Samouczek: trenowanie i wdrażanie modelu klasyfikacji obrazów za pomocą przykładowego notesu Jupyter Notebook
DOTYCZY: Zestaw SDK języka Python azureml w wersji 1
Zestaw SDK języka Python azureml w wersji 1
W tym samouczku przeprowadzisz szkolenie modelu uczenia maszynowego na zdalnych zasobach obliczeniowych. Używasz przepływu pracy trenowania i wdrażania dla usługi Azure Machine Edukacja w notesie Jupyter w języku Python. Następnie możesz użyć notesu jako szablonu do uczenia własnego modelu uczenia maszynowego z użyciem własnych danych.
Ten samouczek szkoli prostą regresję logistyczną przy użyciu zestawu danych MNIST i biblioteki scikit-learn z usługą Azure Machine Edukacja. MNIST jest popularnym zestawem danych składającym się z 70 000 obrazów w skali szarości. Każdy obraz ma rozmiar 28 x 28 pikseli i przedstawia odręcznie napisaną cyfrę z zakresu od 0 do 9. Celem jest utworzenie klasyfikatora wieloklasowego do identyfikacji cyfry reprezentowanej przez dany obraz.
Dowiedz się, jak wykonać następujące czynności:
- Pobierz zestaw danych i przyjrzyj się danym.
- Trenowanie modelu klasyfikacji obrazów i metryk dzienników przy użyciu biblioteki MLflow.
- Wdróż model, aby wykonywać wnioskowanie w czasie rzeczywistym.
Wymagania wstępne
- Ukończ przewodnik Szybki start: rozpoczynanie pracy z usługą Azure Machine Edukacja w celu wykonania następujących czynności:
- Utwórz obszar roboczy.
- Utwórz wystąpienie obliczeniowe oparte na chmurze do użycia w środowisku deweloperów.
Uruchamianie notesu z obszaru roboczego
Usługa Azure Machine Edukacja zawiera serwer notesów w chmurze w obszarze roboczym na potrzeby środowiska bez instalacji i wstępnie skonfigurowanego. Użyj własnego środowiska , jeśli wolisz mieć kontrolę nad środowiskiem, pakietami i zależnościami.
Klonowanie folderu notesu
Wykonaj następujące kroki konfiguracji i uruchamiania eksperymentu w usłudze Azure Machine Edukacja Studio. Ten skonsolidowany interfejs obejmuje narzędzia uczenia maszynowego do wykonywania scenariuszy nauki o danych dla praktyków nauki o danych na wszystkich poziomach umiejętności.
Zaloguj się do usługi Azure Machine Edukacja Studio.
Wybierz subskrypcję i utworzony obszar roboczy.
Po lewej stronie wybierz pozycję Notesy.
U góry wybierz kartę Przykłady .
Otwórz folder SDK w wersji 1.
Wybierz przycisk ... po prawej stronie folderu tutorials, a następnie wybierz pozycję Clone (Klonuj).
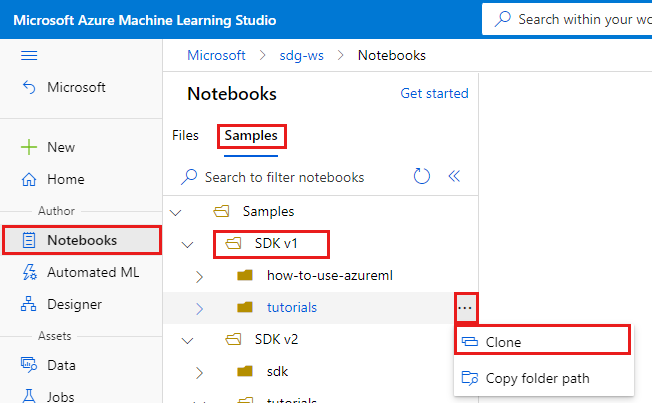
Lista folderów zawiera każdego użytkownika, który uzyskuje dostęp do obszaru roboczego. Wybierz folder, aby sklonować tam folder tutorials .
