Jeśli wystąpienie obliczeniowe zostanie zatrzymane, wybierz pozycję Uruchom środowisko obliczeniowe i poczekaj na jego uruchomienie.

Upewnij się, że jądro znajdujące się w prawym górnym rogu ma wartość
Python 3.10 - SDK v2. Jeśli nie, użyj listy rozwijanej, aby wybrać to jądro.
Jeśli zostanie wyświetlony baner z informacją o konieczności uwierzytelnienia, wybierz pozycję Uwierzytelnij.



Ważne
W pozostałej części tego samouczka znajdują się komórki notesu samouczka. Skopiuj je/wklej do nowego notesu lub przełącz się teraz do notesu, jeśli go sklonujesz.
Uwaga
- Usługa Spark Compute bezserwerowa nie jest
Python 3.10 - SDK v2domyślnie zainstalowana. Zalecamy, aby użytkownicy utworzyli wystąpienie obliczeniowe i wybrali je przed kontynuowaniem pracy z samouczkiem.
Tworzenie dojścia do obszaru roboczego
Przed rozpoczęciem pracy z kodem potrzebny jest sposób odwołowania się do obszaru roboczego. Utwórz ml_client dojście do obszaru roboczego i użyj polecenia ml_client do zarządzania zasobami i zadaniami.
W następnej komórce wprowadź identyfikator subskrypcji, nazwę grupy zasobów i nazwę obszaru roboczego. Aby znaleźć następujące wartości:
- W prawym górnym rogu paska narzędzi Azure Machine Edukacja Studio wybierz nazwę obszaru roboczego.
- Skopiuj wartość obszaru roboczego, grupy zasobów i identyfikatora subskrypcji do kodu.
- Musisz skopiować jedną wartość, zamknąć obszar i wkleić, a następnie wrócić do następnego.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Uwaga
Tworzenie MLClient nie będzie łączyć się z obszarem roboczym. Inicjowanie klienta jest leniwe i czeka po raz pierwszy, aby wykonać wywołanie (dzieje się to w następnej komórce kodu).
Rejestrowanie modelu
Jeśli wcześniejszy samouczek szkoleniowy został już ukończony, trenowanie modelu, zarejestrowano model MLflow jako część skryptu szkoleniowego i możesz przejść do następnej sekcji.
Jeśli nie ukończysz samouczka szkoleniowego, musisz zarejestrować model. Zarejestrowanie modelu przed wdrożeniem jest zalecanym najlepszym rozwiązaniem.
Poniższy kod określa path wbudowany element (gdzie mają być przekazywane pliki). Jeśli sklonujesz folder tutorials, uruchom następujący kod w następujący sposób. W przeciwnym razie pobierz pliki i metadane dla modelu, aby wdrożyć i rozpakować pliki. Zaktualizuj ścieżkę do lokalizacji rozpakowanych plików na komputerze lokalnym.
Zestaw SDK automatycznie przekazuje pliki i rejestruje model.
Aby uzyskać więcej informacji na temat rejestrowania modelu jako zasobu, zobacz Rejestrowanie modelu jako zasobu w usłudze Machine Edukacja przy użyciu zestawu SDK.
# Import the necessary libraries
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
# Provide the model details, including the
# path to the model files, if you've stored them locally.
mlflow_model = Model(
path="./deploy/credit_defaults_model/",
type=AssetTypes.MLFLOW_MODEL,
name="credit_defaults_model",
description="MLflow Model created from local files.",
)
# Register the model
ml_client.models.create_or_update(mlflow_model)
Upewnij się, że model jest zarejestrowany
Możesz sprawdzić stronę Modele w usłudze Azure Machine Edukacja Studio, aby zidentyfikować najnowszą wersję zarejestrowanego modelu.
