Samouczek: Projektant — trenowanie modelu regresji bez kodu
Trenowanie modelu regresji liniowej, który przewiduje ceny samochodów przy użyciu projektanta usługi Azure Machine Edukacja. Ten samouczek jest pierwszą częścią dwuczęściowej serii.
W tym samouczku użyto projektanta usługi Azure Machine Edukacja, aby uzyskać więcej informacji, zobacz Co to jest projektant usługi Azure Machine Edukacja?
Uwaga
Projektant obsługuje dwa typy składników, klasyczne wstępnie utworzone składniki (wersja 1) i składniki niestandardowe (wersja 2). Te dwa typy składników nie są zgodne.
Klasyczne wstępnie utworzone składniki zapewniają wstępnie utworzone składniki na potrzeby przetwarzania danych i tradycyjnych zadań uczenia maszynowego, takich jak regresja i klasyfikacja. Ten typ składników nadal jest obsługiwany, ale nie będą do niego dodawane żadne nowego składniki.
Składniki niestandardowe umożliwiają opakowywanie własnego kodu jako składnika. Obsługuje udostępnianie składników między obszarami roboczymi i bezproblemowe tworzenie w interfejsach programu Studio, interfejsu wiersza polecenia w wersji 2 i zestawu SDK w wersji 2.
W przypadku nowych projektów zdecydowanie zalecamy użycie składnika niestandardowego, który jest zgodny z językiem AzureML w wersji 2 i będzie nadal otrzymywać nowe aktualizacje.
Ten artykuł dotyczy klasycznych wstępnie utworzonych składników i nie jest zgodny z interfejsem wiersza polecenia w wersji 2 i zestawem SDK w wersji 2.
W części jednego z samouczków dowiesz się, jak wykonywać następujące działania:
- Tworzenie nowego potoku.
- Import data.
- Przygotuj dane.
- Trenowanie modelu uczenia maszynowego.
- Ocena modelu uczenia maszynowego.
W drugiej części samouczka wdrożysz model jako punkt końcowy wnioskowania w czasie rzeczywistym, aby przewidzieć cenę dowolnego samochodu na podstawie przesłanych specyfikacji technicznych.
Uwaga
Ukończona wersja tego samouczka jest dostępna jako przykładowy potok.
Aby go znaleźć, przejdź do projektanta w obszarze roboczym. W sekcji Nowy potok wybierz pozycję Przykład 1 — Regresja: Przewidywanie cen samochodów (podstawowa).
Ważne
Jeśli nie widzisz elementów graficznych wymienionych w tym dokumencie, takich jak przyciski w studio lub projektancie, być może nie masz odpowiedniego poziomu uprawnień do obszaru roboczego. Skontaktuj się z administratorem subskrypcji platformy Azure, aby sprawdzić, czy udzielono Ci poprawnego poziomu dostępu. Aby uzyskać więcej informacji, zobacz Zarządzanie użytkownikami i rolami.
Tworzenie nowego potoku
Potoki usługi Azure Machine Edukacja organizują wiele kroków uczenia maszynowego i przetwarzania danych w jeden zasób. Potoki umożliwiają organizowanie i ponowne używanie złożonych przepływów pracy uczenia maszynowego oraz zarządzanie nimi w projektach i użytkownikach.
Aby utworzyć potok usługi Azure Machine Edukacja, potrzebujesz obszaru roboczego usługi Azure Machine Edukacja. W tej sekcji dowiesz się, jak utworzyć oba te zasoby.
Utwórz nowy obszar roboczy
Do korzystania z projektanta potrzebujesz obszaru roboczego usługi Azure Machine Edukacja. Obszar roboczy to zasób najwyższego poziomu dla usługi Azure Machine Edukacja. Zapewnia scentralizowane miejsce do pracy ze wszystkimi artefaktami tworzonymi w usłudze Azure Machine Edukacja. Aby uzyskać instrukcje dotyczące tworzenia obszaru roboczego, zobacz Tworzenie zasobów obszaru roboczego.
Uwaga
Jeśli obszar roboczy korzysta z sieci wirtualnej, należy użyć dodatkowych kroków konfiguracji, aby użyć projektanta. Aby uzyskać więcej informacji, zobacz Korzystanie z usługi Azure Machine Edukacja Studio w sieci wirtualnej platformy Azure
Tworzenie potoku
Uwaga
Projektant obsługuje dwa typy składników, wstępnie utworzone składniki klasyczne i składniki niestandardowe. Te dwa typy składników nie są zgodne.
Klasyczne wstępnie utworzone składniki udostępniają wstępnie utworzone składniki na potrzeby przetwarzania danych i tradycyjnych zadań uczenia maszynowego, takich jak regresja i klasyfikacja. Ten typ składników nadal jest obsługiwany, ale nie będą do niego dodawane żadne nowego składniki.
Składniki niestandardowe umożliwiają podanie własnego kodu jako składnika. Obsługują udostępnianie między obszarami roboczymi i bezproblemowe tworzenie w programie Studio, interfejsie wiersza polecenia i interfejsach zestawu SDK.
Ten artykuł dotyczy klasycznych wstępnie utworzonych składników.
Zaloguj się do ml.azure.com i wybierz obszar roboczy, z którym chcesz pracować.