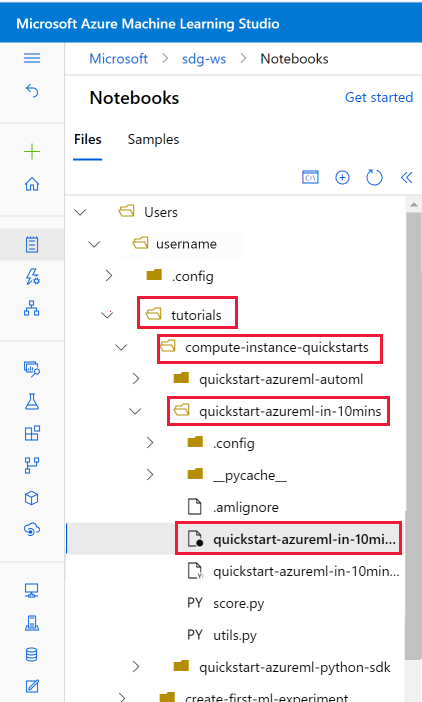
Otwieranie sklonowanego notesu
Otwórz folder tutorials, który został sklonowany do sekcji Pliki użytkownika.
Wybierz plik quickstart-azureml-in-10mins.ipynb z folderu tutorials/compute-instance-quickstarts/quickstart-azureml-in-10mins.
Instalowanie pakietów
Po uruchomieniu wystąpienia obliczeniowego i pojawieniu się jądra dodaj nową komórkę kodu, aby zainstalować pakiety wymagane w tym samouczku.
W górnej części notesu dodaj komórkę kodu.

Dodaj następujący kod do komórki, a następnie uruchom komórkę przy użyciu narzędzia Uruchom lub za pomocą klawiszy Shift+Enter.
%pip install scikit-learn==0.22.1 %pip install scipy==1.5.2
Może zostać wyświetlonych kilka ostrzeżeń dotyczących instalacji. Można je bezpiecznie zignorować.
Uruchamianie notesu
Ten samouczek i towarzyszący plik utils.py jest również dostępny w witrynie GitHub , jeśli chcesz go używać we własnym środowisku lokalnym. Jeśli nie używasz wystąpienia obliczeniowego, dodaj %pip install azureml-sdk[notebooks] azureml-opendatasets matplotlib go do powyższej instalacji.
Ważne
Pozostała część tego artykułu zawiera tę samą zawartość, co w notesie.
Przejdź do notesu Jupyter Notebook teraz, jeśli chcesz uruchomić kod podczas odczytywania. Aby uruchomić pojedynczą komórkę kodu w notesie, kliknij komórkę kodu i naciśnij klawisze Shift+Enter. Możesz też uruchomić cały notes, wybierając pozycję Uruchom wszystko na górnym pasku narzędzi.
Importuj dane
Przed wytreniem modelu musisz zrozumieć dane, których używasz do trenowania. W tej sekcji dowiesz się, jak wykonywać następujące działania:
- Pobieranie zestawu danych MNIST
- Wyświetlanie przykładowych obrazów
Aby uzyskać nieprzetworzone pliki danych MNIST, użyj usługi Azure Open Datasets. Zestawy danych Platformy Azure Open to wyselekcjonowane publiczne zestawy danych, których można użyć do dodawania funkcji specyficznych dla scenariuszy do rozwiązań uczenia maszynowego w celu uzyskania lepszych modeli. Każdy zestaw danych ma odpowiednią klasę, MNIST w tym przypadku, aby pobrać dane na różne sposoby.
import os
from azureml.opendatasets import MNIST
data_folder = os.path.join(os.getcwd(), "/tmp/qs_data")
os.makedirs(data_folder, exist_ok=True)
mnist_file_dataset = MNIST.get_file_dataset()
mnist_file_dataset.download(data_folder, overwrite=True)
Przyjrzyj się danym
Załaduj pliki skompresowane do tablic numpy. Następnie użyj matplotlib do wykreślenia 30 losowych obrazów z zestawu danych wraz z ich etykietami nad nimi.
