łączniki Power Query (wersja zapoznawcza — wycofane)
Ważne
obsługa łącznika Power Query została wprowadzona jako bramna publiczna wersja zapoznawcza w obszarze Uzupełniające warunki użytkowania wersji zapoznawczych platformy Microsoft Azure, ale jest już wycofana. Jeśli masz rozwiązanie do wyszukiwania korzystające z łącznika Power Query, przeprowadź migrację do alternatywnego rozwiązania.
Migrowanie do 28 listopada 2022 r.
Wersja zapoznawcza łącznika Power Query została ogłoszona w maju 2021 r. i nie będzie kontynuowana do ogólnej dostępności. Poniższe wskazówki dotyczące migracji są dostępne dla usług Snowflake i PostgreSQL. Jeśli używasz innego łącznika i potrzebujesz instrukcji dotyczących migracji, skorzystaj z informacji kontaktowych poczty e-mail podanych w rejestracji w wersji zapoznawczej, aby poprosić o pomoc lub otworzyć bilet pomocy technicznej platformy Azure.
Wymagania wstępne
- Konto usługi Azure Storage. Jeśli go nie masz, utwórz konto magazynu.
- Azure Data Factory. Jeśli jej nie masz, utwórz fabrykę danych. Zobacz Cennik potoków usługi Data Factory przed wdrożeniem, aby zrozumieć powiązane koszty. Sprawdź również cennik usługi Data Factory za pomocą przykładów.
Migrowanie potoku danych usługi Snowflake
W tej sekcji wyjaśniono, jak skopiować dane z bazy danych Snowflake do indeksu Azure Cognitive Search. Nie ma procesu bezpośredniego indeksowania z usługi Snowflake do Azure Cognitive Search, dlatego ta sekcja zawiera fazę przejściową, która kopiuje zawartość bazy danych do kontenera obiektów blob usługi Azure Storage. Następnie zaindeksujesz z tego kontenera przejściowego przy użyciu potoku usługi Data Factory.
Krok 1. Pobieranie informacji o bazie danych Snowflake
Przejdź do usługi Snowflake i zaloguj się na swoje konto usługi Snowflake. Konto snowflake wygląda jak https://< account_name.snowflakecomputing.com>.
Po zalogowaniu z okienka po lewej stronie zbierz następujące informacje. Te informacje będą używane w następnym kroku:
- W obszarze Dane wybierz pozycję Bazy danych i skopiuj nazwę źródła bazy danych.
- W Administracja wybierz pozycję Użytkownicy & Role i skopiuj nazwę użytkownika. Upewnij się, że użytkownik ma uprawnienia do odczytu.
- W Administracja wybierz pozycję Konta i skopiuj wartość LOKALIZATOR konta.
- Z adresu URL aplikacji Snowflake, podobnie jak
https://app.snowflake.com/<region_name>/xy12345/organization). skopiuj nazwę regionu. Na przykład w plikuhttps://app.snowflake.com/south-central-us.azure/xy12345/organizationnazwa regionu tosouth-central-us.azure. - W Administracja wybierz pozycję Magazyny i skopiuj nazwę magazynu skojarzonego z bazą danych, której będziesz używać jako źródła.
Krok 2. Konfigurowanie połączonej usługi Snowflake
Zaloguj się do programu Azure Data Factory Studio przy użyciu konta platformy Azure.
Wybierz fabrykę danych, a następnie wybierz pozycję Kontynuuj.
W menu po lewej stronie wybierz ikonę Zarządzaj .
W obszarze Połączone usługi wybierz pozycję Nowe.
W okienku po prawej stronie w wyszukiwaniu magazynu danych wprowadź ciąg "snowflake". Wybierz kafelek Snowflake i wybierz pozycję Kontynuuj.
Wypełnij formularz Nowa połączona usługa danymi zebranymi w poprzednim kroku. Nazwa konta zawiera wartość LOKALIZATORa i region (na przykład:
xy56789south-central-us.azure).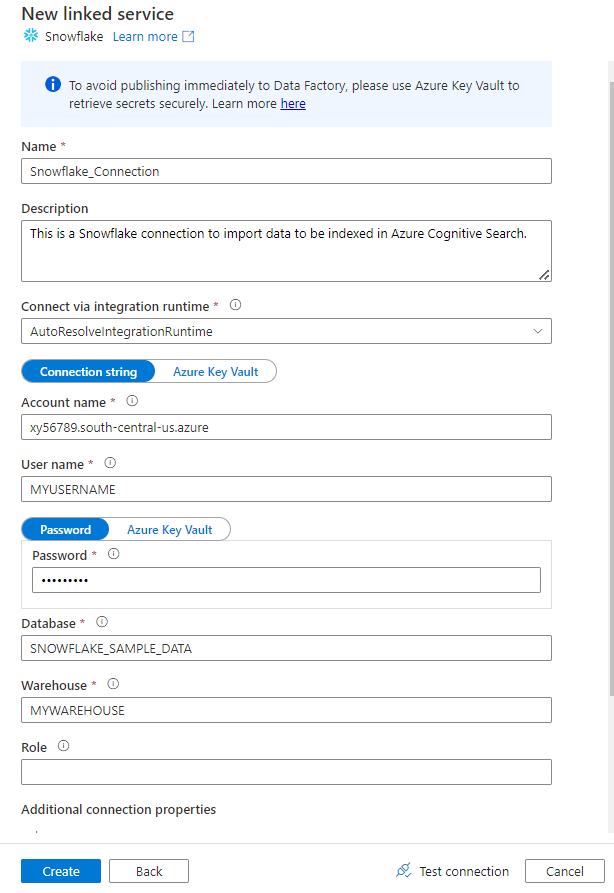
Po zakończeniu formularza wybierz pozycję Testuj połączenie.
Jeśli test zakończy się pomyślnie, wybierz pozycję Utwórz.
Krok 3. Konfigurowanie zestawu danych snowflake
W menu po lewej stronie wybierz ikonę Autor .
Wybierz pozycję Zestawy danych, a następnie wybierz menu Wielokropek akcji zestawów danych (
...).
Wybierz pozycję Nowy zestaw danych.
W okienku po prawej stronie w wyszukiwaniu magazynu danych wprowadź ciąg "snowflake". Wybierz kafelek Snowflake i wybierz pozycję Kontynuuj.

W obszarze Ustaw właściwości:
- Wybierz połączoną usługę utworzoną w kroku 2.
- Wybierz tabelę, którą chcesz zaimportować, a następnie wybierz przycisk OK.
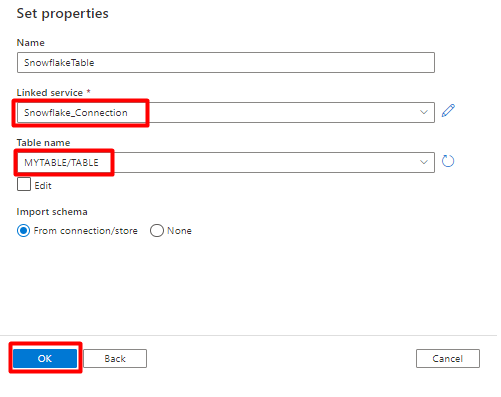
Wybierz pozycję Zapisz.
Krok 4. Tworzenie nowego indeksu w Azure Cognitive Search
Utwórz nowy indeks w usłudze Azure Cognitive Search z tym samym schematem co ten, który jest obecnie skonfigurowany dla danych usługi Snowflake.
Możesz zmienić przeznaczenie indeksu, którego obecnie używasz dla łącznika Snowflake Power Connector. W Azure Portal znajdź indeks, a następnie wybierz pozycję Definicja indeksu (JSON). Wybierz definicję i skopiuj ją do treści nowego żądania indeksu.

Krok 5. Konfigurowanie połączonej usługi Azure Cognitive Search
W menu po lewej stronie wybierz pozycję Zarządzaj ikoną.
W obszarze Połączone usługi wybierz pozycję Nowe.
W okienku po prawej stronie w wyszukiwaniu magazynu danych wprowadź ciąg "search". Wybierz kafelek Azure Search i wybierz pozycję Kontynuuj.
Wypełnij wartości Nowa połączona usługa :
- Wybierz subskrypcję platformy Azure, w której znajduje się twoja usługa Azure Cognitive Search.
- Wybierz usługę Azure Cognitive Search z indeksatorem łącznika Power Query.
- Wybierz przycisk Utwórz.

Krok 6. Konfigurowanie zestawu danych Azure Cognitive Search
W menu po lewej stronie wybierz pozycję Ikona autora .
Wybierz pozycję Zestawy danych, a następnie wybierz menu Wielokropek akcji zestawów danych (
...).
Wybierz pozycję Nowy zestaw danych.
W okienku po prawej stronie w wyszukiwaniu magazynu danych wprowadź ciąg "search". Wybierz kafelek Azure Search i wybierz pozycję Kontynuuj.
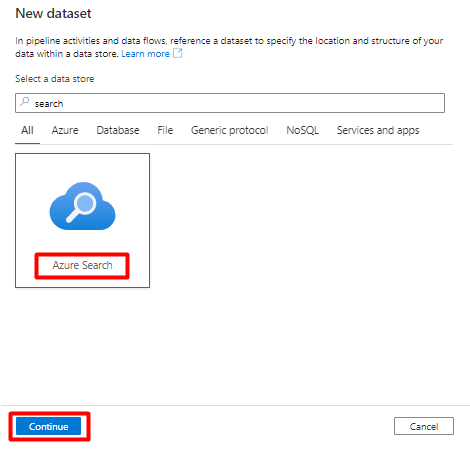
W obszarze Ustaw właściwości:
Wybierz pozycję Zapisz.
Krok 7. Konfigurowanie połączonej usługi Azure Blob Storage
W menu po lewej stronie wybierz pozycję Zarządzaj ikoną.
W obszarze Połączone usługi wybierz pozycję Nowy.
W okienku po prawej stronie w wyszukiwaniu magazynu danych wprowadź "storage". Wybierz kafelek Azure Blob Storage i wybierz pozycję Kontynuuj.
Wypełnij pola Nowe połączone wartości usługi :
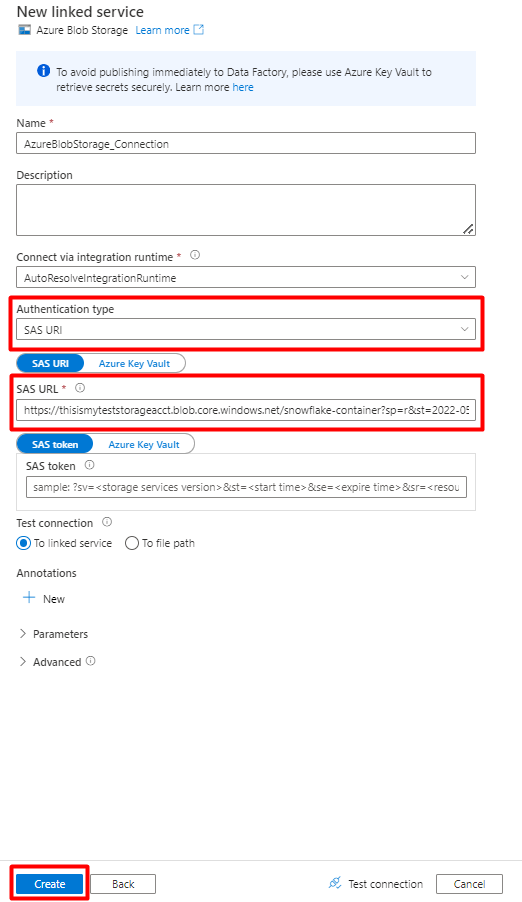
Wybierz typ uwierzytelniania: identyfikator URI sygnatury dostępu współdzielonego. Tylko ten typ uwierzytelniania może służyć do importowania danych z usługi Snowflake do Azure Blob Storage.
