Zarządzanie zużyciem zasobów i ładowaniem w usłudze Service Fabric przy użyciu metryk
Metryki to zasoby, o które dbają Usługi i które są udostępniane przez węzły w klastrze. Metryka to wszystko, co chcesz zarządzać w celu poprawy lub monitorowania wydajności usług. Możesz na przykład obserwować użycie pamięci, aby sprawdzić, czy usługa jest przeciążona. Innym sposobem jest ustalenie, czy usługa może przenieść się gdzie indziej, gdzie pamięć jest mniej ograniczona, aby uzyskać lepszą wydajność.
Przykłady metryk to na przykład użycie pamięci, dysku i procesora CPU. Te metryki są metrykami fizycznymi, zasobami odpowiadającymi zasobom fizycznym w węźle, które muszą być zarządzane. Metryki mogą być również (i często są) metrykami logicznymi. Metryki logiczne są takie jak "MyWorkQueueDepth" lub "MessagesToProcess" lub "TotalRecords". Metryki logiczne są definiowane przez aplikację i pośrednio odpowiadają pewnemu użyciu zasobów fizycznych. Metryki logiczne są typowe, ponieważ może być trudne do mierzenia i raportowania zużycia zasobów fizycznych w poszczególnych usługach. Złożoność mierzenia i raportowania własnych metryk fizycznych jest również przyczyną, dla których usługa Service Fabric udostępnia pewne domyślne metryki.
Metryki domyślne
Załóżmy, że chcesz rozpocząć pisanie i wdrażanie usługi. W tym momencie nie wiesz, jakie zasoby fizyczne lub logiczne zużywają. To dobrze! Klaster usługi Service Fabric Resource Manager używa niektórych domyślnych metryk, gdy nie określono żadnych innych metryk. Są to:
- PrimaryCount — liczba replik podstawowych w węźle
- ReplicaCount — liczba wszystkich replik stanowych w węźle
- Count — liczba wszystkich obiektów usługi (bezstanowych i stanowych) w węźle
| Metric | Ładowanie wystąpień bezstanowych | Stanowe obciążenie pomocnicze | Stanowe obciążenie podstawowe | Waga |
|---|---|---|---|---|
| PrimaryCount | 0 | 0 | 1 | Wys. |
| Liczba replik | 0 | 1 | 1 | Śred. |
| Liczba | 1 | 1 | 1 | Niski |
W przypadku podstawowych obciążeń domyślne metryki zapewniają przyzwoity rozkład pracy w klastrze. W poniższym przykładzie zobaczmy, co się stanie po utworzeniu dwóch usług i polegamy na domyślnych metrykach równoważenia. Pierwsza usługa to usługa stanowa z trzema partycjami i docelowym rozmiarem zestawu replik trzech. Druga usługa jest usługą bezstanową z jedną partycją i liczbą wystąpień wynoszącą trzy.
Oto co otrzymujemy:
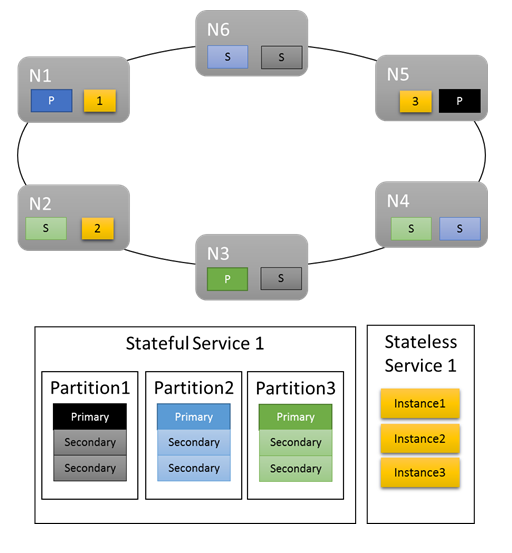
Dodatkowe kwestie, na które należy zwrócić uwagę:
- Repliki podstawowe dla usługi stanowej są dystrybuowane między kilka węzłów
- Repliki dla tej samej partycji znajdują się w różnych węzłach
- Łączna liczba prawyborów i pomocniczych jest dystrybuowana w klastrze
- Łączna liczba obiektów usługi jest równomiernie przydzielana w każdym węźle
Dobry!
Domyślne metryki działają świetnie jako początek. Jednak domyślne metryki będą przenoszone tylko do tej pory. Na przykład: Jakie jest prawdopodobieństwo, że wybrany schemat partycjonowania daje idealnie równomierne wykorzystanie przez wszystkie partycje? Jakie jest prawdopodobieństwo, że obciążenie danej usługi jest stałe w czasie, a nawet po prostu takie samo w wielu partycjach w tej chwili?