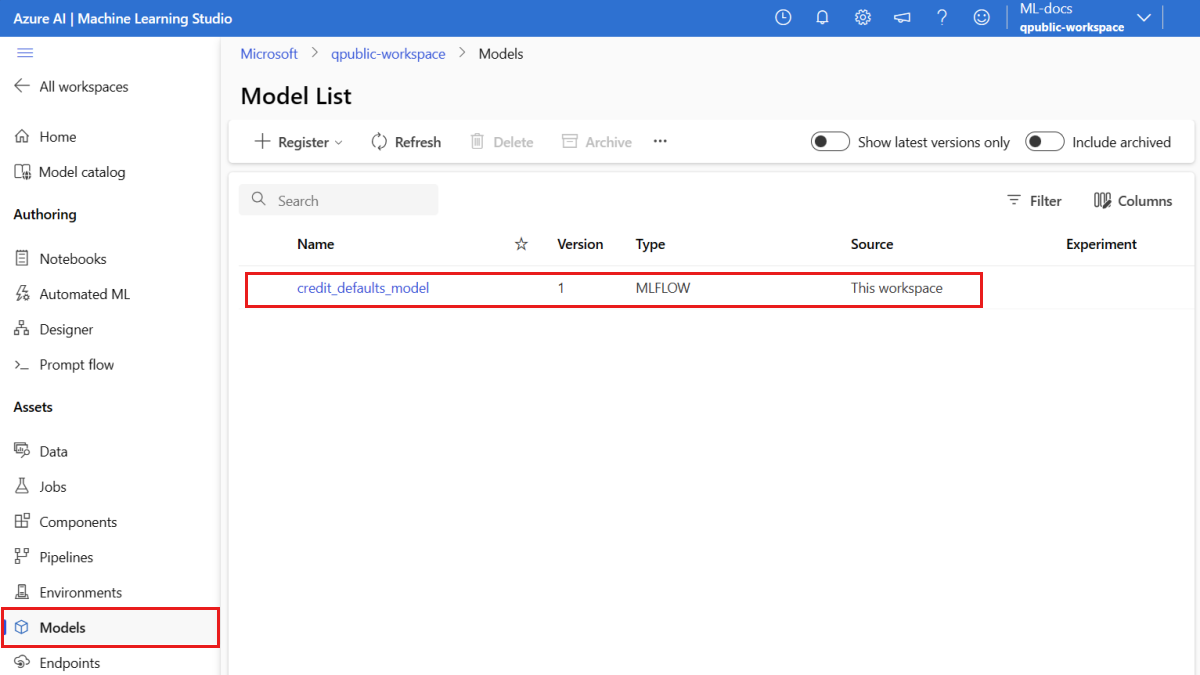
Alternatywnie poniższy kod pobiera najnowszy numer wersji do użycia.
registered_model_name = "credit_defaults_model"
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(latest_model_version)
Po zarejestrowaniu modelu możesz utworzyć punkt końcowy i wdrożenie. W następnej sekcji krótko opisano niektóre kluczowe szczegóły dotyczące tych tematów.
Punkty końcowe i wdrożenia
Po wytrenowaniu modelu uczenia maszynowego należy go wdrożyć, aby inni mogli go używać do wnioskowania. W tym celu usługa Azure Machine Edukacja umożliwia tworzenie punktów końcowych i dodawanie do nich wdrożeń.
Punkt końcowy, w tym kontekście, to ścieżka HTTPS, która udostępnia interfejs dla klientów do wysyłania żądań (danych wejściowych) do wytrenowanego modelu i odbierania wyników wnioskowania (oceniania) z modelu. Punkt końcowy zapewnia:
- Uwierzytelnianie przy użyciu uwierzytelniania opartego na kluczu lub tokenie
- Kończenie żądań protokołu TLS(SSL)
- Stabilny identyfikator URI oceniania (endpoint-name.region.inference.ml.azure.com)
Wdrożenie to zestaw zasobów wymaganych do hostowania modelu, który wykonuje rzeczywiste wnioskowanie.
Pojedynczy punkt końcowy może zawierać wiele wdrożeń. Punkty końcowe i wdrożenia są niezależnymi zasobami usługi Azure Resource Manager, które są wyświetlane w witrynie Azure Portal.
Usługa Azure Machine Edukacja umożliwia implementowanie punktów końcowych online na potrzeby wnioskowania w czasie rzeczywistym na danych klienta oraz punktów końcowych wsadowych na potrzeby wnioskowania na dużych ilościach danych w danym okresie.
