Projektowanie i wydajność migracji teradata
Ten artykuł jest jedną z siedmiu części serii, która zawiera wskazówki dotyczące migracji z usługi Teradata do usługi Azure Synapse Analytics. Celem tego artykułu są najlepsze rozwiązania dotyczące projektowania i wydajności.
Omówienie
Wielu istniejących użytkowników systemów magazynu danych Teradata chce skorzystać z innowacji oferowanych przez nowoczesne środowiska chmurowe. Środowiska chmury typu infrastruktura jako usługa (IaaS) i platforma jako usługa (PaaS) umożliwiają delegowanie zadań, takich jak konserwacja infrastruktury i programowanie platformy dla dostawcy chmury.
Napiwek
Nie tylko baza danych — środowisko platformy Azure zawiera kompleksowy zestaw funkcji i narzędzi.
Chociaż teradata i Azure Synapse Analytics to bazy danych SQL, które używają technik masowego przetwarzania równoległego (MPP) w celu osiągnięcia wysokiej wydajności zapytań na wyjątkowo dużych woluminach danych, istnieją pewne podstawowe różnice w podejściu:
Starsze systemy Teradata są często instalowane lokalnie i używają zastrzeżonego sprzętu, podczas gdy usługa Azure Synapse jest oparta na chmurze i korzysta z usługi Azure Storage i zasobów obliczeniowych.
Ponieważ zasoby magazynu i zasobów obliczeniowych są oddzielne w środowisku platformy Azure i mają elastyczne możliwości skalowania, te zasoby można skalować w górę lub w dół niezależnie.
W razie potrzeby możesz wstrzymać lub zmienić rozmiar usługi Azure Synapse, aby zmniejszyć wykorzystanie zasobów i koszty.
Uaktualnianie konfiguracji teradata jest głównym zadaniem obejmującym dodatkowy sprzęt fizyczny i potencjalnie długotrwałą ponowną konfigurację lub ponowne ładowanie bazy danych.
Platforma Microsoft Azure to globalnie dostępne, wysoce bezpieczne, skalowalne środowisko w chmurze, które obejmuje usługę Azure Synapse i ekosystem pomocniczych narzędzi i możliwości. Następny diagram zawiera podsumowanie ekosystemu usługi Azure Synapse.
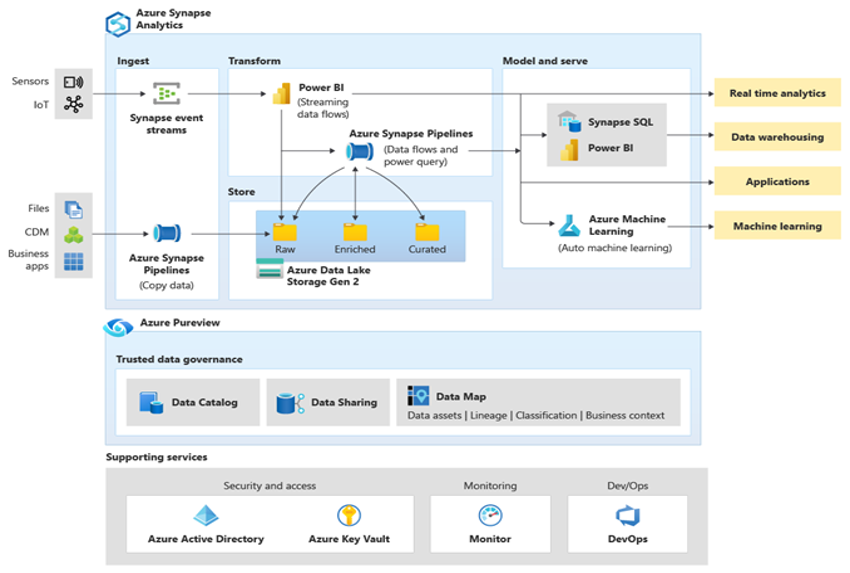
Usługa Azure Synapse zapewnia najlepszą wydajność relacyjnej bazy danych przy użyciu technik, takich jak MPP i wiele poziomów zautomatyzowanego buforowania dla często używanych danych. Wyniki tych technik można zobaczyć w niezależnych testach porównawczych, takich jak ostatnio uruchamiany przez GigaOm, który porównuje usługę Azure Synapse z innymi popularnymi ofertami magazynu danych w chmurze. Klienci migrujący do środowiska usługi Azure Synapse widzą wiele korzyści, w tym:
Zwiększona wydajność i cena/wydajność.