Należy pamiętać, że ten krok wymaga load_data funkcji dołączonej utils.py do pliku. Ten plik znajduje się w tym samym folderze co ten notes. Funkcja load_data po prostu analizuje skompresowane pliki i przetwarza je w tablice numpy.
from utils import load_data
import matplotlib.pyplot as plt
import numpy as np
import glob
# note we also shrink the intensity values (X) from 0-255 to 0-1. This helps the model converge faster.
X_train = (
load_data(
glob.glob(
os.path.join(data_folder, "**/train-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
X_test = (
load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
y_train = load_data(
glob.glob(
os.path.join(data_folder, "**/train-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
y_test = load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
# now let's show some randomly chosen images from the traininng set.
count = 0
sample_size = 30
plt.figure(figsize=(16, 6))
for i in np.random.permutation(X_train.shape[0])[:sample_size]:
count = count + 1
plt.subplot(1, sample_size, count)
plt.axhline("")
plt.axvline("")
plt.text(x=10, y=-10, s=y_train[i], fontsize=18)
plt.imshow(X_train[i].reshape(28, 28), cmap=plt.cm.Greys)
plt.show()
Kod wyświetla losowy zestaw obrazów z ich etykietami, podobnie jak w następujący sposób:

Trenowanie metryk modelu i dzienników za pomocą biblioteki MLflow
Wytrenuj model przy użyciu następującego kodu. Ten kod używa automatycznego rejestrowania MLflow do śledzenia metryk i artefaktów modelu dziennika.
Do klasyfikowania danych będziesz używać klasyfikatora LogisticsRegression z platformy SciKit Learn.
Uwaga
Trenowanie modelu trwa około 2 minut.
# create the model
import mlflow
import numpy as np
from sklearn.linear_model import LogisticRegression
from azureml.core import Workspace
# connect to your workspace
ws = Workspace.from_config()
# create experiment and start logging to a new run in the experiment
experiment_name = "azure-ml-in10-mins-tutorial"
# set up MLflow to track the metrics
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.set_experiment(experiment_name)
mlflow.autolog()
# set up the Logistic regression model
reg = 0.5
clf = LogisticRegression(
C=1.0 / reg, solver="liblinear", multi_class="auto", random_state=42
)
# train the model
with mlflow.start_run() as run:
clf.fit(X_train, y_train)
Wyświetlanie eksperymentu
W menu po lewej stronie w usłudze Azure Machine Edukacja Studio wybierz pozycję Zadania, a następnie wybierz zadanie (azure-ml-in10-mins-tutorial). Zadanie to grupowanie wielu przebiegów z określonego skryptu lub fragmentu kodu. Wiele zadań można grupować razem jako eksperyment.
Informacje dotyczące przebiegu są przechowywane w ramach tego zadania. Jeśli nazwa nie istnieje podczas przesyłania zadania, jeśli wybierzesz przebieg, zobaczysz różne karty zawierające metryki, dzienniki, wyjaśnienia itp.
Kontrola wersji modeli za pomocą rejestru modeli
Rejestrację modelu można użyć do przechowywania i przechowywania wersji modeli w obszarze roboczym. Zarejestrowane modele są identyfikowane za pomocą nazwy i wersji. Za każdym razem, gdy rejestrujesz model o takiej samej nazwie, jaką ma już istniejący model, rejestr zwiększa wersję. Poniższy kod rejestruje i wersje wytrenowanego powyżej modelu. Po wykonaniu poniższej komórki kodu model zostanie wyświetlony w rejestrze, wybierając pozycję Modele w menu po lewej stronie w usłudze Azure Machine Edukacja Studio.
# register the model
model_uri = "runs:/{}/model".format(run.info.run_id)
model = mlflow.register_model(model_uri, "sklearn_mnist_model")
Wdrażanie modelu na potrzeby wnioskowania w czasie rzeczywistym
W tej sekcji dowiesz się, jak wdrożyć model, aby aplikacja mogła korzystać (wnioskować) z modelu za pośrednictwem interfejsu REST.
Tworzenie konfiguracji wdrożenia
Komórka kodu pobiera wyselekcjonowane środowisko, które określa wszystkie zależności wymagane do hostowania modelu (na przykład pakiety takie jak scikit-learn). Ponadto należy utworzyć konfigurację wdrożenia, która określa ilość zasobów obliczeniowych wymaganych do hostowania modelu. W tym przypadku obliczenia mają pamięć 1CPU i 1 GB.
