Tworzenie magazynu wektorów
W usłudze Azure AI Search magazyn wektorów ma schemat indeksu, który definiuje pola wektorów i niewektorów, konfigurację wektorów dla algorytmów tworzących miejsce osadzania i ustawienia definicji pól wektorów używanych w żądaniach zapytań. Interfejs API tworzenia indeksu tworzy magazyn wektorów.
Wykonaj następujące kroki, aby indeksować dane wektorów:
- Definiowanie schematu z co najmniej jedną konfiguracją wektorów, która określa algorytmy indeksowania i wyszukiwania
- Dodawanie co najmniej jednego pola wektora
- Załaduj wstępnie wektoryzowane dane jako oddzielny krok lub użyj zintegrowanej wektoryzacji (wersja zapoznawcza) na potrzeby fragmentowania i kodowania danych podczas indeksowania.
Ten artykuł dotyczy ogólnie dostępnej wersji wyszukiwania wektorów, która zakłada, że kod aplikacji wywołuje zasoby zewnętrzne na potrzeby fragmentowania i kodowania.
Uwaga
Szukasz wskazówek dotyczących migracji z wersji 2023-07-01-preview? Zobacz Uaktualnianie interfejsów API REST.
Wymagania wstępne
Usługa Azure AI Search w dowolnym regionie i w dowolnej warstwie. Większość istniejących usług obsługuje wyszukiwanie wektorów. W przypadku usług utworzonych przed styczniem 2019 r. istnieje mały podzbiór, który nie może obsługiwać wyszukiwania wektorowego. Jeśli nie można utworzyć lub zaktualizować indeksu zawierającego pola wektorowe, jest to wskaźnik. W takiej sytuacji należy utworzyć nową usługę.
Wstępnie istniejące wektory osadzania w dokumentach źródłowych. Usługa Azure AI Search nie generuje wektorów w ogólnie dostępnej wersji zestawów SDK platformy Azure i interfejsów API REST. Zalecamy osadzanie modeli usługi Azure OpenAI, ale można użyć dowolnego modelu do wektoryzacji. Aby uzyskać więcej informacji, zobacz Generowanie osadzania.
Należy znać limit wymiarów modelu używanego do tworzenia osadzonych elementów i sposobu obliczania podobieństwa. W usłudze Azure OpenAI w przypadku osadzania tekstu-ada-002 długość wektora liczbowego wynosi 1536. Podobieństwo jest obliczane przy użyciu metody
cosine. Prawidłowe wartości to od 2 do 3072 wymiary.Należy zapoznać się z tworzeniem indeksu. Schemat musi zawierać pole klucza dokumentu, inne pola, które chcesz przeszukiwać lub filtrować, oraz inne konfiguracje zachowań wymaganych podczas indeksowania i zapytań.
Przygotowywanie dokumentów do indeksowania
Przed indeksowaniem zmontuj ładunek dokumentu zawierający pola danych wektorowych i niewektorowych. Struktura dokumentu musi być zgodna ze schematem indeksu.
Upewnij się, że dokumenty:
Podaj pole lub właściwość metadanych, która unikatowo identyfikuje każdy dokument. Wszystkie indeksy wyszukiwania wymagają klucza dokumentu. Aby spełnić wymagania dotyczące klucza dokumentu, dokument źródłowy musi mieć jedno pole lub właściwość, które może jednoznacznie zidentyfikować go w indeksie. To pole źródłowe musi być mapowane na pole indeksu typu
Edm.Stringikey=truew indeksie wyszukiwania.Podaj dane wektorowe (tablicę liczb zmiennoprzecinkowych o pojedynczej precyzji) w polach źródłowych.
Pola wektorowe zawierają dane liczbowe generowane przez osadzanie modeli, jedno osadzanie na pole. Zalecamy osadzanie modeli w usłudze Azure OpenAI, takich jak osadzanie tekstu-ada-002 dla dokumentów tekstowych lub interfejsu API REST pobierania obrazów dla obrazów. Obsługiwane są tylko pola wektorów najwyższego poziomu indeksu: pola podrzędne wektorów wektorów nie są obecnie obsługiwane.
Podaj inne pola z czytelną dla człowieka zawartością alfanumeryczną dla odpowiedzi na zapytanie oraz w scenariuszach hybrydowych zapytań obejmujących wyszukiwanie pełnotekstowe lub klasyfikację semantyczną w tym samym żądaniu.