Możesz uruchomić polecenie przy użyciu tylko domyślnych metryk. Jednak zwykle oznacza to, że wykorzystanie klastra jest mniejsze i bardziej nierówne niż chcesz. Wynika to z tego, że domyślne metryki nie są adaptacyjne i zakłada się, że wszystko jest równoważne. Na przykład element podstawowy, który jest zajęty, i taki, który nie współtworzy "1" do metryki PrimaryCount. W najgorszym przypadku użycie tylko domyślnych metryk może również spowodować nadmierne zaplanowane węzły, co powoduje problemy z wydajnością. Jeśli chcesz jak najlepiej wykorzystać klaster i uniknąć problemów z wydajnością, musisz użyć metryk niestandardowych i dynamicznego raportowania obciążenia.
Metryki niestandardowe
Metryki są konfigurowane dla poszczególnych nazwanych wystąpień usługi podczas tworzenia usługi.
Każda metryka ma pewne właściwości, które ją opisują: nazwę, wagę i domyślne obciążenie.
- Nazwa metryki: nazwa metryki. Nazwa metryki jest unikatowym identyfikatorem metryki w klastrze z perspektywy Resource Manager.
Uwaga
Nazwa metryki niestandardowej nie powinna być żadną z nazw metryk systemowych, np. servicefabric:/_CpuCores lub servicefabric:/_MemoryInMB, ponieważ może to prowadzić do niezdefiniowanego zachowania. Począwszy od usługi Service Fabric w wersji 9.1, w przypadku istniejących usług z tymi niestandardowymi nazwami metryk zostanie wyświetlone ostrzeżenie o kondycji wskazujące, że nazwa metryki jest niepoprawna.
- Waga: Waga metryki określa, jak ważna jest ta metryka względem innych metryk dla tej usługi.
- Obciążenie domyślne: domyślne obciążenie jest reprezentowane inaczej w zależności od tego, czy usługa jest bezstanowa, czy stanowa.
- W przypadku usług bezstanowych każda metryka ma jedną właściwość o nazwie DefaultLoad
- W przypadku usług stanowych definiujesz:
- PrimaryDefaultLoad: domyślna ilość tej metryki zużywana przez tę usługę, gdy jest to podstawowa
- SecondaryDefaultLoad: domyślna ilość tej metryki zużywana przez tę usługę, gdy jest to pomocnicza
Uwaga
Jeśli zdefiniujesz metryki niestandardowe i chcesz również użyć domyślnych metryk, musisz jawnie dodać domyślne metryki z powrotem i zdefiniować dla nich wagi i wartości. Jest to spowodowane tym, że należy zdefiniować relację między metrykami domyślnymi a metrykami niestandardowymi. Na przykład możesz dbać o parametry ConnectionCount lub WorkQueueDepth więcej niż dystrybucja podstawowa. Domyślnie waga metryki PrimaryCount ma wartość Wysoka, więc chcesz zmniejszyć ją do średniej podczas dodawania innych metryk, aby upewnić się, że mają pierwszeństwo.
Definiowanie metryk dla usługi — przykład
Załóżmy, że potrzebujesz następującej konfiguracji:
- Twoja usługa zgłasza metrykę o nazwie "ConnectionCount"
- Chcesz również użyć domyślnych metryk
- Wykonano kilka pomiarów i wiesz, że zwykle replika podstawowa tej usługi zajmuje 20 jednostek "ConnectionCount"
- Pomocnicze używają 5 jednostek "ConnectionCount"
- Wiesz, że "ConnectionCount" to najważniejsza metryka pod względem zarządzania wydajnością tej konkretnej usługi
- Nadal chcesz zrównoważyć repliki podstawowe. Równoważenie replik podstawowych jest ogólnie dobrym pomysłem niezależnie od tego, co. Pomaga to zapobiec utracie niektórych węzłów lub domeny błędów, które mają wpływ na większość replik podstawowych wraz z nią.
