Fragmentowanie dużych dokumentów dla rozwiązań wyszukiwania wektorów w usłudze Azure AI Search
Partycjonowanie dużych dokumentów na mniejsze fragmenty może pomóc w utrzymaniu maksymalnego limitu danych wejściowych tokenu w modelach osadzania. Na przykład maksymalna długość tekstu wejściowego dla modeli osadzania usługi Azure OpenAI wynosi 8191 tokenów. Biorąc pod uwagę, że każdy token zawiera około czterech znaków tekstu dla typowych modeli OpenAI, ten maksymalny limit odpowiada około 6000 wyrazom tekstu. Jeśli używasz tych modeli do generowania osadzania, ważne jest, aby tekst wejściowy pozostał w limicie. Partycjonowanie zawartości na fragmenty gwarantuje, że dane mogą być przetwarzane przez modele osadzania używane do wypełniania magazynów wektorów i konwersji zapytań tekst-wektor.
W tym artykule opisano kilka metod fragmentowania danych. Fragmentowanie jest wymagane tylko wtedy, gdy dokumenty źródłowe są zbyt duże dla maksymalnego rozmiaru danych wejściowych narzuconego przez modele.
Uwaga
Jeśli używasz ogólnie dostępnej wersji wyszukiwania wektorowego, fragmentowanie i osadzanie danych wymaga kodu zewnętrznego, takiego jak biblioteka lub umiejętność niestandardowa. Nowa funkcja o nazwie wektoryzacja zintegrowana, obecnie w wersji zapoznawczej, oferuje wewnętrzne fragmentowanie i osadzanie danych. Zintegrowana wektoryzacja ma zależność od indeksatorów, zestawów umiejętności, umiejętności podziału tekstu i umiejętności AzureOpenAiEmbedding (lub umiejętności niestandardowej). Jeśli nie możesz używać funkcji w wersji zapoznawczej, przykłady w tym artykule zawierają alternatywną ścieżkę do przodu.
Typowe techniki fragmentowania
Poniżej przedstawiono niektóre typowe techniki fragmentowania, począwszy od najczęściej używanej metody:
Fragmenty o stałym rozmiarze: zdefiniuj stały rozmiar, który jest wystarczający dla semantycznie znaczących akapitów (na przykład 200 wyrazów) i umożliwia nakładanie się (na przykład 10–15% zawartości) może generować dobre fragmenty jako dane wejściowe do osadzania generatorów wektorów.
Fragmenty o zmiennym rozmiarze oparte na zawartości: partycjonuj dane na podstawie cech zawartości, takich jak znaki interpunkcyjne końca zdania, znaczniki końca wiersza lub używanie funkcji w bibliotekach przetwarzania języka naturalnego (NLP). Struktura języka Markdown może również służyć do dzielenia danych.
Dostosuj lub iteruj jedną z powyższych technik. Na przykład podczas pracy z dużymi dokumentami można użyć fragmentów o zmiennym rozmiarze, ale także dołączyć tytuł dokumentu do fragmentów z środka dokumentu, aby zapobiec utracie kontekstu.
Zagadnienia dotyczące nakładania się zawartości
W przypadku fragmentowania danych nakładanie się niewielkiej ilości tekstu między fragmentami może pomóc zachować kontekst. Zalecamy rozpoczęcie od nakładania się około 10%. Na przykład, biorąc pod uwagę stały rozmiar fragmentu 256 tokenów, można rozpocząć testowanie z nakładającymi się na siebie 25 tokenami. Rzeczywista ilość nakładających się danych różni się w zależności od typu danych i konkretnego przypadku użycia, ale ustaliliśmy, że 10–15% działa w wielu scenariuszach.
Czynniki dotyczące danych fragmentowania
Jeśli chodzi o fragmentowanie danych, zastanów się nad następującymi czynnikami:
Kształt i gęstość dokumentów. Jeśli potrzebujesz nienaruszonego tekstu lub fragmentów, większe fragmenty i fragmenty zmiennych, które zachowują strukturę zdań, mogą uzyskać lepsze wyniki.
Zapytania użytkowników: większe fragmenty i nakładające się strategie pomagają zachować kontekst i semantyczny bogactwo zapytań przeznaczonych dla określonych informacji.
Duże modele językowe (LLM) mają wytyczne dotyczące wydajności dotyczące rozmiaru fragmentu. Musisz ustawić rozmiar fragmentu, który działa najlepiej dla wszystkich używanych modeli. Jeśli na przykład używasz modeli do podsumowania i osadzania, wybierz optymalny rozmiar fragmentu, który działa dla obu tych elementów.