Wygeneruj adres URL sygnatury dostępu współdzielonego dla konta magazynu, którego będziesz używać do przemieszczania. Wklej adres URL sygnatury dostępu współdzielonego obiektu blob w polu Adres URL sygnatury dostępu współdzielonego.
Wybierz przycisk Utwórz.
Krok 8. Konfigurowanie zestawu danych magazynu
W menu po lewej stronie wybierz pozycję Ikona autora .
Wybierz pozycję Zestawy danych, a następnie wybierz menu Wielokropek akcji zestawów danych (
...).
Wybierz pozycję Nowy zestaw danych.
W okienku po prawej stronie w wyszukiwaniu magazynu danych wprowadź "storage". Wybierz kafelek Azure Blob Storage i wybierz pozycję Kontynuuj.
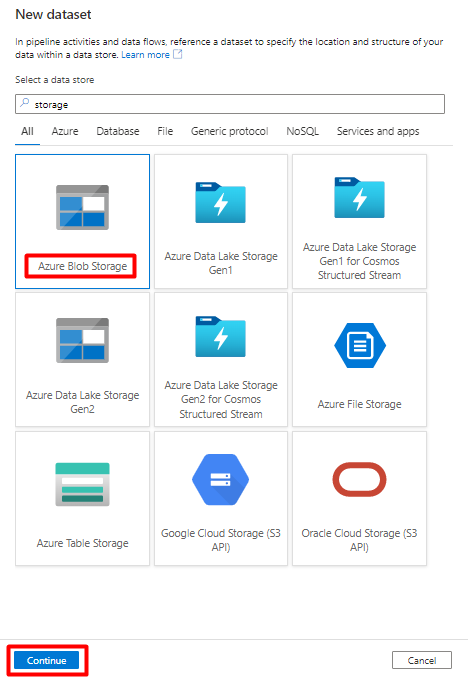
Wybierz pozycję Format ogranicznikaTekstu i wybierz pozycję Kontynuuj.
W obszarze Ustaw właściwości:
W obszarze Połączona usługa wybierz połączoną usługę utworzoną w kroku 7.
W obszarze Ścieżka pliku wybierz kontener, który będzie ujściem procesu przejściowego, a następnie wybierz przycisk OK.

W ograniczniku wierszy wybierz pozycję Źródło wiersza (\n).
Zaznacz pierwszy wiersz jako pole nagłówka .
Wybierz pozycję Zapisz.
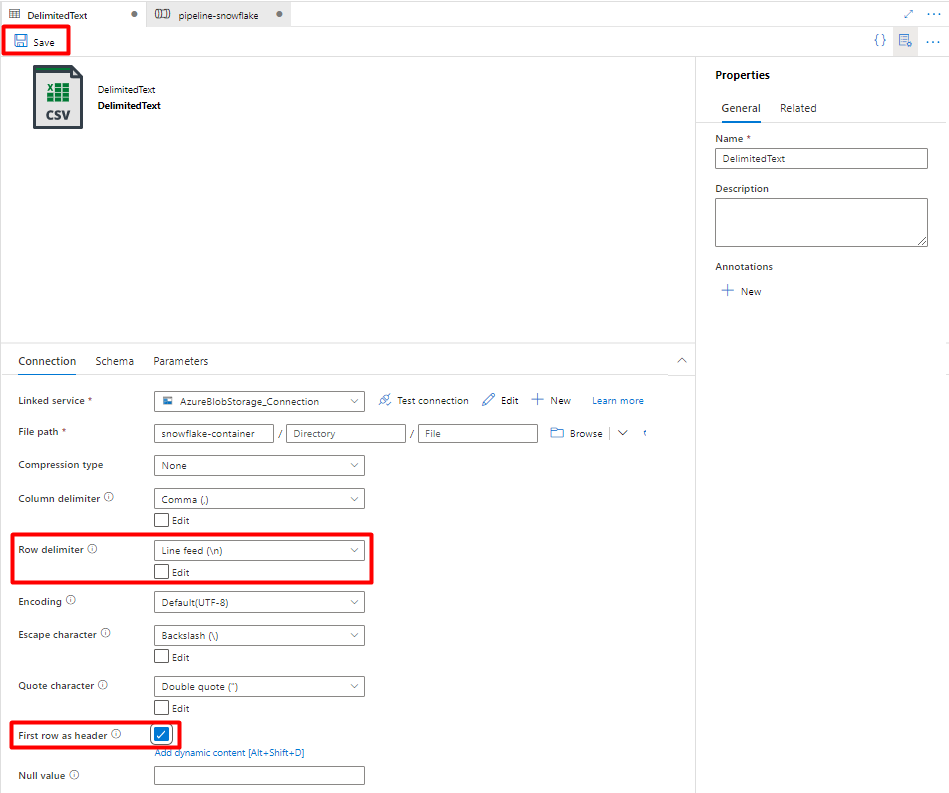
Krok 9. Konfigurowanie potoku
W menu po lewej stronie wybierz pozycję Ikona autora .
Wybierz pozycję Potoki, a następnie wybierz menu Wielokropek akcji potoków (
...).
Wybierz pozycję Nowy potok.
Utwórz i skonfiguruj działania usługi Data Factory , które kopiują z usługi Snowflake do kontenera usługi Azure Storage:
Rozwiń sekcję Przenieś & przekształcenia i przeciągnij i upuść działanie Kopiuj dane na pustą kanwę edytora potoków.
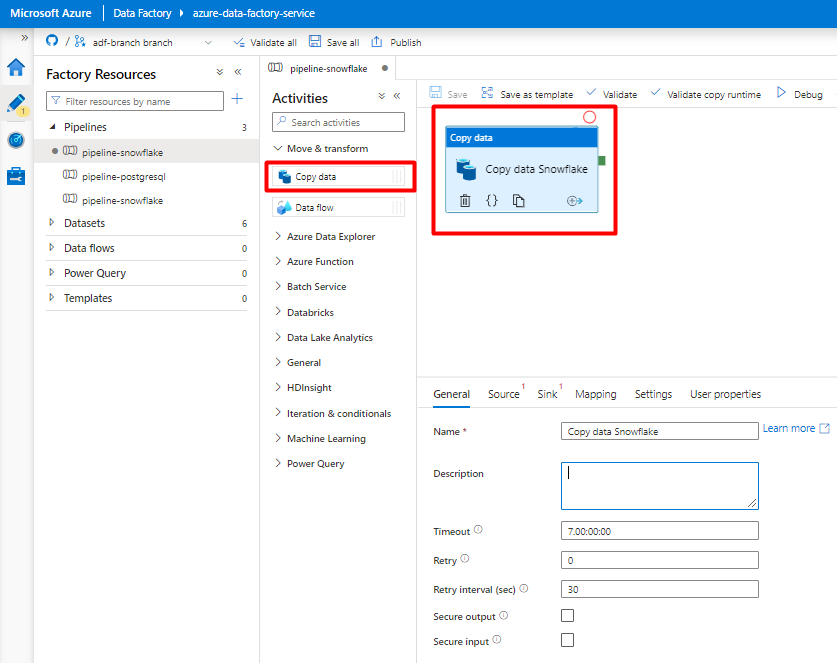
Otwórz kartę Ogólne . Zaakceptuj wartości domyślne, chyba że musisz dostosować wykonanie.
Na karcie Źródło wybierz tabelę Snowflake. Pozostaw pozostałe opcje z wartościami domyślnymi.
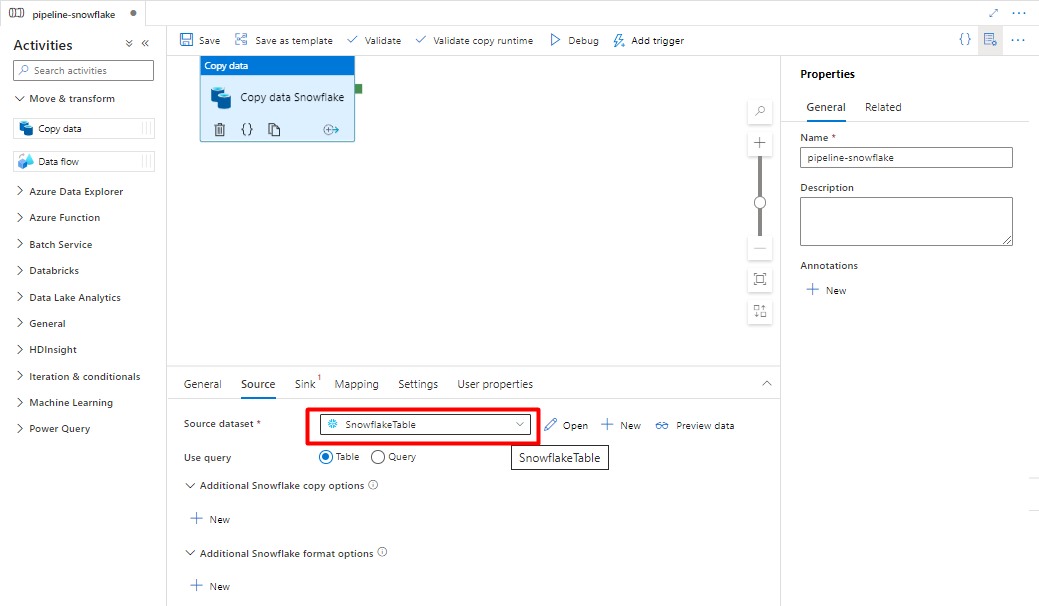
Na karcie Ujście :
Wybierz pozycję Magazyn rozdzielany Tekst zestaw danych utworzony w kroku 8.
W obszarze Rozszerzenie pliku dodaj .csv.
Pozostaw pozostałe opcje z wartościami domyślnymi.
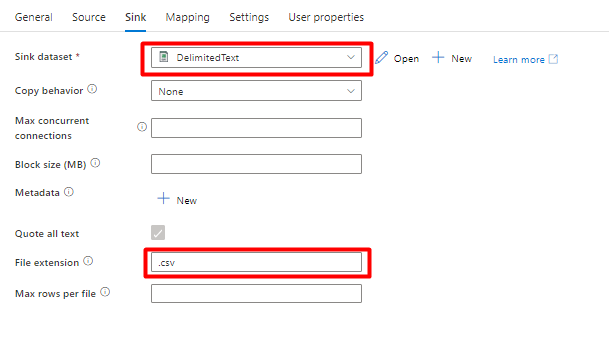
Wybierz pozycję Zapisz.