- W przeciwnym razie domyślne metryki są w porządku
Oto kod, który należy napisać, aby utworzyć usługę z konfiguracją tej metryki:
Kod:
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
StatefulServiceLoadMetricDescription connectionMetric = new StatefulServiceLoadMetricDescription();
connectionMetric.Name = "ConnectionCount";
connectionMetric.PrimaryDefaultLoad = 20;
connectionMetric.SecondaryDefaultLoad = 5;
connectionMetric.Weight = ServiceLoadMetricWeight.High;
StatefulServiceLoadMetricDescription primaryCountMetric = new StatefulServiceLoadMetricDescription();
primaryCountMetric.Name = "PrimaryCount";
primaryCountMetric.PrimaryDefaultLoad = 1;
primaryCountMetric.SecondaryDefaultLoad = 0;
primaryCountMetric.Weight = ServiceLoadMetricWeight.Medium;
StatefulServiceLoadMetricDescription replicaCountMetric = new StatefulServiceLoadMetricDescription();
replicaCountMetric.Name = "ReplicaCount";
replicaCountMetric.PrimaryDefaultLoad = 1;
replicaCountMetric.SecondaryDefaultLoad = 1;
replicaCountMetric.Weight = ServiceLoadMetricWeight.Low;
StatefulServiceLoadMetricDescription totalCountMetric = new StatefulServiceLoadMetricDescription();
totalCountMetric.Name = "Count";
totalCountMetric.PrimaryDefaultLoad = 1;
totalCountMetric.SecondaryDefaultLoad = 1;
totalCountMetric.Weight = ServiceLoadMetricWeight.Low;
serviceDescription.Metrics.Add(connectionMetric);
serviceDescription.Metrics.Add(primaryCountMetric);
serviceDescription.Metrics.Add(replicaCountMetric);
serviceDescription.Metrics.Add(totalCountMetric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
Program PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ConnectionCount,High,20,5”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Uwaga
W powyższych przykładach i pozostałej części tego dokumentu opisano zarządzanie metrykami dla poszczególnych nazwanych usług. Istnieje również możliwość zdefiniowania metryk dla usług na poziomie typu usługi. Można to osiągnąć, określając je w manifestach usługi. Definiowanie metryk na poziomie typu nie jest zalecane z kilku powodów. Pierwszą przyczyną jest to, że nazwy metryk są często specyficzne dla środowiska. Jeśli nie ma umowy firmowej, nie można mieć pewności, że metryka "Rdzenie" w jednym środowisku nie jest "MiliCores" ani "CoReS" w innych. Jeśli metryki są zdefiniowane w manifeście, musisz utworzyć nowe manifesty dla każdego środowiska. Zwykle prowadzi to do rozprzestrzeniania się różnych manifestów tylko z niewielkimi różnicami, co może prowadzić do trudności w zarządzaniu.
Obciążenia metryki są często przypisywane dla poszczególnych nazwanych wystąpień usługi. Załóżmy na przykład, że utworzysz jedno wystąpienie usługi dla klienta CustomerA, które planuje używać jej tylko lekko. Załóżmy również, że tworzysz kolejny dla klienta B, który ma większe obciążenie. W takim przypadku prawdopodobnie chcesz dostosować domyślne obciążenia dla tych usług. Jeśli masz metryki i obciążenia zdefiniowane za pośrednictwem manifestów i chcesz obsługiwać ten scenariusz, wymaga to różnych typów aplikacji i usług dla każdego klienta. Wartości zdefiniowane w czasie tworzenia usługi zastępują wartości zdefiniowane w manifeście, dzięki czemu można użyć ich do ustawienia określonych wartości domyślnych. Jednak powoduje to, że wartości zadeklarowane w manifeście nie pasują do tych, z którymi usługa jest rzeczywiście uruchamiana. Może to prowadzić do zamieszania.
Przypomnienie: jeśli chcesz używać domyślnych metryk, nie musisz w ogóle dotykać kolekcji metryk ani wykonywać żadnych specjalnych czynności podczas tworzenia usługi. Domyślne metryki są używane automatycznie, gdy nie zdefiniowano żadnych innych.
Teraz przyjrzyjmy się dokładniej każdemu z tych ustawień i omówimy zachowanie, które ma to wpływ.
Ładowanie
Cały punkt definiowania metryk polega na reprezentowaniu pewnego obciążenia. Obciążenie to ilość danej metryki używanej przez niektóre wystąpienie usługi lub replikę w danym węźle. Obciążenie można skonfigurować niemal w dowolnym momencie. Przykład:
- Obciążenie można zdefiniować podczas tworzenia usługi. Ten typ konfiguracji ładowania nosi nazwę ładowania domyślnego.
- Informacje o metryce, w tym obciążenia domyślne, można zaktualizować dla usługi po utworzeniu usługi. Ta aktualizacja metryki jest wykonywana przez aktualizację usługi.
- Obciążenia dla danej partycji można zresetować do wartości domyślnych dla tej usługi. Ta aktualizacja metryki jest nazywana resetowaniem obciążenia partycji.
- Obciążenie można zgłaszać na podstawie poszczególnych obiektów usługi, dynamicznie podczas wykonywania. Ta aktualizacja metryki jest nazywana obciążeniem raportowania.
- Ładowanie replik lub wystąpień partycji można również zaktualizować przez raportowanie wartości obciążenia za pośrednictwem wywołania interfejsu API sieci szkieletowej. Ta aktualizacja metryki jest nazywana obciążeniem raportowania dla partycji.
Wszystkie te strategie mogą być używane w ramach tej samej usługi w okresie istnienia.