Jak fragmentowanie pasuje do przepływu pracy
Jeśli masz duże dokumenty, musisz wstawić krok fragmentowania do indeksowania i przepływów pracy zapytań, które dzielą duży tekst. W przypadku korzystania ze zintegrowanej wektoryzacji (wersja zapoznawcza) jest stosowana domyślna strategia fragmentowania przy użyciu umiejętności dzielenia tekstu. Możesz również zastosować niestandardową strategię fragmentowania przy użyciu niestandardowych umiejętności. Niektóre biblioteki, które zapewniają fragmentowanie, obejmują:
Większość bibliotek udostępnia typowe techniki fragmentowania dla stałego rozmiaru, zmiennego rozmiaru lub kombinacji. Można również określić nakładanie się, które duplikuje niewielką ilość zawartości w każdym fragmentie na potrzeby zachowywania kontekstu.
Przykłady fragmentowania
W poniższych przykładach pokazano, w jaki sposób strategie fragmentowania są stosowane do pliku PDF z książki e-book nasa:
Przykład umiejętności dzielenia tekstu
Zintegrowana fragmentowanie danych za pośrednictwem umiejętności dzielenia tekstu jest dostępna w publicznej wersji zapoznawczej. W tym scenariuszu użyj interfejsu API REST w wersji zapoznawczej lub pakietu beta zestawu Azure SDK.
W tej sekcji opisano wbudowane fragmentowanie danych przy użyciu podejścia opartego na umiejętnościach i parametrów umiejętności podziału tekstu.
Przykładowy notes dla tego przykładu można znaleźć w repozytorium azure-search-vector-samples .
Ustaw textSplitMode podział zawartości na mniejsze fragmenty:
pages(wartość domyślna). Fragmenty składają się z wielu zdań.sentences. Fragmenty składają się z pojedynczych zdań. To, co stanowi "zdanie", jest zależne od języka. W języku angielskim używane jest standardowe zdanie kończące znaki interpunkcyjne, takie jak.lub!. Język jest kontrolowanydefaultLanguageCodeprzez parametr .
Parametr pages dodaje dodatkowe parametry:
maximumPageLengthdefiniuje maksymalną liczbę znaków 1 w każdym kawałku. Rozdzielacz tekstu unika dzielenia zdań, więc rzeczywista liczba znaków zależy od zawartości.pageOverlapLengthokreśla, ile znaków od końca poprzedniej strony jest uwzględnionych na początku następnej strony. W przypadku ustawienia ta wartość musi być mniejsza niż połowa maksymalnej długości strony.maximumPagesToTakedefiniuje liczbę stron/fragmentów do przejęcia z dokumentu. Wartość domyślna to 0, co oznacza pobranie wszystkich stron lub fragmentów z dokumentu.
1 Znaki nie są wyrównane do definicji tokenu. Liczba tokenów mierzonych przez llM może być inna niż rozmiar znaku mierzony przez umiejętności dzielenia tekstu.
W poniższej tabeli pokazano, jak wybór parametrów wpływa na łączną liczbę fragmentów z książki e-book Ziemi w nocy:
textSplitMode |
maximumPageLength |
pageOverlapLength |
Łączna liczba fragmentów |
|---|---|---|---|
pages |
1000 | 0 | 172 |
pages |
1000 | 200 | 216 |
pages |
2000 | 0 | 85 |
pages |
2000 | 500 | 113 |
pages |
5000 | 0 | 34 |
pages |
5000 | 500 | 38 |
sentences |
Brak | Brak | 13361 |
textSplitModepages Użycie wyników w większości fragmentów o łącznej liczbie znaków zbliżonych do maximumPageLength. Liczba znaków fragmentów różni się ze względu na różnice w tym, gdzie granice zdań mieszczą się wewnątrz fragmentu. Długość tokenu fragmentu różni się ze względu na różnice w zawartości fragmentu.
