Testy porównawcze wydajności usługi Azure AI Search
Ważne
Te testy porównawcze dotyczą usług wyszukiwania utworzonych przed 3 kwietnia 2024 r. i mają zastosowanie tylko do obciążeń niewektorowych. Aktualizacje oczekują na usługi i obciążenia dotyczące nowych limitów.
Testy porównawcze wydajności są przydatne do szacowania potencjalnej wydajności w ramach podobnych konfiguracji. Rzeczywista wydajność zależy od różnych czynników, w tym rozmiaru usługi wyszukiwania i typów wysyłanych zapytań.
Aby ułatwić oszacowanie rozmiaru usługi wyszukiwania potrzebnej dla obciążenia, uruchomiliśmy kilka testów porównawczych, aby udokumentować wydajność różnych usług wyszukiwania i konfiguracji.
Aby uwzględnić szereg różnych przypadków użycia, uruchomiliśmy testy porównawcze dla dwóch głównych scenariuszy:
- Wyszukiwanie w handlu elektronicznym — ten test porównawczy emuluje rzeczywisty scenariusz handlu elektronicznego i opiera się na nordyckiej firmie zajmującej się handlem elektronicznym CDON.
- Wyszukiwanie dokumentów — ten scenariusz składa się z wyszukiwania słów kluczowych w dokumentach pełnotekstowych z semantic Scholar. To emuluje typowe rozwiązanie do wyszukiwania dokumentów.
Chociaż te scenariusze odzwierciedlają różne przypadki użycia, każdy scenariusz jest inny, dlatego zawsze zalecamy testowanie wydajności poszczególnych obciążeń. Opublikowaliśmy rozwiązanie do testowania wydajnościowego przy użyciu narzędzia JMeter , aby można było uruchamiać podobne testy względem własnej usługi.
Metodologia testowania
Aby porównać wydajność usługi Azure AI Search, przeprowadziliśmy testy dla dwóch różnych scenariuszy w różnych warstwach i kombinacjach replik/partycji.
Aby utworzyć te testy porównawcze, użyto następującej metodologii:
- Test rozpoczyna się od
Xzapytań na sekundę (QPS) przez 180 sekund. Zwykle było to 5 lub 10 QPS. - QPS następnie wzrosła o
Xi prowadził przez kolejne 180 sekund - Co 180 sekund test wzrósł o
XQPS, aż średnie opóźnienie wzrośnie powyżej 1000 ms lub mniej niż 99% zapytań powiodło się.
Poniższy wykres przedstawia wizualny przykład obciążenia zapytania testu:
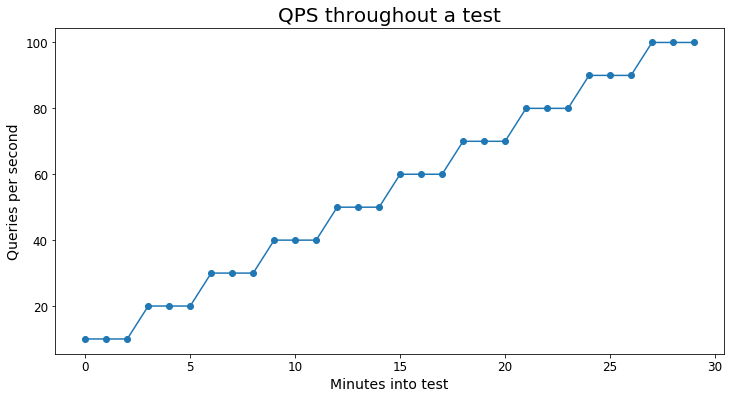
Każdy scenariusz używał co najmniej 10 000 unikatowych zapytań, aby uniknąć nadmiernego niesymetryczności testów przez buforowanie.
Ważne
Te testy obejmują tylko obciążenia zapytań. Jeśli spodziewasz się dużej liczby operacji indeksowania, pamiętaj, aby uwzględnić to w szacowaniu i testowaniu wydajnościowym. Przykładowy kod do symulowania indeksowania można znaleźć w tym samouczku.
Definicje
Maksymalna liczba QPS — maksymalna liczba QPS jest oparta na najwyższym poziomie QPS osiągniętym w teście, w którym 99% zapytań zostało ukończonych pomyślnie bez ograniczania przepustowości i średnie opóźnienie pozostał poniżej 1000 ms.
Procent maksymalnej liczby QPS — procent maksymalnej liczby QPS osiągniętych dla określonego testu. Na przykład jeśli dany test osiągnął maksymalnie 100 QPS, 20% maksymalnej liczby QPS będzie wynosić 20 QPS.