Wybierz Projektant —> wstępnie skompilowana wersja klasyczna
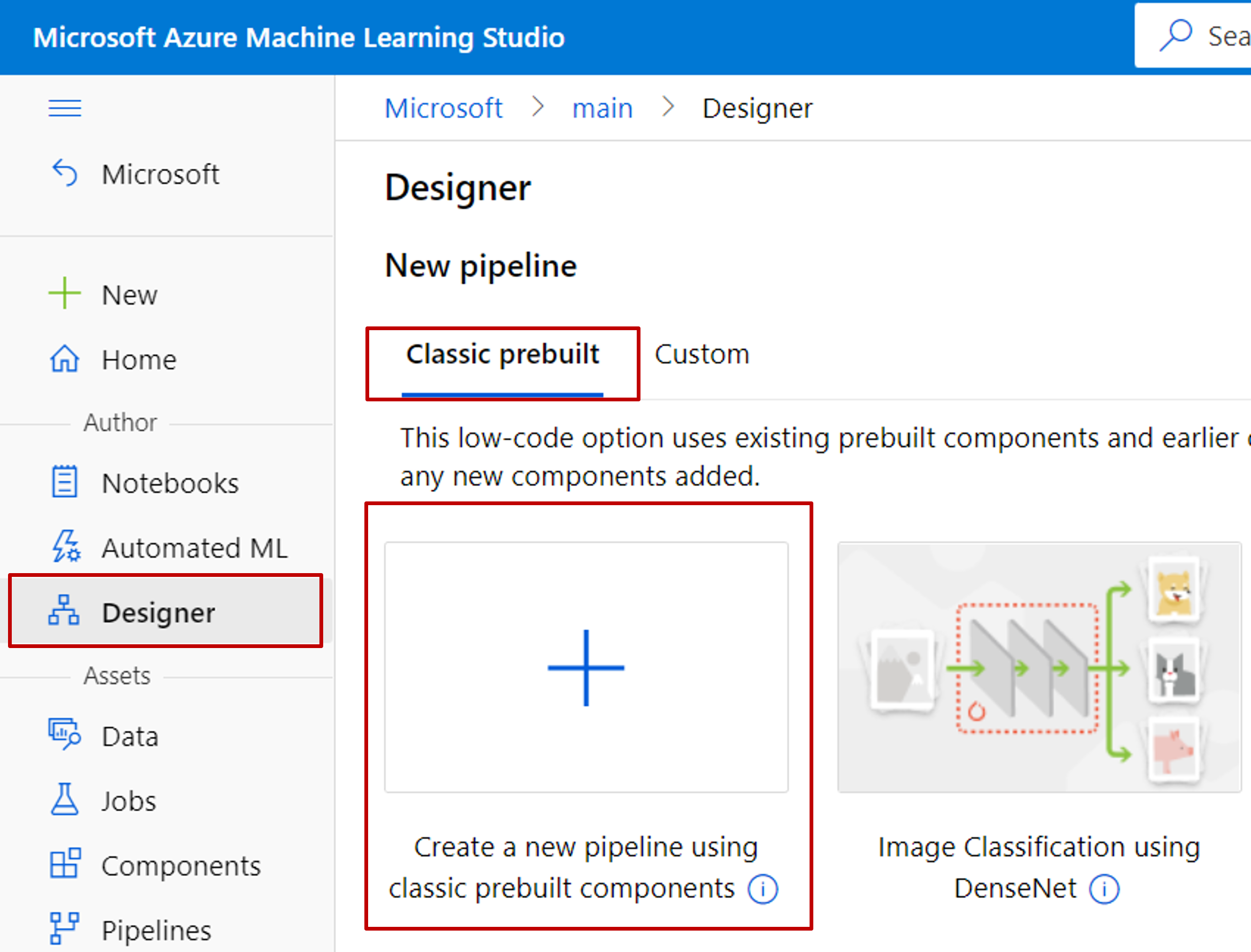
Wybierz pozycję Utwórz nowy potok przy użyciu wstępnie utworzonych składników klasycznych.
Kliknij ikonę ołówka obok automatycznie wygenerowanej nazwy wersji roboczej potoku, zmień jej nazwę na Automobile price prediction (Przewidywanie cen samochodów). Nazwa nie musi być unikatowa.
Importuj dane
Istnieje kilka przykładowych zestawów danych zawartych w projektancie, z którym możesz eksperymentować. Na potrzeby tego samouczka użyj danych cen samochodów (Nieprzetworzone).
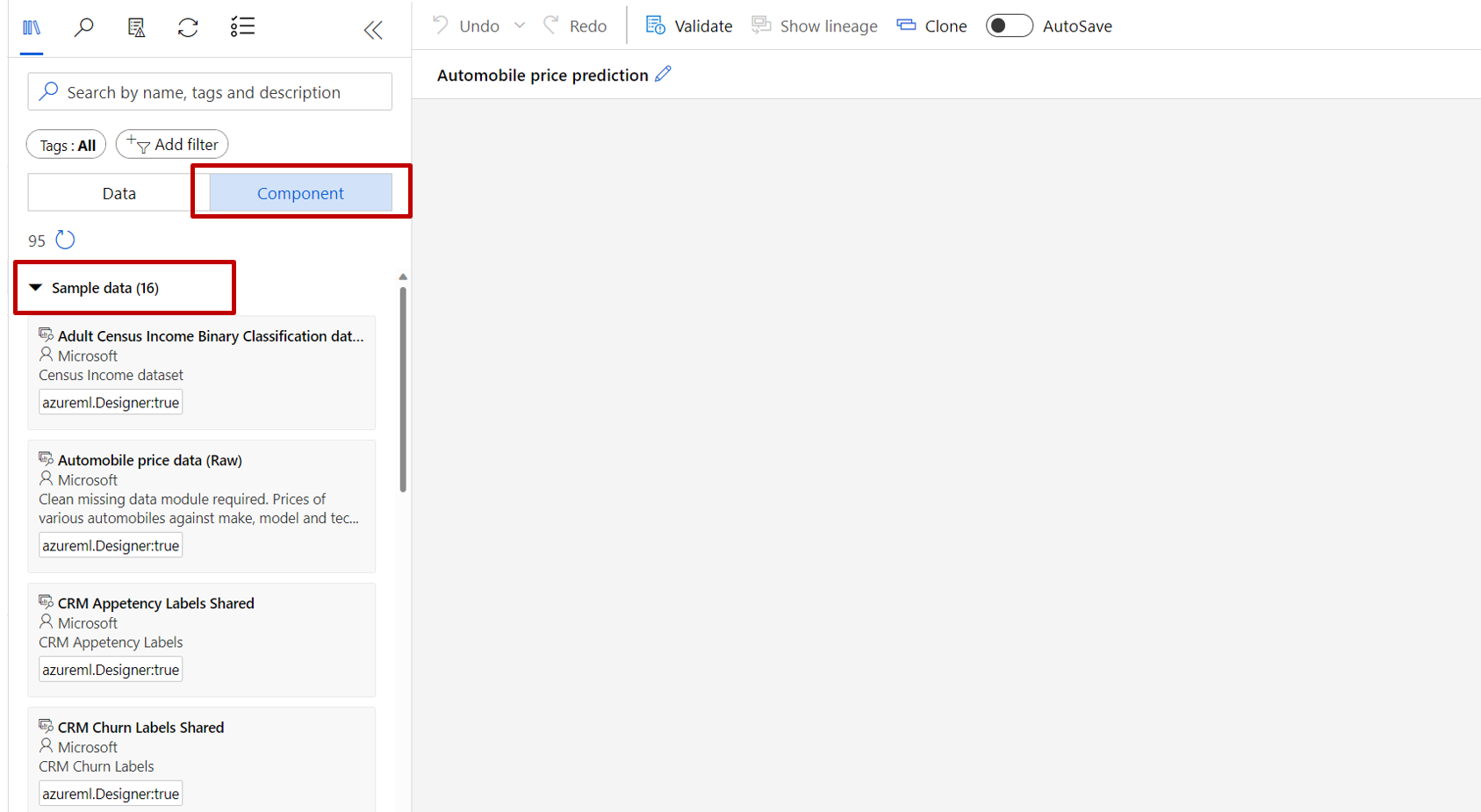
Po lewej stronie kanwy potoku znajduje się paleta zestawów danych i składników. Wybierz pozycję Składnik —> przykładowe dane.