Indeks wyszukiwania powinien zawierać pola i zawartość dla wszystkich scenariuszy zapytań, które chcesz obsługiwać. Załóżmy, że chcesz wyszukiwać lub filtrować nazwy produktów, wersje, metadane lub adresy. W takim przypadku wyszukiwanie podobieństwa nie jest szczególnie przydatne. Wyszukiwanie słów kluczowych, wyszukiwanie geograficzne lub filtry byłyby lepszym wyborem. Indeks wyszukiwania zawierający kompleksową kolekcję pól danych wektorowych i niewektorowych zapewnia maksymalną elastyczność tworzenia zapytań i kompozycji odpowiedzi.
Krótki przykład ładunku dokumentów, który zawiera pola wektorowe i niewektorowe, znajduje się w sekcji danych wektora obciążenia tego artykułu.
Dodawanie konfiguracji wyszukiwania wektorowego
Konfiguracja wektorów określa algorytm wyszukiwania wektorów i parametry używane podczas indeksowania w celu utworzenia informacji "najbliższego sąsiada" między węzłami wektorów:
- Hierarchiczny nawigowalny mały świat (HNSW)
- Wyczerpująca nazwa KNN
Jeśli wybierzesz opcję HNSW w polu, możesz wybrać wyczerpującą nazwę KNN w czasie zapytania. Jednak inny kierunek nie zadziała: jeśli wybierzesz wyczerpujące, nie możesz później zażądać wyszukiwania HNSW, ponieważ dodatkowe struktury danych, które umożliwiają przybliżone wyszukiwanie, nie istnieją.
Szukasz wskazówek dotyczących migracji wersji zapoznawczej do stabilnej wersji? Aby uzyskać instrukcje, zobacz Uaktualnianie interfejsów API REST.
Interfejs API REST w wersji 2023-11-01 obsługuje konfigurację wektorów:
vectorSearchalgorytmy iexhaustiveKnnnajbliższe sąsiadyhnswz parametrami indeksowania i oceniania.vectorProfilesdla wielu kombinacji konfiguracji algorytmów.
Pamiętaj, aby mieć strategię wektoryzacji zawartości. Stabilna wersja nie zapewnia wektoryzatorów wbudowanych osadzania.
Użyj interfejsu API tworzenia lub aktualizowania indeksu , aby utworzyć indeks.
Dodaj sekcję
vectorSearchw indeksie, która określa algorytmy wyszukiwania używane do tworzenia miejsca osadzania."vectorSearch": { "algorithms": [ { "name": "my-hnsw-config-1", "kind": "hnsw", "hnswParameters": { "m": 4, "efConstruction": 400, "efSearch": 500, "metric": "cosine" } }, { "name": "my-hnsw-config-2", "kind": "hnsw", "hnswParameters": { "m": 8, "efConstruction": 800, "efSearch": 800, "metric": "cosine" } }, { "name": "my-eknn-config", "kind": "exhaustiveKnn", "exhaustiveKnnParameters": { "metric": "cosine" } } ], "profiles": [ { "name": "my-default-vector-profile", "algorithm": "my-hnsw-config-2" } ] }Kluczowe punkty:
- Nazwa konfiguracji. Nazwa musi być unikatowa w indeksie.
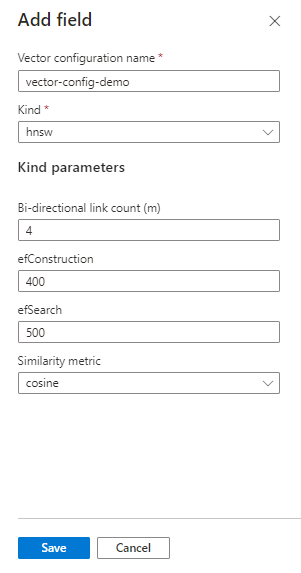
profilesdodaj warstwę abstrakcji, aby uzyskać bardziej rozbudowane definicje. Profil jest definiowany w elemencievectorSearch, a następnie odwołuje się do nich według nazwy w każdym polu wektora."hnsw"i"exhaustiveKnn"to przybliżone algorytmy najbliższych sąsiadów (ANN) używane do organizowania zawartości wektorowej podczas indeksowania."m"Wartość domyślna (liczba linków dwukierunkowych) to 4. Zakres wynosi od 4 do 10. Niższe wartości powinny zwracać mniej szumu w wynikach."efConstruction"wartość domyślna to 400. Zakres wynosi od 100 do 1000. Jest to liczba najbliższych sąsiadów używanych podczas indeksowania."efSearch"wartość domyślna to 500. Zakres wynosi od 100 do 1000. Jest to liczba najbliższych sąsiadów używanych podczas wyszukiwania."metric"jeśli używasz usługi Azure OpenAI, w przeciwnym razie użyj metryki podobieństwa skojarzonej z używanym modelem osadzania. Obsługiwane wartości tocosine, ,euclideandotProduct.