Zwiększona elastyczność i krótszy czas na wartość.
Szybsze wdrażanie serwera i tworzenie aplikacji.
Elastyczna skalowalność — płacisz tylko za rzeczywiste użycie.
Ulepszone zabezpieczenia/zgodność.
Zmniejszono koszty magazynowania i odzyskiwania po awarii.
Niższy ogólny koszt posiadania, lepsza kontrola kosztów i usprawnione wydatki operacyjne (OPEX).
Aby zmaksymalizować te korzyści, zmigruj nowe lub istniejące dane i aplikacje do platformy Azure Synapse. W wielu organizacjach migracja obejmuje przeniesienie istniejącego magazynu danych ze starszej platformy lokalnej, takiej jak Teradata, do usługi Azure Synapse. Na wysokim poziomie proces migracji obejmuje następujące kroki:
Przygotowanie 🡆
Zdefiniuj zakres — co ma zostać zmigrowane.
Tworzenie spisu danych i procesów migracji.
Zdefiniuj zmiany modelu danych (jeśli istnieją).
Zdefiniuj mechanizm wyodrębniania danych źródłowych.
Zidentyfikuj odpowiednie narzędzia i funkcje platformy Azure oraz inne firmy, które mają być używane.
Szkolenie pracowników na początku nowej platformy.
Skonfiguruj platformę docelową platformy Azure.
Migracja 🡆
Zacznij od małych i prostych.
Automatyzuj wszędzie tam, gdzie to możliwe.
Skorzystaj z wbudowanych narzędzi i funkcji platformy Azure, aby zmniejszyć nakład pracy nad migracją.
Migrowanie metadanych dla tabel i widoków.
Migrowanie danych historycznych do utrzymania.
Migrowanie lub refaktoryzacja procedur składowanych i procesów biznesowych.
Migrowanie lub refaktoryzacja procesów ładowania przyrostowego ETL/ELT.
Po migracji
Monitoruj i dokumentuj wszystkie etapy procesu.
Użyj zdobytego doświadczenia, aby utworzyć szablon na potrzeby przyszłych migracji.
W razie potrzeby przeprojektuj ponownie model danych (przy użyciu nowej wydajności i skalowalności platformy).
Testowanie aplikacji i narzędzi do wykonywania zapytań.
Testowanie porównawcze i optymalizowanie wydajności zapytań.
Ten artykuł zawiera ogólne informacje i wytyczne dotyczące optymalizacji wydajności podczas migrowania magazynu danych z istniejącego środowiska Netezza do usługi Azure Synapse. Celem optymalizacji wydajności jest osiągnięcie takiej samej lub lepszej wydajności magazynu danych w usłudze Azure Synapse po migracji schematu.
Uwagi dotyczące projektowania
Zakres migracji
Podczas przygotowywania do migracji ze środowiska Teradata należy wziąć pod uwagę następujące opcje migracji.
Wybieranie obciążenia na potrzeby migracji początkowej
Zazwyczaj starsze środowiska Teradata ewoluowały wraz z upływem czasu, aby obejmować wiele obszarów tematycznych i mieszanych obciążeń. Podczas wybierania miejsca rozpoczęcia projektu migracji wybierz obszar, w którym będzie można wykonywać następujące zadania:
Udowodnij rentowność migracji do usługi Azure Synapse, szybko zapewniając korzyści wynikające z nowego środowiska.
Zezwól swoim pracownikom technicznym na uzyskanie odpowiedniego doświadczenia z procesami i narzędziami, których będą używać podczas migrowania innych obszarów.
Utwórz szablon do dalszych migracji specyficznych dla źródłowego środowiska Teradata oraz bieżących narzędzi i procesów, które już istnieją.
Dobry kandydat do początkowej migracji z teradata wsparcie środowiska poprzednich elementów i:
Implementuje obciążenie analizy biznesowej/analizy, a nie obciążenie przetwarzania transakcji online (OLTP).
Ma model danych, taki jak schemat gwiazdy lub płatka śniegu, który można migrować z minimalnymi modyfikacjami.
Napiwek
Utwórz spis obiektów, które muszą zostać zmigrowane, i udokumentować proces migracji.
Ilość migrowanych danych w początkowej migracji powinna być wystarczająco duża, aby zademonstrować możliwości i zalety środowiska usługi Azure Synapse, ale nie zbyt duże, aby szybko zademonstrować wartość. Typowy jest rozmiar zakresu 1–10 terabajtów.