Wybierz zestaw danych Dane cen samochodów (nieprzetworzone ) i przeciągnij go na kanwę.
Wizualizacja danych
Możesz zwizualizować dane, aby zrozumieć używany zestaw danych.
Kliknij prawym przyciskiem myszy dane cen samochodów (nieprzetworzone) i wybierz pozycję Dane wersji zapoznawczej.
Wybierz różne kolumny w oknie danych, aby wyświetlić informacje o poszczególnych kolumnach.
Każdy wiersz reprezentuje samochód, a zmienne skojarzone z poszczególnymi samochodami są wyświetlane jako kolumny. W tym zestawie danych znajduje się 205 wierszy i 26 kolumn.
Przygotowywanie danych
Zestawy danych zwykle wymagają przetwarzania wstępnego przed analizą. Być może podczas inspekcji zestawu danych zauważysz brakujące wartości. Te brakujące wartości muszą zostać wyczyszczone, aby model mógł prawidłowo analizować dane.
Usuwanie kolumny
Podczas trenowania modelu musisz zrobić coś na temat brakujących danych. W tym zestawie danych brakuje kolumny normalized-losses (znormalizowane straty), więc całkowicie wykluczysz tę kolumnę z modelu.
W palecie zestawów danych i składników po lewej stronie kanwy kliknij pozycję Składnik i wyszukaj składnik Select Columns in Dataset (Wybieranie kolumn w zestawie danych).
Przeciągnij składnik Select Columns in Dataset (Wybieranie kolumn w zestawie danych ) na kanwę. Upuść składnik poniżej składnika zestawu danych.
PołączenieZestaw danych Danych cen samochodów (nieprzetworzonych) do składnika Select Columns in Dataset (Wybieranie kolumn w zestawie danych). Przeciągnij z portu wyjściowego zestawu danych, który jest małym okręgiem w dolnej części zestawu danych na kanwie, do portu wejściowego select columns in Dataset (Wybieranie kolumn w zestawie danych), który jest małym okręgiem u góry składnika.
Napiwek
Przepływ danych jest tworzony za pośrednictwem potoku podczas łączenia portu wyjściowego jednego składnika z portem wejściowym innego.
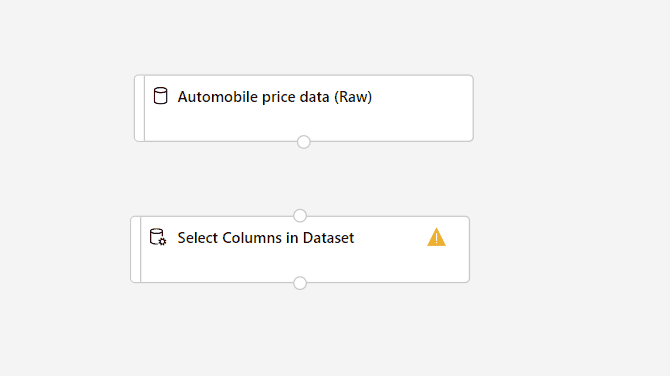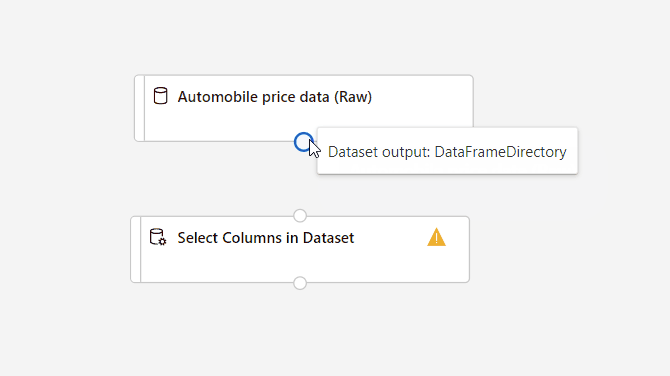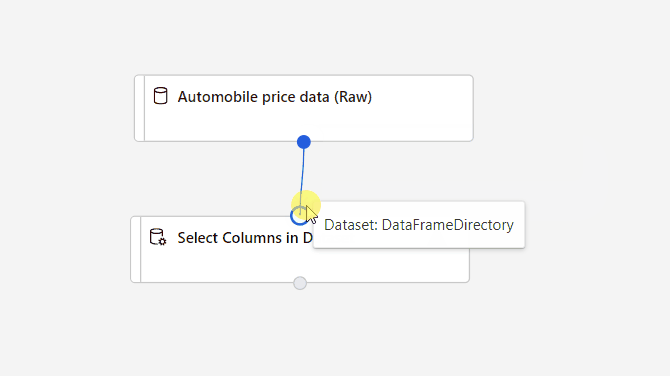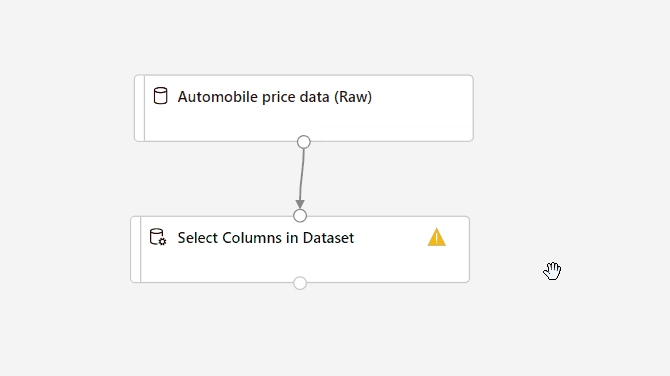
Wybierz składnik Select Columns in Dataset (Wybieranie kolumn w zestawie danych).
