Wyszukiwanie pełnotekstowe w usłudze Azure AI Search
Wyszukiwanie pełnotekstowe to metoda pobierania informacji zgodna z tekstem zwykłym przechowywanym w indeksie. Na przykład, biorąc pod uwagę ciąg zapytania "hotels in San Diego on the beach", wyszukiwarka szuka tokenizowanych ciągów na podstawie tych terminów. Aby zwiększyć wydajność skanowania, ciągi zapytań są poddawane analizie leksykalnej: wszystkie terminy małe litery, usuwanie wyrazów zatrzymania, takich jak "the" i zmniejszanie terminów do pierwotnych formularzy głównych. Po znalezieniu pasujących terminów wyszukiwarka pobiera dokumenty, klasyfikuje je w kolejności istotności i zwraca najlepsze wyniki.
Wykonywanie zapytań może być złożone. Ten artykuł jest przeznaczony dla deweloperów, którzy potrzebują dokładniejszego zrozumienia sposobu działania wyszukiwania pełnotekstowego w usłudze Azure AI Search. W przypadku zapytań tekstowych usługa Azure AI Search bezproblemowo dostarcza oczekiwane wyniki w większości scenariuszy, ale czasami możesz uzyskać wynik, który wydaje się w jakiś sposób "wyłączony". W takich sytuacjach posiadanie tła w czterech etapach wykonywania zapytania Lucene (analizowanie zapytań, analiza leksykalna, dopasowywanie dokumentów, ocenianie) może pomóc w zidentyfikowaniu określonych zmian w parametrach zapytania lub konfiguracji indeksu, które generują pożądany wynik.
Uwaga
Usługa Azure AI Search używa rozwiązania Apache Lucene do wyszukiwania pełnotekstowego, ale integracja z rozwiązaniem Lucene nie jest wyczerpująca. Selektywnie ujawniamy i rozszerzamy funkcje Lucene, aby umożliwić scenariusze ważne dla usługi Azure AI Search.
Omówienie architektury i diagram
Wykonywanie zapytania ma cztery etapy:
- Analizowanie zapytań
- Analiza leksykalna
- Pobieranie dokumentu
- Scoring (Ocenianie)
Zapytanie wyszukiwania pełnotekstowego rozpoczyna się od analizowania tekstu zapytania w celu wyodrębnienia terminów wyszukiwania i operatorów. Istnieją dwa analizatory, dzięki którym można wybrać szybkość i złożoność. Następna faza analizy polega na tym, że poszczególne terminy zapytania są czasami podzielone i ponownie tworzone w nowych formularzach. Ten krok pomaga rzutować szerszą siatkę na to, co można uznać za potencjalny mecz. Następnie wyszukiwarka skanuje indeks w celu znalezienia dokumentów ze zgodnymi terminami i ocenami każdego dopasowania. Zestaw wyników jest następnie sortowany według wyniku istotności przypisanego do każdego indywidualnego zgodnego dokumentu. Osoby w górnej części listy sklasyfikowanej są zwracane do aplikacji wywołującej.
Na poniższym diagramie przedstawiono składniki używane do przetwarzania żądania wyszukiwania.
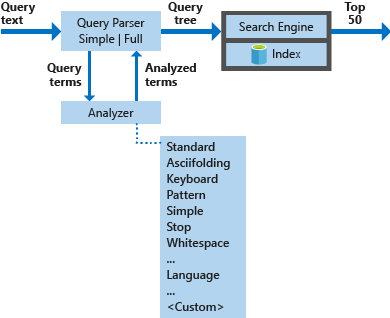
| Najważniejsze składniki | Opis funkcjonalny |
|---|---|
| Analizatory zapytań | Oddziel terminy zapytania od operatorów zapytań i utwórz strukturę zapytań (drzewo zapytań) do wysłania do aparatu wyszukiwania. |
| Analizatory | Wykonywanie analizy leksykalnej na terminach zapytania. Ten proces może obejmować przekształcanie, usuwanie lub rozszerzanie terminów zapytania. |
| Indeks | Wydajna struktura danych używana do przechowywania i organizowania terminów z możliwością wyszukiwania wyodrębnionych z indeksowanych dokumentów. |
| Wyszukiwarki | Pobiera i ocenia pasujące dokumenty na podstawie zawartości odwróconego indeksu. |
Anatomia żądania wyszukiwania
Żądanie wyszukiwania to pełna specyfikacja elementów, które powinny być zwracane w zestawie wyników. W najprostszej formie jest to puste zapytanie bez kryteriów jakiegokolwiek rodzaju. Bardziej realistyczny przykład obejmuje parametry, kilka terminów zapytania, być może zakres określonych pól, z ewentualnie wyrażeniem filtru i regułami porządkowania.