W przypadku początkowego projektu migracji zminimalizuj ryzyko, nakład pracy i czas migracji, aby szybko zobaczyć korzyści środowiska chmury platformy Azure, ograniczyć zakres migracji tylko do składnic danych, takich jak część bazy danych OLAP magazynu Teradata. Zarówno metody migracji metodą "lift-and-shift" ograniczają zakres migracji początkowej tylko do składnic danych i nie dotyczą szerszych aspektów migracji, takich jak migracja ETL i migracja danych historycznych. Można jednak rozwiązać te aspekty w późniejszych fazach projektu, gdy zmigrowana warstwa składnicy danych jest wypełniana z danymi i wymaganymi procesami kompilacji.
Migracja metodą "lift and shift" a podejście etapowe
Ogólnie rzecz biorąc, istnieją dwa typy migracji niezależnie od celu i zakresu planowanej migracji: lift and shift as-is i podejście etapowe, które obejmuje zmiany.
Migrowanie metodą „lift-and-shift”
W przypadku migracji metodą "lift and shift" istniejący model danych, taki jak schemat gwiazdy, jest migrowany bez zmian do nowej platformy Azure Synapse. Takie podejście minimalizuje ryzyko i czas migracji, skracając pracę wymaganą do realizacji korzyści związanych z przejściem do środowiska chmury platformy Azure. Migracja metodą "lift and shift" jest dobrym rozwiązaniem w następujących scenariuszach:
- Masz istniejące środowisko Teradata z pojedynczą składnicą danych do migracji lub
- Masz istniejące środowisko Teradata z danymi, które są już w dobrze zaprojektowanym schemacie gwiazdy lub płatka śniegu, lub
- Czas i presja kosztów jest niewystarczająca, aby przejść do nowoczesnego środowiska chmury.
Napiwek
Lift and shift to dobry punkt wyjścia, nawet jeśli kolejne fazy implementują zmiany w modelu danych.
Podejście etapowe, które obejmuje zmiany
Jeśli starszy magazyn danych ewoluował przez długi czas, może być konieczne ponowne zaprojektowanie go w celu zachowania wymaganych poziomów wydajności. Konieczne może być również ponowne tworzenie inżynierów w celu obsługi nowych danych, takich jak strumienie Internetu rzeczy (IoT). W ramach procesu ponownej inżynierii przeprowadź migrację do usługi Azure Synapse, aby uzyskać korzyści ze skalowalnego środowiska w chmurze. Migracja może również obejmować zmianę bazowego modelu danych, na przykład przejście z modelu Inmon do magazynu danych.
Firma Microsoft zaleca przeniesienie istniejącego modelu danych na platformę Azure (opcjonalnie przy użyciu wystąpienia teradata maszyny wirtualnej na platformie Azure) oraz użycie wydajności i elastyczności środowiska platformy Azure w celu zastosowania zmian inżynierii. Dzięki temu możesz użyć możliwości platformy Azure, aby wprowadzić zmiany bez wpływu na istniejący system źródłowy.
Używanie wystąpienia teradata maszyny wirtualnej platformy Azure w ramach migracji
Podczas migracji z lokalnego środowiska Teradata można wykorzystać magazyn w chmurze i elastyczną skalowalność na platformie Azure, aby utworzyć wystąpienie teradata na maszynie wirtualnej. Takie podejście powoduje utworzenie wystąpienia teradata z docelowym środowiskiem usługi Azure Synapse. Możesz użyć standardowych narzędzi Teradata, takich jak Teradata Parallel Data Transporter, aby efektywnie przenieść podzbiór tabel Teradata migrowanych do wystąpienia maszyny wirtualnej. Następnie wszystkie dalsze zadania migracji mogą wystąpić w środowisku platformy Azure. Takie podejście ma kilka korzyści:
Po początkowej replikacji danych system źródłowy nie ma wpływu na zadania migracji.
Znane interfejsy, narzędzia i narzędzia teradata są dostępne w środowisku platformy Azure.
Środowisko platformy Azure pomija wszelkie potencjalne problemy z dostępnością przepustowości sieci między lokalnym systemem źródłowym a systemem docelowym chmury.
Narzędzia, takie jak Azure Data Factory, mogą wywoływać narzędzia, takie jak Teradata Parallel Transporter, aby wydajnie i szybko migrować dane.
Proces migracji można organizować i kontrolować w całości w środowisku platformy Azure.
Napiwek
Użyj maszyn wirtualnych platformy Azure, aby utworzyć tymczasowe wystąpienie teradata, aby przyspieszyć migrację i zminimalizować wpływ na system źródłowy.