Skonfiguruj działania, które kopiują z usługi Azure Storage Blob do indeksu wyszukiwania:
Rozwiń sekcję Przenieś & przekształcenia i przeciągnij i upuść działanie Kopiuj dane na pustą kanwę edytora potoków.
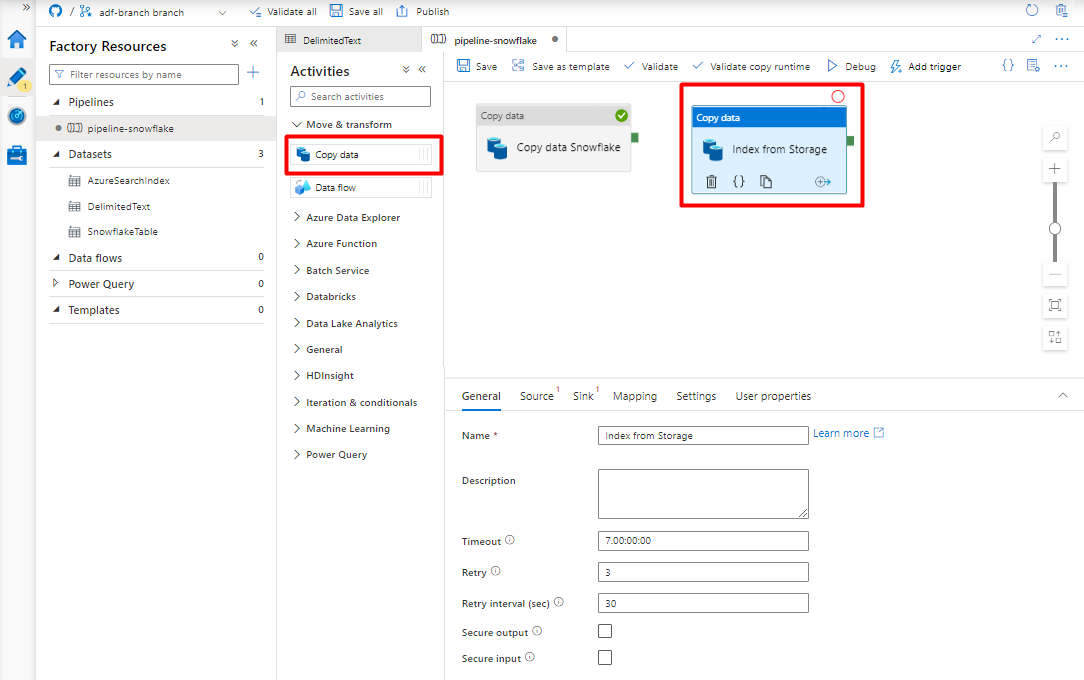
Na karcie Ogólne zaakceptuj wartości domyślne, chyba że musisz dostosować wykonanie.
Na karcie Źródło :
- Wybierz pozycję Magazyn rozdzielany Tekst zestaw danych utworzony w kroku 8.
- W polu Ścieżka pliku wybierzpozycję Ścieżka pliku z symbolami wieloznacznymi.
- Pozostaw wszystkie pozostałe pola z wartościami domyślnymi.
Na karcie Ujście wybierz indeks Azure Cognitive Search. Pozostaw pozostałe opcje z wartościami domyślnymi.
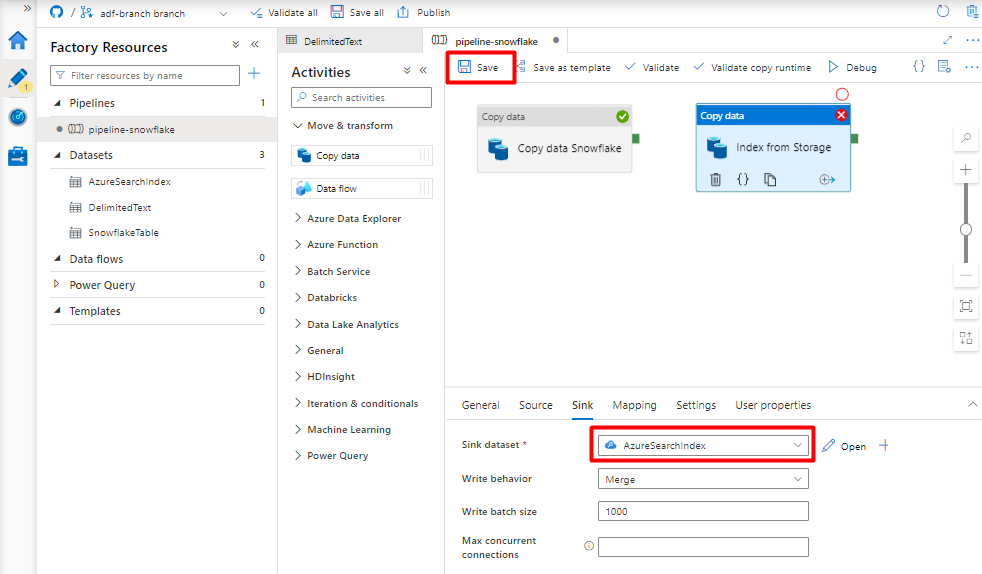
Wybierz pozycję Zapisz.
Krok 10. Konfigurowanie kolejności działań
W edytorze kanwy potoku wybierz mały zielony kwadrat na krawędzi kafelka działania potoku. Przeciągnij go do działania "Indeksy z konta magazynu, aby Azure Cognitive Search", aby ustawić kolejność wykonywania.
Wybierz pozycję Zapisz.
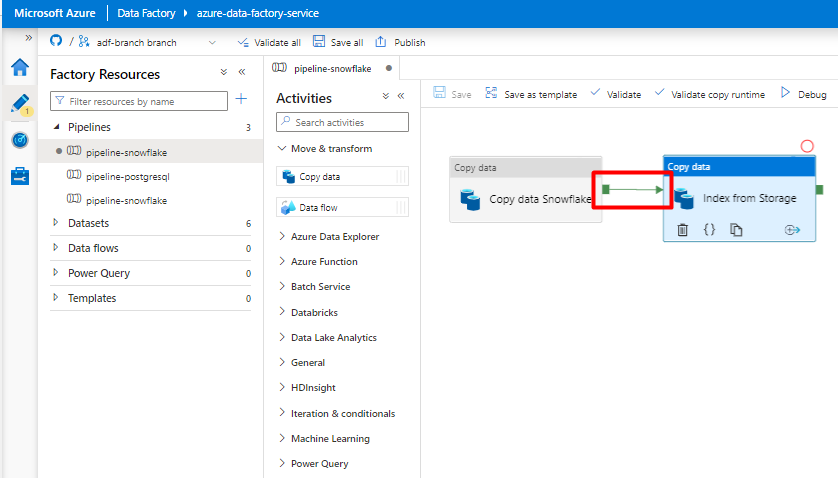
Krok 11. Dodawanie wyzwalacza potoku
Wybierz pozycję Dodaj wyzwalacz , aby zaplanować uruchomienie potoku, a następnie wybierz pozycję Nowy/Edytuj.
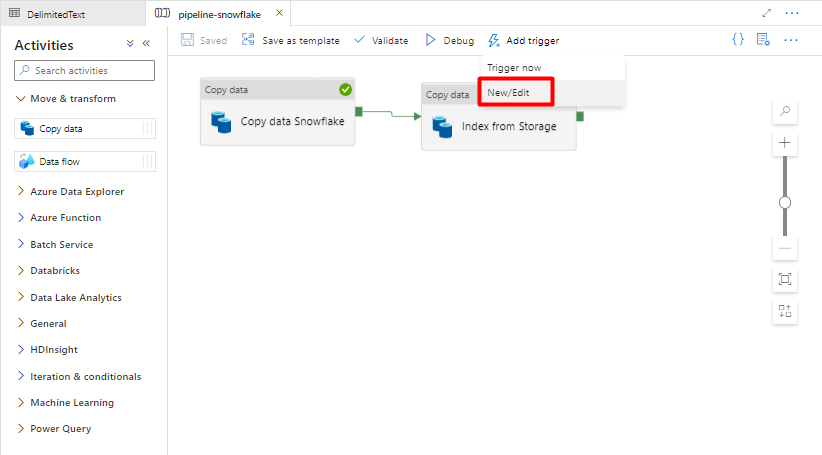
Z listy rozwijanej Wybierz wyzwalacz wybierz pozycję Nowy.
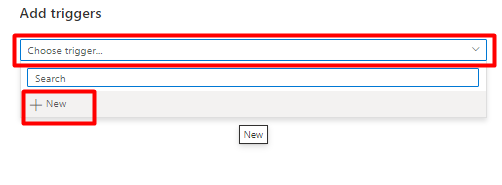
Przejrzyj opcje wyzwalacza, aby uruchomić potok i wybierz przycisk OK.
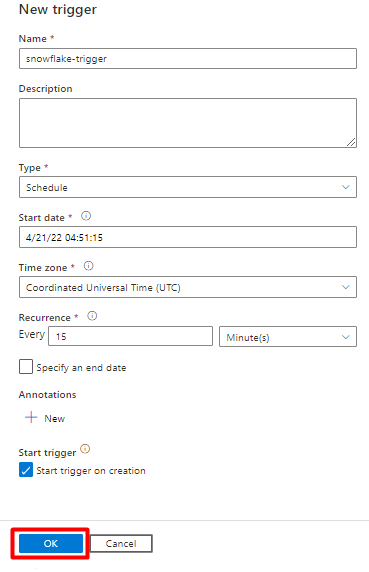
Wybierz pozycję Zapisz.
Kliknij pozycję Opublikuj.

Migrowanie potoku danych PostgreSQL
W tej sekcji wyjaśniono, jak skopiować dane z bazy danych PostgreSQL do indeksu Azure Cognitive Search. Nie ma procesu bezpośredniego indeksowania z bazy danych PostgreSQL do Azure Cognitive Search, dlatego ta sekcja zawiera fazę przemieszczania, która kopiuje zawartość bazy danych do kontenera obiektów blob usługi Azure Storage. Następnie zaindeksujesz z tego kontenera przejściowego przy użyciu potoku usługi Data Factory.
Krok 1. Konfigurowanie połączonej usługi PostgreSQL
Zaloguj się do programu Azure Data Factory Studio przy użyciu konta platformy Azure.
Wybierz usługę Data Factory i wybierz pozycję Kontynuuj.
W menu po lewej stronie wybierz ikonę Zarządzaj .
W obszarze Połączone usługi wybierz pozycję Nowy.
W okienku po prawej stronie w wyszukiwaniu magazynu danych wprowadź "postgresql". Wybierz kafelek PostgreSQL, który reprezentuje lokalizację bazy danych PostgreSQL (azure lub inną), a następnie wybierz pozycję Kontynuuj. W tym przykładzie baza danych PostgreSQL znajduje się na platformie Azure.