Opóźnienie — opóźnienie serwera dla zapytania; te liczby nie obejmują opóźnienia podróży okrężnej (RTT). Wartości są w milisekundach (ms).
Testowanie zastrzeżenia
Kod używany do uruchamiania tych testów porównawczych jest dostępny w repozytorium azure-search-performance-testing . Warto zauważyć, że zaobserwowaliśmy nieco niższe poziomy QPS z rozwiązaniem do testowania wydajności JMeter niż w testach porównawczych. Różnice mogą być przypisywane różnicom w stylu testów. Mówi to o znaczeniu, aby testy wydajnościowe przypominały obciążenie produkcyjne, jak to możliwe.
Ważne
Te testy porównawcze w żaden sposób nie gwarantują pewnego poziomu wydajności usługi, ale mogą dać ci wyobrażenie o wydajności, której można oczekiwać na podstawie danego scenariusza.
Jeśli masz jakiekolwiek pytania lub wątpliwości, skontaktuj się z nami pod adresem azuresearch_contact@microsoft.com.
Test porównawczy 1: wyszukiwanie w handlu elektronicznym
![]()
Ten punkt odniesienia został utworzony we współpracy z firmą zajmującą się handlem elektronicznym, CDON, największym rynkiem online w regionie Nordyckim z operacjami w Szwecji, Finlandii, Norwegii i Danii. Dzięki 1500 kupcom CDON oferuje szeroki asortyment, który obejmuje ponad 8 milionów produktów. W 2020 roku CDON miał ponad 120 milionów odwiedzających i 2 miliony aktywnych klientów. Więcej informacji na temat korzystania z usługi Azure AI Search w witrynie CDON można znaleźć w tym artykule.
Aby uruchomić te testy, użyliśmy migawki indeksu wyszukiwania produkcyjnego CDON i tysięcy unikatowych zapytań z ich witryny internetowej.
Szczegóły scenariusza
- Liczba dokumentów: 6000 000
- Rozmiar indeksu: 20 GB
- Schemat indeksu: indeks szeroki z 250 polami łącznie, 25 polami z możliwością wyszukiwania i 200 polami z możliwością filtrowania/aspektów
- Typy zapytań: zapytania wyszukiwania pełnotekstowego, w tym aspekty, filtry, kolejność i profile oceniania
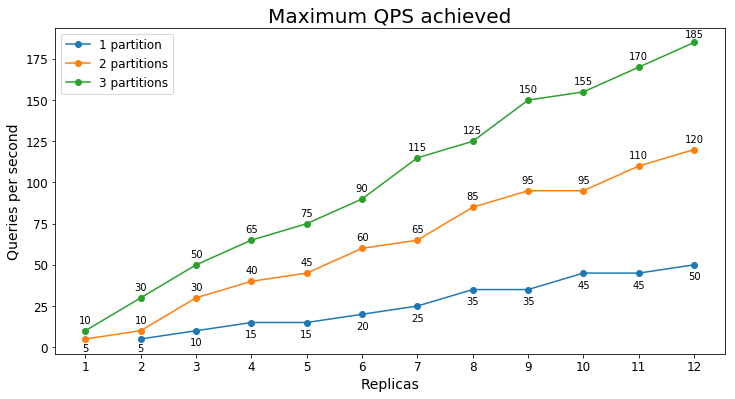
Wydajność S1
Zapytania na sekundę
Na poniższym wykresie przedstawiono najwyższe obciążenie zapytania, które usługa może obsłużyć przez dłuższy czas pod względem zapytań na sekundę (QPS).
Opóźnienie zapytań
Opóźnienie zapytań różni się w zależności od obciążenia usługi i usług pod wyższym obciążeniem, które ma większe średnie opóźnienie zapytań. W poniższej tabeli przedstawiono 25, 50, 75, 90, 95 i 99. percentyle opóźnienia zapytań dla trzech różnych poziomów użycia.
| Procent maksymalnej liczby QPS | Średnie opóźnienie | 25% | 75% | 90% | 95% | 99% |
|---|---|---|---|---|---|---|
| 20% | 104 ms | 35 ms | 115 ms | 177 ms | 257 ms | 738 ms |
| 50% | 140 ms | 47 ms | 144 ms | 241 ms | 400 ms | 1175 ms |
| 80% | 239 ms | 77 ms | 248 ms | 466 ms | 763 ms | 1752 ms |
Wydajność S2
Zapytania na sekundę
Na poniższym wykresie przedstawiono najwyższe obciążenie zapytania, które usługa może obsłużyć przez dłuższy czas pod względem zapytań na sekundę (QPS).