Wdrażanie migracji opartej na metadanych za pomocą usługi Azure Data Factory
Proces migracji można zautomatyzować i zorganizować przy użyciu możliwości środowiska platformy Azure. Takie podejście minimalizuje trafienie wydajności w istniejącym środowisku Netezza, które może już działać blisko pojemności.
Azure Data Factory to oparta na chmurze usługa integracji danych, która obsługuje tworzenie opartych na danych przepływów pracy w chmurze, które organizują i automatyzują przenoszenie danych i przekształcanie danych. Za pomocą usługi Data Factory można tworzyć i planować oparte na danych przepływy pracy (potoki), które pozyskują dane z różnych magazynów danych. Usługa Data Factory może przetwarzać i przekształcać dane przy użyciu usług obliczeniowych, takich jak Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics i Azure Machine Edukacja.
Podczas planowania używania obiektów usługi Data Factory do zarządzania procesem migracji utwórz metadane zawierające listę wszystkich tabel danych, które mają zostać zmigrowane i ich lokalizację.
Różnice projektowe między usługą Teradata i usługą Azure Synapse
Jak wspomniano wcześniej, istnieją pewne podstawowe różnice w podejściu między bazami danych Teradata i Azure Synapse Analytics, a te różnice zostały omówione w dalszej części.
Wiele baz danych a pojedyncza baza danych i schematy
Środowisko Teradata często zawiera wiele oddzielnych baz danych. Na przykład mogą istnieć oddzielne bazy danych: pozyskiwanie danych i tabele przejściowe, podstawowe tabele magazynu i składnice danych (czasami nazywane warstwą semantyczną). Procesy potoków ETL lub ELT mogą implementować sprzężenia między bazami danych i przenosić dane między oddzielnymi bazami danych.
Z kolei środowisko usługi Azure Synapse zawiera pojedynczą bazę danych i używa schematów do oddzielania tabel w logicznie oddzielne grupy. Zalecamy użycie serii schematów w docelowej bazie danych usługi Azure Synapse w celu naśladowania oddzielnych baz danych migrowanych ze środowiska Teradata. Jeśli środowisko Teradata używa już schematów, może być konieczne użycie nowej konwencji nazewnictwa podczas przenoszenia istniejących tabel i widoków teradata do nowego środowiska. Można na przykład połączyć istniejące nazwy schematów i tabel Teradata z nową nazwą tabeli usługi Azure Synapse i użyć nazw schematów w nowym środowisku, aby zachować oryginalne oddzielne nazwy baz danych. Jeśli nazewnictwo konsolidacji schematów ma kropki, usługa Azure Synapse Spark może mieć problemy. Mimo że można używać widoków SQL na podstawie bazowych tabel do obsługi struktur logicznych, istnieją potencjalne wady tego podejścia:
Widoki w usłudze Azure Synapse są tylko do odczytu, więc wszystkie aktualizacje danych muszą odbywać się w podstawowych tabelach podstawowych.
Może już istnieć co najmniej jedna warstwa widoków i dodanie dodatkowej warstwy widoków może mieć wpływ na wydajność i obsługę, ponieważ zagnieżdżone widoki są trudne do rozwiązania.
Napiwek
Połącz wiele baz danych w jedną bazę danych w usłudze Azure Synapse i użyj nazw schematów, aby logicznie oddzielić tabele.
Zagadnienia dotyczące tabeli
Podczas migracji tabel między różnymi środowiskami zazwyczaj tylko nieprzetworzone dane i metadane, które opisują je fizycznie. Inne elementy bazy danych z systemu źródłowego, takie jak indeksy, zwykle nie są migrowane, ponieważ mogą być niepotrzebne lub zaimplementowane inaczej w nowym środowisku. Optymalizacje wydajności w środowisku źródłowym, takie jak indeksy, wskazują, gdzie można dodać optymalizację wydajności w nowym środowisku. Jeśli na przykład tabela w środowisku źródłowym Teradata ma nieukonfigurowany indeks pomocniczy (NUSI), sugeruje to, że indeks nieklasowany powinien zostać utworzony w usłudze Azure Synapse. Inne natywne techniki optymalizacji wydajności, takie jak replikacja tabel, mogą być bardziej odpowiednie niż proste tworzenie indeksów podobnych do podobnych.
Napiwek
Istniejące indeksy wskazują kandydatów do indeksowania w zmigrowanym magazynie.