Wypełnij pola Nowe połączone wartości usługi :
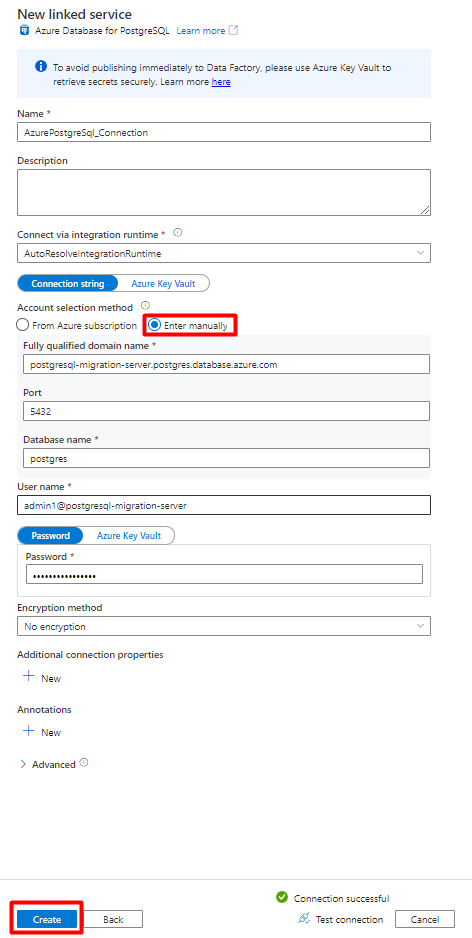
W obszarze Metoda wyboru konta wybierz pozycję Wprowadź ręcznie.
Na stronie Przegląd Azure Database for PostgreSQL w Azure Portal wklej następujące wartości w odpowiednim polu:
- Dodaj nazwę serwera do w pełni kwalifikowanej nazwy domeny.
- Dodaj nazwę użytkownika Administracja do nazwy użytkownika.
- Dodaj bazę danych do nazwy bazy danych.
- Wprowadź hasło nazwy użytkownika Administracja do hasła nazwy użytkownika.
- Wybierz przycisk Utwórz.
Krok 2. Konfigurowanie zestawu danych PostgreSQL
W menu po lewej stronie wybierz pozycję Ikona autora .
Wybierz pozycję Zestawy danych, a następnie wybierz menu Wielokropek akcji zestawów danych (
...).
Wybierz pozycję Nowy zestaw danych.
W okienku po prawej stronie w wyszukiwaniu magazynu danych wprowadź "postgresql". Wybierz kafelek Azure PostgreSQL . Wybierz opcję Kontynuuj.
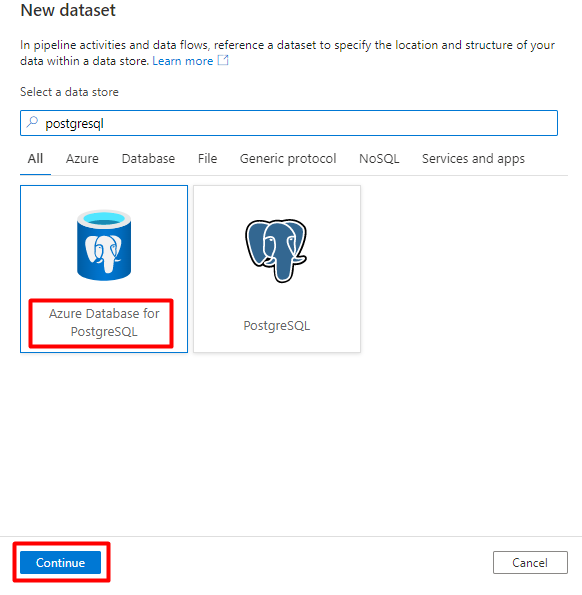
Wypełnij pola Ustaw wartości właściwości :
Wybierz połączoną usługę PostgreSQL utworzoną w kroku 1.
Wybierz tabelę, którą chcesz zaimportować/indeks.
Wybierz przycisk OK.
Wybierz pozycję Zapisz.
Krok 3. Tworzenie nowego indeksu w Azure Cognitive Search
Utwórz nowy indeks w usłudze Azure Cognitive Search z tym samym schematem co ten, który jest używany dla danych PostgreSQL.
Możesz zmienić przeznaczenie indeksu, którego obecnie używasz dla łącznika Programu Power Connector PostgreSQL. W Azure Portal znajdź indeks, a następnie wybierz pozycję Definicja indeksu (JSON). Wybierz definicję i skopiuj ją do treści nowego żądania indeksu.

Krok 4. Konfigurowanie połączonej usługi Azure Cognitive Search
W menu po lewej stronie wybierz ikonę Zarządzaj .
W obszarze Połączone usługi wybierz pozycję Nowe.
W okienku po prawej stronie w wyszukiwaniu magazynu danych wprowadź ciąg "search". Wybierz kafelek Azure Search i wybierz pozycję Kontynuuj.
Wypełnij wartości Nowa połączona usługa :
- Wybierz subskrypcję platformy Azure, w której znajduje się twoja usługa Azure Cognitive Search.
- Wybierz usługę Azure Cognitive Search z indeksatorem łącznika Power Query.
- Wybierz przycisk Utwórz.
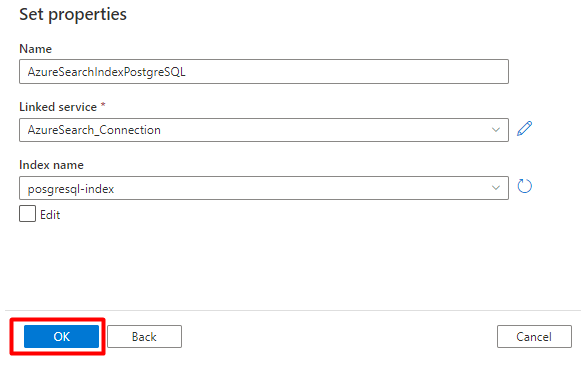
Krok 5. Konfigurowanie zestawu danych Azure Cognitive Search
W menu po lewej stronie wybierz pozycję Ikona autora .
Wybierz pozycję Zestawy danych, a następnie wybierz menu Wielokropek akcji zestawów danych (
...).
Wybierz pozycję Nowy zestaw danych.
W okienku po prawej stronie w wyszukiwaniu magazynu danych wprowadź ciąg "search". Wybierz kafelek Azure Search i wybierz pozycję Kontynuuj.
W obszarze Ustaw właściwości:
Wybierz pozycję Zapisz.
Krok 6. Konfigurowanie połączonej usługi Azure Blob Storage
W menu po lewej stronie wybierz pozycję Zarządzaj ikoną.
W obszarze Połączone usługi wybierz pozycję Nowe.
W okienku po prawej stronie w wyszukiwaniu magazynu danych wprowadź "storage". Wybierz kafelek Azure Blob Storage i wybierz pozycję Kontynuuj.
Wypełnij wartości Nowa połączona usługa :
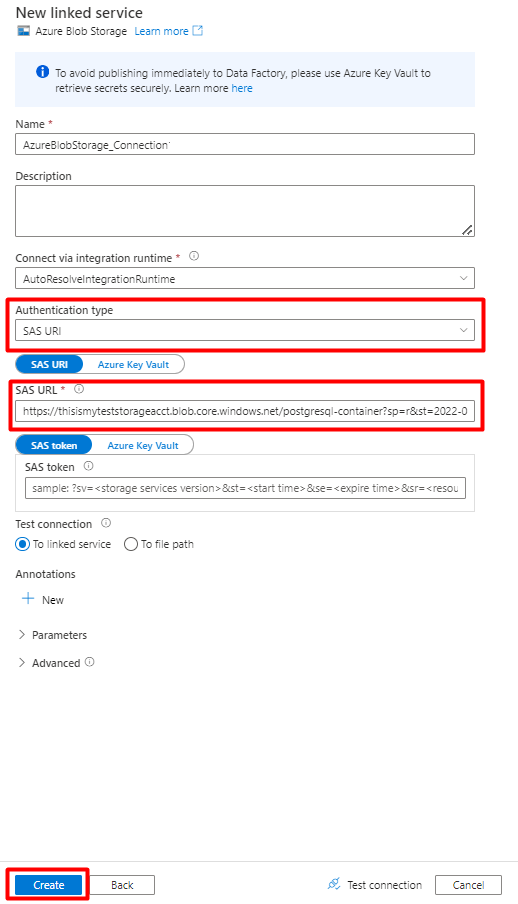
Wybierz typ uwierzytelniania: identyfikator URI sygnatury dostępu współdzielonego. Tylko ta metoda może służyć do importowania danych z bazy danych PostgreSQL do Azure Blob Storage.
Wygeneruj adres URL sygnatury dostępu współdzielonego dla konta magazynu, którego będziesz używać do przemieszczania, i skopiuj adres URL sygnatury dostępu współdzielonego do pola Adres URL sygnatury dostępu współdzielonego.
Wybierz przycisk Utwórz.
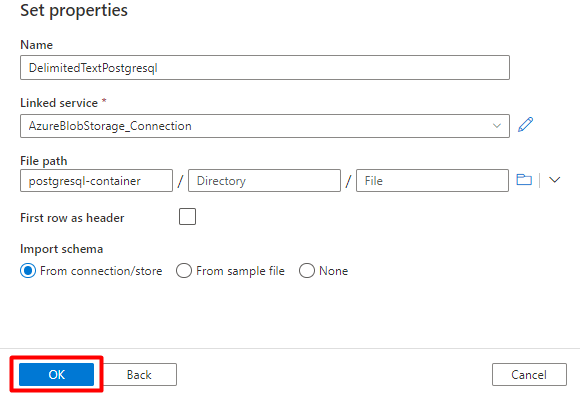
Krok 7. Konfigurowanie zestawu danych magazynu
W menu po lewej stronie wybierz pozycję Ikona autora .
Wybierz pozycję Zestawy danych, a następnie wybierz menu Wielokropek akcji zestawów danych (
...).
Wybierz pozycję Nowy zestaw danych.
W okienku po prawej stronie w wyszukiwaniu magazynu danych wprowadź "storage". Wybierz kafelek Azure Blob Storage i wybierz pozycję Kontynuuj.