Kliknij ikonę strzałki w obszarze Ustawienia po prawej stronie kanwy, aby otworzyć okienko szczegółów składnika. Alternatywnie możesz kliknąć dwukrotnie składnik Select Columns in Dataset (Wybieranie kolumn w zestawie danych ), aby otworzyć okienko szczegółów.
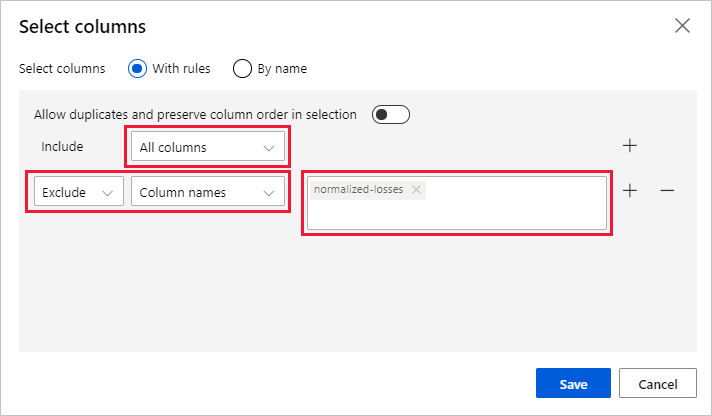
Wybierz pozycję Edytuj kolumnę po prawej stronie okienka.
Rozwiń listę rozwijaną Nazwy kolumn obok pozycji Dołącz, a następnie wybierz pozycję Wszystkie kolumny.
Wybierz pozycję , + aby dodać nową regułę.
Z menu rozwijanych wybierz pozycję Wyklucz i Nazwy kolumn.
Wprowadź znormalizowane straty w polu tekstowym.
W prawym dolnym rogu wybierz pozycję Zapisz , aby zamknąć selektor kolumn.
W okienku Szczegóły składnika Select Columns in Dataset (Wybieranie kolumn w zestawie danych) rozwiń węzeł Informacje o węźle.
Zaznacz pole tekstowe Komentarz i wprowadź wartość Wyklucz znormalizowane straty.
Komentarze będą wyświetlane na grafie, aby ułatwić organizowanie potoku.
Czyszczenie brakujących danych
Zestaw danych nadal zawiera brakujące wartości po usunięciu kolumny normalized-losses (znormalizowane straty). Pozostałe brakujące dane można usunąć przy użyciu składnika Clean Missing Data (Czyszczenie brakujących danych ).
Napiwek
Czyszczenie brakujących wartości z danych wejściowych jest wymaganiem wstępnym w przypadku używania większości składników w projektancie.
W obszarze zestawów danych i palety składników po lewej stronie kanwy kliknij pozycję Składnik i wyszukaj składnik Clean Missing Data (Czyszczenie brakujących danych).
Przeciągnij składnik Clean Missing Data (Czyszczenie brakujących danych) na kanwę potoku. Połączenie go do Wybierz pozycję Kolumny w składniku zestawu danych.
Wybierz składnik Clean Missing Data (Czyszczenie brakujących danych).
Kliknij ikonę strzałki w obszarze Ustawienia po prawej stronie kanwy, aby otworzyć okienko szczegółów składnika. Alternatywnie możesz kliknąć dwukrotnie składnik Clean Missing Data (Czyszczenie brakujących danych ), aby otworzyć okienko szczegółów.
Wybierz pozycję Edytuj kolumnę po prawej stronie okienka.
W wyświetlonym oknie Kolumny do oczyszczenia rozwiń menu rozwijane obok pozycji Uwzględnij. Wybierz, Wszystkie kolumny
Wybierz pozycję Zapisz
W okienku Szczegóły składnika Clean Missing Data (Czyszczenie brakujących danych ) w obszarze Tryb czyszczenia wybierz pozycję Usuń cały wiersz.
W okienku Szczegóły składnika Clean Missing Data (Czyszczenie brakujących danych) rozwiń węzeł Informacje o węźle.
Zaznacz pole tekstowe Komentarz i wprowadź usuń brakujące wiersze wartości.
Potok powinien teraz wyglądać mniej więcej tak:
Trenowanie modelu uczenia maszynowego
Teraz, gdy masz już składniki do przetwarzania danych, możesz skonfigurować składniki szkoleniowe.
Ponieważ chcesz przewidzieć cenę, czyli liczbę, możesz użyć algorytmu regresji. W tym przykładzie użyto modelu regresji liniowej.
Dzielenie danych
Dzielenie danych to typowe zadanie w uczeniu maszynowym. Dane zostaną podzielone na dwa oddzielne zestawy danych. Jeden zestaw danych trenuje model, a drugi sprawdzi, jak dobrze działa model.
W zestawie danych i palecie składników po lewej stronie kanwy kliknij pozycję Składnik i wyszukaj składnik Split Data (Podział danych).
Przeciągnij składnik Split Data (Podział danych) na kanwę potoku.
Połączenie lewego portuWyczyść brakujący składnik Danych do składnika Split Data (Podział danych).
Ważne
Upewnij się, że lewy port wyjściowy funkcji Clean Missing Data (Czyszczenie brakujących danych ) łączy się z podziałem danych. Lewy port zawiera oczyszczone dane. Właściwy port zawiera odrzucone dane.
Wybierz składnik Split Data (Podział danych).
Kliknij ikonę strzałki w obszarze Ustawienia po prawej stronie kanwy, aby otworzyć okienko szczegółów składnika. Alternatywnie możesz kliknąć dwukrotnie składnik Split Data (Podział danych ), aby otworzyć okienko szczegółów.
W okienku Szczegóły podziału danych ustaw pozycję Ułamek wierszy w pierwszym wyjściowym zestawie danych na wartość 0,7.
