Samouczek: przekazywanie i uzyskiwanie dostępu do danych w usłudze Azure Machine Edukacja
DOTYCZY: Zestaw PYTHON SDK azure-ai-ml w wersji 2 (bieżąca)
Zestaw PYTHON SDK azure-ai-ml w wersji 2 (bieżąca)
Ten samouczek zawiera informacje na temat wykonywania następujących czynności:
- Przekazywanie danych do magazynu w chmurze
- Tworzenie zasobu danych usługi Azure Machine Edukacja
- Uzyskiwanie dostępu do danych w notesie na potrzeby interaktywnego programowania
- Tworzenie nowych wersji zasobów danych
Rozpoczęcie projektu uczenia maszynowego zwykle obejmuje eksploracyjne analizy danych (EDA), przetwarzanie danych (czyszczenie, inżynieria cech) oraz tworzenie prototypów modeli Edukacja maszynowych w celu weryfikacji hipotez. Ta faza tworzenia prototypów projektu jest wysoce interaktywna. Nadaje się do programowania w środowisku IDE lub notesie Jupyter z interaktywną konsolą języka Python. W tym samouczku opisano te pomysły.
W tym filmie wideo pokazano, jak rozpocząć pracę w usłudze Azure Machine Edukacja Studio, aby można było wykonać kroki opisane w samouczku. W filmie wideo pokazano, jak utworzyć notes, sklonować notes, utworzyć wystąpienie obliczeniowe i pobrać dane potrzebne do tego samouczka. Kroki zostały również opisane w poniższych sekcjach.
Wymagania wstępne
-
Aby korzystać z usługi Azure Machine Edukacja, najpierw potrzebujesz obszaru roboczego. Jeśli go nie masz, ukończ tworzenie zasobów, aby rozpocząć tworzenie obszaru roboczego i dowiedz się więcej na temat korzystania z niego.
-
Zaloguj się do programu Studio i wybierz swój obszar roboczy, jeśli jeszcze nie jest otwarty.
-
Otwórz lub utwórz notes w obszarze roboczym:
- Utwórz nowy notes, jeśli chcesz skopiować/wkleić kod do komórek.
- Możesz też otworzyć plik tutorials/get-started-notebooks/explore-data.ipynb z sekcji Przykłady w programie Studio. Następnie wybierz pozycję Klonuj, aby dodać notes do plików. (Zobacz, gdzie znaleźć przykłady).
Ustawianie jądra
Na górnym pasku powyżej otwartego notesu utwórz wystąpienie obliczeniowe, jeśli jeszcze go nie masz.

Jeśli wystąpienie obliczeniowe zostanie zatrzymane, wybierz pozycję Uruchom środowisko obliczeniowe i poczekaj na jego uruchomienie.

Upewnij się, że jądro znajdujące się w prawym górnym rogu ma wartość
Python 3.10 - SDK v2. Jeśli nie, użyj listy rozwijanej, aby wybrać to jądro.
Jeśli zostanie wyświetlony baner z informacją o konieczności uwierzytelnienia, wybierz pozycję Uwierzytelnij.



Ważne
W pozostałej części tego samouczka znajdują się komórki notesu samouczka. Skopiuj je/wklej do nowego notesu lub przełącz się teraz do notesu, jeśli go sklonujesz.
Pobieranie danych używanych w tym samouczku
W przypadku pozyskiwania danych usługa Azure Data Explorer obsługuje nieprzetworzone dane w tych formatach. W tym samouczku użyto tego przykładu danych klienta karty kredytowej w formacie CSV. Zobaczymy kroki wykonywane w zasobie usługi Azure Machine Edukacja. W tym zasobie utworzymy folder lokalny z sugerowaną nazwą danych bezpośrednio w folderze, w którym znajduje się ten notes.
Uwaga
Ten samouczek zależy od danych umieszczonych w lokalizacji folderu zasobów usługi Azure Machine Edukacja. W tym samouczku "local" oznacza lokalizację folderu w tym zasobie usługi Azure Machine Edukacja.
Wybierz pozycję Otwórz terminal poniżej trzech kropek, jak pokazano na poniższej ilustracji:
Zostanie otwarte okno terminalu na nowej karcie.
Upewnij się, że znajduje
cdsię ten sam folder, w którym znajduje się ten notes. Jeśli na przykład notes znajduje się w folderze o nazwie get-started-notebooks:cd get-started-notebooks # modify this to the path where your notebook is locatedWprowadź następujące polecenia w oknie terminalu, aby skopiować dane do wystąpienia obliczeniowego:
mkdir data cd data # the sub-folder where you'll store the data wget https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csvTeraz możesz zamknąć okno terminalu.
Dowiedz się więcej o tych danych w repozytorium Edukacja UCI Machine.