Dodawanie pola wektorowego do kolekcji pól
Kolekcja pól musi zawierać pole dla klucza dokumentu, pól wektorów i innych pól, które są potrzebne w scenariuszach wyszukiwania hybrydowego.
Pola wektorowe są wartościami zmiennoprzecinkowymi o pojedynczej Collection(Edm.Single) precyzji. Pole tego typu ma dimensions również właściwość i określa konfigurację wektora.
Użyj tej wersji, jeśli chcesz korzystać tylko z ogólnie dostępnych funkcji.
Utwórz lub zaktualizuj indeks za pomocą polecenia Utwórz lub Aktualizuj indeks.
Zdefiniuj pole wektora z następującymi atrybutami. Można przechowywać jedno wygenerowane osadzanie dla każdego pola. Dla każdego pola wektora:
typemusi mieć wartośćCollection(Edm.Single).dimensionsto liczba wymiarów generowanych przez model osadzania. W przypadku osadzania tekstu-ada-002 jest to 1536.vectorSearchProfileto nazwa profilu zdefiniowanego gdzie indziej w indeksie.searchablemusi być prawdziwe.retrievablemoże mieć wartość true lub false. Wartość True zwraca nieprzetworzone wektory (1536 z nich) jako zwykły tekst i zużywa miejsce do magazynowania. Ustaw wartość true, jeśli przekazujesz wynik wektora do aplikacji podrzędnej.filterablesortable,facetablemusi mieć wartość false.
Dodaj pola niewektorowe do kolekcji, takie jak "title" z ustawioną wartością
filterabletrue, jeśli chcesz wywołać wstępne filtrowanie lub filtrowanie wektorowe.Dodaj inne pola, które definiują istotę i strukturę indeksowania zawartości tekstowej. Co najmniej potrzebny jest klucz dokumentu.
Należy również dodać pola, które są przydatne w zapytaniu lub w odpowiedzi. W poniższym przykładzie przedstawiono pola wektorów dla tytułu i zawartości ("titleVector", "contentVector"), które są równoważne wektorom. Udostępnia również pola równoważnej zawartości tekstowej ("title", "content") przydatne do sortowania, filtrowania i odczytywania w wynikach wyszukiwania.
W poniższym przykładzie przedstawiono kolekcję pól:
PUT https://my-search-service.search.windows.net/indexes/my-index?api-version=2023-11-01&allowIndexDowntime=true Content-Type: application/json api-key: {{admin-api-key}} { "name": "{{index-name}}", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "filterable": true }, { "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "retrievable": true }, { "name": "titleVector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-default-vector-profile" }, { "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true }, { "name": "contentVector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-default-vector-profile" } ], "vectorSearch": { "algorithms": [ { "name": "my-hnsw-config-1", "kind": "hnsw", "hnswParameters": { "m": 4, "efConstruction": 400, "efSearch": 500, "metric": "cosine" } } ], "profiles": [ { "name": "my-default-vector-profile", "algorithm": "my-hnsw-config-1" } ] } }

Ładowanie danych wektorów do indeksowania
Zawartość, którą podajesz do indeksowania, musi być zgodna ze schematem indeksu i zawierać unikatową wartość ciągu klucza dokumentu. Wstępnie wektorowe dane są ładowane do co najmniej jednego pola wektorowego, które mogą współistnieć z innymi polami zawierającymi zawartość alfanumeryczną.
Do pozyskiwania danych można użyć metodologii wypychania lub ściągania.
Użyj dokumentów indeksu (2023-11-01), Dokumentów indeksu (2023-10-01-Preview) lub dodaj, zaktualizuj lub usuń dokumenty (2023-07-01-Preview), aby wypchnąć dokumenty zawierające dane wektorowe.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/index?api-version=2023-11-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"value": [
{
"id": "1",
"title": "Azure App Service",
"content": "Azure App Service is a fully managed platform for building, deploying, and scaling web apps. You can host web apps, mobile app backends, and RESTful APIs. It supports a variety of programming languages and frameworks, such as .NET, Java, Node.js, Python, and PHP. The service offers built-in auto-scaling and load balancing capabilities. It also provides integration with other Azure services, such as Azure DevOps, GitHub, and Bitbucket.",
"category": "Web",
"titleVector": [
-0.02250031754374504,
. . .