# create environment for the deploy
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core.webservice import AciWebservice
# get a curated environment
env = Environment.get(
workspace=ws,
name="AzureML-sklearn-1.0"
)
env.inferencing_stack_version='latest'
# create deployment config i.e. compute resources
aciconfig = AciWebservice.deploy_configuration(
cpu_cores=1,
memory_gb=1,
tags={"data": "MNIST", "method": "sklearn"},
description="Predict MNIST with sklearn",
)
Wdrażanie modelu
Ta następna komórka kodu wdraża model w usłudze Azure Container Instance.
Uwaga
Ukończenie wdrożenia trwa około 3 minut. Ale może to być dłuższe, dopóki nie będzie dostępne do użytku, być może tak długo, jak 15 minut.**
%%time
import uuid
from azureml.core.model import InferenceConfig
from azureml.core.environment import Environment
from azureml.core.model import Model
# get the registered model
model = Model(ws, "sklearn_mnist_model")
# create an inference config i.e. the scoring script and environment
inference_config = InferenceConfig(entry_script="score.py", environment=env)
# deploy the service
service_name = "sklearn-mnist-svc-" + str(uuid.uuid4())[:4]
service = Model.deploy(
workspace=ws,
name=service_name,
models=[model],
inference_config=inference_config,
deployment_config=aciconfig,
)
service.wait_for_deployment(show_output=True)
Plik skryptu oceniania, do którego odwołuje się powyższy kod, można znaleźć w tym samym folderze co ten notes i ma dwie funkcje:
- Funkcja wykonywana
initraz po uruchomieniu usługi — w tej funkcji zwykle uzyskujesz model z rejestru i ustawiasz zmienne globalne - Funkcja
run(data)wykonywana za każdym razem, gdy do usługi jest wykonywane wywołanie. W tej funkcji zwykle formatujesz dane wejściowe, uruchamiasz przewidywanie i generujesz przewidywany wynik.
Wyświetlanie punktu końcowego
Po pomyślnym wdrożeniu modelu możesz wyświetlić punkt końcowy, przechodząc do menu Punkty końcowe w menu po lewej stronie w usłudze Azure Machine Edukacja Studio. Zobaczysz stan punktu końcowego (w dobrej kondycji/złej kondycji), dzienniki i użycie (jak aplikacje mogą korzystać z modelu).
Testowanie usługi modelu
Model można przetestować, wysyłając nieprzetworzone żądanie HTTP w celu przetestowania usługi internetowej.
# send raw HTTP request to test the web service.
import requests
# send a random row from the test set to score
random_index = np.random.randint(0, len(X_test) - 1)
input_data = '{"data": [' + str(list(X_test[random_index])) + "]}"
headers = {"Content-Type": "application/json"}
resp = requests.post(service.scoring_uri, input_data, headers=headers)
print("POST to url", service.scoring_uri)
print("label:", y_test[random_index])
print("prediction:", resp.text)
Czyszczenie zasobów
Jeśli nie zamierzasz nadal korzystać z tego modelu, usuń usługę Model przy użyciu:
# if you want to keep workspace and only delete endpoint (it will incur cost while running)
service.delete()
Jeśli chcesz dalej kontrolować koszty, zatrzymaj wystąpienie obliczeniowe, wybierając przycisk "Zatrzymaj obliczenia" obok listy rozwijanej Obliczenia . Następnie ponownie uruchom wystąpienie obliczeniowe przy następnym jej użyciu.
Usuń wszystko
Wykonaj następujące kroki, aby usunąć obszar roboczy usługi Azure Machine Edukacja i wszystkie zasoby obliczeniowe.
Ważne
Utworzone zasoby mogą być używane jako wymagania wstępne w innych samouczkach usługi Azure Machine Edukacja i artykułach z instrukcjami.
Jeśli nie planujesz korzystać z żadnych utworzonych zasobów, usuń je, aby nie ponosić żadnych opłat:
W witrynie Azure Portal na końcu z lewej strony wybierz pozycję Grupy zasobów.
Z listy wybierz utworzoną grupę zasobów.
Wybierz pozycję Usuń grupę zasobów.