Wysoka dostępność bazy danych
Teradata obsługuje replikację danych między węzłami za pośrednictwem FALLBACK opcji, która replikuje wiersze tabeli, które znajdują się fizycznie w danym węźle do innego węzła w systemie. Takie podejście gwarantuje, że dane nie zostaną utracone, jeśli wystąpi awaria węzła i zapewni podstawę scenariuszy trybu failover.
Celem architektury wysokiej dostępności w usłudze Azure Synapse Analytics jest zagwarantowanie, że baza danych jest uruchomiona przez 99,9% czasu, bez obaw o wpływ operacji konserwacji i awarii. Aby uzyskać więcej informacji na temat umowy SLA, zobacz Umowa SLA dla usługi Azure Synapse Analytics. Platforma Azure automatycznie obsługuje krytyczne zadania obsługi, takie jak stosowanie poprawek, kopie zapasowe i uaktualnienia systemu Windows i sql. Platforma Azure automatycznie obsługuje również nieplanowane zdarzenia, takie jak awarie w bazowym sprzęcie, oprogramowaniu lub sieci.
Magazyn danych w usłudze Azure Synapse jest automatycznie kopii zapasowej za pomocą migawek. Te migawki to wbudowana funkcja usługi, która tworzy punkty przywracania. Nie musisz włączać tej funkcji. Użytkownicy nie mogą obecnie usuwać automatycznych punktów przywracania używanych przez usługę do obsługi umów dotyczących poziomu usług (SLA) na potrzeby odzyskiwania.
Dedykowana pula SQL usługi Azure Synapse tworzy migawki magazynu danych przez cały dzień w celu utworzenia punktów przywracania, które są dostępne przez siedem dni. Nie można zmienić tego okresu przechowywania. Usługa Azure Synapse obsługuje ośmiogodzinny cel punktu odzyskiwania (RPO). Magazyn danych można przywrócić w regionie podstawowym z dowolnej migawki wykonanej w ciągu ostatnich siedmiu dni. Jeśli potrzebujesz bardziej szczegółowych kopii zapasowych, możesz użyć innej opcji zdefiniowanej przez użytkownika.
Nieobsługiwane typy tabel Teradata
Teradata obsługuje specjalne typy tabel dla szeregów czasowych i danych czasowych. Składnia i niektóre funkcje dla tych typów tabel nie są bezpośrednio obsługiwane w usłudze Azure Synapse. Można jednak przeprowadzić migrację danych do standardowej tabeli w usłudze Azure Synapse, mapując na odpowiednie typy danych i indeksowanie lub partycjonowanie kolumny daty/godziny.
Napiwek
Tabele standardowe w usłudze Azure Synapse mogą obsługiwać zmigrowane szeregi czasowe i dane czasowe teradata.
Teradata implementuje funkcje zapytań czasowych przy użyciu ponownego zapisywania zapytań w celu dodania dodatkowych filtrów w zapytaniu czasowym w celu ograniczenia odpowiedniego zakresu dat. Jeśli planujesz migrację tej funkcji ze źródłowego środowiska Teradata, dodaj dodatkowe filtrowanie do odpowiednich zapytań czasowych.
Usługa Azure wsparcie środowiska szczegółowe informacje o szeregach czasowych na potrzeby złożonej analizy danych szeregów czasowych na dużą skalę. Ta funkcja jest przeznaczona dla aplikacji do analizy danych IoT.
Różnice składni języka SQL DML
Różnice składni języka DML (SQL Data Manipulation Language) istnieją między językami Teradata SQL i Azure Synapse T-SQL:
QUALIFY: Teradata obsługujeQUALIFYoperator . Na przykład:SELECT col1 FROM tab1 WHERE col1='XYZ' QUALIFY ROW_NUMBER () OVER (PARTITION by col1 ORDER BY col1) = 1;Równoważna składnia usługi Azure Synapse to:
SELECT * FROM ( SELECT col1, ROW_NUMBER () OVER (PARTITION by col1 ORDER BY col1) rn FROM tab1 WHERE col1='XYZ' ) WHERE rn = 1;Arytmetyka dat: usługa Azure Synapse zawiera operatory, takie jak
DATEADDiDATEDIFF, których można używać w polach lubDATETIME.DATETeradata obsługuje odejmowanie bezpośrednie w datach, takich jakSELECT DATE1 - DATE2 FROM...GROUP BY: dla porządkowegoGROUP BYjawnie podaj nazwę kolumny języka T-SQL.LIKE ANY: Teradata obsługujeLIKE ANYskładnię, taką jak:SELECT * FROM CUSTOMER WHERE POSTCODE LIKE ANY ('CV1%', 'CV2%', 'CV3%');Odpowiednikiem składni usługi Azure Synapse jest:
SELECT * FROM CUSTOMER WHERE (POSTCODE LIKE 'CV1%') OR (POSTCODE LIKE 'CV2%') OR (POSTCODE LIKE 'CV3%');W zależności od ustawień systemowych porównania znaków w usłudze Teradata mogą być domyślnie niewrażliwe na wielkość liter. W usłudze Azure Synapse porównania znaków są zawsze uwzględniane wielkości liter.