Ładowanie domyślne
Domyślne obciążenie to ilość metryki używanej przez każdy obiekt usługi (wystąpienie bezstanowe lub replika stanowa). Klaster Resource Manager używa tej liczby do załadowania obiektu usługi, dopóki nie otrzyma innych informacji, takich jak dynamiczny raport o obciążeniu. W przypadku prostszych usług domyślnym obciążeniem jest definicja statyczna. Domyślne ładowanie nigdy nie jest aktualizowane i jest używane przez okres istnienia usługi. Domyślne obciążenia doskonale sprawdzają się w przypadku prostych scenariuszy planowania pojemności, w których niektóre ilości zasobów są przeznaczone dla różnych obciążeń i nie zmieniają się.
Uwaga
Aby uzyskać więcej informacji na temat zarządzania pojemnością i definiowania pojemności dla węzłów w klastrze, zobacz ten artykuł.
Klaster Resource Manager umożliwia usługom stanowym określanie innego domyślnego obciążenia dla ich prawyborów i pomocniczych. Usługi bezstanowe mogą określać tylko jedną wartość, która ma zastosowanie do wszystkich wystąpień. W przypadku usług stanowych domyślne obciążenie replik podstawowych i pomocniczych jest zwykle różne, ponieważ repliki wykonują różne rodzaje pracy w każdej roli. Na przykład prawybory zwykle obsługują zarówno odczyty, jak i zapisy, i obsługują większość obciążeń obliczeniowych, podczas gdy pomocnicze nie. Zwykle domyślne obciążenie repliki podstawowej jest wyższe niż domyślne obciążenie replik pomocniczych. Rzeczywiste liczby powinny zależeć od własnych pomiarów.
Ładowanie dynamiczne
Załóżmy, że usługa była uruchomiona od jakiegoś czasu. W przypadku monitorowania zauważyliśmy, że:
- Niektóre partycje lub wystąpienia danej usługi zużywają więcej zasobów niż inne
- Niektóre usługi mają obciążenie, które zmienia się w czasie.
Istnieje wiele rzeczy, które mogą powodować tego typu wahania obciążenia. Na przykład różne usługi lub partycje są skojarzone z różnymi klientami z różnymi wymaganiami. Obciążenie może również ulec zmianie, ponieważ ilość pracy wykonywanej przez usługę różni się w ciągu dnia. Niezależnie od przyczyny zazwyczaj nie ma pojedynczej liczby, której można użyć domyślnie. Jest to szczególnie prawdziwe, jeśli chcesz uzyskać największe wykorzystanie z klastra. Każda wartość wybrana dla ładowania domyślnego jest nieprawidłowa w niektórych przypadkach. Niepoprawne domyślne ładowanie powoduje, że klaster Resource Manager lub w ramach przydzielania zasobów. W związku z tym masz węzły, które są ponad lub w pełni wykorzystywane, mimo że klaster Resource Manager uważa, że klaster jest zrównoważony. Obciążenia domyślne są nadal dobre, ponieważ zawierają pewne informacje na temat początkowego umieszczania, ale nie są one kompletną historią dla rzeczywistych obciążeń. Aby dokładnie przechwytywać zmieniające się wymagania dotyczące zasobów, klaster Resource Manager umożliwia każdemu obiektowi usługi aktualizowanie własnego obciążenia podczas wykonywania. Jest to nazywane dynamicznym raportowaniem obciążenia.
Raporty dynamicznego ładowania umożliwiają replikom lub wystąpieniom dostosowywanie alokacji/zgłaszanego obciążenia metryk w okresie ich istnienia. Replika usługi lub wystąpienie, które było zimne i nie wykonuje żadnej pracy, zwykle zgłasza, że używa niskich ilości danej metryki. Zajęta replika lub wystąpienie zgłasza, że używa więcej.
Raportowanie obciążenia na replikę lub wystąpienie umożliwia klastrowi Resource Manager reorganizację poszczególnych obiektów usługi w klastrze. Reorganizacja usług pomaga zapewnić, że uzyskują wymagane zasoby. Zajęte usługi skutecznie uzyskują "odzyskiwanie" zasobów z innych replik lub wystąpień, które są obecnie zimne lub mniej pracy.
W usługach Reliable Services kod do dynamicznego raportowania obciążenia wygląda następująco:
Kod:
this.Partition.ReportLoad(new List<LoadMetric> { new LoadMetric("CurrentConnectionCount", 1234), new LoadMetric("metric1", 42) });
Usługa może zgłaszać dowolne metryki zdefiniowane dla niej w czasie tworzenia. Jeśli usługa zgłasza obciążenie metryki, która nie jest skonfigurowana do użycia, usługa Service Fabric ignoruje ten raport. Jeśli istnieją inne metryki zgłoszone w tym samym czasie, które są prawidłowe, te raporty są akceptowane. Kod usługi może mierzyć i zgłaszać wszystkie metryki, w których wie, jak to zrobić, oraz operatory mogą określać konfigurację metryki do użycia bez konieczności zmiany kodu usługi.