Opóźnienie zapytań
Opóźnienie zapytań różni się w zależności od obciążenia usługi i usług pod wyższym obciążeniem, które ma większe średnie opóźnienie zapytań. W poniższej tabeli przedstawiono 25, 50, 75, 90, 95 i 99. percentyle opóźnienia zapytań dla trzech różnych poziomów użycia.
| Procent maksymalnej liczby QPS | Średnie opóźnienie | 25% | 75% | 90% | 95% | 99% |
|---|---|---|---|---|---|---|
| 20% | 56 ms | 21 ms | 68 ms | 106 ms | 132 ms | 210 ms |
| 50% | 71 ms | 26 ms | 83 ms | 132 ms | 177 ms | 329 ms |
| 80% | 140 ms | 47 ms | 153 ms | 293 ms | 452 ms | 924 ms |
Wydajność S3
Zapytania na sekundę
Na poniższym wykresie przedstawiono najwyższe obciążenie zapytania, które usługa może obsłużyć przez dłuższy czas pod względem zapytań na sekundę (QPS).

W tym przypadku widzimy, że dodanie drugiej partycji znacznie zwiększa maksymalną liczbę QPS, ale dodanie trzeciej partycji zapewnia malejące marginalne zwroty. Mniejsza poprawa jest prawdopodobna, ponieważ wszystkie dane są już pobierane do aktywnej pamięci S3 z zaledwie dwiema partycjami.
Opóźnienie zapytań
Opóźnienie zapytań różni się w zależności od obciążenia usługi i usług pod wyższym obciążeniem, które ma większe średnie opóźnienie zapytań. W poniższej tabeli przedstawiono 25, 50, 75, 90, 95 i 99. percentyle opóźnienia zapytań dla trzech różnych poziomów użycia.
| Procent maksymalnej liczby QPS | Średnie opóźnienie | 25% | 75% | 90% | 95% | 99% |
|---|---|---|---|---|---|---|
| 20% | 50 ms | 20 ms | 64 ms | 83 ms | 98 ms | 160 ms |
| 50% | 62 ms | 24 ms | 80 ms | 107 ms | 130 ms | 253 ms |
| 80% | 115 ms | 38 ms | 121 ms | 218 ms | 352 ms | 828 ms |
Test porównawczy 2: wyszukiwanie dokumentów
Szczegóły scenariusza
- Liczba dokumentów: 7,5 mln
- Rozmiar indeksu: 22 GB
- Schemat indeksu: 23 pola; 8 z możliwością wyszukiwania, 10 filtrowalnych/aspektowych
- Typy zapytań: wyszukiwanie słów kluczowych z aspektami i wyróżnianie trafień
Wydajność S1
Zapytania na sekundę
Na poniższym wykresie przedstawiono najwyższe obciążenie zapytania, które usługa może obsłużyć przez dłuższy czas pod względem zapytań na sekundę (QPS).

Opóźnienie zapytań
Opóźnienie zapytań różni się w zależności od obciążenia usługi i usług pod wyższym obciążeniem, które ma większe średnie opóźnienie zapytań. W poniższej tabeli przedstawiono 25, 50, 75, 90, 95 i 99. percentyle opóźnienia zapytań dla trzech różnych poziomów użycia.
| Procent maksymalnej liczby QPS | Średnie opóźnienie | 25% | 75% | 90% | 95% | 99% |
|---|---|---|---|---|---|---|
| 20% | 67 ms | 44 ms | 77 ms | 103 ms | 126 ms | 216 ms |
| 50% | 93 ms | 59 ms | 110 ms | 150 ms | 184 ms | 304 ms |
| 80% | 150 ms | 96 ms | 184 ms | 248 ms | 297 ms | 424 ms |
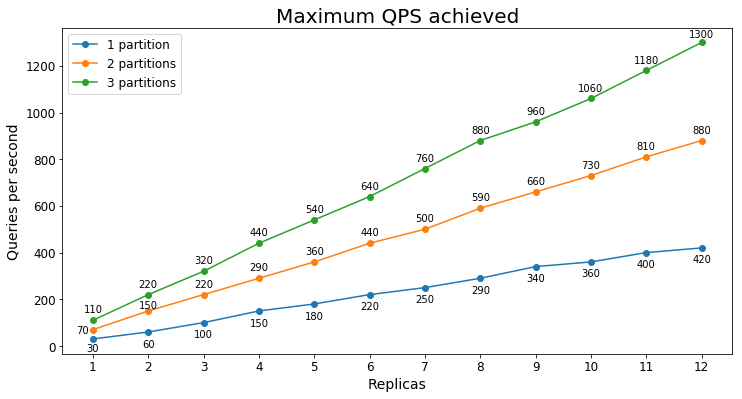
Wydajność S2
Zapytania na sekundę
Na poniższym wykresie przedstawiono najwyższe obciążenie zapytania, które usługa może obsłużyć przez dłuższy czas pod względem zapytań na sekundę (QPS).