W tym samouczku przedstawiono kroki implementowania zarządzanego punktu końcowego online. Zarządzane punkty końcowe online współpracują z zaawansowanymi procesorami CPU i procesorami GPU na platformie Azure w skalowalny, w pełni zarządzany sposób, który zwalnia Cię z nakładu pracy związanego z konfigurowaniem podstawowej infrastruktury wdrażania i zarządzaniem nią.
Tworzenie punktu końcowego online
Teraz, gdy masz zarejestrowany model, nadszedł czas, aby utworzyć punkt końcowy online. Nazwa punktu końcowego musi być unikatowa w całym regionie świadczenia usługi Azure. W tym samouczku utworzysz unikatową nazwę przy użyciu uniwersalnego unikatowego identyfikatora UUID. Aby uzyskać więcej informacji na temat reguł nazewnictwa punktów końcowych, zobacz Limity punktów końcowych.
import uuid
# Create a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Najpierw zdefiniuj punkt końcowy przy użyciu ManagedOnlineEndpoint klasy .
Napiwek
auth_mode: służykeydo uwierzytelniania opartego na kluczach. Służyaml_tokendo uwierzytelniania opartego na tokenach w usłudze Azure Machine Edukacja. Elementkeynie wygasa, aleaml_tokenwygasa. Aby uzyskać więcej informacji na temat uwierzytelniania, zobacz Uwierzytelnianie klientów dla punktów końcowych online.Opcjonalnie możesz dodać opis i tagi do punktu końcowego.
from azure.ai.ml.entities import ManagedOnlineEndpoint
# define an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
},
)
Przy użyciu utworzonego MLClient wcześniej punktu końcowego utwórz punkt końcowy w obszarze roboczym. To polecenie uruchamia tworzenie punktu końcowego i zwraca odpowiedź potwierdzenia, gdy tworzenie punktu końcowego będzie kontynuowane.
Uwaga
Oczekiwano, że tworzenie punktu końcowego potrwa około 2 minut.
# create the online endpoint
# expect the endpoint to take approximately 2 minutes.
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Po utworzeniu punktu końcowego można go pobrać w następujący sposób:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Omówienie wdrożeń online
Kluczowe aspekty wdrożenia obejmują:
name- Nazwa wdrożenia.endpoint_name— Nazwa punktu końcowego, który będzie zawierać wdrożenie.model— Model do użycia na potrzeby wdrożenia. Ta wartość może być odwołaniem do istniejącego modelu w wersji w obszarze roboczym lub specyfikacji wbudowanego modelu.environment— Środowisko do użycia na potrzeby wdrożenia (lub do uruchamiania modelu). Ta wartość może być odwołaniem do istniejącego środowiska w wersji w obszarze roboczym lub specyfikacji środowiska wbudowanego. Środowisko może być obrazem platformy Docker z zależnościami conda lub plikiem Dockerfile.code_configuration— konfiguracja kodu źródłowego i skryptu oceniania.path- Ścieżka do katalogu kodu źródłowego na potrzeby oceniania modelu.scoring_script- Ścieżka względna do pliku oceniania w katalogu kodu źródłowego. Ten skrypt wykonuje model na danym żądaniu wejściowym. Aby zapoznać się z przykładem skryptu oceniania, zobacz Opis skryptu oceniania w artykule "Wdrażanie modelu uczenia maszynowego przy użyciu punktu końcowego online".
instance_type— Rozmiar maszyny wirtualnej do użycia na potrzeby wdrożenia. Aby uzyskać listę obsługiwanych rozmiarów, zobacz Lista jednostek SKU zarządzanych punktów końcowych online.instance_count— liczba wystąpień do użycia na potrzeby wdrożenia.
Wdrażanie przy użyciu modelu MLflow
Usługa Azure Machine Edukacja obsługuje wdrożenie modelu utworzonego i zarejestrowanego za pomocą biblioteki MLflow bez kodu. Oznacza to, że podczas wdrażania modelu nie trzeba dostarczać skryptu oceniania ani środowiska, ponieważ skrypt oceniania i środowisko są generowane automatycznie podczas trenowania modelu MLflow. Jeśli jednak używasz modelu niestandardowego, musisz określić środowisko i skrypt oceniania podczas wdrażania.