Poniższy przykład to żądanie wyszukiwania, które można wysłać do usługi Azure AI Search przy użyciu interfejsu API REST.
POST /indexes/hotels/docs/search?api-version=2020-06-30
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
W przypadku tego żądania wyszukiwarka wykonuje następujące operacje:
Znajduje dokumenty, w których cena wynosi co najmniej $60 i mniej niż $300.
Wykonuje zapytanie. W tym przykładzie zapytanie wyszukiwania składa się z fraz i terminów:
"Spacious, air-condition* +\"Ocean view\""(użytkownicy zazwyczaj nie wprowadzają interpunkcji, ale w tym w przykładzie pozwala nam wyjaśnić, jak analizatory go obsługują).W przypadku tego zapytania wyszukiwarka skanuje pola opisu i tytułu określone w obszarze "searchFields" dla dokumentów zawierających
"Ocean view", a także terminy"spacious"rozpoczynające się od prefiksu"air-condition". Parametr "searchMode" jest używany do dopasowania do dowolnego terminu (domyślnego) lub wszystkich z nich, w przypadkach, gdy termin nie jest jawnie wymagany (+).Porządkuje wynikowy zestaw hoteli w pobliżu danej lokalizacji geograficznej, a następnie zwraca wyniki do aplikacji wywołującej.
Większość tego artykułu dotyczy przetwarzania zapytania wyszukiwania: "Spacious, air-condition* +\"Ocean view\"". Filtrowanie i kolejność są poza zakresem. Aby uzyskać więcej informacji, zobacz dokumentację referencyjną interfejsu API wyszukiwania.
Etap 1. Analizowanie zapytań
Jak wspomniano, ciąg zapytania jest pierwszym wierszem żądania:
"search": "Spacious, air-condition* +\"Ocean view\"",
Analizator zapytań oddziela operatory (takie jak * i + w przykładzie) od terminów wyszukiwania i dekonstrukuje zapytanie wyszukiwania do podzapytania obsługiwanego typu:
- zapytanie dotyczące terminów dla terminów autonomicznych (na przykład przestronnych)
- zapytanie frazy dla cytowanych terminów (na przykład widok oceanu)
- zapytanie prefiksu dla terminów, po którym następuje operator
*prefiksu (na przykład klimatyzator)
Aby uzyskać pełną listę obsługiwanych typów zapytań, zobacz Składnia zapytań Lucene
Operatory skojarzone z podzapytaniem określają, czy zapytanie "musi być" lub "powinno" być spełnione, aby dokument był traktowany jako dopasowanie. Na przykład +"Ocean view" parametr "must" jest spowodowany operatorem + .
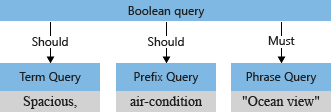
Analizator zapytań przekształca podzapytania w drzewo zapytań (wewnętrzna struktura reprezentująca zapytanie) przekazuje je do aparatu wyszukiwania. W pierwszym etapie analizowania zapytań drzewo zapytań wygląda następująco.
Obsługiwane analizatory: Proste i pełne Lucene
Usługa Azure AI Search uwidacznia dwa różne języki zapytań ( simple wartość domyślna) i full. Ustawiając parametr za queryType pomocą żądania wyszukiwania, należy poinformować analizator zapytań, który język zapytań wybierzesz, aby wiedział, jak interpretować operatory i składnię.