Tworzenie dojścia do obszaru roboczego
Zanim przejdziemy do kodu, musisz odwołać się do obszaru roboczego. Utworzysz ml_client dojście do obszaru roboczego. Następnie użyjesz narzędzia ml_client do zarządzania zasobami i zadaniami.
W następnej komórce wprowadź identyfikator subskrypcji, nazwę grupy zasobów i nazwę obszaru roboczego. Aby znaleźć następujące wartości:
- W prawym górnym rogu paska narzędzi Azure Machine Edukacja Studio wybierz nazwę obszaru roboczego.
- Skopiuj wartość obszaru roboczego, grupy zasobów i identyfikatora subskrypcji do kodu.
- Musisz skopiować jedną wartość, zamknąć obszar i wkleić, a następnie wrócić do następnego.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Uwaga
Utworzenie klasy MLClient nie spowoduje nawiązania połączenia z obszarem roboczym. Inicjowanie klienta jest leniwe, będzie czekać po raz pierwszy, aby wykonać wywołanie (nastąpi to w następnej komórce kodu).
Przekazywanie danych do magazynu w chmurze
Usługa Azure Machine Edukacja używa identyfikatorów URI (Uniform Resource Identifiers), które wskazują lokalizacje magazynu w chmurze. Identyfikator URI ułatwia dostęp do danych w notesach i zadaniach. Formaty identyfikatorów URI danych wyglądają podobnie do adresów URL sieci Web używanych w przeglądarce internetowej w celu uzyskiwania dostępu do stron internetowych. Na przykład:
- Uzyskiwanie dostępu do danych z publicznego serwera https:
https://<account_name>.blob.core.windows.net/<container_name>/<folder>/<file> - Uzyskiwanie dostępu do danych z usługi Azure Data Lake Gen 2:
abfss://<file_system>@<account_name>.dfs.core.windows.net/<folder>/<file>
Zasób danych usługi Azure Machine Edukacja jest podobny do zakładek przeglądarki internetowej (ulubionych). Zamiast pamiętać długie ścieżki magazynu (URI), które wskazują najczęściej używane dane, można utworzyć zasób danych, a następnie uzyskać dostęp do tego zasobu za pomocą przyjaznej nazwy.
Tworzenie zasobu danych tworzy również odwołanie do lokalizacji źródła danych wraz z kopią metadanych. Ponieważ dane pozostają w istniejącej lokalizacji, nie ponosisz dodatkowych kosztów magazynowania i nie ryzykujesz integralności źródła danych. Zasoby danych można tworzyć na podstawie usługi Azure Machine Edukacja magazynów danych, usługi Azure Storage, publicznych adresów URL i plików lokalnych.
Napiwek
W przypadku przekazywania danych o mniejszym rozmiarze usługa Azure Machine Edukacja tworzenie zasobów danych działa dobrze w przypadku przekazywania danych z zasobów komputera lokalnego do magazynu w chmurze. Takie podejście pozwala uniknąć konieczności korzystania z dodatkowych narzędzi lub narzędzi. Jednak przekazywanie danych o większym rozmiarze może wymagać dedykowanego narzędzia lub narzędzia — na przykład azcopy. Narzędzie wiersza polecenia azcopy przenosi dane do i z usługi Azure Storage. Dowiedz się więcej o narzędziu azcopy tutaj.
Następna komórka notesu tworzy zasób danych. Przykładowy kod przekazuje nieprzetworzone pliki danych do wyznaczonego zasobu magazynu w chmurze.
Za każdym razem, gdy tworzysz zasób danych, potrzebna jest unikatowa wersja. Jeśli wersja już istnieje, zostanie wyświetlony błąd. W tym kodzie używamy "początkowego" dla pierwszego odczytu danych. Jeśli ta wersja już istnieje, pominiemy tworzenie jej ponownie.
Można również pominąć parametr wersji , a numer wersji jest generowany dla Ciebie, począwszy od 1, a następnie zwiększa się z tego miejsca.