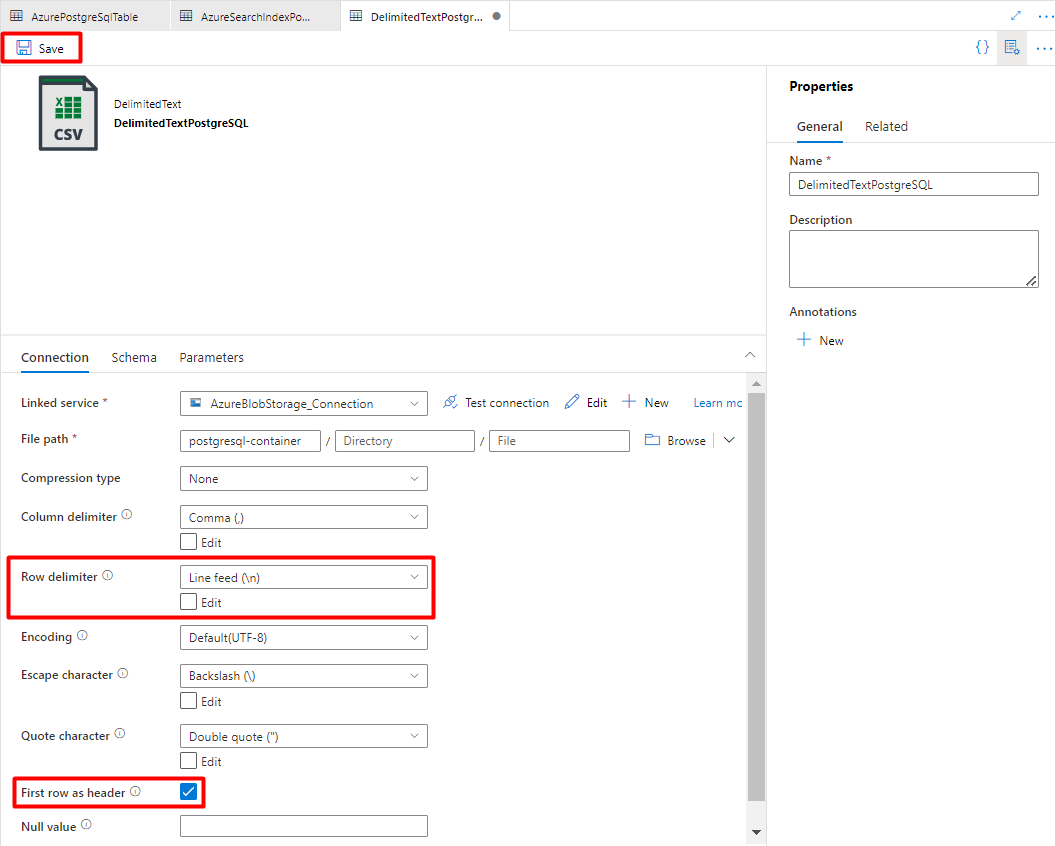
Wybierz pozycję Format delimitedText i wybierz pozycję Kontynuuj.
W ograniczniku wierszy wybierz pozycję Źródło wiersza (\n).
Zaznacz pole Pierwszy wiersz jako nagłówek .
Wybierz pozycję Zapisz.
Krok 8. Konfigurowanie potoku
W menu po lewej stronie wybierz pozycję Ikona autora .
Wybierz pozycję Potoki, a następnie wybierz menu Wielokropek akcji potoków (
...).
Wybierz pozycję Nowy potok.
Tworzenie i konfigurowanie działań usługi Data Factory kopiujących z bazy danych PostgreSQL do kontenera usługi Azure Storage.
Rozwiń sekcję Przenieś & przekształcania , a następnie przeciągnij i upuść działanie Kopiuj dane na pustą kanwę edytora potoków.
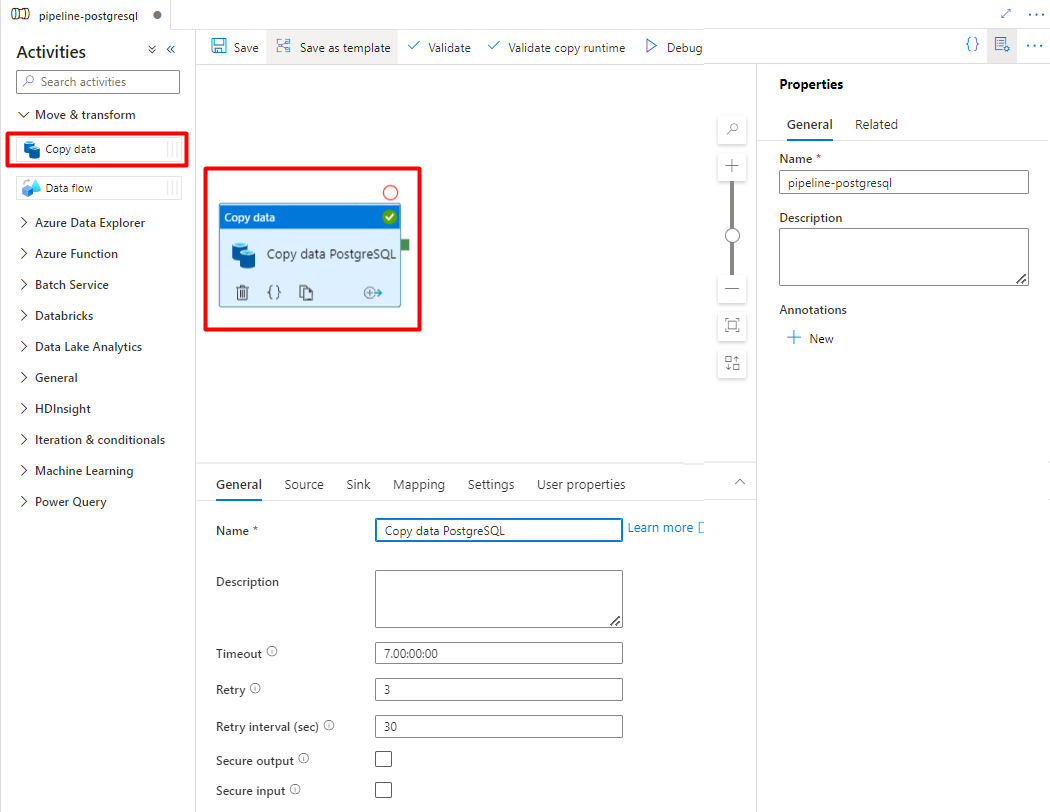
Otwórz kartę Ogólne , zaakceptuj wartości domyślne, chyba że musisz dostosować wykonywanie.
Na karcie Źródło wybierz tabelę PostgreSQL. Pozostaw pozostałe opcje z wartościami domyślnymi.
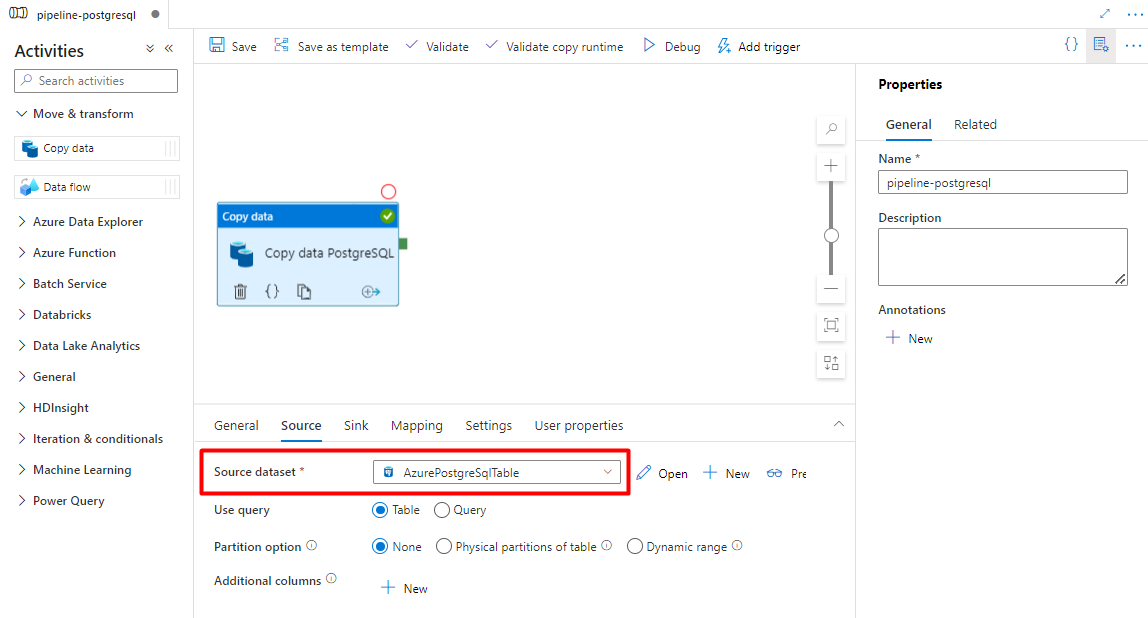
Na karcie Ujście :
Wybierz zestaw danych Storage DelimitedText PostgreSQL skonfigurowany w kroku 7.
W obszarze Rozszerzenie pliku dodaj .csv
Pozostaw pozostałe opcje z wartościami domyślnymi.
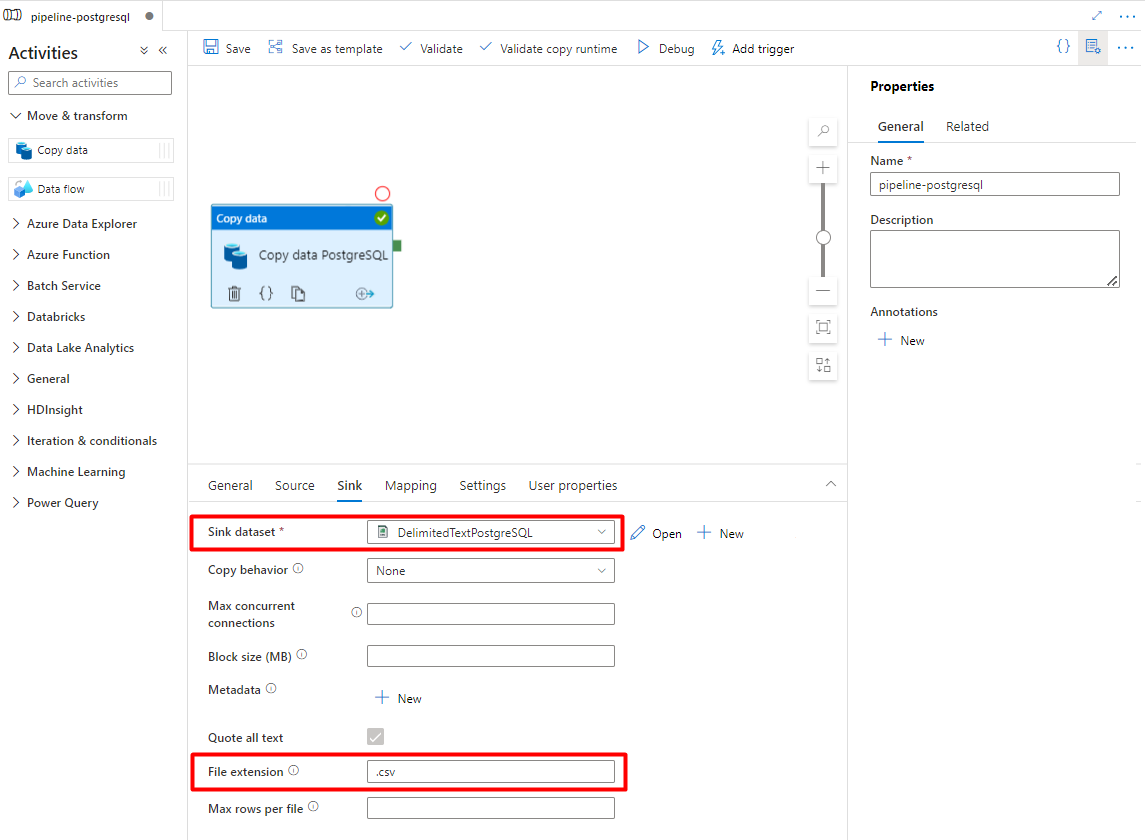
Wybierz pozycję Zapisz.