Ta opcja dzieli 70 procent danych w celu wytrenowania modelu i 30 procent na potrzeby jego testowania. Zestaw danych 70 procent będzie dostępny za pośrednictwem lewego portu wyjściowego. Pozostałe dane są dostępne za pośrednictwem odpowiedniego portu wyjściowego.
W okienku Szczegóły podziału danych rozwiń węzeł Informacje o węźle.
Zaznacz pole tekstowe Komentarz i wprowadź podział zestawu danych na zestaw treningowy (0.7) i zestaw testów (0.3).
Szkolenie modelu
Trenowanie modelu przez nadanie mu zestawu danych zawierającego cenę. Algorytm tworzy model, który wyjaśnia relację między funkcjami a ceną prezentowaną przez dane szkoleniowe.
W zestawach danych i palecie składników po lewej stronie kanwy kliknij pozycję Składnik i wyszukaj składnik Regresja liniowa.
Przeciągnij składnik Regresja liniowa do kanwy potoku.
W zestawie danych i palecie składników po lewej stronie kanwy kliknij pozycję Składnik i wyszukaj składnik Train Model (Trenowanie modelu).
Przeciągnij składnik Train Model (Trenowanie modelu) do kanwy potoku.
Połączenie danych wyjściowych Składnik Regresji liniowej po lewej stronie składnika Train Model (Trenowanie modelu).
Połączenie danych wyjściowych trenowania (lewy port)Podziel składnik Danych na właściwe dane wejściowe składnika Train Model (Trenowanie modelu).
Ważne
Upewnij się, że lewy port wyjściowy funkcji Split Data (Podział danych ) łączy się z usługą Train Model (Trenowanie modelu). Lewy port zawiera zestaw trenowania. Odpowiedni port zawiera zestaw testów.
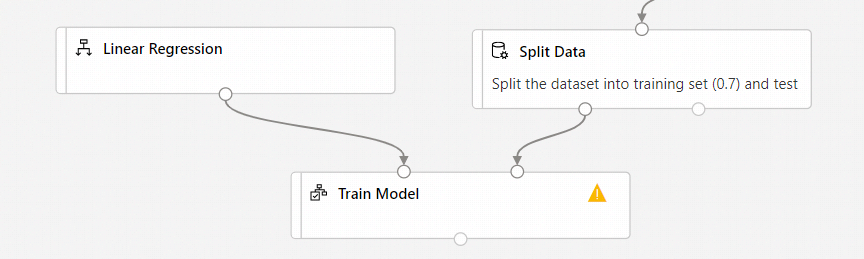
Wybierz składnik Train Model (Trenowanie modelu ).
Kliknij ikonę strzałki w obszarze Ustawienia po prawej stronie kanwy, aby otworzyć okienko szczegółów składnika. Alternatywnie możesz kliknąć dwukrotnie składnik Train Model (Trenowanie modelu ), aby otworzyć okienko szczegółów.
Wybierz pozycję Edytuj kolumnę po prawej stronie okienka.
W wyświetlonym oknie kolumny Etykieta rozwiń menu rozwijane i wybierz pozycję Nazwy kolumn.
W polu tekstowym wprowadź cenę , aby określić wartość, którą będzie przewidywać model.
Ważne
Upewnij się, że dokładnie wprowadzisz nazwę kolumny. Nie wielką literą ceny.
Potok powinien wyglądać następująco:
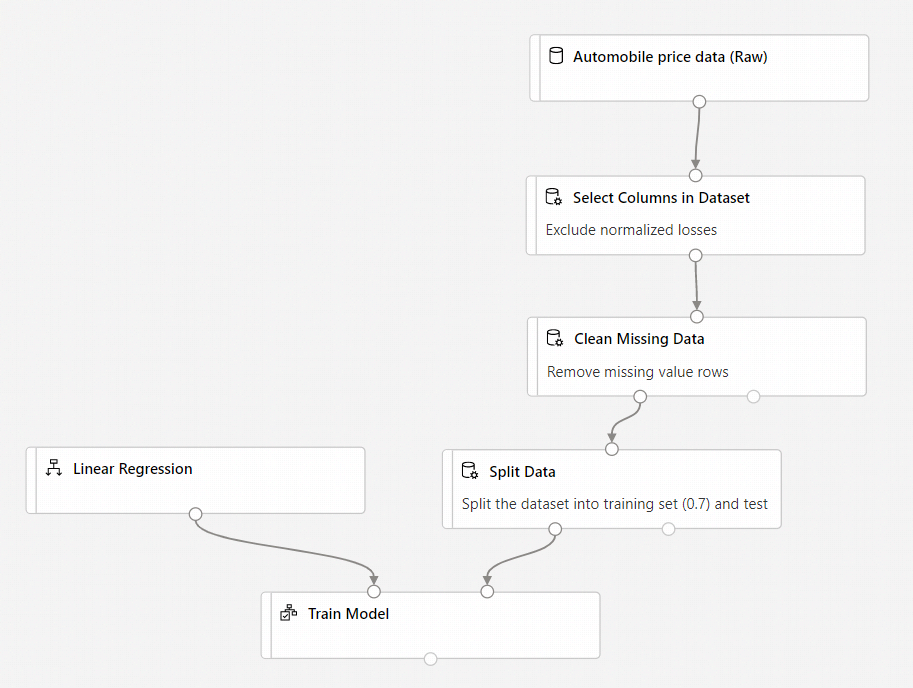
Dodawanie składnika Score Model (Generowanie wyników dla modelu)
Po wytrenowania modelu przy użyciu 70 procent danych możesz użyć go do oceny pozostałych 30 procent, aby zobaczyć, jak dobrze działa model.
W obszarze zestawów danych i palety składników po lewej stronie kanwy kliknij pozycję Składnik i wyszukaj składnik Score Model (Generowanie wyników dla modelu).
Przeciągnij składnik Score Model (Generowanie wyników dla modelu) na kanwę potoku.
Połączenie danych wyjściowych Trenowanie składnika model na lewym porcie wejściowym score model (Generowanie wyników w modelu). Połączenie dane wyjściowe danych testowych (prawy port)Podziel składnik danych na właściwy port wejściowy score model (Generowanie wyników w modelu).
Dodawanie składnika Evaluate Model
Użyj składnika Evaluate Model (Ocena modelu), aby ocenić, jak dobrze model ocenia zestaw danych testowych.