Ważne
Jeśli zazwyczaj wdrażasz modele przy użyciu skryptów oceniania i środowisk niestandardowych i chcesz osiągnąć te same funkcje przy użyciu modeli MLflow, zalecamy przeczytanie wytycznych dotyczących wdrażania modeli MLflow.
Wdrażanie modelu w punkcie końcowym
Zacznij od utworzenia pojedynczego wdrożenia obsługującego 100% ruchu przychodzącego. Wybierz dowolną nazwę koloru (niebieską) dla wdrożenia. Aby utworzyć wdrożenie dla punktu końcowego, użyj ManagedOnlineDeployment klasy .
Uwaga
Nie trzeba określać środowiska ani skryptu oceniania, ponieważ model do wdrożenia jest modelem MLflow.
from azure.ai.ml.entities import ManagedOnlineDeployment
# Choose the latest version of the registered model for deployment
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
Przy użyciu utworzonego MLClient wcześniej polecenia utwórz wdrożenie w obszarze roboczym. To polecenie uruchamia tworzenie wdrożenia i zwraca odpowiedź potwierdzenia, gdy tworzenie wdrożenia będzie kontynuowane.
# create the online deployment
blue_deployment = ml_client.online_deployments.begin_create_or_update(
blue_deployment
).result()
# blue deployment takes 100% traffic
# expect the deployment to take approximately 8 to 10 minutes.
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Sprawdzanie stanu punktu końcowego
Możesz sprawdzić stan punktu końcowego, aby sprawdzić, czy model został wdrożony bez błędu:
# return an object that contains metadata for the endpoint
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
# print a selection of the endpoint's metadata
print(
f"Name: {endpoint.name}\nStatus: {endpoint.provisioning_state}\nDescription: {endpoint.description}"
)
# existing traffic details
print(endpoint.traffic)
# Get the scoring URI
print(endpoint.scoring_uri)
Testowanie punktu końcowego przy użyciu przykładowych danych
Po wdrożeniu modelu w punkcie końcowym możesz uruchomić wnioskowanie. Zacznij od utworzenia przykładowego pliku żądania, który jest zgodny z projektem oczekiwanym w metodzie run znalezionej w skry skryfcie oceniania.
import os
# Create a directory to store the sample request file.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
Teraz utwórz plik w katalogu deploy. Poniższa komórka kodu używa magii IPython do zapisania pliku w właśnie utworzonym katalogu.
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
Korzystając z utworzonego MLClient wcześniej pliku, uzyskaj dojście do punktu końcowego. Punkt końcowy można wywołać przy użyciu invoke polecenia z następującymi parametrami:
endpoint_name- Nazwa punktu końcowegorequest_file- Plik z danymi żądaniadeployment_name- Nazwa określonego wdrożenia do testowania w punkcie końcowym
Przetestuj niebieskie wdrożenie przy użyciu przykładowych danych.
# test the blue deployment with the sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="blue",
request_file="./deploy/sample-request.json",
)
Pobieranie dzienników wdrożenia
Sprawdź dzienniki, aby sprawdzić, czy punkt końcowy/wdrożenie zostało pomyślnie wywołane. Jeśli wystąpią błędy, zobacz Rozwiązywanie problemów z wdrażaniem punktów końcowych online.
logs = ml_client.online_deployments.get_logs(
name="blue", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Tworzenie drugiego wdrożenia
Wdróż model jako drugie wdrożenie o nazwie green. W praktyce można utworzyć kilka wdrożeń i porównać ich wydajność. Te wdrożenia mogą używać innej wersji tego samego modelu, innego modelu lub bardziej zaawansowanego wystąpienia obliczeniowego.
W tym przykładzie wdrożysz tę samą wersję modelu przy użyciu bardziej zaawansowanego wystąpienia obliczeniowego, które może potencjalnie poprawić wydajność.