Opóźnienie zapytań
Opóźnienie zapytań różni się w zależności od obciążenia usługi i usług pod wyższym obciążeniem, które ma większe średnie opóźnienie zapytań. W poniższej tabeli przedstawiono 25, 50, 75, 90, 95 i 99. percentyle opóźnienia zapytań dla trzech różnych poziomów użycia.
| Procent maksymalnej liczby QPS | Średnie opóźnienie | 25% | 75% | 90% | 95% | 99% |
|---|---|---|---|---|---|---|
| 20% | 45 ms | 31 ms | 55 ms | 73 ms | 84 ms | 109 ms |
| 50% | 63 ms | 39 ms | 81 ms | 106 ms | 123 ms | 163 ms |
| 80% | 115 ms | 73 ms | 145 ms | 191 ms | 224 ms | 291 ms |
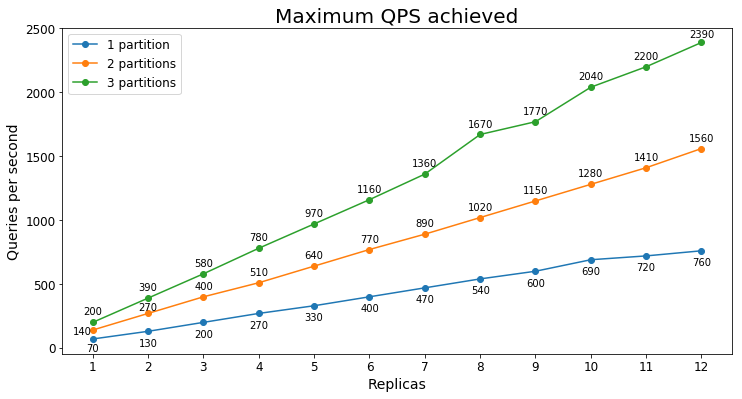
Wydajność S3
Zapytania na sekundę
Na poniższym wykresie przedstawiono najwyższe obciążenie zapytania, które usługa może obsłużyć przez dłuższy czas pod względem zapytań na sekundę (QPS).
Opóźnienie zapytań
Opóźnienie zapytań różni się w zależności od obciążenia usługi i usług pod wyższym obciążeniem, które ma większe średnie opóźnienie zapytań. W poniższej tabeli przedstawiono 25, 50, 75, 90, 95 i 99. percentyle opóźnienia zapytań dla trzech różnych poziomów użycia.
| Procent maksymalnej liczby QPS | Średnie opóźnienie | 25% | 75% | 90% | 95% | 99% |
|---|---|---|---|---|---|---|
| 20% | 43 ms | 29 ms | 53 ms | 74 ms | 86 ms | 111 ms |
| 50% | 65 ms | 37 ms | 85 ms | 111 ms | 128 ms | 164 ms |
| 80% | 126 ms | 83 ms | 162 ms | 205 ms | 233 ms | 281 ms |
Wnioski
Dzięki tym testom porównawczym możesz zapoznać się z wydajnością ofert usługi Azure AI Search. Można również zobaczyć różnicę między usługami w różnych warstwach.
Niektóre kluczowe sposoby na te testy porównawcze to:
- S2 może zwykle obsługiwać co najmniej cztery razy wolumin zapytania jako S1
- S2 zwykle ma mniejsze opóźnienie niż S1 w porównywalnych woluminach zapytań
- Podczas dodawania replik usługa QPS może obsługiwać zwykle skalowanie liniowe (na przykład jeśli jedna replika może obsłużyć 10 QPS, pięć replik może zwykle obsługiwać 50 QPS)
- Im większe obciążenie usługi, tym wyższe średnie opóźnienie
Widać również, że wydajność może się znacząco różnić między scenariuszami. Jeśli nie uzyskujesz oczekiwanej wydajności, zapoznaj się z poradami dotyczącymi lepszej wydajności.
Następne kroki
Teraz, po zapoznaniu się z testami porównawczymi wydajności, możesz dowiedzieć się więcej na temat analizowania wydajności usługi Azure AI Search i kluczowych czynników wpływających na wydajność.