Język prostych zapytań jest intuicyjny i niezawodny, często odpowiedni do interpretowania danych wejściowych użytkownika bez przetwarzania po stronie klienta. Obsługuje ona operatory zapytań znane z aparatów wyszukiwania w Sieci Web.
Język zapytań Full Lucene, który można uzyskać, ustawiając
queryType=full, rozszerza domyślny prosty język zapytań, dodając obsługę większej liczby operatorów i typów zapytań, takich jak symbol wieloznaczny, rozmyty, regex i zapytania w zakresie pól. Na przykład wyrażenie regularne wysyłane w składni prostego zapytania będzie interpretowane jako ciąg zapytania, a nie wyrażenie. Przykładowe żądanie w tym artykule używa języka zapytań Full Lucene.
Wpływ funkcji searchMode na analizator
Innym parametrem żądania wyszukiwania, który ma wpływ na analizowanie, jest parametr "searchMode". Steruje on operatorem domyślnym dla zapytań logicznych: dowolny (domyślny) lub wszystkie.
Gdy parametr "searchMode=any", który jest domyślnym ogranicznikiem przestrzeni między przestronnym a klimatyzatorem jest OR (||), co powoduje, że przykładowy tekst zapytania jest odpowiednikiem:
Spacious,||air-condition*+"Ocean view"
Jawne operatory, takie jak + w +"Ocean view"pliku , są jednoznaczne w konstrukcji zapytania logicznego (termin musi być zgodny). Mniej oczywiste jest, jak interpretować pozostałe terminy: przestronny i klimatyzujący. Czy wyszukiwarka powinna znaleźć dopasowania w widoku oceanu i przestronnym i klimatyznym? A może znaleźć widok oceanu plus jeden z pozostałych terminów?
Domyślnie ("searchMode=any"), wyszukiwarka przyjmuje szerszą interpretację. Należy dopasować pole, odzwierciedlając semantykę "lub". Początkowe drzewo zapytań zilustrowane wcześniej z dwiema operacjami "powinna" pokazuje wartość domyślną.
Załóżmy, że teraz ustawiliśmy wartość "searchMode=all". W tym przypadku spacja jest interpretowana jako operacja "i". Każdy z pozostałych warunków musi być obecny w dokumencie, aby zakwalifikować się jako dopasowanie. Wynikowe przykładowe zapytanie zostanie zinterpretowane w następujący sposób:
+Spacious,+air-condition*+"Ocean view"
Zmodyfikowane drzewo zapytań dla tego zapytania byłoby następujące, gdzie pasujący dokument jest przecięciem wszystkich trzech podzapytania:

Uwaga
Wybranie opcji "searchMode=any" nad ciągiem "searchMode=all" to decyzja najlepiej podjęta przez uruchomienie reprezentatywnych zapytań. Użytkownicy, którzy mogą zawierać operatory (typowe podczas przeszukiwania magazynów dokumentów), mogą znaleźć wyniki bardziej intuicyjne, jeśli "searchMode=all" informuje konstrukcje zapytań logicznych. Aby uzyskać więcej informacji na temat współdziałania między operatorami "searchMode" i operatorami, zobacz Simple query syntax (Prosta składnia zapytań).
Etap 2. Analiza leksykalna
Analizatory leksykalne przetwarzają zapytania terminów i zapytania fraz po ustrukturyzowanym drzewie zapytań . Analizator akceptuje dane wejściowe tekstu podane przez analizator, przetwarza tekst, a następnie wysyła tokenizowane terminy do uwzględnienia w drzewie zapytań.
Najczęstszą formą analizy leksykalnej jest *analiza lingwistyczna, która przekształca terminy zapytania na podstawie reguł specyficznych dla danego języka:
- Zmniejszenie terminu zapytania do formy głównej wyrazu
- Usuwanie nieistotnych słów (stopwords, takich jak "the" lub "and" w języku angielskim)
- Dzielenie wyrazu złożonego na części składników
- Małe litery wielkie litery wyrazu
Wszystkie te operacje mają tendencję do wymazania różnic między wprowadzaniem tekstu dostarczonym przez użytkownika a terminami przechowywanymi w indeksie. Takie operacje wykraczają poza przetwarzanie tekstu i wymagają dogłębnej wiedzy na temat samego języka. Aby dodać tę warstwę świadomości językowej, usługa Azure AI Search obsługuje długą listę analizatorów języków zarówno z firmy Lucene, jak i firmy Microsoft.