# pick the model to deploy. Here you use the latest version of the registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment using a more powerful instance type
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
green_deployment = ManagedOnlineDeployment(
name="green",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_F4s_v2",
instance_count=1,
)
# create the online deployment
# expect the deployment to take approximately 8 to 10 minutes
green_deployment = ml_client.online_deployments.begin_create_or_update(
green_deployment
).result()
Skalowanie wdrożenia w celu obsługi większej liczby ruchu
Za pomocą utworzonego MLClient wcześniej narzędzia możesz uzyskać dojście green do wdrożenia. Następnie można ją skalować, zwiększając lub zmniejszając wartość instance_count.
W poniższym kodzie ręcznie zwiększasz wystąpienie maszyny wirtualnej. Jednak możliwe jest również automatyczne skalowanie punktów końcowych online. Automatyczne skalowanie uruchamia odpowiednią ilość zasobów na potrzeby obsługi obciążenia aplikacji. Zarządzane punkty końcowe online obsługują skalowanie automatyczne dzięki integracji z funkcją automatycznego skalowania usługi Azure Monitor. Aby skonfigurować skalowanie automatyczne, zobacz Autoskalowanie punktów końcowych online.
# update definition of the deployment
green_deployment.instance_count = 2
# update the deployment
# expect the deployment to take approximately 8 to 10 minutes
ml_client.online_deployments.begin_create_or_update(green_deployment).result()
Aktualizowanie alokacji ruchu dla wdrożeń
Możesz podzielić ruch produkcyjny między wdrożeniami. Możesz najpierw przetestować green wdrożenie przy użyciu przykładowych danych, podobnie jak w przypadku blue wdrożenia. Po przetestowaniu zielonego wdrożenia przydziel do niego niewielki procent ruchu.
endpoint.traffic = {"blue": 80, "green": 20}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Przetestuj alokację ruchu, wywołując punkt końcowy kilka razy:
# You can invoke the endpoint several times
for i in range(30):
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
)
Pokaż dzienniki z wdrożenia, green aby sprawdzić, czy istnieją żądania przychodzące, a model został pomyślnie obliczony.
logs = ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Wyświetlanie metryk przy użyciu usługi Azure Monitor
Możesz wyświetlić różne metryki (numery żądań, opóźnienie żądania, bajty sieciowe, procesor CPU/procesor GPU/dysk/pamięć itp.) dla punktu końcowego online i jego wdrożenia, korzystając z linków na stronie Szczegóły punktu końcowego w studio. Poniższe linki prowadzą do dokładnej strony metryk w witrynie Azure Portal dotyczącej punktu końcowego lub wdrożenia.

Jeśli otworzysz metryki dla punktu końcowego online, możesz skonfigurować stronę, aby wyświetlić metryki, takie jak średnie opóźnienie żądania, jak pokazano na poniższym rysunku.

Aby uzyskać więcej informacji na temat wyświetlania metryk punktów końcowych online, zobacz Monitorowanie punktów końcowych online.
Wysyłanie całego ruchu do nowego wdrożenia
Po pełnym zadowoleniu green z wdrożenia przełącz cały ruch do niego.
endpoint.traffic = {"blue": 0, "green": 100}
ml_client.begin_create_or_update(endpoint).result()
Usuwanie starego wdrożenia
Usuń stare (niebieskie) wdrożenie:
ml_client.online_deployments.begin_delete(
name="blue", endpoint_name=online_endpoint_name
).result()
Czyszczenie zasobów
Jeśli po ukończeniu tego samouczka nie będziesz używać punktu końcowego i wdrożenia, usuń je.
Uwaga
Spodziewaj się, że pełne usunięcie potrwa około 20 minut.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name).result()
Usuń wszystko
Wykonaj następujące kroki, aby usunąć obszar roboczy usługi Azure Machine Edukacja i wszystkie zasoby obliczeniowe.
Ważne
Utworzone zasoby mogą być używane jako wymagania wstępne w innych samouczkach usługi Azure Machine Edukacja i artykułach z instrukcjami.
Jeśli nie planujesz korzystać z żadnych utworzonych zasobów, usuń je, aby nie ponosić żadnych opłat:
W witrynie Azure Portal na końcu z lewej strony wybierz pozycję Grupy zasobów.