Następujące histogramy pokazują, w jaki sposób rozkład długości znaków fragmentu porównuje się z długością tokenu fragmentu dla gpt-35-turbo w przypadku używania pagestextSplitMode elementu z wartości maximumPageLength 2000 i pageOverlapLength 500 na Ziemi w nocnym e-booku:
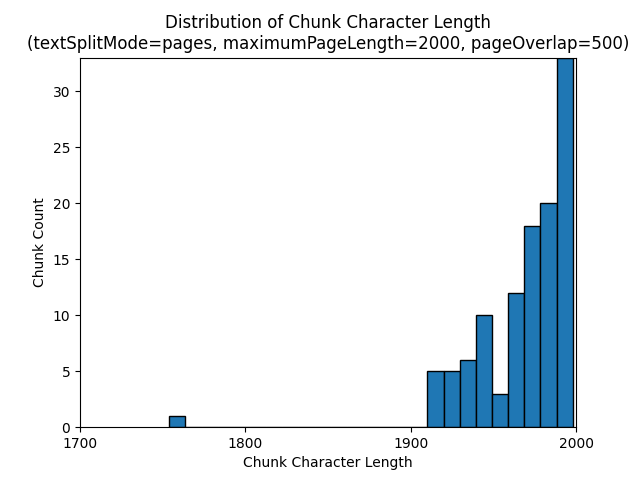
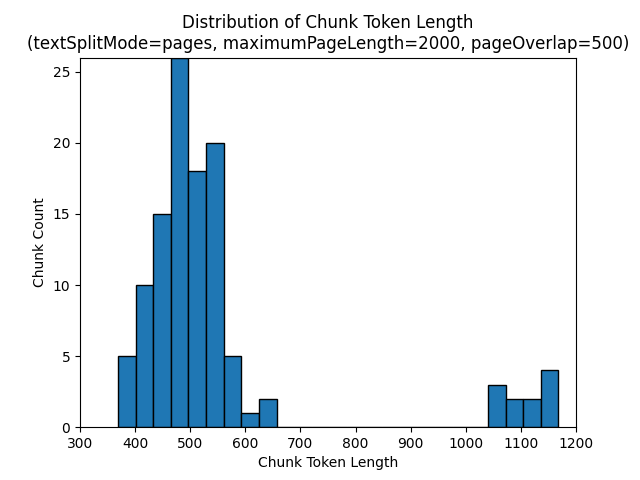
Użycie wyniku textSplitModesentences w dużej liczbie fragmentów składających się z pojedynczych zdań. Te fragmenty są znacznie mniejsze niż te generowane przez pageselement , a liczba fragmentów jest bardziej zgodna z liczbą znaków.
Następujące histogramy pokazują, w jaki sposób rozkład długości znaków fragmentu porównuje się z długością tokenu fragmentu dla gpt-35-turbo podczas korzystania z textSplitModesentences elementu na Ziemi w nocnym e-booku:
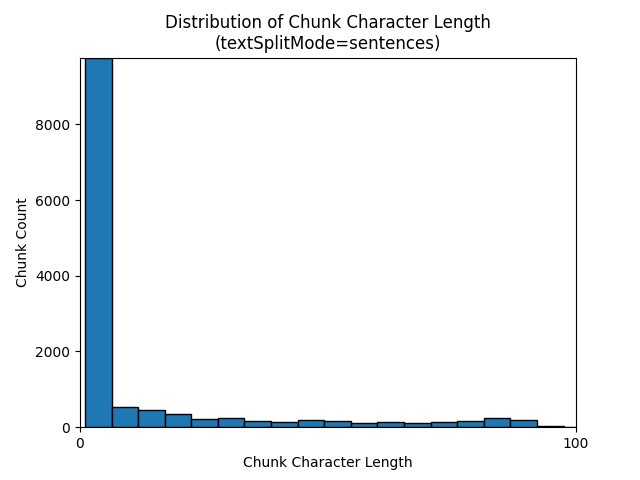
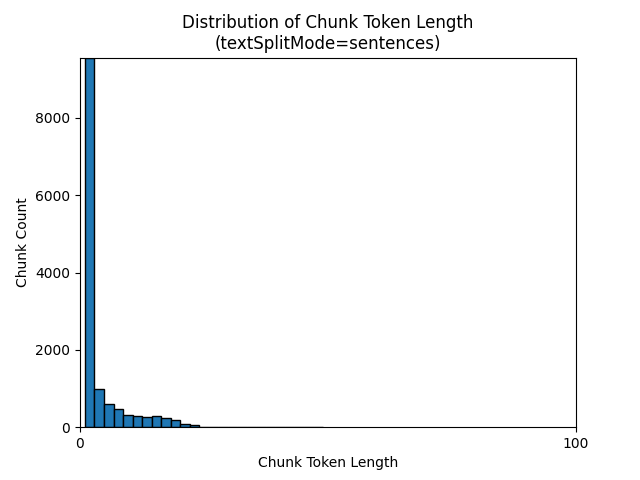
Optymalny wybór parametrów zależy od sposobu użycia fragmentów. W przypadku większości aplikacji zaleca się rozpoczęcie od następujących parametrów domyślnych:
textSplitMode |
maximumPageLength |
pageOverlapLength |
|---|---|---|
pages |
2000 | 500 |
Przykład fragmentowania danych langchain
Usługa LangChain udostępnia moduły ładuwcze dokumentów i rozdzielacze tekstu. W tym przykładzie pokazano, jak załadować plik PDF, pobrać liczby tokenów i skonfigurować rozdzielacz tekstu. Uzyskiwanie liczby tokenów pomaga podjąć świadomą decyzję o określaniu rozmiaru fragmentów.