Skonfiguruj działania, które kopiują z usługi Azure Storage do indeksu wyszukiwania:
Rozwiń sekcję Przenieś & przekształcania , a następnie przeciągnij i upuść działanie Kopiuj dane na pustą kanwę edytora potoków.
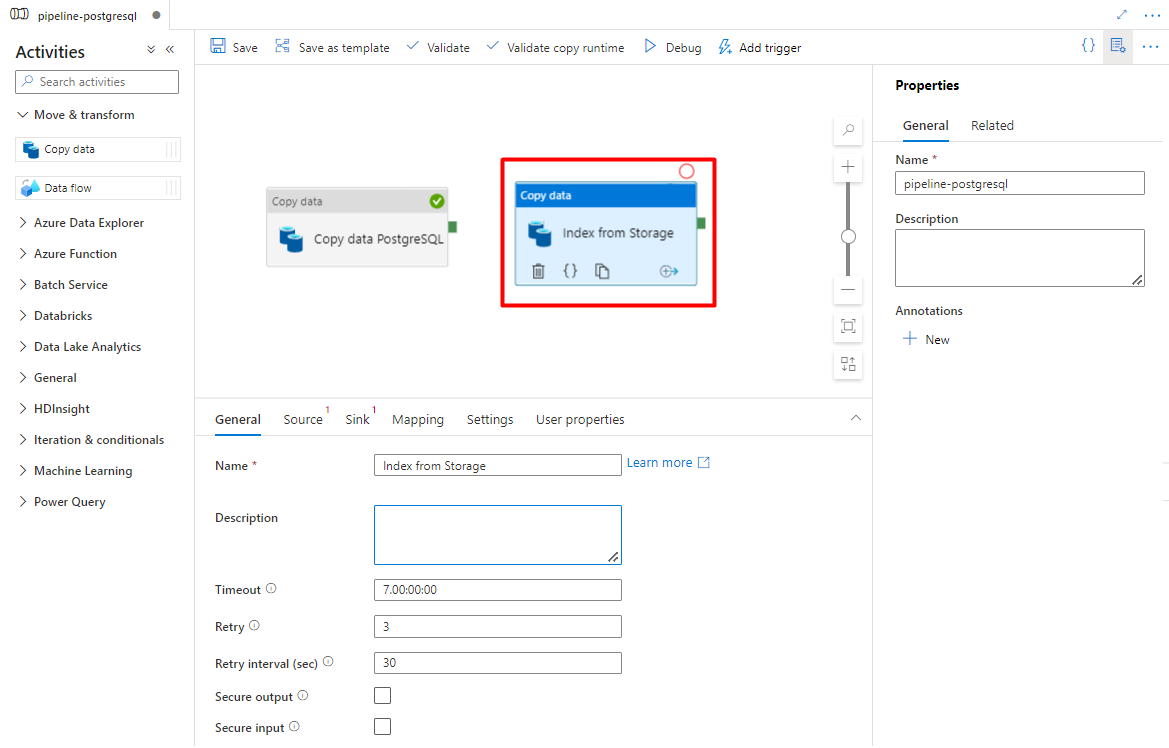
Na karcie Ogólne pozostaw wartości domyślne, chyba że musisz dostosować wykonywanie.
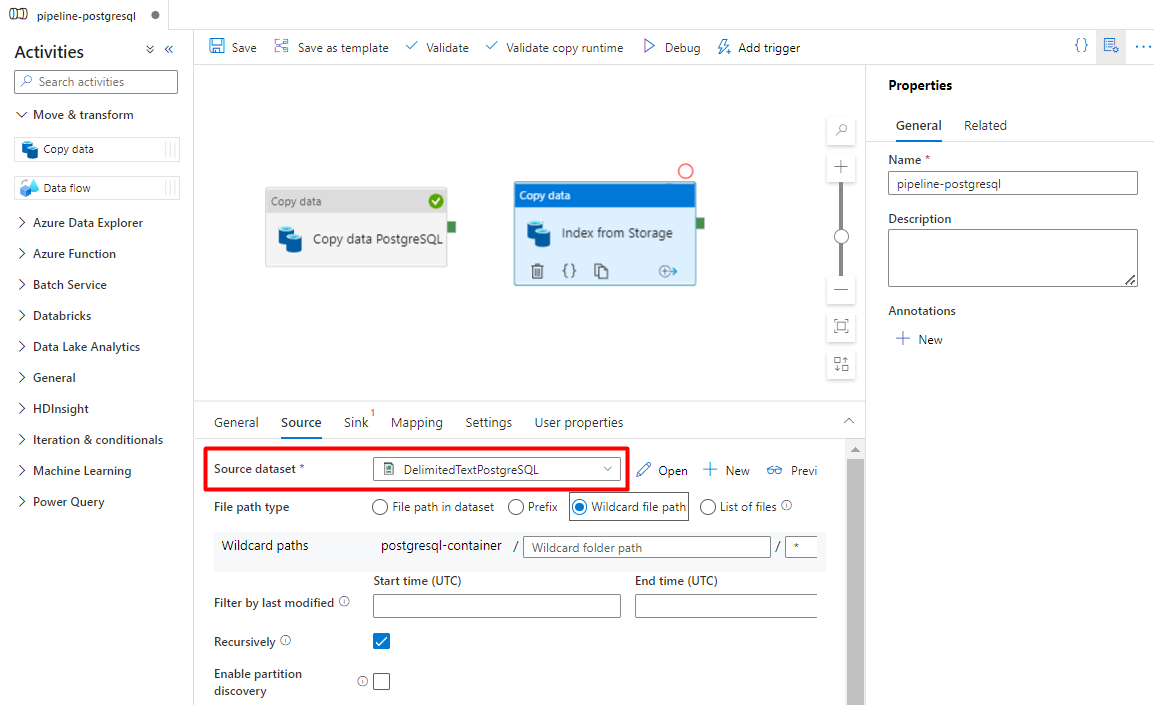
Na karcie Źródło :
- Wybierz zestaw danych źródła magazynu skonfigurowany w kroku 7.
- W polu Typ ścieżki pliku wybierz pozycję Ścieżka pliku z symbolem wieloznacznymi.
- Pozostaw wszystkie pozostałe pola z wartościami domyślnymi.
Na karcie Ujście wybierz indeks Azure Cognitive Search. Pozostaw pozostałe opcje z wartościami domyślnymi.
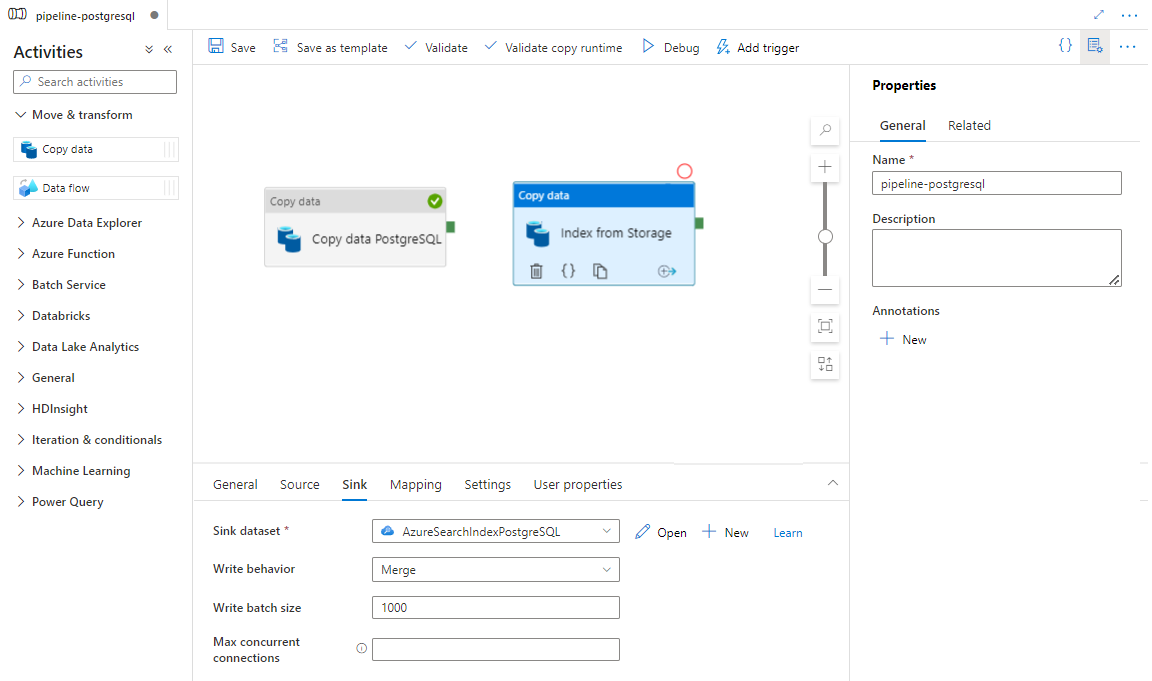
Wybierz pozycję Zapisz.
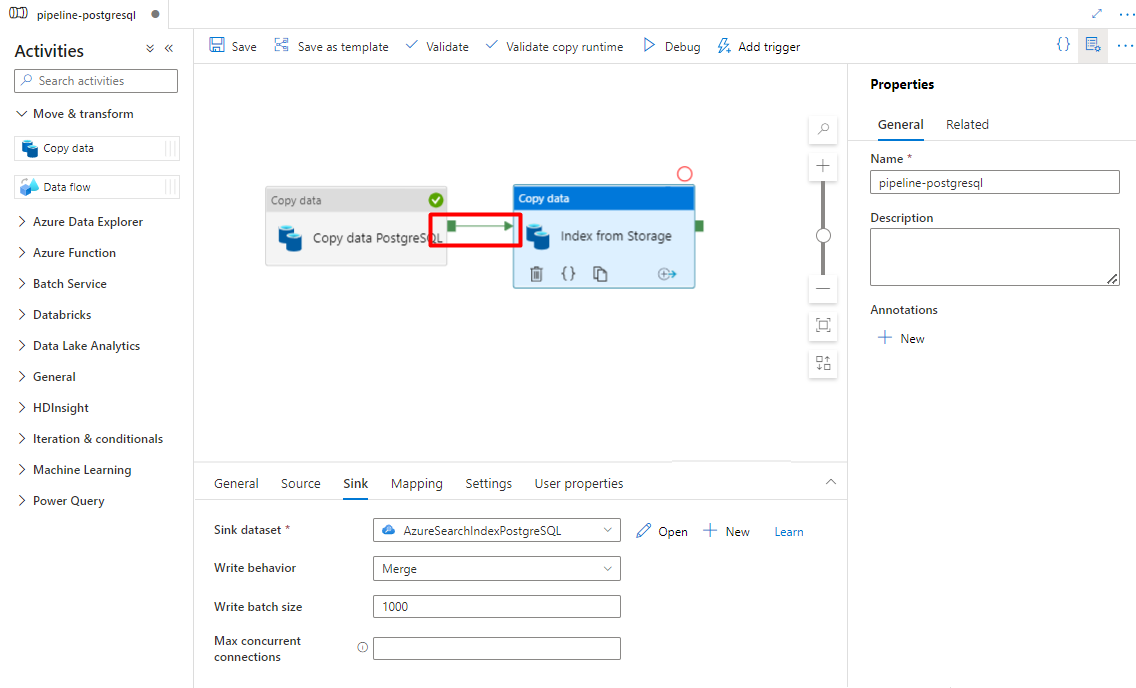
Krok 9. Konfigurowanie kolejności działań
W edytorze kanwy potoku wybierz mały zielony kwadrat na krawędzi działania potoku. Przeciągnij go do działania "Indeksy z konta magazynu do Azure Cognitive Search", aby ustawić kolejność wykonywania.