W tym samouczku użyjemy nazwy "initial" jako pierwszej wersji. Samouczek Tworzenie potoków uczenia maszynowego w środowisku produkcyjnym będzie również używać tej wersji danych, więc w tym miejscu użyjemy wartości, którą zobaczysz ponownie w tym samouczku.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# update the 'my_path' variable to match the location of where you downloaded the data on your
# local filesystem
my_path = "./data/default_of_credit_card_clients.csv"
# set the version number of the data asset
v1 = "initial"
my_data = Data(
name="credit-card",
version=v1,
description="Credit card data",
path=my_path,
type=AssetTypes.URI_FILE,
)
## create data asset if it doesn't already exist:
try:
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(
f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}"
)
except:
ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Przekazane dane można wyświetlić, wybierając pozycję Dane po lewej stronie. Zobaczysz, że dane zostaną przekazane i zostanie utworzony zasób danych:
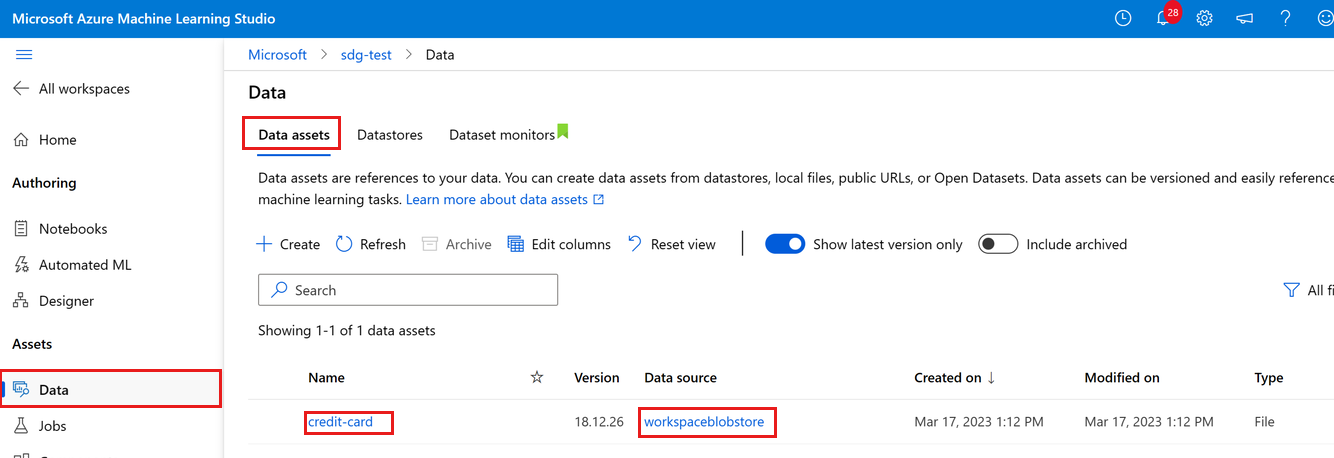
Te dane mają nazwę karta kredytowa, a na karcie Zasoby danych możemy je zobaczyć w kolumnie Nazwa . Te dane przekazane do domyślnego magazynu danych obszaru roboczego o nazwie workspaceblobstore widoczne w kolumnie Źródło danych.
Magazyn danych usługi Azure Machine Edukacja to odwołanie do istniejącego konta magazynu na platformie Azure. Magazyn danych oferuje następujące korzyści:
- Typowy i łatwy w użyciu interfejs API do interakcji z różnymi typami magazynu (Blob/Files/Azure Data Lake Storage) i metodami uwierzytelniania.
- Łatwiejszy sposób odnajdywania przydatnych magazynów danych podczas pracy jako zespół.
- W skryptach sposób ukrywania informacji o połączeniu na potrzeby dostępu do danych opartych na poświadczeniach (jednostka usługi/sygnatura dostępu współdzielonego/klucz).
Uzyskiwanie dostępu do danych w notesie
Biblioteka Pandas bezpośrednio obsługuje identyfikatory URI — w tym przykładzie pokazano, jak odczytać plik CSV z usługi Azure Machine Edukacja Datastore:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Jednak, jak wspomniano wcześniej, trudno jest zapamiętać te identyfikatory URI. Ponadto należy ręcznie zastąpić wszystkie <wartości podciągów> w poleceniu pd.read_csv rzeczywistymi wartościami zasobów.
Chcesz utworzyć zasoby danych dla często używanych danych. Oto łatwiejszy sposób uzyskiwania dostępu do pliku CSV w bibliotece Pandas:
Ważne
W komórce notesu wykonaj ten kod, aby zainstalować bibliotekę azureml-fsspec języka Python w jądrze Jupyter:
%pip install -U azureml-fsspec
import pandas as pd
# get a handle of the data asset and print the URI
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(f"Data asset URI: {data_asset.path}")
# read into pandas - note that you will see 2 headers in your data frame - that is ok, for now
df = pd.read_csv(data_asset.path)
df.head()
Przeczytaj artykuł Access data from Azure Cloud Storage during interactive development (Dostęp do danych z magazynu w chmurze platformy Azure podczas programowania interaktywnego), aby dowiedzieć się więcej o dostępie do danych w notesie.