],
"contentVector": [
-0.024740582332015038,
. . .
],
"@search.action": "upload"
},
{
"id": "2",
"title": "Azure Functions",
"content": "Azure Functions is a serverless compute service that enables you to run code on-demand without having to manage infrastructure. It allows you to build and deploy event-driven applications that automatically scale with your workload. Functions support various languages, including C#, F#, Node.js, Python, and Java. It offers a variety of triggers and bindings to integrate with other Azure services and external services. You only pay for the compute time you consume.",
"category": "Compute",
"titleVector": [
-0.020159931853413582,
. . .
],
"contentVector": [
-0.02780858241021633,
. . .
],
"@search.action": "upload"
}
. . .
]
}
Sprawdzanie indeksu pod kątem zawartości wektorowej
W celach walidacji można wykonywać zapytania dotyczące indeksu przy użyciu Eksploratora wyszukiwania w witrynie Azure Portal lub wywołania interfejsu API REST. Ponieważ usługa Azure AI Search nie może przekonwertować wektora na tekst czytelny dla człowieka, spróbuj zwrócić pola z tego samego dokumentu, które dostarczają dowody dopasowania. Jeśli na przykład zapytanie wektorowe jest przeznaczone dla pola "titleVector", możesz wybrać pozycję "title" dla wyników wyszukiwania.
Pola muszą być przypisywane jako "możliwe do pobrania", aby zostały uwzględnione w wynikach.
Eksplorator wyszukiwania umożliwia wykonywanie zapytań względem indeksu. Eksplorator wyszukiwania ma dwa widoki: widok zapytania (domyślny) i widok JSON.
Użyj widoku JSON dla zapytań wektorowych, wklejając w definicji JSON zapytania wektorowego, które chcesz wykonać.
Użyj domyślnego widoku zapytania, aby szybko potwierdzić, że indeks zawiera wektory. Widok zapytania jest przeznaczony do wyszukiwania pełnotekstowego. Chociaż nie można go używać do zapytań wektorowych, możesz wysłać puste wyszukiwanie (
search=*), aby sprawdzić zawartość. Zawartość wszystkich pól, w tym pól wektorowych, jest zwracana jako zwykły tekst.
Aktualizowanie magazynu wektorów
Aby zaktualizować magazyn wektorów, zmodyfikuj schemat i w razie potrzeby załaduj ponownie dokumenty, aby wypełnić nowe pola. Interfejsy API aktualizacji schematu obejmują tworzenie lub aktualizowanie indeksu (REST), CreateOrUpdateIndex w zestawie Azure SDK dla platformy .NET, create_or_update_index w zestawie Azure SDK dla języka Python i podobne metody w innych zestawach SDK platformy Azure.
Standardowe wskazówki dotyczące aktualizowania indeksu zostały omówione w temacie Drop and rebuild an index (Usuwanie i ponowne kompilowanie indeksu).
Kluczowe kwestie obejmują:
Usuwanie i ponowne kompilowanie jest często wymagane w przypadku aktualizacji i usuwania istniejących pól.
Można jednak zaktualizować istniejący schemat przy użyciu następujących modyfikacji bez konieczności ponownego kompilowanie:
- Dodaj nowe pola do kolekcji pól.
- Dodaj nowe konfiguracje wektorów przypisane do nowych pól, ale nie istniejące pola, które zostały już wektoryzowane.
- Zmień "możliwe do pobrania" (wartości są prawdziwe lub fałszywe) w istniejącym polu. Pola wektorowe muszą być wyszukiwalne i możliwe do pobrania, ale jeśli chcesz wyłączyć dostęp do pola wektorowego w sytuacjach, w których upuszczanie i ponowne kompilowanie nie jest możliwe, możesz ustawić pobieranie na wartość false.
Następne kroki
W następnym kroku zalecamy wykonywanie zapytań dotyczących danych wektorów w indeksie wyszukiwania.
Przykłady kodu w repozytorium azure-search-vector przedstawiają kompleksowe przepływy pracy, które obejmują definicję schematu, wektoryzację, indeksowanie i zapytania.
Dostępny jest kod demonstracyjny dla języków Python, C# i JavaScript.