Z listy wybierz utworzoną grupę zasobów.
Wybierz pozycję Usuń grupę zasobów.
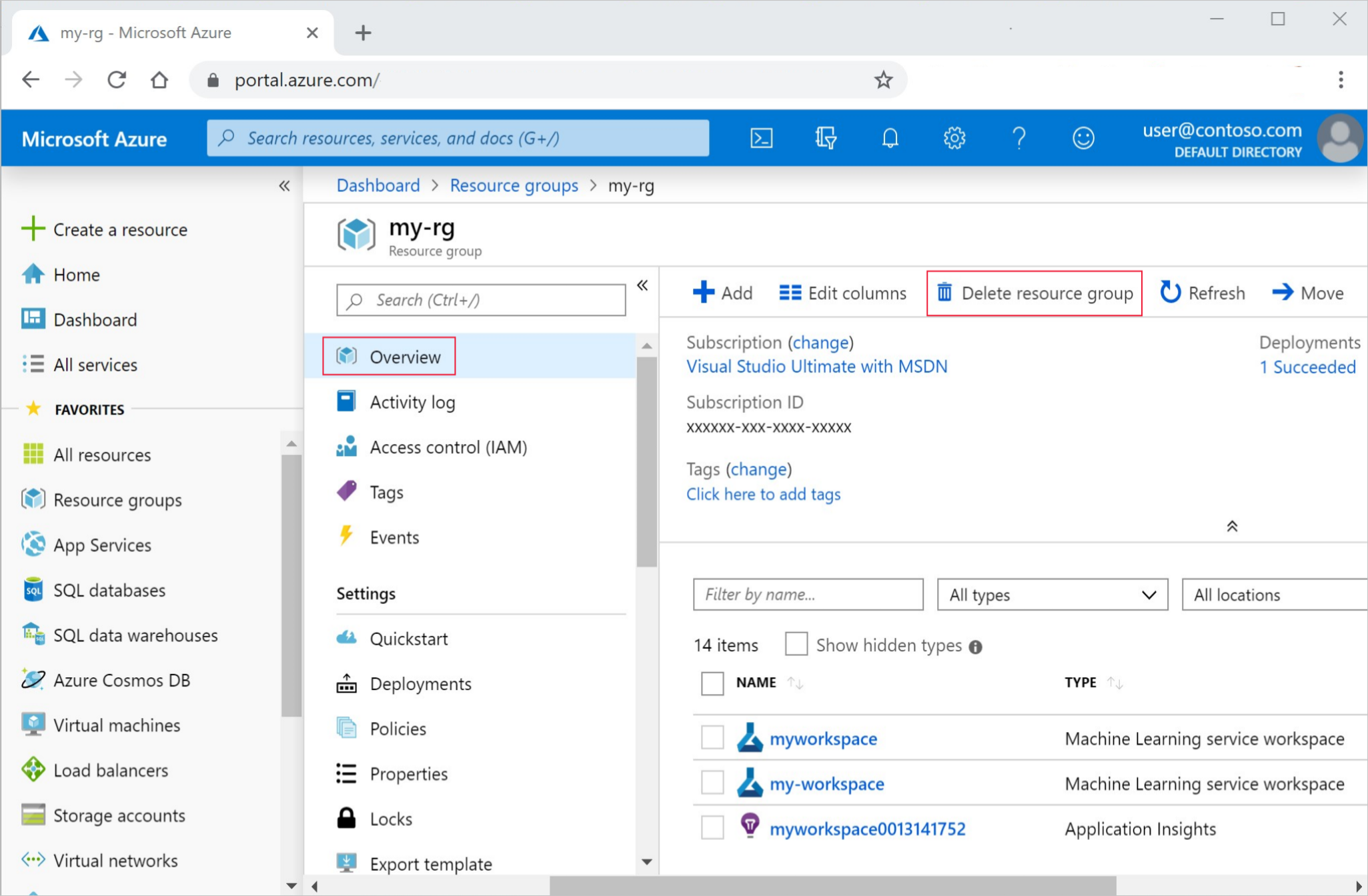
Wpisz nazwę grupy zasobów. Następnie wybierz Usuń.