W obszarze zestawów danych i palety składników po lewej stronie kanwy kliknij pozycję Składnik i wyszukaj składnik Evaluate Model (Oceń model).
Przeciągnij składnik Evaluate Model (Ocena modelu) do kanwy potoku.
Połączenie danych wyjściowych Generowanie wyników składnika model po lewej stronie danych wejściowych funkcji Evaluate Model(Ocena modelu).
Końcowy potok powinien wyglądać mniej więcej tak:

Przesyłanie potoku
Wybierz pozycję Konfiguruj i prześlij w prawym górnym rogu, aby przesłać potok.

Następnie zobaczysz kreatora krok po kroku, postępuj zgodnie z instrukcjami kreatora, aby przesłać zadanie potoku.


W kroku Podstawy można skonfigurować eksperyment, nazwę wyświetlaną zadania, opis zadania itp.
W kroku Dane wejściowe i wyjściowe można przypisać wartość do poziomów danych wejściowych/wyjściowych . W tym przykładzie będzie on pusty, ponieważ nie podwyższyliśmy poziomu danych wejściowych/wyjściowych do poziomu potoku.
W obszarze Ustawienia środowiska uruchomieniowego można skonfigurować domyślny magazyn danych i domyślne zasoby obliczeniowe do potoku. Jest to domyślny magazyn danych/obliczenia dla wszystkich składników potoku. Jeśli jednak jawnie ustawisz inne zasoby obliczeniowe lub magazyn danych dla składnika, system uwzględnia ustawienie poziomu składnika. W przeciwnym razie używa wartości domyślnej.
Krok Przeglądanie i przesyłanie to ostatni krok umożliwiający przejrzenie wszystkich ustawień przed przesłaniem. Kreator zapamięta ostatnią konfigurację, jeśli kiedykolwiek prześlesz potok.
Po przesłaniu zadania potoku w górnej części zostanie wyświetlony komunikat z linkiem do szczegółów zadania. Możesz wybrać ten link, aby przejrzeć szczegóły zadania.

Wyświetlanie ocenianych etykiet
Na stronie szczegółów zadania możesz sprawdzić stan zadania potoku, wyniki i dzienniki.
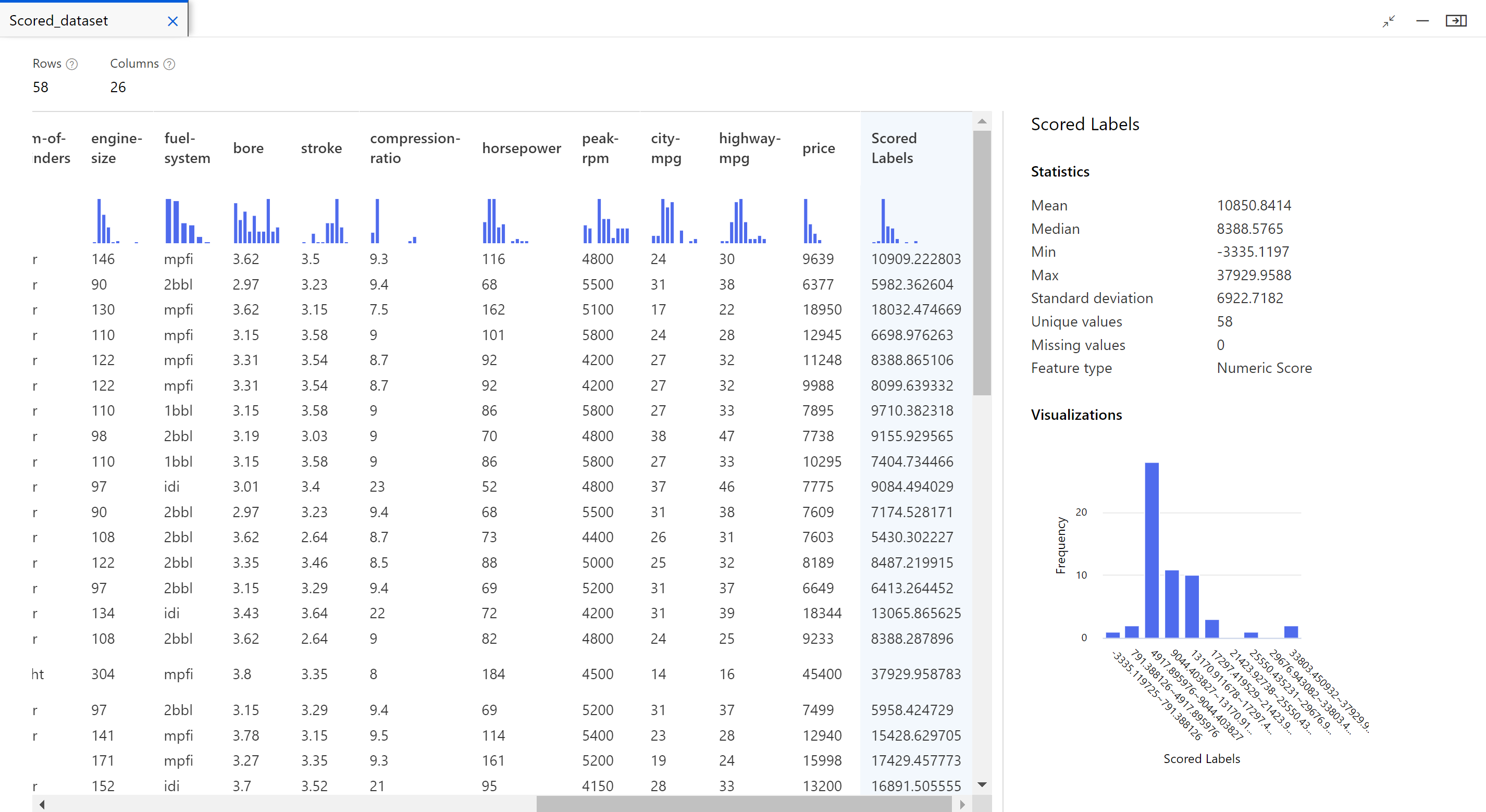
Po zakończeniu zadania można wyświetlić wyniki zadania potoku. Najpierw przyjrzyj się przewidywaniom wygenerowanymi przez model regresji.
