Szybki start: ładowanie zbiorcze za pomocą programu Synapse Studio
Ładowanie danych jest łatwe za pomocą kreatora ładowania zbiorczego w programie Synapse Studio. Usługa Synapse Studio to funkcja usługi Azure Synapse Analytics. Kreator ładowania zbiorczego przeprowadzi Cię przez proces tworzenia skryptu T-SQL za pomocą instrukcji COPY w celu zbiorczego ładowania danych do dedykowanej puli SQL.
Punkty wejścia kreatora ładowania zbiorczego
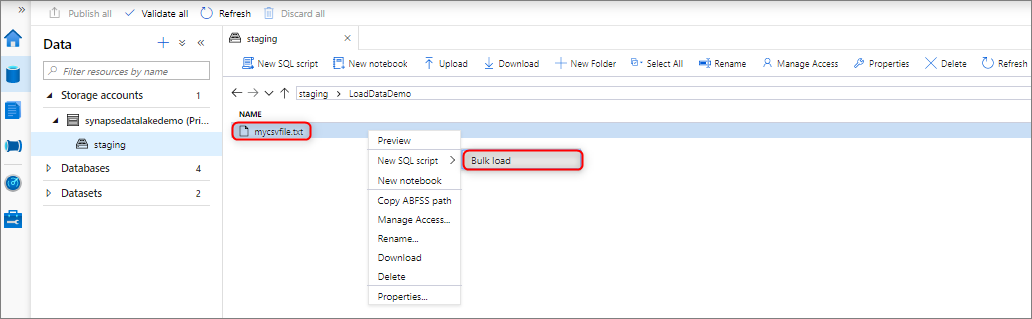
Dane można ładować zbiorczo, klikając prawym przyciskiem myszy następujący obszar w programie Synapse Studio: plik lub folder z konta usługi Azure Storage dołączonego do obszaru roboczego.
Wymagania wstępne
Kreator generuje instrukcję COPY, która używa przekazywania firmy Microsoft do uwierzytelniania. Użytkownik firmy Microsoft Entra musi mieć dostęp do obszaru roboczego z co najmniej rolą współautora danych obiektu blob usługi Storage dla konta usługi Azure Data Lake Storage Gen2.
Jeśli tworzysz nową tabelę do załadowania, musisz mieć wymagane uprawnienia do używania instrukcji COPY i Create Table.
Połączona usługa skojarzona z kontem usługi Data Lake Storage Gen2 musi mieć dostęp do pliku lub folderu do załadowania. Jeśli na przykład mechanizm uwierzytelniania połączonej usługi jest tożsamością zarządzaną, tożsamość zarządzana obszaru roboczego musi mieć co najmniej uprawnienie Czytelnik danych obiektu blob usługi Storage na koncie magazynu.
Jeśli sieć wirtualna jest włączona w obszarze roboczym, upewnij się, że zintegrowane środowisko uruchomieniowe skojarzone z połączonymi usługami konta usługi Data Lake Storage Gen2 dla danych źródłowych i lokalizacji pliku błędów ma włączoną interaktywną funkcję tworzenia. Tworzenie interakcyjne jest wymagane do wykrywania autoschemy, wyświetlania podglądu zawartości pliku źródłowego i przeglądania kont magazynu usługi Data Lake Storage Gen2 w kreatorze.
Kroki
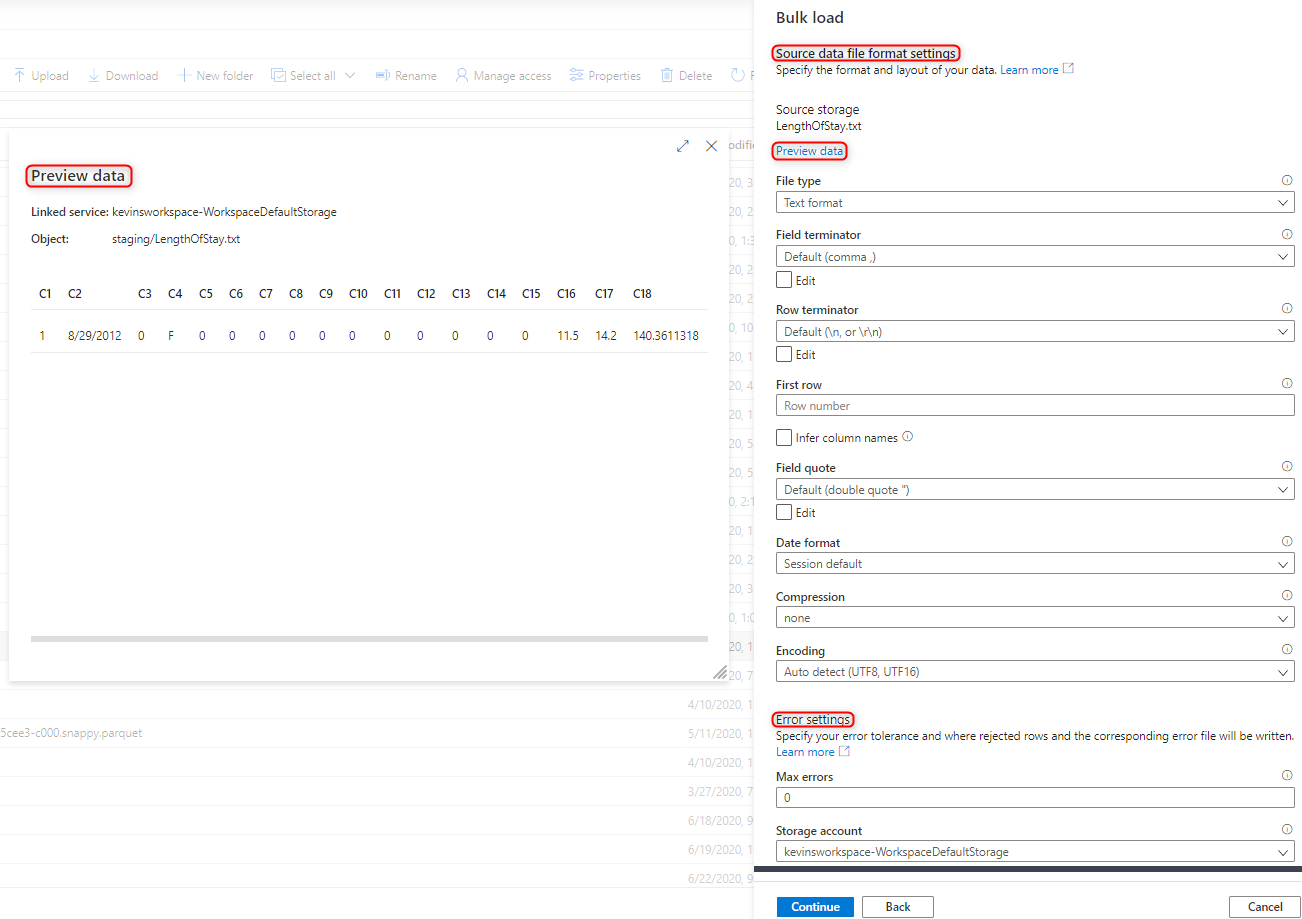
Na panelu Lokalizacja magazynu źródłowego wybierz konto magazynu i plik lub folder, z którego się ładujesz. Kreator automatycznie próbuje wykryć pliki Parquet i rozdzielane pliki tekstowe (CSV), w tym mapowanie pól źródłowych z pliku na odpowiednie docelowe typy danych SQL.