Raportowanie obciążenia partycji
W poprzedniej sekcji opisano sposób ładowania samych replik usług lub wystąpień. Istnieje dodatkowa opcja dynamicznego raportowania obciążenia replik lub wystąpień partycji za pośrednictwem interfejsu API usługi Service Fabric. Podczas raportowania obciążenia partycji można zgłaszać wiele partycji jednocześnie.
Te raporty będą używane w dokładnie taki sam sposób, jak raporty ładowania pochodzące z samych replik lub wystąpień. Zgłoszone wartości będą prawidłowe do momentu zgłoszenia nowych wartości obciążenia przez replikę lub wystąpienie albo raportowanie nowej wartości obciążenia dla partycji.
W tym interfejsie API istnieje wiele sposobów aktualizowania obciążenia w klastrze:
- Partycja usługi stanowej może zaktualizować obciążenie repliki podstawowej.
- Zarówno usługi bezstanowe, jak i stanowe mogą aktualizować obciążenie wszystkich replik pomocniczych lub wystąpień.
- Zarówno usługi bezstanowe, jak i stanowe mogą aktualizować obciążenie określonej repliki lub wystąpienia w węźle.
Istnieje również możliwość połączenia dowolnej z tych aktualizacji na partycję w tym samym czasie. Kombinacja aktualizacji obciążenia dla określonej partycji powinna być określona za pośrednictwem obiektu PartitionMetricLoadDescription, który może zawierać odpowiednią listę aktualizacji obciążenia, jak pokazano w poniższym przykładzie. Aktualizacje obciążenia są reprezentowane za pośrednictwem obiektu MetricLoadDescription, który może zawierać bieżącą lub przewidywaną wartość obciążenia dla metryki określonej za pomocą nazwy metryki.
Uwaga
Przewidywane wartości obciążenia metryki są obecnie funkcją w wersji zapoznawczej. Umożliwia raportowanie przewidywanych wartości obciążenia i używanie ich po stronie usługi Service Fabric, ale ta funkcja nie jest obecnie włączona.
Aktualizowanie obciążeń dla wielu partycji jest możliwe za pomocą pojedynczego wywołania interfejsu API, w tym przypadku dane wyjściowe będą zawierać odpowiedź na partycję. W przypadku, gdy aktualizacja partycji nie zostanie pomyślnie zastosowana z jakiegokolwiek powodu, aktualizacje dla tej partycji zostaną pominięte, a odpowiedni kod błędu partycji docelowej zostanie udostępniony:
- PartitionNotFound — określony identyfikator partycji nie istnieje.
- ReconfigurationPending — partycja jest obecnie ponownie konfigurowana.
- InvalidForStatelessServices — podjęto próbę zmiany obciążenia repliki podstawowej dla partycji należącej do usługi bezstanowej.
- ReplicaDoesNotExist — replika pomocnicza lub wystąpienie nie istnieje w określonym węźle.
- InvalidOperation — może się zdarzyć w dwóch przypadkach: aktualizowanie obciążenia partycji należącej do aplikacji systemowej lub aktualizowanie przewidywanego obciążenia nie jest włączone.
Jeśli zostaną zwrócone niektóre z tych błędów, możesz zaktualizować dane wejściowe dla określonej partycji i ponowić próbę aktualizacji.
Kod:
Guid partitionId = Guid.Parse("53df3d7f-5471-403b-b736-bde6ad584f42");
string metricName0 = "CustomMetricName0";
List<MetricLoadDescription> newPrimaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 100)
};
string nodeName0 = "NodeName0";
List<MetricLoadDescription> newSpecificSecondaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 200)
};
OperationResult<UpdatePartitionLoadResultList> updatePartitionLoadResults =
await this.FabricClient.UpdatePartitionLoadAsync(
new UpdatePartitionLoadQueryDescription
{
PartitionMetricLoadDescriptionList = new List<PartitionMetricLoadDescription>()
{
new PartitionMetricLoadDescription(
partitionId,
newPrimaryReplicaLoads,
new List<MetricLoadDescription>(),
new List<ReplicaMetricLoadDescription>()
{
new ReplicaMetricLoadDescription(nodeName0, newSpecificSecondaryReplicaLoads)
})
}
},
this.Timeout,
cancellationToken);
W tym przykładzie wykonasz aktualizację ostatniego zgłoszonego obciążenia dla partycji 53df3d7f-5471-403b-b736-bde6ad584f42. Obciążenie repliki podstawowej dla metryki CustomMetricName0 zostanie zaktualizowane o wartość 100. W tym samym czasie obciążenie tej samej metryki dla określonej repliki pomocniczej znajdującej się w węźle NodeName0 zostanie zaktualizowane o wartość 200.