Uwaga
Wymagania dotyczące analizy mogą wahać się od minimalnych do skomplikowanych w zależności od scenariusza. Złożoność analizy leksykalnej można kontrolować, wybierając jeden ze wstępnie zdefiniowanych analizatorów lub tworząc własny analizator niestandardowy. Analizatory są ograniczone do pól z możliwością wyszukiwania i są określane jako część definicji pola. Umożliwia to różnice w analizie leksykalnej dla poszczególnych pól. Nieokreślone, używany jest standardowy analizator Lucene.
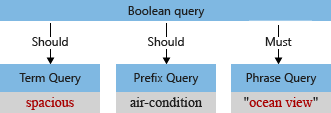
W naszym przykładzie przed analizą początkowe drzewo zapytań zawiera termin "Przestronny", z wielkimi literami "S" i przecinkiem, który analizator zapytań interpretuje jako część terminu zapytania (przecinek nie jest uważany za operator języka zapytań).
Gdy domyślny analizator przetwarza termin, będzie zawierać małe litery "widok oceanu" i "przestronny" i usunąć znak przecinka. Zmodyfikowane drzewo zapytań wygląda następująco:
Zachowania analizatora testowania
Zachowanie analizatora można przetestować przy użyciu interfejsu API analizowania. Podaj tekst, który chcesz przeanalizować, aby zobaczyć, jakie terminy są generowane przez dany analizator. Aby na przykład zobaczyć, jak standardowy analizator przetworzy tekst "klimatyzator", możesz wydać następujące żądanie:
{
"text": "air-condition",
"analyzer": "standard"
}
Analizator standardowy dzieli tekst wejściowy na następujące dwa tokeny, dodając do nich adnotacje z atrybutami takimi jak przesunięcia początkowe i końcowe (używane do wyróżniania trafień), a także ich pozycja (używana do dopasowywania fraz):
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
Wyjątki od analizy leksykalnej
Analiza leksykalna ma zastosowanie tylko do typów zapytań, które wymagają pełnych terminów — zapytania terminowego lub zapytania frazy. Nie ma zastosowania do typów zapytań z niepełnymi terminami — zapytanie prefiksem, zapytanie wieloznaczne, kwerenda regex lub kwerenda rozmyte. Te typy zapytań, w tym zapytanie prefiksu z terminem air-condition* w naszym przykładzie, są dodawane bezpośrednio do drzewa zapytań, pomijając etap analizy. Jedyną transformacją wykonywaną na warunkach zapytania tych typów jest małe litery.
Etap 3. Pobieranie dokumentu
Pobieranie dokumentu odnosi się do znajdowania dokumentów ze zgodnymi terminami w indeksie. Ten etap najlepiej rozumie się za pomocą przykładu. Zacznijmy od indeksu hoteli o następującym prostym schemacie:
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
Ponadto przyjęto założenie, że ten indeks zawiera następujące cztery dokumenty:
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
Jak są indeksowane terminy
Aby zrozumieć pobieranie, warto zapoznać się z kilkoma podstawowymi informacjami na temat indeksowania. Jednostka magazynu jest odwróconym indeksem, po jednym dla każdego pola z możliwością wyszukiwania. W indeksie odwróconym jest posortowana lista wszystkich terminów ze wszystkich dokumentów. Każdy termin jest mapowana na listę dokumentów, w których występuje, jak widać w poniższym przykładzie.
Aby utworzyć terminy w indeksie odwróconym, wyszukiwarka wykonuje analizę leksykalną nad zawartością dokumentów, podobnie jak w przypadku przetwarzania zapytań:
- Dane wejściowe tekstu są przekazywane do analizatora, małych liter, pozbawionych znaków interpunkcyjnych i tak dalej, w zależności od konfiguracji analizatora.