Kliknij prawym przyciskiem myszy składnik Score Model (Generowanie wyników dla modelu), a następnie wybierz pozycję Preview data Scored dataset (Podgląd danych>scored dataset), aby wyświetlić jego dane wyjściowe.
W tym miejscu można zobaczyć przewidywane ceny i rzeczywiste ceny z danych testowych.
Ocena modeli
Użyj modelu Evaluate Model (Ocena modelu), aby zobaczyć, jak dobrze wytrenowany model został wykonany na zestawie danych testowych.
- Kliknij prawym przyciskiem myszy składnik Evaluate Model (Ocena modelu) i wybierz pozycję Preview data Evaluation results (Podgląd wyników oceny danych>), aby wyświetlić jego dane wyjściowe.
Dla modelu są wyświetlane następujące statystyki:
- Średni błąd bezwzględny (MAE): średnia błędów bezwzględnych. Błąd to różnica między przewidywaną wartością a rzeczywistą wartością.
- Pierwiastek błędu średniokwadratowego (RMSE, Root Mean Squared Error): pierwiastek kwadratowy ze średniej kwadratów błędów prognoz dla zestawu danych testowych.
- Względny błąd absolutny: iloraz średniej błędów absolutnych i bezwzględnej wartości różnicy między wartościami rzeczywistymi a średnią wszystkich wartości rzeczywistych.
- Błąd względny średniokwadratowy: iloraz średniej kwadratów błędów i kwadratu różnicy między wartościami rzeczywistymi a średnią wszystkich wartości rzeczywistych.
- Współczynnik determinacji: znany również jako wartość kwadratowa języka R, ta metryka statystyczna wskazuje, jak dobrze model pasuje do danych.
W przypadku wszystkich powyższych statystyk mniejsze wartości oznaczają lepszą jakość modelu. Mniejsza wartość wskazuje, że przewidywania są bliżej rzeczywistych wartości. Dla współczynnika determinacji im bliżej jest jedna (1,0), tym lepiej przewidywanie.
Czyszczenie zasobów
Pomiń tę sekcję, jeśli chcesz kontynuować z częścią 2 samouczka, wdrażanie modeli.
Ważne
Możesz użyć zasobów utworzonych jako wymagania wstępne dla innych samouczków usługi Azure Machine Edukacja i artykułów z instrukcjami.
Usuń wszystko
Jeśli nie planujesz używać utworzonych elementów, usuń całą grupę zasobów, aby nie ponosić żadnych opłat.
W witrynie Azure Portal wybierz pozycję Grupy zasobów po lewej stronie okna.
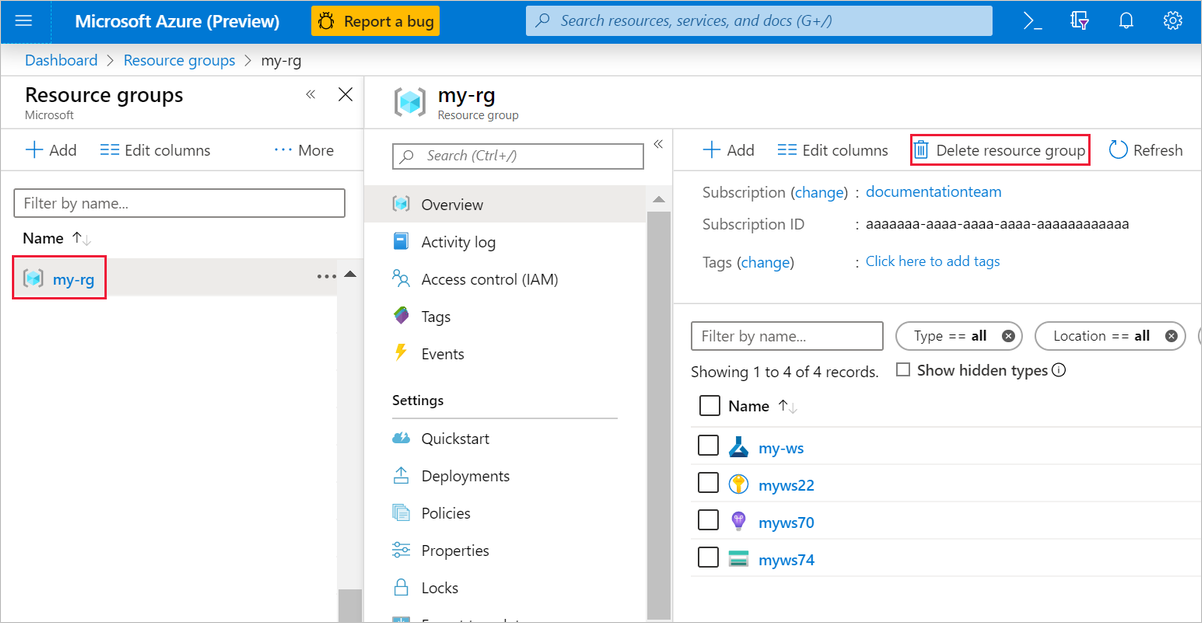
Na liście wybierz utworzoną grupę zasobów.
Wybierz pozycję Usuń grupę zasobów.
Usunięcie grupy zasobów powoduje również usunięcie wszystkich zasobów utworzonych w projektancie.
Usuwanie pojedynczych zasobów
W projektancie, w którym utworzono eksperyment, usuń poszczególne zasoby, wybierając je, a następnie wybierając przycisk Usuń .