Aktualizowanie konfiguracji metryk usługi
Lista metryk skojarzonych z usługą oraz właściwości tych metryk można aktualizować dynamicznie, gdy usługa jest aktywna. Umożliwia to eksperymentowanie i elastyczność. Oto kilka przykładów przydatnych elementów:
- wyłączanie metryki z raportem o usterce dla określonej usługi
- ponowne konfigurowanie wag metryk na podstawie żądanego zachowania
- włączanie nowej metryki dopiero po wdrożeniu i zweryfikowaniu kodu za pomocą innych mechanizmów
- zmiana domyślnego obciążenia usługi na podstawie obserwowanego zachowania i zużycia
Główne interfejsy API służące do zmieniania konfiguracji metryki znajdują się FabricClient.ServiceManagementClient.UpdateServiceAsync w języku C# i Update-ServiceFabricService w programie PowerShell. Niezależnie od informacji, które określisz za pomocą tych interfejsów API, natychmiast zastąpią istniejące informacje o metrykach dla usługi.
Mieszanie domyślnych wartości obciążenia i dynamicznych raportów obciążenia
Domyślne ładowanie i dynamiczne obciążenia mogą być używane dla tej samej usługi. Gdy usługa korzysta zarówno z raportów ładowania domyślnego, jak i dynamicznego ładowania, domyślne obciążenie służy jako oszacowanie do momentu wyświetlenia raportów dynamicznych. Obciążenie domyślne jest dobre, ponieważ zapewnia Resource Manager klastra, z czym można pracować. Domyślne obciążenie umożliwia klastrowi Resource Manager umieszczanie obiektów usługi w dobrych lokalizacjach podczas ich tworzenia. Jeśli nie podano żadnych domyślnych informacji o obciążeniu, umieszczanie usług jest efektywnie losowe. Gdy raporty ładowania docierają później, początkowe losowe umieszczanie jest często nieprawidłowe, a Resource Manager klastra musi przenosić usługi.
Przyjrzyjmy się naszemu poprzedniemu przykładowi i zobaczmy, co się stanie po dodaniu metryk niestandardowych i dynamicznego raportowania obciążenia. W tym przykładzie jako przykładowa metryka używamy wartości "MemoryInMb".
Uwaga
Pamięć jest jedną z metryk systemowych, którymi usługa Service Fabric może zarządzać zasobami, a raportowanie jest zwykle trudne. Nie spodziewamy się, że zgłosisz zużycie pamięci; Pamięć jest używana tutaj jako pomoc w poznawaniu możliwości Resource Manager klastra.
Załóżmy, że początkowo utworzyliśmy usługę stanową za pomocą następującego polecenia:
Program PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("MemoryInMb,High,21,11”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Przypominamy, że ta składnia to ("MetricName, MetricWeight, PrimaryDefaultLoad, SecondaryDefaultLoad").
Zobaczmy, jak może wyglądać jeden możliwy układ klastra:
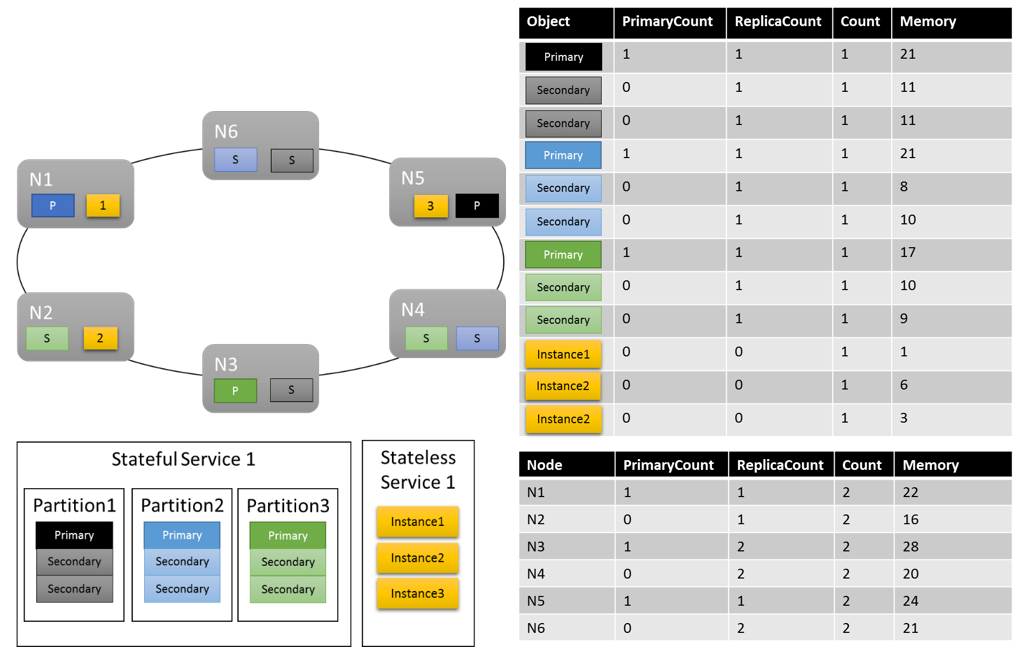
Warto zauważyć kilka rzeczy:
- Repliki pomocnicze w ramach partycji mogą mieć własne obciążenie
- Ogólnie rzecz biorąc, metryki wyglądają na zrównoważone. W przypadku pamięci stosunek maksymalnego i minimalnego obciążenia wynosi 1,75 (węzeł o największym obciążeniu to N3, najmniej to N2 i 28/16 = 1,75).