- Tokeny to dane wyjściowe analizy leksykalnej .
- Terminy są dodawane do indeksu.
Często zdarza się, ale nie jest to wymagane, aby używać tych samych analizatorów do operacji wyszukiwania i indeksowania, aby terminy zapytania wyglądały bardziej jak terminy wewnątrz indeksu.
Uwaga
Usługa Azure AI Search umożliwia określenie różnych analizatorów do indeksowania i wyszukiwania za pomocą dodatkowych indexAnalyzer parametrów i searchAnalyzer pól. Jeśli nie określono, analizator ustawiony z właściwością analyzer jest używany zarówno do indeksowania, jak i wyszukiwania.
Odwrócony indeks dla przykładowych dokumentów
Wracając do naszego przykładu , w polu tytułu odwrócony indeks wygląda następująco:
| Termin | Lista dokumentów |
|---|---|
| Atman | 1 |
| Beach | 2 |
| Hotel | 1, 3 |
| Ocean | 100 |
| Playa | 3 |
| Resort | 3 |
| Retreat | 100 |
W polu tytułu tylko hotel jest wyświetlany w dwóch dokumentach: 1, 3.
W polu opisu indeks jest następujący:
| Termin | Lista dokumentów |
|---|---|
| Powietrza | 3 |
| oraz | 100 |
| Beach | 1 |
| Uwarunkowane | 3 |
| Komfortowe | 3 |
| odległość | 1 |
| island | 2 |
| kaua cortani | 2 |
| Znajdujące się | 2 |
| north | 2 |
| Ocean | 1, 2, 3 |
| of | 2 |
| on | 2 |
| cichy | 100 |
| Pokoje | 1, 3 |
| Zaciszne | 100 |
| Brzegu | 2 |
| Przestronne | 1 |
| względem zasobu | 1, 2 |
| na wartość | 1 |
| wyświetl | 1, 2, 3 |
| Chodzenie | 1 |
| with | 3 |
Dopasowywanie terminów zapytania względem indeksowanych terminów
Biorąc pod uwagę odwrócone indeksy powyżej, wróćmy do przykładowego zapytania i zobaczmy, jak pasujące dokumenty znajdują się w naszym przykładowym zapytaniu. Przypomnij sobie, że końcowe drzewo zapytań wygląda następująco:
Podczas wykonywania zapytania poszczególne zapytania są wykonywane niezależnie względem pól z możliwością wyszukiwania.
TermQuery, "przestronny", pasuje do dokumentu 1 (Hotel Atman).
PrefiksQuery "air-condition*" nie pasuje do żadnych dokumentów.
Jest to zachowanie, które czasami mylą deweloperów. Mimo że termin klimatyzowany istnieje w dokumencie, jest on podzielony na dwa terminy domyślnie analizatora. Pamiętaj, że zapytania prefiksów, które zawierają częściowe terminy, nie są analizowane. W związku z tym terminy z prefiksem "klimatyzator" są sprawdzane w odwróconym indeksie i nie można go odnaleźć.
WyrażenieQuery, "widok oceanu", wyszukuje terminy "ocean" i "view" i sprawdza bliskość terminów w oryginalnym dokumencie. Dokumenty 1, 2 i 3 pasują do tego zapytania w polu opisu. Zwróć uwagę, że dokument 4 zawiera termin ocean w tytule, ale nie jest uważany za dopasowanie, ponieważ szukamy frazy "widok oceanu", a nie pojedynczych słów.
Uwaga
Zapytanie wyszukiwania jest wykonywane niezależnie względem wszystkich pól z możliwością wyszukiwania w indeksie usługi Azure AI Search, chyba że ograniczysz pola ustawione za pomocą parametru searchFields , jak pokazano w przykładowym żądaniu wyszukiwania. Zwracane są dokumenty zgodne z dowolnymi wybranymi polami.
W całości dla danego zapytania dokumenty pasują do 1, 2, 3.