Wybierz ustawienia formatu pliku, w tym ustawienia błędu, jeśli podczas procesu ładowania zbiorczego są odrzucane wiersze. Możesz również wybrać pozycję Podgląd danych , aby zobaczyć, jak instrukcja COPY przeanalizuje plik, aby ułatwić skonfigurowanie ustawień formatu pliku. Wybierz pozycję Podgląd danych za każdym razem, gdy zmieniasz ustawienie formatu pliku, aby zobaczyć, jak instrukcja COPY przeanalizuje plik przy użyciu zaktualizowanego ustawienia.
Uwaga
- Kreator ładowania zbiorczego nie obsługuje wyświetlania podglądu danych za pomocą terminatorów pól wieloznacznych. Po określeniu terminatora pola wieloznakowego kreator wyświetli podgląd danych w jednej kolumnie.
- Po wybraniu nazw kolumn wnioskowania kreator obciążenia zbiorczego przeanalizuje nazwy kolumn z pierwszego wiersza określonego przez pole Pierwszy wiersz . Kreator ładowania zbiorczego
FIRSTROWautomatycznie zwiększa wartość instrukcji COPY przez 1, aby zignorować ten wiersz nagłówka. - Określanie terminatorów wierszy wieloznacznych jest obsługiwane w instrukcji COPY. Jednak kreator ładowania zbiorczego nie obsługuje go i zgłosi błąd.
Wybierz dedykowaną pulę SQL używaną do załadowania, w tym niezależnie od tego, czy obciążenie będzie dotyczyć istniejącej tabeli, czy nowej tabeli.
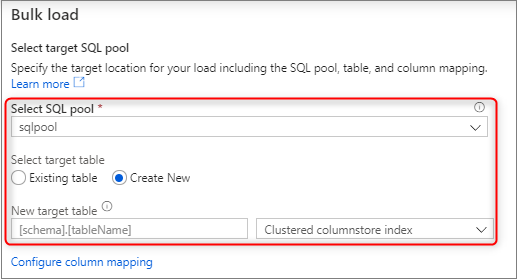
Wybierz pozycję Konfiguruj mapowanie kolumn, aby upewnić się, że masz odpowiednie mapowanie kolumn. W przypadku włączenia nazw kolumn wnioskowanie nazwy kolumn zostaną wykryte automatycznie. W przypadku nowych tabel konfigurowanie mapowania kolumn ma kluczowe znaczenie dla aktualizowania typów danych kolumn docelowych.

Wybierz pozycję Otwórz skrypt. Skrypt języka T-SQL jest generowany za pomocą instrukcji COPY w celu załadowania z magazynu data lake.

Następne kroki
- Zapoznaj się z artykułem dotyczącym instrukcji COPY, aby uzyskać więcej informacji na temat możliwości kopiowania.
- Zapoznaj się z artykułem omówienie ładowania danych, aby uzyskać informacje o korzystaniu z procesu wyodrębniania, przekształcania i ładowania (ETL).