Wybierz pozycję Zapisz.
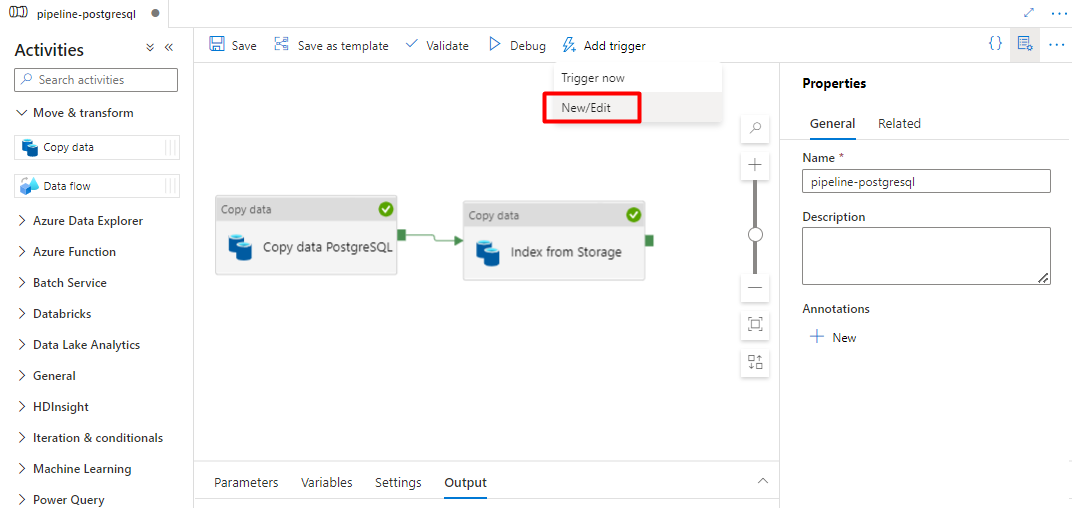
Krok 10. Dodawanie wyzwalacza potoku
Wybierz pozycję Dodaj wyzwalacz , aby zaplanować uruchomienie potoku, a następnie wybierz pozycję Nowy/Edytuj.
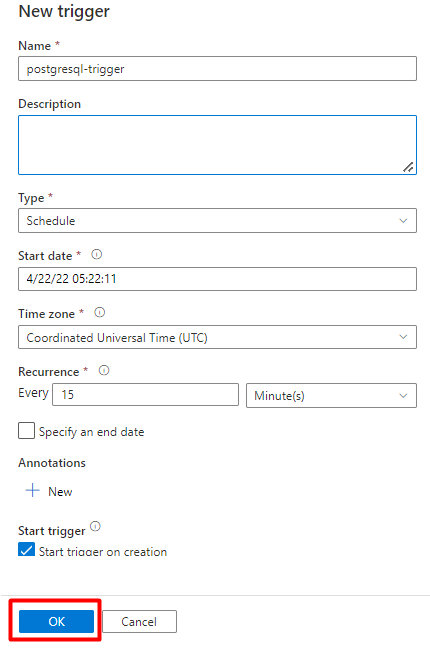
Z listy rozwijanej Wybierz wyzwalacz wybierz pozycję Nowy.
Przejrzyj opcje wyzwalacza, aby uruchomić potok i wybierz przycisk OK.
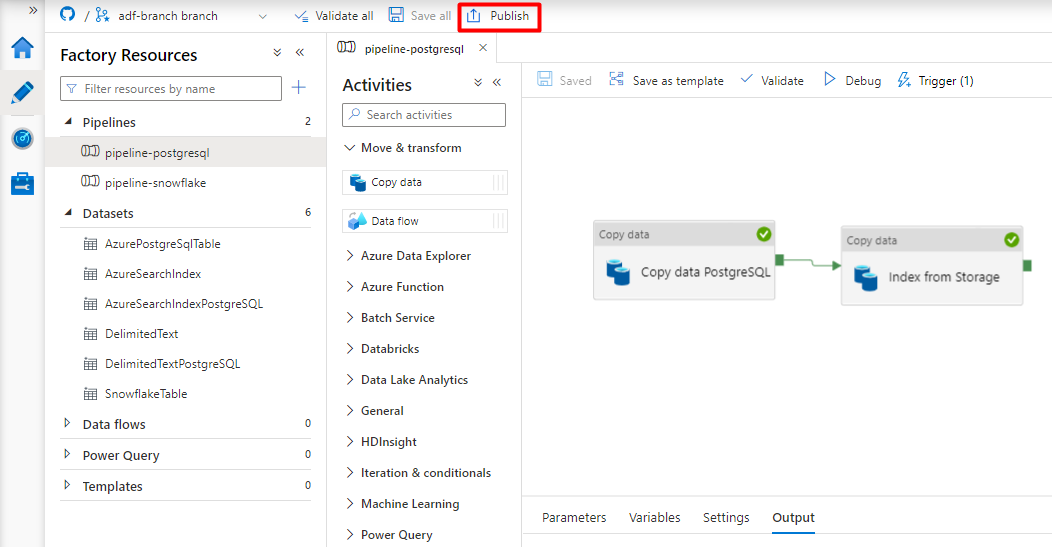
Wybierz pozycję Zapisz.
Kliknij pozycję Opublikuj.
Starsza zawartość dla wersji zapoznawczej łącznika Power Query
Łącznik Power Query jest używany z indeksatorem wyszukiwania w celu zautomatyzowania pozyskiwania danych z różnych źródeł danych, w tym tych u innych dostawców usług w chmurze. Używa Power Query do pobierania danych.
Źródła danych obsługiwane w wersji zapoznawczej obejmują:
- Amazon Redshift
- Elasticsearch
- PostgreSQL
- Obiekty Salesforce
- Raporty Salesforce
- Smartsheet
- Snowflake
Obsługiwane funkcje
Power Query łączniki są używane w indeksatorach. Indeksator w Azure Cognitive Search to przeszukiwarka, która wyodrębnia przeszukiwalne dane i metadane z zewnętrznego źródła danych i wypełnia indeks na podstawie mapowań między indeksem a źródłem danych. Takie podejście jest czasami określane jako "model ściągania", ponieważ usługa ściąga dane bez konieczności pisania kodu, który dodaje dane do indeksu. Indeksatory zapewniają wygodny sposób indeksowania zawartości ze źródła danych bez konieczności pisania własnego przeszukiwarki lub modelu wypychania.
Indeksatory odwołujące się do Power Query źródeł danych mają taki sam poziom obsługi zestawów umiejętności, harmonogramów, logiki wykrywania zmian ze znacznikami górnego znaku wodnego i większości parametrów obsługiwanych przez inne indeksatory.
Wymagania wstępne
Chociaż nie można już używać tej funkcji, w wersji zapoznawczej są spełnione następujące wymagania:
Azure Cognitive Search usługi w obsługiwanym regionie.
Rejestracja w wersji zapoznawczej. Ta funkcja musi być włączona w zapleczu.
Azure Blob Storage konto, używane jako pośrednik dla Twoich danych. Dane będą przepływać ze źródła danych, a następnie do usługi Blob Storage, a następnie do indeksu. To wymaganie istnieje tylko w początkowej wersji zapoznawczej z bramą.
Dostępność w regionach
Wersja zapoznawcza była dostępna tylko w usługach wyszukiwania w następujących regionach:
- Central US
- East US
- Wschodnie stany USA 2
- Północno-środkowe stany USA
- Europa Północna
- South Central US
- Zachodnio-środkowe stany USA
- West Europe
- Zachodnie stany USA
- Zachodnie stany USA 2
Ograniczenia wersji zapoznawczej
W tej sekcji opisano ograniczenia specyficzne dla bieżącej wersji zapoznawczej.
Ściąganie danych binarnych ze źródła danych nie jest obsługiwane.
Sesja debugowania nie jest obsługiwana.
Wprowadzenie do korzystania z Azure Portal
Azure Portal zapewnia obsługę łączników Power Query. Próbkowanie danych i odczytywanie metadanych w kontenerze powoduje, że kreator importu danych w Azure Cognitive Search może utworzyć domyślny indeks, mapować pola źródłowe na pola indeksu docelowego i załadować indeks w ramach jednej operacji. W zależności od rozmiaru i złożoności danych źródłowych można mieć operacyjny indeks wyszukiwania pełnotekstowego w ciągu kilku minut.
W poniższym filmie wideo pokazano, jak skonfigurować łącznik Power Query w Azure Cognitive Search.
Krok 1. Przygotowywanie danych źródłowych
Upewnij się, że źródło danych zawiera dane. Kreator importu danych odczytuje metadane i wykonuje próbkowanie danych w celu wywnioskowania schematu indeksu, ale także ładuje dane ze źródła danych. Jeśli brakuje danych, kreator zatrzyma i zwróci błąd.
Krok 2. Uruchamianie kreatora importowania danych
Po zatwierdzeniu wersji zapoznawczej zespół Azure Cognitive Search udostępni Ci link Azure Portal, który używa flagi funkcji, dzięki czemu będzie można uzyskać dostęp do łączników Power Query. Otwórz tę stronę i uruchom kreatora na pasku poleceń na stronie usługi Azure Cognitive Search, wybierając pozycję Importuj dane.
Krok 3. Wybieranie źródła danych
Istnieje kilka źródeł danych, z których można ściągać dane przy użyciu tej wersji zapoznawczej. Wszystkie źródła danych korzystające z Power Query będą zawierać kafelek "Powered By Power Query". Wybierz źródło danych.

Po wybraniu źródła danych wybierz pozycję Dalej: Skonfiguruj dane , aby przejść do następnej sekcji.
Krok 4. Konfigurowanie danych
W tym kroku skonfigurujesz połączenie. Każde źródło danych będzie wymagać różnych informacji. W przypadku kilku źródeł danych dokumentacja Power Query zawiera więcej szczegółowych informacji na temat nawiązywania połączenia z danymi.
Po podaniu poświadczeń połączenia wybierz pozycję Dalej.
Krok 5. Wybieranie danych
Kreator importu wyświetli podgląd różnych tabel dostępnych w źródle danych. W tym kroku sprawdzisz jedną tabelę zawierającą dane, które chcesz zaimportować do indeksu.

Po wybraniu tabeli wybierz pozycję Dalej.
Krok 6. Przekształcanie danych (opcjonalnie)
Power Query łączniki zapewniają rozbudowane środowisko interfejsu użytkownika, które umożliwia manipulowanie danymi, dzięki czemu można wysyłać odpowiednie dane do indeksu. Możesz usuwać kolumny, filtrować wiersze i wiele innych.