Funkcje, procedury składowane, wyzwalacze i sekwencje
Podczas migrowania magazynu danych ze środowiska dojrzałego, takiego jak Teradata, prawdopodobnie trzeba migrować elementy inne niż proste tabele i widoki. Przykłady obejmują funkcje, procedury składowane, wyzwalacze i sekwencje. Sprawdź, czy narzędzia w środowisku platformy Azure mogą zastąpić funkcje, procedury składowane i sekwencje, ponieważ zwykle bardziej wydajne jest używanie wbudowanych narzędzi platformy Azure niż ponowne kodowanie tych elementów dla usługi Azure Synapse.
W ramach fazy przygotowania utwórz spis obiektów, które muszą zostać zmigrowane, zdefiniuj metodę ich obsługi i przydziel odpowiednie zasoby w planie migracji.
Partnerzy integracji danych oferują narzędzia i usługi, które mogą zautomatyzować migrację funkcji, procedur składowanych i sekwencji.
W poniższych sekcjach szczegółowo omówiono migrację funkcji, procedur składowanych i sekwencji.
Funkcje
Podobnie jak w przypadku większości produktów baz danych, teradata obsługuje funkcje systemowe i zdefiniowane przez użytkownika w ramach implementacji SQL. Podczas migracji starszej platformy bazy danych do usługi Azure Synapse typowe funkcje systemowe mogą być zwykle migrowane bez zmian. Niektóre funkcje systemowe mogą mieć nieco inną składnię, ale wszelkie wymagane zmiany można zautomatyzować.
W przypadku funkcji systemowych Teradata lub dowolnych funkcji zdefiniowanych przez użytkownika, które nie mają odpowiedników w usłudze Azure Synapse, zakoduj ponownie te funkcje przy użyciu docelowego języka środowiska. Usługa Azure Synapse używa języka Transact-SQL do implementowania funkcji zdefiniowanych przez użytkownika.
Procedury składowane
Większość nowoczesnych produktów baz danych obsługuje procedury przechowywania w bazie danych. Teradata udostępnia język SPL w tym celu. Procedura składowana zwykle zawiera zarówno instrukcje SQL, jak i logikę proceduralną oraz zwraca dane lub stan.
Usługa Azure Synapse obsługuje procedury składowane przy użyciu języka T-SQL, dlatego należy ponownie zakodować wszystkie zmigrowane procedury składowane w tym języku.
Wyzwalacze
Usługa Azure Synapse nie obsługuje tworzenia wyzwalacza, ale tworzenie wyzwalacza można zaimplementować przy użyciu usługi Azure Data Factory.
Sekwencje
Usługa Azure Synapse obsługuje sekwencje w podobny sposób do teradata i można zaimplementować sekwencje przy użyciu kolumn IDENTITY lub kodu SQL, który generuje następny numer sekwencji w serii. Sekwencja udostępnia unikatowe wartości liczbowe, których można użyć jako wartości klucza zastępczego dla kluczy podstawowych.
Wyodrębnianie metadanych i danych ze środowiska Teradata
Generowanie języka DDL (Data Definition Language)
Standard ANSI SQL definiuje podstawową składnię poleceń języka Data Definition Language (DDL). Niektóre polecenia DDL, takie jak CREATE TABLE i CREATE VIEW, są wspólne zarówno dla teradata, jak i usługi Azure Synapse, ale także udostępniają funkcje specyficzne dla implementacji, takie jak indeksowanie, dystrybucja tabel i opcje partycjonowania.
Istniejące dane teradata CREATE TABLE i CREATE VIEW skrypty można edytować, aby uzyskać równoważne definicje w usłudze Azure Synapse. W tym celu może być konieczne użycie zmodyfikowanych typów danych i usunięcie lub zmodyfikowanie klauzul specyficznych dla danych Teradata, takich jak FALLBACK.