Etap 4. Ocenianie
Każdy dokument w zestawie wyników wyszukiwania ma przypisany wynik istotności. Funkcja oceny istotności polega na wyższej klasyfikacji tych dokumentów, które najlepiej odpowiadają na pytanie użytkownika wyrażone przez zapytanie wyszukiwania. Wynik jest obliczany na podstawie właściwości statystycznych terminów, które są zgodne. W rdzeniu formuły oceniania jest tf/IDF (częstotliwość odwrotna częstotliwości dokumentu). W zapytaniach zawierających rzadkie i typowe terminy tf/IDF promuje wyniki zawierające rzadki termin. Na przykład w hipotetycznym indeksie ze wszystkimi artykułami Wikipedii, z dokumentów pasujących do zapytania prezydenta, dokumenty pasujące do prezydenta są uważane za bardziej istotne niż dokumenty pasujące do elementu .
Przykład oceniania
Przypomnij sobie trzy dokumenty pasujące do naszego przykładowego zapytania:
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
Dokument 1 najlepiej dopasował zapytanie, ponieważ w polu opisu występuje zarówno termin przestronny, jak i wymagany widok oceanu frazy. Dwa następne dokumenty pasują tylko do widoku oceanu frazy. Może być zaskakujące, że wynik istotności dokumentu 2 i 3 jest inny, mimo że pasuje do zapytania w taki sam sposób. Wynika to z faktu, że formuła oceniania ma więcej składników niż tylko tf/IDF. W tym przypadku do dokumentu 3 przypisano nieco wyższy wynik, ponieważ jego opis jest krótszy. Dowiedz się więcej o praktycznej formule oceniania Lucene, aby zrozumieć, jak długość pola i inne czynniki mogą wpływać na ocenę istotności.
Niektóre typy zapytań (symbol wieloznaczny, prefiks, regex) zawsze współtworzyją stały wynik ogólnej oceny dokumentu. Umożliwia to uwzględnianie dopasowań za pomocą rozszerzenia zapytania w wynikach, ale bez wpływu na klasyfikację.
Przykład ilustruje, dlaczego ma to znaczenie. Wyszukiwania symboli wieloznacznych, w tym wyszukiwania prefiksów, są niejednoznaczne według definicji, ponieważ dane wejściowe są ciągiem częściowym z potencjalnymi dopasowaniami w bardzo dużej liczbie różnych terminów (należy wziąć pod uwagę dane wejściowe "tour*", z dopasowaniami znalezionymi w "tours", "tourettes" i "tourmaline"). Biorąc pod uwagę charakter tych wyników, nie ma sposobu, aby rozsądnie wywnioskować, które terminy są cenniejsze niż inne. Z tego powodu ignorujemy częstotliwości terminów podczas oceniania wyników w zapytaniach z symbolami wieloznacznymi, prefiksem i wyrażeniem regularnym. W wieloczęściowym żądaniu wyszukiwania zawierającym częściowe i kompletne terminy wyniki z częściowych danych wejściowych są uwzględniane ze stałą oceną, aby uniknąć stronniczności w kierunku potencjalnie nieoczekiwanych dopasowań.
Dostrajanie trafności
Istnieją dwa sposoby dostosowywania wyników istotności w usłudze Azure AI Search:
Profile oceniania promują dokumenty na liście sklasyfikowanych wyników na podstawie zestawu reguł. W naszym przykładzie możemy rozważyć dokumenty pasujące do pola tytułu bardziej istotne niż dokumenty pasujące do pola opisu. Ponadto, jeśli nasz indeks miał pole cenowe dla każdego hotelu, możemy promować dokumenty o niższej cenie. Dowiedz się więcej o dodawaniu profilów oceniania do indeksu wyszukiwania.
Zwiększenie terminu (dostępne tylko w składni pełnej kwerendy Lucene) udostępnia operator
^zwiększający, który można zastosować do dowolnej części drzewa zapytań. W naszym przykładzie zamiast wyszukiwać prefiks klimatyzator*, można wyszukać dokładny termin klimatyzatora lub prefiks, ale dokumenty pasujące do dokładnego terminu są klasyfikowane wyżej, stosując zwiększenie do terminu zapytanie: klimatyzator^2||klimatyzator*. Dowiedz się więcej na temat zwiększania terminów w zapytaniu.