Nie jest wymagane przekształcenie danych przed zaimportowaniem ich do Azure Cognitive Search.
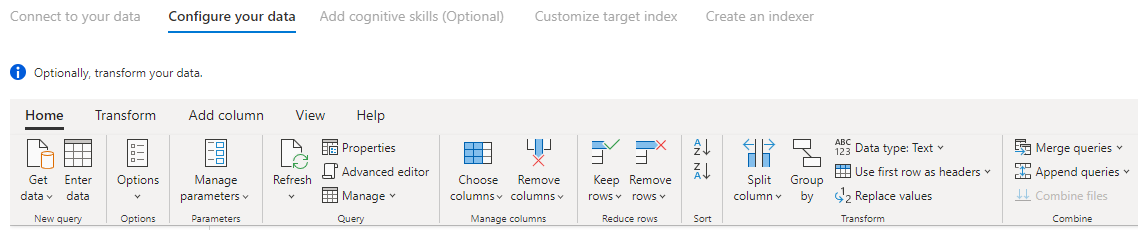
Aby uzyskać więcej informacji na temat przekształcania danych za pomocą Power Query, zobacz Using Power Query in Power BI Desktop (Używanie Power Query).
Po przekształceniu danych wybierz pozycję Dalej.
Krok 7. Dodawanie usługi Azure Blob Storage
Wersja zapoznawcza łącznika Power Query wymaga obecnie podania konta magazynu obiektów blob. Ten krok istnieje tylko w początkowej wersji zapoznawczej z bramą. To konto magazynu obiektów blob będzie służyć jako magazyn tymczasowy dla danych, które przechodzą ze źródła danych do indeksu Azure Cognitive Search.
Zalecamy udostępnienie konta magazynu pełnego dostępu parametry połączenia:
{ "connectionString" : "DefaultEndpointsProtocol=https;AccountName=<your storage account>;AccountKey=<your account key>;" }
Możesz uzyskać parametry połączenia z Azure Portal, przechodząc do bloku > Konta magazynu Klucze ustawień > (dla klasycznych kont magazynu) lub Klucze dostępu ustawień > (dla kont magazynu usługi Azure Resource Manager).
Po podaniu nazwy źródła danych i parametry połączenia wybierz pozycję "Dalej: Dodaj umiejętności poznawcze (opcjonalnie)".
Krok 8. Dodawanie umiejętności poznawczych (opcjonalnie)
Wzbogacanie sztucznej inteligencji to rozszerzenie indeksatorów, które może służyć do zwiększenia możliwości wyszukiwania zawartości.
Możesz dodać wszelkie wzbogacania, które dodają korzyść do swojego scenariusza. Po zakończeniu wybierz pozycję Dalej: Dostosuj indeks docelowy.
Krok 9. Dostosowywanie indeksu docelowego
Na stronie Indeks powinna zostać wyświetlona lista pól z typem danych i serią pól wyboru dotyczących ustawiania atrybutów indeksu. Kreator może wygenerować listę pól na podstawie metadanych i próbkować dane źródłowe.
Atrybuty można wybierać zbiorczo, zaznaczając pole wyboru w górnej części kolumny atrybutu. Wybierz pozycję Pobieranie i Możliwość wyszukiwania dla każdego pola, które powinno zostać zwrócone do aplikacji klienckiej, i z zastrzeżeniem przetwarzania wyszukiwania pełnotekstowego. Zauważysz, że liczby całkowite nie są pełnym tekstem ani wyszukiwaniem rozmytym (liczby są oceniane dosłownie i często są przydatne w filtrach).
Aby uzyskać więcej informacji, przejrzyj opis atrybutów indeksu i analizatorów języka.
Poświęć chwilę na przejrzenie wybranych opcji. Po uruchomieniu kreatora zostaną utworzone fizyczne struktury danych i nie będzie można edytować większości właściwości tych pól bez porzucania i ponownego tworzenia wszystkich obiektów.
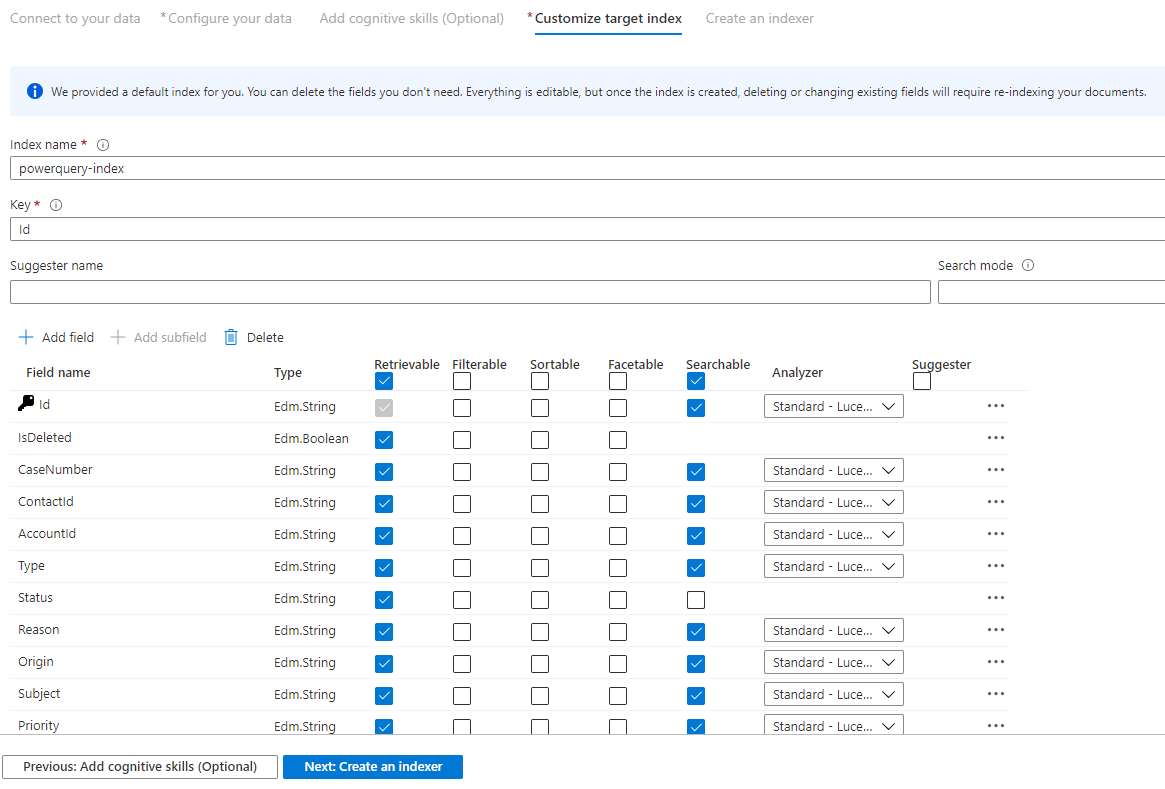
Po zakończeniu wybierz pozycję Dalej: Utwórz indeksator.
Krok 10 . Tworzenie indeksatora
Ostatni krok powoduje utworzenie indeksatora. Nazewnictwo indeksatora umożliwia jej istnienie jako zasób autonomiczny, który można zaplanować i zarządzać niezależnie od indeksu i obiektu źródła danych utworzonego w tej samej sekwencji kreatora.
Dane wyjściowe kreatora importu danych to indeksator, który przeszuka źródło danych i importuje dane wybrane do indeksu na Azure Cognitive Search.
Podczas tworzenia indeksatora możesz opcjonalnie uruchomić indeksator zgodnie z harmonogramem i dodać wykrywanie zmian. Aby dodać wykrywanie zmian, należy wyznaczyć kolumnę "wysoki znacznik wody".
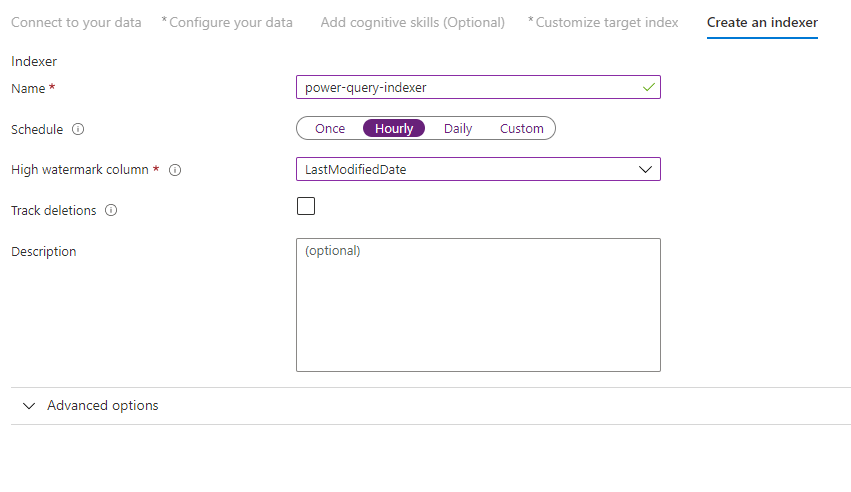
Po zakończeniu wypełniania tej strony wybierz pozycję Prześlij.
Zasady wykrywania zmian znacznika górnego znaku wodnego
Te zasady wykrywania zmian opierają się na kolumnie "znacznika górnego" przechwytywania wersji lub godziny ostatniej aktualizacji wiersza.
Wymagania
- Wszystkie wstawki określają wartość kolumny.
- Wszystkie aktualizacje elementu również zmieniają wartość kolumny.
- Wartość tej kolumny zwiększa się wraz z każdym wstawianiem lub aktualizowaniem.
Nieobsługiwane nazwy kolumn
Nazwy pól w indeksie Azure Cognitive Search muszą spełniać określone wymagania. Jednym z tych wymagań jest to, że niektóre znaki, takie jak "/", nie są dozwolone. Jeśli nazwa kolumny w bazie danych nie spełnia tych wymagań, wykrywanie schematu indeksu nie rozpozna kolumny jako prawidłowej nazwy pola i nie zobaczysz tej kolumny jako sugerowanego pola dla indeksu. Zwykle użycie mapowań pól rozwiązuje ten problem, ale mapowania pól nie są obsługiwane w portalu.
Aby indeksować zawartość z kolumny w tabeli, która ma nieobsługiwaną nazwę pola, zmień nazwę kolumny w fazie "Przekształć dane" w procesie importowania danych. Możesz na przykład zmienić nazwę kolumny o nazwie "Kod rozliczeniowy/Kod pocztowy" na "kod pocztowy". Zmieniając nazwę kolumny, wykrywanie schematu indeksu rozpozna je jako prawidłową nazwę pola i doda je jako sugestię do definicji indeksu.
Następne kroki
W tym artykule wyjaśniono, jak ściągać dane przy użyciu łączników Power Query. Ponieważ ta funkcja w wersji zapoznawczej została wycofana, wyjaśniono również, jak migrować istniejące rozwiązania do obsługiwanego scenariusza.
Aby dowiedzieć się więcej o indeksatorach, zobacz Indeksatory w Azure Cognitive Search.