Jednak wszystkie informacje, które określają bieżące definicje tabel i widoków w istniejącym środowisku Teradata, są przechowywane w tabelach wykazu systemu. Te tabele są najlepszym źródłem tych informacji, ponieważ gwarantowane jest, że są aktualne i kompletne. Dokumentacja przechowywana przez użytkownika może nie być zsynchronizowana z bieżącymi definicjami tabeli.
W środowisku Teradata tabele wykazu systemu określają bieżącą tabelę i definicję widoku. W przeciwieństwie do dokumentacji obsługiwanej przez użytkownika informacje o katalogu systemowym są zawsze kompletne i zsynchronizowane z bieżącymi definicjami tabeli. Za pomocą widoków do wykazu, takiego jak DBC.ColumnsV, można uzyskać dostęp do informacji katalogu systemu w celu wygenerowania CREATE TABLE instrukcji DDL, które tworzą równoważne tabele w usłudze Azure Synapse.
Napiwek
Użyj istniejących metadanych teradata, aby zautomatyzować generowanie CREATE TABLE i CREATE VIEW DDL dla usługi Azure Synapse.
Aby uzyskać podobne wyniki, można również użyć narzędzi do migracji innych firm i narzędzi ETL, które przetwarzają informacje o katalogu systemu.
Wyodrębnianie danych z teradata
Nieprzetworzone dane tabeli można wyodrębnić z tabel Teradata do prostych plików rozdzielonych, takich jak pliki CSV, przy użyciu standardowych narzędzi Teradata, takich jak podstawowe zapytanie Teradata (BTEQ), Teradata FastExport lub Teradata Parallel Transporter (TPT). Użyj TPT, aby wyodrębnić dane tabeli tak wydajnie, jak to możliwe. Funkcja TPT używa wielu równoległych strumieni FastExport w celu osiągnięcia najwyższej przepływności.
Napiwek
Użyj usługi Teradata Parallel Transporter do najbardziej wydajnego wyodrębniania danych.
Wywołaj metodę TPT bezpośrednio z usługi Azure Data Factory. Jest to zalecane podejście do migracji danych wystąpień lokalnych teradata i wystąpień teradata uruchamianych w ramach maszyny wirtualnej w środowisku platformy Azure.
Wyodrębnione pliki danych powinny zawierać rozdzielany tekst w formacie CSV, zoptymalizowanym kolumnie wierszy (ORC) lub Parquet.
Aby uzyskać więcej informacji na temat migrowania danych i etL ze środowiska Teradata, zobacz Migracja danych, ETL i ładowanie migracji teradata.
Zalecenia dotyczące wydajności migracji teradata
Celem optymalizacji wydajności jest taka sama lub lepsza wydajność magazynu danych po migracji do usługi Azure Synapse.
Napiwek
Określ priorytety opcji dostrajania w usłudze Azure Synapse na początku migracji.
Różnice w podejściu dostrajania wydajności
W tej sekcji przedstawiono różnice implementacji dostrajania wydajności niskiego poziomu między usługą Teradata i usługą Azure Synapse.
Opcje dystrybucji danych
W celu uzyskania wydajności usługa Azure Synapse została zaprojektowana z architekturą z wieloma węzłami i korzysta z przetwarzania równoległego. Aby zoptymalizować wydajność poszczególnych tabel w usłudze Azure Synapse, możesz zdefiniować opcję dystrybucji danych w CREATE TABLE instrukcjach przy użyciu instrukcji DISTRIBUTION . Można na przykład określić tabelę rozproszoną przy użyciu skrótu, która dystrybuuje wiersze tabeli między węzłami obliczeniowymi przy użyciu funkcji wyznaczania wartości skrótu deterministycznego. Celem jest zmniejszenie ilości danych przenoszonych między węzłami przetwarzania podczas wykonywania zapytania.
W przypadku dużych sprzężeń tabeli do dużych tabel skrót rozłóż jedną lub, najlepiej, obie tabele w jednej z kolumn sprzężenia — która ma szeroki zakres wartości, aby zapewnić równomierną dystrybucję. Przeprowadź przetwarzanie sprzężenia lokalnie, ponieważ wiersze danych, które zostaną połączone, są sortowane w tym samym węźle przetwarzania.