Ocenianie w indeksie rozproszonym
Wszystkie indeksy w usłudze Azure AI Search są automatycznie podzielone na wiele fragmentów, co pozwala nam szybko dystrybuować indeks między wiele węzłów podczas skalowania usługi w górę lub w dół. Po wydaniu żądania wyszukiwania jest wystawiane względem każdego fragmentu niezależnie. Wyniki z każdego fragmentu są następnie scalane i uporządkowane według wyniku (jeśli nie zdefiniowano żadnej innej kolejności). Ważne jest, aby wiedzieć, że funkcja oceniania waży częstotliwość terminu zapytania względem odwrotnej częstotliwości dokumentów we wszystkich dokumentach w obrębie fragmentu, a nie we wszystkich fragmentach!
Oznacza to, że ocena istotności może być inna w przypadku identycznych dokumentów, jeśli znajdują się na różnych fragmentach. Na szczęście takie różnice zwykle znikają, ponieważ liczba dokumentów w indeksie rośnie z powodu bardziej równomiernego rozkładu terminów. Nie można założyć, na którym fragment zostanie umieszczony dowolny dany dokument. Jednak przy założeniu, że klucz dokumentu nie ulegnie zmianie, zawsze zostanie przypisany do tego samego fragmentu.
Ogólnie rzecz biorąc, ocena dokumentu nie jest najlepszym atrybutem do zamawiania dokumentów, jeśli stabilność kolejności jest ważna. Na przykład, biorąc pod uwagę dwa dokumenty o identycznym wyniku, nie ma gwarancji, że jeden z nich pojawia się jako pierwszy w kolejnych uruchomieniach tego samego zapytania. Wynik dokumentu powinien mieć ogólne poczucie istotności dokumentu względem innych dokumentów w zestawie wyników.
Podsumowanie
Sukces komercyjnych wyszukiwarek wzbudził oczekiwania dotyczące pełnotekstowego wyszukiwania danych prywatnych. W przypadku niemal każdego rodzaju środowiska wyszukiwania oczekujemy, że aparat zrozumie naszą intencję, nawet jeśli terminy są błędnie napisane lub niekompletne. Możemy nawet oczekiwać dopasowań na podstawie niemal równoważnych terminów lub synonimów, których nigdy nie określiliśmy.
Z punktu widzenia technicznego wyszukiwanie pełnotekstowe jest wysoce złożone, wymagające zaawansowanej analizy językowej i systematycznego podejścia do przetwarzania w sposób destylowania, rozszerzania i przekształcania terminów zapytania w celu dostarczenia odpowiedniego wyniku. Biorąc pod uwagę nieodłączne złożoność, istnieje wiele czynników, które mogą mieć wpływ na wynik zapytania. Z tego powodu inwestowanie czasu, aby zrozumieć mechanikę wyszukiwania pełnotekstowego, oferuje namacalne korzyści podczas próby pracy z nieoczekiwanymi wynikami.
W tym artykule omówiono wyszukiwanie pełnotekstowe w kontekście usługi Azure AI Search. Mamy nadzieję, że zapewnia wystarczające doświadczenie do rozpoznawania potencjalnych przyczyn i rozwiązań dotyczących rozwiązywania typowych problemów z zapytaniami.
Następne kroki
Skompiluj przykładowy indeks, wypróbuj różne zapytania i przejrzyj wyniki. Aby uzyskać instrukcje, zobacz Kompilowanie i wykonywanie zapytań dotyczących indeksu w portalu.
Wypróbuj inną składnię zapytania z sekcji Przykładowe dokumenty wyszukiwania lub składnia prostego zapytania w Eksploratorze wyszukiwania w portalu.
Przejrzyj profile oceniania, jeśli chcesz dostosować klasyfikację w aplikacji wyszukiwania.
Dowiedz się, jak stosować analizatory leksykalne specyficzne dla języka.
Skonfiguruj analizatory niestandardowe pod kątem minimalnego przetwarzania lub wyspecjalizowanego przetwarzania w określonych polach.