Nadal musimy wyjaśnić pewne kwestie:
- Co ustaliło, czy stosunek 1,75 był rozsądny, czy nie? W jaki sposób klaster Resource Manager wiedzieć, czy jest to wystarczająco dobre, czy istnieje więcej pracy do zrobienia?
- Kiedy następuje równoważenie?
- Co to znaczy, że pamięć została ważona "Wysoka"?
Wagi metryk
Śledzenie tych samych metryk w różnych usługach jest ważne. Ten widok globalny umożliwia klastrowi Resource Manager śledzenie zużycia w klastrze, równoważenie zużycia między węzłami i zapewnienie, że węzły nie przejdą przez pojemność. Jednak usługi mogą mieć różne poglądy co do znaczenia tej samej metryki. Ponadto w klastrze z wieloma metrykami i dużą liczbą usług idealnie zrównoważone rozwiązania mogą nie istnieć dla wszystkich metryk. W jaki sposób klaster Resource Manager obsługiwać te sytuacje?
Wagi metryk umożliwiają klastrowi Resource Manager decydowanie, jak zrównoważyć klaster, gdy nie ma doskonałej odpowiedzi. Wagi metryk umożliwiają również Resource Manager klastra równoważenie określonych usług w inny sposób. Metryki mogą mieć cztery różne poziomy wagi: Zero, Niski, Średni i Wysoki. Metryka o wadze Zero nie przyczynia się do niczego, biorąc pod uwagę, czy elementy są zrównoważone, czy nie. Jednak jego obciążenie nadal przyczynia się do zarządzania pojemnością. Metryki o zerowej wadze są nadal przydatne i są często używane jako część zachowania usługi i monitorowania wydajności. Ten artykuł zawiera więcej informacji na temat korzystania z metryk na potrzeby monitorowania i diagnostyki usług.
Rzeczywisty wpływ różnych wag metryk w klastrze polega na tym, że Resource Manager klastra generuje różne rozwiązania. Wagi metryk informują klaster Resource Manager, że niektóre metryki są ważniejsze niż inne. Jeśli nie ma idealnego rozwiązania, klaster Resource Manager może preferować rozwiązania, które lepiej równoważą metryki o wyższych wagach. Jeśli usługa uważa, że określona metryka jest nieważna, może okazać się, że ich użycie tej metryki jest nierównowagowane. Dzięki temu inna usługa może uzyskać równomierny rozkład niektórych metryk, które są dla niej ważne.
Przyjrzyjmy się przykładowi niektórych raportów obciążenia i sposobie, w jaki różne wagi metryk są wynikiem różnych alokacji w klastrze. W tym przykładzie widzimy, że zmiana względnej wagi metryk powoduje, że klaster Resource Manager utworzyć różne rozwiązania usług.
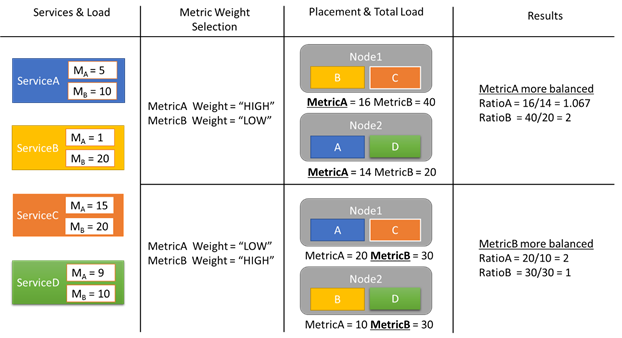
W tym przykładzie istnieją cztery różne usługi, wszystkie raportowanie różnych wartości dla dwóch różnych metryk, MetricA i MetricB. W jednym przypadku wszystkie usługi definiują MetricA jest najważniejszym (Waga = Wysoka) i MetricB jako nieistotne (Waga = Niska). W związku z tym widzimy, że klaster Resource Manager umieszcza usługi tak, aby MetricA był lepiej zrównoważony niż MetricB. "Lepsze równoważenie" oznacza, że wartość MetricA ma niższe odchylenie standardowe niż MetricB. W drugim przypadku odwracamy wagi metryk. W związku z tym klaster Resource Manager zamienia usługi A i B, aby wymyślić alokację, w której Metryka jest lepiej zrównoważona niż MetricA.