Tworzenie nowej wersji zasobu danych
Być może zauważysz, że dane wymagają nieco lekkiego czyszczenia, aby dopasować je do trenowania modelu uczenia maszynowego. Ma:
- dwa nagłówki
- kolumna identyfikatora klienta; Nie będziemy używać tej funkcji w usłudze Machine Edukacja
- spacje w nazwie zmiennej odpowiedzi
Ponadto w porównaniu z formatem CSV format pliku Parquet staje się lepszym sposobem przechowywania tych danych. Parquet oferuje kompresję i utrzymuje schemat. W związku z tym, aby wyczyścić dane i zapisać je w Parquet, użyj:
# read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# remove ID column
df.drop("ID", axis=1, inplace=True)
# write file to filesystem
df.to_parquet("./data/cleaned-credit-card.parquet")
W tej tabeli przedstawiono strukturę danych w oryginalnym pliku default_of_credit_card_clients.csv . Plik CSV pobrany we wcześniejszym kroku. Przekazane dane zawierają 23 zmienne objaśniające i 1 zmienną odpowiedzi, jak pokazano poniżej:
| Nazwy kolumn | Typ zmiennej | opis |
|---|---|---|
| X1 | Wyjaśniające | Kwota danego kredytu (dolar NT): obejmuje zarówno kredyt konsumencki indywidualny, jak i kredyt rodzinny (dodatkowy). |
| X2 | Wyjaśniające | Płeć (1 = mężczyzna; 2 = kobieta). |
| X3 | Wyjaśniające | Edukacja (1 = szkoła absolwentów; 2 = uniwersytet; 3 = liceum; 4 = inne). |
| X4 | Wyjaśniające | Stan małżeński (1 = żonaty; 2 = samotny; 3 = inne). |
| X5 | Wyjaśniające | Wiek (lata). |
| X6-X11 | Wyjaśniające | Historia przeszłych płatności. Prześledziliśmy ostatnie miesięczne rekordy płatności (od kwietnia do września 2005 r.). -1 = wynagrodzenie należycie; 1 = opóźnienie płatności za jeden miesiąc; 2 = opóźnienie płatności za dwa miesiące; . . .; 8 = opóźnienie płatności przez osiem miesięcy; 9 = opóźnienie płatności przez dziewięć miesięcy i powyżej. |
| X12-17 | Wyjaśniające | Kwota zestawienia rachunku (dolar NT) od kwietnia do września 2005 r. |
| X18-23 | Wyjaśniające | Kwota poprzedniej płatności (dolar NT) od kwietnia do września 2005 r. |
| Y | Response | Płatność domyślna (Tak = 1, Nie = 0) |
Następnie utwórz nową wersję zasobu danych (dane są automatycznie przekazywane do magazynu w chmurze). W tej wersji dodamy wartość czasu, aby za każdym razem, gdy ten kod jest uruchamiany, zostanie utworzony inny numer wersji.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time
# Next, create a new *version* of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./data/cleaned-credit-card.parquet"
# Define the data asset, and use tags to make it clear the asset can be used in training
my_data = Data(
name="credit-card",
version=v2,
description="Default of credit card clients data.",
tags={"training_data": "true", "format": "parquet"},
path=my_path,
type=AssetTypes.URI_FILE,
)
## create the data asset
my_data = ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Oczyszczony plik parquet jest najnowszym źródłem danych wersji. Ten kod przedstawia najpierw zestaw wyników wersji CSV, a następnie wersję Parquet:
import pandas as pd
# get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version=v1)
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)
# print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))
# print the v2 data
print(
"_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))
Czyszczenie zasobów
Jeśli planujesz kontynuować korzystanie z innych samouczków, przejdź do sekcji Następne kroki.
Zatrzymywanie wystąpienia obliczeniowego
Jeśli nie zamierzasz go teraz używać, zatrzymaj wystąpienie obliczeniowe:
- W programie Studio w obszarze nawigacji po lewej stronie wybierz pozycję Obliczenia.
- Na pierwszych kartach wybierz pozycję Wystąpienia obliczeniowe
- Wybierz wystąpienie obliczeniowe na liście.
- Na górnym pasku narzędzi wybierz pozycję Zatrzymaj.
Usuwanie wszystkich zasobów
Ważne
Utworzone zasoby mogą być używane jako wymagania wstępne w innych samouczkach usługi Azure Machine Edukacja i artykułach z instrukcjami.
Jeśli nie planujesz korzystać z żadnych utworzonych zasobów, usuń je, aby nie ponosić żadnych opłat:
W witrynie Azure Portal na końcu z lewej strony wybierz pozycję Grupy zasobów.
Z listy wybierz utworzoną grupę zasobów.
Wybierz pozycję Usuń grupę zasobów.
Wpisz nazwę grupy zasobów. Następnie wybierz Usuń.
Następne kroki
Aby uzyskać więcej informacji na temat zasobów danych, przeczytaj artykuł Create data assets (Tworzenie zasobów danych).
Przeczytaj artykuł Create datastores (Tworzenie magazynów danych), aby dowiedzieć się więcej o magazynach danych.
Kontynuuj pracę z samouczkami, aby dowiedzieć się, jak opracować skrypt szkoleniowy.