Usługa Azure Synapse obsługuje również sprzężenia lokalne między małą tabelą a dużą tabelą za pośrednictwem małej replikacji tabel. Rozważmy na przykład małą tabelę wymiarów i dużą tabelę faktów w modelu schematu gwiazdy. Usługa Azure Synapse może replikować mniejszą tabelę wymiarów we wszystkich węzłach, aby upewnić się, że wartość dowolnego klucza sprzężenia dla dużej tabeli ma pasujący, lokalnie dostępny wiersz wymiaru. Obciążenie replikacji tabeli wymiarów jest stosunkowo niskie dla małej tabeli wymiarów. W przypadku tabel dużych wymiarów bardziej odpowiednie jest podejście dystrybucji skrótów. Aby uzyskać więcej informacji na temat opcji dystrybucji danych, zobacz Wskazówki dotyczące projektowania dotyczące używania replikowanych tabel i Wskazówki dotyczące projektowania tabel rozproszonych.
Indeksowanie danych
Usługa Azure Synapse obsługuje kilka opcji indeksowania z możliwością definiowania użytkownika, które różnią się od opcji indeksowania zaimplementowanych w usłudze Teradata. Aby uzyskać więcej informacji na temat różnych opcji indeksowania w usłudze Azure Synapse, zobacz Indeksy w dedykowanych tabelach puli SQL.
Istniejące indeksy w środowisku źródłowym Teradata zapewniają przydatne wskazanie użycia danych i kolumn kandydatów do indeksowania w środowisku usługi Azure Synapse.
Data partitioning (Partycjonowanie danych)
W magazynie danych przedsiębiorstwa tabele faktów mogą zawierać miliardy wierszy. Partycjonowanie optymalizuje konserwację i wydajność zapytań tych tabel, dzieląc je na oddzielne części, aby zmniejszyć ilość przetwarzanych danych. W usłudze Azure Synapse CREATE TABLE instrukcja definiuje specyfikację partycjonowania dla tabeli. Partycjonuj tylko bardzo duże tabele i upewnij się, że każda partycja zawiera co najmniej 60 milionów wierszy.
Do partycjonowania można używać tylko jednego pola na tabelę. To pole jest często polem daty, ponieważ wiele zapytań jest filtrowanych według daty lub zakresu dat. Po początkowym załadowaniu można zmienić partycjonowanie tabeli przy użyciu instrukcji (CTAS), aby ponownie utworzyć tabelę przy użyciu CREATE TABLE AS nowej dystrybucji. Aby zapoznać się ze szczegółowym omówieniem partycjonowania w usłudze Azure Synapse, zobacz Partycjonowanie tabel w dedykowanej puli SQL.
Statystyki tabeli danych
Należy upewnić się, że statystyki dotyczące tabel danych są aktualne, tworząc krok statystyki dla zadań ETL/ELT.
Program PolyBase lub COPY INTO na potrzeby ładowania danych
Technologia PolyBase obsługuje wydajne ładowanie dużych ilości danych do magazynu danych przy użyciu strumieni ładowania równoległego. Aby uzyskać więcej informacji, zobacz Strategia ładowania danych polyBase.
FUNKCJA COPY INTO obsługuje również pozyskiwanie danych o wysokiej przepływności i:
Pobieranie danych ze wszystkich plików w folderze i podfolderach.
Pobieranie danych z wielu lokalizacji na tym samym koncie magazynu. Można określić wiele lokalizacji przy użyciu ścieżek rozdzielanych przecinkami.
Usługi Azure Data Lake Storage (ADLS) i Azure Blob Storage.
Formaty plików CSV, PARQUET i ORC.
Zarządzanie obciążeniami
Uruchamianie mieszanych obciążeń może stanowić wyzwanie dla zasobów w systemach zajętych. Pomyślny schemat zarządzania obciążeniami skutecznie zarządza zasobami, zapewnia wysoce wydajne wykorzystanie zasobów i maksymalizuje zwrot z inwestycji (ROI). Klasyfikacja obciążeń, ważność obciążenia i izolacja obciążenia zapewniają większą kontrolę nad sposobem korzystania z zasobów systemowych przez obciążenie.
W przewodniku zarządzania obciążeniami opisano techniki analizowania obciążenia, zarządzania i monitorowania ważności obciążenia oraz kroków konwertowania klasy zasobów na grupę obciążeń. Użyj witryny Azure Portal i zapytań T-SQL w widokach DMV, aby monitorować obciążenie w celu zapewnienia efektywnego wykorzystania odpowiednich zasobów.
Następne kroki
Aby dowiedzieć się więcej o etL i obciążeniu migracji teradata, zobacz następny artykuł w tej serii: Migracja danych, ETL i ładowanie migracji teradata.