Docelowy obiekt obliczeniowy utworzony w tym miejscu automatycznie skaluje się do zera węzłów, gdy nie jest używany. Ta akcja jest podejmowana w celu zminimalizowania opłat. Jeśli chcesz usunąć docelowy obiekt obliczeniowy, wykonaj następujące kroki:
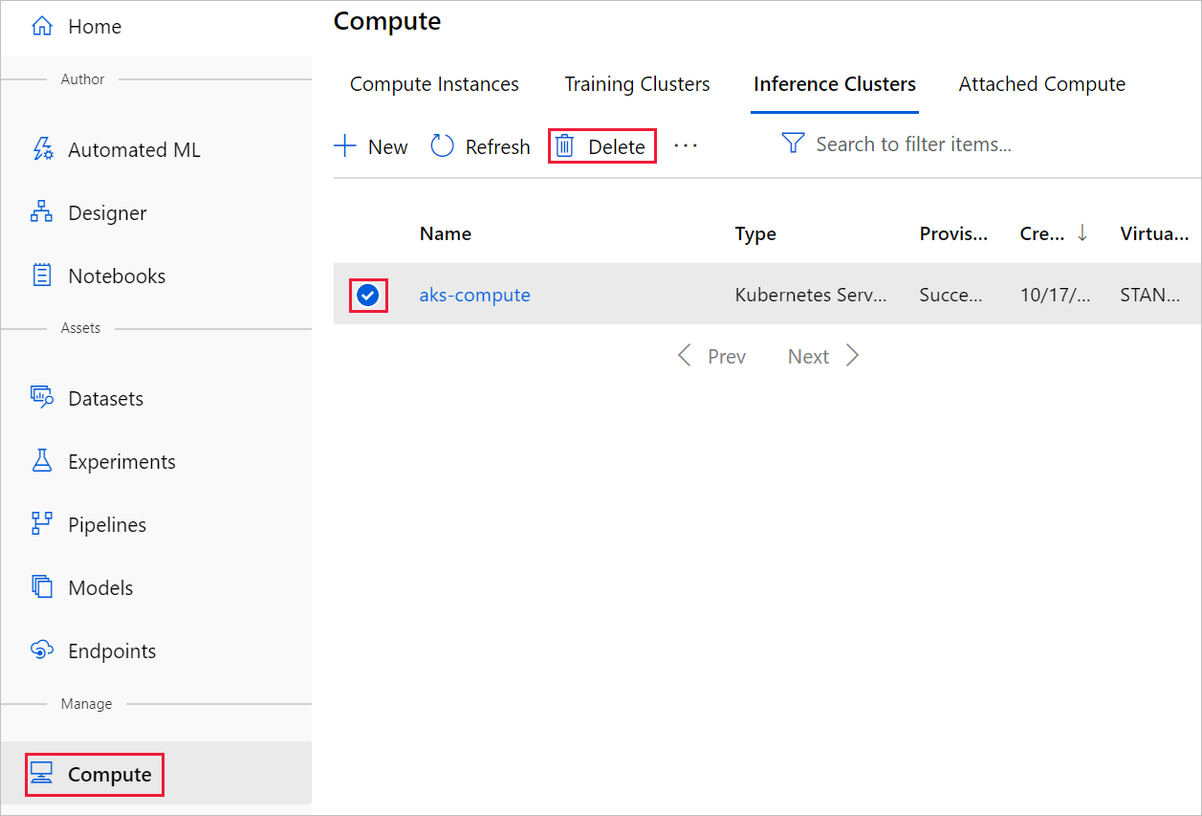
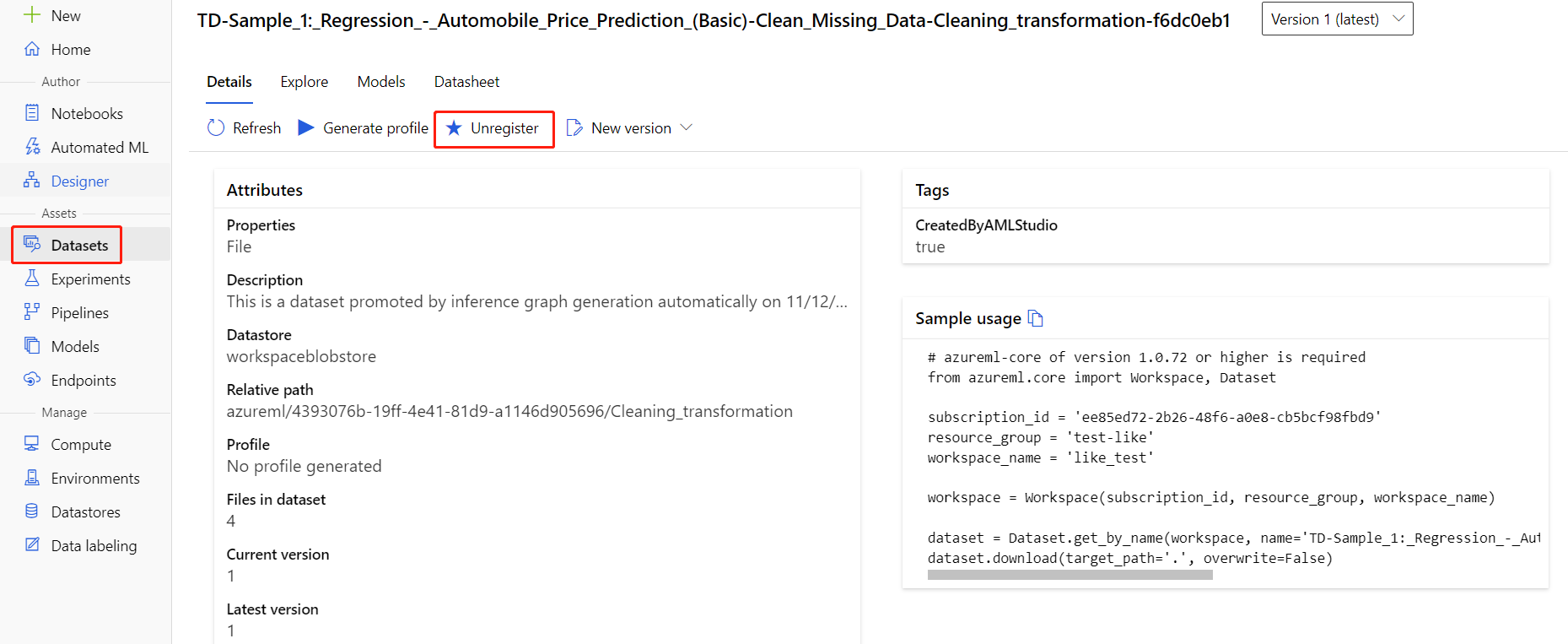
Zestawy danych można wyrejestrować z obszaru roboczego, wybierając każdy zestaw danych i wybierając pozycję Wyrejestruj.
Aby usunąć zestaw danych, przejdź do konta magazynu przy użyciu witryny Azure Portal lub Eksplorator usługi Azure Storage i ręcznie usuń te zasoby.
Następne kroki
W drugiej części dowiesz się, jak wdrożyć model jako punkt końcowy w czasie rzeczywistym.