Przykładowy notes dla tego przykładu można znaleźć w repozytorium azure-search-vector-samples .
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/earth_at_night_508.pdf")
pages = loader.load()
print(len(pages))
Dane wyjściowe wskazują 200 dokumentów lub stron w pliku PDF.
Aby uzyskać szacowaną liczbę tokenów dla tych stron, użyj tokenu TikToken.
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
tiktoken.encoding_for_model('gpt-3.5-turbo')
# create the length function
token_counts = []
for page in pages:
token_counts.append(tiktoken_len(page.page_content))
min_token_count = min(token_counts)
avg_token_count = int(sum(token_counts) / len(token_counts))
max_token_count = max(token_counts)
# print token counts
print(f"Min: {min_token_count}")
print(f"Avg: {avg_token_count}")
print(f"Max: {max_token_count}")
Dane wyjściowe wskazują, że żadne strony nie mają tokenów zerowych, średnia długość tokenu na stronę wynosi 189 tokenów, a maksymalna liczba tokenów dowolnej strony wynosi 1583.
Znajomość średniego i maksymalnego rozmiaru tokenu zapewnia wgląd w ustawianie rozmiaru fragmentu. Chociaż można użyć standardowej rekomendacji 2000 znaków z nakładającymi się 500 znakami, w tym przypadku warto przejść do niższej liczby tokenów przykładowego dokumentu. W rzeczywistości ustawienie nakładającej się wartości, która jest zbyt duża, może spowodować, że w ogóle nie pojawią się nakładające się wartości.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split documents into text and embeddings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_documents(pages)
print(chunks[20])
print(chunks[21])
Dane wyjściowe dla dwóch kolejnych fragmentów pokazują tekst z pierwszego fragmentu nakładających się na drugi fragment. Dane wyjściowe są lekko edytowane w celu zapewnienia czytelności.
'x Earth at NightForeword\nNASA’s Earth at Night explores the brilliance of our planet when it is in darkness. \n It is a compilation of stories depicting the interactions between science and \nwonder, and I am pleased to share this visually stunning and captivating exploration of \nour home planet.\nFrom space, our Earth looks tranquil. The blue ethereal vastness of the oceans \nharmoniously shares the space with verdant green land—an undercurrent of gentle-ness and solitude. But spending time gazing at the images presented in this book, our home planet at night instantly reveals a different reality. Beautiful, filled with glow-ing communities, natural wonders, and striking illumination, our world is bustling with activity and life.**\nDarkness is not void of illumination. It is the contrast, the area between light and'** metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
'**Darkness is not void of illumination. It is the contrast, the area between light and **\ndark, that is often the most illustrative. Darkness reminds me of where I came from and where I am now—from a small town in the mountains, to the unique vantage point of the Nation’s capital. Darkness is where dreamers and learners of all ages peer into the universe and think of questions about themselves and their space in the cosmos. Light is where they work, where they gather, and take time together.\nNASA’s spacefaring satellites have compiled an unprecedented record of our \nEarth, and its luminescence in darkness, to captivate and spark curiosity. These missions see the contrast between dark and light through the lenses of scientific instruments. Our home planet is full of complex and dynamic cycles and processes. These soaring observers show us new ways to discern the nuances of light created by natural and human-made sources, such as auroras, wildfires, cities, phytoplankton, and volcanoes.' metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
Umiejętność niestandardowa
Przykładowy fragment o stałym rozmiarze i osadzanie generowania przedstawia zarówno fragmentowanie, jak i generowanie osadzania wektorów przy użyciu modeli osadzania w usłudze Azure OpenAI . W tym przykładzie użyto niestandardowej umiejętności usługi Azure AI Search w repozytorium Umiejętności zasilania w celu opakowania kroku fragmentowania.