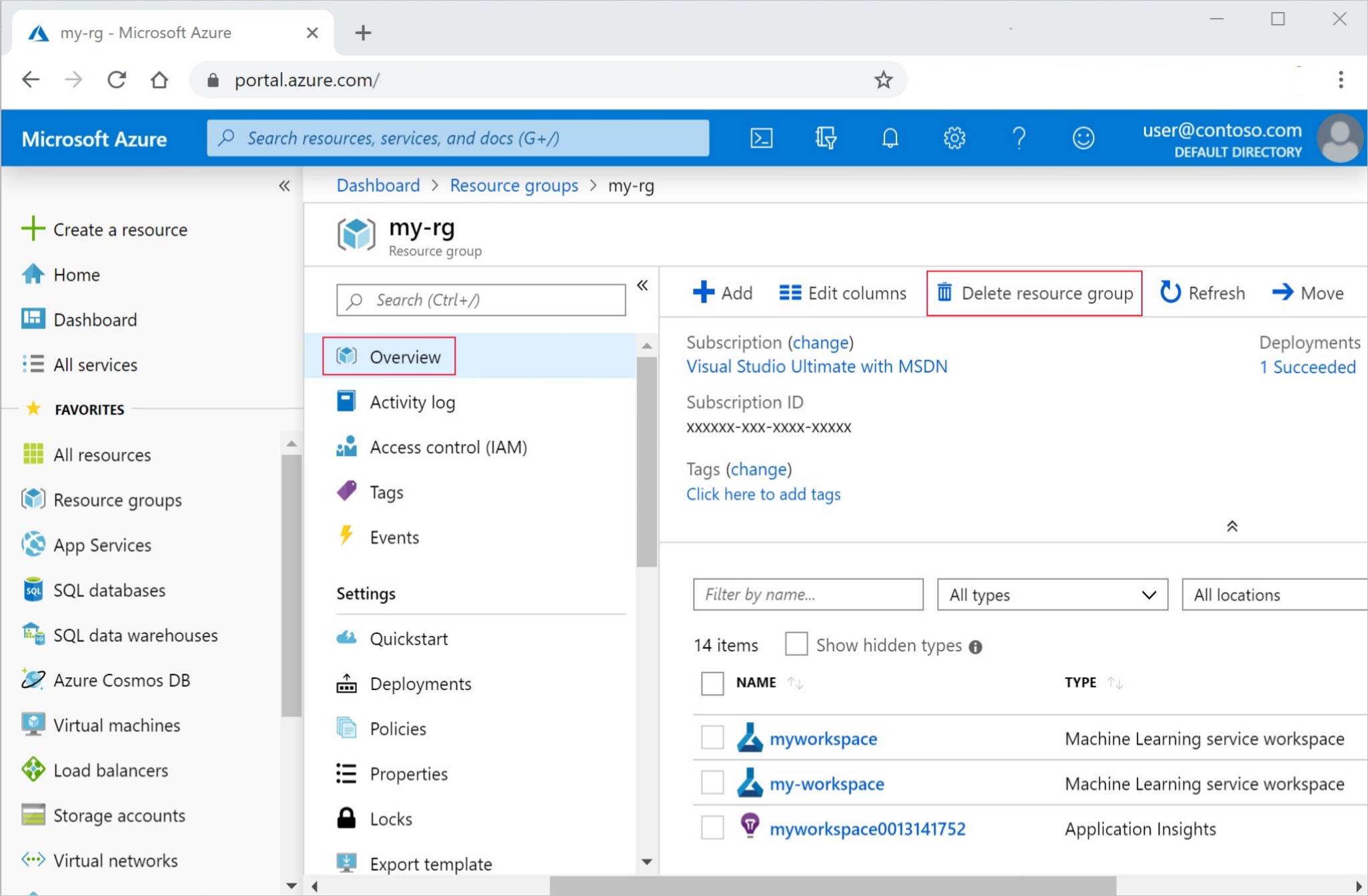
Wpisz nazwę grupy zasobów. Następnie wybierz Usuń.
Powiązane zasoby
- Dowiedz się więcej o wszystkich opcjach wdrażania usługi Azure Machine Edukacja.
- Dowiedz się, jak uwierzytelniać się w wdrożonym modelu.
- Asynchronicznie twórz prognozy dotyczące dużych ilości danych.
- Monitoruj swoje modele usługi Azure Machine Learning przy użyciu usługi Application Insights.