Uwaga
Wagi metryk określają sposób równoważenia Resource Manager klastra, ale nie podczas równoważenia. Aby uzyskać więcej informacji na temat równoważenia, zapoznaj się z tym artykułem
Globalne wagi metryk
Załóżmy, że usługa ServiceA definiuje MetricA jako wagę Wysoką, a usługa ServiceB ustawia wagę MetricA na low lub zero. Jaka jest rzeczywista waga, która kończy się coraz używany?
Istnieje wiele wag śledzonych dla każdej metryki. Pierwsza waga to ta zdefiniowana dla metryki podczas tworzenia usługi. Druga waga to waga globalna, która jest obliczana automatycznie. Klaster Resource Manager używa obu tych wag podczas oceniania rozwiązań. Uwzględnianie obu wag jest ważne. Dzięki temu klaster Resource Manager równoważyć każdą usługę zgodnie z własnymi priorytetami, a także zapewnić prawidłowe przydzielanie klastra jako całości.
Co się stanie, jeśli Resource Manager klastra nie obchodzi zarówno równowagi globalnej, jak i lokalnej? Cóż, łatwo jest tworzyć rozwiązania, które są globalnie zrównoważone, ale co skutkuje niską równowagą zasobów dla poszczególnych usług. W poniższym przykładzie przyjrzyjmy się usłudze skonfigurowanej przy użyciu tylko domyślnych metryk i zobaczmy, co się stanie, gdy uwzględniane jest tylko saldo globalne:
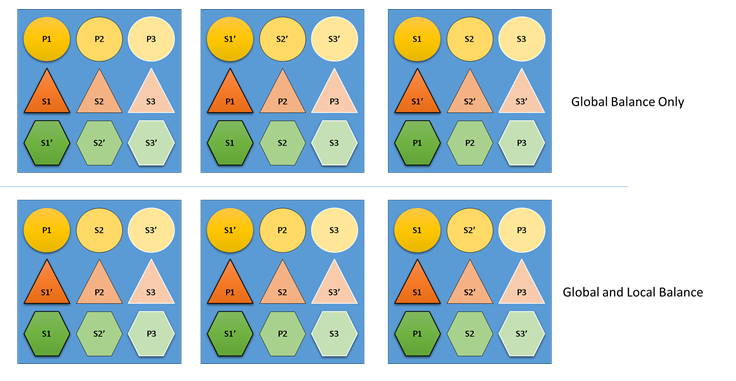
W najlepszym przykładzie opartym tylko na równowadze globalnej klaster jako całość jest rzeczywiście zrównoważony. Wszystkie węzły mają tę samą liczbę prawyborów i tę samą liczbę replik sum. Jeśli jednak przyjrzysz się rzeczywistemu wpływowi tej alokacji, nie jest tak dobry: utrata jakiegokolwiek węzła ma nieproporcjonalny wpływ na określone obciążenie, ponieważ wyjmuje wszystkie jego prawybory. Jeśli na przykład pierwszy węzeł ulegnie awarii trzech prawyborów dla trzech różnych partycji usługi Circle, wszystkie zostaną utracone. Z drugiej strony usługi Trójkąt i Sześciokąt mają swoje partycje tracą replikę. Nie powoduje to żadnych zakłóceń, poza koniecznością odzyskania repliki w dół.
W dolnym przykładzie klaster Resource Manager dystrybuował repliki na podstawie globalnego i dla poszczególnych usług. Podczas obliczania wyniku rozwiązania daje większość wagi globalnemu rozwiązaniu oraz (konfigurowalną) część do poszczególnych usług. Globalne saldo dla metryki jest obliczane na podstawie średniej wag metryk z każdej usługi. Każda usługa jest zrównoważona zgodnie z własnymi zdefiniowanymi wagami metryk. Gwarantuje to, że usługi są wyważone samodzielnie zgodnie z ich własnymi potrzebami. W związku z tym, jeśli ten sam pierwszy węzeł ulegnie awarii, awaria zostanie rozproszona we wszystkich partycjach wszystkich usług. Wpływ na każdy z nich jest taki sam.
Następne kroki
- Aby uzyskać więcej informacji na temat konfigurowania usług, dowiedz się więcej o konfigurowaniu usług (service-fabric-cluster-resource-manager-configure-services.md)
- Definiowanie metryk defragmentacji to jeden ze sposobów konsolidacji obciążenia węzłów zamiast rozkładania go. Aby dowiedzieć się, jak skonfigurować defragmentację, zapoznaj się z tym artykułem
- Aby dowiedzieć się, jak klaster Resource Manager zarządza obciążeniem klastra i równoważy je w klastrze, zapoznaj się z artykułem dotyczącym równoważenia obciążenia
- Zacznij od początku i uzyskaj wprowadzenie do klastra usługi Service Fabric Resource Manager
- Koszt ruchu jest jednym ze sposobów sygnalizowania klastra Resource Manager, że niektóre usługi są droższe do przeniesienia niż inne. Aby dowiedzieć się więcej na temat kosztów przenoszenia, zapoznaj się z tym artykułem